很多人第一次用 MongoDB,看到 find() 返回一个 JavaScript 对象,就自然以为「MongoDB 存的是 JSON」。这个认知在应用层成立,但一旦往下看一层就会失效:driver、mongod、WiredTiger 之间流动的根本不是 JSON 文本,而是 BSON------一种带类型标记和长度前缀的二进制格式。
理解 BSON 不是为了背字节表,而是为了回答几类实际问题:为什么 MongoDB 解析文档比「逐字符扫描 JSON」快得多?为什么存一个日期,MongoDB 比 JSON 文本省?反过来,为什么大量短字符串字段会让 BSON 比 JSON 还大?这些都是类型设计在起作用,不是接口层能解释的。
先把机制边界说清楚
BSON 的全称是 Binary JSON,但它的设计目标不是「JSON 的二进制版本」,而是「一种适合数据库快速遍历的序列化格式」。它和 JSON 的核心差别有三点:
- 每个字段自带类型标记:BSON 在字段名前用一个字节标明值的类型,所以读取时不需要猜。
- 值带长度前缀:字符串、数组、子文档都先写长度,读取时可以直接跳过,不用逐字符找结束符。
- 数值类型定长存储:int32、int64、double、timestamp 都按固定字节数存,省掉了 JSON 里数字的字符化与反序列化。
这套设计的代价是元数据开销:每个字段都要多出一个类型字节、字段名后的 \0、以及长度前缀。这也是 BSON 在短字段密集场景可能比 JSON 更大的原因。
JSON 视图 vs BSON 字节流
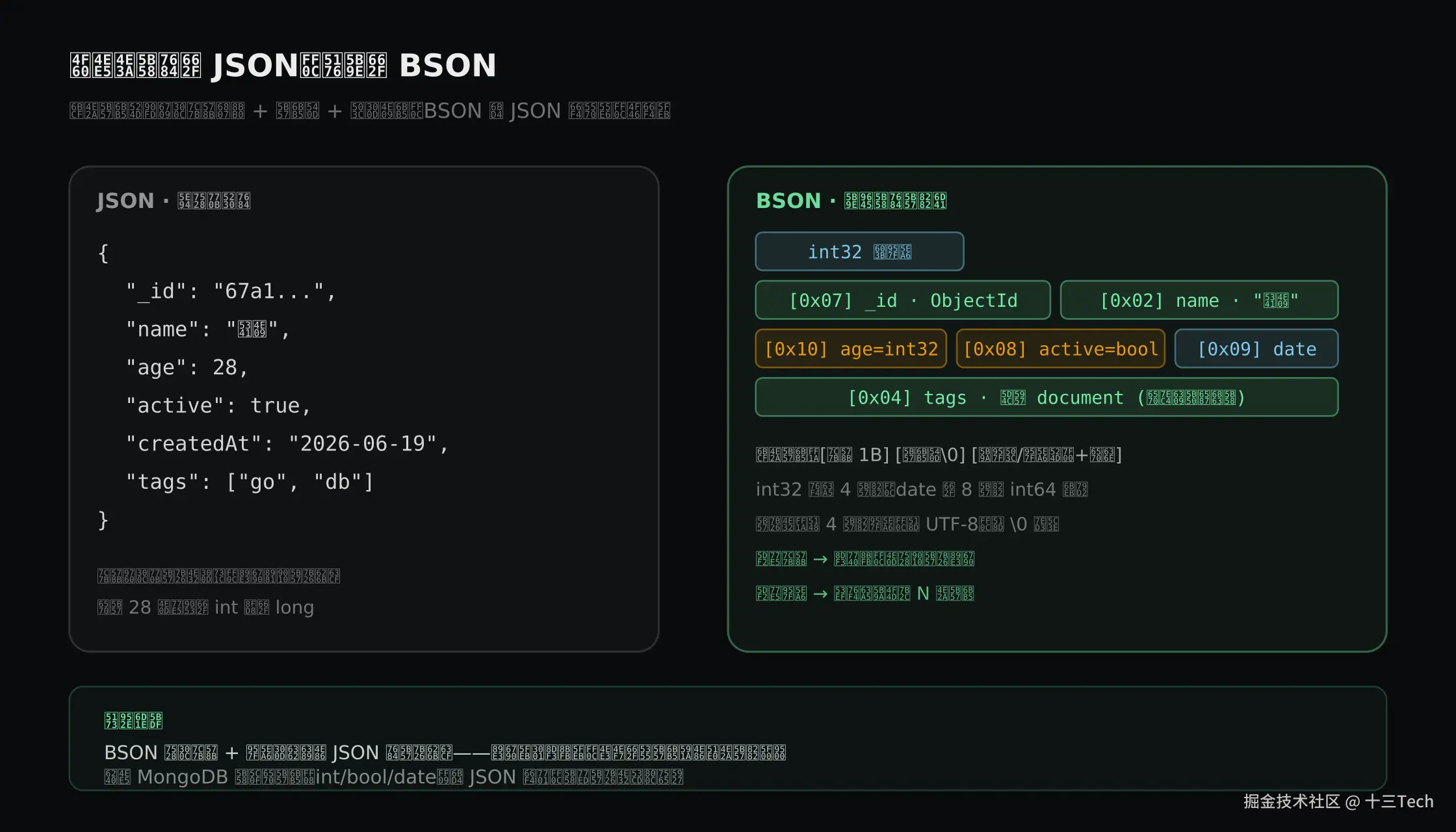
把两种表示并排放,差别立刻清晰:JSON 要靠逐字符扫描区分类型,BSON 用类型标记和长度前缀让遍历变成跳读。
这个差别在文档体量大、字段多的时候会被放大。BSON 的「已知长度 → 跳读」特性,是 MongoDB 能在索引、投影、聚合里快速定位字段的底层前提。
BSON 的核心类型与字节数
BSON 的类型表比 JSON 丰富得多,这也是它能精确表达业务语义的关键。常用的几类:
| 类型 | 标记 | 字节数 | 说明 |
|---|---|---|---|
| double | 0x01 | 8 | 64 位浮点 |
| string | 0x02 | 4 + len + 1 | 长度前缀 + UTF-8 + 终止符 |
| document | 0x03 | 变长 | 嵌套文档 |
| array | 0x04 | 变长 | 本质是 key 为 "0","1",... 的子文档 |
| binary | 0x05 | 4 + len + 1 | 任意二进制 |
| ObjectId | 0x07 | 12 | 时间戳 + 机器 + PID + 计数器 |
| bool | 0x08 | 1 | true/false |
| date | 0x09 | 8 | int64 毫秒时间戳 |
| int32 | 0x10 | 4 | 32 位整数 |
| timestamp | 0x11 | 8 | 内部复制用 |
| int64 | 0x12 | 8 | 64 位整数 |
两个反直觉的点值得记住:数组在 BSON 里就是 key 为 "0"、"1"、"2"... 的子文档 ,这也是为什么大数组在索引和内存上比想象中贵;日期是 8 字节 int64 毫秒 ,不是字符串,所以用 ISODate 存时间远比存 "2026-06-19" 这种文本高效,也能正确排序和范围查询。
为什么 BSON 比 JSON「更快但可能更大」
BSON 的快来自类型标记和长度前缀:解析器读到字段就知道类型,知道长度就能跳过整段数据,不再需要逐字符扫描。对数据库来说,跳读比扫描快一个数量级,尤其在索引页、投影和聚合这种「只关心部分字段」的场景。
BSON 的「可能更大」来自元数据开销。每个字段至少多出:1 字节类型 + 字段名后的 \0;字符串、数组、子文档还要加 4 字节长度。所以当你存一个只有 2 个字符的字段值时,元数据可能比数据本身还大。
这条规律反过来也成立:存数值和日期时 BSON 比 JSON 省 ,因为 28 在 JSON 里是 2 个字符,在 BSON 里是定长 4 字节 int32,而 2026-06-19T00:00:00Z 这种 20 字符的日期文本,BSON 只用 8 字节。
这怎么影响你选字段类型
类型选择在 BSON 层面是实打实的内存和索引成本,不是「写哪个都行」。几个可复用的判断:
- 时间用 date,不要用字符串。 字符串日期排序错、范围查询慢、还更占空间。date 是 8 字节,且天然可比较。
- ID 用 ObjectId,不要用自造字符串。 ObjectId 12 字节,自带时间戳,能单调递增,索引局部性好。
- 数字按真实范围选 int32 / int64 / double。 不要把计数器存成 double,会浪费空间且失去整数语义。
- 布尔就是 bool,不要用 0/1 整数或 "true" 字符串。 bool 只占 1 字节,且语义清晰。
- 大数组要警惕。 BSON 数组本质是子文档,元素越多元数据越多,多键索引的代价也线性增长。
几个容易踩的边界
数组越大越贵。 一个 1000 元素的数组,BSON 里是 1000 个带长度前缀的字段,文档膨胀会比直觉大。如果只是存标签,考虑用 Set 语义去重,或拆到子集合。
字段名也要算成本。 BSON 里字段名是完整存储的,userRegistrationTimestamp 比 regAt 每个文档多十几字节。千万级文档下,字段名长度会变成可观的内存开销。
$size 和数组长度。 因为数组是子文档,$size 查询便宜,但「数组里第 N 个元素满足条件」这种访问要走多键索引,成本另算。
判断框架
把上面的内容收成几条可复用的判断:
- 把 BSON 理解成「带类型标记的跳读格式」,而不是「JSON 的二进制外壳」。
- 数值、日期、布尔:BSON 比 JSON 省,优先用原生类型。
- 短字符串、短字段名密集:BSON 元数据开销会显现,要算文档平均大小。
- 数组:按子文档算成本,大数组是 MongoDB 内存和索引最常见的隐性开销。
- 任何「为什么我的集合比预期大」的疑问,先用
bsonsize()抽样看单文档字节数,再决定要不要调整类型或拆文档。
BSON 看起来只是个格式细节,但 MongoDB 的内存治理、索引代价和查询效率,大部分时候就是从这一层开始的。
关于十三Tech
我是十三,All in AI Agent 方向的架构师,专注 AI 工程实践。
我相信 AI 是程序员的最佳搭档,也希望帮助每一位开发者更好地驾驭 AI。
如果你想继续跟完这套「图解 MongoDB」,欢迎关注公众号 「十三Tech」。后续会按文档模型、索引优化、存储引擎、高可用和分片集群这条线更新。
