langchain 提供的 InMemoryVectorStore 适合学习 RAG 流程,但它的数据只存在内存里。
真实项目需要一个可以持久化、可以索引、可以被多个服务连接的向量数据库。Milvus 就是这类场景里很常见的选择。
向量数据库 Milvus
InMemoryVectorStore 适合学习,但生产环境需要持久化向量库。
Milvus 可以理解成专门给向量检索使用的数据库。
txt
MySQL:按 id、字段、索引查结构化数据
Milvus:按向量相似度查语义相关内容安装 milvus
这里采用 docker 来进行安装(如何安装 docker 这里就不说了)。
第一步,先去 github.com/milvus-io/m... 下载一个 yml 文件,记住保存路径。
第二步,采用 docker-compose 来运行上面的 yml 文件:
bash
docker compose -f ./milvus-standalone-docker-compose.yml up -d第三步,就可以在 docker 客户端中,看到 Milvus 镜像,也启动容器了。
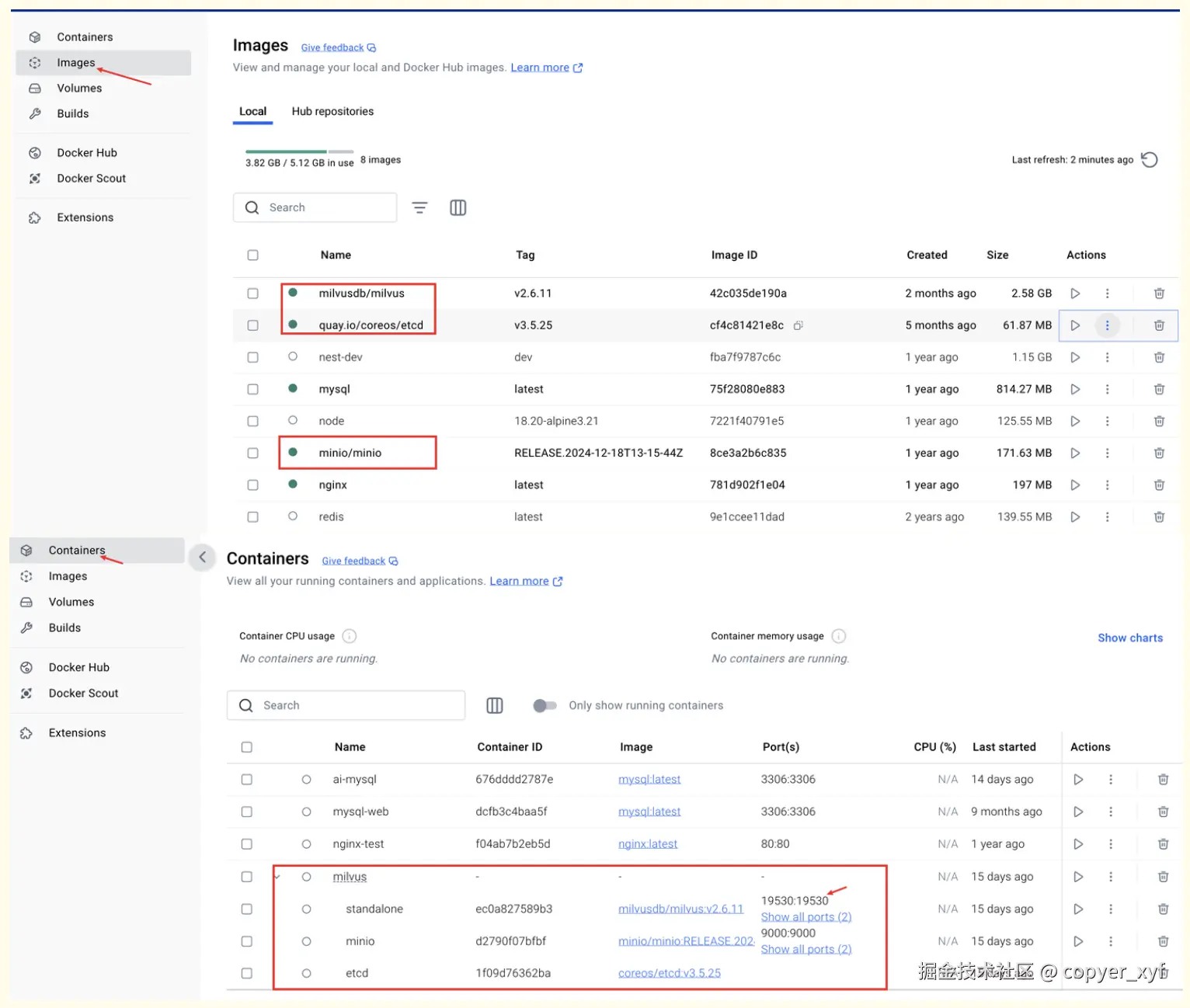
可以看到 milvus 数据库是跑在 19530 端口上的。
查看是否启动成功没有:http://localhost:9091/healthz,访问网页,出现 OK 就代表成功了。
安装 Attu
Attu 是 Milvus 生态最好的 GUI 工具。
根据自己的电脑型号下载对应的安装包即可。安装成功之后,启动软件
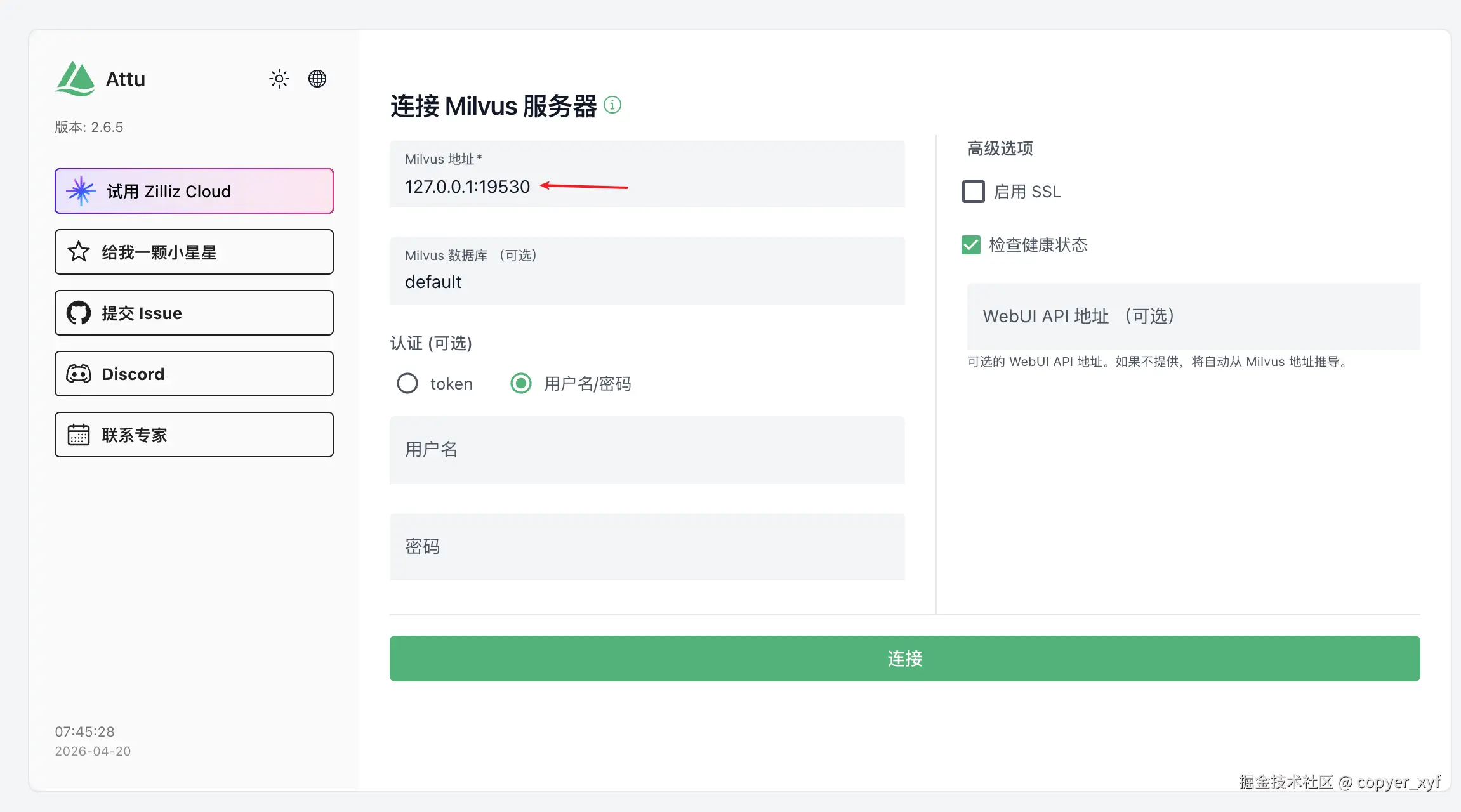
按照默认配置即可,直接点击 连接,就可以成功连接了。至于这个可视化界面,就自己去熟悉了。
Milvus 理解与实操
在写 Milvus 代码之前,先熟悉几个概念。
-
Collection类似数据库表。日记、文章、商品、客服知识库,都可以各自建成一个 collection。 -
Field类似表字段 。比如id、content、date都是普通字段。 -
Vector Field是向量字段,它是向量数据库的核心。RAG 检索时,真正参与相似度计算的是这个字段。 -
Index是向量索引,用来加速相似度检索。数据量变大后,不能每次查询都遍历所有向量。 -
Metric是相似度计算方式。文本语义检索里,通常优先试COSINE,也就是余弦相似度。
字段的常见类型:
DataType.VARCHAR表示字符串。DataType.FLOAT_VECTOR表示浮点向量。DataType.INT64表示 64 位整数。DataType.BOOL表示布尔值。
常见索引:
FLAT是暴力搜索,适合小数据和高精度场景。IVF_FLAT是比较通用的倒排文件索引。IVF_PQ会做量化,适合更大规模并且希望节省内存的场景。HNSW是图索引,召回效果好,但更吃内存。AUTOINDEX可以让 Milvus 自动选择,适合先跑通流程。
常见相似度计算方式:
COSINE适合文本语义搜索。L2是欧几里得距离。IP是内积。
接下来编写代码。
先安装 Python SDK 和 embedding 依赖:
bash
uv add pymilvus langchain-openai示例默认 Milvus 服务在http://localhost:19530
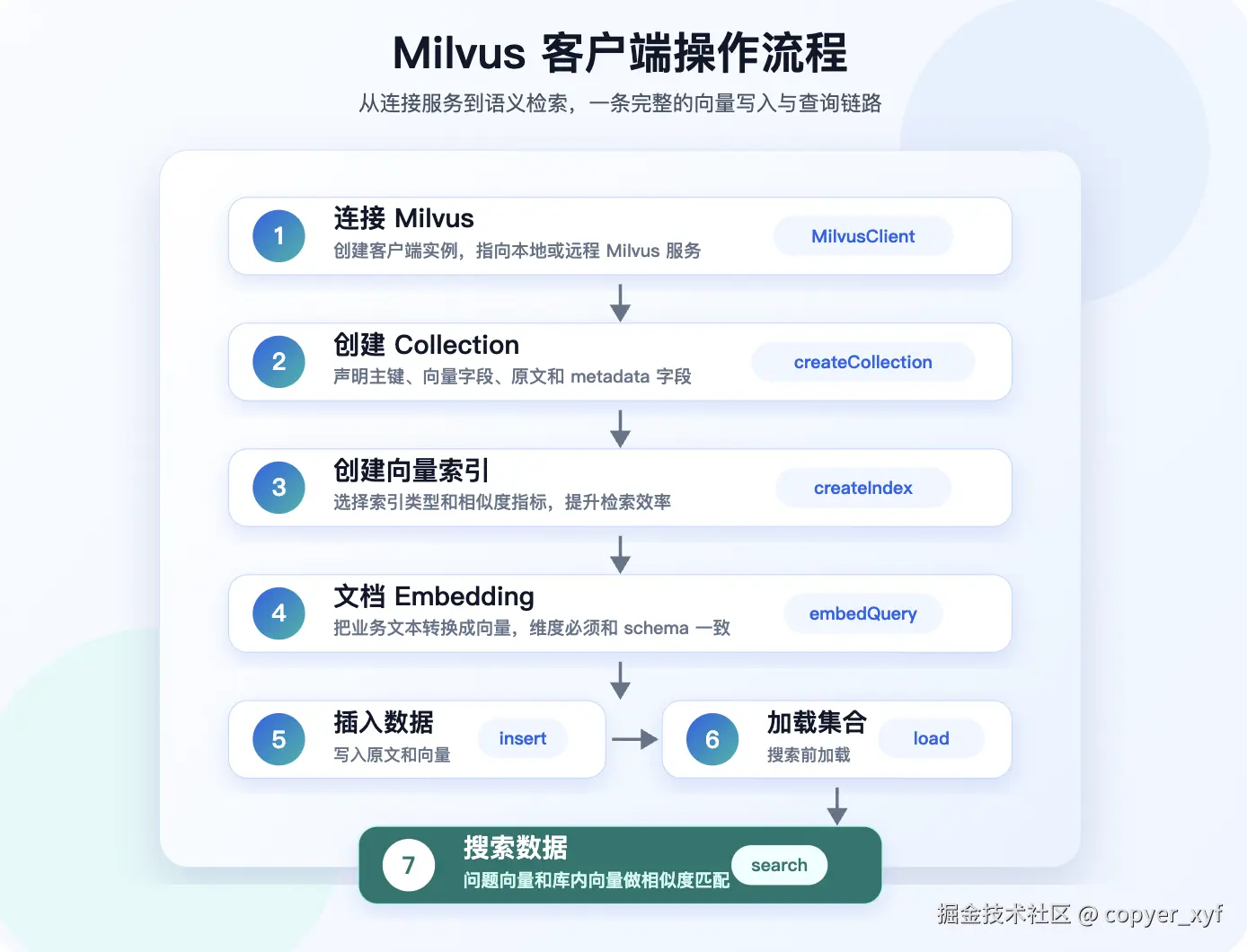
连接 Milvus
这里先创建 Milvus 客户端,同时准备后面要用到的 embedding 模型。
python
import os
from langchain_openai import OpenAIEmbeddings
from pymilvus import DataType, MilvusClient
# 定义 collection 名称
COLLECTION_NAME = "work_diary"
# 这个维度必须和 embedding 模型输出一致。换 embedding 模型时,先确认维度再建 collection。
VECTOR_DIM = 1024
# 连接服务
client = MilvusClient(uri="http://localhost:19530")
# 嵌入模型
embeddings = OpenAIEmbeddings(
api_key=os.environ["AI_KEY"],
model=os.environ["AI_EMBEDDING_MODEL"],
base_url=os.environ["AI_BASE_URL"],
# 部分 embedding 服务支持指定输出维度;Milvus schema 的 dim 要和这里保持一致。
dimensions=VECTOR_DIM,
)创建 Collection 和向量索引
这一步是 Milvus 代码里最重要的部分:先定义数据结构,再给向量字段创建索引。
python
# 创建 collection
def setup_collection() -> None:
# 判断 collection 是否存在
if client.has_collection(collection_name=COLLECTION_NAME):
client.drop_collection(collection_name=COLLECTION_NAME)
# 定义 schema
# auto_id=False 表示主键 id 由业务自己传入,这样后续更新、删除、排查数据会更直观。
# enable_dynamic_field=False 表示不允许写入 schema 之外的字段,避免脏字段悄悄进入 collection。
schema = MilvusClient.create_schema(
auto_id=False,
enable_dynamic_field=False,
)
# 主键字段。这里用字符串 id,而不是自增数字,是为了让业务数据和向量数据能稳定对应。
# max_length 是 VARCHAR 必填配置,长度要覆盖真实业务 id 的最大长度。
schema.add_field(
field_name="id",
datatype=DataType.VARCHAR,
max_length=50,
is_primary=True,
)
# 向量字段。RAG 的相似度检索真正比较的是这个字段。
# dim 必须和 embedding 模型输出维度完全一致;维度不一致时,插入和查询都会失败。
schema.add_field(
field_name="vector",
# 向量字段是语义检索的核心;没有向量字段,Milvus 就退化成普通元数据存储。
datatype=DataType.FLOAT_VECTOR,
dim=VECTOR_DIM,
)
# content,检索出来用于拼接到 prompt 中
schema.add_field(
field_name="content",
datatype=DataType.VARCHAR,
max_length=5000,
)
# metadata,元数据
schema.add_field(
field_name="date",
datatype=DataType.VARCHAR,
max_length=50,
)
# index_params 描述向量字段如何建立索引。
# 没有索引也能理解数据结构,但真正做向量检索时,索引会影响查询速度、召回率和资源消耗。
index_params = client.prepare_index_params()
index_params.add_index(
field_name="vector",
# IVF_FLAT 是教学和中小数据量常用选择;追求高召回可进一步评估 HNSW。
index_type="IVF_FLAT",
# 文本 embedding 检索通常优先用 COSINE,和前面的"向量夹角"概念对应。
metric_type="COSINE",
# nlist 可以理解成把向量空间预先分成多少个簇。
# 值越大,索引越细,查询时可调空间越大;但建索引和内存成本也会增加。
params={"nlist": 1024},
)
# 创建 collection 时,把字段结构和索引配置一起交给 Milvus。
# 后续 insert 的每一行数据,都必须符合上面声明的 schema。
client.create_collection(
collection_name=COLLECTION_NAME,
schema=schema,
index_params=index_params,
)文档 embedding
写入 Milvus 的时候,既要保存原文,也要保存原文对应的向量。
python
# mock 数据
diary_contents = [
{
"id": "diary_001",
"date": "2026-04-13",
"content": "周一参加项目启动会议,讨论 Q2 产品规划和技术架构。",
"tags": ["工作", "会议"],
},
{
"id": "diary_002",
"date": "2026-04-17",
"content": "周五项目上线,监控系统显示一切正常,晚上团队聚餐庆祝。",
"tags": ["上线", "部署"],
},
{
"id": "diary_003",
"date": "2026-04-19",
"content": "周日研究 Milvus 向量数据库,搭建本地测试环境。",
"tags": ["学习", "AI", "向量数据库"],
},
]
def embed(text: str) -> list[float]:
# 把 embedding 封装成函数,方便后续统一做限流、缓存、重试和批量化。
return embeddings.embed_query(text)插入数据并加载集合
数据写入前,先把每条日记的 content 转成向量。写入后调用 load_collection(...),后面才能搜索。
python
def insert_data() -> None:
rows = [
{
"id": item["id"],
"content": item["content"],
"date": item["date"],
# 写入向量库前,业务文本要先变成向量;原文仍要保留,方便最终拼 prompt。
"vector": embed(item["content"]),
}
for item in diary_contents
]
client.insert(
collection_name=COLLECTION_NAME,
data=rows,
)
# Milvus 搜索前需要把 collection load 到内存;只插入不搜索时可以延后。
client.load_collection(collection_name=COLLECTION_NAME)搜索数据
用户问题也要先转成向量,再交给 search(...) 和库里的向量做相似度匹配。
python
def search_diary(question: str):
# 查询文本也必须走同一个 embedding 模型,才能和库里的文档向量比较。
vector = embed(question)
result = client.search(
collection_name=COLLECTION_NAME,
data=[vector],
# limit 控制召回数量,后面还会影响 prompt 长度。
limit=2,
search_params={"metric_type": "COSINE"},
# 只取回答需要的字段,避免把无关字段塞进后续 prompt。
output_fields=["id", "content", "date"],
)
return result最后把这些步骤串起来执行:
python
setup_collection()
insert_data()
results = search_diary("哪天学习了向量数据库?")
print(results)把这些 API 放回 RAG 流程里看:
txt
create_schema / create_collection:准备向量库结构
insert:写入知识
load_collection:准备检索
search:根据用户问题召回资料执行后,可以在 Attu 里看到集合和数据。
CRUD
查询靠 search:
python
def query_data():
query = "我哪天学习了 AI 相关内容?"
query_vector = embed(query)
return client.search(
collection_name=COLLECTION_NAME,
data=[query_vector],
limit=3,
search_params={"metric_type": "COSINE"},
output_fields=["id", "content", "date"],
)更新可以用 upsert:
python
def update_data() -> None:
updated = {
"id": "diary_001",
"date": "2026-04-13",
"content": "周一重新整理了技术方案,并补充了 RAG 检索设计。",
}
client.upsert(
collection_name=COLLECTION_NAME,
data=[
{
**updated,
# 内容变化后必须重新计算向量,否则检索仍会命中旧语义。
"vector": embed(updated["content"]),
}
],
)删除用 delete,重点是写 filter:
python
def delete_data() -> None:
client.delete(
collection_name=COLLECTION_NAME,
filter='id == "diary_002"',
)
client.delete(
collection_name=COLLECTION_NAME,
filter='id in ["diary_001", "diary_003"]',
)search(...) 是 RAG 查询阶段最常用的 API,它按问题向量找相似内容。upsert(...) 适合更新知识库:如果主键已经存在就更新,不存在就插入。注意,只要正文变了,vector 也必须重新计算。
delete(...) 用来删除过期文档或重建局部知识库。它依赖 filter 过滤条件,例如按 id 删除、按文档来源删除、按租户删除。
电子书 RAG 案例
电子书 RAG 的流程和企业文档问答一样:
txt
TXT 文件
-> TextLoader
-> Splitter 切块
-> Embedding
-> Milvus
-> 用户提问
-> 检索相关片段
-> 拼 prompt
-> 模型回答下面是核心结构,不把所有工程细节展开。
这里会读取 TXT 文件并切块:
bash
uv add langchain-community langchain-text-splitters
python
from langchain_community.document_loaders import TextLoader
from langchain_text_splitters import RecursiveCharacterTextSplitter
BOOK_NAME = "./book.txt"
BOOK_COLLECTION = "book"
def load_book():
# Loader 只负责把原始文件读成 Document;清洗、去噪、章节识别通常要单独做。
loader = TextLoader(BOOK_NAME, encoding="utf-8")
documents = loader.load()
splitter = RecursiveCharacterTextSplitter(
# 小说片段要尽量保留连续叙事;chunk 太小会丢情节,太大会稀释检索焦点。
chunk_size=500,
# overlap 用来缓解"答案被切在两个 chunk 中间"的问题。
chunk_overlap=50,
)
return splitter.split_documents(documents)
def index_book() -> None:
chunks = load_book()
rows = [
{
# 真实项目建议使用稳定文档 id + chunk 序号,方便重复导入时幂等 upsert。
"id": f"book_{index}",
"content": chunk.page_content,
"vector": embed(chunk.page_content),
"book_name": BOOK_NAME,
"chunk_index": index,
}
for index, chunk in enumerate(chunks)
]
client.insert(
collection_name=BOOK_COLLECTION,
data=rows,
)
def retrieve_book(question: str, k: int = 3):
question_vector = embed(question)
result = client.search(
collection_name=BOOK_COLLECTION,
data=[question_vector],
# 电子书问答通常需要多个片段拼答案,但 k 过大容易把不相关剧情也带进 prompt。
limit=k,
search_params={"metric_type": "COSINE"},
output_fields=["content", "book_name", "chunk_index"],
)
return result[0]
def format_book_chunk(item, index: int) -> str:
# 这里先只拼内容。生产里建议同时带章节号、页码或 source,方便答案引用出处。
return f"""片段 {index + 1}:
{item["entity"]["content"]}"""
def answer_book_question(question: str):
results = retrieve_book(question, k=5)
context = "\n\n".join(
format_book_chunk(item, index)
for index, item in enumerate(results)
)
prompt = f"""
你是一个电子书阅读助手。
请只根据小说片段回答问题,如果片段中没有相关信息,请直接说明没有查到。
小说片段:
{context}
问题:
{question}
"""
return model.invoke(prompt)
answer = answer_book_question("主角第一次进入流云城发生了什么?")
print(answer.content)在这个电子书案例里,TextLoader 负责读取 TXT 文件,并把它变成 LangChain 的 Document 列表。接着 split_documents(...) 把整本书切成多个 chunk,每个 chunk 后面都会单独计算向量。
入库阶段用 client.insert(...),写进去的不只是 chunk 原文,还包括 chunk 的向量和定位信息。查询阶段用 client.search(...),它根据问题向量找出最相关的小说片段。
最后,model.invoke(prompt) 负责生成答案。模型看到的不是整本书,而是检索出来的少量相关片段。
这个案例里,Agent 并不需要把整本书放进上下文。
它只需要在每次提问时,检索出最相关的几个片段。
要点
关键环节:
- 向量维度是否和 embedding 模型一致
- Collection schema 是否方便检索和溯源
- 索引类型和 metric 是否适合当前数据规模
- 写入后是否 load collection
- 检索结果是否能拼成可靠 context
- 内容更新后是否重新计算向量
常见问题:
| 问题 | 可能原因 |
|---|---|
| 搜索报错 | collection 没有 load,或者向量字段没建索引 |
| 检索结果不准 | metric 选错,embedding 模型不一致,或 chunk 切得不合理 |
| 更新后仍命中旧内容 | upsert 时没有重新计算 vector |
| prompt 太长 | topK 太大,chunk 太大,或没有筛选 output fields |
| 很难排查答案来源 | metadata 设计太少,没有保留 source、章节、chunk 序号 |
小结
这一篇要记住几个核心点:
- Milvus 是面向向量相似度检索的数据库。
- Collection 类似表,Field 类似字段,Vector Field 是检索核心。
- 向量字段的维度必须和 embedding 模型输出一致。
- 搜索前要创建索引,并把 collection 加载到内存。
- Python 项目可以通过
pymilvus连接 Milvus。 - 电子书、企业文档、知识库问答的 RAG 流程本质一致:切块、向量化、入库、检索、拼 prompt、生成答案。