
这两年,大模型、智能问答越来越多地落到实际业务里。很多企业在推进过程中慢慢发现,影响 AI 应用落地效率的,除了模型本身能力之外,数据链路是否能顺畅跑通,也同样非常关键。
目前,企业大部分的业务数据库依然在关系型数据库中,而AI应用对支撑语义检索、相似召回的向量数据库有着更强的依赖。怎么把结构化业务数据稳定、持续地同步到向量数据库,正在成为不少企业建设 AI 数据底座时绕不开的问题。
现在,火山引擎 DTS 正式支持 MySQL 同步到 Milvus,帮助企业快速打通从业务数据库到向量数据库的数据链路,让业务数据更高效地流向搜索、推荐、知识库和智能问答等 AI 应用场景。
从业务库到向量库,企业为什么总在"最后一公里"卡住?
在很多公司里,商品信息、内容数据、知识文档、用户属性、服务记录这些数据,长期都躺在 MySQL 里。等到要做知识库问答、智能搜索、推荐这类 AI 应用,又得把它们同步进 Milvus,才能拿去做语义理解和向量检索。
这条链路看起来清晰,真正落地却并不轻松。
自研链路复杂,接入成本高
不少团队会自己写同步程序,把 MySQL、消息队列、Embedding 服务、Milvus 串起来。但全量导入、增量捕获、数据转换、异常重试、任务调度这些环节都得自己管,做下来周期不短,后面维护也得有人盯着。
向量生成能力分散,系统复杂度高
有的团队把"同步"和"生成向量"拆成两套系统:一套搬数据,一套出向量。链路一长、依赖一多,出了问题排查起来就更费劲。
增量更新难,数据容易"不同步"
检索类应用对数据新鲜度比较敏感。MySQL 里改了数据,要是没及时同步到 Milvus,搜出来的结果就会滞后、召回也不准,用户体感会变差。
运维门槛高,规模越大压力越大
数据量大了、表多了,任务监控、性能调优、故障恢复、扩容这些活都得跟上。一个本来只是"接数据"的需求,最后常常变成一套要长期养着的基础设施。
归根结底,企业面临的真正难题,不是"能不能同步",而是能否用更低成本、更高稳定性、更少运维负担的方式,把这条链路真正跑通。
火山 DTS,同步 + 向量化,一条链路全搞定
针对企业在数据接入过程中的复杂性和运维压力,火山引擎 DTS 正式支持 MySQL 同步到 Milvus。
和传统做法相比,它不只是多接了一个目标端,更关键的是把 Embedding 能力直接放进了同步链路里。也就是说,同步数据的时候不用再单独搭一套向量生成的链路,在同一条通道里就能把业务数据处理成向量数据。
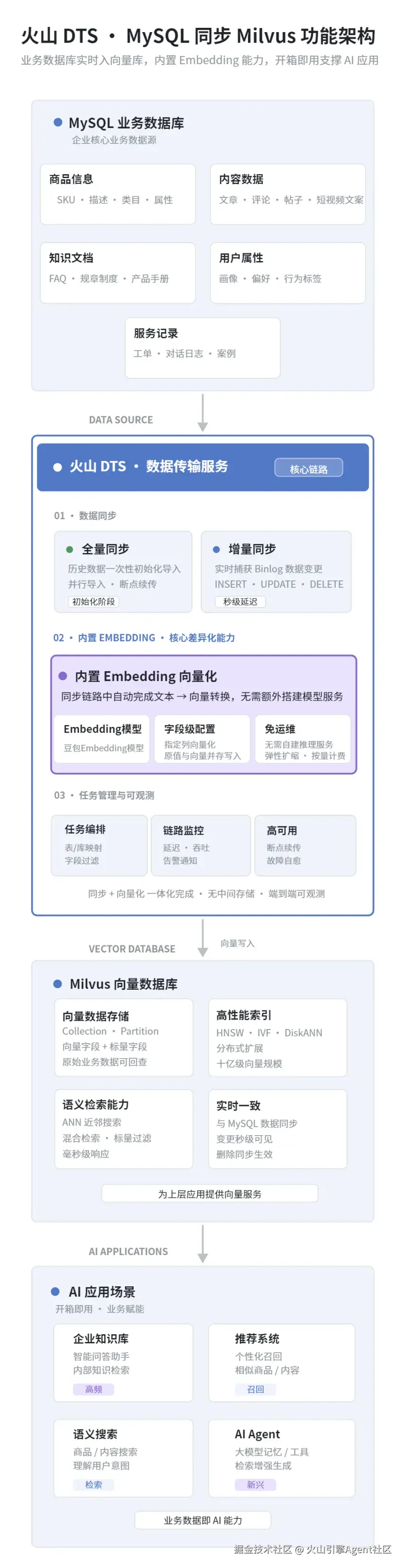
支持全量与增量同步,数据能一直跟着更新
在业务落地中,企业既需要一次性完成历史数据的初始化导入,也需要在后续持续同步新增和变更数据。火山 DTS 支持 MySQL 到 Milvus 的全量与增量同步,帮助企业在完成首批数据接入后,继续保持数据链路的持续更新能力。
内置 Embedding,让数据接入 AI 应用更简单
Embedding 能力可被直接集成在数据同步链路中,用户只需配置对应Embedding模型接入点和向量列,即可完成向量化配置。把"数据同步"和"向量化"纳入同一条链路中,减少人工同步和多系统协调带来的复杂度。
开发和接入门槛更低,交付更快
比起自己从头搭,产品化的数据传输能力能省掉很多重复开发。研发不用再把精力耗在底层链路的拼装和维护上,可以更专注在知识库、智能搜索、推荐、AI Agent 这些核心场景上。
更稳定的产品能力,更好的用户体验
数据同步不只看"能不能传",更要看"能不能一直稳定地传"。基于火山引擎 DTS 的数据传输能力,企业在任务配置、运行管理、链路维护上都能更省心,链路长期跑下来的不确定性也更小。
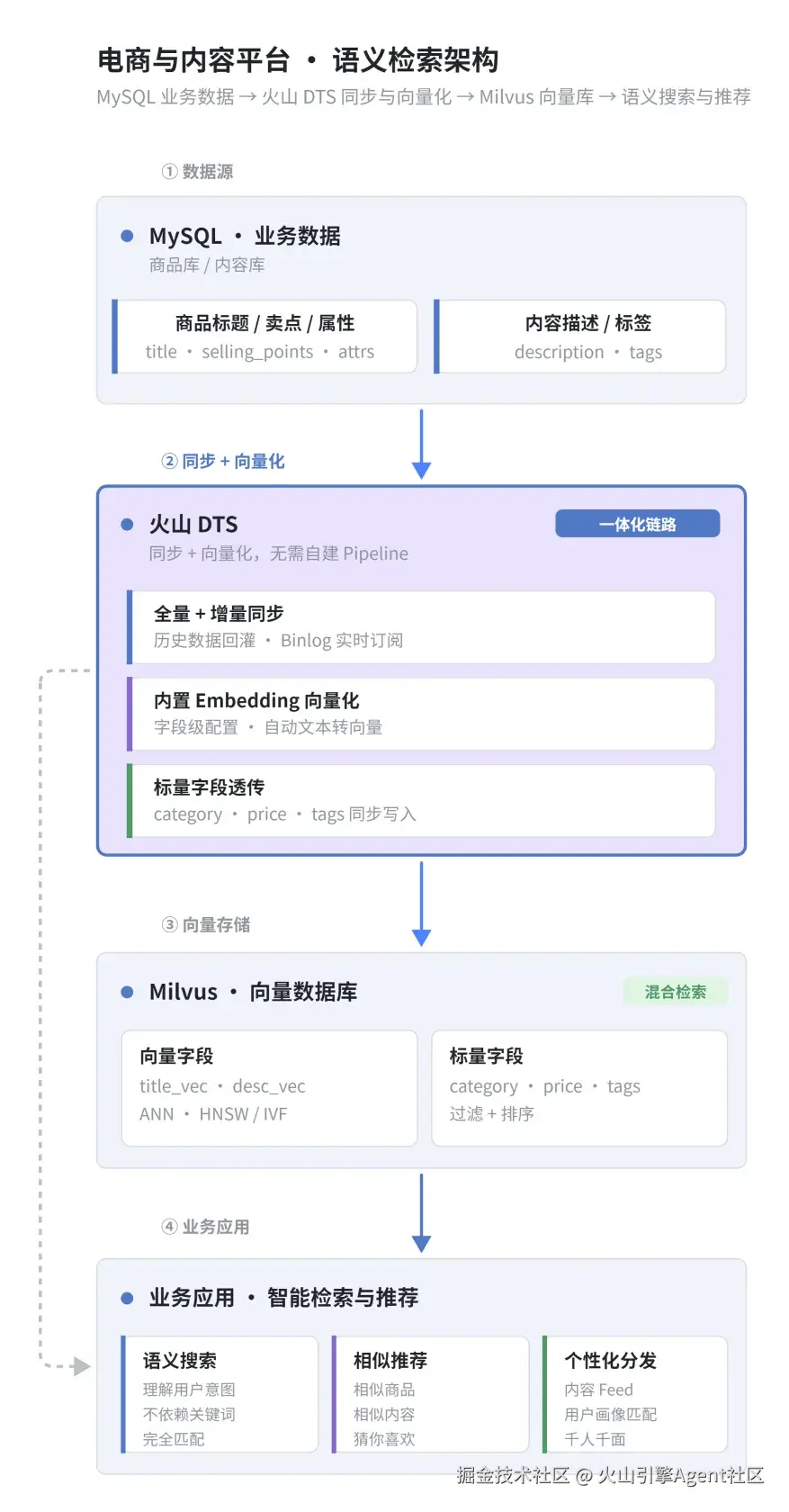
电商与内容平台语义检索:搜索更懂人,分发更准
在电商和内容平台中,商品标题、卖点、属性、内容描述、标签等核心数据,通常都沉淀在 MySQL 中。但传统关键词检索更依赖字面匹配,一旦用户搜索词和商品或内容的表达方式不完全一致,就容易出现"搜不到、搜不准、相关性不高"的问题。
举个例子,用户在电商里搜"适合通勤的轻便双肩包",想要的其实不只是标题里带着"轻便""双肩包"的商品,而是同时能满足"通勤、容量合适、日常好搭"这些需求的那一类。内容平台也一样,有人搜"拍照构图技巧",平台真正要懂的是"摄影入门、拍摄角度、构图方法"这一片相关内容,而不是非得关键词一字不差。
这个场景的核心难点主要集中在三点:
- 数据在 MySQL,难以直接用于语义检索商品信息、内容信息原本是业务数据,想真正用于语义搜索和相似召回,还需要进一步向量化处理。
- 链路长,接入复杂传统方式通常要先做数据抽取,再调用 Embedding 服务生成向量,最后写入 Milvus,系统拼装多,开发和维护成本高。
- 数据变化快,更新难度大商品会上新、改标题、改卖点,内容也会持续新增和调整标签。如果不能及时完成增量向量化和写入,搜索和推荐效果就容易滞后。
火山 DTS 支持 MySQL 同步到 Milvus,并内置 Embedding 能力,可以把原本分散的"数据同步 + 向量生成 + 写入向量库"整合成一条更顺畅的链路。可以直接将 MySQL 中的商品或内容数据同步到 Milvus,并在过程中完成向量化处理,减少额外的系统建设和链路拼装成本,把业务数据直接转化为可被 AI 检索系统理解和调用的向量数据。
场景架构示意
邀测申请途径
- 进入火山引擎官网(www.volcengine.com/)页面,通过右侧【售前...
- 与售前同学建立联系后,申请 MySQL 同步 Milvus 邀测资格,并提供已完成火山企业认证的账号 ID,进行邀测开放。账号 ID 可通过火山引擎页面右上角获取。
- 登录官网,创建工单:console.volcengine.com/workorder/c...
点击这里,访问产品官网。