对照项目 Agentium 的背景:Agentium 论文与开源项目介绍。本文图表及核心设计均来自开源项目 Agentium,源码详见 GitHub
连载 28 用 interaction_mode 拧油门;连载 31 用 Persona 拼 system;连载 19用 orchestration_mode 把会话分到 普通 Chat tool loop、固定 workflow、研究 job 三条干线。这几道旋钮都默认:用户话多半直接进 LLM 或已由客户端选好模式 。企业里还有一类高频任务------标签集合固定、要毫秒级批量扫------用 7B+ 做「这是聊天还是写代码还是做研究」又贵又飘。
这类事适合 小 encoder + schema 驱动 IE (信息抽取),典型代表是 GLiNER2 :一次 forward 可组合 实体、分类、结构化字段、关系 ;输出是 绑 schema 的 dict 。本篇讲 Agent 系统里该放哪、和 LLM 怎么分工 ,含 Harness 场景分类 ------普通 chat、多智能体研究、编程等 先分轨再进不同流程。
什么问题不该再交给 LLM
| 任务形态 | 典型例子 | 小模型 IE 为何更合适 |
|---|---|---|
| Harness 场景分类 | 普通 chat / 研究 / 编程 / 固定 SOP | 标签闭集;错轨代价高;不必每句调 LLM router |
| 闭集分类 | steer / followup、工单意图、风险档 | 标签固定;CPU 百毫秒级;无按 token 计费 |
| span 级抽取 | PII、人名机构、发票字段 | 要 start/end;LLM 常格式漂移 |
| 固定表结构 | 工具返回里抠「来源/结论/金额」 | schema 即合同;下游直进规则或 DB |
| 高 QPS 前置 | 全量入站扫、出站 DLP 补强 | 不出网、可 batch;与网关并行 |
开放域推理、多跳阅读、schema 每周大变 ------仍归 LLM 或专用 harness(连载 19、29)。小模型是 前置结构化层,不是第二个大脑。
GLiNER2 一分钟心智模型(机制不展开)
和 GPT 式 decoder 不同:GLiNER2 是 DeBERTa encoder + 任务头 ------schema 与正文 一次编码 ;分类在标签 embedding 上出 logit;NER/结构/关系在 词级 span 候选 上与类型向量打分。你声明「要抽什么」,库编成 Task Prompt,直接出 Python dict。
sql
# 概念示例:场景 + 入站意图一次 extract(非 Agentium 内置 API)
schema = (
extractor.create_schema()
.classification(
"harness_scene",
["chat", "research", "coding", "workflow_sop", "kb_qa"],
)
.classification("ingress_intent", ["steer", "followup", "new_task"])
.entities({"person_name": "自然人姓名", "phone": "手机号"})
)
result = extractor.extract(text, schema)
# {'harness_scene': 'research', 'ingress_intent': 'new_task', ...}中文 NER/结构:连续汉字须预分词 (如 jieba 后空格隔开),训推一致;宜用 gliner2-multi-v1 。PII、邮箱等可在 span 抽出后用 RegexValidator 复核------模型候选 + 规则确认,不是二选一。
在 Agentium 五平面里放哪
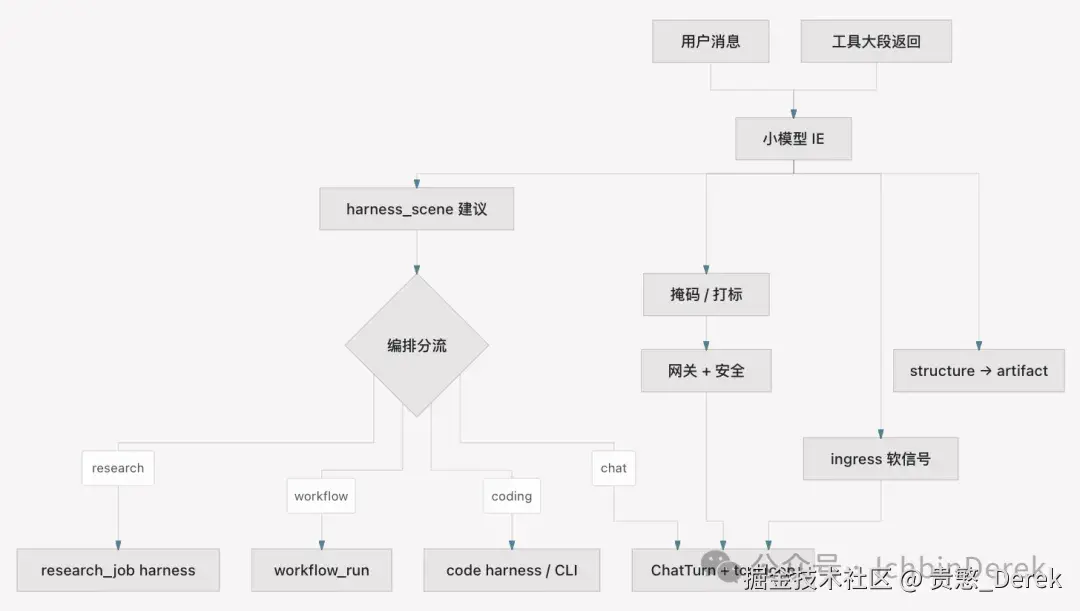
原则 :IE 在 进 LLM 之前或 tool 结果整形阶段 ;不 替代 ToolRegistry 裁决、不 替代 PolicyEngine。审计记 ie_extract_completed(类型计数、耗时),不落原文。
与现实现的对照(演进方向,非必选):
| 落点 | Agentium 常见做法 | 小模型可补强 |
|---|---|---|
| Harness 场景 | 客户端显式传 orchestration_mode;resolve_orchestration_dispatch |
首句/每句 harness_scene 建议是否改轨 |
| Skill / Persona 预选 | skills/routing.py 启发式;workspace 手选 |
多标签:research/coding/deep-research |
| 入站 disposition | classify_chat_ingress 正则 |
分类:steer/followup/code |
| 网关前安全 | PromptInjectionProbe + DLPClassifier |
PII span 定位再 redact |
| MID 写入 | LLM 或启发式 mid 语义 | structure:fact/constraint |
| KB 索引 | 27 章词法检索 | chunk 实体/日期/产品名 |
| 大 tool 结果 | 34 章 spill | 先 structure 压表再 spill |
场景一:Harness 场景分类------先进对管线(接 19、28、29 章)
故事 :用户在一个「通用助手」入口说:「对比 ACL 和 EMNLP 近两年多 Agent 论文并写综述」------应进 research_job + Lead/Worker (连载 29),而不是普通 Chat 里硬 tool loop;又说「给这个 repo 加单元测试」------应进 编程 harness (agentium code、Coding skill、side-git),而不是研究 spawn。
Agentium 今天主要靠 显式配置 分轨:
| 场景 | 典型用户话 | Agentium 落点 | 进 LLM 后的形态 |
|---|---|---|---|
| 普通 Chat | 问答、轻量工具 | orchestration_mode=agentic → chat_turn |
ChatTurnService + tool loop |
| 多智能体研究 | 综述、对比、多源检索 | orchestration_mode=research → research_job |
Lead/Worker、spawn、黑板 |
| 固定 Workflow | 合规 SOP、DAG 稳定 | orchestration_mode=workflow → workflow_run |
节点图、制品合同 |
| 编程 | 改仓、跑测试、看 diff | Coding 入口 / coding skill + coding_mode_policy |
仓库宪法、LSP、NDJSON harness |
| KB 问答 | 「查内部手册某条」 | 常仍 agentic,但绑 KB skill + kb_retrieve |
检索预算 + spill(34 章) |
小模型适合在「用户没选模式」或「统一入口」时做第一道分类------标签集合由产品定义,和 GLiNER2 的 classification 头天然对齐:
scss
用户首句(+ 可选会话标题)
→ GLiNER2(classification: harness_scene)
→ 建议 orchestration_mode / primary_skill / 是否弹「切换研究模式」
→ resolve_orchestration_dispatch(表驱动,仍 deterministic)
→ 若 chat:再 resolve_turn_route(28 章油门)
→ ingress coordinator(25 章 collect/steer)
ini
# 概念:场景建议不替代 dispatch,只写 metadata 或 UI 确认
scene = ie.classify(text, "harness_scene") # e.g. "research"
dispatch = resolve_orchestration_dispatch(
mode=session.orchestration_mode or scene_to_mode_hint(scene),
session_metadata=session.metadata,
)
# scene_to_mode_hint: research→research, coding→agentic+coding_skill, ...为什么不用 LLM 做场景 router :QPS 高、标签 <10 个时,小模型 延迟稳定、无 JSON 解析、可本地部署 ;难例可用 LLM 标注进 JSONL 微调。研究类话术和「随便聊聊」在 embedding 里常挨得近,闭集分类 + 业务描述(标签旁写「多文献对比、要引用」)往往比零样本 LLM 一句 router 更可控。
纪律(和 ingress 场景一样) :
- 软信号优先:置信度低 → 保持当前 session 模式或弹确认,别静默改轨。
- 能力门控不变 :
research仍要research.runcapability;coding 仍过沙箱与 tool tier。 - 分层不合并 :
harness_scene选 哪条干线 ;interaction_mode选 本轮油门 ;ingress_intent选 collect/steer ------三个 classification 任务可 一次 extract,但裁决仍分层。 - 会话内少反复跳轨 :首句判 research、第二句短 followup 别打回 chat------可结合 25 章 session 状态 冻结 scene 直到 steer。
| 误判 | 代价 | 缓解 |
|---|---|---|
| 研究话进普通 Chat | spawn 预算用尽、报告质量差 | 高置信 research → 202 job 或强提示切模式 |
| 闲聊进 research job | 排队、成本、用户懵 | 低置信不开 job;阈值 + 确认 |
| 写代码进研究 | 乱 spawn、无 repo 上下文 | coding 标签绑定 coding skill + 仓库绑定 |
| SOP 进 agentic | 跳过审批节点 | workflow_sop 直连 workflow_run |
场景二:入站意图与 disposition(接 25、28 章)
故事 :用户说「别管刚才那个,直接查上周销售表」------要识别 steer,而不是 followup。
v1 ingress 用 确定性正则 (chat_ingress_classification.py):快、可测,但口语变体要不断加规则。演进路径:
scss
用户消息 → [可选] jieba 预分词 → GLiNER2(classification: ingress_intent)
→ 建议 disposition + tier → ingress coordinator(租约不变)
→ resolve_turn_route(28 章仍握最终油门)关键纪律 :小模型输出是 软信号 ;plan 强制关工具、autonomous 强制 code-exec 仍由 router 覆盖。IE 只减少「误判 steer 导致 collect 堆积」的概率,不夺裁决权。
场景三:PII 与私域数据(接 13 章)
故事 :用户粘贴含手机号、身份证的段落,要求「帮我总结」------原文 不能完整进 LLM 上下文。
scss
原文 → GLiNER2(PII entities) → 掩码/替换 → ContentSafetyPipeline → 网关与 DLPClassifier、SecretLeakGuard并联 :小模型找 span ;规则引擎做 Luhn、校验位、出站 OutboundOrchestrator 二次扫。优势:数据不出内网、CPU 可批量 ;短板:合规口径(什么算地址)常要 描述微调 + 少量 JSONL 全量微调,零样本只作起点。
场景四:工具大结果先结构再 spill(接 27、34 章)
故事:Connector 或 MCP 返回五千字 HTML/日志,模型只需要「工单号、状态、三句结论」。
别让 LLM 从大段文本 再抽一遍 JSON。固定 structure schema:
scss
tool 返回大文本 → GLiNER2(structure: ticket_id, status, summary_lines)
→ 小表(几十 token)进 tool message
→ 仍超阈值则 spill 到 artifact + artifact_search这与 kb_retrieve → spill 同构:IE 是 交付链上的压缩器,检索平面(27 章)与 Harness(34 章)不变。
和 LLM 的分工表
| 维度 | 小模型 IE(如 GLiNER2) | LLM |
|---|---|---|
| 标签/字段 | 闭集、版本化 schema | 开放描述 |
| 延迟与成本 | CPU 毫秒~百毫秒级 | API/GPU、按 token |
| 输出 | dict + 可选 span | 自然语言 / 需解析 JSON |
| 部署 | 本地权重、不出网 | 常需外呼 |
| 弱项 | 超长单篇、多跳推理 | 格式与幻觉要护栏 |
流水线 :GPT-4o 标注难例 → JSONL 微调小模型 → 上线推理 是常见工业路径;大模型生成监督、小模型扛 QPS。
不适合硬上的情况
schema 每周改字段名 ------微调与发版成本高。单篇超长不切块 ------词数 max_len 会静默截断。用 IE 替代检索或规划 ------它不建索引、不选工具。让 LLM 重复抽已确定的字段 ------浪费且增加幻觉面。中文 NER 不预分词------span 易整段糊成一个「词」。
几句容易踩坑的地方
把小模型当唯一安全闸 ------仍须 policy、审批、出站 DLP。IE 结果直写 LONG 记忆不审计 ------须打来源 turn、类型计数。ingress 分类结果覆盖 turn_route ------与 28 章 router 冲突。场景分类静默改 orchestration_mode ------应低置信保持或 UI 确认。研究 job 与 Chat 来回跳 ------session 内冻结 scene 直到 steer。coding 只靠关键词 python ------应用 harness_scene + repo 上下文。 Connector 返回全文进 prompt 再让 LLM 抽 ------应先 structure 或 spill。零样本 PII 直接上线合规场景 ------要 holdout 与 RegexValidator。batch 不设 max_len ------长文尾部静默丢。多任务 schema 一次堆满 ------先从 harness_scene + ingress 两个分类起。混淆 Skill 路由与 harness 场景------前者选 SOP 包,后者选干线(chat/research/code)。
收束一下,下一篇讲什么
闭集分类、意图与字段抽取 适合 小 encoder + schema IE :Harness 场景 (chat / 研究 / 编程 / workflow)宜作 进不同 Agent 流程前的第一道分类 ;其后还有 ingress disposition、PII span、工具大结果压表。GLiNER2 是现成参照;Agentium 侧宜 可插拔 adapter ,与 resolve_orchestration_dispatch、resolve_turn_route并列。
下一篇进入 集成与连接器 :ConnectorRegistry、HTTP/Legacy 适配------外部 API 进同一治理平面;大段返回可再接本篇 structure 链。(连载 33)