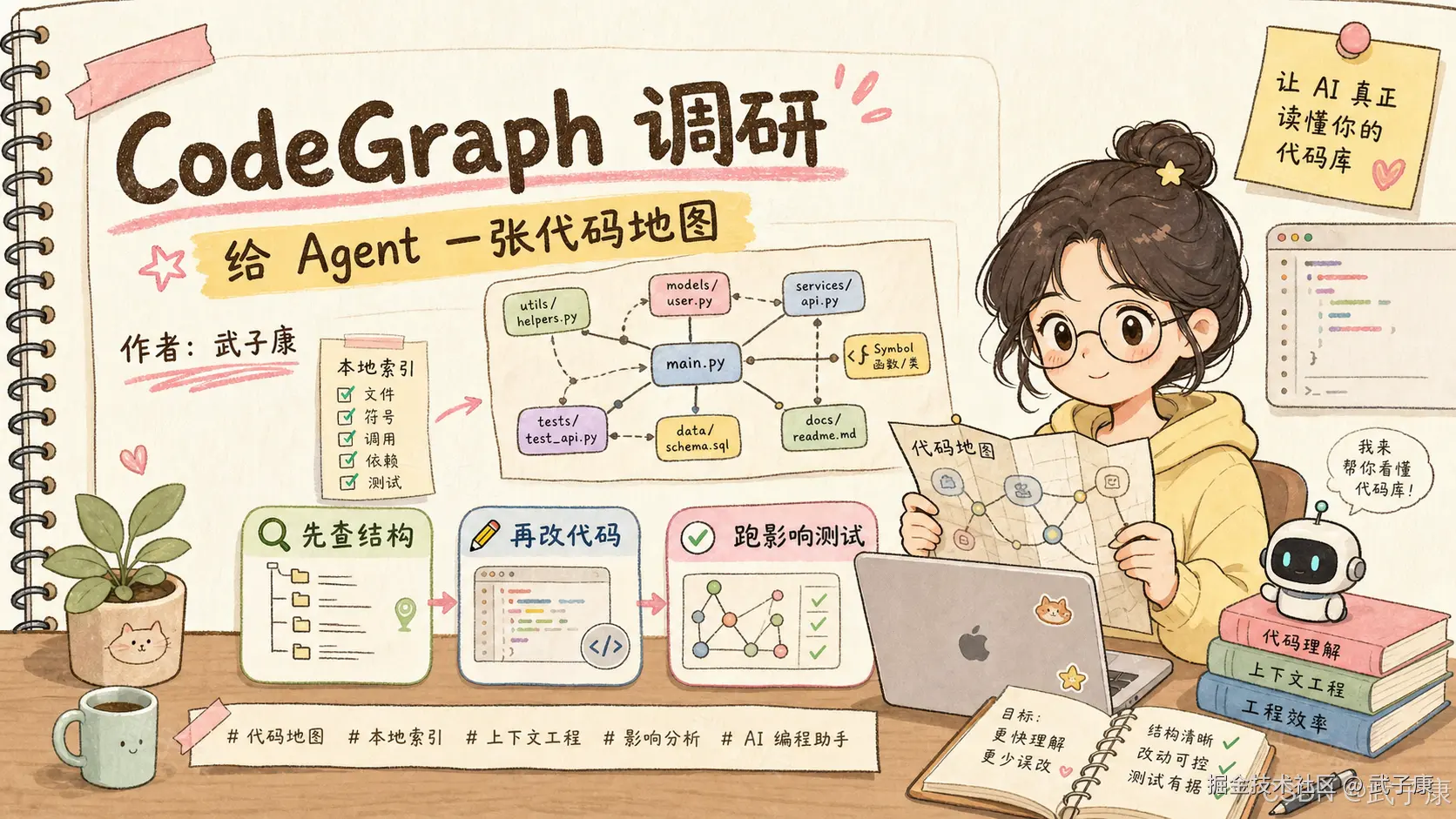
CodeGraph 调研:给 AI 编程 Agent 一张代码库地图,少一点反复 grep(2026)
TL;DR
- 场景:AI 编程 Agent 在真实仓库中频繁陷入「重新认识项目」的循环------反复 grep / 读文件 / 拼调用链,token 与时间大量浪费
- 结论:CodeGraph 通过 tree-sitter + SQLite FTS5 + MCP 把仓库预索引成本地知识图谱,让 Agent 带着结构地图工作,与 RAG / LSP 形成互补分工
- 产出:CodeGraph 定位、架构三层模型、8 个 MCP 工具、5 类适配场景、与 RAG/LSP 区别、最佳实践 7 步流程、4 条不可替代边界
版本矩阵
| 功能/特性 | 状态 | 说明 |
|---|---|---|
| GitHub 仓库 suatkocar/codegraph 公开维护 | ✅ 已验证 | 截至 2026-02 累计 45 commits,活跃迭代中 |
| GitHub Stars ~29.1k / Forks ~1.7k | ✅ 已验证 | 数据截至 2026-05-27,5 月 23 日单日新增 2,434 star |
| License: MIT | ✅ 已验证 | 仓库公开声明 |
| 平台支持 Windows / macOS / Linux | ✅ 已验证 | 官方 README 声明 |
| Node ≥18 <25(0.9 起捆绑运行时) | ✅ 已验证 | 0.9 版本起支持裸机一键安装 |
| tree-sitter AST 解析 | ✅ 已验证 | 官方架构核心层 |
| SQLite FTS5 本地知识图谱存储 | ✅ 已验证 | .codegraph/ 目录本地索引 |
| MCP Server 暴露 8 个查询工具 | ✅ 已验证 | explore / search / callers / callees / impact / node / files / status |
| 支持 20+ 编程语言 | ✅ 已验证 | Java / Python / Go / TS / JS / Rust 等 |
| Token 减少 57% / Tool Call 减少 71% | ✅ 已验证 | 官方 7 项目实测 |
| VS Code 仓库省 73% token | ✅ 已验证 | 约 10k 文件级别实测 |
| 100% local,默认不上传外部 | ✅ 已验证 | 官方 README 强调 |
| 覆盖 AOP / 反射 / 动态注入等运行时路径 | ❌ 不可覆盖 | 静态图谱天然盲区,仅作"地图"参考 |
CodeGraph 调研:给 AI 编程 Agent 一张代码库地图,少一点反复 grep
摘要:AI 编程 Agent 已经能很快写代码,但它们在真实仓库里经常卡在"重新认识项目"这件事上:反复 grep、反复读文件、反复猜调用链。CodeGraph 的价值不是替代模型写代码,而是把代码库提前解析成本地知识图谱,让 Agent 可以通过 MCP 查询符号、调用关系、文件结构、影响面和受影响测试。本文从工程使用视角拆解 CodeGraph 的定位、架构、MCP 工具、与 RAG/LSP/静态分析的区别,以及它适合什么项目、不适合什么项目。
关键词:CodeGraph、AI 编程 Agent、MCP Server、代码图谱、代码库地图、tree-sitter、SQLite、FTS5、impact analysis、call graph、affected tests、Codex、Claude Code、Cursor、代码智能
1. AI 写代码很快,理解项目很慢
过去我们评价 AI 编程工具,常常看它能不能补全代码、生成函数、修 Bug。
但在真实项目里,一个更隐蔽的成本是:Agent 每次开始工作,都像刚入职的新同事。
它需要先知道:
- 这个项目的目录怎么分层?
- 某个 API 从 Controller 到 Service 再到 Repository 怎么流转?
- 某个函数是谁调用的?
- 改一个方法会影响哪些地方?
- 相关测试在哪里?
- 这个功能到底有几套相似实现?
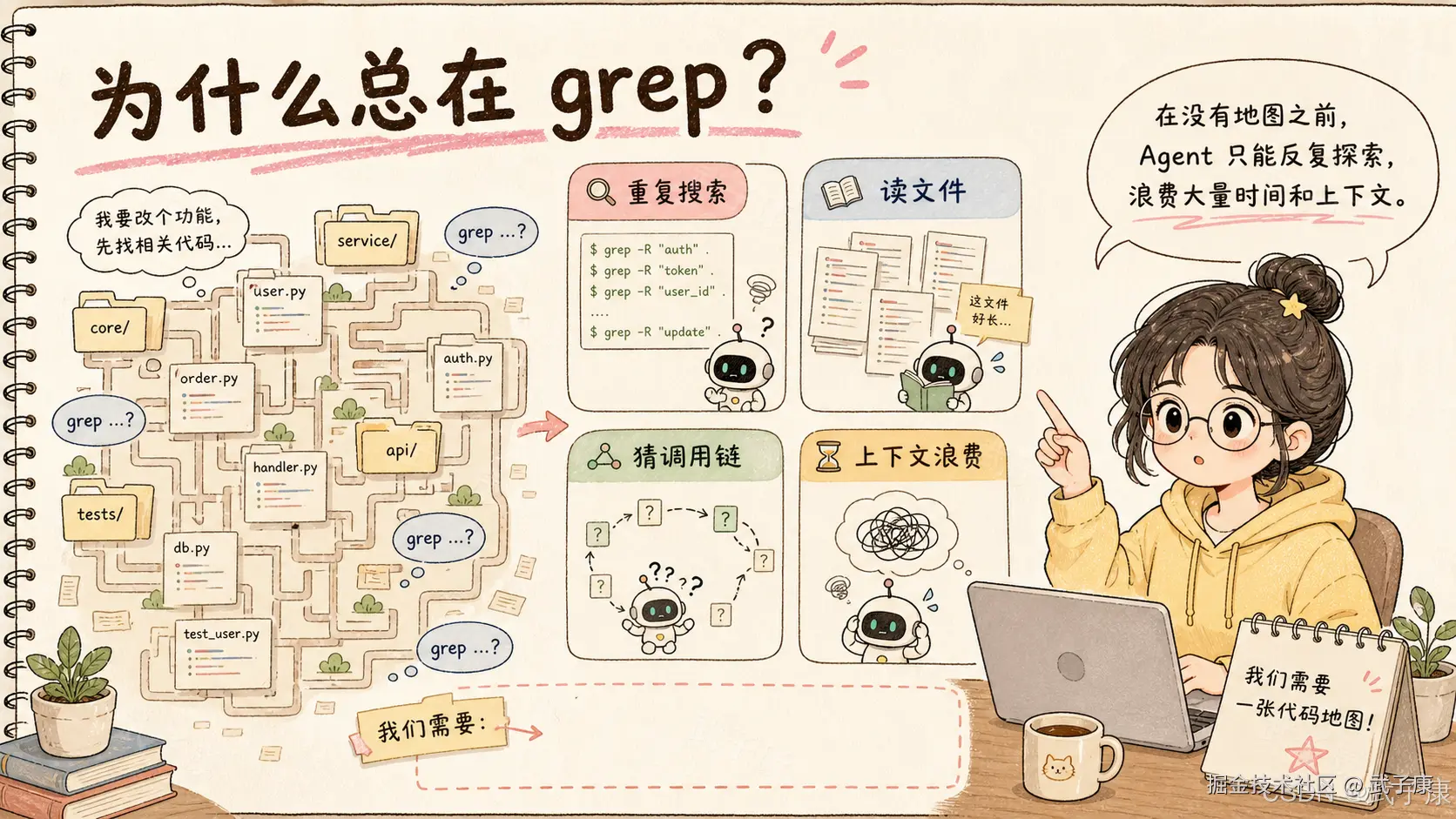
如果没有项目结构感,Agent 就只能靠文件搜索和阅读一步步摸索。
text
用户:帮我改一下登录流程
Agent:先 grep login
Agent:再读 auth 文件
Agent:再 grep UserService
Agent:再读 controller
Agent:再找 tests
Agent:再猜哪条链路是真的这不是模型不努力,而是工具层给它的"地图"不够。
大模型擅长读上下文,但它并不天然知道一个仓库的结构。把更多文件塞进上下文当然有用,但这会带来 token 成本、噪音和遗漏。CodeGraph 要解决的正是这个问题:先把代码库变成一张可查询的结构图,再让 Agent 带着地图工作。
2. CodeGraph 是什么
CodeGraph 可以理解为一个面向 AI 编程 Agent 的本地代码智能层。
它不是代码生成器,也不是另一个聊天模型,而是把仓库预先索引成"代码知识图谱":符号、文件、调用关系、导入关系、继承关系、路由关系、影响半径等结构信息,会被整理到本地索引里。Agent 需要理解项目时,不必总是从 grep 和读文件开始,而是可以先问 CodeGraph。
官方仓库把它描述为给 Claude Code、Cursor、Codex、OpenCode、Gemini 等工具使用的 semantic code intelligence,并强调 100% local。也就是说,核心索引存在本地,默认不是把你的代码上传到外部服务做检索。
一个很简化的理解是:
text
普通 Agent 工作方式:
自然语言问题 → grep / find / read → 拼上下文 → 猜结构 → 修改代码
接入 CodeGraph 后:
自然语言问题 → 查询代码图谱 → 拿到相关符号和关系 → 修改代码它的关键价值不在于"让模型变聪明",而在于"让模型少迷路"。
3. 它大概怎么工作
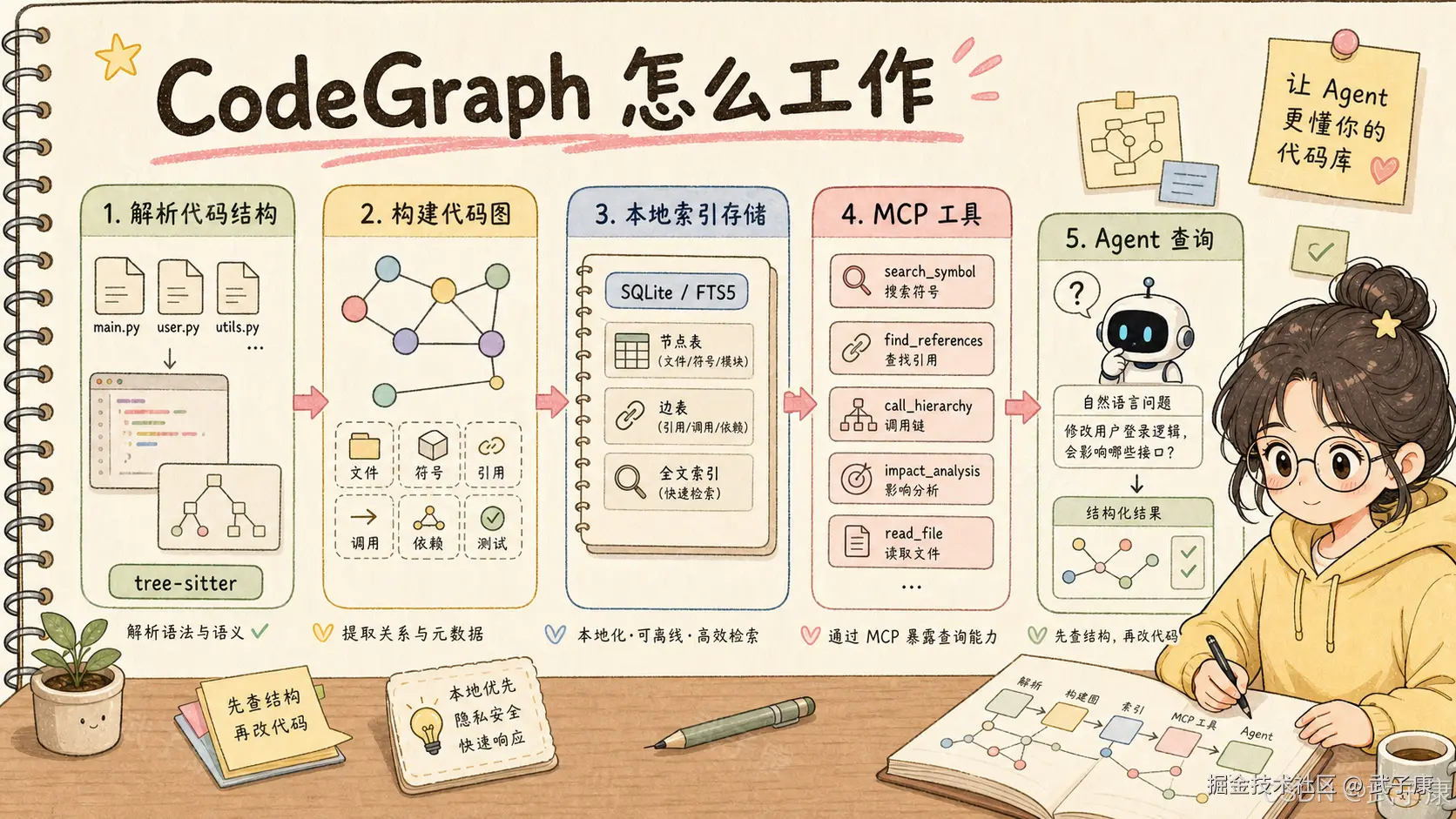
从公开说明看,CodeGraph 的架构可以拆成三层。
第一层是代码提取。
它使用 tree-sitter 解析源代码,获得 AST,再通过语言相关的查询规则提取函数、类、方法、接口、结构体、路由等节点,同时识别调用、导入、继承、实现等关系。
这一步很关键。普通全文搜索知道"某个字符串出现在哪里",但不知道它是函数名、类名、调用点还是注释。AST 解析让工具可以把代码从文本提升到结构。
第二层是本地存储。
CodeGraph 会把索引放在本地 .codegraph/ 目录中,官方 README 里提到 SQLite knowledge graph 和 FTS5 full-text search。这样它既能做结构查询,也能做全文搜索。
第三层是工具接口。
开发者可以用 CLI 操作,例如:
bash
codegraph init -i
codegraph status
codegraph query UserService
codegraph callers createUser
codegraph callees createUser
codegraph impact updatePassword
codegraph affected src/auth.ts更重要的是,它可以作为 MCP Server 暴露给 Agent。Agent 看到的不再只是 shell、grep、read,而是一些更贴近代码理解的工具。
4. MCP 工具:Agent 的项目地图接口
CodeGraph 暴露的 MCP 工具很像一组"读项目地图"的 API。
官方 README 中列出的典型工具包括:
codegraph_explore:适合问"某个功能如何工作""某条链路怎么走""某个区域怎么组织",一次返回相关符号、源码和关系图。codegraph_search:按名称搜索符号。codegraph_callers:查某个函数或方法被谁调用。codegraph_callees:查某个函数或方法调用了谁。codegraph_impact:分析修改某个符号可能影响什么代码。codegraph_node:查看某个具体符号的详细信息和源码。codegraph_files:查看索引后的文件结构。codegraph_status:检查索引状态和统计信息。
这些工具的意义在于:它们把 Agent 的探索动作从"文本搜索"提升成"结构查询"。
比如你问:
text
请帮我给注册流程加一个邀请码校验。没有 CodeGraph 时,Agent 很可能先搜索 register、signup、createUser、invite,然后读一批文件,试图拼出入口、服务层、数据库层和测试。
有 CodeGraph 时,更合理的路径是:
text
1. codegraph_explore "how does user registration work?"
2. codegraph_callers createUser
3. codegraph_callees createUser
4. codegraph_impact createUser
5. 找到受影响测试
6. 再开始修改代码这就是从"边走边找路"变成"先看地图再动手"。
5. 为什么不是继续 grep 就够了
grep 当然不会过时。
对工程师来说,rg 仍然是非常高效的搜索工具。问题是,Agent 不是人。人看到几十个搜索结果,会结合经验判断哪个文件更像入口、哪个名字是业务核心、哪个测试更相关。Agent 也能做,但代价更高,而且容易反复走同一段路。
grep 的结果是"字符串出现位置"。
CodeGraph 试图提供的是"代码结构关系"。
这两者差别很大:
text
grep:
login 这个词在哪里出现?
CodeGraph:
login 入口在哪里?
它调用了谁?
谁又调用了它?
改它会影响哪些模块?
相关测试可能在哪里?当项目很小的时候,区别不明显。几十个文件的仓库,直接搜索和阅读就够了。
但当项目变成几百、几千、上万个文件,或者进入 monorepo、多语言、多框架混合状态,探索成本就会快速上升。Agent 每次重复探索同一批文件,实际上是在把 token、时间和注意力花在"重新建图"上。
CodeGraph 的思路是:这张图不要每次让 Agent 临时重建,提前建好。
6. 和 Embedding / RAG 的区别
很多人会问:我已经有代码 RAG 了,还需要 CodeGraph 吗?
答案取决于你想解决什么问题。
Embedding / RAG 擅长语义相似度。
比如你问"哪里处理了用户登录失败",向量检索可能找到一批语义相关的文件、注释、文档和代码片段。这对概念搜索、文档问答、自然语言描述很有用。
但代码里的很多问题不是"语义相似",而是"结构相连"。
例如:
- A 函数是否调用 B 函数?
- 改这个接口会影响哪些实现?
- 某个 Controller 最终会不会走到某个 Repository?
- 某个工具函数被多少业务路径复用?
- 哪些测试覆盖了这个调用链?
这些问题需要图关系,而不是只靠向量相似度。
所以更好的组合不是二选一,而是分工:
text
Embedding/RAG:适合语义召回、文档、概念、相似代码。
CodeGraph:适合符号、调用链、依赖关系、影响面。把它们放在一起,才更接近一个完整的代码理解系统。
7. 和 LSP 的区别
LSP 也能做跳转定义、查找引用、诊断、重命名。那 CodeGraph 和 LSP 又有什么不同?
我理解主要有三点。
第一,服务对象不同。
LSP 首先是给 IDE 和人用的。它让开发者在编辑器里跳转、补全、查引用。
CodeGraph 更偏 Agent 工具层。它希望 Agent 能通过 MCP 直接问"这个功能怎么工作""改这里会影响什么""相关符号有哪些"。
第二,输出形态不同。
LSP 的返回更接近编辑器操作:位置、诊断、引用、补全项。
CodeGraph 的返回更接近上下文包:入口点、相关符号、源码片段、关系图、影响半径。
第三,使用节奏不同。
LSP 是开发者编辑时持续交互。CodeGraph 更像 Agent 在执行任务前和执行任务中查询项目地图。
所以它们不是替代关系。更像是:
text
LSP 帮人写代码。
CodeGraph 帮 Agent 理解仓库。8. 适合哪些场景
CodeGraph 最适合的不是小玩具项目,而是已经有一定复杂度的长期项目。
第一类是中大型后端项目。
例如 Java/Spring、Go、Python、Rust、Node.js 服务。一个请求往往从路由入口进入,经过 Controller、Service、Repository、外部 SDK、消息队列、缓存、鉴权、日志和测试。Agent 如果只靠 grep,很容易漏掉某条旁路逻辑。
第二类是前端 monorepo。
现代前端项目里,页面、路由、组件、hooks、store、API client、服务端组件、构建脚本经常互相穿插。CodeGraph 的价值在于帮助 Agent 更快找到组件依赖、路由入口和调用关系。
第三类是多语言项目。
比如一个仓库里既有 TypeScript,又有 Python 脚本、Go 服务、Rust 工具、Java 后端。单一语言的 IDE 能力不一定覆盖整体项目关系,而 Agent 往往要跨目录、跨语言理解任务。
第四类是大量使用 AI Agent 的团队。
如果一个团队每天让 Agent 修 Bug、补测试、做重构、写 PR,那么"每次探索项目"的成本会重复发生。CodeGraph 这种预索引工具,越是在高频使用场景下越有意义。
9. 不适合哪些场景
也不要把 CodeGraph 神化。
如果只是几十行脚本、一次性 Demo、小型教程项目,直接搜索文件更快。为了建索引、配置 MCP、维护工具链,可能反而变复杂。
如果项目核心难点不在代码结构,而在产品判断、算法推导、数据质量、模型效果、需求澄清,代码图谱也帮不了太多。
如果代码高度依赖运行时动态行为、反射、元编程、AOP、动态 import、配置驱动注入,静态图谱就会有天然盲区。它可以给出很好的结构线索,但不能保证覆盖所有运行时路径。
所以我的判断是:
text
项目越大,团队越依赖 Agent,CodeGraph 越值得试。
项目越小,任务越短,直接用 grep / IDE / 测试就够了。10. Java/Spring 项目里怎么理解它
后端同学可以用 Spring 项目来理解 CodeGraph。
一个典型请求链路可能是:
text
POST /users
↓
UserController.create
↓
UserService.createUser
↓
UserRepository.save
↓
UserCreatedEventPublisher.publish
↓
WelcomeEmailJob如果你要改 createUser,真正要关注的不是一个文件,而是一条业务链路。
Agent 需要知道:
- Controller 入口在哪里?
- Service 被哪些地方复用?
- Repository 是否还有其他调用者?
- 事件发布后还有哪些异步消费者?
- 测试是 controller test、service test,还是 integration test?
CodeGraph 这类工具的价值就是帮 Agent 先建立"调用链"和"影响面"的初步认知。
但 Spring 也有静态分析的难点:依赖注入、注解扫描、AOP、反射、配置条件、运行时代理,都会让纯静态关系变得不完整。所以在这类项目中,CodeGraph 适合作为"地图",但不能当成"真相本身"。最终还要靠测试、日志、运行时验证和人工判断。
11. 前端项目里怎么理解它
前端项目的痛点也很典型。
比如你要改一个按钮的提交逻辑,真实链路可能是:
text
Route
↓
Page
↓
Form Component
↓
custom hook
↓
API client
↓
state cache
↓
toast / analytics / error boundary如果 Agent 只搜索按钮文案,可能会改到 UI 层,却漏掉 hook、接口封装、缓存刷新、埋点和测试。
对 React、Vue、Svelte、Astro、Next.js、Nuxt 这类项目来说,文件路由、组件引用、服务端接口、客户端状态和构建约定都很重要。CodeGraph 如果能把这些结构尽量索引出来,Agent 就更容易从"某个页面"追到"真实业务动作"。
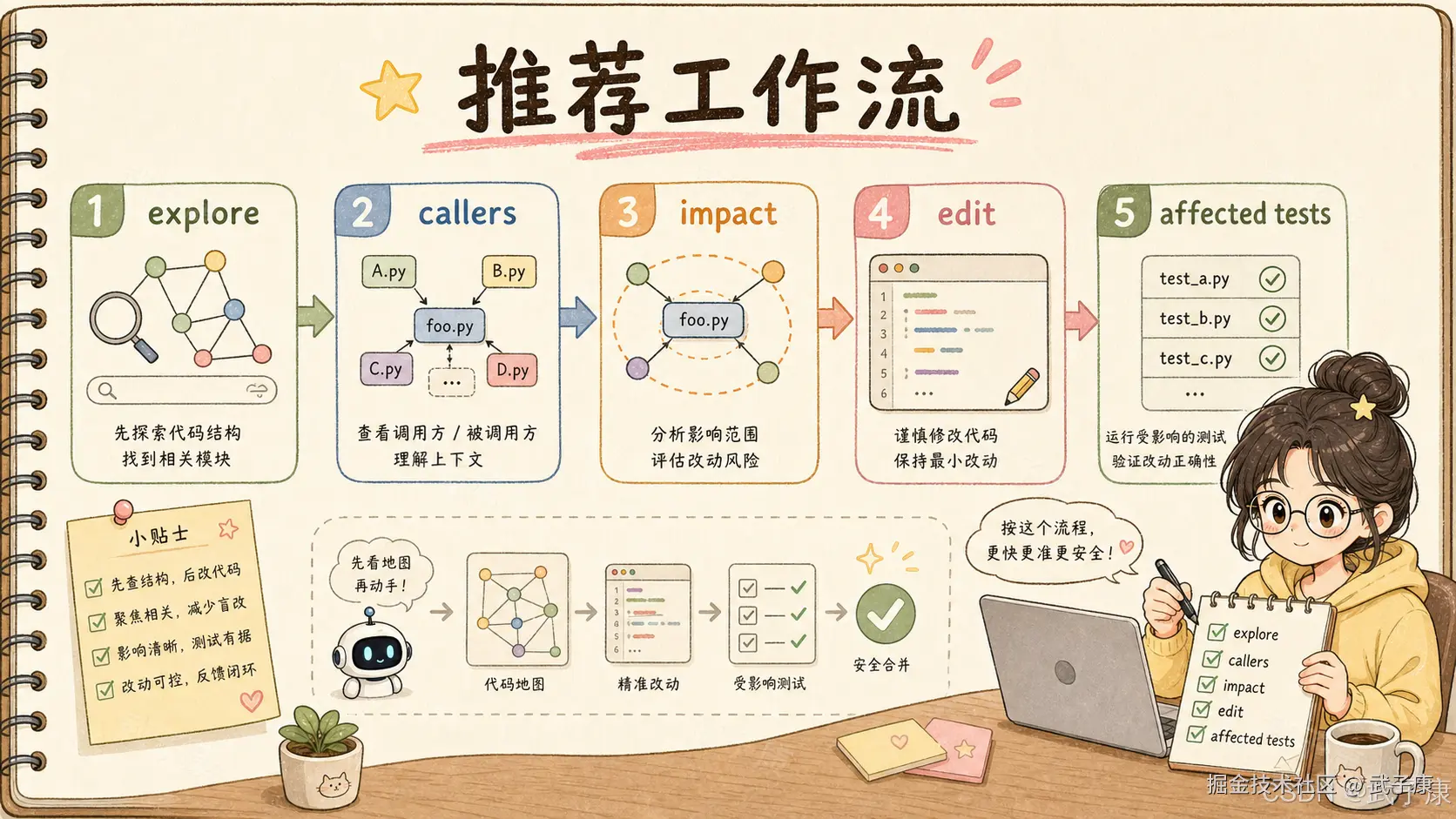
12. 最佳实践:先查结构,再动代码
我觉得 CodeGraph 最重要的使用原则是:
text
不要让 Agent 一上来就改代码。
先让它查结构。可以给 Agent 加一条工作约束:
text
修改复杂代码前,先用 CodeGraph 查询相关入口、调用方、被调用方和影响面。
确认修改范围后,再读必要源码并动手。一个更工程化的流程可以是:
text
1. explore:理解功能入口和核心链路
2. callers/callees:确认上下游关系
3. impact:评估修改影响面
4. edit:只修改必要文件
5. affected:选择相关测试
6. test:运行受影响测试
7. review:在 PR 里说明影响面这套流程不会让 Agent 万无一失,但能明显减少"没看清就改"的概率。
13. 它不能替代测试,也不能消灭幻觉
CodeGraph 是工具,不是保险箱。
它能降低探索成本,但不能替代测试。
它能帮助定位影响面,但不能保证所有运行时路径都被覆盖。
它能减少无意义 grep,但不能让模型永远不误解需求。
它能让 Agent 更容易拿到正确上下文,但最终修改是否正确,仍然要靠:
- 单元测试
- 集成测试
- 类型检查
- lint
- CI
- 代码审查
- 运行时验证
- 人对业务边界的判断
尤其是支付、权限、数据迁移、删除操作、生产配置、安全策略这类高风险改动,不能因为 Agent 查过 CodeGraph 就直接放行。
更稳妥的心态是:
text
CodeGraph 负责给地图。
测试负责验路径。
人负责定边界。14. 对 AI 编程工具链的启发
从更大的趋势看,CodeGraph 代表的是一个方向:AI 编程不再只是"模型 + 上下文窗口"。
真正好用的 Agent 工程体系,可能会由多层工具组成:
- 代码图谱:理解符号、调用、依赖、影响面。
- Embedding/RAG:理解语义、文档、相似代码。
- LSP:提供编辑器级定位、诊断和重构能力。
- 测试系统:验证修改是否破坏行为。
- CI/CD:把验证放到团队流程里。
- 规划器:把复杂任务拆成可执行步骤。
- 审查工具:检查安全、隐私、性能和可维护性。
CodeGraph 不是全部答案,但它补上了很关键的一层:代码结构地图。
当 Agent 从"会写代码"走向"能维护项目",它需要的不只是更大的上下文窗口,还需要更好的项目感知能力。
15. 结论:先给 Agent 一张地图
如果只用一句话总结 CodeGraph,我会说:
text
它不是让 Agent 写得更多,而是让 Agent 少走弯路。在小项目里,这种差异可能不明显。
在真实团队、长期仓库、中大型项目里,差异会越来越大。
AI 编程 Agent 的瓶颈,很多时候不是"生成不出代码",而是"没弄清楚该在哪改、改了会影响谁、该跑哪些测试"。
CodeGraph 把仓库变成可查询的代码图谱,让 Agent 在动手之前先理解结构。这件事听起来不性感,但非常工程化。
未来的 AI 编程体验,很可能不是把整个仓库塞给模型,而是让模型通过一组可靠工具按需读取结构、源码、测试和运行结果。
换句话说:
text
别只给 Agent 一堆文件。
先给它一张地图。
错误速查卡
| 症状 | 根因 | 定位 | 修复 |
|---|---|---|---|
| Agent 每次会话都重复 grep 同一批文件 | 每次会话让模型用工作记忆重建结构图 | 看 Agent 是否反复执行 grep / find / read 同一类路径 | 给项目接入 CodeGraph,让 Agent 通过 MCP 查结构 |
| 改了某个函数后相关模块静默失效 | 没查 impact,误判影响面 | 跑 codegraph_impact <symbol> 看下游 |
改前先做 impact / callers / affected tests 三连查 |
| Spring AOP / 反射调用没出现在图里 | 静态 AST 看不到运行时代理 | 对比 CodeGraph 关系与运行时 trace | 用 CodeGraph 作地图,运行时行为靠测试 + 日志验证 |
| 装好 MCP 但 Agent 不用 codegraph_* 工具 | Agent prompt 没强调"先查结构" | 看 Agent 是否仍优先用 Read / Grep | 在系统提示里加约束:改复杂代码前必须先 explore + impact |
| 索引文件巨大、首次启动慢 | 仓库太大,首次全量建索引 | codegraph status 看索引规模和耗时 |
排除 node_modules / dist / build 等目录后重建 |
| 多语言项目里某语言关系缺失 | 该语言 tree-sitter grammar 没启用 | 看 codegraph status 输出 | 升级到最新版本,确认 20+ 语言支持已启用 |
| CodeGraph 和 Embedding/RAG 选型纠结 | 没分清语义相似 vs 结构相连 | 看问题是「找到相似代码」还是「找到上下游调用」 | 概念/文档问题走 RAG,调用/影响面问题走 CodeGraph |
作者:武子康的个人博客