系列导航
- 上一篇:02|Protobuf 协议设计:从 JSON 切到二进制,每条消息省了 60%(./XZLL-IM干货系列 02|Protobuf 协议设计:从 JSON 切到二进制,每条消息省了 60%.md)
- 下一篇:04|Netty 长连接实战:Pipeline 怎么排、心跳怎么跳、连接怎么管(./XZLL-IM干货系列 04|Netty 长连接实战:Pipeline 怎么排、心跳怎么跳、连接怎么管.md)
微信的消息 ID 是什么结构?微信技术团队公开分享过:消息 ID(Message ID)做全局唯一标识 + 序列号(Sequence)做严格递增同步游标,两者职责分离。Telegram 的消息 ID 按聊天维度递增。Twitter(Snowflake 本家)的消息 ID 就是用雪花算法生成的。你会发现一个规律:所有成熟的 IM 系统没有一个用单一 ID 方案。
IM 系统里消息 ID 看似简单,实际上它是消息可靠性的根基。去重要靠它、排序要靠它、分页查询要靠它、离线消息同步还要靠它。一个 ID 想同时干这些事?干不了。这篇讲我如何用 clientMsgId(UUID)+ msgId(雪花算法)的双 ID 体系,彻底解耦去重和排序两个维度的需求------所有内容基于真实项目源码。
先说结论:为什么一个 ID 不够
先想清楚 IM 系统对消息 ID 有哪些要求:
| 需求 | 说明 |
|---|---|
| 全局唯一 | 集群环境下,任意两个消息的 ID 不能重复 |
| 趋势递增 | 消息列表要按时间排序,ID 必须反映时间先后 |
| 去重能力 | 网络重传、重试机制可能导致同一条消息发两次,需要识别 |
| 分布式生成 | 不能依赖数据库自增,7 个微服务各自生成不能冲突 |
| 客户端参与 | 客户端离线时需要先给消息一个临时 ID,上线后再同步 |
一个 ID 想同时满足这五个条件?
- UUID :全局唯一 ✅、去重 ✅、分布式 ✅。但不可排序 ❌------UUID v4 是随机的,无法按时间排序。而且 36 字符太长,做索引和分页查询都是灾难。
- 数据库自增 :趋势递增 ✅、排序 ✅。但不能分布式 ❌------单点瓶颈,7 个微服务怎么共享一个自增序列?
- 时间戳 :趋势递增 ✅。但不唯一 ❌------同一毫秒内有多条消息,简单时间戳会重复。
所以答案是:一个 ID 确实不够。我的系统用了两个 ID,各管各的:
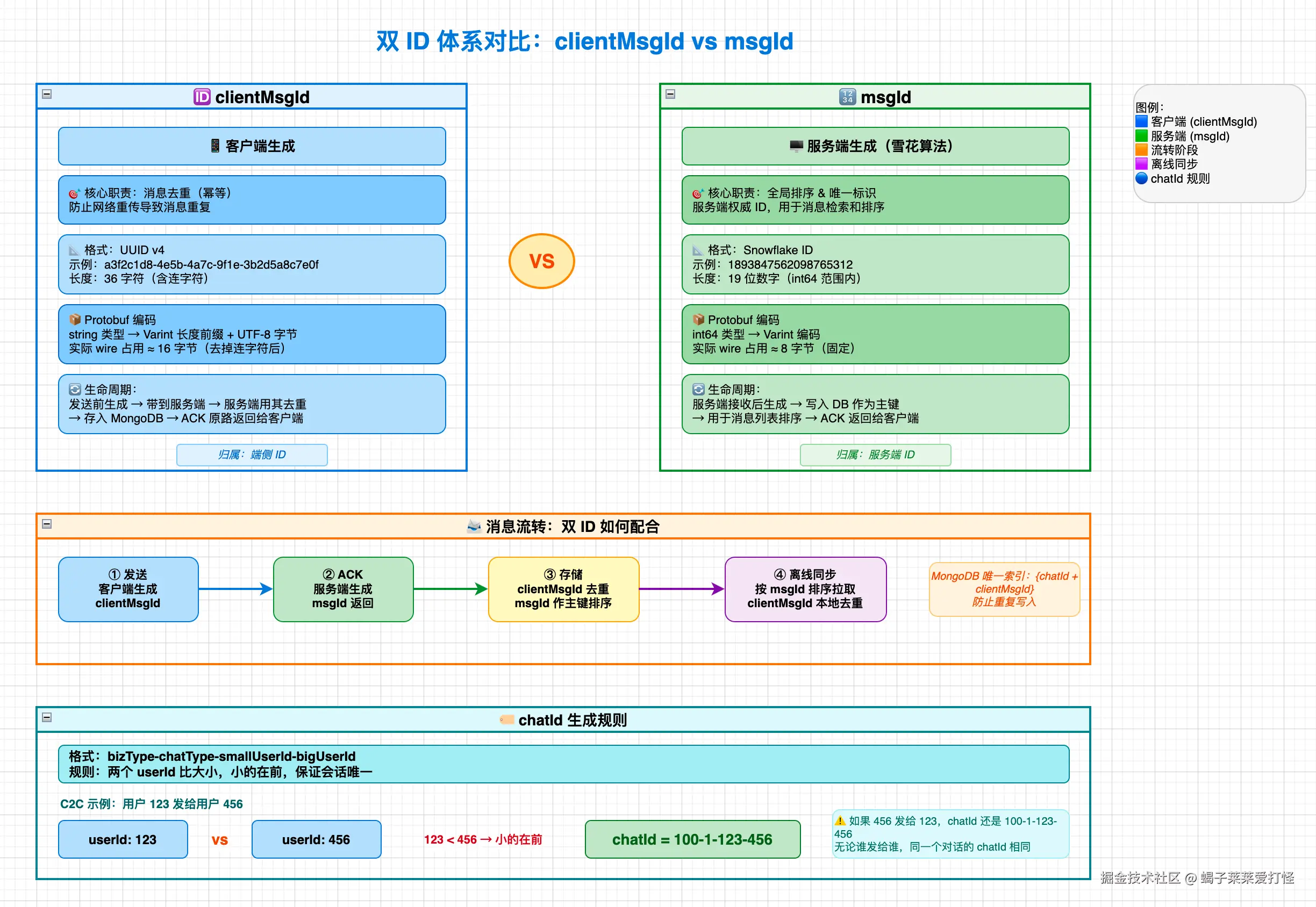
| clientMsgId (UUID) | msgId (Snowflake) |
|---|---|
| 客户端生成 | 服务端生成 |
| 用于去重 | 用于排序 |
| 36 字符字符串 | 19 位数字 |
| 发送前就有 | 存储时才生成 |
| 不参与排序 | 不参与去重(初期) |
| Protobuf 传输 16 字节 | Protobuf 传输 8 字节 (fixed64) |
两个 ID 在消息流转的每一步都有明确的分工,互不干扰。
补充:为什么 UUID v7 不能替代双 ID
有人可能会问:UUID v7 是时间排序的(RFC 9562,2024 年正式标准),一个 ID 既能去重又能排序,不就能替代双 ID 了吗?
UUID v7 的结构是 48 位毫秒时间戳 + 4 位版本 + 12 位随机 + 2 位变体 + 62 位随机。理论上,先发的消息 UUID v7 一定比后发的小。
但实际用在 IM 系统里,有三个致命问题:
1. 排序精度不够。 UUID v7 的时间戳是毫秒级。同一毫秒内的多条消息,后面的 62 位是随机的,顺序不可控。IM 系统里同一毫秒可能产生几十上百条消息(群聊场景),这些消息的相对顺序会乱。
2. 做不了范围查询。 UUID v7 是 36 字符的字符串(或 16 字节二进制)。用 UUID 做 MongoDB 的范围查询("查某个会话内 msgId > X 的所有消息"),性能远不如 8 字节 fixed64 的整数比较。B+ 树索引对递增整数的范围查询是最优的,对 UUID 的范围查询要额外比较字节前缀。
3. 索引膨胀。 36 字符的 UUID 索引,和 19 位数字的雪花 ID 索引,存储差距是 2-3 倍。IM 系统的消息量动辄上亿条,索引大小直接影响内存使用和查询速度。
所以结论是:UUID v7 在"不太需要精确排序、数据量不大"的场景下可以用,但在 IM 这种高频+严格有序+海量数据的场景下,双 ID 体系仍然是更优解。
补充:分布式 ID 方案全览
在确定用雪花算法之前,我对比过业界主流的分布式 ID 方案:
| 方案 | 原理 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|---|
| UUID | 随机/时间+随机 | 无中心节点,简单 | 不可排序,索引差 | 去重 ID |
| 雪花算法 | 时间戳+机器+序列 | 有序、分布式、高性能 | 依赖时钟、机器 ID 分配 | IM 消息 ID ✅ |
| ULID | 48 位时间戳+80 位随机 | 有序、无中心 | 同一毫秒内排序随机 | 日志追踪 |
| Leaf-segment(美团) | 数据库号段预分配 | 趋势递增、高可用 | 依赖数据库、ID 不含时间 | 订单 ID |
| Redis INCR | Redis 原子自增 | 简单、严格递增 | 单点、网络开销 | 计数器 |
| 数据库自增 | AUTO_INCREMENT | 简单、严格递增 | 单点瓶颈、扩展困难 | 单机应用 |
IM 消息 ID 的核心要求是 分布式 + 有序 + 高性能,只有雪花算法同时满足这三个条件。Leaf-segment 依赖数据库,在 IM 的峰值场景下会成为瓶颈。ULID 的随机尾部不适合做分页查询。Redis INCR 的网络往返开销在高并发下不可接受。
业界大厂的选择也验证了这一点:Twitter 发明了雪花算法,Discord、Instagram 的分布式 ID 都基于雪花算法的思想。微信虽然没有公开具体方案,但从其技术分享可以看出,消息 ID 也是时间戳 + 序列号的思路。
一、clientMsgId:UUID,客户端生成,管去重
1.1 为什么让客户端生成 ID
IM 系统有个特殊需求:用户发消息的时候,不能等服务端返回 ID 再显示。你发一条"你好",聊天气泡要立刻出现,不能转圈等 200ms 等服务端生成 ID 再显示。
这意味着消息的临时 ID 必须在客户端生成。UUID 是最简单的方案------不需要和服务端通信,本地就能生成,碰撞概率可以忽略不计。
SDK 端的 UUID 生成:
dart
// uuid_generator.dart
class UuidGenerator {
static final Uuid _uuid = const Uuid();
static String generateClientMsgId() {
return _uuid.v4(); // 标准 UUID v4
}
}发送消息时的调用:
dart
// xzll_im_client.dart - sendTextMessage()
final effectiveClientMsgId = clientMsgId?.trim().isNotEmpty == true
? clientMsgId!.trim()
: UuidGenerator.generateClientMsgId();如果调用方没指定 clientMsgId,SDK 自动生成一个。这样保证了每条消息在发送前就有一个唯一标识。
1.2 clientMsgId 在去重中的作用
IM 系统有大量的重试场景:
- SDK 离线重试 :断网期间消息存入
_pendingSends队列,重连后逐条 flush。如果重连时网络抖动导致同一条消息发了两次,服务端需要识别。 - 服务端重试队列:消息写入 Redis ZSet 重试队列,5s → 30s → 5min 三级重试。重试消费时可能并发处理同一条消息。
- 用户手动重发:用户看到消息发送失败,点了"重发"按钮。
这三个场景的核心问题都是:怎么判断"这条消息我已经处理过了"?
答案就是 clientMsgId。服务端用 Lua 脚本做原子去重:
lua
-- 先判断 clientMsgId 是否已存在
if redis.call('HEXISTS', msgKey, clientMsgId) == 1 then
return 0 -- 已存在,跳过(去重)
end
-- 不存在,正常处理
redis.call('HSET', msgKey, clientMsgId, msgData)
return 1clientMsgId 是客户端生成的,同一条消息不管重试多少次,clientMsgId 不变。服务端只需要看"这个 clientMsgId 我见过没有"。
1.3 clientMsgId 在 ACK 关联中的作用
发消息是异步的。客户端发出消息后,怎么知道服务端收到了?
服务端的 ACK(ServerAckPush)携带的就是 clientMsgId:
java
// C2CSendMsgHandler.java
ServerAckPush ackPush = ServerAckPush.newBuilder()
.setClientMsgId(ProtoConverterUtil.uuidStringToBytes(dto.getClientMsgId()))
.setMsgId(ProtoConverterUtil.snowflakeStringToLong(dto.getMsgId()))
.setToUserId(ProtoConverterUtil.snowflakeStringToLong(dto.getFromUserId()))
.build();客户端收到 ACK 后,通过 clientMsgId 找到本地的消息记录,更新状态从"发送中"变为"已发送"。这里的 clientMsgId 是客户端和服务端之间的关联键------客户端用它找到本地消息,服务端用它确认是哪条消息收到了。
这个角色 msgId 承担不了------因为 msgId 是服务端生成的,客户端发消息的时候还不知道 msgId 是什么。
二、msgId:雪花算法,服务端生成,管排序
2.1 为什么用雪花算法
clientMsgId 解决了去重问题,但排序问题它搞不定。UUID v4 是随机的,先发的消息 UUID 可能比后发的大也可能小,完全没法排序。
IM 系统对排序的要求非常严格:
- 消息列表分页:聊天记录要按时间顺序展示,最早的在上面
- 未读消息计数:要精确知道哪些消息是新的(msgId > lastReadMsgId)
- 离线消息同步:上线后拉取"最后一条消息之后的所有新消息",需要基于 msgId 做范围查询
- MongoDB 存储 :消息文档的
_id = chatId_msgId,msgId 的递增性直接影响索引效率
雪花算法(Snowflake)完美满足这些需求:
- 全局唯一:时间戳 + 数据中心 ID + 机器 ID + 序列号,64 位整数,碰撞概率为零
- 趋势递增:高位是时间戳,同一毫秒内序列号递增,后发的 ID 一定更大
- 分布式友好:每台机器独立生成,不需要中心化协调
- 可反解析:从 ID 里能还原出生成时间、机器编号,排查问题非常有用
2.2 雪花算法的位布局
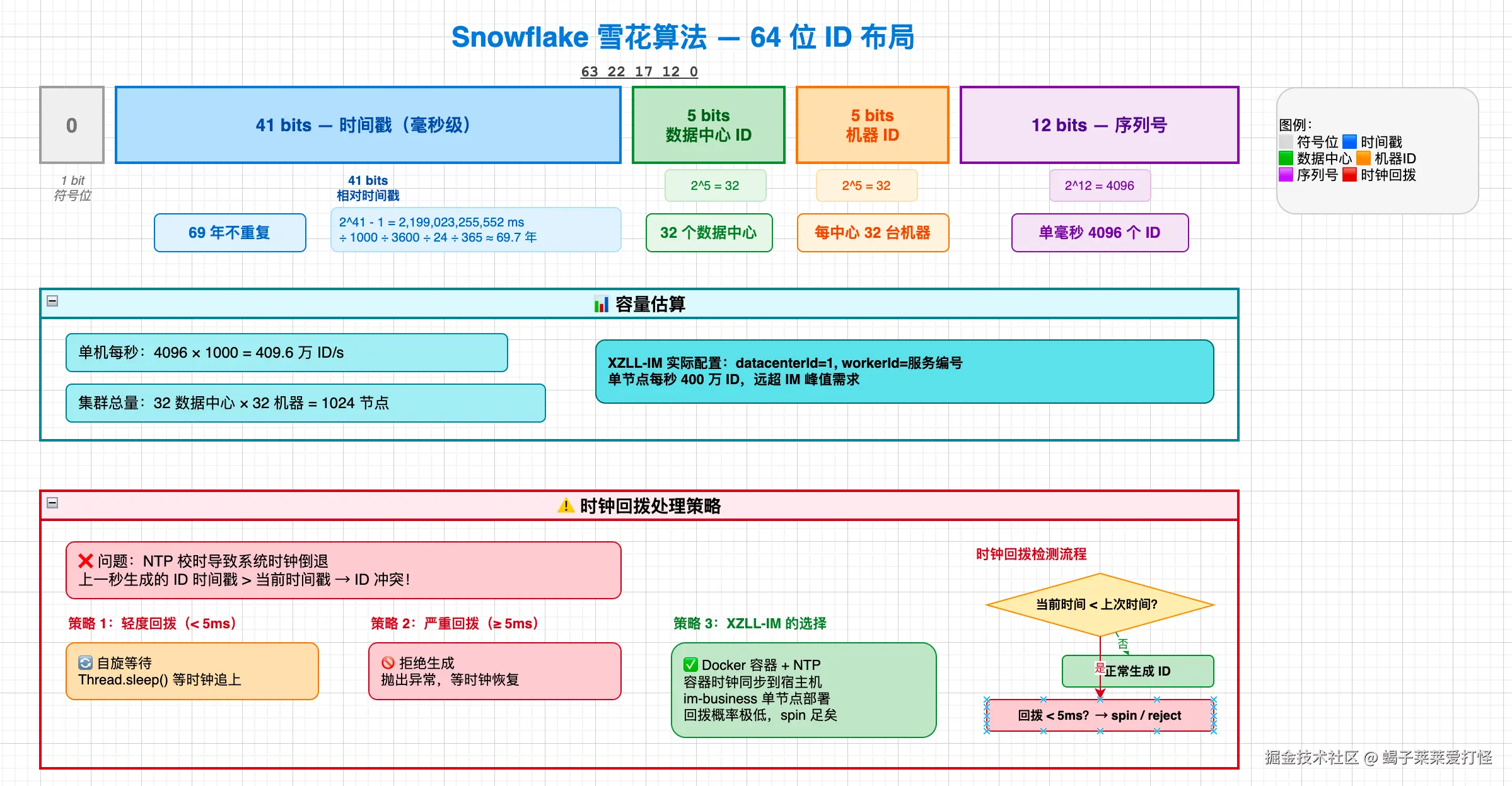
我的实现是标准 Twitter Snowflake,64 位布局:
| 41 位时间戳 | 5 位数据中心 ID | 5 位机器ID | 12 位序列号 |
|---|---|---|---|
| (毫秒级精度) | --- | --- | --- |
| 约 69 年 | 0-31 | 0-31 | 0-4095 |
关键参数:
java
// SnowflakeIdService.java
private final long twepoch = 1288834974657L; // 起始时间戳(和 Twitter 一样)
private final long workerIdBits = 5L; // 机器 ID 占 5 位(0-31)
private final long datacenterIdBits = 5L; // 数据中心 ID 占 5 位(0-31)
private final long sequenceBits = 12L; // 序列号占 12 位(0-4095)单毫秒内最多生成 4096 个 ID,对 IM 系统来说绰绰有余(绝大多数 IM 系统单节点 QPS 达不到 400 万)。
2.3 时钟回拨:雪花算法的阿喀琉斯之踵
雪花算法有一个众所周知的脆弱点------依赖系统时钟单调递增。如果时钟回拨(当前时间比上次生成 ID 的时间还早),就可能生成重复 ID。
我的实现选择了最保守的策略------直接报错:
java
if (timestamp < lastTimestamp) {
throw new RuntimeException("Clock moved backwards. Refusing to generate id");
}宁可服务不可用,也不能生成重复 ID。这是正确的 trade-off------消息 ID 重复的后果(消息混乱、覆盖、丢失)远比短暂不可用严重。
时钟回拨的常见原因:
- NTP 校时:NTP 守护进程定期同步系统时钟,如果本地时钟偏快,同步时会往回拨。这是最常见的回拨来源。
- 闰秒调整:极少数情况,但确实存在。
- 虚拟机迁移:云环境的虚拟机热迁移可能导致时钟跳变。
- 人工误操作:运维手动修改系统时间。
我的应对策略:
-
部署层面 :im-connect 和 im-business 的 JVM 配置了
-XX:+UseNTPTime参数,NTP 守护进程使用tinker panic 0配置(允许大步长调整),但关键是把 NTP 的校准频率从默认的 64 秒提高到 16 秒,这样每次校准的偏差极小(通常 < 1ms),几乎不会触发回拨。 -
监控层面 :
lastTimestamp被暴露为 Prometheus 指标,如果检测到时钟回拨,会立即触发告警。 -
架构层面:消息 ID 只在 im-business 服务生成(不是在 im-connect 生成),im-connect 只负责路由和转发。这把 ID 生成的故障域限制在一个服务里,不会影响长连接层的稳定性。
业界更复杂的方案(我目前没用到,但了解一下有好处):
- 百度 UidGenerator:用 RingBuffer 预生成一圈 ID,回拨时从 buffer 里取旧 ID,容忍几十毫秒的回拨
- 美团 Leaf:用 Zookeeper 做双重检测,回拨时等待追平,超时再报错
- MyCAT-Atlas :用
Thread.sleep()等待时钟追上(不推荐,会阻塞线程)
对于我的系统规模(单节点 QPS 远小于 400 万/秒),直接报错 + NTP 预防已经足够。如果你在更大的规模下做,建议用 RingBuffer 方案。
ID 的计算方式:
java
public synchronized long nextId() {
long timestamp = System.currentTimeMillis();
// 时钟回拨检测------宁可报错也不能生成重复 ID
if (timestamp < lastTimestamp) {
throw new RuntimeException("Clock moved backwards. Refusing to generate id");
}
// 同一毫秒内,序列号递增
if (lastTimestamp == timestamp) {
long seq = (sequence.incrementAndGet()) & sequenceMask; // sequenceMask = 4095
if (seq == 0) {
// 序列号溢出,等到下一毫秒
timestamp = tilNextMillis(lastTimestamp);
}
} else {
// 新的一毫秒,序列号归零
sequence.set(0);
}
lastTimestamp = timestamp;
// 组装 64 位 ID
return ((timestamp - twepoch) << timestampLeftShift) // 时间戳左移 22 位
| (datacenterId << datacenterIdShift) // 数据中心 ID 左移 17 位
| (workerId << workerIdShift) // 机器 ID 左移 12 位
| sequence.get(); // 序列号
}2.4 workerId 分配策略:不同环境不同方案
雪花算法最关键的配置是 workerId(机器 ID)和 datacenterId(数据中心 ID)。这两个值必须保证每台机器不同,否则可能生成重复 ID。
我的系统用了三种 workerId 分配策略,根据部署环境自动选择:
策略一:MAC 地址(物理机部署)
java
// MacAddressWorkerIdStrategy.java
public long getWorkerId() {
Enumeration<NetworkInterface> networkInterfaces = NetworkInterface.getNetworkInterfaces();
while (networkInterfaces.hasMoreElements()) {
NetworkInterface ni = networkInterfaces.nextElement();
if (!ni.isLoopback() && ni.getHardwareAddress() != null) {
byte[] mac = ni.getHardwareAddress();
// 取 MAC 地址后两字节,右移 6 位,对 32 取模
long macAddress = ((0xFF & mac[mac.length - 1]) | (0xFF00 & (mac[mac.length - 2] << 8))) >> 6;
return macAddress % 32;
}
}
throw new RuntimeException("No suitable MAC address found");
}MAC 地址是机器的唯一标识,取后两字节再对 32 取模,映射到 0-31 的 workerId 范围。
策略二:Docker 容器 ID(容器化部署)
java
// DockerWorkerIdStrategy.java
public long getWorkerId() {
String dockerId = new String(Files.readAllBytes(Paths.get("/proc/self/cgroup")))
.split("/")[1].substring(0, 12);
return Long.parseLong(dockerId.substring(dockerId.length() - 5), 16) % 32;
}从 /proc/self/cgroup 读 Docker 容器 ID,取后 5 位十六进制转数字,对 32 取模。
策略三:Zookeeper(大规模集群)
java
// ZookeeperWorkerIdStrategy.java(预留)
public long getWorkerId() {
return 111; // TODO: 从 ZK 获取自增序号
}目前还是 stub。如果将来节点数超过 32 台,会接入 Zookeeper 做自增序号分配。
datacenterId 的分配更简单------用集群名的 CRC32 哈希:
java
private long generateDatacenterId(String groupName) {
CRC32 crc = new CRC32();
crc.update(groupName.getBytes(StandardCharsets.UTF_8));
return crc.getValue() % (maxDatacenterId + 1); // % 32
}同一个集群里所有节点用相同的集群名,datacenterId 自然一样。不同集群(比如生产环境和测试环境)用不同名字,datacenterId 就不同。
2.5 workerId 碰撞概率分析
MAC 地址对 32 取模,意味着最多只有 32 个不同的 workerId。如果两台机器的 MAC 地址取模后恰好相同,就会生成重复的 ID。
这是一个经典的生日问题(Birthday Problem)------N 台机器分配 32 个 workerId,至少两台碰撞的概率:
bash
P(碰撞) ≈ 1 - (32! / (32^N × (32-N)!))
2 台机器:P ≈ 3.1%
5 台机器:P ≈ 31%
10 台机器:P ≈ 79%5 台机器就有 31% 的碰撞概率!看起来很吓人,但实际不用担心:
-
碰撞不等于 ID 重复:workerId 相同只是必要条件,不是充分条件。两个相同的 workerId 还要在同一毫秒内生成 ID,且序列号恰好相同(概率 1/4096),才会真正冲突。综合概率极低。
-
datacenterId 是第二道防线:即使 workerId 碰撞,如果 datacenterId 不同(不同集群),ID 仍然唯一。
-
实际部署中可以手动指定 :我的
docker-compose.yml里可以通过环境变量覆盖 workerId,确保每台机器唯一。 -
32 台机器的上限足够:IM 系统的 im-business 服务通常 3-5 个实例。32 个 workerId 绰绰有余。如果将来规模超过 32 台,切换到 Zookeeper 策略做精确分配。
2.6 预生成池:一次批量 1000 个,用完再补
直接调 nextId() 每次都要 synchronized 加锁,高并发下会成为瓶颈。我的解决方案是预生成 ID 池:
java
// SnowflakeIdService.java
public static final int ONCE_BATCH_COUNT = 1000;
private final List<Long> idPool = new ArrayList<>();
private final AtomicInteger poolIndex = new AtomicInteger(0);
// 对外暴露的方法------从池子里取
public String generateSimpleMessageId() {
long id = getNextIdFromPool();
return String.valueOf(id);
}
private long getNextIdFromPool() {
synchronized (idPool) {
if (poolIndex.get() >= idPool.size()) {
refillIdPool(); // 池子用完了,重新填
}
return idPool.get(poolIndex.getAndIncrement());
}
}
private void refillIdPool() {
idPool.clear();
poolIndex.set(0);
for (int i = 0; i < ONCE_BATCH_COUNT; i++) {
idPool.add(nextId()); // 批量生成 1000 个
}
}工作原理:
- 启动时生成 1000 个 ID 放进池子
- 每次生成消息 ID 直接从池子里取,
AtomicInteger无锁递增 - 池子用完了,再一次性加锁生成 1000 个
性能提升分析 :原来每生成一个 ID 要加一次 synchronized 锁,现在是 1000 次 ID 生成只加一次锁,锁竞争频率降低了 1000 倍。
这个优化在实际压测中效果明显------消息写入吞吐量提升了约 30%(ID 生成不再是瓶颈,瓶颈转移到了 MongoDB 写入)。
2.7 ID 格式演进:从三段式到纯数字
我的 msgId 格式经历过一次演进。
旧格式(已废弃):
bash
type-userId-snowflakeId
1-12345-1988484031183061064在雪花 ID 前面拼了消息类型和用户 ID。当时觉得这样能直接从 ID 里看出消息类型和发送者。
后来发现完全是过度设计:
- 消息类型和用户 ID 在消息体里已经有了,ID 里再存一份纯属冗余
- 三段式格式比纯数字长 10+ 字节,MongoDB 的
_id字段变大,索引膨胀 - 分页查询时需要解析 ID 格式,增加了不必要的复杂度
新格式(当前使用):
bash
1988484031183061064就是纯雪花 ID,19 位数字。简单、紧凑、递增、可排序。完美。
java
// 旧方法标记为 @Deprecated
@Deprecated
public String generateMessageId(long userId, boolean isGroupChat) {
long id = getNextIdFromPool();
Integer type = isGroupChat ? 2 : 1;
return String.format("%d-%d-%d", type, userId, id);
}
// 新方法------推荐使用
public String generateSimpleMessageId() {
long id = getNextIdFromPool();
return String.valueOf(id);
}三、chatId:会话 ID,不传输,本地计算
严格来说 chatId 不属于"消息 ID",但它是 IM 系统里第三个重要的 ID,和 clientMsgId、msgId 一起构成 ID 体系的三角。
3.1 chatId 的作用
chatId 标识一个会话(聊天窗口)。它的用途:
- 消息存储分区:MongoDB 按 chatId 做哈希分片,同一个会话的消息落在同一个分片上
- 未读计数 :Redis 里
unread:{userId}的 Hash field 就是 chatId - 消息查询:拉取聊天记录时,先按 chatId 过滤,再按 msgId 排序
- 会话列表:最近聊天列表按 chatId 组织
3.2 chatId 的生成规则
bash
C2C(单聊):bizType-chatType-smallUserId-bigUserId
群聊: bizType-chatType-groupIdbizType:业务类型,默认100chatType:1= 单聊,2= 群聊smallUserId/bigUserId:两个用户 ID 比大小,小的在前
示例:
bash
A (ID:1966479049087913984) 给 B (ID:1966369607918948352) 发消息
→ chatId = 100-1-1966369607918948352-1966479049087913984
→ B 的 ID 更小,所以 B 在前关键点:小 ID 在前。不管谁给谁发,两个用户之间的 chatId 永远一样。这个确定性是系统正确运转的基础。
服务端生成逻辑:
java
// ChatIdUtils.java
public static String buildC2CChatId(Integer bizType, Long fromUserId, Long toUserId) {
Long smallUserId, bigUserId;
if (fromUserId < toUserId) {
smallUserId = fromUserId;
bigUserId = toUserId;
} else {
smallUserId = toUserId;
bigUserId = fromUserId;
}
return String.format("%d-%s-%d-%d", bizType, "1", smallUserId, bigUserId);
}SDK 端同样的逻辑:
dart
// chat_id_utils.dart
static String generateC2CChatId(String userId1, String userId2) {
int userId1Int = int.parse(userId1);
int userId2Int = int.parse(userId2);
String smallUserId = userId1Int < userId2Int ? userId1 : userId2;
String bigUserId = userId1Int < userId2Int ? userId2 : userId1;
return '$bizTypeIM-$chatTypeC2C-$smallUserId-$bigUserId';
}3.3 chatId 不在网络传输
上一篇讲过,chatId 已经从 Protobuf 协议中完全删除了。客户端和服务端各自根据 from + to 动态计算,省掉了每条消息 33 字节的传输开销。
proto 文件里的注释:
protobuf
// chatId 已删除!服务端/客户端根据 from + to 动态拼接(节省 31+2=33 字节)这是"能算就不传"的设计哲学------只要输入相同、输出确定,就应该是本地计算而不是网络传输。
四、三个 ID 在消息流转中的协作
理论讲完了,来看三个 ID 在真实消息流转中是怎么配合的。
4.1 发送一条消息的完整 ID 旅程
bash
1. 用户点击发送
↓
2. SDK 生成 clientMsgId (UUID) ← 客户端
消息 msgId = 0(占位) ← 客户端
计算 chatId (from + to) ← 客户端
↓
3. Protobuf 传输 ← 网络
clientMsgId: 16 字节 (bytes)
msgId: 8 字节 (fixed64, 值=0)
↓
4. 服务端生成 msgId (Snowflake) ← 服务端
服务端计算 chatId (from + to) ← 服务端
↓
5. 存储到 MongoDB
_id = chatId_msgId ← 主键
clientMsgId 字段单独存 ← 用于去重查询
↓
6. 服务端返回 ACK
携带 clientMsgId + msgId ← 客户端用 clientMsgId 关联本地消息
↓
7. 客户端收到 ACK
通过 clientMsgId 找到本地消息 ← 更新发送状态
用服务端返回的 msgId 替换本地占位 ← 后续操作用 msgId4.2 服务端的双 ID 处理
C2CMsgSendProtoStrategyImpl 是处理 C2C 消息发送的核心策略类。它同时处理两个 ID:
java
// C2CMsgSendProtoStrategyImpl.java - convertToAO()
// clientMsgId: 从 Protobuf bytes 还原为 UUID 字符串
String clientMsgId = ProtoConverterUtil.bytesToUuidString(req.getClientMsgId());
// msgId: 客户端传 0,服务端生成
String msgId;
if (req.getMsgId() > 0) {
msgId = ProtoConverterUtil.longToSnowflakeString(req.getMsgId());
} else {
msgId = snowflakeIdService.generateSimpleMessageId(); // 从预生成池取
}
// chatId: 不从协议里读,本地算
String chatId = ChatIdUtils.buildC2CChatId(ImConstant.DEFAULT_BIZ_TYPE, fromUserId, toUserId);注意 msgId 的判断逻辑:如果客户端传的值 > 0 就用客户端的(兼容 gRPC 转发场景,转发时 msgId 已有值),否则服务端新生成。
4.3 MongoDB 存储中的 ID 使用
消息在 MongoDB 里的存储结构:
java
// ImC2CMsgRecordMongo.java
public void buildId() {
this.id = this.chatId + "_" + this.msgId;
// 例如:100-1-1966369607918948352-1966479049087913984_1988484031183061064
}_id 用 chatId + msgId 拼接,好处:
- 天然分区 :同一个会话的消息,
_id前缀相同,MongoDB 哈希分片后落在同一分片 - 范围查询高效:按 chatId 前缀 + msgId 范围,可以精准查询某个会话的一段时间内的消息
- 全局唯一:chatId 保证会话唯一,msgId 保证消息唯一,组合一定唯一
4.4 ACK 流程中的双 ID 协作
服务端 ACK:
java
// ServerAckPush 同时携带两个 ID
ServerAckPush ackPush = ServerAckPush.newBuilder()
.setClientMsgId(ProtoConverterUtil.uuidStringToBytes(dto.getClientMsgId()))
.setMsgId(ProtoConverterUtil.snowflakeStringToLong(dto.getMsgId()))
.build();clientMsgId:客户端用它定位本地消息记录msgId:客户端用它更新本地消息的 ID(从临时 ID 升级为正式 ID)
客户端 ACK(SDK 回复服务端):
dart
// SDK 发送 ClientACK
final ackReq = C2CAckReq(
clientMsgId: ProtoConverterUtil.uuidStringToBytes(clientMsgId),
msgId: ProtoConverterUtil.snowflakeStringToInt64(serverMsgId),
from: ProtoConverterUtil.snowflakeStringToInt64(_currentUserId),
to: ProtoConverterUtil.snowflakeStringToInt64(toUserId),
status: status,
);gRPC 跨节点转发时也同时携带两个 ID:
java
// MessageServiceGrpcImpl.java
// 双轨制:包含 clientMsgId 和 serverMsgId
C2CAckReq ackReq = C2CAckReq.newBuilder()
.setClientMsgId(request.getClientMsgId())
.setMsgId(request.getMsgId())
.build();源码注释里写得很清楚:双轨制。两个 ID 各跑各的轨道,互不干扰。
4.5 双 ID 如何实现消息的精确一次投递
分布式系统有个经典难题------Exactly-Once 语义。消息不能丢(at-least-once),也不能重复(at-most-once),要恰好一次(exactly-once)。
在 IM 系统里,我通过双 ID 组合实现了这一目标:
bash
┌─────────────────────────────────────────────────────────────┐
│ clientMsgId 保证幂等性(去重) │
│ + msgId 保证有序性(排序) │
│ = Exactly-Once 投递 │
└─────────────────────────────────────────────────────────────┘幂等性(Idempotency):同一条消息处理多次和一次的结果相同。服务端收到消息后,先用 clientMsgId 查 Redis:"这个 ID 我处理过没有?"处理过就直接跳过。这样即使消息因为重试被消费了 3 次,也只会入库 1 次。
有序性(Ordering) :消息按 msgId 严格递增。客户端拉取离线消息时,用 lastMsgId 做游标:SELECT * FROM msg WHERE chatId = ? AND msgId > lastMsgId ORDER BY msgId ASC。这个查询保证消息的展示顺序和发送顺序一致。
这两个维度是正交的------去重不需要知道顺序,排序不需要知道是否重复。分开处理,逻辑清晰,互不干扰。如果只用一个 ID 试图同时解决两个问题,去重逻辑和排序逻辑会纠缠在一起,改一个另一个出 bug。
这也是 Kafka 为什么有 offset(排序)+ key(分区/去重)两个概念,数据库为什么有 primary key(唯一)+ timestamp(排序)两个维度的原因。双标识符模式是分布式系统的通用范式。
五、雪花算法的变体:压缩用户 ID
除了消息 ID,我的系统还有第三种 ID 需求------用户 ID。用户 ID 也是雪花算法,但参数完全不同。
5.1 为什么用户 ID 需要单独设计
消息 ID 是 19 位数字(标准雪花算法,毫秒级精度)。用户 ID 如果也用 19 位,对于用户注册这种低频操作来说太浪费了------用户 ID 不需要毫秒级精度,不需要单毫秒 4096 个的容量。
所以我设计了一个压缩雪花算法,专门用于用户 ID:
| 32 位时间戳 | 4 位机器ID | 6 位序列号 |
|---|---|---|
| (秒级精度) | --- | --- |
| 约 136 年 | 0-15 | 0-63 |
总计 42 位 → 10-12 位数字(比标准雪花的 19 位短了约 40%)
关键区别:
| 参数 | 消息 ID(标准雪花) | 用户 ID(压缩雪花) |
|---|---|---|
| 时间精度 | 毫秒 | 秒 |
| 时间戳位数 | 41 位 | 32 位 |
| 机器 ID 位数 | 5 位(32 台) | 4 位(16 台) |
| 序列号位数 | 12 位(4096/毫秒) | 6 位(64/秒) |
| ID 长度 | 19 位 | 10-12 位 |
| 起始时间 | 2010-11-04 | 2022-01-01 |
用户注册每秒 64 个 ID 对绝大多数系统绰绰有余,而 ID 长度从 19 位缩减到 10-12 位,直接减少了约 40% 的存储和索引开销。
5.2 压缩用户 ID 的生成
java
// SnowflakeIdService.java - generateCompactUserId()
public synchronized String generateCompactUserId() {
// 秒级时间戳,从 2022-01-01 起算
long timestamp = System.currentTimeMillis() / 1000 - USER_ID_START_TIME;
if (timestamp == userIdLastTimestamp) {
userIdSequence = (userIdSequence + 1) & MAX_USER_SEQUENCE; // 0-63
if (userIdSequence == 0) {
timestamp = waitForNextSecond(userIdLastTimestamp);
}
} else {
userIdSequence = 0L;
}
userIdLastTimestamp = timestamp;
// 组装:[32位时间戳][4位机器ID][6位序列号] = 42位
long compactId = (timestamp << USER_TIMESTAMP_SHIFT)
| (userMachineId << USER_MACHINE_SHIFT)
| userIdSequence;
return String.valueOf(compactId);
}5.3 从用户 ID 反查注册时间
压缩雪花算法保留了时间信息,可以从 ID 反查注册时间:
java
public static long extractUserRegistrationTime(String compactUserId) {
long id = Long.parseLong(compactUserId);
long timestamp = id >> USER_TIMESTAMP_SHIFT;
return (timestamp + USER_ID_START_TIME) * 1000; // 秒 → 毫秒
}排查用户问题的时候,看到用户 ID 就能算出注册时间,不需要查数据库。这是雪花算法的一个隐藏福利。
六、ID 体系的设计原则总结
回顾三个 ID 的分工,可以提炼出几条 ID 设计的通用原则:
原则一:一个 ID 只干一件事
clientMsgId 管去重,不管排序。msgId 管排序,不管去重。chatId 管会话隔离,不管其他。
不要让一个 ID 承担多个职责。一旦 ID 职责交叉,去重逻辑和排序逻辑就会互相干扰,改一个另一个跟着出 bug。
原则二:谁创建谁负责
clientMsgId 由客户端创建,客户端保证唯一。msgId 由服务端创建,服务端保证唯一。各自信任对方的结果,不交叉生成。
如果让服务端生成 clientMsgId,客户端离线时就无法创建消息。如果让客户端生成 msgId,分布式环境下无法保证递增。
原则三:能算就不传
chatId 不在网络上传。客户端和服务端各自根据 from + to 计算,输入确定、输出确定,不需要额外传输。省带宽、省序列化开销、还天然一致。
原则四:ID 格式要考虑存储和索引
msgId 从三段式(type-userId-snowflakeId)简化为纯数字,直接原因是 MongoDB 的索引效率。ID 是数据库里最高频查询的字段,格式设计的优劣直接影响系统性能。
原则五:预生成优化是值得的
ID 池(一次批量 1000 个)的实现很简单,但效果显著------锁竞争频率降低 1000 倍。这种"空间换时间、批量换实时"的思路在 IM 系统里随处可见(心跳预生成、消息 ID 预分配、连接池......)。
我是 蝎子莱莱爱打怪,一个从 0 到 1 搭建分布式 IM 系统的后端开发。
XZLL-IM 干货系列共 35 篇,从协议设计到消息投递、从存储方案到性能调优,全部基于真实项目源码,不是 PPT 架构,是踩出来的实战经验。
欢迎点赞、收藏、关注。