一、引言
Key Generation(键生成)是 Apache Hudi 数据湖表的核心机制之一,它决定了每条记录如何被唯一标识(Record Key)以及如何被路由到正确的分区(Partition Path)。这一机制直接影响着数据的去重、更新、索引效率以及查询性能,本文将系统性地介绍 Hudi 中 Key Generation 的工作机制、各类型 KeyGenerator 以及生产实践。
二、核心概念与原理
1.关键术语
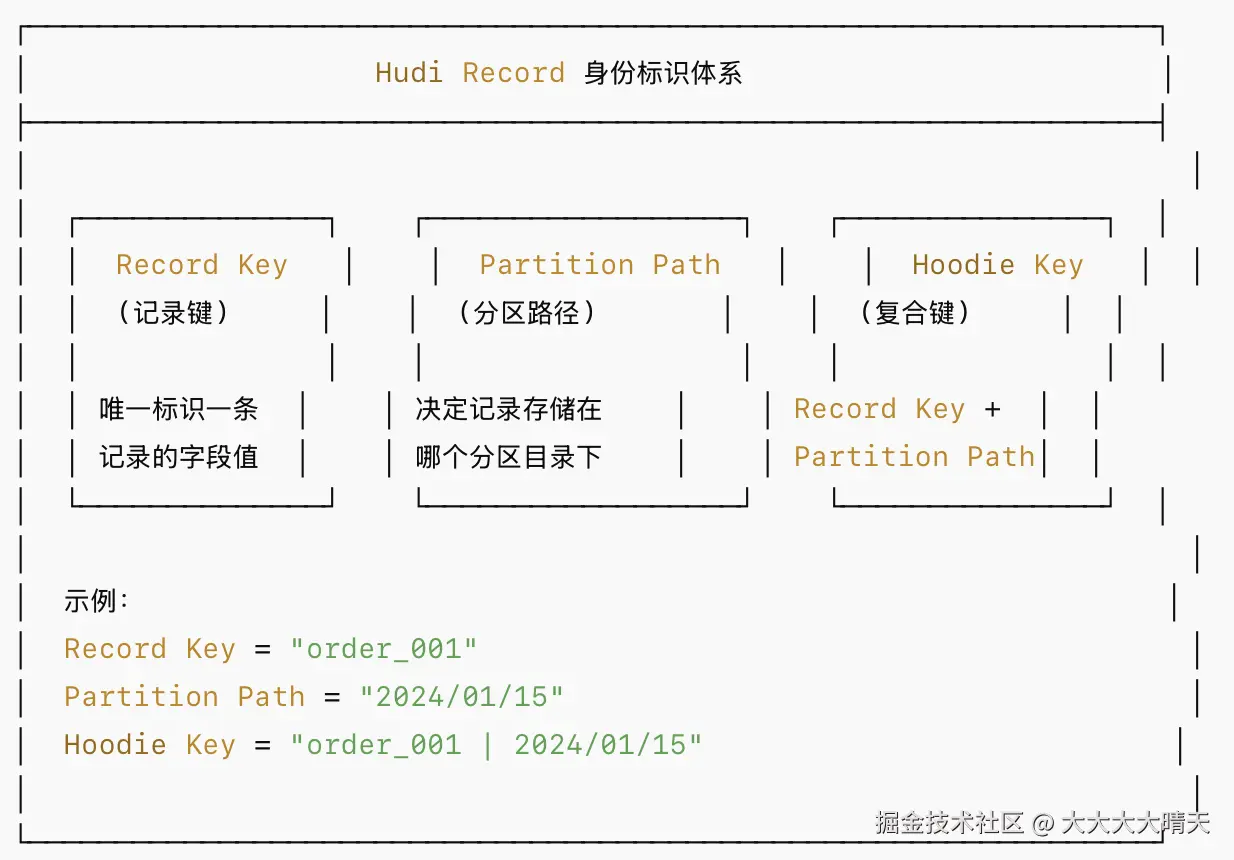
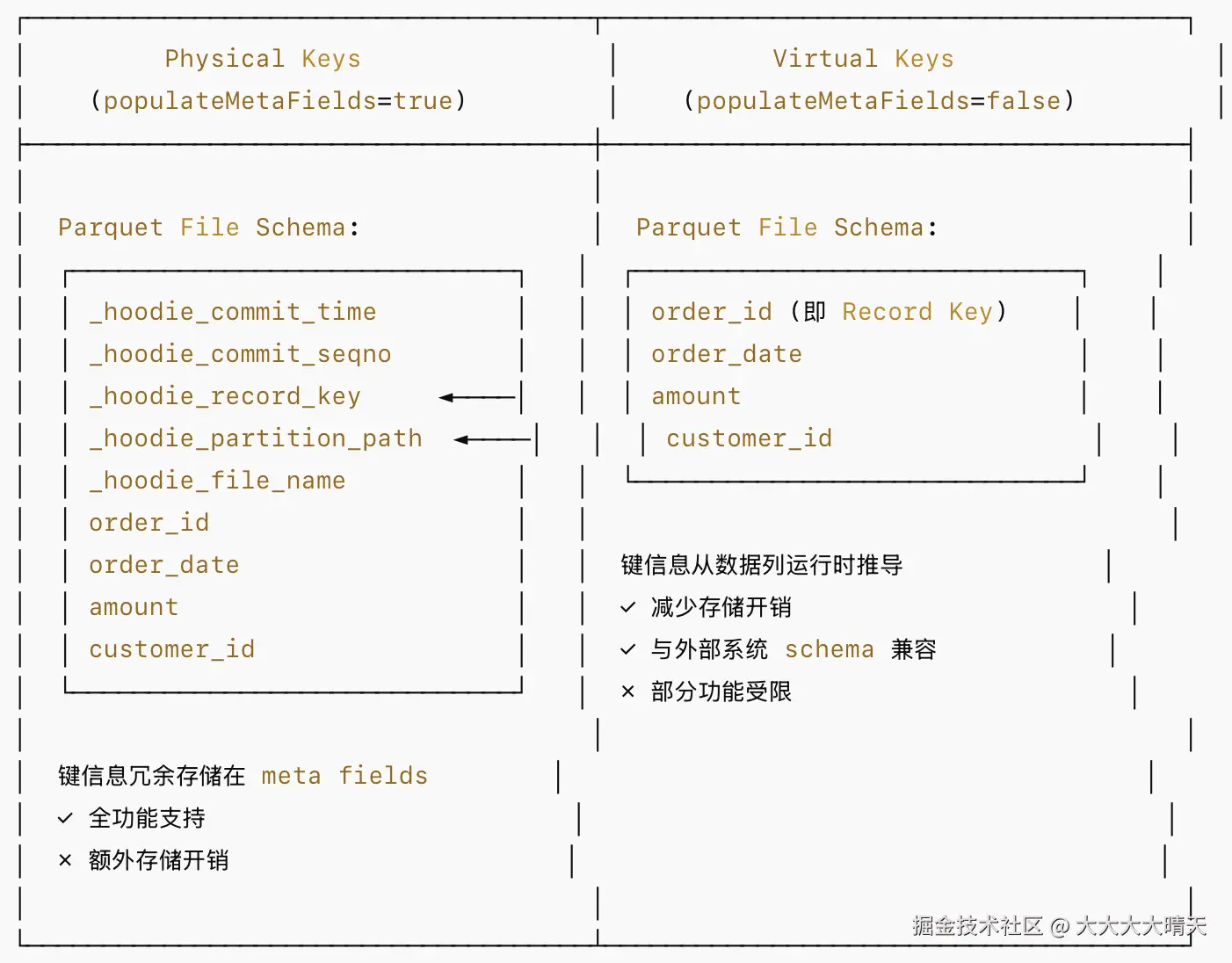
2.Physical Keys vs Virtual Keys
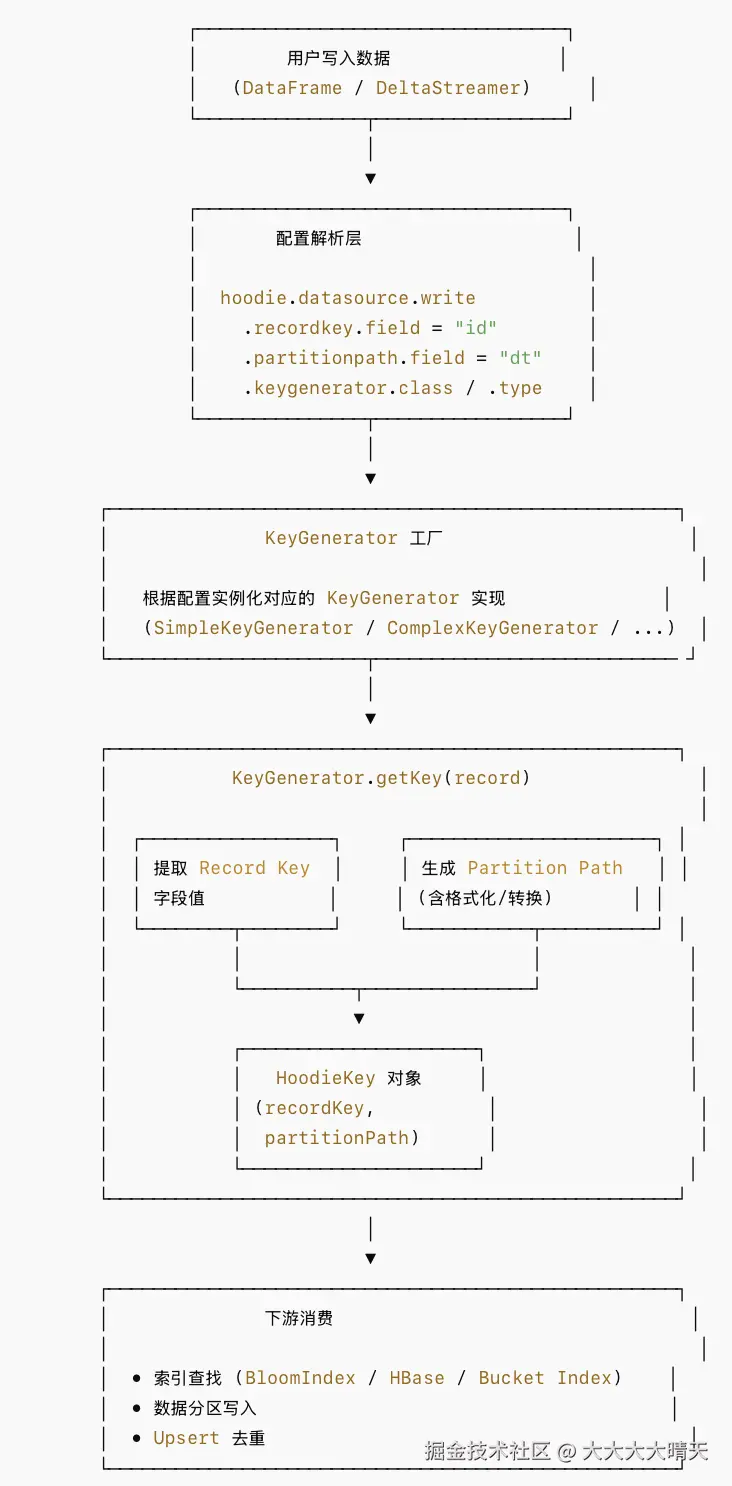
3.Key Generation整体架构
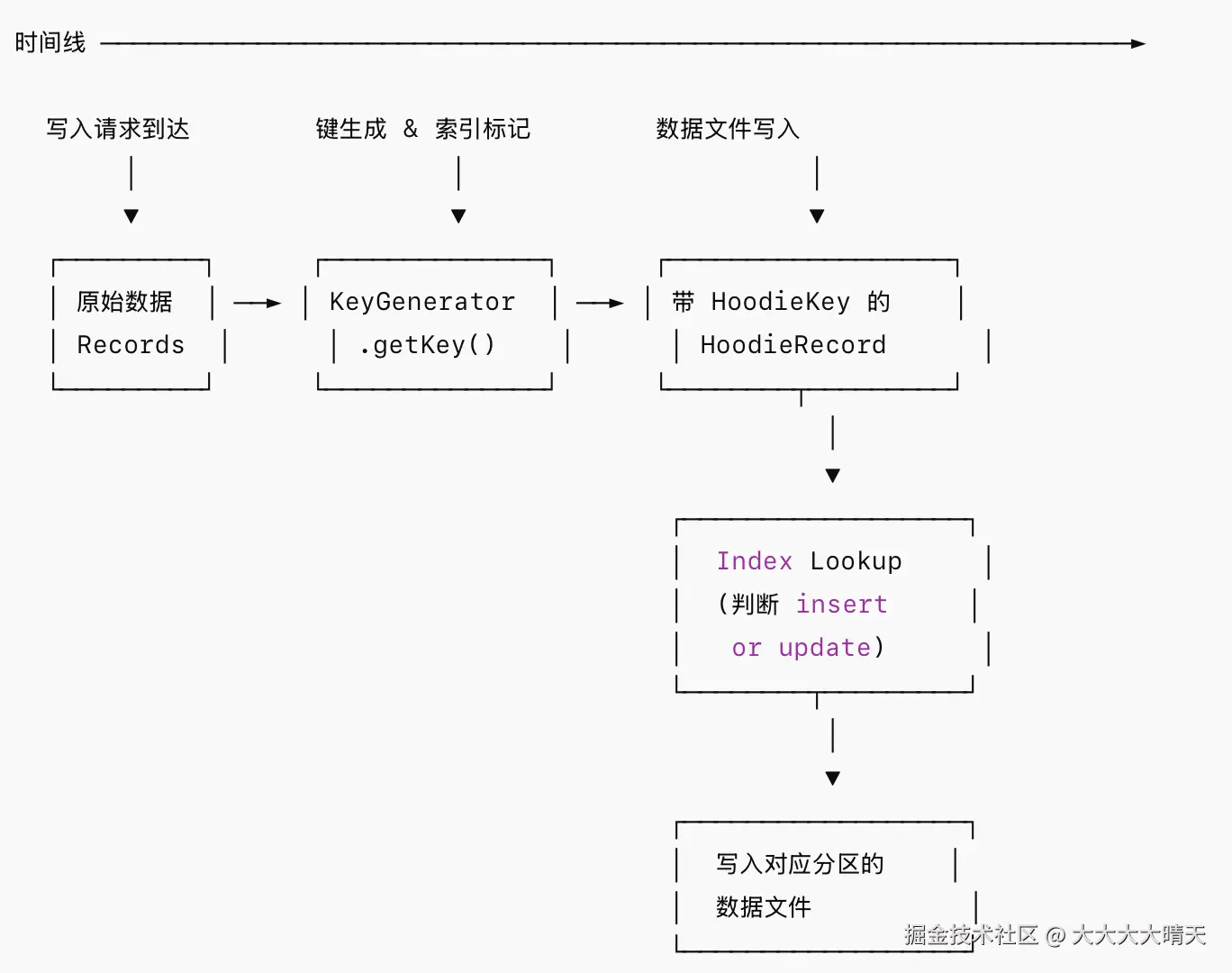
4.键生成时机
5.核心源码流程
java
// 简化示意 - 基于 Hudi 源码 KeyGenerator 抽象类
public abstract class KeyGenerator implements Serializable {
// 为单条记录生成 HoodieKey
public abstract HoodieKey getKey(GenericRecord record);
// 批量生成(性能优化)
public List<HoodieKey> getKeys(List<GenericRecord> records) {
return records.stream()
.map(this::getKey)
.collect(Collectors.toList());
}
}
// HoodieKey 的结构
public class HoodieKey implements Serializable {
private final String recordKey; // 记录唯一标识
private final String partitionPath; // 分区路径
// ...
}三、KeyGenerator 类型详解与适用场景
1.KeyGenerator类型全景
| KeyGenerator 类型 | 配置类型枚举值 | 适用场景 |
|---|---|---|
| SimpleKeyGenerator | SIMPLE | 单一字段做 Record Key + 单一字段做 Partition Path |
| ComplexKeyGenerator | COMPLEX | 多字段组合 Record Key 和/或多字段组合 Partition Path |
| CustomKeyGenerator | CUSTOM | 灵活混合分区类型(不同字段使用不同格式化策略) |
| TimestampBasedKeyGenerator | TIMESTAMP | 需要将时间戳字段转换为特定日期格式的分区路径 |
| NonpartitionedKeyGenerator | NON_PARTITION | 非分区表 |
| GlobalDeleteKeyGenerator | GLOBAL_DELETE | 全局删除场景(无需指定分区即可删除记录) |
2.SimpleKeyGenerator
最常用的默认选择,适合大多数标准场景。
ini
hoodie.datasource.write.recordkey.field=order_id
hoodie.datasource.write.partitionpath.field=order_date
hoodie.datasource.write.keygenerator.type=SIMPLE
# 或 hoodie.datasource.write.keygenerator.class=org.apache.hudi.keygen.SimpleKeyGenerator生成示例:
css
输入记录: {order_id: "ORD001", order_date: "2024-01-15", amount: 99.9}
│
▼
Record Key: "ORD001"
Partition Path: "order_date=2024-01-15" (默认带 Hive 风格前缀)配置选项:
ini
# 是否使用 Hive 风格分区 (field_name=value)
hoodie.datasource.write.hive_style_partitioning=true # 默认 true (Hudi 1.x)适用场景:
- 业务表有天然的单字段主键(如订单ID、用户ID)
- 按单一日期字段分区
3.ComplexKeyGenerator
当单个字段无法唯一标识记录时使用。
ini
hoodie.datasource.write.recordkey.field=rider_id,driver_id,trip_date
hoodie.datasource.write.partitionpath.field=country,city
hoodie.datasource.write.keygenerator.type=COMPLEX生成示例:
css
输入记录: {rider_id: "R01", driver_id: "D05", trip_date: "2024-01-15",
country: "cn", city: "beijing", fare: 45.0}
│
▼
Record Key: "rider_id:R01,driver_id:D05,trip_date:2024-01-15"
Partition Path: "country=cn/city=beijing"适用场景:
- 联合主键场景(如行程表需要 rider + driver + time 才能唯一标识)
- 多级分区(如 country/city/date)
4.TimestampBasedKeyGenerator
专门处理时间戳字段到分区路径的格式转换。
ini
hoodie.datasource.write.recordkey.field=event_id
hoodie.datasource.write.partitionpath.field=event_timestamp
hoodie.datasource.write.keygenerator.type=TIMESTAMP
# 输入时间格式
hoodie.deltastreamer.keygen.timebased.timestamp.type=EPOCHMILLISECONDS
# 或 DATE_STRING / UNIX_TIMESTAMP / SCALAR 等
# 输出分区格式
hoodie.deltastreamer.keygen.timebased.output.dateformat=yyyy/MM/dd
# 时区配置
hoodie.deltastreamer.keygen.timebased.timezone=Asia/Shanghai生成示例:
css
输入记录: {event_id: "EVT001", event_timestamp: 1705276800000}
│ (epoch ms)
▼
Record Key: "EVT001"
Partition Path: "2024/01/15"支持的时间戳类型:
| timestamp.type | 说明 | 输入示例 |
|---|---|---|
| EPOCHMILLISECONDS | 毫秒级 Unix 时间戳 | 1705276800000 |
| UNIX_TIMESTAMP | 秒级 Unix 时间戳 | 1705276800 |
| DATE_STRING | 日期字符串 | "2024-01-15 08:00:00" |
| SCALAR | 标量值(天/小时/秒) | 19738 (days since epoch) |
适用场景:
- 事件流数据(Kafka 消费场景)
- 日志数据按时间分区
- 源数据时间格式与期望分区格式不一致
5.CustomKeyGenerator
最灵活的选择,允许为不同分区字段指定不同的处理策略。
ini
hoodie.datasource.write.recordkey.field=event_id
hoodie.datasource.write.partitionpath.field=event_type:SIMPLE,event_timestamp:TIMESTAMP
hoodie.datasource.write.keygenerator.type=CUSTOM
# 时间戳相关配置同 TimestampBasedKeyGenerator
hoodie.deltastreamer.keygen.timebased.timestamp.type=EPOCHMILLISECONDS
hoodie.deltastreamer.keygen.timebased.output.dateformat=yyyy/MM/dd生成示例:
css
输入记录: {event_id: "EVT001", event_type: "click", event_timestamp: 1705276800000}
│
▼
Record Key: "EVT001"
Partition Path: "click/2024/01/15"
│ │
│ └── TIMESTAMP 类型处理
└── SIMPLE 类型处理(直接使用字段值)字段类型标注格式:field_name:TYPE,支持的 TYPE:
SIMPLE--- 直接使用字段值TIMESTAMP--- 时间戳格式化处理
适用场景:
- 混合分区策略(如按业务类型 + 时间分区)
- 需要对不同分区字段应用不同转换逻辑
6.NonpartitionedKeyGenerator
用于不需要分区的表。
ini
hoodie.datasource.write.recordkey.field=id
hoodie.datasource.write.partitionpath.field=""
hoodie.datasource.write.keygenerator.type=NON_PARTITION生成示例:
sql
Record Key: "12345"
Partition Path: "" (空字符串,所有数据写入同一目录)适用场景:
- 维度表(数据量小,无需分区)
- 配置表、字典表
7.GlobalDeleteKeyGenerator
用于删除操作时无需知道记录所在分区。
ini
hoodie.datasource.write.keygenerator.type=GLOBAL_DELETE
hoodie.datasource.write.recordkey.field=user_id
hoodie.datasource.write.partitionpath.field=""适用场景:
- GDPR 合规删除(只知道用户 ID,不知道具体分区)
- 跨分区的全局删除需求
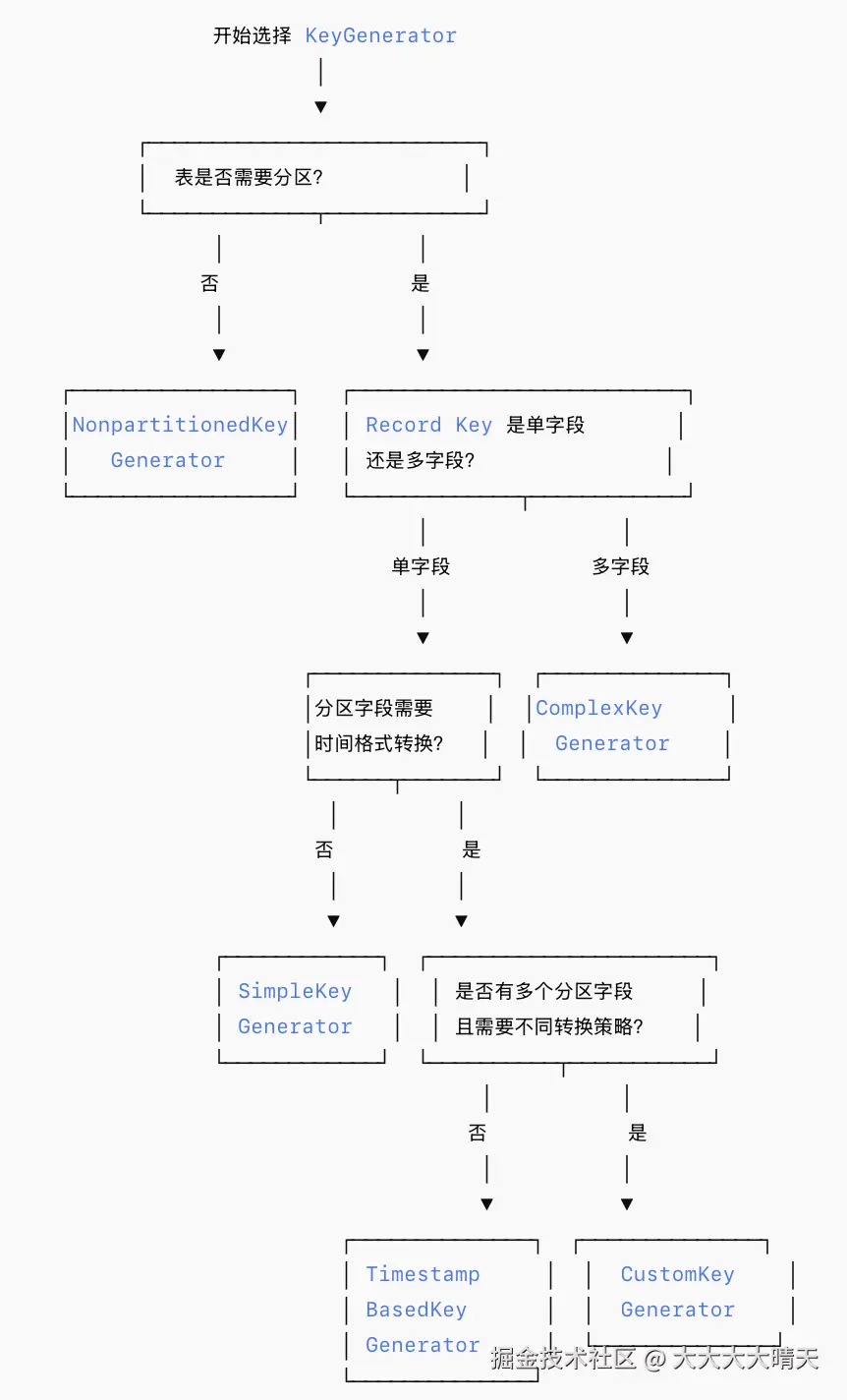
8.KeyGenerator选型决策树
四、最佳实践
1.Record Key 设计原则

2.Partition Path 设计原则
| 场景 | 推荐分区策略 | 说明 |
|---|---|---|
| 事件/日志数据 | yyyy/MM/dd 或 yyyy-MM-dd | 按天分区,平衡查询粒度与文件数 |
| 高流量事件流 | yyyy/MM/dd/HH | 按小时分区,避免单分区过大 |
| 缓慢变化维度 | 不分区 | 数据量小,全量扫描成本低 |
| 多租户 SaaS | tenant_id/yyyy/MM/dd | 租户隔离 + 时间分区 |
分区数量控制:
markdown
过少分区 ──────── 适中 ──────── 过多分区
│ │
▼ ▼
单分区文件过大 大量小文件问题
查询无法剪枝 元数据管理开销大
文件列举缓慢3.常见问题与排查
| 问题 | 原因 | 解决方案 |
|---|---|---|
| Record key field not found | 配置的 recordkey.field 不在 schema 中 | 检查字段名大小写、确认 source schema |
| 数据重复 | Key 未能唯一标识记录 | 审视 Key 设计,考虑组合键 |
| 分区路径异常 | 时间格式解析失败 | 检查 input/output dateformat 配置 |
| Null key exception | Key 字段存在 NULL 值 | 数据清洗或设置默认值 |
| 分区变更后查询不到旧数据 | Key 配置变更导致分区路径改变 | Key/分区配置一旦确定不可变更 |