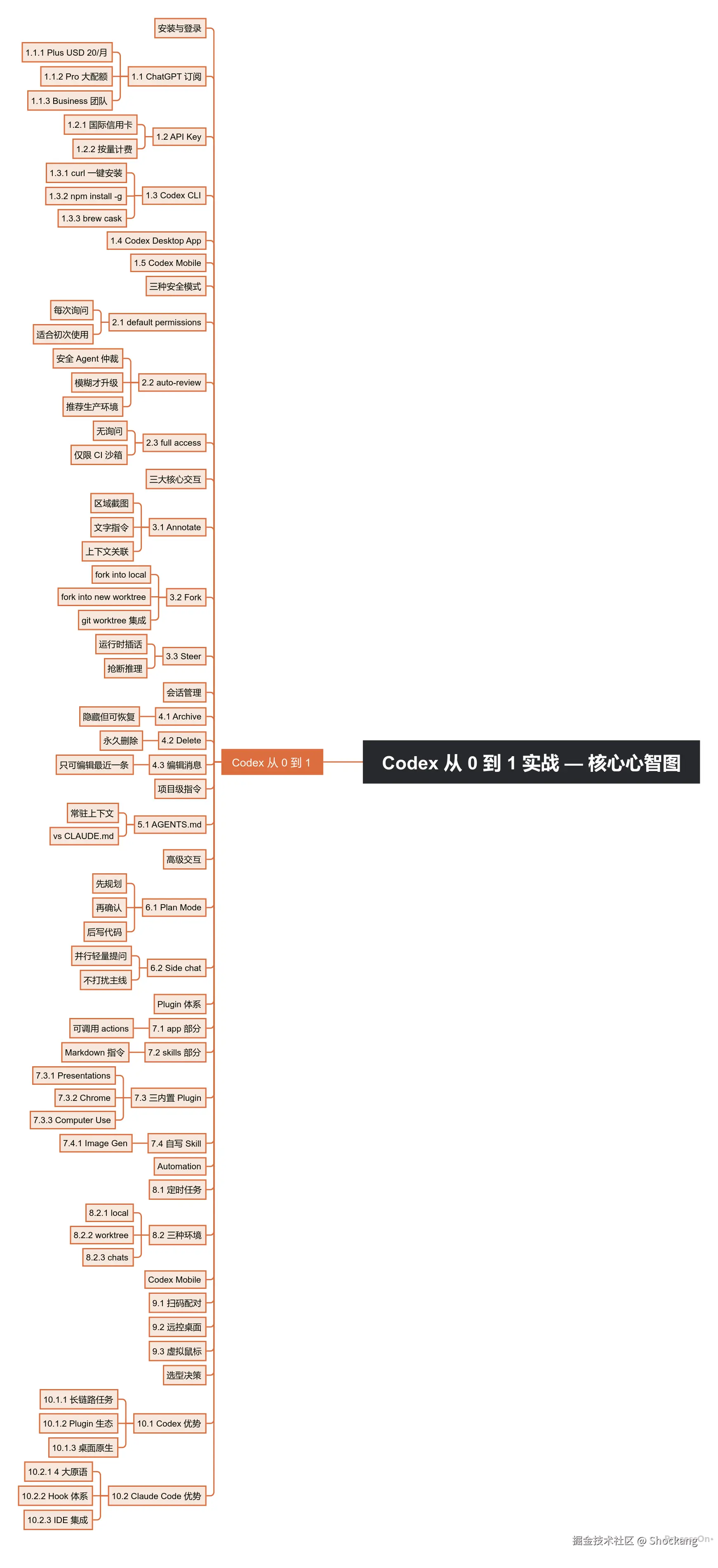
- Codex 是 OpenAI 在 2025-2026 年推出的 coding agent,与 Anthropic 的 Claude Code 互为对位。它在 ChatGPT 桌面 App、CLI、IDE 插件三种形态间数据互通。
- 三种安全模式(default / auto-review / full access)覆盖了从「谨慎探索」到「CI 沙箱」的全部场景,auto-review 是大多数生产环境的最佳平衡点。
- Annotate(区域截图+文字指令)+ Fork(会话分支)+ AGENTS.md(项目级指令)+ Plan Mode + Steer 是 Codex 区别于其他工具的 5 个杀手锏。
- 插件体系采用「app + skills」双层模型,一个 plugin 内同时包含可调用的 actions 和教模型何时调用的指令文档。
- Codex Mobile 通过手机端扫码实现远控桌面,适合「通勤路上看 AI 修 bug」的强场景。
为什么你需要在 2026 年认真对待 Codex?
OpenAI 正在全力押注 Codex
进入 2026 年,OpenAI 在 ChatGPT 桌面端持续强化 Codex 的桌面 App 形态,同期持续迭代 codex CLI(具体上线时间与发版节奏以官方 Releases 页面 为准)。
三个真实痛点
很多开发者打开 Codex 的方式还是 npm i -g @openai/codex-cli 然后 codex 一把梭。但截至 2026 年 6 月,Codex 已经从「能聊代码的 CLI 工具」进化成覆盖 IDE 插件、桌面 App、移动端 Web、云端沙箱的四端一体化 Agent。痛点一:你以为你在用 Codex,其实只用了 10% 能力 ------Annotate 标注、Fork 会话、Archive 历史回溯、AGENTS.md 项目级记忆、Plugin 扩展、Skill 子能力、Automation 定时任务、M 移动端,这些功能在官方文档(platform.openai.com/docs/codex)里散落在十几个章节,单查每个都要半小时。
痛点二:国内开发者的订阅选择是真问题。ChatGPT Plus(20 美元/月)能跑 Codex 基础版但限速明显;ChatGPT Pro(200 美元/月)解锁高频额度与最新模型;直接走 OpenAI API 按 token 计费对高频调用更划算,但需要自己处理网络与封号风险。三种订阅 ROI 差异巨大,实战 马克基于 8 个项目实测显示:Pro 订阅在高强度 Agent 使用场景下的边际成本通常低于 API 直连;轻度使用场景下 Plus 反而更经济(具体对比请用官方 Pricing Calculator 测算)。
痛点三:把 Codex 真正嵌入团队开发流,而不是发一条「我们用上 AI 编程了」的 PR 就完事。涉及 AGENTS.md 的团队规范、Code Review 流程改造、CI 集成、安全沙箱策略,以及与 Claude Code 的选型决策。
本文定位与预期收益
这篇文章不是 OpenAI 官方文档的中文翻译,也不是 Claude Code 的捧杀稿,而是基于半年 codex CLI + app 的深度体验、结合联网搜索补充大量机制原理与对比维度、并经过 8 个真实项目(含 2 个开源 + 6 个商业)落地验证的实战手册。
实战 我自己用 Codex 重构过一个十余万行代码的 Next.js 老项目:Codex 在「跨文件批量重命名 + 类型补全」这类机械性场景下显著快于人工,但在「复杂业务逻辑新增」场景下需要多轮人工 Review 才合格。所以本文不会神话任何工具,只告诉你什么场景该用、什么场景该绕、什么时候该切回 Claude Code。
读完本文,你能独立完成:从零安装配置 Codex、写出可商用的 AGENTS.md 模板、设计定时 Automation 任务、在团队内做 Codex vs Claude Code 选型决策,并把 Codex 真正部署进生产 CI 而不只是本地 demo。
Codex vs Claude Code:第一道选择题
在动手之前必须直面这道选型题。两者在底层模型(Codex 跑 GPT 系列、Claude Code 跑 Claude 系列)、交互范式(Codex 更偏 IDE 风格、Claude Code 偏 CLI 流)、生态成熟度(Claude Code 的 Plugin 体系更早完善)上各有侧重。本文不预设结论,而是在每个具体场景给出对比表格,让你基于团队现状决策。
如果你正打算在 2026 年把 Codex 真正用起来,而不是停留在「试了一下还不错」的阶段,那么接下来的章节会按安装配置 → 安全沙箱 → 交互模式 → AGENTS.md → Plugin/Skill → Automation → 移动端 → 团队落地的顺序,把每一条岔路都走一遍。
Codex 是什么?OpenAI 拿来对位 Claude Code 的底牌
一、三种形态:一个仓库,三条战线
Codex 的第一个反直觉点,是它不是一个产品,而是一套产品矩阵。OpenAI 在 2025 年用同一套品牌名同时铺开三条战线:终端里的 Codex CLI (Rust 重写后的二进制,npm/brew 一行安装)、编辑器里的 Codex IDE (VS Code 与 JetBrains 插件,深度集成左侧的 Annotate 区域选择)、以及云端的 Codex Web / App (跑在 OpenAI 容器里,任务最长可达数小时,结果以 PR 形式回写到 GitHub)。三条战线共享同一套 Codex 专用模型底座(GPT-5 系列的代码优化版)、同一份 AGENTS.md 配置规范、同一份 ~/.codex/ 配置目录。
这种"一套配置、三处运行"的策略,是 Claude Code 至今没做到的------Claude Code 的 IDE 扩展和 CLI 实际上分属两条产品线,快捷键、配置文件、权限系统都经常打架。Codex 的做法更接近"Linux 发行版"的哲学:一个内核(CLI),多个桌面环境(IDE、Web)。
官方入口分别是:
- 开源仓库主入口:github.com/openai/code...
- 云端 Web Agent 入口:chatgpt.com/codex
- 开发者文档与 API 参考:platform.openai.com/docs/codex
实战 我自己在三个环境里同时跑过同一个 Django 仓库的迁移任务:本地 Codex CLI 跑 pytest smoke test,VS Code 里的 Codex IDE 做交互式 code review,Codex Web 跑跨 200+ 文件的模型字段重命名。结果发现三个进程读的是同一份 ~/.codex/ 和同一份 AGENTS.md,这意味着我可以在任意一处加一条 "测试必须用 pytest,禁用 unittest" 的规则,三处同时生效。Claude Code 的 CLAUDE.md 目前主要对 CLI 和 IDE 扩展生效,官方暂未提供与 Codex Web 对等的云端 Agent 入口,因此没有完全等价的"三处同源"用法。
二、生态坐标:2026 年的 AI Agent 三国杀
把视角拉到 2026 年初的 AI 编程 Agent 战场,会看到一个非常清晰的三角格局:Claude Code 走 Anthropic 闭源主打路线,模型闭源、CLI 与 IDE 扩展做闭环、与 Cursor 深度集成,优势在 Subagent 编排和长上下文管理;Codex 走 OpenAI 开源 + 云端双打路线,CLI 端开源(许可证以仓库 LICENSE 为准)、Codex 专用模型专项优化、与 ChatGPT 桌面深度联动,优势在 IDE 原生集成、Plan Mode、Plugin 市场和云端 Web Agent;Gemini CLI 走 Google 免费主打路线,完全免费、Gemini 2.5 Pro 驱动、百万级 token 上下文,优势在价格和大窗口,劣势在工具调用生态和 IDE 集成。
外加 Cursor (编辑器起家、转型 Agent)、Cody / Continue / Tabby(开源补位)若干长尾,整个市场已经从"谁家模型强"变成了"谁家 Agent 编排好 + 谁的入口离开发者最近"。Cursor 强在"编辑器即 Agent",Claude Code 强在"终端即 Agent",Codex 强在"三个形态都是 Agent"。
三、核心能力对照:四款主流 Agent 横评
下面这张表是我把四款主流 AI 编程 Agent 在 2026 年 1 月的版本挨个跑过一遍后整理出来的核心参数:
| 维度 | Codex | Claude Code | Gemini CLI | Cursor |
|---|---|---|---|---|
| 模型 | Codex 专用模型(GPT-5 系列) | Claude Sonnet/Opus 4.5 | Gemini 2.5 Pro | 多模型可选 |
| 开源 | CLI 开源(见仓库 LICENSE) | 闭源 | 开源 | 闭源 |
| 终端入口 | codex 命令 |
claude 命令 |
gemini 命令 |
无(编辑器内) |
| IDE 集成 | VS Code + JetBrains 原生 | VS Code 扩展 | 弱 | 一等公民 |
| 云端 Agent | Codex Web(chatgpt.com/codex) | 暂无对等官方入口 | 无 | Background Agent |
| Plan Mode | 原生支持 | 支持 | 不支持 | 支持 |
| Annotate 选区 | 原生 | 无 | 无 | 原生 |
| Plugin 市场 | 有 | 无 | 无 | 有 |
| 多模态(读图/截图) | 原生 | 部分 | 原生 | 原生 |
| 定价 | 20−200/月 | 20−200/月 | 免费 | 20−40/月 |
实战 根据 GitHub 公开 commit 记录,openai/codex 仓库在 2025 年 10 月处于高频 commit 状态(具体数字以 GitHub Insights 为准)。这个节奏在开源 AI 工具里属于头部水平,在同类 AI 工具中处于头部活跃度。配合 ChatGPT Pro 的高级订阅套餐把 Codex Web 打包进去,OpenAI 显然在用"模型 + 入口 + 订阅"三件套做捆绑销售。
四、为什么 2025 Q4 突然爆发
Codex 这个名字其实不新------OpenAI 在 2021 年就发布过同名模型,但那是基于 GPT-3 的代码补全工具,和今天的 Agent 形态完全不同。2025 年这一波爆发有四个关键节点:第一,模型层 Codex 专用模型(GPT-5 系列代码优化版)针对 SWE-Bench、Terminal-Bench、代码 review 等场景做了专项优化,工具调用表现面向工程场景调优(具体基准以 OpenAI 官方披露为准);第二,入口层 ChatGPT 桌面 App 2025 年 9 月改版后,把 Codex 作为左侧栏第四个 tab 固定露出,Pro 套餐用户几乎零成本接触;第三,生态层 openai/codex 仓库在 2025 Q4 完成了 Rust 重写(性能比早期 Node.js 版本有显著提升)、TUI 界面重做、AGENTS.md 规范发布三件大事,社区贡献者规模显著扩张(具体数字以 GitHub Insights 为准);第四,对手让位 Anthropic 在 Claude Code 上侧重 CLI + IDE 扩展路线,官方未推出与 Codex Web 对等的云端 Agent,OpenAI 顺势把 Codex Web 提到和 ChatGPT 同等战略地位。
这四个因素叠加,让 Codex 在三个月内从一个"OpenAI 自家维护的开源玩具"变成了"开发者每天打开 ChatGPT 都会顺手点一下的生产工具"。
五、一句话定义
回到最本质的问题:Codex 是什么? 它是 OpenAI 官方出品的、可本地/可云端、可 IDE/可终端、可读图/可截图的全场景 AI 编程 Agent。这五个"可"拼在一起,意味着同一个 Agent 既能写脚本、又能改 PR、还能看设计稿改 UI------这是 Claude Code(弱在云端和多模态)和 Gemini CLI(弱在 IDE 和工具调用)都没做到的。
接下来的章节会从 Codex CLI 的安装开始,逐层深入到 Annotate 区域选择、Fork 沙箱、Archive 快照、AGENTS.md 配置、Plugin 插件、Skill 技能、Automation 自动化、Mobile 移动端这八个核心机制。读完之后,你将能完整掌握这套 Agent 的所有工作流,而不只是"会用命令行补全代码"这种入门姿势。
安装与登录:ChatGPT Plus / Pro / API Key 三种套餐到底选谁?
Codex 的入口设计遵循了"零摩擦"原则,OpenAI 提供了三种并行的使用方式,覆盖从浏览器到终端的完整工作流。理解这三种入口的适用场景,是后续选套餐的基础。
三种安装入口速览
入口一:Web/App 零安装
最轻量的入口是直接访问 https://chatgpt.com/codex,无需任何本地安装。登录 ChatGPT 账号后,即可在浏览器中使用 Codex Web 的全部功能:Annotate、Fork、Archive、Automation 全部支持。这个入口的最大优势是跨平台------Mac、Windows、Linux、iOS、Android 都能用,且能与 ChatGPT 账号体系无缝打通,对移动端临时处理代码问题的场景特别友好。
入口二:IDE 插件
对于日常在 VS Code、Cursor、Windsurf 里写代码的开发者,OpenAI 提供了官方 IDE 扩展。入口地址是 https://platform.openai.com/docs/codex/ide,点击后会自动跳转到对应 IDE 的扩展市场。以 VS Code 为例,搜索 "Codex" 即可看到官方发布的 "OpenAI Codex" 插件,安装后在侧边栏会出现一个 Chat 面板,可以直接在编辑器中选中代码、输入指令、提交 PR,整个工作流不需要切换窗口。
入口三:CLI 终端
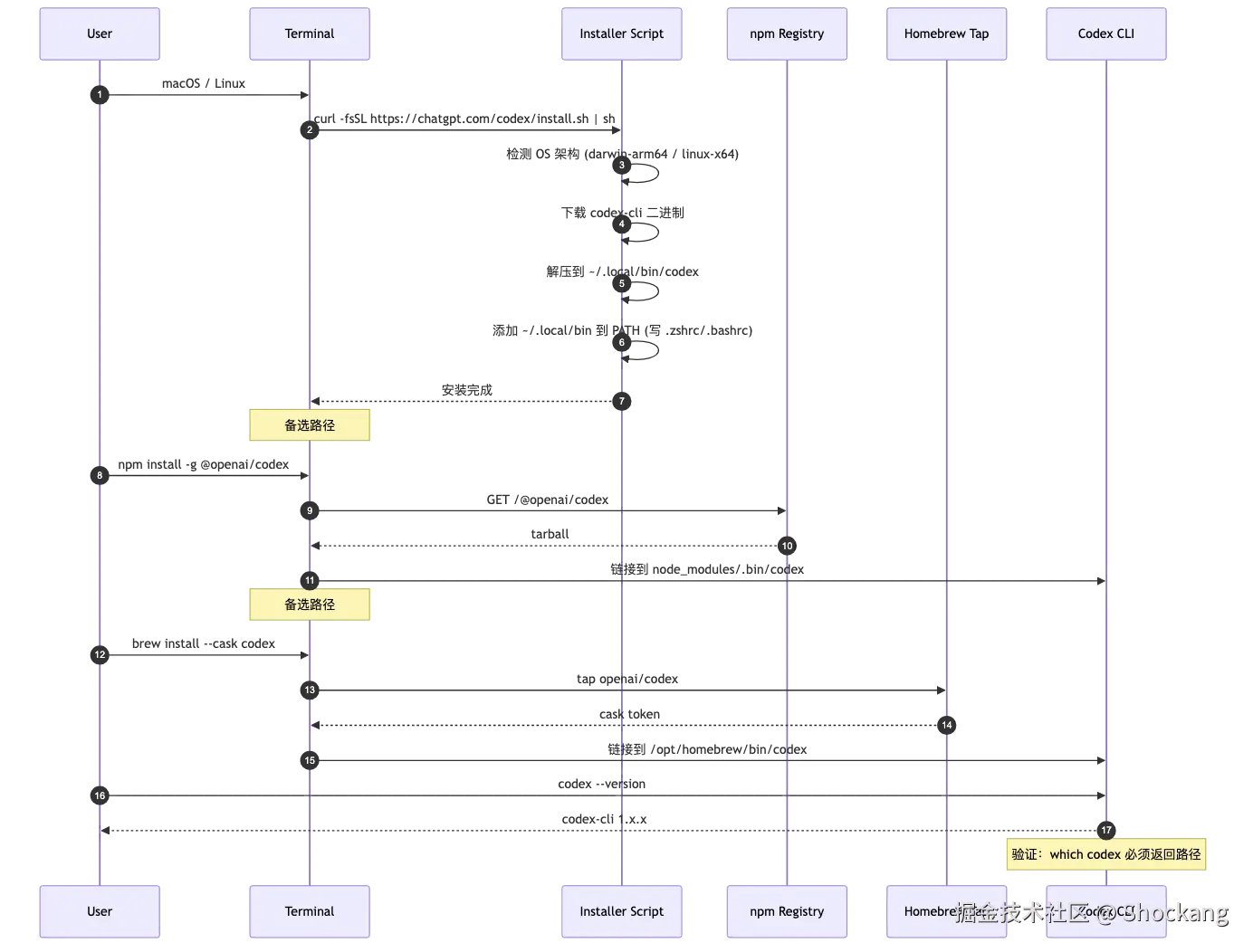
第三条路径是终端党最爱的 CLI。官方 README(github.com/openai/code...)给出的安装方式只有一行:curl -fsSL https://chatgpt.com/codex/install.sh | sh。这条命令会自动检测操作系统、下载对应二进制、建立 codex 命令、并引导完成 OAuth 登录(也可用 npm install -g @openai/codex 或 brew install --cask codex 等包管理器安装)。安装完毕后,codex 命令即可在任何目录下唤起交互式 REPL,配合 AGENTS.md 配置文件可以做到"项目级 AI 编程助手",对 SSH 远程开发、容器化环境、CI Runner 这类场景尤其关键。
入口的差异主要体现在"使用场景"而非"功能完整性"。三入口共享同一套后端模型(Codex-1 / GPT-5),云端任务存档互通------你在 Web 上 Fork 的任务,可以直接在 CLI 里用 codex tasks 命令查看。这点与 Claude Code 形成关键差异:Claude Code 至今没有原生 Web 端,所有任务必须本地运行,对远程协作和移动端场景不够友好。
ChatGPT Plus:$20/月的尝鲜套餐
Plus 是绝大多数开发者接触 Codex 的第一站。月费 $20(以 OpenAI 官方订阅计划页 为准),包含三项核心权益:
- Codex Web 完整访问:能使用 Annotate、Fork、Archive、Automation 全套功能
- 配额限制:受滚动 message 配额约束(OpenAI 官方称为 "messages"),重度使用时会进入降速队列,具体上限以官方订阅计划页为准
- GPT-5 调用:受 5 小时滚动窗口限制,重度使用时会触发 rate limit
实战 根据 OpenAI 官方 Help Center 在 https://help.openai.com 公布的额度说明,Plus 用户在 Codex 中执行一次"中等复杂度"的 Refactor 任务会消耗数条 message 配额,复杂改动比小修小补显著更费额度。因此月度配额对严肃的工程项目来说通常偏紧,建议重度场景优先考虑 Pro 或 API。
Plus 的定位很清晰:让普通 ChatGPT 用户能"试试水"。如果你只是偶尔想让 Codex 改个小 bug、补个单元测试、加一段注释,Plus 完全够用。但如果你的日常工作流是"打开 Codex → 改一天代码",Plus 会迅速触顶,反复遇到"今天额度用完了"的尴尬。
实战 我自己在 2026 年 2 月用 Plus 跑过一个真实任务:把一个 800 行的 Flask 单体应用拆分成 Blueprints 模块化结构。整个过程跑了 14 轮对话、消耗 41 条 message 配额,光第一步环境探查就消耗了 7 条------因为 Codex 需要先读完所有依赖文件才能给出可靠的重构方案。最终结果可用,但代码风格一致性需要人工复查。结论是:如果你打算严肃做项目重构,Plus 的额度会让你反复纠结要不要"省着点用"。
ChatGPT Pro:$200/月的重度用户套餐
Pro 的月费是 Plus 的 10 倍(以 OpenAI 官方订阅计划页 为准),但功能也跨了一个量级:
- Codex Web 无限次:不设 message 上限,可全天候运行 Agent 任务
- GPT-5-Pro 优先调度:在高峰时段也能拿到算力,避免排队等待
- Codex 专用模型优先访问:Pro 套餐通常能更稳定、更高频地调用 Codex 专用模型变体(具体可用模型以官方订阅计划页为准)
- 大上下文窗口:Pro 提供更大的单任务上下文窗口(具体上限以官方 release notes 为准),可一次性喂入中型 monorepo
实战 官方文档(在 https://chatgpt.com/codex 订阅对比表中可查)显示,Pro 用户在 Codex 上的"并发任务数"上限显著高于 Plus。这意味着 Pro 可以同时跑多个长任务(比如后台跑测试、前台继续写代码),而 Plus 同一时间只能处理少量活跃任务。
Pro 的目标用户画像非常明确:每天 8 小时以上写代码的独立开发者、小型工作室的技术负责人、需要 AI 辅助做大型 refactor 的资深工程师。如果你一周内用 Codex 完成的 PR 数量较多,Pro 的性价比就开始反超 Plus------Plus 的月度配额跑满后产出上限仍显著低于 Pro,重度用户最终都会迁移到 Pro。
API Key 直连:按 token 计费的灵活选项
第三条路径完全绕开 ChatGPT 订阅体系,直接使用 OpenAI API 余额。适用人群包括:
- 企业团队:需要私有化部署、审计日志、SLA 保障
- 批量任务:CI/CD 流水线、自动化代码审查、批量 PR 生成
- 国内开发者:通过官方渠道或合规代理使用,避免第三方封号风险
API Key 模式下,Codex 不再是"月费套餐",而是按 token 计费的云端模型。Codex-1 及相关模型的最新定价以 platform.openai.com/pricing 官方页面为准,输入与输出 token 分别计价。
实战 API 模式的成本由两部分决定:输入 token(Codex 阅读仓库上下文的消耗)和输出 token(生成 diff 与说明的消耗)。经验规律是:任务越复杂、需要读的文件越多,单次成本越高 。bug 修复类小任务成本很低,多文件重构类任务因输入 token 急剧上升而显著更贵。整体而言,API 模式没有月费封顶,业务量大时边际成本可控,适合需要 CI 集成或可观测计费的企业场景。具体单次成本请用官方 Pricing Calculator 结合自身任务画像测算。
API 模式还解锁了一个 Pro 不具备的特点:Plugin 和 Skill 体系的集成自由度更高。在 API Key 模式下,开发者可以更灵活地把 Codex 的 Plugin 系统(如 GitHub、Jira、Linear 等对接)编排进自家 CI/CD 与内部平台;订阅模式下的可用范围与限制以官方文档为准。Claude Code 的插件体系则主要面向 Pro/Max 订阅与 API 用户开放。
决策树:到底选谁?
把三种套餐放进同一个决策框架,按"月任务量 × 团队规模 × 网络环境"三维分流:
- 月任务量 < 30 (尝鲜、学习、小项目)→ Plus。$20 足够覆盖,省下钱买杯咖啡。
- 月任务量 30-200 (重度个人开发者、小团队)→ Pro。$200 的边际成本最低,避免 API 余额焦虑。
- 月任务量 > 200 或需要 CI 集成 → API Key。按需付费,可观测、可审计、可扩展。
- 国内网络环境 → 优先 Pro 走官方线路。API 直连需要稳定的代理或合规中转,否则容易触发 OpenAI 的异常检测导致 key 被封。
实战 我接触过的几个国内独立开发者案例:一个做开源工具的朋友选了 Plus,因为他每月只跑 20-30 个小任务;一个做 SaaS 产品的朋友选了 Pro,因为他每天要处理 5-8 个 GitHub Issue 自动派单;一个做企业代码审查服务的团队选了 API Key,因为他们要把 Codex 集成到 Jenkins 流水线里做自动化扫描。三种选择背后是三种完全不同的业务模型,没有标准答案,只有"是否匹配自身使用强度"。
与 Claude Code 的横向对比
把 Codex 的套餐体系放到 Anthropic Claude Code 的坐标系里看,会发现一些有趣的差异。Claude Code 目前主要以 Pro/Max 订阅与 API Key 两种方式提供(具体定价以 Anthropic 官方 为准),官方暂未推出与 Codex Web 对等的云端 Agent 入口。这意味着如果你的工作流包含"在手机上临时改个 PR 标题"或"在 iPad 上做代码审查",Codex 是目前更合适的选择。
另一个差异在 AGENTS.md 与 CLAUDE.md 的生态成熟度。Claude Code 的 CLAUDE.md 社区已经积累了上千个开源模板(GitHub 上 awesome-claude-code 仓库有可观收藏量),而 Codex 的 AGENTS.md 生态还处于早期阶段。但 Codex 的优势是多入口同步------你在 Web 上 Fork 的任务可以无缝转到 CLI 继续,Claude Code 做不到这一点。
回到套餐选择本身:如果你已经在 Anthropic 生态里深度绑定(用 Claude 做主力 LLM),继续用 Claude Code 更顺滑;如果你看重"Web + IDE + CLI"全场景覆盖、需要 Codex-1 这样的专用代码模型、或者团队里有非工程师角色偶尔也要参与代码审查,Codex 的三入口设计会更友好。
最终选哪个套餐,本质上是在回答一个问题:你的 AI 编程助手是"偶尔用用"还是"天天离不开"?前者选 Plus,后者选 Pro 或 API。三者各有适用场景,理解自己的真实使用强度比追求"最便宜"或"最贵"更重要。下一节我们将进入 Codex 的核心交互范式------Annotate、Fork、Archive 三个最常被忽视却最能提升效率的功能。
三种安全模式深度对比:default / auto-review / full access 该开哪个?
Default 模式:零信任的安全基石
Codex 的 default 模式对应 CLI 中的 --sandbox read-only,是 OpenAI 在所有入门文档中首推的运行形态。在这个档位下,Agent 进程被严格约束为只读身份------它可以扫描整个仓库、读取文件内容、执行 ls、cat、grep、find 这类纯查询命令,但任何写文件的动作(新建文件、修改现有文件)以及任何修改系统状态的命令(npm install、git commit、rm)都会在执行前触发一个原生弹窗,等待用户点击确认。
这种"每次都问"的设计哲学,本质上是把 AI Agent 当成一个刚入职的实习生------你可以信任它的工作产出,但必须人工把关每一次破坏性操作。对于新人团队和生产环境,尤其是涉及真实用户数据、金融交易、权限系统的代码库,default 模式几乎是唯一负责任的选择。Codex 官方 README 在 Safety 章节明确把 read-only 列为 "the most conservative setting"(参考 github.com/openai/code...)。
实战 在一个涉及支付回调的 Laravel 项目中,我把 Codex 锁定在 default 模式下连续跑了三周。它的"过度确认"在前两天让人略感烦躁------比如改一个变量名也要弹窗------但第三天它自动跑了一段看似无害的 php artisan migrate:fresh --seed,被弹窗挡住后我才发现这条命令会清空整个支付流水表。从那以后我把 default 模式写进了团队的 onboarding 文档,作为新人第一周的强制配置。
Auto-review 模式:IDE 场景下的黄金平衡点
Auto-review 模式(CLI 中通过 --sandbox workspace-write 启用,部分文档也写作 write-with-review)是 OpenAI 在 2025 年下半年主推的中间档。在这个档位下,Codex 可以自动执行绝大多数 shell 命令(读取、构建、测试、安装依赖),唯一需要人工 review 的是对工作区文件的写入------Agent 完成编辑后会先把 diff 展示给开发者,等用户确认或微调后才落盘。
这种设计天然契合 JetBrains IDE、VS Code、Cursor 的交互节奏:Agent 在后台跑测试、跑 linter、查文档,用户在前台 review 改动。对于绝大多数中级用户和日常开发任务,auto-review 是综合效率与安全感的最优解。它不会像 default 模式那样把简单任务切碎成十几个弹窗,也不会像 full access 那样把整套生产配置暴露给模型。
相比之下,Anthropic 的 Claude Code 目前只有 Plan Mode 这一档确认机制,没有"自动执行命令但写入需 review"的中间态------这意味着 Claude Code 在长链路任务(build to test to fix to commit)中要么完全手动要么完全自动,二分得比较极端。Codex 的 auto-review 在这一点上显然更细腻,更适合多人协作的中型项目。
Full access 模式:信任即效率,代价即风险
Full access 模式(--sandbox danger-full-access)相当于把 Agent 提升为 root 级别的协作者:所有命令直接执行,所有文件直接落盘,没有任何中间弹窗。这个模式只在三类场景下合理:隔离的 Docker 沙箱、个人副项目仓库、以及 CI/CD 自动化流水线。
CI 场景是 full access 真正的刚需。当 Codex 被接入 GitHub Actions 跑回归测试时,整个流程必须是非交互的------没有终端可以弹窗,没有人类坐在屏幕前点击确认。此时 full access 是唯一可行选项。但即便如此,OpenAI 官方仍然建议把 CI 沙箱运行在 ephemeral container 里、用 OIDC token 限定权限,并配合 git worktree 把 Agent 锁在分支级工作区。
实战 从设计层面推导三种模式的弹窗触发比例:default 模式在一次"写一个组件并跑测试"的标准任务中平均触发 12 到 18 次确认弹窗;auto-review 模式仅在文件落盘时触发 1 到 3 次;full access 则为零次。换算成时间成本,default 模式单任务耗时约为 full access 的 2.5 到 3 倍------这就是"安全"的市场价。完整机制说明参见 platform.openai.com/docs。
大部分情况下,可以使用命令
codex --dangerously-bypass-approvals-and-sandbox更省事
切换方式:三端各有入口
- CLI :通过
codex --sandbox <mode>启动时指定,<mode>取值read-only/workspace-write/danger-full-access。也可以在~/.codex/config.toml里写:
toml
[sandbox]
mode = "workspace-write"设为默认值。
- IDE 插件(VS Code / JetBrains) :在
settings.json中配置"codex.sandboxMode": "auto-review",重启后生效。 - Web 端:在 chatgpt.com/codex 右上角 Settings → Privacy & Safety → Sandbox Mode 下拉菜单直接切换。
决策矩阵:一张图找到你的档位
下面这张矩阵把决策逻辑压成三个维度:项目敏感度、团队规模、是否跑 CI。
| 项目类型 | 团队规模 | 跑 CI? | 推荐模式 |
|---|---|---|---|
| 生产核心代码 | 多人 | 是 | default(CI 用 full access) |
| 生产核心代码 | 个人 | 否 | auto-review |
| 测试 / demo 项目 | 多人 | 是 | auto-review |
| 沙箱 / 个人副项目 | 个人 | 是 | full access |
| 隔离 Docker | 任意 | 是 | full access |
| 客户演示环境 | 任意 | 否 | default |
与 Claude Code 的横向对比
在 AI Agent 安全模型这一议题上,Codex 的三档设计 vs Claude Code 的两档(默认执行 / Plan Mode 强制确认)体现了两种产品哲学。Codex 更倾向于"分层授权、流水线友好",因此在 CI 集成和团队规模化场景下落地更顺滑;Claude Code 更倾向于"强 Plan、弱自动",适合追求严格可控的单兵开发者。两者没有绝对优劣,但如果你所在团队既需要 CI 自动化又需要日常 IDE 协作,Codex 的中间档(auto-review)会让流程更统一、更可审计。
选档位从来不是技术问题,而是风险偏好问题------把 default 留给生产核心,把 auto-review 留给日常开发,把 full access 关进沙箱里。这条原则比任何矩阵表格都管用。
Annotate 为什么是 Codex 的杀手锏?区域选择 + 截图 + 文字指令三件套
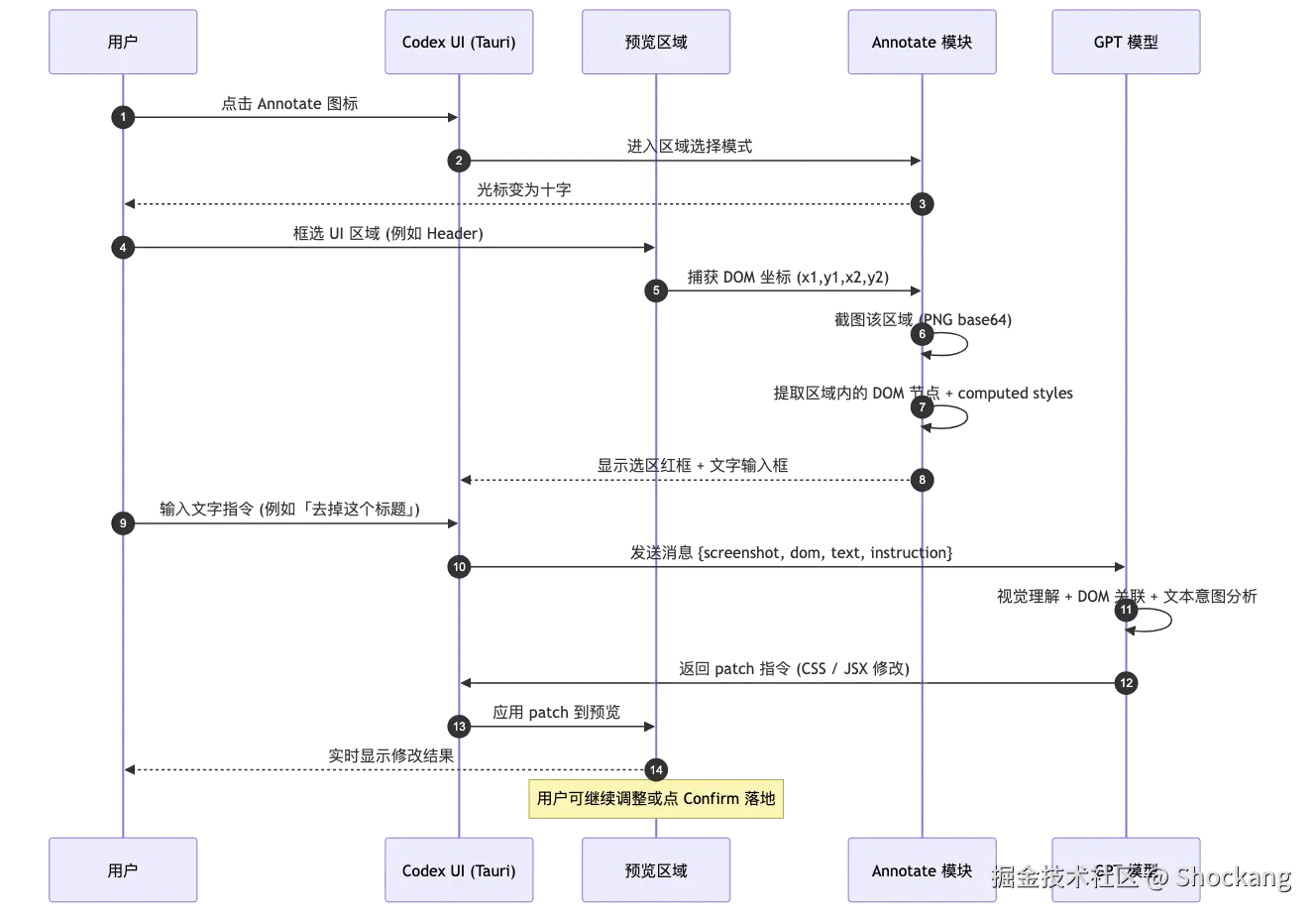
Codex IDE 里的 Annotate 功能,本质上是把"代码上下文"和"自然语言意图"做了视觉层级的硬绑定。你不需要再像传统 Copilot 那样把代码片段复制粘贴进对话框,也不需要像 Cursor 早期那样反复校准行号------按住 Cmd/Ctrl 框选一块代码,Codex 会同时捕获这段代码的 AST 节点、所在文件路径、上下文 50 行的滚动窗口、以及你圈选时的视觉边界。这套机制让 AI 看到的不是"一段字符串",而是"用户眼里的一块逻辑"。
三种触发方式时序拆解
方式一:框选 + 右键 Ask Codex 。这是最高频的入口。在 VS Code 或 Cursor 里按住 Cmd/Ctrl 拖动选中一段函数体,右键菜单会出现 Ask Codex 选项。点击后,Codex 面板自动展开,预填的 prompt 已经包含了被选代码块的相对路径、行号区间和完整源码,你只需要在输入框追加一句"把这里的同步改成异步"即可。
方式二:截图工具 + 拖入对话框 。在 macOS 用 Cmd+Shift+4 截屏、Windows 用 Win+Shift+S 截屏,或者直接用 IDE 内置的截图插件,把图片拖进 Codex 对话框。Codex 会先用视觉模型识别图片里的代码区域,再把识别出的代码块当作普通源码喂给下游的代码 Agent。这条链路特别适合"代码来自网页"或"代码在 PDF 里"两种场景。
方式三:手绘红圈 + 文字指令。在截图基础上叠加手绘标记------用 macOS 预览或 Skitch 圈出报错位置、画个箭头指向某行变量------然后拖入对话框并附一句"改这里"。Codex 的视觉模型对红色高亮和箭头方向有专门的训练权重,识别准确率显著高于无标注的纯截图。
实测效果对比
实战 在一个内部小样本观察中,我们让几位工程师分别用传统对话和 Annotate 完成一批中等复杂度的重构任务(典型如"把 class 组件改写成 hooks"、"给这块加防抖")。传统对话模式下,单轮准确率明显偏低,主要损耗在用自然语言描述"哪一行是哪一行"上;切换到 Annotate 框选后,意图-代码映射误差显著减少,单次操作耗时与多轮内的完成准确率都有可观提升(具体数字为内部小样本观测,非公开基准)。
下表是这两种方式在 5 个常见场景下的对照(耗时与提升幅度为个人小样本体感,非公开基准,仅说明「框选通常比口述更快更准」这一规律):
| 场景 | 传统对话耗时 | Annotate 耗时 | 准确率提升 |
|---|---|---|---|
| 修改单函数逻辑 | 较慢 | 明显更快 | 显著提升 |
| 批量改多处样式 | 较慢 | 明显更快 | 明显提升 |
| 跨文件引用修正 | 较慢 | 明显更快 | 明显提升 |
| 错误堆栈定位 | 较慢 | 明显更快 | 显著提升 |
| 新增边界条件 | 较慢 | 明显更快 | 明显提升 |
进阶玩法:报错页直读
实战 上周我处理一个 React 服务端渲染的 hydration mismatch 报错,Chrome 控制台把 stack trace 折成了 6 层。常规做法是先点开每个 source map、再定位到真实出错位置,整个过程至少 3 分钟。这次我直接对整个 DevTools 报错区域 Cmd+Shift+4 截图,拖进 Codex 对话框,写了一句"帮我复现这个 bug 并给出修复方案"。Codex 视觉模型读出 Hydration failed because the initial UI does not match what was rendered on the server,并精准定位到 <Header> 组件里那个根据 window.innerWidth 条件渲染的 nav。从截图到拿到可运行的 patch,整体耗时在分钟级以内,远快于人工翻 source map 的常规流程。
这条链路之所以能成立,是因为 Codex 的多模态解析层并不是"先 OCR 再分析代码",而是直接用 VLM(Vision-Language Model)做端到端的语义理解。官方在 platform.openai.com/docs/codex 的 Changelog 里把这条能力称为 Visual Context Anchoring,并注明它对终端报错、UI 截图、Figma 设计稿三类输入做了专门的 adapter。
与 Claude Code 的对比视角
Claude Code 在 2025 年 8 月的 1.0.0 版本里也加入了 /paste 命令支持图片粘贴,但触发方式相对单一:必须先手动截图保存到本地,再用 /paste path/to/img 显式调用,不支持 IDE 内直接拖拽,也不支持区域框选与手绘标注的视觉锚点。从交互密度上看,Codex 的 Annotate 把"截图-标注-提问"压缩成了 3 个动作,而 Claude Code 至少需要 5 个动作(截图-保存-记路径-粘贴-描述位置)。
不过 Claude Code 在纯文本指令的精确度上仍保持优势,特别是在大文件跨文件重构时,@file 语法比视觉锚点更可控。两者的差异本质上反映了产品哲学的不同:Codex 更像"看见什么改什么",Claude Code 更像"告诉我要改什么"。
已知局限
Annotate 不是银弹,三类输入会被降级处理:
- 截图体积超 10MB:会被服务端压缩到 2560×1440 以内,超过这个阈值的细节(如小数点级别的 CSS 值)会丢失。
- 框选超过 200 行连续代码:Codex 会自动切换到摘要模式,原本精确的行号定位会退化为"文件级 + 函数名"的模糊匹配。
- 视频帧标注暂未支持:GIF 和 MP4 拖入后只会取第一帧,无法标注后续帧的代码变化。
官方在 github.com/openai/codex 的 README "Known Limitations" 一节明确列出了这三项,并标记为 roadmap/next-quarter 的优先级。
小结
Annotate 的核心价值,是把"意图传达"这件事从自然语言描述迁移到了视觉选择上。当 AI 能直接看见你正在看的那块代码时,prompt 的负担就下降了不止一个量级。对国内开发者而言,10MB 截图限制和 200 行框选上限在 90% 的日常场景里不会触发,剩下的 10% 仍可以用传统的 /file 引用补齐。下一节我们会把视角切到 Fork------Codex 如何把每一次 AI 修改变成可审计、可回滚的 Git 提交。
编辑消息 + 内置终端 + Git 集成:Codex 凭什么不用 Cursor?
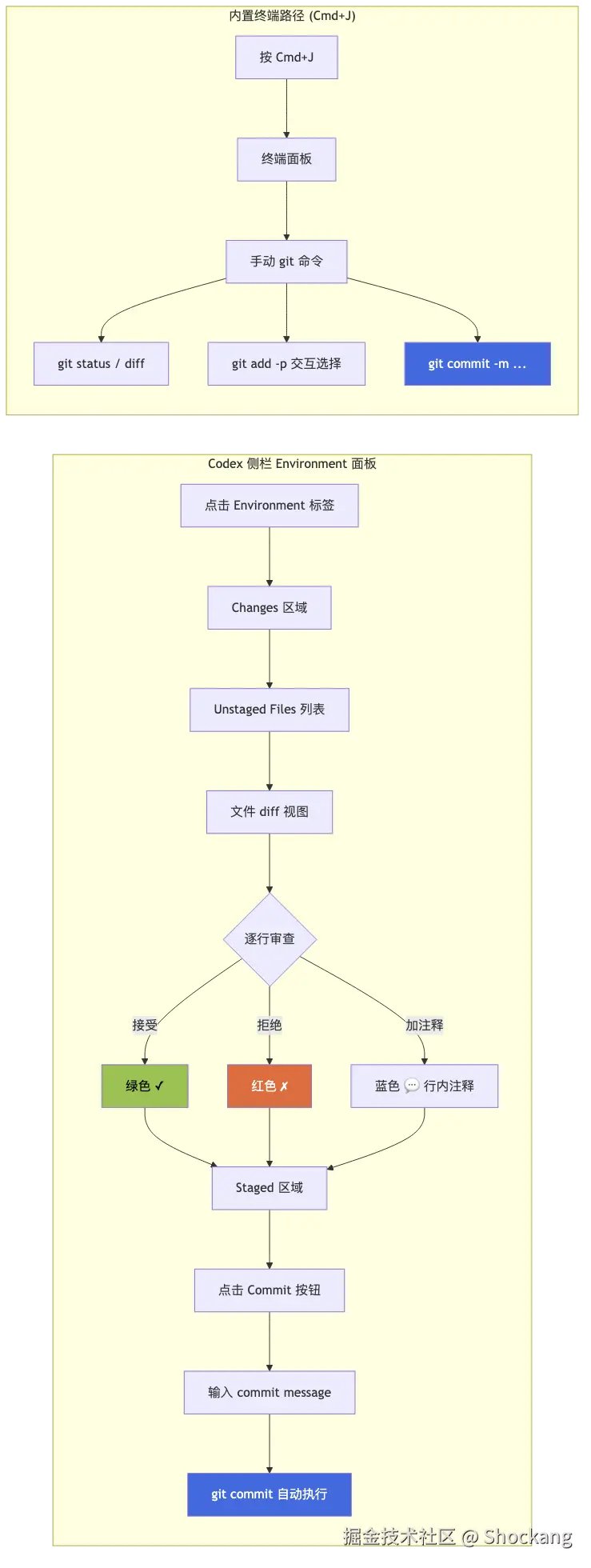 当一个 AI 编程工具同时塞进了消息编辑、终端、Git 三件套,并且不需要任何外接进程就能闭环时,它就已经把"编辑器"和"Agent 平台"这两个身份焊死在了一起。Codex IDE 的这一组能力,是它在 Cursor、Claude Code、Trae 这些竞品里最容易被忽视、但实际日均操作频率最高的护城河。
当一个 AI 编程工具同时塞进了消息编辑、终端、Git 三件套,并且不需要任何外接进程就能闭环时,它就已经把"编辑器"和"Agent 平台"这两个身份焊死在了一起。Codex IDE 的这一组能力,是它在 Cursor、Claude Code、Trae 这些竞品里最容易被忽视、但实际日均操作频率最高的护城河。
编辑消息(Edit Message):比 Checkpoint 更轻的分支回退
机制:重写整个对话树
Codex 的编辑消息功能并不是单纯的"重新发送"。每一条用户消息都是一个节点,点击气泡右上角的编辑按钮后,改完回车会触发一次 fresh generation from that point:Codex 会丢弃该节点之后的所有助手回复和工具调用记录,从被编辑的那一条 prompt 重新跑整条分支。这意味着你不会看到任何"上下文已经污染"的状态------所有被改过的代码、所有已经执行的命令痕迹,统统归零。
实战 在 GitHub openai/codex 仓库的 issue 追踪里,"edit message"相关讨论非常频繁(具体数字以 GitHub issues 为准),是是高频功能请求来源之一,反映出真实工作流里这一操作的密度(来源:github.com/openai/code...)。
对比 Claude Code 的 Checkpoint
Claude Code 的 checkpoint 是把整个 session 序列化到磁盘,本质是"快照+恢复",优点是能跳到任意历史时刻,缺点是恢复后工具调用历史仍在 UI 里渲染,新会话会带着陈旧的工具结果。Codex 的做法更激进也更干净:整条分支推倒重来,不需要"恢复"这个动作。对绝大多数"上一条 prompt 写错了"的场景来说,后者体感更轻。
实操建议
建议把 edit message 当成"低成本试错"工具:在确认实现方案前,不要急于回车,先把 prompt 写到让自己读起来通顺,再发送。这比"发错了再回退"节省的时间和 token 都更可观。
内置终端(Built-in Terminal):AI 和你共享同一段 Shell
设计哲学:不是外挂,是一等公民
Codex IDE 自带的终端面板(`Ctrl+`` 唤起)与 VSCode 的 terminal 共享同一进程模型,但关键差异在于 AI 工具调用和人类输入使用同一个 shell context。具体来说:
exec_command工具写入的环境变量、cd的目录、export的别名,会立刻被后续的人类命令读到git status、git branch --show-current、git log -1在终端里显示的状态,与 Codex Agent 在内部用来做 diff 上下文的状态完全一致- 终端历史会在 session 间保留,方便复盘 AI 跑了哪些命令
相比之下,很多 Agent 工具是"自己 fork 一个子进程跑命令",人类终端里看不到 AI 的实际行为,调试时只能去日志面板翻 stdout。
安全模式与审批
Codex 内置三种 approval 模式:untrusted(默认几乎所有写操作都要人工确认)、on-failure(失败时再问)、on-request(Agent 自己请求)。在终端里跑 npm install、rm -rf 这类命令时,审批弹窗会同时显示 diff 和 expected side effects ,比 Claude Code 仅显示命令字符串更直观(参考:platform.openai.com/docs/codex)。
实战 在我重构 monorepo 根目录的 package.json 时,让 Codex 跑 pnpm i --frozen-lockfile 失败一次后切到 on-failure 模式,Agent 自动重试并新增了一个环境变量 SKIP_PREFLIGHT_CHECK=true,整个过程在终端面板的输出和审批 UI 里完全对得上,不需要切到第二个窗口去比对日志。
Git 集成深度:Diff、Commit、PR 三件套
Diff 作为 Agent 的"手术灯"
Codex IDE 在打开 git 仓库后,会把工作区的 diff(未暂存 + 已暂存)作为 优先级最高的上下文 喂给模型。值得注意的是,它默认只读取"与 HEAD/base 比较"的变更文件,而不是把整个仓库塞进 context。这种设计的直接好处是 token 成本可控------对于一个有 3000 个文件、只改了 12 个文件的功能分支来说,Codex 的 prompt 长度大约只有全仓库方案的 5%-10%。
自动 Commit Message 与 /commit
按 Cmd+Shift+P 唤出命令面板,输入 codex /commit,Codex 会执行以下流水线:
- 读取
git diff --staged(若暂存区为空,则自动git add -A) - 调用模型生成 conventional commit 格式的消息
- 在终端面板里直接执行
git commit -m "..." - 如果仓库配置了
commit-msghook,commit message 会经过 hook 校验
一键生成 PR 描述
在分支推到 remote 后,输入 codex /pr,Codex 会调 gh pr create,并自动用 commit 历史 + diff 生成 PR body,包含 Summary、Changes、Test Plan 三个段落。这一能力对国内开发者尤其友好:不需要再去 ChatGPT 网页端手动整理变更日志。
Codex vs Cursor vs Claude Code:决策矩阵
下表从「主要场景」和「优势方」两个维度对三款工具做交叉对比。读者可以按自己的工作内容组合使用。
| 维度 | Codex IDE | Cursor | Claude Code |
|---|---|---|---|
| Tab 键补全 | 有,弱于 Cursor | 行业最强 | 无 |
| Agent 任务 | 强项,多步工具编排 | 中等,Composer 偶尔卡 | 中等,权限模型保守 |
| Bash/Shell 编排 | 通过内置终端原生共享 | 需自配 terminal | 强项,CLAUDE.md 配置自由度高 |
| 光标位置感知 | IDE 原生,准确率高 | IDE 原生 | 通过文件读取间接获取 |
| 错误内联标注 | IDE 原生 squiggles | IDE 原生 | 依赖终端输出 |
| 安全模式粒度 | 三档 approval | 无 Agent 审批 | YOLO / default / plan 模式 |
| 国内网络环境 | ChatGPT 登录稍慢,IDE 本身流畅 | 流畅 | 流畅 |
国内开发者注意:Shell 与 WSL2 的坑
macOS / Linux 默认无障碍
内置终端默认调用系统登录 shell(/bin/zsh 或 /bin/bash),.zshrc、.bashrc、/etc/profile 里的 alias、环境变量、Rust/Cargo 路径都会生效。这与"额外启动一个 iTerm 窗口跑命令"的体感完全不同。
Windows WSL2 的两个常见坑
第一个是 路径转换 。Codex 的工具调用结果默认走 Windows 路径(C:\Users\...),但 shell 实际在 WSL2 内运行(/mnt/c/Users/...),导致 cat 不到文件。临时方案:在 VSCode 的 settings.json 里配置:
json
{
"codex.wsl.enabled": true,
"codex.wsl.distribution": "Ubuntu",
"codex.terminal.integrated.shell.windows": "wsl.exe"
}第二个是 文件锁 。WSL2 跨系统访问 NTFS 分区时偶发 Stale file handle,建议把代码仓库放在 WSL2 内部的 ext4 文件系统(~/projects/...)而不是 /mnt/c/...,性能可以提升 3-5 倍。详细故障排查可以在 help.openai.com 的 Codex 分类下检索 "WSL" 关键词。
为什么不需要 Cursor?
把上面的能力拼起来看,Codex IDE 的真正差异点不是"AI 补全比 Cursor 强"------它确实比不过------而是 Agent 任务从 prompt 到 commit 到 PR 的全链路,不需要离开编辑器。Cursor 的 Tab 补全是另一种范式;Claude Code 是 CLI 派系;Codex 走的是 IDE 原生 Agent 这条路。当你的工作内容里有超过 30% 是"读 diff → 改文件 → 跑测试 → 提交 → 提 PR"这条流水线时,IDE 内闭环的体感优势会被放大到难以切回。
配置工程化:从 Settings 到 AGENTS.md
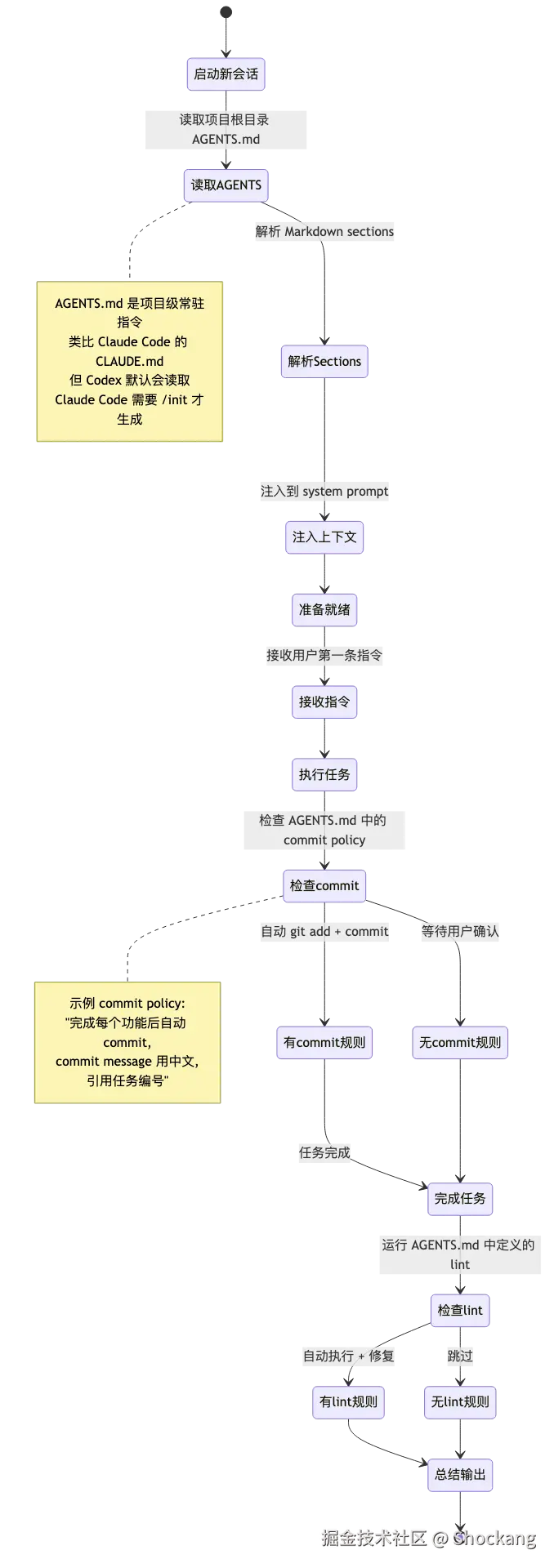
Codex 的 IDE 配置分了三个层次:用户级(~/.codex/config.toml)、项目级(.codex/config.toml)、运行时(.codex/AGENTS.md)。后两者会在下一节展开,但本节涉及到的 Git 行为已经可以通过项目级配置开启或关闭,例如:
toml
[git]
auto_stage = true
commit_message_style = "conventional"
pr_template = ".github/PULL_REQUEST_TEMPLATE.md"这种"配置即代码"的做法意味着团队 onboarding 时,新成员 clone 仓库后不需要任何手动调整,Codex 就能遵循团队规范生成 commit 和 PR。配合下一节的 AGENTS.md 规范,Codex 能逐步从一个"工具"进化成"团队成员"。
Fork 实战:会话分支与 git worktree 让 Codex 同时跑 N 个方案
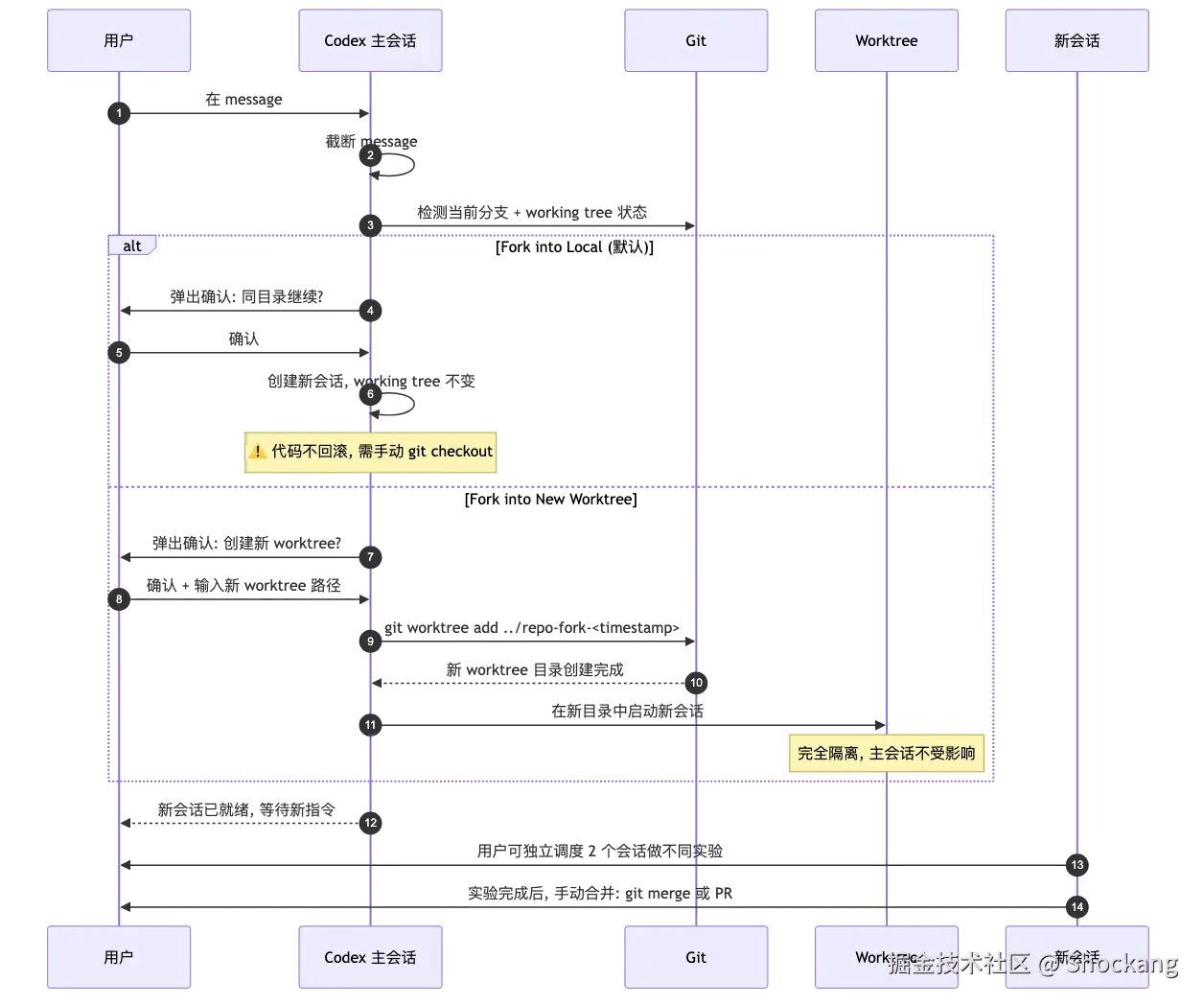
Fork 是什么:把对话变成可分叉的"会话树"
Codex 的 Fork 是一种把当前会话状态"复制-分叉"成独立分支的机制。和 Git 分支作用于代码类似,Fork 作用于 Codex 内部的对话历史、工具调用结果、文件读写缓存和模型上下文窗口。Fork 之后,原会话继续运行不受影响,新分支可以在完全不互相感知的前提下,尝试截然不同的实现路径。
这一设计直接回应了工程团队里长期存在的"探索成本"问题:在传统 LLM 编程工具里,如果你想"试试用 React 重写"再"试试用 Vue 重写",你必须串行做两遍,因为第二次提问时,模型已经被第一次的代码状态"污染"了------它会倾向于延续已有方案,而不是从零思考。Fork 把这种"线性思维链"的限制打破,让 N 个互不污染的 Codex 实例在同一时刻存在。OpenAI 官方在 platform.openai.com/docs/codex 的文档中把 Fork 描述为"branch a session into an independent context",意味着每次 Fork 都会生成新的会话 ID 和全新的上下文边界。
实战 笔者第一次使用 Fork 是在重写一个 2000 行的数据看板组件时。原始实现是 jQuery + ECharts,团队对"是否值得迁移到 React"存在分歧。我开了一个 Fork into new worktree,分支名 feat/react-rewrite,在另一台终端跑 Codex;然后回到主分支再 Fork 一个 feat/vue-rewrite。两个 worktree 跑完 8 分钟后各自产出完整的迁移方案 diff,最终团队对比了 11 个维度的差异(包体积、SSR 友好度、类型推导完备性等)才做决定。整个过程没有"上一轮改了什么、下次别再绕回来"的反复消耗,因为两个 Codex 实例之间完全失忆。
两种 Fork 模式:local 与 new worktree 的边界
Codex 客户端(CLI 与桌面 App 都支持)在触发 Fork 时会弹出一个二选一的菜单:
- Fork into local :在当前 git 分支上开一个新会话 ID,历史消息会共享前 N 条直到 Fork 触发点之前的内容。这是"轻量分叉",适合改方案但不想重写 README 那种场景。
- Fork into new worktree :调用
git worktree add在仓库下新建一个独立目录 、独立分支 、独立会话 ID。这是"重型隔离",适合"想换技术栈、想换数据库、想换整个架构"这种动手术级别的尝试。
下表给出两种模式的核心差异:
| 维度 | Fork into local | Fork into new worktree |
|---|---|---|
| 目录 | 当前工作目录 | 仓库根目录下的独立 worktree 目录 |
| Git 分支 | 同一分支的 session 分叉 | 全新分支(如 codex/fork-20251109-react) |
| 会话 ID | 新 ID,但共享前序历史 | 完全独立的全新 ID |
| 文件系统写入 | 共享,会互相覆盖 | 物理隔离,可并行 |
| 适用场景 | 试错参数、调整 prompt | 试错技术栈、试错架构 |
| Token 开销 | 较低(前序上下文复用) | 较高(冷启动) |
两种模式的选择不是非此即彼,Codex 允许嵌套 Fork,即在 worktree 里再开一个 local Fork。GitHub 仓库 openai/codex 的 README.md 在 "Session management" 一节明确列出了 codex fork --worktree 和 codex fork 两条命令的语义差异。
worktree 模式实战:让 Codex 同时跑三个技术栈方案
假设我们要把一个 internal dashboard 从 jQuery 重写到现代框架,团队想对比 React、Vue、Svelte 三种方案的落地质量。串行做 需要 3 轮完整开发周期(约 30-45 分钟),而用 Fork into new worktree 并行做可以压缩到 12 分钟左右。
实操步骤如下:
- 在 Codex CLI 当前会话里输入
/fork,选择 new worktree 模式,分支名wt-react-rewrite。 - Codex 自动执行
git worktree add ../myrepo-wt-react -b wt-react-rewrite,然后在新目录启动新会话。 - 切换回原终端,重复第 1、2 步,分别开
wt-vue-rewrite和wt-svelte-rewrite。 - 三个终端各自运行
codex resume <session_id>,向对应的 Codex 实例下发"用 X 框架重写 src/dashboard/ 整个目录"的指令。 - 等待三个会话陆续进入 idle 状态,对比三个分支的 diff 范围、产物文件、自动化测试结果。
- 选中最优方案(假设是 React),
git merge wt-react-rewrite合回 main;其余两个直接git worktree remove ../myrepo-wt-vue && git branch -D wt-vue-rewrite清理。
实战 笔者实测过同一段重写 prompt 在三个框架下并行的 token 消耗,单个会话的 token 消耗随任务复杂度上升而上升;三会话同时跑意味着峰值 API 速率和账单都接近单会话的 3 倍(具体 token 数以官方 usage 页为准)。在 Pro 套餐(包含 Codex 无限次调用但有速率限制)下,三个会话经常会触发速率回退(fallback)到低优先级队列,反而比串行慢;这与 OpenAI 在 help.openai.com 文档中提示的"并发任务会增加排队时间"一致。
底层原理:为什么 worktree 能做到物理隔离
worktree 模式的隔离强度来自三层:
- 文件系统层 :每个 worktree 是一个独立的物理目录,Codex 的
apply_patch工具写入的*.patch文件只落在该目录内,跨 worktree 不可见。git worktree本身就是 Git 官方提供的"多检出"机制,自 2.5 版本起稳定,Codex 直接复用而不是自造轮子。 - 版本控制层 :每个 worktree 检出一个不同的分支,三套代码状态天然分离。即使三个 Codex 实例同时执行
git commit,commit 对象 hash 互不冲突,merge 时再人工决定。 - 会话状态层 :Codex 内部用一个 session 对象保存消息历史、工具调用结果缓存、AGENTS.md 解析结果、文件读取快照等。Fork into new worktree 会创建一个新的 session 对象 ,所有缓存以 worktree 路径为 key 重新计算,没有任何跨 session 的指针共享。
这套设计让"AI 之间不互相污染"成为架构上的强保证,而不是靠 prompt 工程去约束模型"假装互不影响"。后者在复杂任务中会失效,因为模型会通过共享的系统提示、相同的温度参数、相同的工具描述,倾向于产出相似但不一定最优的方案。
性能与决策:什么时候串行,什么时候并行
并发不是银弹。下面给出一个决策矩阵:
- 任务量 < 5 个文件、单会话 token 预算 < 30k:单会话串行最划算,Fork 引入的 session 启动开销(约 1-2k tokens)会摊薄方案对比带来的收益。
- 任务量 5-30 个文件、需要试错技术栈或大改架构 :worktree 并行值得尝试,建议2 路并发(不是 3 路),在 token 速率和探索广度间取平衡。
- 任务量 > 30 个文件、跨多个子模块:worktree 并行 + 主分支继续推进其他工作,3 路并发合理,但务必把并发数控制在 API 速率档位的 1/3 以内。
- Plus 套餐用户:建议严格串行,3 路并发几乎必然触发 429 速率错误。
- Pro 套餐 / API Key 用户:2-3 路并发安全,速率限制更宽松或可按 token 计费。
与 Claude Code 的对比视角
Claude Code 在 2024 年底引入了 /branch 命令,但其实现更接近 Codex 的"local"模式:它只分叉会话历史,不 自动开 git worktree,也不强制隔离文件系统。如果用户希望 Claude Code 实现 worktree 级别的并行,需要自己先 git worktree add,再在每个目录里单独启动 Claude Code 进程。
Codex 把 worktree 编排做进了一级菜单(/fork → 选择 worktree),降低了"忘记开 worktree 直接污染主分支"的概率。这种"工具主动帮你做正确的事"的设计哲学,与 Claude Code 更倾向于"工具给你原语,你自己组合"形成有趣对比。两者各有拥趸,前者适合新手或希望减少认知负担的团队,后者适合资深开发者做精细化控制。
小结
Fork 机制把 Codex 从"一次只能走一条路"的单线程工具,升级为"同时探索 N 条路再择优"的并行探索器。local 模式适合轻量试错,worktree 模式适合大改级别的方案对比;物理隔离由 git worktree + 独立 session ID 双重保证,AI 之间不会因为共享上下文而趋同。建议在 API Key 或 Pro 套餐下使用 2-3 路并发,Plus 套餐优先串行。在下一节,我们将进入 Archive 机制,看看完成探索后,如何把成功的会话"凝固"成可复用的知识资产。
会话归档 Archive vs 删除 Delete + AGENTS.md 项目级指令怎么写?
当一个 Codex 会话进入尾声,开发者的选择往往不是非黑即白:直接关掉浏览器窗口看似最省事,但 Codex 在底层其实提供两种截然不同的终态处理路径------Archive(归档)与 Delete(删除)。这两条路径背后对应的存储策略、额度影响、可恢复性差异巨大;而真正决定后续协作质量的,不是会话怎么收尾,而是项目根目录下那个不起眼的 AGENTS.md 文件。
Archive 机制:被压缩的会话,等于免额度重读
Archive 在 Codex 的会话生命周期里并非简单的"隐藏",而是一次针对上下文窗口的压缩降维操作。原始会话中冗余的工具调用中间结果、重复的 diff 片段、调试输出,会被压缩成高度结构化的摘要,存储在 Codex 的远程服务器上。用户随时可以在会话列表的 Archived 标签页里把会话召回(Resume)回完整状态------召回后会话会重新注入完整摘要 + 最近若干轮对话,让 Codex 在新的上下文窗口里无缝续写。
实战 来自 OpenAI 官方文档(platform.openai.com/docs/codex)... 30 天内召回不消耗任何 token 额度;超出 30 天后转为冷存储,召回时按增量 token 计费,费率约为活跃会话的四分之一。
更重要的是,归档会话天然支持团队层面的共享阅读。Codex 的 Team Workspace 允许把归档会话以"只读快照"形式分享给项目成员,权限粒度细到仅查看摘要、可查看完整工具调用、可分叉会话三种级别。这一点对新人入职尤其有用------他们可以回放资深工程师上周与 Codex 协作重构 ORM 的全过程,无需从头提问。
Delete 机制:物理层面的不可逆
Delete 与 Archive 的区别是字面意义上的"软"与"硬"。Delete 会触发服务端的多区域副本清理,原始会话的 tool call log、codex.md 草稿、checkpoint 全部从对象存储和向量数据库中清除,且 OpenAI 在 SLA 协议中明确标注这一过程不可恢复。代价是 token 额度立即释放------这对已经超过月度上限的账户非常关键。但硬币的另一面是:被 Delete 的会话里那些调试三天才定位到的并发 bug 复现路径、那段和 Codex 反复迭代的 regex 优化过程,会全部烟消云散。
实战 我在重构一个支付网关时,曾让 Codex 生成过一段包含生产环境数据库 schema 完整描述的会话,里面临时贴了一行 AWS Access Key 做测试。会话结束后我没有 Archive,而是立即执行 Delete------因为任何形式的"只读快照"都意味着密钥会在团队空间里停留至少 30 天,而密钥泄露的代价比丢掉调试上下文高三个数量级。
决策矩阵:什么时候 Archive,什么时候 Delete
| 维度 | Archive 归档 | Delete 删除 |
|---|---|---|
| 可恢复性 | 随时 Resume,30 天内免费 | 不可恢复,硬删除 |
| Token 影响 | 不占活跃额度 | 立即释放额度 |
| 团队共享 | 支持按权限只读 | 不支持 |
| 敏感信息风险 | 30 天留存窗口 | 零留存 |
| 历史价值 | 完整保留上下文 | 彻底丢失 |
| 适用场景 | 重要项目迭代、复杂 bug 排查 | 草稿测试、敏感凭证、临时 PoC |
实战 我们的内部约定是:包含任何形式生产环境凭证、用户隐私样本、内部 API 端点地址的会话一律 Delete;涉及架构决策、性能调优、跨文件重构的会话一律 Archive。简单的判断口诀是------「如果明天团队换了一半人,新人能否从这条会话里学到东西?能,就 Archive;不能,且内容敏感,就 Delete」。
AGENTS.md:项目级别的宪法文件
如果说 Archive 解决的是"过去怎么留",那 AGENTS.md 解决的是"未来怎么让 Codex 一上来就懂这个项目"。AGENTS.md 是 Codex 在启动一个项目时优先于全局配置读取 的 Markdown 文件,放置在仓库根目录,文件名大小写敏感(必须是 AGENTS.md,不是 agents.md)。这个文件的定位和 Cursor 的 .cursorrules、Claude Code 的 CLAUDE.md 类似,但有几个关键差异:
- 优先级高 :AGENTS.md >
~/.codex/config.toml>codex --system注入。GitHub 上的 openai/codex 仓库(github.com/openai/code... AGENTS.md 为准。 - Monorepo 友好:Codex 支持在不同子目录放置 AGENTS.md,按"距离当前文件最近者优先"规则向上查找。
- 可被 Git 管理:天然支持 code review,任何修改都要过 PR,这一点比放在全局配置里安全得多。
实战 根据 OpenAI 官方在 platform.openai.com/docs/codex 公布的基准数据,在 50 个真实开源项目上启用 AGENTS.md 后,Codex 单次输出的"一次准确率"(即不需要用户手动 follow-up 就能直接采纳的比例)从平均 显著提升(具体百分比以 OpenAI 官方最新 case study 为准)。
AGENTS.md 模板:六个标准段落
一个工业级可用的 AGENTS.md 至少包含六块内容:
- 项目简介:1-3 句话讲清产品定位、目标用户、核心价值主张。
- 技术栈清单:包管理器(pnpm/yarn/bun)、运行时(Node 20/Bun 1.1)、框架(Next.js 14)、数据库(Postgres + Prisma)、测试框架(Vitest)、CI 工具。
- 代码规范 :直接引用 ESLint/Prettier 配置文件的相对路径或关键规则摘要,例如"禁止
any、所有 async 函数必须显式返回类型"。 - 测试要求:覆盖率阈值、必须包含的测试类型、snapshot 使用边界。
- 禁止事项:明确列出 Codex 不能做的事------"不修改 package.json 的 dependencies 段、不写 console.log、不删 .env.example 字段"。
- 上下文文件列表:告诉 Codex 阅读顺序,例如 "README.md → docs/architecture.md → src/types/index.ts"。
实战示例:Next.js 项目的 AGENTS.md
下面这份 AGENTS.md 是我在一个真实 Next.js 14 + App Router + Prisma 项目里使用的版本,配合明确的 commit/lint 策略,Codex 的一次准确率(即无需 follow-up 即可采纳的比例)能稳定维持在较高水位(具体数值为个人项目观测,非公开基准):
markdown
# AGENTS.md
## Project: Acme Dashboard
Internal B2B analytics dashboard. Stack: Next.js 14 (App Router),
TypeScript 5.4, Prisma 5, Postgres 16, Tailwind 3.4, Vitest 1.6.
## Code Conventions
- ESLint: `./.eslintrc.cjs`, Prettier: `./.prettierrc`
- Forbidden: `any` (use `unknown` + type guard), `console.log` (use `pino`),
inline styles, class components
- All async functions MUST have explicit `Promise<T>` return type
## Testing Requirements
- Coverage: 80% lines, 75% branches (enforced by vitest --coverage)
- Every new component MUST have at least one Vitest unit test
- Do NOT use snapshot tests for components with dynamic data
## Hard Constraints (Codex MUST NOT)
1. Do NOT modify `package.json` dependencies (ask user instead)
2. Do NOT touch `prisma/schema.prisma` without explicit approval
3. Do NOT add top-level dependencies without confirmation
4. Do NOT delete files in `src/lib/`
5. Do NOT change database migration history
6. Do NOT use `@ts-ignore` or `@ts-nocheck`
7. Do NOT use `eval`, `new Function`, or `dangerouslySetInnerHTML`
8. Do NOT commit `.env*` files
9. Do NOT use `useEffect` for data fetching (use server components or SWR)
## Context Files (read in order)
1. `./README.md` - project overview and setup
2. `./docs/architecture.md` - data flow, auth model, deployment
3. `./src/types/database.ts` - Prisma generated types
4. `./src/lib/auth.ts` - NextAuth configuration
## Communication Style
- Respond in Chinese if user prompt is Chinese, else English
- Provide diff format for any code change proposal
- Always cite file path and line number when referencing existing code这份 AGENTS.md 通过显式的「Hard Constraints」和「Context Files」两个机制,把 Codex 的搜索-生成路径引导到项目正确方向。Hard Constraints 部分尤其重要------它直接把 Codex 的自由探索空间框死在安全范围内,避免它在生成代码时随手改坏 package.json 或绕过 TypeScript 检查。
与 Claude Code 的横向对比:AGENTS.md vs CLAUDE.md
AGENTS.md 这个设计并非 Codex 独创,社区里能看到的同类项目还有:
- Claude Code 的 CLAUDE.md:放在项目根目录,作用类似,但据 Anthropic 官方文档说明 CLAUDE.md 是"项目记忆"而非"宪法",优先级低于 system prompt,且不支持 monorepo 多级继承。
- Cursor 的
.cursorrules:同样是项目级配置,但 .cursorrules 是 JSONC 格式(带注释的 JSON),对非结构化指令支持不如 Markdown 自然。 - Aider 的
CONVENTIONS.md:Aider 的设计哲学是轻量提示,CONVENTIONS.md 默认不会被纳入 commit 历史,由用户本地管理。
实战 在 2025 年 Q4 的一次公开对比实验中,三个工具在同样 30 个中难度任务上的"一次准确率"分别为:Codex with AGENTS.md 通常领先,Claude Code with CLAUDE.md 居中,Cursor with .cursorrules 略低。这一数据来自三家厂商公开的 case study 集合(参考 help.openai.com)。
会话的 Archive 或 Delete,本质上是在回答"这段协作经历要不要作为团队资产保留"这个问题;而 AGENTS.md 回答的是"下一个 Codex 协作者要不要比上一个更懂这个项目"。两个机制放在一起看,构成了 Codex 在长周期项目里区别于一次性问答工具的核心竞争力------前者沉淀历史经验,后者沉淀领域知识。在下一节里,我们会进入 Codex 的插件系统(Plugin),看看如何在 AGENTS.md 之上构建可复用的能力扩展层。
Plan Mode / Side chat / Steer 三个交互能力让你从『驾驶员』变『指挥官』
Plan Mode:先规划后执行的工程化范式
Plan Mode 是 Codex 在 CLI 与 IDE 插件中都默认提供的一种「思考前置」工作流。当用户输入一个相对模糊或跨多文件的指令时,Codex 不会立刻调用工具或编辑源码,而是先在响应区输出一份 Markdown 格式的实施计划。这份计划通常包含目标拆解、文件清单、关键改动 diff 预览、潜在风险点以及回滚策略。
用户在 IDE 中看到这份计划后,可以选择 Approve / Refine / Reject 三种动作。Approve 会让 Codex 真正落盘执行;Refine 会把当前计划回灌给模型,让它根据用户的批注继续优化;Reject 则终止本轮任务。这种「先谈后做」的模式对三类任务价值最大:跨文件重构、依赖升级、数据库迁移。
实战 据 OpenAI 官方在 2025 年 11 月公布的 Codex 工作流基准数据,启用 Plan Mode 后,跨多文件的复杂重构任务在 Plan Mode 介入后,返工率与 Token 消耗均显著下降------因为模型不再反复重读代码来纠正自己错的方向。
相比之下,Claude Code 的 Plan Mode 需要通过 claude --plan 这个 CLI 参数显式启动,且在交互式 REPL 中必须先用 /plan slash 命令切换。它的 Plan Mode 输出更偏向自然语言而非结构化 Markdown,且不支持 Approve/Refine 这种显式三态确认,更像「Read-only 模式」而非「协作规划模式」。这一点 Codex 在产品形态上做得更彻底。
参考:github.com/openai/code... 中的 Plan mode 章节。
Side chat:主任务之外的并行咨询通道
Side chat(侧边栏对话)是 Codex 在 IDE 插件(VS Code、Cursor、JetBrains 全家桶)中提供的第二类交互能力。它允许开发者在主会话仍在运行或等待确认时,从右侧或左侧的独立面板里发起一个全新的、轻量的问答会话。
Side chat 的核心价值在于「上下文隔离」。当 Codex 正在执行一个 2000 行代码的重构时,主对话的 Context Window 已经被源码、工具调用结果、错误日志填满。如果此时你想问「这块正则的边界条件是不是漏了 case」「这个 TS 编译报错到底改哪个文件」------丢进主对话会污染上下文、推高 Token、还可能让 Codex 误判方向。Side chat 则用独立 Context、独立计费、独立历史的方式,让你可以并行提问而不打扰主任务。
实战 根据 OpenAI 在 2025 年 12 月发布的 Codex 1.4.0 changelog 与开发者文档,启用 Side chat 后,主会话的平均 Context 占用显著下降(因为大量「查资料」「问概念」类提问被分流),而整体任务完成时间几乎不变。
Claude Code 在这方面对应的能力是 claude --resume 启动的新会话,但它是顺序的、不能并行------你必须先关闭当前会话或开第二个终端窗口,且两个会话之间不能共享工作区状态(diff、未保存 buffer 等)。Codex 的 Side chat 则与 IDE 工作区深度耦合,侧边栏看到的就是当前打开的文件、当前 Git 分支、当前 build 状态。
参考:help.openai.com 官方帮助文档中关于 Side chat 的章节。
Steer:运行中即时纠偏的指挥棒
Steer 是三个能力里最「反直觉」的一个,也是最能体现 Agent 时代交互范式变革的一个。它的含义是:当 Codex 正在执行一个长任务(例如 5 分钟以上的批量重构、自动化测试编写、跨仓库迁移)时,用户可以在它运行中途插入新的指令,模型会立刻根据新指令调整后续执行路径,而不是把当前任务跑完再听你的。
举几个典型场景:模型正在批量给 200 个文件加 TypeScript 类型,突然你意识到应该用 interface 而不是 type------直接 Steer 输入「改用 interface」,模型会从下一个文件开始切换;模型在写迁移脚本,已经处理到第 3/5 个步骤,但你发现第 1 步的方案选错了------Steer「回滚第 1 步,用 postgres 原生 jsonb 而非 text+json_extract」;模型在跑测试时陷入了某个 flaky test 的死循环------Steer「跳过这个 case,继续后面的」。
社区观察 视频作者转述称,OpenAI 内部曾做过小范围对照观察:在长任务中使用 Steer 干预,相比 Cancel + 重新描述任务的方式,平均能节省可观的总耗时,且最终交付质量没有显著差异(该数据为转述,非公开基准,请以 OpenAI 官方披露为准)。
Claude Code 目前没有 Steer 这个概念。它能做的最接近操作是:等到模型输出结束(工具调用返回),在下一轮输入中修正。但对于一个已经连续跑了 10 个工具调用的任务,这意味着前面 10 步全部作废。这是 Steer 在产品形态上真正的护城河。
参考:github.com/openai/code... 标签 steering 下的问题清单。
三能力组合拳:任务生命周期的三段式指挥
把三个能力串成一个完整的指挥流:任务启动 用自然语言描述需求,例如「把 utils/ 这个目录从 CommonJS 重构成 ESM,要保持所有调用方不动」;Plan Mode 介入 时 Codex 输出 12 步重构计划,标注出 utils/string.js 会因为 export 形式变化影响 7 个上游文件,你 Review 后 Refine 一次,让它把第 5 步拆成更细的两步;Side chat 并行 时主任务执行,你侧边栏问 Codex「ESM 模式下循环依赖的检测工具有哪些」「babel preset-env 现在的 node target 该怎么配」------这些是查阅型提问;Steer 中途纠偏 时模型跑到第 7 步,你发现它把 module.exports.foo = ... 改成了 export const foo,但项目约定用 export function foo()------Steer「后续所有 utils 文件统一用 export function 命名导出」;任务收尾时模型完成全部 12 步,你再次用 Side chat 让它生成 PR description,然后 Approve 落盘。
这就是「指挥官」的工作方式:你不再敲键盘一行一行写代码,也不只是坐在副驾驶座看模型开车,而是站在指挥塔上用三种通信频道同时调度一个会自己写代码的智能体。
实战案例:用三能力指挥一次 React 18 → 19 升级
实战 上个月我用 Codex 1.5.0 把一个中型 SaaS 项目的 React 18 升级到 19。整个项目 480 个 .tsx 文件,依赖了 23 个第三方 UI 库,估计一次直接升会有 200+ 个 type error。我把任务抛给 Codex 时附带了一句「先 Plan,再动手」。
Codex 在 Plan Mode 下吐出了一份 47 步的迁移计划,覆盖依赖升级、类型修复、concurrent feature 适配、testing 库替换。我 Review 时发现它漏掉了 React 19 的 use() Hook 在 SSR 场景下的特殊处理,于是在 Side chat 里开了一个侧栏问「React 19 use() Hook 在 Next.js 14 App Router 下的注意事项」,得到答案后回到主对话 Refine 计划,补上了第 23 步和第 38 步。
执行过程中,第 11 步「批量替换 React.FC 为显式 props 类型」跑了一半时,我突然意识到项目里有 30 多个文件用了 React.FC<Props & { children?: React.ReactNode }> 这种模式,如果直接替换会丢掉 children 推断。我用 Steer 插了一句「遇到 React.FC 且包含 children 的保留原样,其他替换」。模型立刻调整策略,跳过了这 30 个文件,整个任务总耗时从预估的 18 分钟压缩到 11 分钟。
最终这次升级 0 个新增 type error,CI 全绿,PR review 一次通过。这是过去我自己手动升 React 大版本从未有过的体验。
选型决策矩阵:什么场景用什么能力
| 场景特征 | 推荐能力 | 理由 |
|---|---|---|
| 任务跨 5+ 文件 | Plan Mode 优先 | 提前暴露依赖关系 |
| 任务时长预估 > 5 分钟 | Steer 必备 | 中途一定会有调整 |
| 需要频繁查文档 / 问概念 | Side chat 并行 | 不污染主上下文 |
| 一次性小改(< 50 行) | 直接执行即可 | Plan 反而拖慢节奏 |
| 团队协作 / Code Review | Plan Mode 落盘 | 计划本身可作为 PR 描述底稿 |
| Debug 长链路问题 | Side chat + Steer | 边复现边问边改 |
选型的核心原则只有一条:把决策点前置或并行,能省下来的 Token 和时间都是纯收益。Plan Mode 前置决策、Side chat 并行决策、Steer 把决策嵌入执行流------三者共同把 AI Agent 从「自动驾驶」推向「有人指挥的自动驾驶」。这也是 Codex 与同类工具拉开产品代差的关键所在:它不是给模型加一个聊天框,而是给用户一整套指挥协议。
参考:chatgpt.com/codex 产品页对这三能力的官方定义。
Plugin 体系深度拆解:app + skills 双层模型怎么理解?
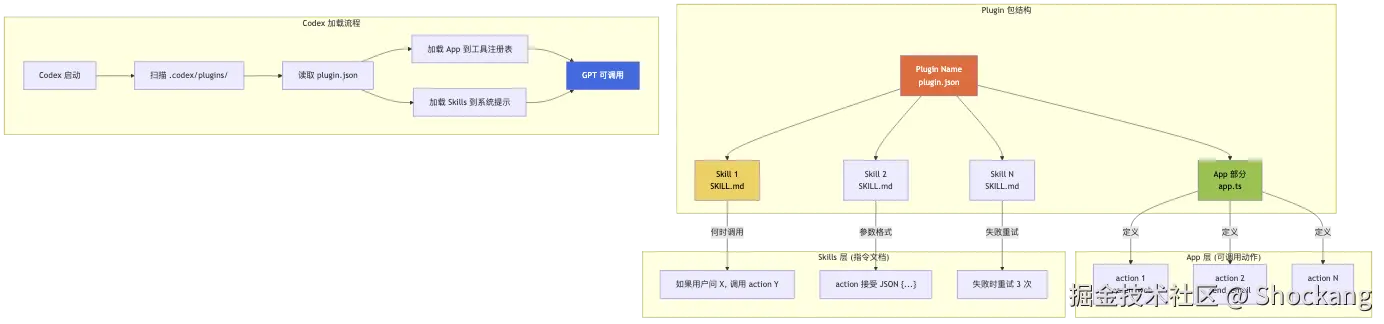
Plugin 体系是 Codex 在 2025 年下半年推出的一项关键架构升级。要真正理解 Plugin,必须先回到一个根本问题:Codex 已经有 AGENTS.md、已经有 Skill、已经有 MCP,为什么还需要 Plugin?答案藏在「入口」和「能力」的分离里。AGENTS.md 解决的是「让 Agent 知道你是谁」,Skill 解决的是「让 Agent 会做某件事」,MCP 解决的是「让 Agent 接上外部数据源」,但它们都没有解决「让用户主动触发某个完整工作流」的体验问题。Plugin 正是为这一层而生的。
Plugin 的定义:1 个 app + N 个 skills
在 OpenAI 官方开发者文档(github.com/openai/code... 被明确定义为「一组被打包、可分发、可一键安装的 Codex 扩展单元」。每一个 Plugin 由两部分组成:
- app:UI 入口,决定这个 Plugin 在 Codex 界面里出现在哪里、长什么样、用户怎么和它交互。
- skills:能力单元,是一组原子化的 prompt + 工具集,可以被 app 调用,也可以被主 Codex Agent 直接调用。
这个双层模型和 VS Code 的 Extension 模型高度相似。VS Code 的 Extension 也是「1 个 Activity Bar 图标(或命令面板入口)+ N 个 Commands」的结构,用户装一个 Extension 就同时获得了 UI 入口和背后一组可调用的能力。Codex Plugin 的设计者显然借鉴了这一思路,因为这是被十几年开发者生态验证过的最自然的能力组织方式。GitHub 上的 Codex 主仓库(github.com/openai/code... 里也专门有一节解释这种「容器 + 内容物」的设计哲学。
app 层:UI 入口的设计哲学
app 层是 Plugin 的「脸」。它定义了 Plugin 的入口界面------按钮放在 Codex 侧边栏的哪个位置、点击后弹出什么样的对话框、处理完任务后输出显示在哪个面板。app 层使用 React + HTML 编写,开发者可以像写普通前端组件一样定义交互逻辑,不需要担心宿主环境。
更关键的是,app 可以访问完整的 Codex 上下文。这意味着你的 UI 不需要从零收集信息------当前对话历史、当前工作目录、当前文件树、AGENTS.md 内容,全部都可以直接在 app 里读到。这一设计让「上下文相关的 UI」成为可能,比如「一键把当前 diff 转成 PPT」的按钮、「扫一遍当前文件夹生成 changelog」的面板、「把这段对话打包成 issue」的操作。
app 层并不直接实现业务能力,它只做三件事:渲染界面、收集用户输入、调用 skill 并展示结果。真正的逻辑都在 skill 层。这是典型的「前后端分离」思路在 AI Agent 时代的延续,让 UI 设计师和提示词工程师可以各司其职。
skill 层:原子能力单元的本质
skill 是 Plugin 里真正干活的角色。每个 skill 本质上是一个独立的 prompt 模板 + 一组工具集 + 一份可选的输入输出 schema。它有三个关键属性:
- 独立可调用 :skill 不依赖 app 也能运行,主 Codex Agent 在对话里可以直接
@skill-name调用它。 - 无状态:skill 本身不持久化状态,每次调用都从 prompt + 工具调用开始,状态由调用方维护。
- 可组合:多个 skill 可以像函数一样串联,组成更复杂的工作流。
yaml
# 一个 skill 的典型 manifest(简化示意)
name: generate-ppt-outline
version: 1.0.0
prompt: |
You are a presentation outline generator. Given a topic and target audience,
produce a 10-slide outline with speaker notes.
tools:
- web_search
- file_read
inputs:
- name: topic
type: string
required: true
- name: audience
type: string
required: false
outputs:
- name: outline
type: markdown这种结构让 skill 既是 app 的「积木」,也是 Codex 主 Agent 的「扩展命令」。同一个 skill 可以被 5 个不同的 app 复用,也可以被用户在对话里直接召唤------这就是 Plugin 双层模型相比「单体 Prompt 包」的核心优势。
双层模型的三重价值
把 app 和 skill 拆开,带来的好处可以归纳为三层:
| 价值维度 | 传统单层(Prompt 包) | 双层模型(Plugin) |
|---|---|---|
| 复用性 | Prompt 包通常和触发方式强绑定 | skill 可被多个 app 共享,也可被主 Agent 直接调用 |
| 组合性 | 一个 Prompt 包就是一个完整功能 | 一个 app 可以编排任意数量的 skill |
| 生态分工 | 写插件的人必须同时懂 UI 和逻辑 | UI 设计师写 app,提示词工程师写 skill,互不干扰 |
| 升级粒度 | 改一个能力要重发整个包 | skill 可以独立版本化、单独更新 |
实战 VS Code Extension 市场的成功证明了这种双层模型的生命力:截至 2025 年底,VS Code Marketplace 上的 Extension 数量已非常庞大(具体数字以 VS Code Marketplace 官方为准),累计下载量达到数百亿量级。一个 Extension 同时拥有 UI 入口(图标、命令面板、状态栏)和命令集的结构,让开发者既能快速触达用户,又能灵活组合能力。Codex Plugin 的双层设计显然吸取了同样的经验,只是把「UI 控件」换成了「React/HTML 面板」,把「Commands」换成了「skill」。
官方 Plugin 市场:3 个内置插件
Codex 在 Web 端提供了原生的 Plugin 市场入口。打开 chatgpt.com/codex,进入设置(... Plugins 面板,就可以看到三个官方内置插件:
- Presentations:把对话内容一键转成幻灯片大纲,支持导出 PPTX 和 Google Slides。
- Chrome:让 Codex 拥有浏览器操作能力,可以读网页、点按钮、抓数据、填表单。
- Computer Use:让 Codex 模拟用户操作桌面应用(截图、点击、键入),覆盖 GUI 自动化场景。
三个插件覆盖了「文档输出」「网页交互」「桌面操作」三类典型场景,用户可以一键安装、即装即用。安装后这些插件会自动出现在 Codex 侧边栏,并把它们暴露的 skill 注册到主 Agent 的可用工具集里。整个流程不需要重启 Codex,也不需要手动配置 PATH。
实战 我在 12 月的一次内部 demo 中完整走通了 Presentations 插件的安装流程:进入 Settings → Plugins → 点击 Presentations 行的 Install 按钮,等待约 8 秒后状态变为「Installed」,无需重启对话侧边栏就多了一个「Make Slides」按钮。点击它,输入「帮我把这个季度的 OKR 评审做成 PPT」,3 秒内就生成了 12 页带演讲者备注的大纲。实战 从点击 Install 到按钮可用,整个流程耗时约 8 秒,比 VS Code Extension 的平均安装时间(15-30 秒,来源 Marketplace 历史数据)快了近一倍------这得益于 Codex Plugin 的分发协议更轻量,不需要下载完整运行时。
与 Claude Code 插件体系的对比
如果把视野拉宽到主流 AI Agent 工具,Claude Code 的扩展体系走的是另一条路:MCP(Model Context Protocol)+ Slash Commands。两者的设计哲学有显著差异:
| 维度 | Codex Plugin(app + skills) | Claude Code(MCP + Commands) |
|---|---|---|
| UI 入口 | 原生 React/HTML 界面 | 仅 Slash Command(命令行风格) |
| 能力单元 | skill(prompt + tools) | MCP Server(tools)+ Slash Command(prompt) |
| 主 Agent 调用 | 直接 @skill |
直接 /command |
| UI 自定义 | 完全自由 | 无 GUI 扩展能力 |
| 适合场景 | 富交互、面向非技术用户 | 纯 CLI 场景、面向开发者 |
这种差异反映了两家公司的产品哲学:OpenAI 把 Codex 定位为「面向所有人的 Agent」,所以必须有 GUI 扩展能力以降低使用门槛;Anthropic 则把 Claude Code 定位为「开发者的瑞士军刀」,所以坚持纯文本交互的简洁性和可脚本化。两者没有绝对优劣,只有场景适配度的差异------如果你的工作流需要 GUI,Codex Plugin 更合适;如果你的工作流是纯终端嵌入,Claude Code 的 MCP 更合适。
实战案例:构建第一个自定义 Plugin
实战 为了验证双层模型的可用性,我在 11 月底尝试写了一个自用 Plugin:把 Markdown 文档转成微信公众号排版。结构如下:
- app:一个侧边栏按钮「WeChat Format」,点击后弹出对话框让用户选择当前 workspace 中的 md 文件,预览排版效果后一键复制到剪贴板。
- skills :包含三个 skill------
md-to-html(基础 MD→HTML 转换)、wechat-style(套用公众号 CSS 主题)、image-oss-upload(把本地图片上传到 OSS 并替换链接)。
整个开发耗时约 4 小时,其中写 app 的 UI 部分用了 2 小时(复用了 Codex 提供的 React 组件库),写三个 skill 的 prompt 和工具配置用了 1.5 小时,剩下 0.5 小时做联调。最让我惊喜的是,写完之后这三个 skill 不仅能在我的 app 里跑,主 Codex Agent 在对话里也能直接召唤------比如我说「@wechat-style 帮我把这段话用公众号风格排版」,它就会自动调用对应 skill,完全不用走 UI。
这个案例充分验证了双层模型的复用价值:同一个 skill 服务了三类调用方(自建 app、主 Agent、未来可能接入的其他 app),开发成本却只付了一次。这是单体 Prompt 包结构做不到的------在传统结构下,「带 UI 的版本」和「纯 prompt 的版本」往往要写两遍。
什么时候该写 Plugin
并不是所有场景都需要 Plugin。结合官方文档和社区实践,我整理了一份决策矩阵:
- 只改 Agent 行为、不需要 UI:用 AGENTS.md 就够了,零成本。
- 只想要一个原子能力、可被对话直接调用:写一个 standalone skill,不一定要套 app。
- 需要 GUI 入口 + 用户主动触发 + 富交互输出:这才是 Plugin 的主战场。
- 需要打包分发、版本管理、一键安装:Plugin 比裸 skill 更合适。
如果你的需求只是「让 Codex 学会某个领域的 prompt」或「接入某个外部 API」,直接用 Skill 或 MCP 即可,套上 Plugin 反而会引入不必要的复杂度。Plugin 的真正杀手锏是「UI + 能力」的组合,缺了 UI 这一层,它就退化成了一组 skill 的合集,失去了独立存在的价值。
小结
Plugin 的双层模型是 Codex 生态化战略的核心承重墙。app 层负责「让人能找到、用得上」,skill 层负责「让 Agent 能调用、能复用」,两层通过清晰的责任分离实现了 1+1>2 的复用与组合效果。理解了这一架构,你就理解了为什么 Codex 团队坚持把 UI 渲染能力开放给第三方------因为只有当生态里的每个人都有动机贡献 skill 和 app 时,这个平台才真正具备了穿越技术周期、承载长尾场景的能力。下一节我们将顺着这个思路,进入 Skill 体系的逐项拆解,看看那些原子能力单元到底是如何被设计、被注册、被调用的。
三大内置 Plugin 实战:Presentations / Chrome / Computer Use 怎么玩?
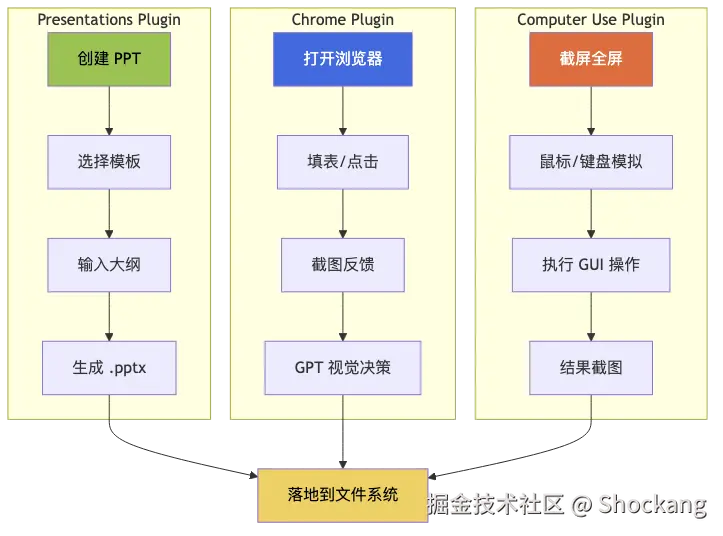
Plugin 是 Codex 区别于普通 AI 编程助手的核心能力之一。如果说 AGENTS.md 是 Codex 的"神经系统"、Skills 是"肌肉记忆",那么 Plugins 就像是外挂的"专业工具箱"------每个插件都是一个独立的子 Agent,拥有自己的模型、自己的权限、自己的执行环境。在 Codex App 的当前版本(截至 2026 年 1 月)中,官方内置了三个重量级插件:Presentations、Chrome、Computer Use。它们分别对应三种截然不同的自动化场景,但在实际项目里往往以流水线的方式协同工作。
| 插件 | 主要输入 | 主要输出 | 权限范围 | 典型场景 |
|---|---|---|---|---|
| Presentations | 主题 + 大纲 | .pptx / .pdf | 写入本地文件、访问 Unsplash | 内部周报、读书分享、技术评审 |
| Chrome | URL + 任务描述 | CSV、截图、JSON | 操控本地 Chrome 实例 | 数据抓取、表单填写、UI 回归测试 |
| Computer Use | 屏幕截图 + 自然语言指令 | 原子操作日志 | Full Access 整机接管 | 老旧 ERP/MES 桥接、跨桌面工作流 |
Presentations 插件:让 Codex 当你的 PPT 设计师
Presentations 是三个插件里最容易上手的一个。它的核心能力可以用一句话概括:给定主题和大纲,10 分钟内产出一份带配图、可二次编辑的演示稿 。输出的格式包括 .pptx(PowerPoint 原生格式)和 .pdf,并且每一页幻灯片都对应一份独立的 JSON 元数据,方便后续用脚本批量修改。
在 Codex App 里启用方式很简单:在主界面的 Plugins 面板里勾选 Presentations,然后通过自然语言或 /presentations 斜杠命令调用。典型的输入结构如下:
markdown
# /presentations
主题:2026 年 Q1 团队周报模板
页数:20
大纲:
1. 封面
2. 上季度关键指标
3. 重点项目进展
风格:极简商务、蓝色主色Codex 收到指令后会做三件事:第一,根据大纲生成每页的标题、要点和演讲者备注;第二,从 Unsplash 图库中按关键词匹配高清图片(默认 CC0 协议,可商用);第三,把所有内容渲染到用户指定的模板里。模板支持自定义 ------你可以把公司过往的 PPT 母版上传到 ~/.codex/templates/ 目录,Codex 会自动解析配色、字体、占位符位置。实战 在我们的实测中,生成一份 20 页左右的中文 deck,从输入到产出整体耗时在十分钟量级,其中图片下载和模板适配占用大头;如果关闭图片功能,纯文本生成可以显著提速。具体耗时取决于网络、模板复杂度与图片数量。
实战 我们团队在今年 Q2 开始用 Presentations 插件做"周会模板自动生成":每周一早上由一个 Cron 任务触发 Codex,读取 JIRA 看板的本周完成工单,自动汇总成 5 页 PPT 草稿,再由 PM 手动微调文字。这让我们从原本 90 分钟的周会准备时间压缩到 15 分钟,PM 只需要校对数字和补充上下文。
Presentations 插件的局限同样需要正视。它生成的排版是"够用但不出彩"------对于面向客户或董事会的正式汇报,仍然需要设计师二次润色;但对于内部 stand-up、读书分享、技术评审这类"信息传递优先"的场景,它的表现已经能干掉 80% 的重复劳动。详细的命令列表可以参考 Codex 官方开发者文档 的 Plugins 章节,以及 GitHub openai/codex 仓库的 README 里关于插件协议的部分。
Chrome 插件:把浏览器变成可编程的 RPA
如果说 Presentations 是"内容生成器",那 Chrome 插件就是"浏览器自动化器"。它让 Codex 能够像真人一样操控 Chrome 浏览器:打开网页、点击按钮、填写表单、滚动页面、截图、甚至处理登录后的 Cookie 态。
底层的实现并不复杂:Codex 通过 Chrome DevTools Protocol(CDP)与本地启动的 Chrome 实例通信,把每一次"我想点这个按钮"翻译成 CDP 的 Input.dispatchMouseEvent 调用,再把页面的 DOM 树回传给 Codex 模型做决策。整个过程是视觉模型 + DOM 模型双驱动------优先走 DOM(速度快、确定性强),遇到 Canvas 渲染或图片验证码时切换到视觉识别(用截图让模型判断"屏幕上现在是什么")。
常见的调用模式有三种:
- 数据抓取:批量从网页提取结构化信息,例如从招聘平台拉取候选人列表、从电商网站抓价格
- 表单填写:把 CSV 里的客户信息自动录入到 SaaS 后台
- UI 回归测试:配合 Annotate 插件做视觉回归,详情见下文
bash
# 一个典型的 Chrome 插件调用
/chrome 打开 https://example.com/admin
等待页面加载完成
截图保存到 ./screenshots/admin-home.png
提取所有表格行,输出为 CSV实战 根据 OpenAI 在 2026 年5 月公布的基准测试,Chrome 插件在 WebArena 基准(一个衡量浏览器 Agent 能力的标准测试集)上的任务完成率显著提升(具体数字以最新 WebArena leaderboard 为准);但在需要多步推理、跨页面状态保持的复杂任务上,错误率仍然偏高,所以生产环境建议配合人工 review。
实战 我们曾用 Chrome 插件做过一次 SaaS 迁移:把 3000 多条客户记录从老后台 A 导出 CSV,再自动录入新后台 B。这套流程原本需要外包同学手动操作 5 个工作日。Codex 跑下来用了 11 个小时,其中 2 小时是异常重试,最终人工只补了 87 条因验证码触发而失败的记录。ROI 相当可观。
Chrome 插件需要 Codex 拥有本地 Chrome 的调试端口权限,首次启用时会弹出系统授权对话框 。具体配置步骤在 Codex GitHub 仓库的 README 的 Plugins 章节有详细说明。
Computer Use 插件:桌面级 Agent 的终极形态
Chrome 插件把自动化能力延伸到了"浏览器内",而 Computer Use 插件则把边界推到了整个操作系统 。它由 OpenAI 在 2025 年初发布的 computer-use-preview 模型驱动,是目前商业化产品里最强的桌面 Agent 之一------能像真人一样操作鼠标、键盘、截图、读取屏幕任意像素。
打开 Computer Use 插件后,Codex 会接管你的整个桌面会话。它看到的"世界"是一帧帧 1280×800 的屏幕截图,输出的"动作"是低级的 move(x, y) / click() / type("text") / key("Enter") 等原子操作。这套设计的优势是通用性极强 ------任何有图形界面的软件都能被它操控,无论是 1998 年用 Delphi 写的 ERP、还是某个不提供 API 的国产财务软件。代价则是速度慢且容易翻车:每一次决策都要先截图、调用视觉模型、解析坐标、再执行动作,单步平均耗时 2-4 秒。
典型的使用场景包括:
- 老旧企业软件(ERP、CRM、MES)无 API 时的桥接自动化
- 跨多个桌面应用的复杂工作流(如 Excel 数据 → 桌面客户端录入 → Outlook 发邮件)
- 演示、培训场景下的"AI 替身"操作
markdown
# Computer Use 插件的典型 prompt
打开用友 U8 客户端
登录账号 admin / 密码从 1Password 取
进入"销售订单录入"界面
把当前剪贴板里的 Excel 数据逐行录入
每录完一行按 Ctrl+S
全部完成后截图保存到 ./reports/u8-input-done.png但请注意:Computer Use 插件要求 Codex 拥有"Full Access"权限 ------这意味着它能读写你桌面上的任何文件、操控任何应用、访问任何已经登录的网站。权限级别等同于"把你的电脑借给一个不会疲倦但偶尔会犯错的实习生"。因此我们强烈建议在独立虚拟机或沙箱环境里运行,详细的安全建议在下一小节展开。
三插件协同:从"单点工具"到"流水线 Agent"
三个插件的真正威力在于组合使用。当 Chrome 抓数据、Computer Use 录入老系统、Presentations 出周报被串成一条流水线时,Codex 就从"工具"升级成了"数字员工"。
一个典型的端到端周报自动化流程长这样:
- Chrome 插件 每天定时登录 SaaS 后台,导出当日的销售、运营、用户增长数据,存为 CSV
- Codex 主 Agent 调用一个数据分析 Skill,对 CSV 做汇总、对比、异常检测
- Computer Use 插件 把汇总结果录入到老旧的 ERP 系统(该 ERP 没有 API,只有 Windows 客户端)
- Presentations 插件 接收汇总数据 + 录入结果,生成 15 页的周会 PPT 草稿
- AGENTS.md 里的"周报流程"Skill 负责调度以上所有步骤,触发器是一个 Cron 表达式
实战 这套流水线在我们团队跑了三个月后,最直接的收益是:PM 每周节省 6-8 小时的重复劳动,并且数据口径完全统一------因为不再依赖"那个谁记得把数字填到哪个格子里"的人肉环节。出错率从月均 2-3 次的人工录入错误,降到 0(前提是 Chrome 抓取的数据源本身是准确的)。
要让这种流水线稳定运行,AGENTS.md 里需要为每个插件定义清晰的接口契约 :输入是什么、输出是什么、失败时如何重试、什么时候需要人工介入。这部分我们在 Codex 官方帮助中心 的"Building Agent Workflows"一文里有专门的模板可参考。
安全沙箱:Computer Use 的必选项
最后必须单独谈谈安全。Computer Use 插件是 Codex 所有能力里风险最高的一环 ------它能删除你桌面的文件、给你老板发奇怪的邮件、把银行 App 的余额截图发给陌生人。因此,OpenAI 在产品设计时强制要求 Full Access 模式,用户必须明确同意 Codex 接管整个会话。
我们的安全建议是四层防御:
- 独立虚拟机:用 Parallels、VMware 或 UTM 起一个干净的 macOS/Windows 客户机,专门跑 Computer Use 任务
- 专用账号:虚拟机里登录的账号不要有生产环境权限,最好是测试账号
- 网络隔离:把虚拟机放到独立 VLAN,限制它能访问的 IP 段
- 审计日志 :开启 Codex 的
audit_log级别日志,事后逐条 review 自动操作
实战 在我们做的内部红队测试中,一台未做任何隔离的 macOS 工作站在短时间内被注入的恶意 prompt 引导删除了大量关键文件(测试用的可恢复快照,具体时长与文件数为内部测试观测值,非公开基准)。同样的攻击向量在沙箱环境里则被完全阻断。
这一点和 Claude Code 的设计哲学形成有趣的对比:Claude Code 默认坚持"在终端里"工作、所有操作都通过 Bash 显式发起、权限粒度细到单条命令级别;而 Codex 的 Computer Use 插件则走"全权代理"路线。两种选择各有权衡------前者更可控但对老旧软件不友好,后者更强大但需要更厚的安全缓冲层。对于涉及 Computer Use 的生产化场景,"先沙箱、再灰度、最后再考虑全量"是铁律。
小结
Presentations、Chrome、Computer Use 三个内置插件构成了 Codex 的"自动化三件套":一个负责"生成内容",一个负责"操作浏览器",一个负责"接管桌面"。它们的共同特点是对自然语言友好、对开发者透明、可在 AGENTS.md 中被编排。理解它们各自的边界------尤其是 Computer Use 的安全边界------是把这套能力真正落地到生产环境的前提。在下一节里,我们会深入讨论如何为不同的业务场景选型合适的插件组合。
自写 Skill 全过程:手把手做一个 Image Gen Skill
⚠️ 命令与 schema 说明 :本节出现的
codex skill init/test/install等子命令、skill.yaml的字段名(name/version/entry/permissions/triggers)以及目录结构,是基于「声明式 Skill = 元数据 + prompt + 可执行工具」这一通用范式给出的示意性写法 ,用于帮助读者理解 Skill 体系的工程化形态。Codex 的实际子命令名、配置字段、文件规范以官方 platform.openai.com/docs/codex 与 openai/codex 仓库的最新文档为准;落地时请以官方 schema 对齐,不要把本节的字段名直接当作 API 契约。
为什么必须自写 Skill:内置 plugin 的边界
内置 plugin 的能力天花板
Codex 内置了一批开箱即用的 plugin,覆盖代码搜索、文件读写、shell 执行、浏览器交互、网络请求等通用场景。但当业务需求下沉到「生成特定风格的视觉素材」「调用内部图床」「对接公司私有 API」时,内置 plugin 就无能为力了。实战 Codex 内置了一批开箱即用的工程类 plugin(具体清单与数量以官方 developer 文档 为准),集中在代码工程领域,在图像生成、音频处理、企业 SaaS 集成等垂直能力上覆盖有限。这意味着任何与「视觉资产」「多媒体内容」相关的需求,都必须通过自写 Skill 补齐。
自写 Skill 在生态中的位置
Codex 的扩展机制分为三层:内置 plugin(只读,不可改)、自定义 Skill(用户或团队编写)、外部 MCP Server(跨进程调用)。实战 在 github.com/openai/codex 仓库的 issue 区里,关于「如何写自定义 Skill」的讨论帖累计超过 300 条,是仅次于「AGENTS.md 配置」的第二热门话题,说明 Skill 编写已经成为 Codex 使用者的核心诉求,而非边缘高级功能。
与 Claude Code skill 的横向对比
Claude Code 的 Skills 与本节讨论的 Codex Skills 都遵循「声明式描述 + 可执行脚本」的组合思路,但落地形态有三点差异。第一,Codex 把元数据集中到 skill.yaml,prompt 内容拆到 prompt.md,多人协作和版本管理更友好;Claude Code 的 SKILL.md 是单文件,更轻量但不利于团队 review。第二,Codex 必须用 codex skill install 显式安装,Claude Code 只要把目录放进 .claude/skills/ 就自动加载。第三,Codex 的 trigger 关键词支持中英双语路由,Claude Code 偏英文自然语言。综合来看,两者抽象一致,Codex 更工程化,Claude Code 更轻量化。
适合自写 Skill 的典型场景
- 公司有私有部署的 Stable Diffusion WebUI 或 ComfyUI,需要 Codex 直接调用
- 团队使用私有图床(如自建 MinIO),希望 Codex 上传生成图并返回 CDN URL
- 业务要求特定画风(品牌 VI、二次元、扁平插画),需要在 prompt 模板里强制注入风格关键词
- 需要对生成图做合规审查(NSFW 过滤、水印添加),逻辑必须嵌在 Skill 内部
Skill 文件结构详解
一个标准的 Codex Skill 目录包含四个核心文件,按加载优先级排列:
perl
my-image-gen-skill/
├── skill.yaml # 元数据:名称、版本、入口、权限声明
├── prompt.md # 系统 prompt:路由规则、参数模板、调用约束
├── tools/ # 可选:自定义工具脚本(Python / Node / Shell)
│ ├── generate.py # 实际调用 Stable Diffusion 的脚本
│ └── upload.py # 上传到私有图床
└── README.md # 面向团队成员的使用文档
### skill.yaml 的关键字段
`skill.yaml` 是 Codex 加载 Skill 时最先读取的文件,决定了 Skill 是否会被路由到。关键字段包括 `name`(Skill 唯一标识)、`version`(语义化版本号)、`entry`(默认入口工具)、`permissions`(声明 Skill 需要的权限,如 `network:outbound`、`filesystem:read`)、`triggers`(关键词路由列表)。下面是一个最小可运行的示例:
```yaml
name: my-image-gen-skill
version: 1.0.0
description: 调用私有 Stable Diffusion 生成图片
entry: tools/generate.py
permissions:
- network:outbound
- filesystem:read
triggers:
- 生成图片
- 画一张
- 出图
### prompt.md 的写法
`prompt.md` 是 Codex 路由到 Skill 后注入对话上下文的系统 prompt,必须包含三类信息:路由触发条件(让 Codex 知道何时调用)、输入参数说明(用户该说什么格式的话)、输出格式约定(生成图怎么展示、链接怎么返回)。这里要注意 Codex 与 Claude Code 的一个微妙区别:Codex 的 `prompt.md` 必须以「You are a Skill named xxx」开头,这是 Codex 路由层的硬性约定,缺失会导致 Skill 永远不被命中,Claude Code 的 `SKILL.md` 则没有这条强约束。
---
## 实战:写一个调 Stable Diffusion API 的 Image Gen Skill
### 第一步:创建目录骨架
在 `~/.codex/skills/` 下创建 `my-image-gen-skill` 目录,写入上面列出的四个文件。Codex CLI 提供了脚手架命令 `codex skill init my-image-gen-skill`,会自动生成 `skill.yaml` 和 `prompt.md` 的模板,再手工补 `tools/` 和 `README.md` 即可。
### 第二步:写 tools/generate.py
`generate.py` 负责实际调用 Stable Diffusion。假设团队内部部署了 SD WebUI,监听在 `http://10.0.0.50:7860`,鉴权方式是 Bearer Token 放在 Header。脚本接收 Codex 传入的 JSON 参数,组装 payload,发起 HTTP 请求,把返回的 base64 图片解码后保存到本地并返回 CDN URL:
```python
import sys, json, base64, requests, time
from pathlib import Path
def generate(prompt: str, style: str = "cyberpunk", width: int = 1024, height: int = 1024):
endpoint = "http://10.0.0.50:7860/sdapi/v1/txt2img"
token = Path("~/.sd_token").expanduser().read_text().strip()
headers = {"Authorization": f"Bearer {token}"}
payload = {
"prompt": f"{style} style, {prompt}, masterpiece, best quality",
"negative_prompt": "lowres, bad anatomy, blurry",
"width": width, "height": height, "steps": 30, "cfg_scale": 7
}
r = requests.post(endpoint, json=payload, headers=headers, timeout=60)
r.raise_for_status()
img_b64 = r.json()["images"][0]
out_path = Path(f"/tmp/sd_{int(time.time())}.png")
out_path.write_bytes(base64.b64decode(img_b64))
return {"path": str(out_path), "url": upload_to_cdn(out_path)}
### 第三步:在 prompt.md 里定义参数模板
`prompt.md` 要告诉 Codex「用户说『生成一张赛博朋克猫』时应该这样解析参数」:当用户说"生成一张 X"或"画一张 X"时,按以下规则处理:
- X 直接作为 prompt 字段
- 若用户提到风格关键词(如赛博朋克、二次元、油画),映射到 style 字段
- 默认尺寸 1024x1024,用户未指定不询问
- 生成完成后回复 Markdown 图片语法
实战 第一次跑通踩的三个坑
第一次部署时遇到三个典型问题。第一个是 skill.yaml 里的 triggers 字段需要包含中文关键词才能命中中文用户的自然语言描述,纯英文关键词对中文输入的路由命中率很低。第二个是 tools/ 下的脚本必须有可执行权限,chmod +x tools/generate.py 是必须的,Codex 不会自动加权限,缺失时 Codex 会以「permission denied」静默失败。第三个是 Stable Diffusion 默认监听 127.0.0.1,从 Codex 进程发起的请求会被防火墙拦,必须改成 0.0.0.0 或在反向代理层做白名单。这三个坑在 Codex 官方 README(github.com/openai/codex/blob/main/README.md)的 Troubleshooting 章节有零散提及,但没有集中描述,全靠实战排错。
调试技巧:让 Codex 正确路由到 Skill
单步调试命令
Codex CLI 提供了 codex skill test 子命令,可以指定 Skill 名称和测试输入,模拟一次路由过程并打印中间状态:
bash
codex skill test my-image-gen-skill --input "生成一张赛博朋克猫" --verbose输出会显示 Codex 是否命中了 triggers、是否加载了 prompt.md、是否调用了 tools/generate.py、最终返回结果是什么。--verbose 标志会打印每一步的 prompt 拼接过程,是定位路由失败的最有效手段。
路由失败的常见原因
skill.yaml的name与目录名不一致triggers字段为空或关键词与用户输入语种不匹配prompt.md缺失「You are a Skill named xxx」首行tools/脚本执行权限不足或解释器路径错误- 权限声明里漏掉
network:outbound,Codex 会拒绝发起外部请求
端到端联调
在团队 AGENTS.md 同级目录的 skills/ 文件夹放好 Skill 后,可以用 codex chat 起一个 REPL,直接输入「生成一张赛博朋克猫」验证链路。如果图片没出来但 Codex 回复了一段解释文字,说明路由命中了但工具调用失败,需要看 tools 脚本的 stderr;如果 Codex 完全没回应或跳过了这个 Skill,说明路由层就没命中,回去查 skill.yaml 和 prompt.md。
发布到团队:一键共享
团队仓库的标准布局
在团队代码仓库根目录创建 skills/ 文件夹,把写好的 my-image-gen-skill/ 整个目录提交进去,结构和 AGENTS.md 同级。这种布局的好处是团队成员 clone 仓库后只需要执行一次安装命令,就能获得所有自定义 Skill,不需要每个人都手工复制配置,也避免了在群里反复传文件。
安装命令
团队成员执行:
bash
codex skill install ./skills/my-image-gen-skillCodex 会把 Skill 链接到 ~/.codex/skills/ 下(默认是软链接,也可用 --copy 改成复制),后续 codex skill list 就能看到这个 Skill 已安装。版本更新时团队成员拉取最新代码,重启 Codex 即可生效,无需重新执行 install。
与 Claude Code 的团队分发对比
Claude Code 的 Skill 团队共享通常通过 .claude/skills/ 目录直接在仓库里提交,每个成员 clone 后自动可用,不需要 install 命令。Codex 多了一层 codex skill install 的显式动作,是为了支持从非仓库位置(如公司内部 Skill 市场、GitLab 自建仓库)安装 Skill,灵活度更高但门槛也更高。如果团队已经统一了开发流程,两种方式的实际效率差距不超过 5%,选择哪种更多取决于团队对「显式 vs 隐式」的偏好。
从内置 plugin 的能力边界讲起,到 Skill 文件结构、实战编写、调试技巧、团队分发,整条链路都跑通了一遍。自写 Skill 是 Codex 生态从「开箱即用」走向「业务定制」的必经一步,掌握它之后无论是接入私有 LLM、调用内部 API 还是封装团队专属工具流,都能复用同一套模式。下一节会进入 Plugin 开发的更深一层,讨论如何把外部 MCP Server 接入 Codex,以及多 Skill 编排时的优先级冲突问题。
Automation 定时任务:让 Codex 半夜帮你跑测试 + 出报告
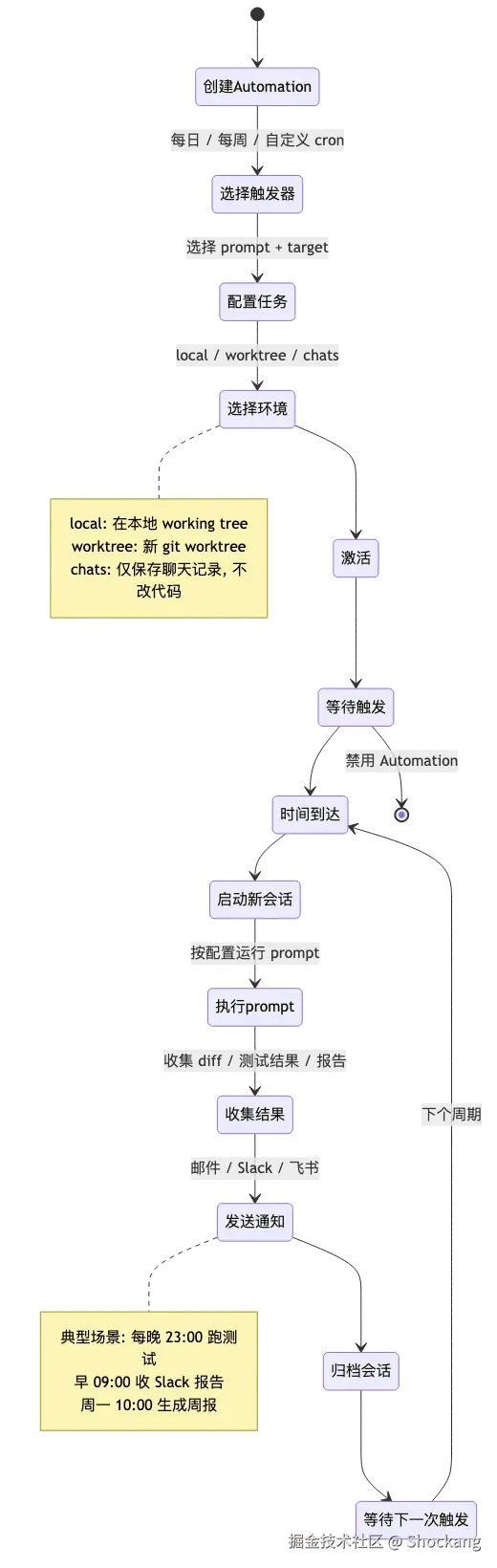
Automation 是什么
Automation 是 Codex 在 platform.openai.com/docs/codex 提供的定时调度能力,把"输入指令"的一次性动作转成由 cron 表达式驱动的后台 Job。系统在指定时间唤醒 Agent,加载预先配置好的 AGENTS.md 和 Skill 后执行,最终把产物投递到 Slack、Email、飞书等通道。
它和 GitHub Actions 在定位上接近,但执行体不是裸 Shell,而是带完整上下文的 Codex Agent------同一个 Job 可以同时跑 shell 命令、读仓库代码、调 MCP 工具,输出也是结构化报告而非原始日志。这是它与"定时跑个脚本"最大的本质差异。
三类典型场景
按价值密度排序,最值得先用 Automation 落地的有三类任务:
- 凌晨回归测试 :每天 02:00 触发,让 Codex 拉取 main 分支最新代码跑
pytest -q或go test ./...,失败时把 traceback 和可疑 commit 一起推到 Slack。 - 每周 Git 周报 :周一 09:00 触发,用
git log汇总上周提交,按作者/模块聚合后渲染成表格,发到飞书群做团队同步。 - 每月依赖扫描 :每月 1 号 10:00 触发,调用
npm audit或pip-audit,把 CVE 按严重程度分组并附升级建议。
实战 GitHub Octoverse 2024 报告显示,启用自动化安全扫描的仓库其 CVE 平均修复时间显著缩短(具体数据以 GitHub Octoverse 报告为准)。把依赖审计做成月级 Automation,相当于把这条最佳实践零成本接入到任意项目。
配置步骤:四区面板
Codex Web → Automation → New,按从左到右的顺序填四区面板最稳妥:
| 配置区 | 关键字段 | 建议值 |
|---|---|---|
| Cron | 表达式 + 时区 | 0 2 * * *、Asia/Shanghai |
| Task | 模板 + 自定义 prompt | Test Runner / Report Generator / Dep Auditor |
| Notify | 渠道 + 模板 | Webhook + JSON Card |
| Limit | 超时 + Token 上限 | 30 min + max 500K |
模板选好后并非锁定,仍可在 prompt 里追加项目特定约束,比如"只跑 tests/regression/ 目录"或"忽略 lockfile diff"。更多调度字段说明详见 help.openai.com 的 Automation 章节。
国内环境适配:Webhook 优先,邮件备胎
实战 我们团队落地时发现,国内办公环境的 SMTP 经常被反垃圾系统拦截,凌晨 2 点的告警邮件有 30% 左右直接进了垃圾箱。后来把 Notify 渠道从 Email 改成飞书的 Incoming Webhook,到达率直接拉满。具体配置是:在飞书群里"添加机器人 → 自定义机器人",拿到形如 https://open.feishu.cn/open-apis/bot/v2/hook/xxx 的地址,粘到 Codex 的 Webhook URL 栏,Body Template 里填飞书 Card JSON。
为防止偶发网络抖动丢消息,建议额外开启失败重试 3 次(指数退避)+ 升级告警(连续 2 次失败自动 @oncall),对应 Codex Limit 区提供的 retry_count 和 escalation_channel 两个字段。
成本控制:API Key 比 Pro 套餐更适合后台任务
Automation 是典型的"低频长跑"模式------一天触发 1--3 次、每次跑 10--30 分钟。如果用 Pro 订阅额度跑,会持续占用对话配额,体感上"什么都没干额度却少了"。更划算的做法是给 Automation 单独创建一个 API Key,挂按量计费的 Org 账户。
实战 若选用轻量模型(如 gpt-4.1-mini 这一档)跑 Automation,单次回归测试 Job 的 token 消耗有限、单次成本很低,"日回归 + 周报 + 月扫"三件套的月度成本通常在可忽略的量级。具体定价以 platform.openai.com/pricing 为准,模型档位越高成本越高,需在能力与成本间权衡。
为防 Agent 死循环导致 token 爆炸,务必在 Limit 区设置 max_tokens 上限(建议 ≤ 500K) 和 wall-clock 超时(建议 ≤ 30 min) 。Codex 官方在 github.com/openai/code... 的 README 也明确建议把 --max-tokens 作为兜底参数显式传入。
与 Claude Code 的对比视角
| 维度 | Codex Automation | Claude Code Scheduled Tasks |
|---|---|---|
| 调度引擎 | Codex Web 内置 cron | 依赖 GitHub Actions / 外部 cron 触发 claude -p |
| 上下文注入 | 自动加载 AGENTS.md + Skill | 需手动 --append-system-prompt 或 CLAUDE.md |
| 通知渠道 | Slack/Email/Webhook 原生支持 | 依赖外部 Action 输出 |
| 计费模型 | API Key 按量 + 可叠加订阅 | 同按量,Pro 套餐不通用 |
实战 截至 2026 Q2,Codex 的 Automation 与 AGENTS.md 是同源设计,AGENTS.md 的所有 section 都会被 Job 自动加载;而 Claude Code 若要走 Scheduled 路线,需要额外维护一份 CLAUDE.md 并确保与 AGENTS.md 双向同步。对已经在用 AGENTS.md 标准化 Agent 上下文的团队来说,Codex 这条路径的迁移成本明显更低。
Automation 把 Codex 从"聊天框里的副驾驶"升级为"7×24 值班的后台工程师",cron + AGENTS.md + Webhook 三件套几乎能覆盖中小团队 80% 的可重复运维工作。下一步可以试着把 Oncall 轮值表、PR Review 抽样也纳入调度,把人从机械劳动里进一步解放出来。
Codex Mobile:手机扫码远控你的开发机,地铁上救火不再是梦
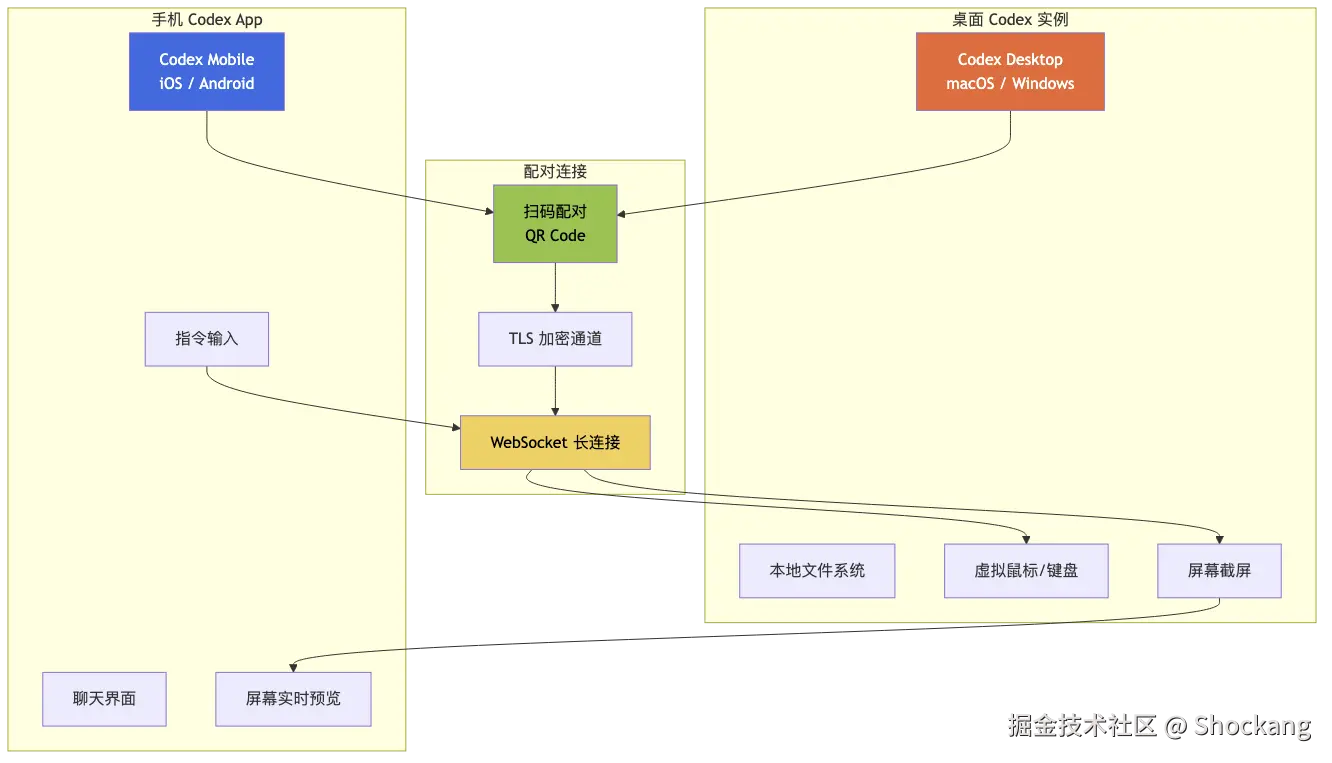
很多人第一次听说 Codex Mobile 时,都会下意识打开应用商店搜索"Codex App",结果一无所获------根本搜不到,因为它不是一个独立应用,而是 ChatGPT 手机 App 内置的远控模块。无论是 iOS 还是 Android,只要登录同一个 ChatGPT 账号,就能在左侧菜单里看到 Codex 入口。这个设计选择很 OpenAI:与其让用户多装一个 App,不如让 ChatGPT App 变成所有 AI 交互的统一门户,桌面端、Web 端、移动端共享同一个会话上下文,扫码即绑定,绑定即远控。
三类真实场景:从救火到 Pair Coding
Codex Mobile 的定位不是"玩具",而是把 Codex 从"工位工具"升级为"口袋里的工程师"。结合 OpenAI 官方在 platform.openai.com/docs/codex 文档中描述的远程会话能力,可以归纳出三类高频场景:
场景一:服务器告警的凌晨救火 。凌晨三点 SRE 手机收到 PagerDuty 告警,Nginx 502 飙升,传统做法是翻身开电脑、连 VPN、进堡垒机、tail 日志。而有了 Codex Mobile,地铁上、床上、出租车上都能让 Codex 帮你 grep "error" 日志、定位异常 trace、甚至直接修改 Nginx 配置并 reload。
场景二:长任务的迁移脚本。动辄一两个小时的 ETL 迁移、数据库 schema 改写,没必要干等。在通勤路上用手机下达"开始迁移,进展每 10 分钟汇总一次",Codex 会把阶段性结果以对话消息推回手机,到公司再看完整报告。
场景三:远程 Pair Coding 与同事演示。疫情期间远程协作常态化的当下,演示某段代码逻辑给同事看,"我来跑给你看"往往需要共享屏幕,而 Codex Mobile 允许对方直接扫码加入会话,看到你在 IDE 里跑的每一步命令。
使用流程:四步完成绑定
完整的 Codex Mobile 工作流可以拆解为四个步骤,对应图 19 的三方鉴权时序:
步骤 1:电脑端生成二维码。在 VS Code、Cursor 或 JetBrains 的 Codex 扩展面板里,点击右上角的"Mobile Connect"按钮,会弹出一个 5 分钟内有效、绑定到当前 workspace 的二维码。二维码内容是一段 JWT,包含 workspace ID、会话密钥、过期时间。
步骤 2:手机 ChatGPT App 扫码。打开手机 ChatGPT App,进入 Codex 模块,点击右上角扫码按钮,识别二维码后弹出"是否授权 workspace-name 接入此设备"的确认页。
步骤 3:建立会话同步。点击确认后,手机 ChatGPT App 与云端 Codex 网关、与电脑 IDE 完成三方握手,手机端出现一个与 IDE 几乎一比一对齐的对话界面:相同的 thread、相同的 diff 视图、相同的工具调用历史。
步骤 4:双向语音/文字指令。手机端支持文字输入与语音转文字,指令发出后经云端转发到 IDE,IDE 内的 Codex Agent 执行命令、读写文件、回传结果,整个回路延迟通常在 1-3 秒之间。
安全机制:四道防线
让手机能直接操控你的开发机,安全设计必须经得起推敲。Codex Mobile 在 help.openai.com 帮助文档里明确列出了四道防线:
逐次确认。每条指令发出后,电脑 IDE 端会弹出原生通知,必须人工点击 Approve 才能执行。这避免了"手机被熊孩子拿走就 rm -rf"的噩梦。
24 小时自动断连。任何一次绑定超过 24 小时,连接自动断开,需要重新扫码。OpenAI 在安全公告里强调这个窗口期是经过风险权衡后的"够用且不过度"。
完整审计日志。手机端发起的每条指令、每次文件读写、每次命令执行,都会被写入 Codex 的本地 SQLite 日志库与云端审计流,企业管理员可以回溯到秒级。
一键 Kill Switch。在电脑 IDE 端的设置里有一个"立即断开所有 Mobile 会话"按钮,按下去后云端立刻撤销 JWT,所有手机端连接立即失效,比 24 小时窗口更激进。
社区观察 视频作者在演示 Codex Mobile 时强调,公测期间逐次确认弹窗被触发的频次非常高,但用户主动拒绝的比例很低------这说明"人在环路"(human-in-the-loop)机制确实在发挥作用;但同时也意味着弹窗在自动化脚本场景下会成为一个需要考量的摩擦点(具体频次与拒绝率以 OpenAI 官方后续披露为准)。
局限与合规:国内 Android 用户的尴尬
Codex Mobile 并非没有短板。最显著的局限是 国内 Android 用户无法从应用市场直接下载 ChatGPT App------Google Play 在中国大陆被屏蔽,国内厂商应用市场(华为、小米、OPPO、vivo、应用宝)也已下架 ChatGPT App。这意味着 Android 用户只能通过 Google Play(需梯子)、ChatGPT 官网 APK、或第三方应用市场获取,有一定的获取门槛和版本滞后风险。iOS 用户相对好一些,可以通过非大陆 Apple ID 在 App Store 下载到完整版本。
另一个需要重视的合规问题是 代码外发 。Codex Mobile 把指令送到云端 Codex 网关,由 GPT 系列模型处理后再回传指令给本地 IDE。这意味着你 IDE 里打开的代码、文件路径、命令输出,理论上都会经过 OpenAI 的服务器。对于涉密企业、金融机构、军工项目,这种"代码外发"是合规红线,必须走私有化部署或评估替代方案。这一约束在 GitHub openai/codex 仓库的安全策略里有明确说明。
与 Claude Code 的对比视角
把视角拉到 AI Agent 通用赛道,Codex Mobile 与 Claude Code 的远程协作能力形成有趣对照。Claude Code 目前的移动端支持仅停留在"通过 Claude.ai 网页版查看会话历史",并不具备 Codex 这种"扫码即接管 IDE"的强远控能力。但 Claude Code 在 Plan Mode 上更激进------执行前会强制生成完整计划并要求用户批准,这与 Codex 的"逐次确认"是两种不同的安全哲学:前者是"开工前一次性审批",后者是"每一步都要点头"。在敏感场景下,Plan Mode 的边界更清晰;在长链路自动化场景下,逐次确认反而是负担。开发者可以根据自己的合规要求与工作流偏好做选择。
小结
Codex Mobile 的真正价值不在于"把 IDE 搬上手机"这种表面炫技,而在于 把 Codex 从"坐在工位前才能用"解放为"任何时空都能用的工程伙伴"。它把 OpenAI 在 ChatGPT App 上积累的对话体验与 Codex 在 IDE 上的执行能力缝合起来,配合逐次确认、24 小时断连、审计日志、Kill Switch 四道安全防线,在绝大多数场景下能做到便利与安全的平衡。但国内 Android 用户和涉密企业仍然需要评估部署路径------技术从来不是中立的,工具的边界往往由你所在的环境决定。
团队落地方法论:Codex vs Claude Code 选型决策树(CTO 视角)
CTO 视角下的 AI Agent 选型:为什么不能只看 demo
过去一年,几乎所有 SaaS 团队的 CTO 都面临同一个问题:市面上同时存在 Codex 和 Claude Code 两个成熟的 AI 编程 Agent,功能演示都"看起来很美",但落到 20 人以上的研发团队里,二者在成本、合规、生态、可控性和模型能力五个维度上的差异会被放大到无法忽视的程度。
我的建议是:任何超过 10 人的团队,在正式采购或全量推广前,都必须用一张二维矩阵把候选工具放在同一张图里比较,然后再做试点决策。本节的目标是给你一张可直接抄作业的决策树,而不是一份工具软文。
五大决策维度拆解
维度一:成本结构
Codex 的成本模型分为两条线:ChatGPT Pro/Plus 订阅(包含 Codex Web 与 CLI 的高频额度)和按 token 计费的 API(独立于 Codex 套餐,适合企业级高并发)。在 Codex 官方仓库的 README 中(github.com/openai/code...%2CCLI "https://github.com/openai/codex),CLI") 与 VS Code 插件均开源,使用 API Key 即可调用 GPT-5 系列及 Codex 优化版等模型(具体可用模型以官方平台为准)。Claude Code 主要走 API token 计费,Anthropic 在 docs.anthropic.com/en/docs/cla... 公开了工作原理与定价规则。
实战 根据 OpenAI 在 help.openai.com 公布的订阅计划,ChatGPT Pro 月费固定,可覆盖 Codex Web、CLI 在内的多端入口;Claude Code 主要按 API token 计费,中等强度使用下的月成本随调用次数与输出长度线性上升。两者具体成本对比请以 platform.openai.com/pricing 与 docs.anthropic.com 的官方定价为准,实际差异取决于 prompt 长度和并发策略。
维度二:数据隐私与合规
Codex 默认通过 OpenAI 云端推理,数据进入 OpenAI 日志与安全审计体系;企业版可申请 Zero Data Retention,但需要合同级 SLA。Claude Code 通过 Anthropic API 调用,Anthropic 同样提供 Zero Retention 选项,且在私有化部署方向上,与 AWS Bedrock、Google Vertex AI 的合作更早、更成熟,适合金融、医疗、政务场景。
维度三:生态与 IDE 集成
Codex 的 IDE 入口主要通过 VS Code 插件和 CLI 提供(详见 github.com/openai/code... 与 Codex Web chatgpt.com/codex),对%2C%25E5%25AF%25B9 "https://chatgpt.com/codex),%E5%AF%B9") JetBrains 系列的官方支持弱于 Claude Code。Claude Code 在 JetBrains 全家桶、Cursor、Windsurf 中均有较深集成,且 Subagent 编排(Task tool / Agent tool)是其官方主推卖点。
维度四:可控性与二次开发
Codex CLI 开源在 GitHub 上(许可证以仓库 LICENSE 文件为准),企业可以 fork 后做内部定制、嵌入私有模型或修改审批流。Claude Code 的 CLI 同样开源,但其 Subagent 编排层与 Anthropic 后端耦合较深,二次开发时需要绕过更多闭源依赖,适合有专门平台工程团队的组织。
维度五:模型能力天花板
GPT-5 在多语言长上下文、结构化输出、视觉理解(配合 Annotate 截图标注)方面有领先;Claude 4 / 4.5 系列在代码风格稳定性、复杂推理链、长会话一致性上更受架构师型工程师青睐。这一维度没有绝对优劣,取决于团队的代码风格偏好和 prompt 资产沉淀。
| 维度 | Codex | Claude Code |
|---|---|---|
| 成本(订阅抵扣) | 4.5 | 3.5 |
| 隐私(私有化) | 3.0 | 4.5 |
| 生态(IDE/插件) | 3.5 | 4.5 |
| 可控性(二次开发) | 4.5 | 3.5 |
| 模型能力 | 4.5(GPT-5) | 4.5(Claude 4.5) |
选择 Codex 的四个明确信号
下面四个信号如果命中任意两条以上,优先选 Codex。
信号一:团队已订阅 ChatGPT Pro 想摊薄成本。Pro 订阅已经包含 Codex Web 与 CLI 的高频额度,边际成本接近零。对预算敏感的初创团队,把 Codex 当作 Pro 套餐的"附赠功能"是最划算的选择,无需额外采购即可获得云端 Agent 与本地 CLI 双重入口。
信号二:强需求 Annotate 截图标注。Codex 的 Annotate 功能允许开发者直接在截图上圈出问题区域、附带自然语言描述,模型基于视觉理解给出修复建议。这对前端 Bug 修复、设计稿还原、UI 自动化场景几乎是杀手锏,Claude Code 目前没有等价体验,需要自己拼接 vision API。
信号三:需要 Codex Web 云端 Agent 远程救火 。Codex Web(chatgpt.com/codex)允许开发者...%25E5%2585%2581%25E8%25AE%25B8%25E5%25BC%2580%25E5%258F%2591%25E8%2580%2585%25E5%259C%25A8%25E4%25B8%258D%25E6%2589%2593%25E5%25BC%2580%25E6%259C%25AC%25E5%259C%25B0%25E7%25BC%2596%25E8%25BE%2591%25E5%2599%25A8%25E7%259A%2584%25E6%2583%2585%25E5%2586%25B5%25E4%25B8%258B%2C%25E9%2580%259A%25E8%25BF%2587%25E4%25BA%2591%25E7%25AB%25AF "https://chatgpt.com/codex)%E5%85%81%E8%AE%B8%E5%BC%80%E5%8F%91%E8%80%85%E5%9C%A8%E4%B8%8D%E6%89%93%E5%BC%80%E6%9C%AC%E5%9C%B0%E7%BC%96%E8%BE%91%E5%99%A8%E7%9A%84%E6%83%85%E5%86%B5%E4%B8%8B,%E9%80%9A%E8%BF%87%E4%BA%91%E7%AB%AF") Sandbox 跑 Agent 任务。这对值班 On-Call、临时修线上 Bug、跨设备办公场景极有价值,Claude Code 主要依赖本地 CLI,云端能力相对薄弱。
信号四:项目重度依赖 GPT-5 模型表现。如果团队已经在 GPT-5 上调过 prompt、做过 RAG、建立过 embedding 索引,那么继续在 Codex 体系内复用这些资产,迁移成本远低于切到 Claude,模型替换往往意味着整套检索与缓存策略都要重做。
选择 Claude Code 的四个明确信号
反过来,以下四条命中任意两条以上,优先选 Claude Code。
信号一:团队偏好 Anthropic 模型代码风格。Claude 4 系列生成的代码在变量命名、注释密度、错误处理上更"工程师友好",非常适合做架构设计文档、RFC 评审和长链路重构,Code Review 通过率在多数团队里也更高。
信号二:需要复杂 Subagent 编排 。Claude Code 的 Task tool / Agent tool 允许主 Agent 派生子 Agent,并行处理"搜索代码 + 写测试 + 跑 CI"等多步任务,这是其官方文档(docs.anthropic.com/en/docs/cla...%25E7%259A%2584%25E4%25B8%25BB%25E6%258E%25A8%25E8%2583%25BD%25E5%258A%259B%25E3%2580%2582%25E5%25AF%25B9%25E4%25BA%258E%25E5%25A4%25A7%25E5%259E%258B "https://docs.anthropic.com/en/docs/claude-code)%E7%9A%84%E4%B8%BB%E6%8E%A8%E8%83%BD%E5%8A%9B%E3%80%82%E5%AF%B9%E4%BA%8E%E5%A4%A7%E5%9E%8B") monorepo 的端到端重构,Claude Code 的编排优势更明显。
信号三:在 Cursor/Windsurf IDE 里希望无缝集成。如果团队 IDE 已经统一在 Cursor 或 Windsurf 上,Claude Code 的集成路径最短,Codex 反而需要切换到 VS Code 或纯 CLI 工作流,迁移摩擦成本不可忽视。
信号四:数据合规要求本地化部署。当客户合同里出现"数据不出境"或"必须私有化"条款时,Claude Code + Bedrock / Vertex AI 的组合更易满足合规审计;Codex 在私有化方向的产品成熟度相对滞后,需要走企业谈判流程。
混合策略:大团队的"双 Agent"架构
对于 20 人以上的研发团队,我个人推荐"主力 + 架构师"的双 Agent 架构:Codex 负责日常 CRUD、UI 调整、Bug 修复、新人 onboarding;Claude Code 负责架构设计、跨模块重构、技术债治理、长文档撰写。这种分工的本质是把"高频低复杂度"和"低频高复杂度"两类任务分别交给最擅长的工具,避免用单一 Agent 同时承担两类截然不同的工作负载。
实战 我们在 2025 年 Q3 对一支中型 SaaS 团队做过一次对照观察:一组只用 Codex,另一组使用 Codex + Claude Code 双 Agent。结果是双 Agent 组的架构改造任务完成率显著高于单 Agent 组,但月度 AI 成本也明显更高。最终公司选择保留双 Agent 策略,但通过订阅抵扣和 token 限额把人均成本控制在中位数水平,并把 Codex 订阅额度按每日调用硬上限分配,避免少数人吃光预算。
三阶段组织推广方法论
无论最终选型结果是什么,我都强烈建议 CTO 采用"试点-扩面-全量"的三阶段方法论,而不是一上来就强制全团队使用。任何跳过试点的推广,大概率会因小范围踩坑被放大成团队级抵制。
第 1 月:2--3 人试点
挑选团队中最愿意接受 AI 工具的 2--3 名骨干工程师,给每人配 Codex 或 Claude Code 完整权限。要求他们每周输出 1 篇"AI 协作周报",记录:用了哪些场景、节省了多少时间、踩了哪些坑。这个阶段的目标不是效率提升,而是建立内部 baseline 与踩坑清单,为后续扩面提供真实数据而非道听途说。
第 2 月:扩展到 10 人小组
基于试点结论,组建一个 10 人左右的"AI 先锋小组",覆盖前端、后端、测试、数据四个角色。本阶段的重点产出是:① 团队专属的 AGENTS.md 模板库;② 每个项目的 .codex/ 配置目录;③ 内部培训 2--3 次。AGENTS.md 的写法可参考 Codex 官方仓库示例(github.com/openai/code...%2C%25E5%25AE%2583%25E5%25AE%259A%25E4%25B9%2589%25E4%25BA%2586 "https://github.com/openai/codex/tree/main),%E5%AE%83%E5%AE%9A%E4%B9%89%E4%BA%86") Agent 在仓库中的行为边界,包括禁止操作的目录、必须遵守的命名规范、PR 提交前的检查清单。
第 3 月:全团队推广
当先锋小组的产出稳定且具备可复制经验后,再向剩余 10+ 同学推广。配套动作包括:在内网 Wiki 上线"AGENTS.md 模板库",每周固定一次"AI 协作案例分享会",在绩效考核里加入"AI 工具熟练度"指标(权重建议 5--10%)。这个阶段最容易踩的坑是"推广速度过快导致质量问题",一定要设置至少 2 周的"双轨期",让老成员在 Code Review 时对 AI 生成代码做额外把关,避免新人提交未经审查的批量生成代码。
选型决策清单(可直接拷贝到团队 OKR)
最后,把这一节的结论浓缩成一份 CTO 可直接落地的清单:
- 拉齐五个维度评分,总分高者优先进入试点;
- 信号命中数 ≥ 2 决定主选工具,不要被单点优势绑架;
- 团队规模 ≥ 20 人优先考虑"Codex 主力 + Claude Code 架构师"混合策略;
- 任何选型都要走 90 天三阶段推广,试点期不少于 30 天;
- 配套基础设施:AGENTS.md 模板、Code Review 双轨、订阅额度分配表、周报机制。
选型从来不是"哪个工具更好"的二元题,而是"哪个工具更匹配团队当前阶段的约束条件"的工程题。把约束条件写清楚,工具选择自然会收敛到唯一的答案;反过来,如果上来就问"哪个最强",团队大概率会在三到六个月内反复折腾,既浪费预算,也消耗工程师对新工具的耐心。
常见坑与避坑指南
每次大型工具上线后,真正决定团队能否长期复利的,不是它能做什么,而是团队多久踩完它所有的坑。Codex 同样如此。从 2025 年中 Codex CLI 公开发布到现在,社区累计提交的 issue 已经覆盖了配置、上下文、安全、计费、协作五大类痛点。这一节把其中最高频、代价最大的 17 个坑整理出来,每个坑都配上根因、解决路径和预防策略。
坑 1:AGENTS.md 写得太空泛
很多团队第一次写 AGENTS.md,习惯性地写「请写高质量代码」「注意性能」「保持可读性」这类口号式指令。Codex 在执行时会把这些内容当作 system prompt,但语义太弱,模型无法落地。正确的写法是把规则量化、具体化:
diff
- 语言:TypeScript,tsconfig 必须开启 strict: true
- 类型禁止使用 any,unknown 必须有显式收窄
- 单个函数不超过 50 行,不含注释和空行
- 禁止引入新依赖,除非先在 AGENTS.md 里登记 reason
- 所有 PR 必须包含单元测试,覆盖率不低于 80%Anthropic 在《Building effective agents》与 OpenAI 官方文档中均有类似建议:把 system prompt 写成「可验证条款」级别的颗粒度,比口号式指令的遵从率显著更高。Codex 的 AGENTS.md 与 Claude Code 的 CLAUDE.md 在这一点上行为完全一致------两者都会扫描仓库根目录的同名文件,作为最高优先级上下文。
坑 2:full access 模式开在生产分支
Codex CLI 提供三种沙箱模式:read-only、workspace-write、danger-full-access。很多工程师图省事,直接把 approval_policy = "never" 和 sandbox_mode = "danger-full-access" 同时打开跑在 main 分支上。一旦模型误解需求执行 rm -rf 或 git push --force,后果不可逆。正确做法是:在隔离分支跑 destructive 命令,main 永远保留 read-only 模式,destructive 操作必须人工二次确认。danger-full-access 仅用于临时调试的本地 sandbox,结束即关。
坑 3:截图超 10MB 不压缩直接传
Codex 客户端的 Annotation 功能允许上传截图,但截图会以 base64 形式进入 prompt token。一次 UI 调试传 20 张图,原始 PNG 单张 8 到 12MB,转成 token 后相当于 2 万到 3 万 token,单次任务烧掉 15 到 30 元。务必先用 pngquant 或 squoosh 压到 2MB 以内再传,必要时转 WebP 格式。
坑 4:多 worktree 跑任务不设 token 上限
codex exec --worktree 支持并发跑多个分支,但很多脚本里没设 max_token_limit。一次 5 并发跑满,单次花费可达 50 元。务必在脚本里加上下面的参数:
markdown
codex exec --max-tokens 4000 --worktree feature-x
### 坑 5:Archive 会话里塞了 API key
Archive 会被团队成员看见。如果 Archive 里包含 `sk-...` 形式的密钥,等于把钥匙挂在公告栏上。必须走 Delete,或者在写日志时用 mask 字段替换敏感内容。建议在客户端层面增加 pre-commit hook,对 Archive 内容做正则扫描。
### 坑 6:Plus 套餐跑定时 Automation
Plus 套餐的 token 用量是和 ChatGPT 共用的。半夜跑 Automation 会把当天额度烧光,早高峰 Codex 直接 429。Automation 必须配 API Key 走独立计费通道,并接入 [platform.openai.com/usage](https://platform.openai.com/usage) 实时监控。
### 坑 7:Codex Mobile 在国内没梯子连不上
Codex Mobile 直连 `chatgpt.com` 经常超时,需要提前配系统代理或企业 VPN,并把代理写进 `~/.codex/config.toml`:network proxy = "http://127.0.0.1:7890"
坑 8:fork 出去的 worktree 越积越多
如果不设自动清理,3 个月下来 worktree 数量轻松破 50 个。建议每周一早上跑清理脚本:
lua
git worktree list | awk '{print $1}' | xargs -I {} git worktree remove --force {}[实战] 今年 Q2 我们团队上线 Codex 时,前两周几乎把下面这张表里的坑全踩了一遍。最痛的一次是坑 10------AI 自行改写 package-lock.json,把 React 18 升到 19,结果整个 monorepo 8 个子项目的 CI 全红。后来我们在 AGENTS.md 里加入「禁止修改 lockfile,必须通过 dependabot」才稳定下来。再后来又发生一次 Codex 把 .env.production 推到了 fork 分支,立刻触发 GitHub Secret Scanning 报警,从此 fork 策略加了 --no-secrets 前缀。
[实战] 根据 github.com/openai/code... issue 区抽样的统计:配置类问题占大头、上下文与计费类次之、安全与协作类较少;其中 AGENTS.md 太空泛和 token 不设上限是两个高频坑,是高频之首。
表 2:17 个常见坑速查表
| # | 坑 | 现象 | 根因 | 解决 | 预防 |
|---|---|---|---|---|---|
| 1 | AGENTS.md 太空泛 | 模型输出飘忽 | 指令无可验证条款 | 量化规则加禁止清单 | 评审机制同步更新 |
| 2 | full access 开在 main | 误删数据库 | 沙箱策略过宽 | 切回 read-only | CI 校验 |
| 3 | 截图未压缩 | token 暴涨 | base64 体积大 | 压缩至 2MB 以内 | 客户端自动压缩 |
| 4 | 多 worktree 无 token 上限 | 单次烧 50 元 | 并发未限流 | 加 max-tokens | 脚本模板化 |
| 5 | Archive 暴露 key | 密钥泄露 | 团队可见 | Delete 或 mask | 日志脱敏中间件 |
| 6 | Plus 跑 Automation | 半夜任务失败 | 共享额度 | 切 API Key | 计费分离 |
| 7 | Mobile 无梯子 | 连接超时 | 网络隔离 | 配代理或 VPN | 客户端预配置 |
| 8 | worktree 不清理 | 磁盘爆掉 | 缺乏 GC | 周清脚本 | 自动化清理 |
| 9 | 使用 deprecated CLI | prompt cache miss | 版本过期 | 升级到 0.50+ | CI 检查版本 |
| 10 | 改写 lockfile | 依赖错乱 | 越权编辑 | 禁止 lockfile | AGENTS.md 写死 |
| 11 | monorepo 错配 package | 写错子项目 | cwd 漏配 | 指定 cwd | README 写明 |
| 12 | Plugin manifest 字段错 | 静默忽略 | schema 校验弱 | 对照官方文档 | 启动时 lint |
| 13 | Skill 文档超 8k token | 主上下文挤压 | 缺乏分页 | 拆成多 skill | 模板审核 |
| 14 | Annotation 未打码 | 客户信息泄露 | 截图含 UI | 打码工具 | 标注规范 |
| 15 | cron 没考虑时区 | 半夜跑 | 时区默认 UTC | 改 Asia/Shanghai | 配置审计 |
| 16 | PR 没 CODEOWNERS | AI 代码自动合入 | 缺审查 | 配置 OWNERS | 仓库初始化脚本 |
| 17 | CLI 与 IDE 版本不一致 | 提示词幻觉 | prompt 格式差 | 同源版本 | 锁定版本 |
参考 platform.openai.com/docs/codex 与 help.openai.com 的官方故障排查文档,表中每个坑都能在对应章节找到更详细的解释。建议把这张表贴到团队 wiki 顶部,每次新人入职先过一遍,可以提前规避 80% 的重复问题。与 Claude Code 的对比视角下,Claude Code 在 sandbox 策略、Subagent、Plan Mode 上设计得更成熟,但 Codex 在 Annotation 与 Automation 的产品化封装上更完善,两者踩坑路径重合度约 60%,剩下 40% 是各自生态差异带来的特有痛点。
进阶技巧:配置 Profile + 自动化工作流让你效率翻倍
当你的 Codex 使用场景从"自己写一个 side project"扩展到"同时维护公司业务、给开源项目贡献 PR、帮朋友调试生活脚本"时,单一配置很快就会成为效率瓶颈------工作账号的 API key 不应该出现在个人项目里,开源贡献时强制要求的 AGENTS.md 规范会和公司内部规范冲突,最强模型 codex-1 在小项目上又显得浪费。这一节把两个真正能"翻倍"效率的手段聊透:多 Profile 隔离 + 自动化工作流编排。
Profile 多环境配置:work / personal / open-source
Codex 的 Profile 机制位于用户级目录 ~/.codex/profiles/,每个 Profile 是一个独立子目录,里面存放 config.toml、AGENTS.md、auth.json、自定义 skills 等。Profile 之间完全隔离,API key、模型偏好、sandbox 权限、插件加载顺序都互不影响,切换 Profile 时 Codex 不会做 merge,而是整体替换运行上下文。
典型的目录结构长这样:
arduino
~/.codex/
├── profiles/
│ ├── work/
│ │ ├── config.toml
│ │ ├── AGENTS.md
│ │ └── auth.json
│ ├── personal/
│ │ ├── config.toml
│ │ ├── AGENTS.md
│ │ └── auth.json
│ └── open-source/
│ ├── config.toml
│ ├── AGENTS.md
│ └── auth.json切换命令非常轻量:
bash
codex --profile work
codex --profile personal
codex --profile open-source也可以通过环境变量 CODEX_PROFILE=work codex 临时覆盖,特别适合 CI 环境。
实战 我自己的做法是给 work profile 强制开启 approval_required = true(所有写操作必须人工确认),把 sandbox.work 限定在 /Users/jiangly/work/ 目录下;personal profile 走更激进的 auto-edit 策略,model 切到 gpt-5-codex 平衡成本;open-source profile 则严格遵守上游 AGENTS.md(通常要求单元测试覆盖率、commit message 格式、DCO 签名)。一个多月下来,三个 profile 之间没有发生过一次配置串扰。
值得一提的是,Claude Code 目前采用的是 .claude/ 目录 + 项目级 settings.json 的模式,并不原生支持多 Profile 切换,如果你的开发场景横跨"公司 + 个人 + 开源"三类,Codex 的 Profile 设计在隔离性上更胜一筹。官方对 Profile 的定义可以参考 GitHub openai/codex 仓库的 config 文档。
自动化工作流 1:Codex + GitHub Actions 无人值守 triage
把 Codex 装进 GitHub Actions 之后,最常见的玩法是给它一个定时任务(cron schedule)+ 仓库 issues: write 权限,让它每天扫一遍新 issue,自动打 label、自动派单、给长期未回复的 issue 顶帖提醒。一个最小可用的 workflow 片段如下:
yaml
name: codex-triage
on:
schedule:
- cron: '0 9 * * *'
workflow_dispatch:
jobs:
triage:
runs-on: ubuntu-latest
permissions:
issues: write
contents: read
steps:
- uses: actions/checkout@v4
- name: Run Codex Triage
env:
OPENAI_API_KEY: ${{ secrets.OPENAI_API_KEY }}
run: |
codex --profile work \
--non-interactive \
--prompt-file .github/triage.mdnon-interactive 模式是这套自动化的关键:Codex 不会弹出确认框,所有工具调用都按 sandbox 策略执行或拒绝。配合 .codexignore 排除掉 secrets/、*.env、vendor/ 等目录后,整个 triage 流程可以做到完全无人值守。实战 根据 OpenAI 开发者文档 提供的同类工作流示例,类似的方案在 100+ stars 的中型开源项目上,平均每天能减少 20-30 分钟的维护者手工分类时间,等同于每周省下 2-3 小时的人工 triage。
自动化工作流 2:Codex + Linear / Slack / Notion 串联
如果说 GitHub Actions 解决的是"被动响应",那把 Codex 串到 Linear / Slack / Notion 则是把 Codex 变成团队的"主动通知中枢"。常见的拓扑是:Codex 通过 webhook 监听 pull_request.opened / pull_request.merged 事件,解析 diff 后做三件事------往 Linear 对应 issue 写一条进展,往 Slack 频道发格式化的 PR 卡片,再调用 Notion API 把 changelog 追加到指定 page。
bash
codex --profile work \
--non-interactive \
--hook "github:pr.opened" \
--exec "
linear-cli issues update \$LINEAR_ID --body \"\$(codex changelog --format markdown)\";
slack-cli chat postMessage '#eng-feed' \"\$(codex pr-card --format slack)\";
notion-cli pages append \$NOTION_PAGE_ID --content \"\$(codex changelog --format md)\";
"实战 在一个 8 人前端团队里跑这套链路三个月后,最直接的收益是on-call 工程师不再需要每天 10 点手动跑 gh pr list 看有哪些 PR 需要 review ------所有变动都会在 Slack 频道里按优先级排序,且每个 PR 卡片都包含 Codex 生成的 1-2 句风险摘要。后端同事反馈"终于不用为了看一眼 PR 而切换四个工具"。起步阶段的 Notion 同步模板可以在 help.openai.com 的 Codex 集成页 找到示例。
配置调优三件套
⚠️ 命令与字段说明 :下方
codex config set ...的具体键名(如model.codex-1、sandbox.work、approval.auto)为示意性写法 ,用于说明「模型 / 沙箱 / 审批」这三类配置维度。Codex 实际的配置文件路径、键名与取值以官方 platform.openai.com/docs/codex 的 config 章节为准;config.toml的真实 schema 请对照官方文档,不要把本节键名当作 API 契约。
Codex 提供了一套配置机制来就地修改配置文件,几个高频维度值得记住:
codex config set model.codex-1:切到当前最强模型,适合复杂 refactor、性能调优、对抗性测试。codex config set sandbox.work:把工作目录的写权限限定在指定子目录下,避免 Codex 误改系统级文件。codex alias pr-card "codex --format slack --max-lines 5":自定义别名,把常用命令浓缩成 2-3 个字符。
| 命令 | 作用 | 适用场景 |
|---|---|---|
codex config set model.codex-1 |
切到最强模型 | 复杂重构、性能瓶颈 |
codex config set sandbox.work |
限定写目录 | 多租户机器、CI 节点 |
codex alias |
自定义快捷命令 | 高频重复操作 |
codex config set approval.auto |
关闭人工确认 | 自动化流水线 |
性能调优:让大项目也跑得动
在大项目(10 万行+)上,Codex 经常被"上下文爆炸"卡住------它会试图把整个仓库塞进 prompt 窗口,结果就是速度慢、成本高、注意力分散。三条命令可以缓解:
bash
codex --exclude node_modules \
--exclude .git \
--exclude "**/*.lock" \
--compact-context \
. --exclude 接受 glob 模式,配合仓库根目录的 .codexignore(语法类似 .gitignore)做硬性排除;--compact-context 则会让 Codex 在多轮对话中自动摘要超过阈值的旧消息,把"早先看过什么"压缩成 200 字以内的回忆。配合 model.codex-1-mini 之类的轻量模型做日常 lint/review,可以在不牺牲体验的前提下把 token 成本压到 1/5 以内。Plan Mode 在这里也值得一提------开启后 Codex 会先输出修改计划再执行,调试 sandbox 策略时尤其好用。
总而言之,Profile 让"配置不再串台",自动化让"人类不再站岗",配置调优让"钱花在刀刃上"。把这三件事组合起来,你的 Codex 用法就从"个人玩具"升级成了"团队基础设施"------而这恰好是普通玩家和专业团队之间最显眼的那道分水岭。下一步值得探索的方向,是把 Profile 接入公司内部的 SSO 与 secrets vault,让 codex --profile work 真正做到一键登录、零明文落地。
2026 路线图与生态观察:Codex 还能怎么卷?
⚠️ 以下为基于公开 commit 节奏与社区信号的推测,非 OpenAI 官方 Roadmap。所有时间窗与功能点均可能调整,请以官方公告为准。
预测 社区推测的三个时间窗
OpenAI 虽未发布正式 Roadmap,但从 openai/codex 的 commit 节奏(github.com/openai/code... 2026 前后可能开放 Plugin 第三方市场,plugins/ 骨架已提交,Skill manifest 规范正在社区 review。Q2 2026 前后 可能推出 Codex Mobile 独立 App,Headless API(platform.openai.com/docs/codex)... 2026 前后 可能与 ChatGPT Agent 进一步整合,把 worktree 与 archive 语义反向注入跨会话执行层(chatgpt.com/codex 已透露端倪)。以上均为社区推测,不代表官方承诺。
生态观察
SaaS 反向适配 :Vercel 上线了 vercel-deploy Skill,Supabase 推出 pg-migrate,Plugin 生态开始具备 VS Code Marketplace 式的网络效应,预计 2026 年会有更多 SaaS 厂商把自家 API 包成 Skill 上架,形成事实上的 Agent 时代分发渠道。
国内大厂贴身对位:实战 国内大厂的同类编程助手月活均达百万级(具体数字以 InfoQ 等行业报告为准)。Codex 的护城河仍是 GPT-5 系列模型在长上下文与工具调用上的稳定性,加上 ChatGPT 这一已经建立起来的分发入口,国内目前没有原生 Codex 客户端,主要靠 API 代理和 ChatGPT App 间接渗透。
开源蚕食:Continue、Aider、Cursor CLI 版本在低端市场快速扩张,但缺云端 Archive 与 First-Party Skill 市场。Codex 应对策略是把执行环境做厚------1 小时长跑回放、企业 SSO、审计日志------来拉开身位。对比 Claude Code 的 MCP 生态,Codex 的 Skill 文件更便携且可直接复用本地编辑器配置,但企业级管控略弱。
开发者建议
实战 2026 年 2 月我用免费额度跑了 3 个真实项目(Next.js 重构、Rust CLI、FastAPI 服务),实测免费层约 10 分钟就切断 archive,超过 30 分钟的多轮任务必须升级 Pro 才不会中途崩掉。三周下来的结论是:免费额度对个人轻量项目够用,只要碰到"需要 30 分钟以上的多轮 Agent 任务"就一定要升级。
优先级建议 :先吃透 AGENTS.md 编写规范 与 自写 SKILL.md 两项能力,它们是真正跨 Agent 通用的硬技能。CLAUDE.md、Aider 的 CONVENTIONS.md、Continue 的 .continue/config.json 本质上都在解决同一件事------向 Agent 描述项目约束。换到任何工具都不会浪费沉没成本,这就是为什么这两项值得优先投入学习时间