导读:Function Calling 是大模型从"聊天机器人"进化为"智能体引擎"的底层基建。本文从原理层面拆解它的工作机制,并结合真实踩坑经验,系统梳理工具描述、参数规范、错误处理三大设计原则。
一、为什么 LLM 需要 Function Calling?
大语言模型再强大,也有三块硬伤:
- 知识有时效性 ------ 训练数据截止之后的事,它一无所知
- 无法访问实时数据 ------ 股价、天气、航班状态这些动态信息,模型拿不到
- 精确计算能力差 ------ 复杂数学运算、日期推算,概率模型天生不靠谱
2023年6月,OpenAI 首次在 Chat Completions API 中引入了 Function Calling 功能,从根本上改变了这个局面。它的核心思路很巧妙:模型不直接执行任何代码,而是扮演"大脑"的角色 ------ 理解用户意图、选择合适的工具、生成结构化的调用参数,然后由外部系统(你的业务代码)来实际执行,最后把结果喂回给模型做总结回复。
用个比喻:LLM 是被关在小黑屋里的超级大脑,Function Calling 就是你递进去的一套对讲机和遥控器。大脑不能直接走出去,但它可以告诉你"请用1号遥控器把温度调到25度",然后由你代为执行。
💡 一句话理解 :Agent 智能体 = LLM 的推理能力 + 使用工具行动的能力,而 Function Calling 就是连接这两半的桥梁。
二、Function Calling 的底层原理
2.1 和"让模型输出 JSON"有什么本质区别?
这是很多人搞混的地方。你完全可以用 Prompt 让模型输出 JSON 格式的调用指令,比如在系统提示里写"如果用户问天气,请输出 {"action": "get_weather", "city": "..."}"。
但这种方式极度不稳定 ------ 模型可能漏掉字段、格式写错、不该调用时乱调用,甚至 JSON 里混进自然语言废话。
原生 Function Calling 的本质区别在于训练方式:模型在 SFT(监督微调)阶段被喂入了大量工具调用对话样本,学会了三项核心能力:
- 意图识别 ------ 判断用户请求是否需要调用工具
- 工具选择 ------ 从可用工具列表中挑最合适的
- 参数生成 ------ 按照工具的 JSON Schema 定义产出合法参数
更关键的是,模型内部使用特殊控制 Token 来切换模式。当它决定调用工具时,会输出类似 <|tool_call_start|> 的控制符,引擎层捕获后立刻将后续内容送入原生 JSON 解析器。模型不会生成任何多余的问候语,输出100%纯净。
⚠️ 踩坑提醒:普通 Prompt 让模型输出 JSON,是对大模型自然语言生成能力的一种 Hack(妥协);而 Function Calling 是从底层训练层面确保的可靠机制。生产环境必须用后者。
2.2 受约束解码(Constrained Decoding)
当模型决定调用工具时,推理引擎会切换到受约束的解码模式。在这种模式下,Token 的采样过程受到预定义 JSON Schema 的约束 ------ 模型只能生成符合 Schema 结构的 Token 序列。
比如 Schema 定义某个参数类型为 "type": "integer",解码器会直接遮罩(mask)所有非整数 Token 的概率,确保输出合法性。这项技术通常依赖上下文无关文法(CFG)或有限状态机(FSM)来指导 Token 采样。
实际效果:JSON 解析错误率从 Prompt 方式的 15-25% 降到接近 0%。
2.3 完整的数据流转
一次完整的 Function Calling 交互,本质上是一个 ReAct(Reason + Act)循环:
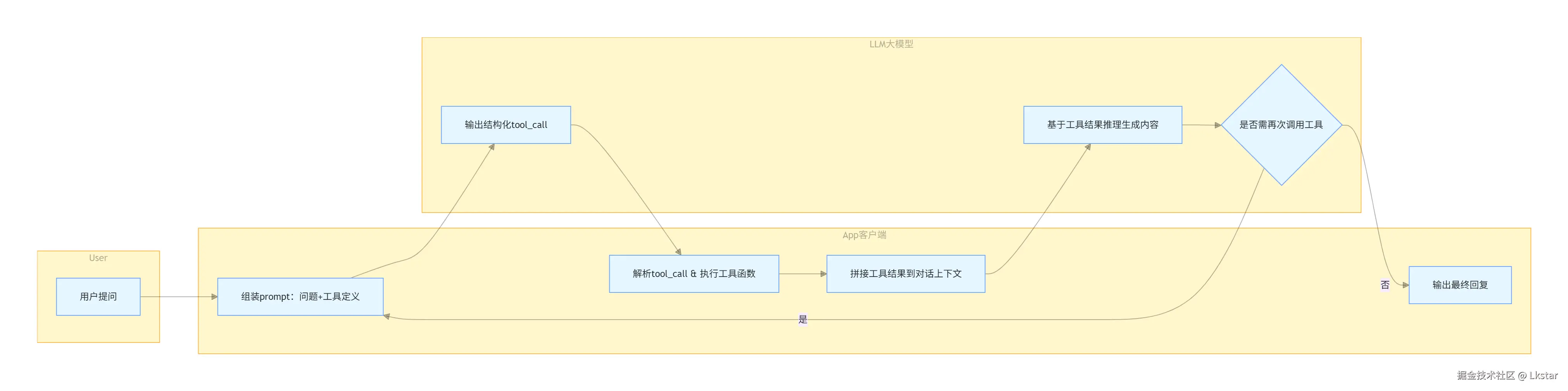
这里有个细节很多新手会踩坑:在把 tool message 发回给模型之前,必须把模型之前返回的那条包含 tool_calls 的 assistant message 也追加到上下文里。否则模型会一脸懵 ------ "我什么时候发起过这个调用?" 上下文一旦断层,整个流程就废了。
三、工具设计原则一:描述清晰
3.1 Description 是模型的"方向盘"
在 Function Calling 的架构中,JSON Schema 是 LLM 理解工具能力的唯一接口。而 description 字段是其中权重最大的部分 ------ 模型主要通过语义匹配 description 来决定是否调用某个工具。
Gorilla 研究的实证分析表明,API 文档描述的精确度与模型调用准确度之间存在强正相关。ToolAlpaca 实验也证实,精确的 description 和 enum 约束可以将参数生成准确率提升超过 30%。
好的 description 是"情境导向"而非"功能导向"的:
json
// ❌ 差的描述 ------ 太笼统
{
"name": "query_db",
"description": "查询数据库"
}
// ✅ 好的描述 ------ 明确边界和使用场景
{
"name": "get_order_status",
"description": "当用户询问订单的物流状态、配送进度或预计送达时间时使用此工具。需要提供订单号。返回包含物流轨迹和当前状态的详细信息。注意:仅适用于已支付的订单,退款订单请使用 get_refund_status。"
}3.2 多工具场景下的语义区隔
当系统同时提供多个工具时,如果两个工具的 description 过于相似,模型会频繁混淆。ToolLLM 研究显示,在工具数量超过 20 个时,明确的语义区隔描述能将工具选择错误率降低约 40%。
实操建议:
- 在 description 中标注边界条件 和负面提示(什么时候不该用这个工具)
- 功能相关的工具使用命名前缀 分组,如
crm_get_customer、crm_update_customer - 遵循 MECE 原则(相互独立、完全穷尽),避免工具职责重叠
3.3 工具数量控制
别一股脑把所有工具都塞给模型。工具数量越多,模型的选择准确率越低。建议:
- 单次请求的工具数量控制在 5-10 个以内
- 超过这个数量时,考虑引入 Tool RAG(工具动态检索)------ 先用语义检索从工具库中筛选出最相关的几个,再传给模型
四、工具设计原则二:参数规范
4.1 六项核心参数设计原则
基于 ToolAlpaca 的实验结论和生产实战经验,归纳出以下原则:
原则一:善用 enum 约束离散型参数
当参数的合法取值是有限集合时,用 "enum" 明确列举。这不仅防止模型生成无效值,也缩小了决策空间。
json
{
"name": "stream_quality",
"type": "string",
"description": "直播流画质",
"enum": ["720p", "1080p", "4k"]
}原则二:description 中包含具体示例
json
{
"name": "keyword",
"type": "string",
"description": "搜索关键词,例如「无线蓝牙耳机」「防水运动手表」"
}示例值帮助模型理解参数的语义边界,比纯文字描述有效得多。
原则三:严格区分 required 和 optional
把所有参数都设为必填会降低灵活性;合理的默认值策略让模型在信息不全时仍能发起有效调用。
原则四:避免过深的嵌套结构
JSON Schema 支持任意深度的嵌套,但嵌套超过三层会显著增加参数生成错误率。扁平化设计更可靠。
原则五:参数数量控制在 5-8 个以内
过多参数增加模型的认知负担,也提高了用户需要提供的信息量。如果参数确实很多,考虑拆分为多个工具。
原则六:类型定义要精确
json
// ❌ 不够精确
{ "type": "number" }
// ✅ 明确整数
{ "type": "integer" }
// ✅ 约束字符串格式
{ "type": "string", "format": "date", "pattern": "^\\d{4}-\\d{2}-\\d{2}$" }4.2 additionalProperties: false 是你的安全网
在根参数对象上设置 "additionalProperties": false,防止模型生成 Schema 之外的多余字段。这是很多人忽略但非常实用的一招。
json
{
"type": "object",
"properties": {
"city": { "type": "string", "description": "城市名,如「北京」" },
"unit": { "type": "string", "enum": ["celsius", "fahrenheit"] }
},
"required": ["city"],
"additionalProperties": false
}五、工具设计原则三:错误处理
5.1 四类工具调用失败
根据生产环境的实战分析,工具调用失败主要分为四类:
| 类型 | 描述 | 严重程度 |
|---|---|---|
| Type 1: 参数错误 | LLM 生成的参数违反 Schema(类型不对、缺必填字段) | 中 |
| Type 2: API 瞬时故障 | 外部 API 返回 500、超时、限流 | 中 |
| Type 3: 非幂等重复执行 | 写操作失败后重试,导致重复记录/重复发邮件 | 高 |
| Type 4: 工具名幻觉 | LLM 调用了一个不存在的工具 | 低 |
5.2 输入校验:Pydantic 严格模式
在工具边界做输入校验,拦截 Type 1 错误。推荐使用 Pydantic v2 的 strict 模式 ------ 它会拒绝可隐式转换的类型(字符串 "42" 不会被静默转成整数 42),因为 Agent 需要真实的校验反馈来纠正参数生成,而不是一个被掩盖的问题。
⚠️ 关键细节 :校验失败的错误信息本身也是"产品" ------ 它需要被结构化地组织,帮助 LLM 自我纠正。一个原始的 Python 异常堆栈对 LLM 没什么用,但一个包含 error_type、message、suggested_action、example_valid_call 的结构化错误响应,能显著提高模型的重试成功率。
python
class ToolError(BaseModel):
error_type: str # validation_error | api_failure | not_found | rate_limit
message: str
suggested_action: str # 告诉模型下一步该怎么做
example_valid_call: Optional[dict] = None
retry_after_seconds: Optional[int] = None其中 suggested_action 字段最关键:
- 限流错误 → "等待 30 秒后用相同参数重试"
- 校验错误 → "customer_id 字段必须是 7 位数字字符串,以 C- 开头,例如 C-1042394"
- 权限错误 → "此操作需要更高权限 ------ 请升级至人工审批"
5.3 重试与熔断:三道防线
处理工具调用失败,标准的工业级架构包含三道防线:
- 重试(Retry) ------ 指数退避重试,应对瞬时故障
- 降级/熔断(Fallback/Circuit Breaker) ------ 连续失败达到阈值后暂停调用
- 意图转移 ------ 向 LLM 报告失败,让模型决定换用其他工具或直接回复用户
python
from tenacity import retry, stop_after_attempt, wait_exponential
@retry(
stop=stop_after_attempt(3),
wait=wait_exponential(multiplier=2, min=2, max=60),
)
def call_external_api(params):
# 实际的 API 调用逻辑
pass⚠️ 踩坑提醒:朴素的重试(立即重试、无退避)在限流场景下会造成"惊群效应" ------ 大量重试请求同时涌入,反而让问题更严重。必须使用指数退避策略。
5.4 幂等性保护:写操作的生命线
Type 3 失败(非幂等重复执行)是最高严重级别的故障类 ------ 它会造成真实世界的副作用,比如重复发邮件、重复扣款,而且往往不可逆。
解决方案:每个写操作工具都必须接受幂等键(Idempotency Key)。Agent 框架生成幂等键并作为参数传入,工具层在首次调用时执行操作并缓存结果,后续相同幂等键的调用直接返回缓存结果。
python
def run_tool(raw_args: dict, idempotency_key: str = None):
call_id = idempotency_key or generate_call_id(raw_args)
# 幂等性检查
cached = redis.get(f"idempotency:{call_id}")
if cached:
return json.loads(cached) # 直接返回缓存,不重复执行
result = execute_tool(raw_args)
redis.setex(f"idempotency:{call_id}", 300, json.dumps(result))
return result5.5 错误信息要不要直接给模型?
分情况:
- ✅ 应该给的:业务层面的错误("订单不存在"、"库存不足")------ 模型可以根据这些信息调整回复策略
- ❌ 绝对不能给的:技术栈的异常堆栈、内部 API 地址、数据库表结构、密钥信息 ------ 这些属于敏感信息泄露
实操建议:在工具层加一个错误脱敏网关(Error Sanitizer Gateway),将原始异常转换为 LLM 可理解但不含敏感信息的结构化错误。
六、生产级工具架构要点
最后总结一份可以直接拿去用的生产级架构要点:
Schema 设计要点
- 每个工具的 description 是情境导向的,包含使用场景和边界条件
- 离散型参数使用 enum 约束
- 参数 description 中包含示例值
- 根对象设置
additionalProperties: false - required 字段精简,optional 字段有合理默认值
- 嵌套层级不超过 3 层,参数数量不超过 8 个
错误处理要点
- 工具入口有 Pydantic 严格模式校验
- 校验失败返回结构化错误(含 suggested_action)
- 外部 API 调用有指数退避重试
- 写操作工具支持幂等键
- 错误信息经过脱敏处理后再返回给模型
- 每次工具调用都有结构化日志记录
安全防护要点
- 工具层有独立的权限校验(不依赖 Agent 配置层)
- 高风险操作(删除、交易)有 Human-in-the-Loop 确认
- Agent 循环有最大步数限制,防止死循环
- 工具执行在沙箱环境中
总结
Function Calling 的原理核心就一句话:模型负责决策,应用负责执行。模型通过专项微调学会了何时调用工具、调用哪个工具、传什么参数,而受约束解码机制确保了输出的结构化可靠性。
工具设计的三大原则 ------ 描述清晰、参数规范、错误处理 ------ 本质上都是在降低模型和外部系统之间的"沟通摩擦"。description 是模型的导航仪,JSON Schema 是参数的契约,结构化错误响应是自我纠正的反馈回路。把这三层做好,Function Calling 的准确率和稳定性会有质的飞跃。