大家好,我是二哥呀。
粗略算一下,我每个月的token账单在 4000 多,其中 Claude 和 Codex 占大头。
说不心疼是假的,但这些钱在AI时代又必须得花,因为几乎每天都在高强度使用。

尤其是处在项目密集开发期的时候,token的消耗非常大,所以我对免费的 token 是非常渴望的。
这不,必须得告诉大家一个好消息。
Agnes AI 宣布无限期免费开放全模态模型 API。文本、图片、视频,三条线全免费,不限量哦。

我拿到的一个数据样本是这样的。全模态总Token调用量达到3.12T,其中文本模型 Agnes-2.0-Flash 贡献了约1.9T;视觉模型Agnes-Image-2.1-Flash + Agnes-Video-2.0 合计贡献了约1.2T。
非常恐怖的一个数据啊!
说明大家对免费token的需求真的非常大。
我也是第一时间就把 Agnes 的这三个模型接到了 PaiAgent(我的一个开源项目),从文本对话到图片生成到视频输出,一条龙跑完。
系好安全带,我们粗粗粗发~
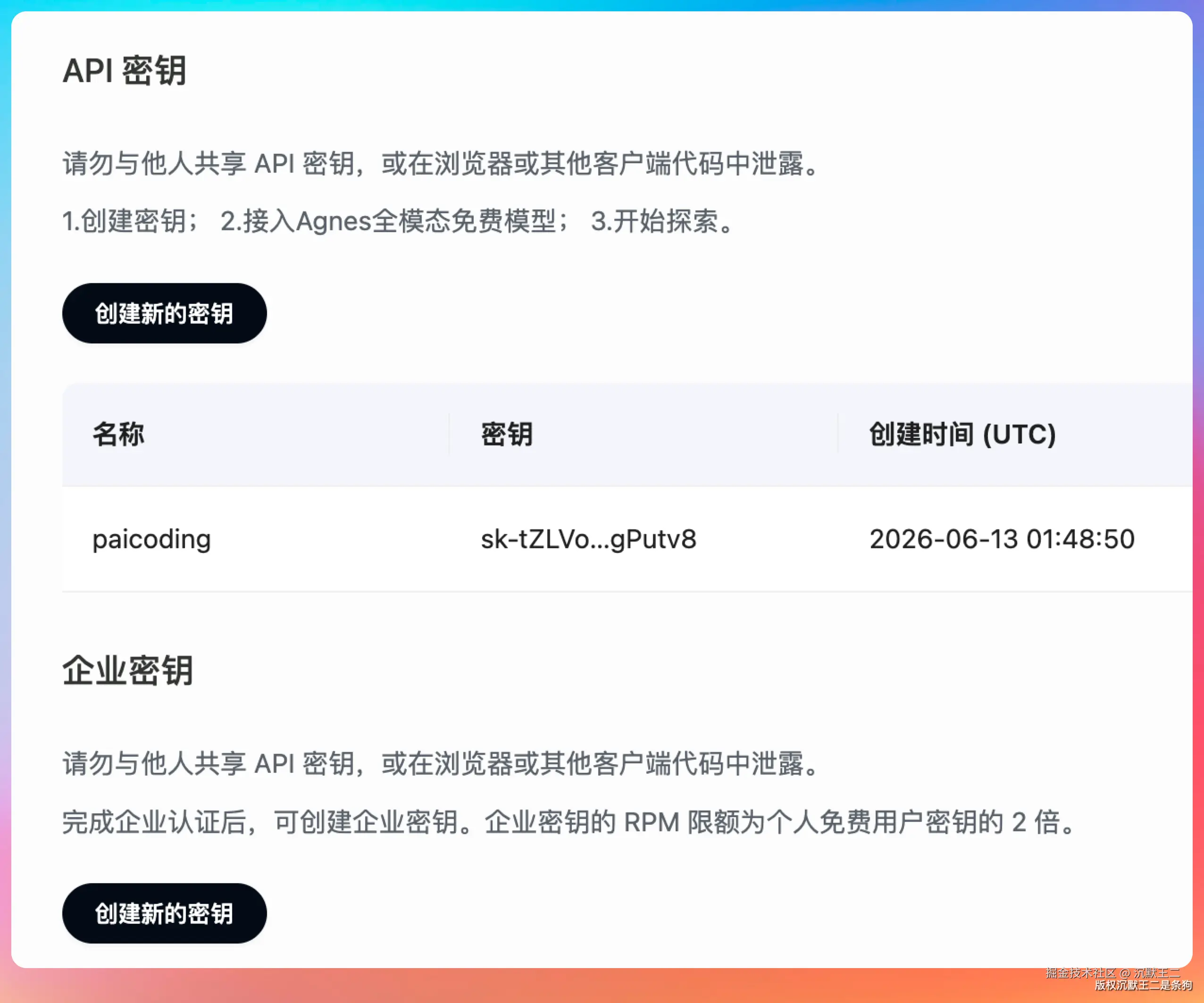
01、先把 API Key 搞到手
Agnes 的注册流程很快
登录后在控制台创建 API Key。
Agnes 的 API 是兼容 OpenAI 格式的,Base URL 是 https://api.agnes-ai.com/v1,认证方式和 OpenAI 一样,在 Header 里传 Authorization: Bearer <API_KEY>。
这意味着市面上所有支持 OpenAI 接口的工具、框架和平台,改一下 Base URL 和 API Key 就能直接用 Agnes 的模型。
简单给大家介绍下,PaiAgent是一个类似dify的企业级工作流编排平台,用到了LangGraph4J、SpringAI、MCP、Skill、React等一系列 AI Agent 相关的技术栈。
好,我们继续上实战。
在 PaiAgent 的全局模型配置里,新建一个配置,供应商选 Agnes,API 地址填图上有,模型名填 agnes-2.0-flash,API Key 填之前复制的那个。
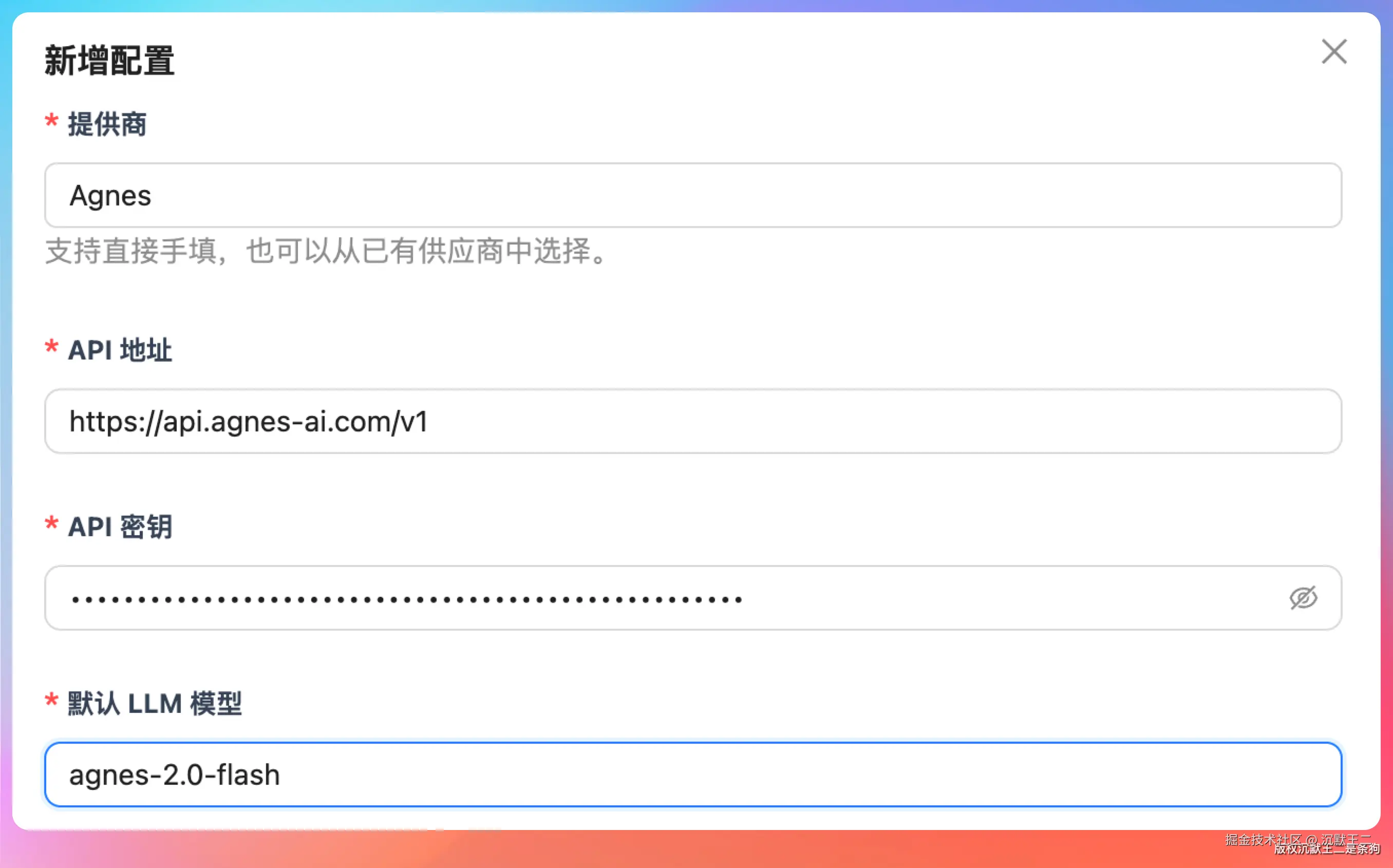
为了支持图片和视频生成,图片模型填 agnes-image-2.1-flash,视频模型填 agnes-video-2.0,保存即可。
TTS 预计本周五灰度,到时候我也会第一时间接入。
有了语音能力,Agnes 就真正实现了全模态覆盖,文本、图片、视频、语音四条线齐活。
02、文本模型Agnes-2.0-Flash
Agnes-2.0-Flash 是一个通用文本模型,覆盖对话、代码生成、知识问答、任务规划和工具调用。
在 Claw-Eval 评测中,它的 Safety 得分达到 97.2、Robustness 得分 95.4,这两个维度衡量的是模型在对抗性输入下的稳定性和安全性,属于 Agent 场景下的硬指标。
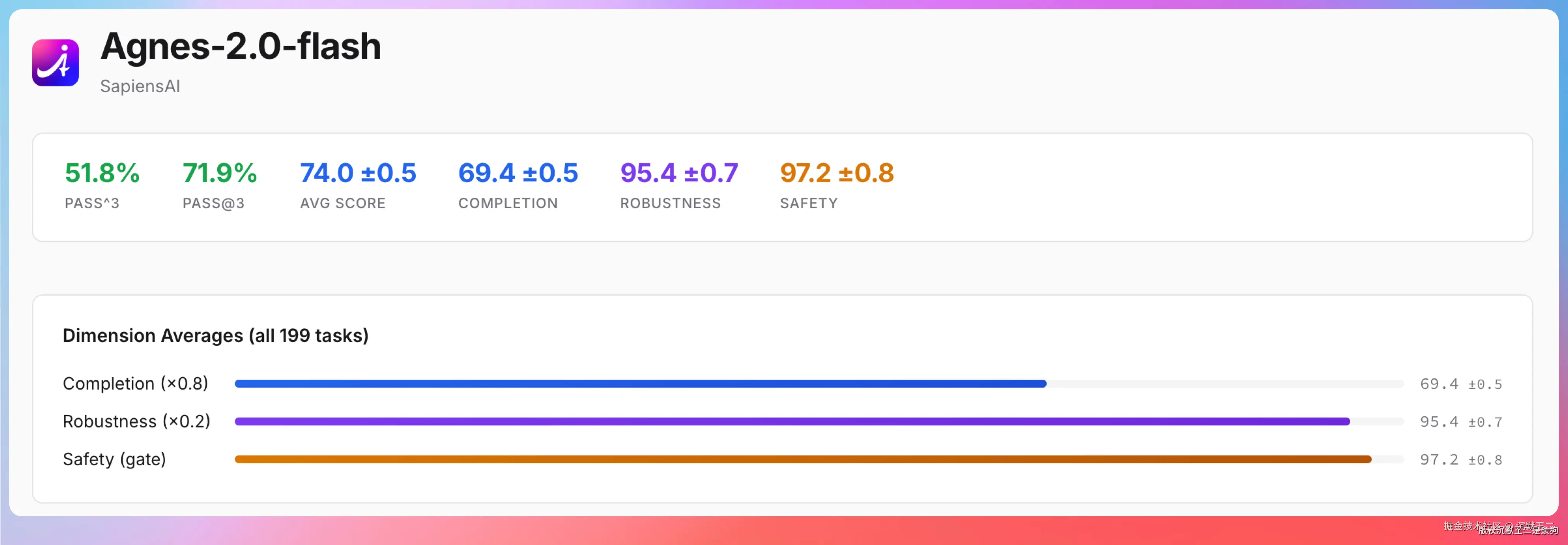
Claw-Eval 和传统 Benchmark 不同,评测的不是数学题和选择题,而是模型在真实 Agent 场景下的综合执行能力,包括工具调用准确性、多步骤规划和复杂上下文保持。
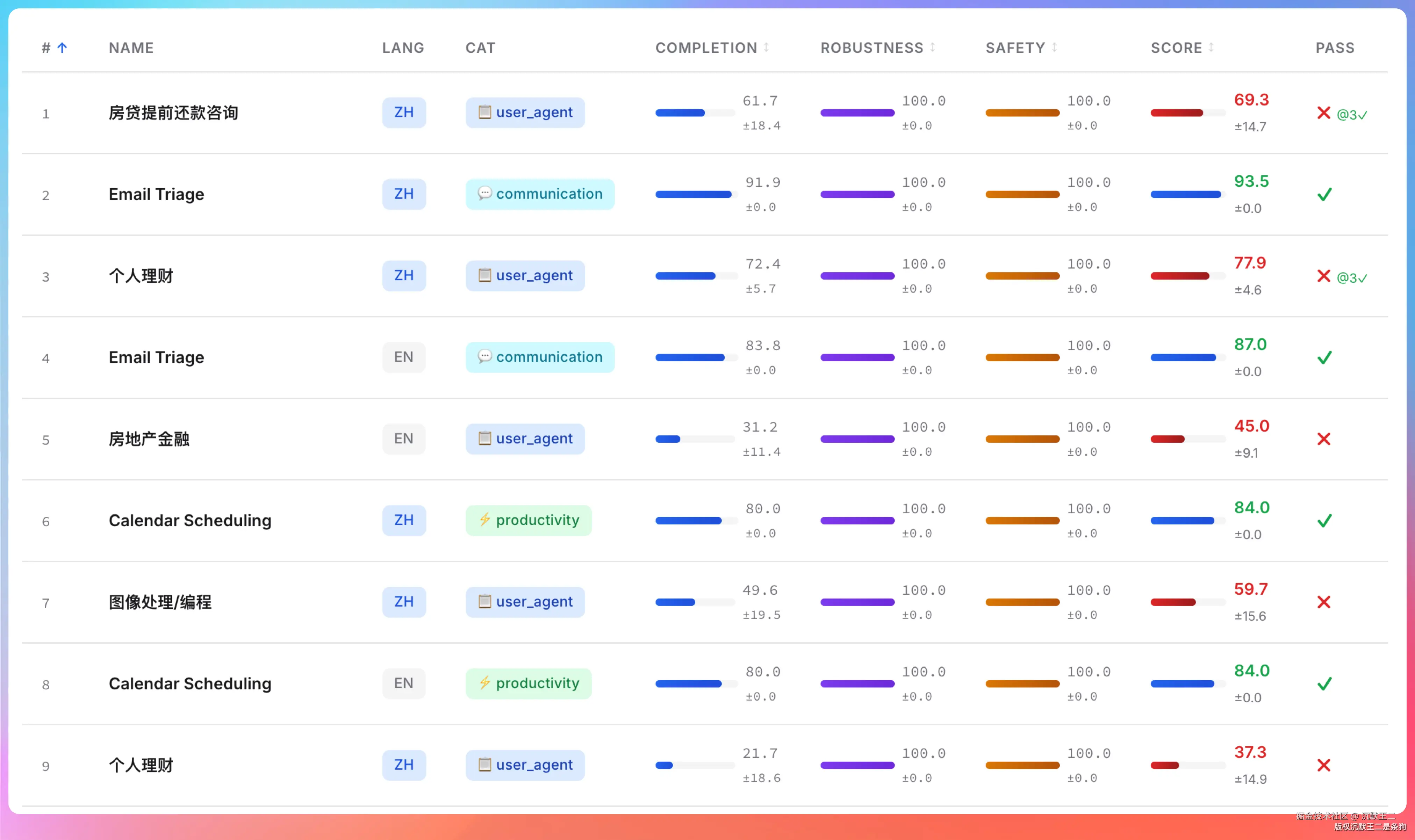
是最接近 AI Agent 实战能力的评测。
Agnes-2.0-Flash 已支持 1M 上下文,我在 PaiCLI 里设计了三个测试用例,分别验证长文档理解、代码生成和工具调用能力。
第一个测 1M 上下文。我把 Spring AI 的官方文档(大约 15 万字)整份喂给 Agnes-2.0-Flash,然后问它"Spring AI 的 Tool Calling 和 MCP 的 Function Calling 在实现机制上有什么区别"。这个问题的答案散落在文档的不同章节里,需要模型把前面关于 Tool 注解的描述和后面关于 MCP 协议的细节关联起来才能回答准确。Agnes 给出的答案准确抓住了两者在设计层面的核心差异,引用的内容也能在原文档中对应上。换成 128K 上下文的模型,这份文档塞不进去,只能先做 RAG 检索再拼接,中间的信息损失不可避免。
第二个测代码生成。我让它从零写一个完整的 Spring Boot REST API demo,要求包含用户 CRUD、JWT 认证和 Swagger 文档配置。生成的代码结构清晰,Controller、Service、Repository 分层合理,JWT 过滤器的实现也没有明显的安全漏洞。拿过来跑 mvn spring-boot:run,改一下数据库连接就能启动。我还追加让它加上参数校验和全局异常处理,补充的代码和前面生成的风格保持一致,没有出现前后矛盾的情况。对于一个免费模型,这个代码生成质量够用了。
第三个测工具调用(Function Calling),这也是 Claw-Eval 重点考察的能力。PaiCLI 内置了 read_file、write_file、execute_command、grep_code、web_search 等工具,模型需要根据用户意图自主判断调用哪个。我测了一个复合场景,让它"查一下 PaiCLI 项目里有没有硬编码的 API Key,找到的话帮我改成从环境变量读取"。Agnes-2.0-Flash 先调 grep_code 搜关键词,再调 read_file 确认上下文,最后调 write_file 完成修改,整条工具调用链的参数格式全部正确,也没有凭空捏造工具名。对于编码助手来说,工具调用的准确性比对话质量更重要。
这个模型免费前的价格是输入 0.03/1Mtokens、输出0.15/1M tokens,大概是同类模型价格的一半。现在直接免费了。
03、图片模型 Agnes-Image-2.1-Flash
Agnes-Image-2.1-Flash 在 Artificial Analysis 的图片质量评测中取得了 Elo 1191 的成绩(基于 4494 个样本的盲评数据)。这个评测用的是真实用户盲评机制,评测者不知道图片是哪个模型生成的,纯粹按画面质量打分。作为一个免费模型,能在以付费模型为主的榜单里站住脚,已经超出预期。
【此处插入Artificial Analysis 图片榜单截图:截图目标:证明 Agnes 图片模型在盲评榜单中的排名;关键词:Artificial Analysis、图片编辑、排名;建议位置:网页】
免费前的价格是 3/1000张图,相比海外部分图像模型30/1000 张的定价,Agnes 本来就便宜。现在连这 3 块钱都省了。
图片模型的 API 同样兼容 OpenAI 格式,核心参数就四个。
json
{
"model": "agnes-image-2.1-flash",
"prompt": "提示词",
"size": "1K",
"ratio": "1:1"
}size 支持 1K、2K、3K、4K 四档,ratio 支持 1:1、3:4、4:3、16:9、9:16、2:3、3:2、21:9 八种宽高比。本周 4K 输出能力上线后,最高可以生成 4096×4096 的超高清图像。
我在 PaiAgent 里用图片生成节点实测了几个场景。
文生图,提示词是"一座城市夜景,高楼林立,霓虹闪烁,雨水反射着光影,赛博朋克风格,整体很有电影感"。出图速度大约 4-5 秒,画面的光影层次和雨水反射细节确实到位,赛博朋克的氛围感很到位。
【此处插入赛博朋克城市夜景生成图:截图目标:展示文生图的画面质量;关键词:赛博朋克、城市夜景、光影;建议位置:网页】
人像生成,提示词是"一位面目沧桑的老人,高品质,照片级真实感,王家卫电影风格,使用柯达 Portra 800 胶卷拍摄,高对比度"。这张图我反复看了好几遍,皮肤纹理、光影过渡、胶片颗粒感都有,不像 AI 生成的"塑料感"。
【此处插入老人人像生成图:截图目标:展示人像生成的真实感;关键词:人像、胶片感、写实;建议位置:网页】
图生图,先准备一张原图,让模型把人物表情改成自然的微微一笑。Agnes-Image-2.1-Flash 的编辑能力支持图改图、多图融合、局部修改、背景替换、风格转换、文字编辑和图像修复,总共七种编辑模式。我试了一下证件照场景,上传一张普通照片,提示词写"将图像生成一张蓝底证件照",出来的结果背景替换得很干净,人物边缘没有明显的毛边。
【此处插入证件照生成对比图:截图目标:展示图生图的编辑能力;关键词:证件照、背景替换、编辑;建议位置:网页】
4K 能力上线后,对电商主图、产品海报、广告素材这类需要高分辨率输出的场景会更友好。只需要把 size 参数从 "1K" 改成 "4K",其他代码不用动。免费生成 4K 图片,这个诚意确实够足。
04、视频模型 Agnes-Video-2.0
Agnes-Video-2.0 支持原生音画同步生成,输出分辨率可选 720P 和 1080P。免费前的价格是 $0.3/分钟,一条 10 秒的 720P 视频只需要 3 毛钱。
在 Artificial Analysis 的 Video Leaderboard 上,Agnes-Video-2.0 同样进入了前列。
【此处插入Artificial Analysis 视频榜单截图:截图目标:证明 Agnes 视频模型在榜单中的排名;关键词:Video Leaderboard、排名、音画同步;建议位置:网页】
视频模型的能力矩阵包括首帧生视频、首尾帧生视频、多帧生视频、多镜头内容生成、人物内容生成、景别切换、第一视角运镜和光影氛围塑造。
我在 PaiAgent 的视频生成节点跑了三个测试。
第一个是纯文本生视频。提示词是"一场 GT3 赛车比赛,晴天日间,一辆 88 号红色法拉利领跑,远景、中景、特写来回切,要电影质感"。生成耗时大约 40-60 秒,出来的视频镜头切换确实有节奏感,从远景的赛道全貌切到中景的弯道超车再到特写的轮胎摩擦,配合原生音效,引擎轰鸣和轮胎尖叫都是模型自动生成的,整体氛围很到位。
【此处插入赛车视频截图:截图目标:展示文生视频的画面质量和镜头切换;关键词:赛车、镜头切换、电影质感;建议位置:网页】
第二个测试的提示词是"一支摇滚乐队在演出,主唱挥手带动观众,背景射灯从暖黄逐渐过渡到冷蓝"。这条视频的亮点在光影过渡,射灯颜色的渐变很自然,不是那种突然跳色的效果。音画同出的特性也发挥了作用,背景里能听到隐约的音乐和观众呐喊。
【此处插入摇滚乐队视频截图:截图目标:展示光影过渡和音画同步效果;关键词:摇滚乐队、光影过渡、音画同步;建议位置:网页】
第三个是图生视频。我找来一张跑车的图片作为首帧,提示词让模型基于这张图片生成一段高速公路追逐大片。这个场景更考验模型对参考图的理解和运动连贯性。生成出来的视频在保持车辆外观一致性方面做得不错,运镜也有追逐片的紧迫感。
【此处插入图生视频效果截图:截图目标:展示首帧生视频的效果和运动连贯性;关键词:图生视频、追逐、运镜;建议位置:网页】
关于音画同步,多说两句。市面上大部分视频模型生成的是纯画面,音频需要额外用 TTS 或音效模型来配。Agnes-Video-2.0 原生输出带音频的视频文件,引擎声、音乐声、环境音都是模型根据画面内容自动匹配的。赛车场景有引擎轰鸣,演唱会场景有乐器和人声,这种匹配精度在免费模型里确实少见。当然,原生音频的质量和专业音效工具比还有差距,但对于短视频、产品 Demo 这类场景已经够用了。
PaiAgent 的视频生成节点内部实现了一个轮询机制,先提交生成任务拿到 taskId,然后每 5 秒查询一次任务状态,直到生成完成或超时(最长 5 分钟)。生成完的视频会自动转存到 MinIO 对象存储,返回可访问的 URL。整个流程对用户透明,在工作流画布上拖一个视频生成节点,填好提示词,点执行就行。视频生成的 API 和文本、图片不同,它是异步的,需要先提交再轮询。PaiAgent 把这个异步流程封装在了节点执行器内部,通过 SSE 协议向前端推送生成进度,用户在画布上能实时看到"生成中 30%""生成中 80%"这样的进度反馈。
05、GitHub 生态和开发者采用
Agnes 模型免费开放两周以来,GitHub 上已经出现了多个围绕 Agnes AI 的开源项目(截至 2026-06-16 通过 GitHub API 检索)。项目类型涵盖 Agent Skill、ComfyUI 节点、CLI 工具、Web 应用和 API 网关,覆盖了 Claude Code、Codex、ComfyUI 等主流工具链。
【此处插入GitHub 项目列表截图:截图目标:展示 Agnes 在开发者社区的真实采用;关键词:GitHub、Skill、开源;建议位置:网页】
06、调用数据和全模态布局
Agnes AI 官方公布的数据,首周 Agnes-2.0-Flash 调用量超过 1 万亿 Token,Agnes-Image-2.1-Flash 首周生成超过 200 万张图片,Agnes-Video-2.0 首周生成超过 200 万秒视频。
进入第二周,全模态总 Token 调用量达到 3.12T。文本模型贡献约 1.9T,图片与视频模型合计约 1.2T。图片和视频的占比接近 40%,说明免费政策确实降低了开发者在视觉内容生成方面的试用门槛。之前需要算着成本来生成,现在可以大量尝试不同的提示词和参数组合,不用盯着余额干活。
【此处插入Agnes 调用数据统计图:截图目标:证明模型的真实调用规模;关键词:3.12T、调用量、Token;建议位置:网页】
Agnes 的全模态布局目前覆盖文本、图片、视频三条线,TTS(语音合成)能力预计本周也会灰度上线。到时候文本生成、图片生成、视频生成、语音合成四种能力就齐了,一套 API Key 全部搞定。
对于做内容自动化的团队来说,这意味着一条完整的生产线。Agent 写脚本 → 生成配图 → 生成视频 → 配上语音旁白,整个流程都可以在一个平台的 API 下完成。PaiAgent 的工作流编排正好适合串起这样的多模态流水线。
ending
两周前还在纠结 API 账单怎么控制 现在文本、图片、视频三条线全部免费,不限量 PaiAgent 工作流里的每个节点都换上了 Agnes 的模型 跑了上百次测试,一分钱没花
4K 图片生成本周上线 1M 上下文本周上线 TTS 语音合成也快了
【一套 API Key 管文本图片视频语音四条线,省下来的钱,够我请团队吃顿好的了。】