系列导航
- 上一篇:03|消息 ID 设计:一个 UUID 搞不定的事,我用两个 ID 解决了
- 下一篇:05 断线重连:移动端 IM 最头疼的问题,我是怎么解的
做即时通讯,长连接是命脉。连接断了,消息就丢了;心跳假了,用户就离线了;Pipeline 排错了,整个链路就废了。
WhatsApp 用 Erlang 做到单节点 200 万连接,微信早期用 C++ 实现单机 10 万连接的长连接网关。Java 生态里,Netty 是唯一能到这个量级的选择------Tomcat 的 NIO Connector 上限在万级,WebFlux 的 WebSocket 支持不够精细。
这一篇,我把 im-connect 长连接层从 0 到 1 的设计全部拆开:Pipeline 11 个 Handler 为什么这么排、心跳怎么做三次容错、连接管理怎么支持 5 台设备同时在线、连接数怎么监控、Epoll 和 NIO 怎么选。每一行都是线上跑过的代码,不是 PPT 架构。
1. 先看全貌:im-connect 做了什么
在 第一篇架构文章 里我说过,IM 系统拆了 7 个微服务,其中 im-connect 是唯一一个和客户端保持 WebSocket 长连接的服务。
它的职责很明确:
bash
客户端 ←──WebSocket/Protobuf──→ im-connect ←──gRPC/RocketMQ──→ im-business
│
├── 接入:鉴权、限流、连接管理
├── 投递:消息路由、群广播
└── 保活:心跳检测、断线清理技术上,im-connect 是一个 非 Web 的 Spring Boot 应用,内部启动 Netty Server 处理 WebSocket:
java
// IMConnectServiceApplication.java
@SpringBootApplication
@ConfigurationPropertiesScan
@EnableScheduling
public class IMConnectServiceApplication {
public static void main(String[] args) {
new SpringApplicationBuilder(IMConnectServiceApplication.class)
.web(WebApplicationType.NONE) // 不启动 Tomcat,只用 Netty
.run(args);
}
}为什么不用 Spring WebSocket(@ServerEndpoint)?因为 Netty 给了我对 线程模型、内存管理、Pipeline 编排 的完全控制权。在 C10K 甚至 C100K 场景下,这些细节决定了系统能不能扛住。
Spring 的 @ServerEndpoint 底层走的是 Tomcat/Jetty 的 WebSocket 实现,线程模型受限于 Servlet 容器。而 Netty 采用的是 Reactor 线程模型,可以精确控制 IO 线程数量、内存分配策略、Handler 编排顺序------这些在高并发场景下每一个都是性能瓶颈的潜在来源。
2. Netty 启动:从 Epoll 到 ByteBuf 池化
2.1 启动时机:为什么用 ApplicationRunner
Netty Server 的启动我放在了 ApplicationRunner.run() 里,而不是 @PostConstruct 或 CommandLineRunner:
java
@Slf4j
@Component
public class NettyServer implements ApplicationRunner {
@Override
public void run(ApplicationArguments args) {
log.info("[NettyServer] 正在启动 WebSocket 服务器");
initEventLoopGroups();
ServerBootstrap bootstrap = new ServerBootstrap();
configureServerBootstrap(bootstrap);
// ... bind and start
}
}为什么? 因为 ApplicationRunner 在 Spring 容器完全初始化之后才执行。之前我试过 @PostConstruct,结果遇到 Bean 还没注入完就启动 Netty 的坑------WebSocketChannelInitializer 里通过 SpringUtil.getBean() 获取的配置对象全是 null。
2.2 Epoll vs NIO:自动检测,Linux 一律用 Epoll
java
private void initEventLoopGroups() {
int cpuCores = Runtime.getRuntime().availableProcessors();
int bossThreads = imConnectServerConfig.getBossThreads();
int workerThreads = imConnectServerConfig.getWorkerThreads();
if (bossThreads <= 0) bossThreads = Math.max(1, cpuCores / 4);
if (workerThreads <= 0) workerThreads = cpuCores * 2;
if (Epoll.isAvailable()) {
bossGroup = new EpollEventLoopGroup(bossThreads,
new DefaultThreadFactory("netty-boss", Thread.MAX_PRIORITY));
workerGroup = new EpollEventLoopGroup(workerThreads,
new DefaultThreadFactory("netty-worker", Thread.NORM_PRIORITY));
bootstrap.channel(EpollServerSocketChannel.class);
} else {
bossGroup = new NioEventLoopGroup(bossThreads, ...);
workerGroup = new NioEventLoopGroup(workerThreads, ...);
bootstrap.channel(NioServerSocketChannel.class);
}
}Epoll 和 NIO 的本质区别:
| 特性 | NIO (select/poll) | Epoll |
|---|---|---|
| 事件通知模型 | 每次调用遍历全部 fd | 只返回就绪的 fd(事件驱动) |
| 连接数增长时性能 | O(n) 线性下降 | O(1) 恒定 |
| 适合场景 | < 1 万连接 | 10 万+ 连接 |
| 平台 | 全平台 | 仅 Linux |
Linux 是服务端部署的绝对主流,Epoll 是百万连接的前提条件。代码里 Epoll.isAvailable() 自动检测,开发机(macOS)走 NIO,线上走 Epoll,零配置切换。
深入理解 Epoll 的性能优势:
传统的 select/poll 模型,每次调用都需要把所有 fd(文件描述符)从用户态拷贝到内核态,内核遍历所有 fd 检查是否有事件就绪,再把结果拷贝回来。连接数从 1 万涨到 10 万,每次遍历的时间也从 O(1 万) 涨到 O(10 万)。
Epoll 用了完全不同的思路:通过 epoll_ctl 注册 fd 到内核的红黑树中,通过 ep_wait 只返回就绪的 fd 列表。注册是一次性的,不需要每次都拷贝;返回时只遍历真正有事件的 fd,复杂度 O(活跃 fd 数)。
用一个比喻:select 是老师点名,全班 50 个学生逐个问"到了没";Epoll 是学生主动举手,老师只看举手的学生。人越多,差距越大。
线程分配策略------主从 Reactor 模式:
- Boss 线程(Main Reactor) :
max(1, CPU/4),只负责 Accept 新连接,1-2 个足够 - Worker 线程(Sub Reactor) :
CPU*2,负责所有已建立连接的 IO 读写
这就是经典的 主从 Reactor 多线程模型 。Boss 是"前台接待",只负责迎接新客户;Worker 是"业务专员",负责和老客户的所有交互。这个比例不是拍脑袋------Boss 线程的工作量极小(就是一个 accept() 系统调用),给它多了是浪费;Worker 线程要做编解码、业务分发,CPU 密集型场景需要足够的线程数避免上下文切换等待。
Netty 的 EventLoopGroup 本质上是 Reactor 模式的实现。每个 EventLoop 是一个单线程的 Reactor,内部维护一个 Selector(Epoll/NIO),不断轮询 IO 事件,然后分发给对应的 Handler 处理。一个 Worker EventLoop 通常管理数百个 Channel,通过 IO 多路复用实现高并发。
2.3 TCP 参数:每一个都有讲究
java
private void configureServerBootstrap(ServerBootstrap bootstrap) {
bootstrap
.option(ChannelOption.SO_BACKLOG, soBacklog) // 半连接队列大小
.option(ChannelOption.SO_REUSEADDR, true) // 快速复用端口
.childOption(ChannelOption.SO_KEEPALIVE, true) // TCP 层 Keepalive
.childOption(ChannelOption.TCP_NODELAY, true) // 禁用 Nagle 算法
.childOption(ChannelOption.SO_LINGER, 0) // 关闭时立即释放
.childOption(ChannelOption.SO_RCVBUF, bufferSize) // 接收缓冲区 32KB
.childOption(ChannelOption.SO_SNDBUF, bufferSize) // 发送缓冲区 32KB
.childOption(ChannelOption.WRITE_BUFFER_WATER_MARK,
new WriteBufferWaterMark(32 * 1024, 128 * 1024)) // 写水位线
.childOption(ChannelOption.ALLOCATOR,
PooledByteBufAllocator.DEFAULT) // 池化内存分配器
.childOption(ChannelOption.AUTO_READ, true); // 自动读取
}重点说三个:
TCP_NODELAY = true:Nagle 算法会把小包攒成大包再发,减少网络带宽。但 IM 消息对延迟极其敏感------你敲一个字,对方要立刻看到。禁掉 Nagle,每个消息立刻发出去。
WRITE_BUFFER_WATER_MARK :写缓冲区水位线,低水位 32KB,高水位 128KB。当待写数据超过 128KB,Netty 自动将 Channel 标记为不可写,触发 channelWritabilityChanged 事件。这是 背压(Backpressure) 机制------发送端生产太快时,让上游减速,避免 OOM。
PooledByteBufAllocator :Netty 默认用非池化分配器 UnpooledByteBufAllocator,每次分配都向 JVM 堆申请内存,GC 压力大。池化分配器预分配内存池(Arena),分配和释放都在池内完成,大幅减少 GC 停顿。线上监控显示切换到池化后,Young GC 频率降了约 40%。
深入 ByteBuf 池化的内部结构:
PooledByteBufAllocator 的内存管理分三层:
bash
Arena(内存竞技场)
├── PoolChunk(16MB 的内存块)
│ ├── PoolSubpage(小于 8KB 的小内存分配)
│ └── PoolSubpage(通过 buddy 算法分割)
└── PoolChunkList(管理多个 Chunk,按使用率分组)
├── qInit(新分配的 Chunk)
├── q000(0%~25% 使用率)
├── q025(25%~50%)
├── q050(50%~75%)
├── q075(75%~100%)
└── q100(完全使用,等待释放)- Arena:每个 Arena 默认 16MB(堆内)或按需分配(堆外 Direct),Netty 会为每个 Worker 线程分配一个 Arena,避免线程竞争
- PoolChunk:Arena 内的内存块,使用伙伴系统(Buddy System)管理,支持 8KB~16MB 的内存分配
- PoolSubpage:小于 8KB 的内存通过 Subpage 管理,按固定大小切分(如 16B、32B、...、4KB),用位图记录哪些 slot 已分配
这种设计让 ByteBuf 的分配和释放变成了 O(1) 的内存池操作,而不是 O(n) 的 JVM 堆扫描。在每秒处理数万条消息的 IM 场景下,这个差异直接影响 GC 停顿时间。
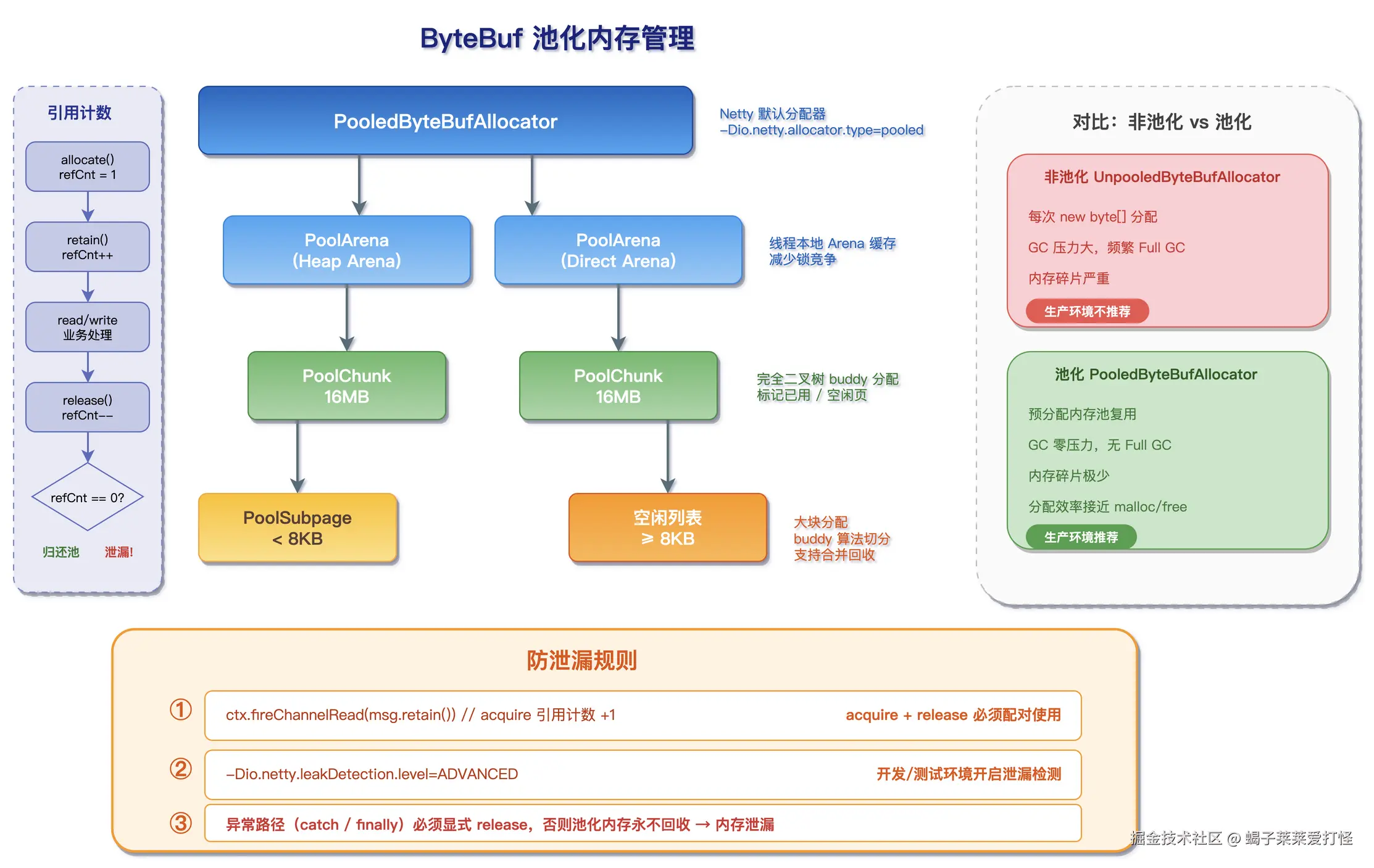
2.4 ByteBuf 内存泄漏检测
池化内存带来了 GC 上的好处,但也引入了一个新问题:内存泄漏 。池化 ByteBuf 不受 JVM GC 管理,如果你忘了调用 release(),那块内存就永远不会归还到池中,最终把池耗尽,抛出 OutOfMemoryError。
Netty 内置了泄漏检测机制,通过 JVM 参数控制:
bash
-Dio.netty.leakDetection.level=ADVANCED四个检测级别:
| 级别 | 开销 | 用途 |
|---|---|---|
DISABLED |
无 | 关闭检测(不要在生产环境用) |
SIMPLE |
极低 | 默认级别,采样 1/128 的 ByteBuf,报告是否存在泄漏 |
ADVANCED |
中等 | 采样 1/128 的 ByteBuf,记录访问位点,定位到具体代码行 |
PARANOID |
高 | 100% 采样,每分配一个 ByteBuf 都记录。仅用于测试 |
推荐实践 :开发/测试环境用 ADVANCED,线上用 SIMPLE。PARANOID 只在定位特定泄漏问题时短暂开启,因为它会给每个 ByteBuf 的分配和访问都打一条日志,吞吐量直接腰斩。
ReferenceCountUtil.release() 的规范用法:
java
// 正确:finally 块释放
ByteBuf buf = null;
try {
buf = ctx.alloc().buffer();
buf.writeBytes(data);
ctx.writeAndFlush(new BinaryWebSocketFrame(buf));
buf = null; // 交由 WebSocketFrame 持有,Frame 被写完后自动 release
} finally {
if (buf != null) { // 如果 writeAndFlush 前抛异常,手动释放
ReferenceCountUtil.release(buf);
}
}异常路径的泄漏防范 是关键。正常路径下的 release() 大家都不会忘,但异常路径很容易遗漏。几个常见的泄漏场景:
- Handler 异常未处理 :
channelRead里抛异常,ByteBuf 没人释放。解决:重写exceptionCaught,在 finally 中release。 - 编解码中途失败 :Protobuf
parseFrom()抛InvalidProtocolBufferException,ByteBuf 没释放。解决:try-catch 包裹parseFrom,catch 中 release。 - 业务线程池拒绝 :
CompletableFuture.runAsync提交任务时线程池已满,消息的 ByteBuf 没被消费。解决:提交前检查队列长度(我们已经做了),被拒绝时主动 release。
java
// 异常路径泄漏防范的典型写法
@Override
public void channelRead0(ChannelHandlerContext ctx, WebSocketFrame frame) {
ByteBuf content = frame.content();
try {
byte[] bytes = new byte[content.readableBytes()];
content.getBytes(content.readerIndex(), bytes);
ImProtoRequest request = ImProtoRequest.parseFrom(bytes);
handlerDispatcher.dispatcher(ctx, request);
} catch (InvalidProtocolBufferException e) {
log.warn("Protobuf 解析失败,关闭连接");
ctx.close();
// content 由 frame 持有,frame 在 channelRead 完成后由 Netty 自动 release
}
}我们在线上遇到过一次泄漏:某个异常分支里 ctx.fireExceptionCaught() 之后没有 release 之前读出的 ByteBuf,跑了 6 小时后 PooledByteBufAllocator 的 Direct Memory 从 256MB 涨到 2GB,最终 OOM。加上 ADVANCED 级别检测后,日志里直接打出了泄漏的分配栈和最后一次访问栈,定位到具体代码行,5 分钟修复。
所有这些参数都可以通过 Nacos 配置中心动态调整:
yaml
# Nacos imConnect.yaml
im:
netty:
nettyPort: 8085
soBackLog: 65535
bossThreads: 0 # 0 = 自动计算
workerThreads: 0 # 0 = 自动计算
socketBufferSize: 32768 # 32KB
writeBufferLowWaterMark: 32768
writeBufferHighWaterMark: 131072
enableCompression: false需要注意,这些参数的"动态生效"范围是有限的:
- TCP 参数(SO_BACKLOG、SO_RCVBUF、SO_SNDBUF 等) :在
ServerBootstrap.bind()后就固化了,改配置只影响下次重启 时生效。这些参数绑定在ServerSocketChannel和SocketChannel的底层 fd 上,Netty 不会为已有连接重新设置。 - 运行时参数(心跳间隔、限流阈值、线程池大小等) :通过 Nacos 配置变更 +
@RefreshScope可以热更新,不需要重启服务。
所以 Nacos 配置变更的实际效果取决于参数类型。对于 TCP 参数的调整,仍然需要滚动重启实例。
3. Pipeline 编排:11 个 Handler,顺序错了就是事故
这是整篇文章最核心的部分。
3.1 完整 Pipeline 顺序
java
// WebSocketChannelInitializer.java
@Override
protected void initChannel(SocketChannel ch) {
ChannelPipeline pipeline = ch.pipeline();
// ① 调试日志(可开关)
if (imConnectServerConfig.isDebug()) {
pipeline.addLast(new LoggingHandler(LogLevel.DEBUG));
}
// ② HTTP 编解码(WebSocket 升级需要)
pipeline.addLast(new HttpServerCodec());
// ③ HTTP 聚合器(合并 HTTP 分片)
pipeline.addLast(new HttpObjectAggregator(65536));
// ④ 大数据分块传输
pipeline.addLast(new ChunkedWriteHandler());
// ⑤ WebSocket 压缩(可选,高 QPS 建议关闭)
if (imConnectServerConfig.isEnableCompression()) {
pipeline.addLast(new WebSocketServerCompressionHandler());
}
// ⑥ 空闲检测(读超时 30 秒触发 READER_IDLE 事件)
pipeline.addLast("heart-notice", new IdleStateHandler(
idleCheckInterval, 0, 0, TimeUnit.SECONDS));
// ⑦ 连接数限制(Redis 分布式)
pipeline.addLast("connection-limit", SpringUtil.getBean(ConnectionLimitHandler.class));
// ⑧ 流量控制(Redis 分布式)
pipeline.addLast("flow-control", SpringUtil.getBean(FlowControlHandler.class));
// ⑨ Prometheus 指标采集
pipeline.addLast("metrics", new MetricsHandler());
// ⑩ JWT 认证(认证成功后自动移除自己)
pipeline.addLast("auth", SpringUtil.getBean(AuthHandler.class));
// ⑪ WebSocket 帧处理 + Protobuf 消息分发
pipeline.addLast("websocket", SpringUtil.getBean(WebSocketServerHandler.class));
}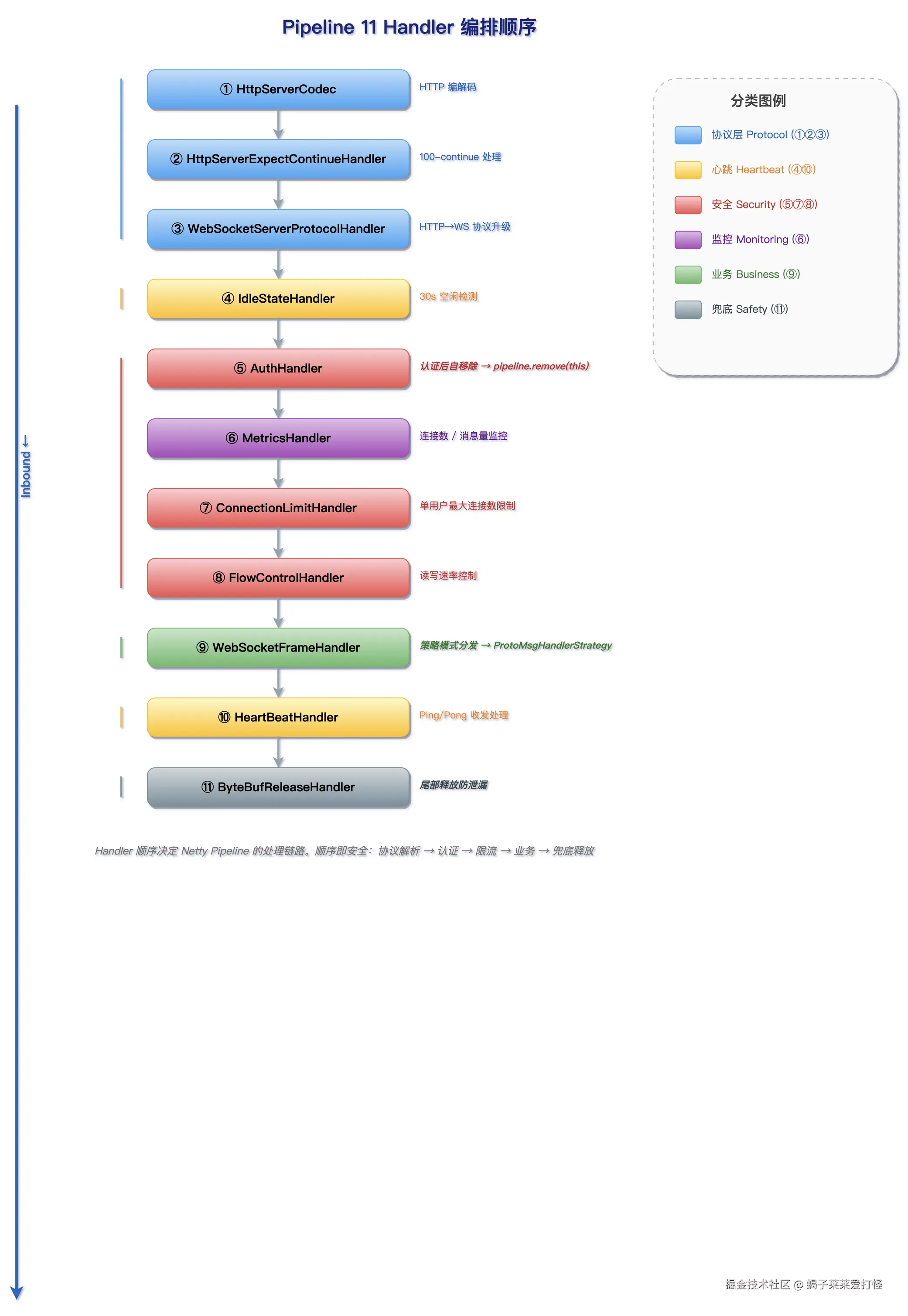
3.2 为什么顺序不能乱
Pipeline 是责任链模式,消息从 Head → Tail 依次经过每个 Handler。顺序不对,轻则功能异常,重则安全漏洞。
在深入讲之前,先理解 Netty Pipeline 的两个关键特性:
1. Handler 分为 Inbound 和 Outbound 两种方向
bash
入站方向(Inbound):Head → Tail
客户端数据 → 解码 → 处理 → 业务逻辑
出站方向(Outbound):Tail → Head
业务逻辑 → 编码 → 写回客户端我们的 11 个 Handler 中,大部分是 Inbound(处理入站数据),但 HttpServerCodec 同时包含编码器(Outbound)和解码器(Inbound),WebSocketServerCompressionHandler 也是双向的。
2. 事件传播机制
ctx.fireChannelRead(msg) 将消息传递给下一个 Inbound Handler;ctx.write(msg) 触发 Outbound Handler 链。如果一个 Handler 不调用 fireChannelRead,消息就停在那里------这就是 AuthHandler 认证失败时不调用 fireChannelRead,消息不会继续往下传的原理。
核心规则:协议层 → 安全层 → 业务层
bash
HTTP 协议层(②③④) → 先解码出 HTTP 请求
↓
WebSocket 协议层(⑤) → 处理压缩扩展
↓
心跳检测(⑥) → 超时事件必须能触达到所有连接
↓
安全防护(⑦⑧) → 在认证之前拦截恶意连接
↓
指标采集(⑨) → 统计所有合法流量
↓
认证(⑩) → 验证通过后从 Pipeline 移除自己
↓
业务处理(⑪) → 只处理已认证的 WebSocket 帧几个容易踩的坑:
坑 1:IdleStateHandler 必须在 AuthHandler 前面
如果放在后面,未认证的恶意连接就不会被空闲检测到------它们永远走不到 IdleStateHandler,就永远不会被超时断开。攻击者可以开十万个空连接把你的服务器耗死。
坑 2:ConnectionLimitHandler 必须在 AuthHandler 前面
连接数限制必须在认证前执行。否则攻击者可以用不同的 Token 建立无数连接,每个连接都消耗认证资源(查 Redis、解析 JWT),直接把 Redis 和 CPU 打满。
坑 3:HttpObjectAggregator 必须在 HttpServerCodec 后面
HttpServerCodec 把字节流解码为 HTTP 消息,但如果请求被分片(Transfer-Encoding: chunked),会产出多个 HttpContent 对象。HttpObjectAggregator 把它们合并成一个完整的 FullHttpRequest,后续 Handler 才能正常处理。
坑 4:AuthHandler 认证成功后要移除自己
java
// AuthHandler.java - 认证成功
private boolean performAuthentication(...) {
// ... 验证逻辑
ctx.channel().attr(ImConstant.USER_ID_KEY).setIfAbsent(uid);
ctx.pipeline().remove(this); // ← 移除自己
ctx.fireChannelRead(msg); // ← 继续传递
return true;
}为什么要移除?因为认证只发生一次(HTTP 升级 WebSocket 的那个请求),之后所有通信都是 WebSocket 帧。如果 AuthHandler 留在 Pipeline 里,每条消息都要经过它的 channelRead,它会检查 msg instanceof FullHttpRequest,WebSocket 帧不是 HTTP 请求,直接 fireChannelRead 跳过------虽然逻辑上没错,但白白多一次类型检查。移除后,消息少经过一个 Handler,在每秒数万条消息的场景下,这点优化是有意义的。
3.3 两种共享模式
Pipeline 里的 Handler 分两种创建方式:
| Handler | 创建方式 | 原因 |
|---|---|---|
| LoggingHandler | new |
无状态,每个 Channel 独立 |
| HttpServerCodec | new |
有状态(编解码上下文),必须独立 |
| IdleStateHandler | new |
有状态(每个连接的空闲时间不同) |
| ConnectionLimitHandler | SpringUtil.getBean() |
@Sharable,无状态 |
| AuthHandler | SpringUtil.getBean() |
@Sharable,状态存在 Channel 属性里 |
| WebSocketServerHandler | SpringUtil.getBean() |
@Sharable,状态存在 LocalChannelManager 里 |
@Sharable 标注的 Handler 是单例,所有 Channel 共享。它们不能在成员变量里存连接级别的状态------状态必须存在 Channel 的 AttributeKey 里或外部的 ConcurrentHashMap 里。
@Sharable 误用的后果 :如果把一个有状态的 Handler(比如内部有 Map<String, String> 的编解码器)标为 @Sharable 并共享,会导致 A 用户读到 B 用户的数据。这是 Netty 初学者最常见的 bug 之一。Netty 不会阻止你这么做(@Sharable 只是一个标记),但运行时会出诡异的数据错乱。
4. 心跳设计:三层容错,不误杀不断连
心跳是长连接的"脉搏"。TCP 连接看起来在,但中间的代理、NAT、防火墙可能已经把连接偷偷掐断了------这就是所谓的 "半开连接" 问题。心跳就是用来检测并清理这些僵尸连接的。
为什么 TCP 自带的 Keepalive 不够用?
TCP Keepalive 是操作系统层面的机制,默认配置通常是 2 小时无数据才检测一次。这个时间对 IM 来说太长了------用户断网 2 小时后你才发现他离线?而且 TCP Keepalive 只能检测直接连接的状态,中间有代理、NAT、负载均衡器时,TCP 连接可能已经被中间设备掐断了,但两端都不知道。
| 维度 | TCP Keepalive | 应用层心跳 |
|---|---|---|
| 检测间隔 | 默认 2 小时(Linux tcp_keepalive_time) |
自定义(我们用 45 秒) |
| 检测内容 | TCP 层连通性 | 应用层可达性(消息能否正常处理) |
| 穿透性 | 可能被中间设备干扰 | 走应用协议,穿透更可靠 |
| 灵活性 | 依赖操作系统配置 | 应用代码完全控制 |
| 跨代理 | 代理可能重置连接但不通知 | 心跳超时即判定不可达 |
所以结论很明确:TCP Keepalive 是兜底,应用层心跳才是主力 。我们在配置里也开了 SO_KEEPALIVE = true,但它只是最后一道防线。
4.1 心跳架构:IdleStateHandler + 失败计数 + 主动 Ping
bash
时间线:
0s 30s 60s 90s
│ │ │ │
│ ← 客户端发消息/心跳 →│← IdleState 检测 → │← IdleState 检测 → │
│ │ 失败计数 +1 │ 失败计数 +2 │
│ │ 服务端主动 Ping → │ 服务端主动 Ping → │
│ │ │ │
│ │ │ 120s
│ │ │← IdleState 检测 → │
│ │ │ 失败计数 +3 = MAX │
│ │ │ 关闭连接 ❌ │4.2 第一层:IdleStateHandler 检测
java
// 每 30 秒检测一次读空闲
pipeline.addLast("heart-notice", new IdleStateHandler(
idleCheckInterval, // 读空闲 30 秒
0, // 写空闲不检测
0, // 读写空闲不检测
TimeUnit.SECONDS
));IdleStateHandler 的工作原理:它在 channelRead 时记录最后读取时间,然后用一个定时任务周期性检查。如果超过 idleCheckInterval 没有读到任何数据,就触发 userEventTriggered 事件,事件类型是 IdleStateEvent.READER_IDLE。
注意参数:只监控读空闲,不监控写空闲。为什么?因为 IM 场景下,客户端发消息的频率远低于服务端。如果监控写空闲,服务端会在"没有消息要推给客户端"时误判为空闲。
4.3 第二层:失败计数 + 三次容错
java
// NettyServerHeartBeatHandlerImpl.java
@Override
public void process(ChannelHandlerContext ctx) {
long heartBeatTimeMs = imConnectServerConfig.getHeartBeatTime() * 1000; // 45 秒
Long lastReadTime = NettyAttrUtil.getReaderTime(ctx.channel());
long currentTime = System.currentTimeMillis();
if (lastReadTime == null) {
NettyAttrUtil.updateReaderTime(ctx.channel(), currentTime);
return;
}
long timeSinceLastRead = currentTime - lastReadTime;
if (timeSinceLastRead > heartBeatTimeMs) {
// 超时,增加失败计数
int failureCount = heartbeatFailureCount.getOrDefault(channelId, 0) + 1;
heartbeatFailureCount.put(channelId, failureCount);
if (failureCount >= maxFailures) { // 默认 3 次
closeConnectionDueToHeartbeatFailure(ctx, userId, channelId, timeSinceLastRead);
} else {
sendActiveHeartbeat(ctx, userId, channelId); // 主动发 Ping 探测
}
} else {
heartbeatFailureCount.remove(channelId); // 正常,重置计数
}
}关键设计:不是一次超时就断连,而是容忍 3 次。
为什么?因为网络抖动。某个时刻网络拥堵,客户端的心跳包延迟了 1 秒,如果 1 次超时就断连,用户就会被踢下线。3 次容错给了网络恢复的机会:
- 第 1 次超时:可能只是暂时的网络波动,发个 Ping 探测一下
- 第 2 次超时:网络可能真的有问题了,再发一次 Ping
- 第 3 次超时:确认连接已死,关闭并清理资源
4.4 第三层:主动 Ping + 关闭前二次确认
java
private void closeConnectionDueToHeartbeatFailure(...) {
// 【关键】关闭前再次确认,防止误杀重连用户
Long lastReadTime = NettyAttrUtil.getReaderTime(ctx.channel());
long currentTime = System.currentTimeMillis();
long heartBeatTimeMs = imConnectServerConfig.getHeartBeatTime() * 1000;
if (lastReadTime != null) {
long actualTimeSinceLastRead = currentTime - lastReadTime;
if (actualTimeSinceLastRead < heartBeatTimeMs) {
// 用户可能刚重连,取消关闭
log.info("检测到用户{}可能刚重连(实际超时{}ms < {}ms),取消关闭连接",
userId, actualTimeSinceLastRead, heartBeatTimeMs);
heartbeatFailureCount.remove(channelId);
return;
}
}
ctx.channel().close();
}为什么需要二次确认?考虑这个场景:
- 用户 A 的连接心跳超时
- 服务端准备关闭连接
- 就在这时,用户 A 断线重连成功了,新连接的
channelRead更新了lastReadTime - 如果不二次确认,就会把新连接也清理掉------用户刚连上又被踢下线
二次确认就是检查 lastReadTime 是否在准备关闭时被更新了。如果更新了,说明用户已经恢复,取消关闭。
4.5 配置参数关系
bash
idleStateCheckInterval(30s) < heartBeatTime(45s) < maxFailures(3) × heartBeatTime
↓ ↓ ↓
触发检测的频率 判断是否超时的阈值 允许的连续超时次数idleStateCheckInterval 必须小于 heartBeatTime,否则会出现检测间隔大于超时阈值,逻辑矛盾。我在配置类里加了启动校验:
java
@PostConstruct
public void validateConfig() {
if (idleStateCheckInterval >= heartBeatTime) {
throw new IllegalStateException(
"心跳配置错误:idleStateCheckInterval 必须 < heartBeatTime");
}
log.info("心跳配置验证通过:idleStateCheckInterval={}秒, heartBeatTime={}秒, 容错余量={}秒",
idleStateCheckInterval, heartBeatTime, heartBeatTime - idleStateCheckInterval);
}最终效果 :从客户端最后一次活动到被判定为超时关闭,最长需要 3 × 45s = 135s。这个时间窗口足够容忍网络抖动,又不会让僵尸连接占着资源太久。
和业界对比:
| IM 系统 | 心跳间隔 | 超时断连 | 容错策略 |
|---|---|---|---|
| 微信 | ~300s | ~900s | 多次超时 |
| ~30s | ~60s | 3 次重试 | |
| 钉钉 | ~60s | ~180s | 指数退避 |
| 我们(XZLL-IM) | 30s 检测 / 45s 超时 | 135s(3 次) | 主动 Ping + 二次确认 |
我们的超时时间比微信短得多,因为我们的用户规模没有微信那么大,不需要容忍那么长的网络中断。但对于一个中小型 IM 系统来说,135 秒的超时窗口在"快速检测死连接"和"容忍网络抖动"之间取得了不错的平衡。

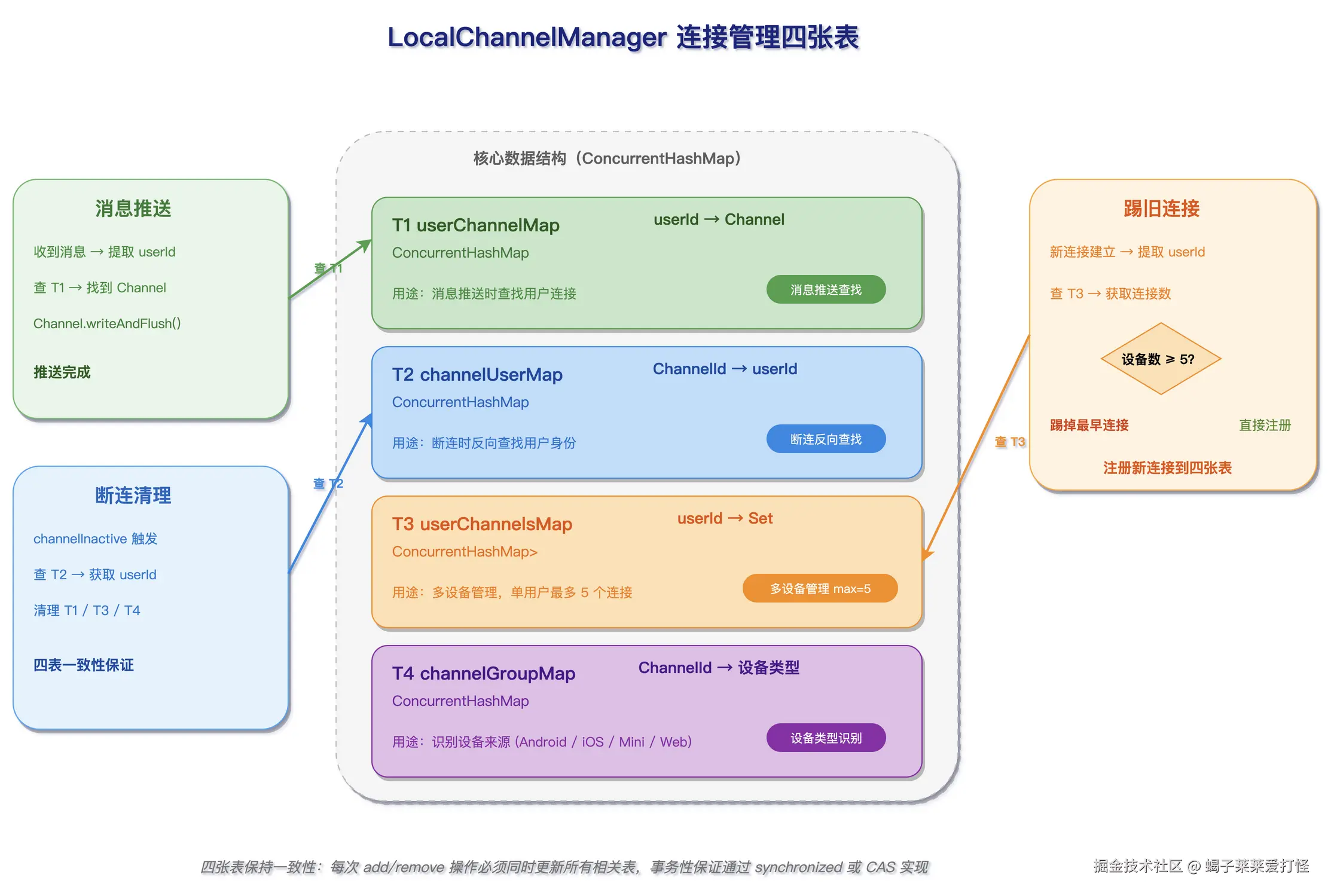
5. 连接管理:四张表 + 多设备 + 僵尸清理
5.1 LocalChannelManager 的四张表
java
@Component
public class LocalChannelManager {
// 表 1:用户 → 当前主连接(最近一次活跃的 Channel)
private static final ConcurrentMap<String, Channel> userIdChannelMap = new ConcurrentHashMap<>();
// 表 2:Channel ID → 用户 ID(反向查找)
private static final ConcurrentMap<String, String> channelIdUserIdMap = new ConcurrentHashMap<>();
// 表 3:用户 → 连接时间(统计连接时长)
private static final ConcurrentMap<String, Long> userConnectTimeMap = new ConcurrentHashMap<>();
// 表 4:用户 → 所有设备 Channel(多设备支持)
private static final ConcurrentMap<String, Set<String>> userMultiChannelMap = new ConcurrentHashMap<>();
// 连接计数器
private static final AtomicInteger totalConnections = new AtomicInteger(0);
private static final AtomicInteger activeConnections = new AtomicInteger(0);
// 单用户最大连接数
private static final int MAX_CONNECTIONS_PER_USER = 5;
}为什么是四张表而不是一张?因为查询场景不同:
| 查询场景 | 用的表 |
|---|---|
| 发消息给用户:userId → Channel | userIdChannelMap |
| 连接断开:channelId → userId → 清理 | channelIdUserIdMap |
| 监控面板:在线用户数 | userIdChannelMap.size() |
| 多设备推送:userId → 所有 Channel | userMultiChannelMap |
用 ConcurrentHashMap 而不是 HashMap + 锁,是因为它的分段锁(CAS + synchronized)在高并发读写场景下性能更好------10 万在线用户的情况下,每秒可能发生数千次连接建立/断开/查找操作。
5.2 多设备支持:最多 5 台
java
public static boolean addUserChannel(String userId, Channel channel) {
Set<String> userChannels = userMultiChannelMap.computeIfAbsent(userId,
k -> ConcurrentHashMap.newKeySet());
// 检查连接数限制
if (userChannels.size() >= MAX_CONNECTIONS_PER_USER) {
log.warn("用户{}连接数超过限制:{},拒绝新连接", userId, MAX_CONNECTIONS_PER_USER);
return false;
}
// 如果该用户已有主连接,踢掉旧的
Channel oldChannel = userIdChannelMap.get(userId);
if (oldChannel != null && !oldChannel.id().equals(channel.id())) {
// 先从映射中移除,再关闭(防止 channelInactive 误删新连接)
userIdChannelMap.remove(userId, oldChannel); // 原子操作
channelIdUserIdMap.remove(oldChannel.id().asLongText());
userChannels.remove(oldChannel.id().asLongText());
if (oldChannel.isActive()) {
oldChannel.close(); // 异步关闭旧连接
}
}
// 添加新连接
userIdChannelMap.put(userId, channel);
channelIdUserIdMap.put(channelId, userId);
userConnectTimeMap.put(userId, System.currentTimeMillis());
userChannels.add(channelId);
}为什么最多 5 台? 微信支持手机 + 平板 + 电脑 + 网页 4 端同时在线,我给了 5 个名额------留了一点余量。这不仅仅是技术限制,也是安全策略:如果一个用户的连接数突然超过 5 个,很可能是 Token 被盗用了。
踢旧连接的时序问题:
注意这段代码的顺序------先从 Map 中移除旧连接,再关闭旧 Channel。这个顺序非常重要:
bash
正确:Map.remove(old) → old.close() → channelInactive 触发
↓
发现 Map 里已经没有旧连接了,不做额外清理
错误:old.close() → channelInactive 触发 → Map.remove(userId)
↓
可能把刚加进去的新连接也删了!5.3 定时清理僵尸连接
java
static {
// 每 60 秒清理一次无效连接
cleanupExecutor.scheduleAtFixedRate(
LocalChannelManager::cleanupInactiveChannels,
1, 1, TimeUnit.MINUTES);
// 每 60 秒输出一次连接统计
cleanupExecutor.scheduleAtFixedRate(
LocalChannelManager::logConnectionStats,
60, 60, TimeUnit.SECONDS);
}
private static void cleanupInactiveChannels() {
for (ConcurrentMap.Entry<String, Channel> entry : userIdChannelMap.entrySet()) {
Channel channel = entry.getValue();
if (channel == null || !channel.isActive()) {
removeUserChannel(entry.getKey());
}
}
// 清理孤儿映射(channelId 存在但 userId 已不存在)
channelIdUserIdMap.entrySet().removeIf(entry ->
!userIdChannelMap.containsKey(entry.getValue()));
}为什么要定时清理?因为 channelInactive 不一定总是被触发。比如服务端直接 kill -9 杀进程、网络设备硬断连,Channel 的关闭事件可能丢失。定时清理是兜底机制,保证 Map 里不会积累僵尸映射。
5.4 多设备踢旧连完整时序分析
上一节提到踢旧连接时要"先移除再关闭",这里把完整的多设备踢旧连时序拆开来看。这是一个非常容易出 bug 的场景------我们在线上踩过坑,才最终敲定了这套时序。
场景:用户 U001 在手机 A 上已经连接(Channel-A),此时又在手机 A 上重新打开 APP 建立了新连接(Channel-B)。
bash
时间轴:
t1 t2 t3 t4
│ │ │ │
客户端(手机A) │ │ │ │
Channel-A ────────┤ 已在线 │ │ │
│ │ │ │ │
│ 新连接请求 ─────┤──────────────→ │ │ │
│ Channel-B │ │ │ │
│ │ 服务端处理流程: │ │
│ │ ① 查 userIdChannelMap │ │
│ │ 找到旧 Channel-A │ │
│ │ ② userIdChannelMap.remove(U001, Channel-A) │
│ │ (原子操作,CAS 保证并发安全) │ │
│ │ ③ channelIdUserIdMap.remove(Channel-A.id) │
│ │ ④ userMultiChannelMap.remove(Channel-A.id) │
│ │ ⑤ Channel-A.close() 异步关闭 │ │
│ │ ┌──────────────────────┐ │ │
│ │ │ Channel-A.close() 是 │ │ │
│ │ │ 异步操作,不会阻塞当 │ │ │
│ │ │ 前线程 │ │ │
│ │ └──────────────────────┘ │ │
│ │ ⑥ userIdChannelMap.put(U001, Channel-B) │
│ │ ⑦ channelIdUserIdMap.put(Channel-B.id, U001) │
│ │ ⑧ userMultiChannelMap.add(Channel-B.id) │
│ │ │ │ │
│ │ │ t3 时刻:Channel-A 的 │
│ │ │ channelInactive 回调触发 │
│ │ │ ┌──────────────────────┐ │
│ │ │ │ 检查 userIdChannelMap │ │
│ │ │ │ 发现 U001 已指向 │ │
│ │ │ │ Channel-B(不是自己) │ │
│ │ │ │ → 不做额外清理 │ │
│ │ │ └──────────────────────┘ │
│ │ │ │ │
│ ← 握手成功 │ │ │ │
│ Channel-B │ │ │ │并发场景下的安全保障:
如果同一用户在极短时间内从两台设备发起连接(Device-A 和 Device-B 几乎同时),userIdChannelMap.remove(userId, oldChannel) 使用了 ConcurrentHashMap 的原子 remove(key, value) 方法------它只有在 key 对应的 value 等于期望值时才删除。这样:
- Device-A 的连接先执行 remove,成功移除旧连接
- Device-B 的连接后执行 remove,此时 value 已经变了,remove 返回 false,不会误删 Device-A 的新连接
这是 ConcurrentHashMap 的 CAS 语义在并发场景下的巧妙运用。
6. 安全防护:连接限制 + 流量控制 + IP 封禁
Pipeline 里第 ⑦ ConnectionLimitHandler 和第 ⑧ FlowControlHandler 是安全防护层。它们都基于 Redis 实现,支持分布式部署。
6.1 ConnectionLimitHandler:连接数三层限制
java
@Override
public void channelActive(ChannelHandlerContext ctx) throws Exception {
String clientIp = getClientIp(ctx);
// 检查 1:IP 是否被封禁
if (isIpBlocked(clientIp)) { ctx.close(); return; }
// 检查 2:全局连接数是否超限(默认 10000)
if (!checkGlobalConnectionLimit()) { ctx.close(); return; }
// 检查 3:单 IP 连接数是否超限(默认 1000)
if (!checkIpConnectionLimit(clientIp)) { ctx.close(); return; }
// 检查 4:单 IP 每分钟连接频率(默认 6000)
if (!checkIpConnectionRate(clientIp)) { ctx.close(); return; }
// 通过所有检查,增加 Redis 计数器
incrementConnectionCounters(clientIp);
super.channelActive(ctx);
}为什么把 ConnectionLimitHandler 放在 AuthHandler 前面?因为 认证是有成本的(查 Redis、解析 JWT)。如果恶意攻击者建十万个连接,每个都走完认证流程才被限制,你的 Redis 和 CPU 早就扛不住了。在认证前就拦截,把代价降到最低。
6.2 FlowControlHandler:消息级限流
java
// 配置项
@Value("${im.netty.flow-control.max-messages-per-second:10000}")
private int maxMessagesPerSecond; // 每 IP 每秒最多 10000 条消息
@Value("${im.netty.flow-control.max-message-size:8192}")
private int maxMessageSize; // 单条消息最大 8KB
@Value("${im.netty.flow-control.max-bytes-per-second:102400}")
private long maxBytesPerSecond; // 每 IP 每秒最多 100KB 带宽三层限流:频率 (条/秒)、大小 (字节/条)、带宽 (字节/秒)。用 Redis 的 RAtomicLong + 1 秒 TTL 实现滑动窗口计数。
触发限流后,IP 被标记为 throttled 状态(Redis Key,默认 1 分钟),后续所有来自该 IP 的消息直接丢弃,不做任何处理。
6.3 AuthHandler:JWT 认证 + 防暴力破解
java
private boolean performAuthentication(...) {
String token = headers.get(ImConstant.TOKEN);
// 1. 格式校验
if (!TokenUtils.isValidJwtFormat(token)) { return false; }
// 2. 解析 Token
TokenInfo tokenInfo = TokenUtils.parseTokenInfo(token);
// 3. Redis 验证(Key = userId:deviceType:tokenMd5)
String redisKey = tokenInfo.buildRedisKey(ImConstant.RedisKeyConstant.USER_TOKEN_KEY);
String storedUid = redissonUtils.getString(redisKey);
if (storedUid != null && storedUid.equals(tokenInfo.getUserId())) {
// 认证成功
ctx.channel().attr(ImConstant.USER_ID_KEY).setIfAbsent(uid);
ctx.pipeline().remove(this); // 移除自己
return true;
}
return false;
}防暴力破解机制:
java
private void handleAuthFailure(ChannelHandlerContext ctx, String clientIp, String reason) {
// 原子增加失败计数
RAtomicLong failureCounter = redissonUtils.getAtomicLong(AUTH_FAILURE_KEY_PREFIX + clientIp);
long currentFailures = failureCounter.incrementAndGet();
failureCounter.expire(lockoutDurationMinutes * 2, TimeUnit.MINUTES);
// 超过 50 次失败,锁定 IP
if (currentFailures >= maxAuthFailures) {
lockIp(clientIp); // Redis 标记,默认锁定 1 分钟
}
ctx.channel().close();
}50 次失败锁定 1 分钟------正常用户不可能连续输错 50 次密码,但这个阈值又不会太敏感,避免在测试阶段误伤开发者。
7. WebSocket 生命周期:从 HTTP 升级到 Protobuf 消息分发
7.0 WebSocket 协议升级原理
WebSocket 连接的建立本质上是一个 HTTP 升级握手。客户端发一个特殊的 HTTP 请求,服务端回复 101 状态码,然后这个 TCP 连接就从 HTTP 协议"升级"为 WebSocket 协议:
bash
客户端请求:
GET /ws HTTP/1.1
Host: im.example.com
Upgrade: websocket ← 告诉服务器要升级协议
Connection: Upgrade ← 连接不要关闭
Sec-WebSocket-Key: xxx ← 握手密钥(Base64 随机数)
Sec-WebSocket-Version: 13 ← WebSocket 协议版本
服务端响应:
HTTP/1.1 101 Switching Protocols ← 101 表示协议切换
Upgrade: websocket
Connection: Upgrade
Sec-WebSocket-Accept: yyy ← 用 SHA-1(Key + GUID) 计算的接受值握手完成后,这个 TCP 连接就变成了双向的全双工通道。客户端和服务端都可以随时发消息,不需要再走 HTTP 的请求-响应模式。
为什么 Pipeline 里需要 HttpServerCodec 和 HttpObjectAggregator?
因为 WebSocket 的握手请求是标准的 HTTP 请求。HttpServerCodec 把字节流解码为 HTTP 消息对象,HttpObjectAggregator 把可能的分片合并。只有先正确解码 HTTP,才能读取 Upgrade 头,才能决定是否执行 WebSocket 握手。握手成功后,WebSocketServerHandler 接管这个连接,后续的数据帧按 WebSocket 帧格式解析。
这也是为什么 AuthHandler 放在握手之前------它在 HTTP 阶段从请求头读取 Token 并验证。验证通过后 Token 就不需要再传了(后续走 WebSocket 帧),所以 AuthHandler 可以放心地移除自己。

7.1 一次连接的完整生命周期
bash
客户端 服务端
│ │
│── HTTP GET /ws (Upgrade: websocket, Token: xxx) ──→│
│ │ ① HttpServerCodec 解码
│ │ ② AuthHandler 认证 JWT
│ │ 认证成功,AuthHandler 自移除
│ │ ③ WebSocketServerHandler 握手
│←── 101 Switching Protocols ──────│
│ │ ④ 设置 LocalChannelManager
│ │ ⑤ 设置 Redis 在线状态
│ │ ⑥ 异步推送离线好友请求/响应
│ │
│── BinaryWebSocketFrame(Protobuf) ─→│ ⑦ 解析 ImProtoRequest
│ │ ⑧ 异步分发到业务线程池
│ │
│── PingWebSocketFrame ────────────→│ ⑨ 回复 Pong + 更新心跳
│←── PongWebSocketFrame ───────────│
│ │
│── CloseWebSocketFrame ───────────→│ ⑩ 关闭连接
│ │ ⑪ 清理 LocalChannelManager
│ │ ⑫ 清理 Redis 在线状态7.2 WebSocket 握手:为什么在握手成功后才设置状态
java
// WebSocketServerHandler.java
private void handleHttpRequest(ChannelHandlerContext ctx, FullHttpRequest req) {
// ... 握手
ChannelFuture handshake = handShaker.handshake(ctx.channel(), req);
handshake.addListener(future -> {
if (future.isSuccess()) {
// 1. 先设置本地映射
LocalChannelManager.addUserChannel(uidStr, ctx.channel());
// 2. 再设置 Redis 在线状态
userStatusManagerService.userConnectSuccessAfter(
ImConstant.UserStatus.ON_LINE.getValue(), uidStr);
// 3. 异步推送离线数据
CompletableFuture.runAsync(() -> {
pushOfflineFriendRequests(ctx, uid);
pushOfflineFriendResponses(ctx, uid);
}, threadPoolTaskExecutor);
}
});
}注意顺序:先 LocalChannelManager,再 Redis 状态 。为什么?因为后续操作(推送离线消息、心跳管理)都依赖 LocalChannelManager 里的映射。如果 Redis 状态设置失败,可以在 catch 里回滚本地映射。反过来就不行------Redis 状态设好了,本地映射没设好,其他线程查 LocalChannelManager 找不到用户,消息投递就会丢。
还有一个细节:离线数据推送是 异步的 。握手成功的 Listener 里不能做耗时操作,否则会阻塞 Netty 的 IO 线程。推送离线好友请求通过 CompletableFuture.runAsync 放到业务线程池,不阻塞握手响应。
7.3 Protobuf 消息分发:业务线程隔离
java
// 收到 Protobuf 二进制帧
if (frame instanceof BinaryWebSocketFrame) {
ByteBuf content = ((BinaryWebSocketFrame) frame).content();
int readableBytes = content.readableBytes();
// 消息长度检查(10KB 限制)
if (readableBytes > MAX_MESSAGE_LENGTH) {
ctx.close();
return;
}
byte[] bytes = new byte[readableBytes];
content.getBytes(content.readerIndex(), bytes);
ImProtoRequest protoRequest = ImProtoRequest.parseFrom(bytes);
// 检查线程池队列长度
ThreadPoolExecutor executor = threadPoolTaskExecutor.getThreadPoolExecutor();
if (executor.getQueue().size() > MAX_QUEUE_SIZE) { // 1000
log.warn("线程池队列过长,拒绝处理消息");
return;
}
// 异步分发到业务线程池
CompletableFuture.runAsync(() -> {
handlerDispatcher.dispatcher(ctx, protoRequest);
}, threadPoolTaskExecutor);
}为什么要把消息分发从 Netty IO 线程剥离?
Netty 的 Worker 线程是共享的,一个 Worker 线程负责多个 Channel。如果某个 Channel 的消息处理耗时 50ms(比如查数据库),同一个 Worker 上的其他 100 个 Channel 这 50ms 内都收不到数据。
用 CompletableFuture.runAsync 把业务逻辑放到独立线程池,Worker 线程只负责收发数据,IO 和业务完全解耦。
线程池队列长度也做了保护:超过 1000 个任务排队时直接丢弃,防止任务堆积导致 OOM。这是一种 有界队列 + 丢弃策略 的背压设计。
背压(Backpressure)的两种实现:
本系统用了两层背压:
- Netty 写水位线 (TCP 发送端背压):
WriteBufferWaterMark(32KB, 128KB)。当待写数据超过高水位,Channel 变为不可写,ctx.channel().isWritable()返回 false。业务代码应该检查这个状态:
java
if (ctx.channel().isWritable()) {
ctx.writeAndFlush(response);
} else {
// 丢弃或缓存,避免 OOM
log.warn("Channel 不可写,丢弃消息");
}- 线程池队列限制 (业务处理端背压):队列超过 1000 直接丢弃。这看似粗暴,但在高负载场景下,丢弃比堆积更安全。如果让队列无限增长,最终会拖垮整个 JVM。
背压的本质思想来自 响应式流(Reactive Streams) 规范:下游处理不过来时,必须通知上游减速或停止。Netty 的水位线机制就是背压在传输层的实现,线程池队列限制是背压在业务层的实现。
7.4 只支持 Protobuf,文本消息直接关闭连接
java
if (frame instanceof TextWebSocketFrame) {
log.warn("收到文本消息,系统仅支持 Protobuf 二进制格式,请升级客户端");
ctx.close();
return;
}在 第二篇 Protobuf 协议设计 里详细说过为什么从 JSON 切到 Protobuf。这里直接把文本消息的口子堵死,防止老版本客户端用 JSON 发消息造成解析异常。
7.5 生产环境必须:SSL/TLS 配置
前面所有内容都建立在明文 WebSocket(ws://)的基础上。但生产环境必须使用加密连接(wss://),原因很简单:JWT Token 在握手请求头里明文传输,不用 TLS 等于裸奔。
SslHandler 在 Pipeline 中的位置 :必须放在 HttpServerCodec 前面。因为 TLS 握手发生在 HTTP 请求之前------客户端先建立 TLS 连接,然后在这个加密通道里发送 HTTP 升级请求。如果 SslHandler 放在 HttpServerCodec 后面,HttpServerCodec 收到的是加密后的乱码字节,根本无法解码。
java
// WebSocketChannelInitializer.java - 生产环境 SSL 配置
@Override
protected void initChannel(SocketChannel ch) {
ChannelPipeline pipeline = ch.pipeline();
// ⓪ SSL/TLS 处理(必须在 HttpServerCodec 之前)
if (sslContext != null) {
pipeline.addLast(sslContext.newHandler(ch.alloc()));
}
// ① 调试日志
// ② HTTP 编解码(此时收到的已经是解密后的明文)
pipeline.addLast(new HttpServerCodec());
// ... 后续 Handler 不变
}SslContext 的创建和证书加载:
java
@Configuration
public class SslConfig {
@Value("${im.netty.ssl.enabled:false}")
private boolean sslEnabled;
@Value("${im.netty.ssl.cert-path:}")
private String certPath;
@Value("${im.netty.ssl.key-path:}")
private String keyPath;
@Value("${im.netty.ssl.key-password:}")
private String keyPassword;
@Bean
public SslContext sslContext() throws SSLException {
if (!sslEnabled) {
return null; // 开发环境可以关闭 SSL
}
// 加载证书和私钥
InputStream certChain = new FileInputStream(certPath); // PEM 格式的证书链
InputStream key = new FileInputStream(keyPath); // PEM 格式的私钥
return SslContextBuilder.forServer(certChain, key, keyPassword)
// 推荐使用 JDK 的 SSL 提供者,OpenSSL 性能更好但需要额外依赖
// 如果引入了 netty-tcnative 依赖,可以用 OpenSSL:
// .sslProvider(SslProvider.OPENSSL)
.sslProvider(SslProvider.JDK)
// 只支持 TLS 1.2 和 1.3,禁用不安全的 TLS 1.0/1.1
.protocols("TLSv1.2", "TLSv1.3")
// 加密套件:优先使用 AEAD(GCM/ChaCha20)
.ciphers(Http2SecurityUtil.CIPHERS, SupportedCipherSuiteFilter.INSTANCE)
.build();
}
}Nginx 终结 SSL vs Netty 直连 SSL:
在实际部署中,我们选择了 Nginx 终结 SSL,而不是让 Netty 直接处理 TLS。原因是:
| 方案 | 优点 | 缺点 |
|---|---|---|
| Nginx 终结 SSL | 证书管理集中、Nginx 的 OpenSSL 实现更成熟、可以复用 Nginx 的连接池 | 多一跳网络开销(通常在内网,影响极小) |
| Netty 直连 SSL | 少一跳,理论上延迟更低 | 证书管理分散到每个 im-connect 实例、需要引入 netty-tcnative 原生库 |
我们的部署架构是 客户端 → Nginx(443/wss) → im-connect(8085/ws),Nginx 负责 TLS 终结,im-connect 内部走明文 WebSocket。这样 im-connect 不需要关心证书,SSL 配置只用在 Nginx 侧:
text
# Nginx 配置
server {
listen 443 ssl;
server_name im.example.com;
ssl_certificate /etc/nginx/ssl/im.example.com.pem;
ssl_certificate_key /etc/nginx/ssl/im.example.com.key;
ssl_protocols TLSv1.2 TLSv1.3;
location /ws {
proxy_pass http://192.168.1.131:8085;
proxy_http_version 1.1;
proxy_set_header Upgrade $http_upgrade;
proxy_set_header Connection "upgrade";
proxy_set_header X-Real-IP $remote_addr;
proxy_read_timeout 3600s; # WebSocket 长连接超时
}
}但 SslContext 的代码我们保留着,方便在 Nginx 不可用的场景(比如开发环境直连)下快速启用 TLS。
8. 监控:Prometheus 指标 + 连接统计
8.1 MetricsHandler:请求级指标
java
@ChannelHandler.Sharable
public class MetricsHandler extends ChannelInboundHandlerAdapter {
// 总请求数
private static final Counter requests = Counter.build()
.name("netty_requests_total").register();
// 请求延迟分布
private static final Histogram requestLatency = Histogram.build()
.name("netty_request_latency_seconds")
.buckets(0.001, 0.005, 0.01, 0.025, 0.05, 0.1, 0.25, 0.5, 1, 2.5, 5)
.register();
// 按消息类型统计
private static final Counter msgReceived = Counter.build()
.name("netty_msg_received_total")
.labelNames("msg_type").register();
@Override
public void channelRead(ChannelHandlerContext ctx, Object msg) throws Exception {
requests.inc();
Histogram.Timer timer = requestLatency.startTimer();
try {
if (msg instanceof ImProtoRequest) {
msgReceived.labels(((ImProtoRequest) msg).getType().name()).inc();
}
super.channelRead(ctx, msg);
} finally {
timer.observeDuration();
}
}
}MetricsHandler 是无状态的(所有数据存在 Prometheus 的静态变量里),所以可以每次 new 一个新实例。
8.2 连接数和 ByteBuf 池监控
java
// MetricsConfig.java - Prometheus Gauge 注册
@Component
public class MetricsConfig {
@PostConstruct
public void init() {
// 连接数指标
Gauge.build("netty_connections_active", "Active connections")
.register()
.setChild(() -> (double) LocalChannelManager.getActiveConnectionCount());
Gauge.build("netty_online_users", "Online users")
.register()
.setChild(() -> (double) LocalChannelManager.getAllOnLineUserId().size());
// ByteBuf 池指标
Gauge.build("netty_buffer_direct_used_bytes", "Direct buffer used")
.register()
.setChild(() -> (double) PooledByteBufAllocator.DEFAULT.metric().usedDirectMemory());
Gauge.build("netty_buffer_heap_used_bytes", "Heap buffer used")
.register()
.setChild(() -> (double) PooledByteBufAllocator.DEFAULT.metric().usedHeapMemory());
}
}Grafana 面板上可以直接看到:
- 当前在线连接数
- 当前在线用户数
- ByteBuf 池的内存使用量(堆内 + 堆外)
- 请求延迟 P50/P95/P99
9. 优雅关闭:不丢消息地停机
java
// NettyServer.java
@PreDestroy
public void shutdownGracefully() {
// 1. 关闭服务器通道(不再接受新连接)
if (serverChannel != null && serverChannel.isActive()) {
serverChannel.close().sync();
}
// 2. 优雅关闭 EventLoopGroup
bossGroup.shutdownGracefully();
workerGroup.shutdownGracefully();
}
// ShutdownHandler.java
@Component
public class ShutdownHandler implements ApplicationListener<ContextClosedEvent> {
@Override
public void onApplicationEvent(ContextClosedEvent event) {
// 清理所有用户的 Redis 在线状态
Set<String> userIds = LocalChannelManager.getAllOnLineUserId();
for (String userId : userIds) {
userStatusManagerService.userDisconnectAfter(userId);
}
LocalChannelManager.closeAllConnections();
}
}关闭流程:
- 停止接受新连接(关闭 ServerSocketChannel)
- 关闭所有已建立的连接(Channel.close)
- 清理本地映射(LocalChannelManager.clear)
- 清理 Redis 状态(在线状态、Token 映射)
- 释放线程池资源(EventLoopGroup.shutdownGracefully)
shutdownGracefully() 的特点是:它会等待所有正在处理的任务完成后再关闭,不会粗暴地中断正在执行的消息处理。
9.1 优雅关闭完整时序
上面的代码给出了骨架,但线上实际关闭的过程要精细得多。一次完整的优雅停机,从触发到完成,需要经历以下步骤:
bash
触发停机(SIGTERM / kill / Spring Actuator shutdown)
│
▼
① Nginx 摘流(从 upstream 移除该节点)
│ 新连接不再路由到本节点
│ 已有连接不受影响
▼
② Spring 容器开始关闭,触发 @PreDestroy
│
├── ②a 关闭 ServerSocketChannel
│ serverChannel.close().sync()
│ → 操作系统层面关闭监听端口
│ → 新的 TCP SYN 包会被拒绝(Connection Refused)
│ → 已建立的连接不受影响
│
├── ②b 等待在途消息处理完成(quiet period)
│ 业务线程池:等队列中的任务执行完毕
│ Worker EventLoop:等已读取但未处理完的消息走完 Pipeline
│ 时间窗口:默认 2 秒(quietPeriod),最长等 15 秒(timeout)
│
├── ②c 向所有已连接客户端发送 CloseWebSocketFrame
│ 遍历 LocalChannelManager 中的所有 Channel
│ 逐个发送 CloseWebSocketFrame(正常关闭帧,状态码 1000)
│ 客户端收到后会主动断开,触发 channelInactive 回调
│
├── ②d 关闭所有 Channel
│ LocalChannelManager.closeAllConnections()
│ 遍历 userIdChannelMap,逐个 Channel.close()
│
├── ②e 清理 Redis 在线状态
│ 遍历所有在线用户,调用 userStatusManagerService.userDisconnectAfter()
│ 删除 Redis 中的在线标记、设备信息
│ 这一步必须在 Channel 关闭之后------否则会出现短暂的"用户不在线"
│ 但实际上已经连着(channelInactive 还没触发)的不一致状态
│ (注意:因为是 Redis 远程操作,这一步即使部分失败也不影响连接关闭)
│
└── ②f 释放 EventLoopGroup 资源
bossGroup.shutdownGracefully(2, 15, TimeUnit.SECONDS)
workerGroup.shutdownGracefully(2, 15, TimeUnit.SECONDS)
→ quietPeriod=2s:等待 2 秒,期间新提交的任务会被拒绝
→ timeout=15s:最多等 15 秒,超时后强制关闭为什么需要 Nginx 摘流(步骤 ①)?
如果不摘流直接停机,Nginx 还会把新连接路由到正在关闭的节点上。虽然 ServerSocketChannel.close() 会拒绝新连接,但在这之前可能有 TCP 握手已经完成但 HTTP 升级还没开始的连接------这些连接会收到一个 RST 而不是正常的关闭帧,客户端体验很差。
通过 Nginx 摘流,先停止新连接进入,等在途连接自然关闭或超时关闭,再执行后续步骤。在生产环境中,这一步通常通过调用 Nginx 的 API 或修改 upstream 配置实现,也可以配合 Kubernetes 的 preStop hook:
yaml
# Kubernetes deployment.yaml
lifecycle:
preStop:
exec:
command: ["/bin/sh", "-c", "sleep 10"] # 给 Nginx/Ingress 时间摘流Kubernetes 发送 SIGTERM 后,preStop hook 会先执行 sleep 10,这期间 Pod 的 Ready 状态变为 false,Service 不再把流量路由到这个 Pod。等 sleep 结束后才真正开始 Spring 容器的关闭流程。
shutdownGracefully 的两个参数:
java
bossGroup.shutdownGracefully(2, 15, TimeUnit.SECONDS);- quietPeriod(2 秒):静默期。在这段时间内,EventLoop 不接受新任务,但会处理完已提交的任务。如果所有任务在 1 秒内就处理完了,不会傻等 2 秒,直接关闭。
- timeout(15 秒):最大等待时间。如果 15 秒后还有任务没处理完,强制关闭。这是兜底------防止某个卡住的任务(比如死锁、外部服务无响应)导致进程永远不退出。
这个设计在 IM 场景下非常关键:如果粗暴关闭,正在处理中的消息(已经从 Channel 读取但还没写入 MongoDB)就会丢失。优雅关闭确保了这些在途消息要么处理完毕,要么超时后放弃(但不会丢------因为客户端的重连重发机制会兜底,这个在 05 篇讲)。
10. 总结:Pipeline 是骨架,心跳是脉搏,连接管理是心脏
| 组件 | 职责 | 关键设计 |
|---|---|---|
| NettyServer | 启动引导 | Epoll 自动检测,线程数可配,ByteBuf 池化 |
| WebSocketChannelInitializer | Pipeline 编排 | 11 个 Handler 严格有序,协议→安全→业务 |
| AuthHandler | JWT 认证 | 认证成功自移除,IP 防暴力破解 |
| IdleStateHandler + HeartBeatHandler | 心跳保活 | 三次容错,主动 Ping,关闭前二次确认 |
| LocalChannelManager | 连接管理 | 四张 ConcurrentHashMap,多设备支持 |
| ConnectionLimitHandler | 连接限制 | Redis 分布式,全局 + 单 IP + 频率三层限制 |
| FlowControlHandler | 流量控制 | Redis 原子计数,频率 + 大小 + 带宽三维限制 |
| MetricsHandler | 指标采集 | Prometheus Counter + Histogram |
| WebSocketServerHandler | 帧处理 | Protobuf 解析,业务线程隔离,背压保护 |
一个健壮的长连接层,不是某个单一技术的堆砌,而是 Pipeline 编排 + 心跳保活 + 连接管理 + 安全防护 + 监控告警 的系统工程。每一个细节都决定了你的 IM 系统在 10 万在线用户时是稳如磐石还是全线崩溃。
我是 蝎子莱莱爱打怪,欢迎关注我的公众号和星球,文章将第一时间发表到公众号和星球:蝎子莱莱爱打怪
此系列35 篇文章将全量发表到知识星球: 我正在「蝎子莱莱爱打怪·AI与IM学习」和朋友们讨论有趣的话题,你⼀起来吧? t.zsxq.com/Vvopc
XZLL-IM 干货系列共 35 篇,从协议设计到消息投递、从存储方案到性能调优,全部基于真实项目源码,不是 PPT 架构,是踩出来的实战经验。
欢迎点赞、收藏、关注。