1. 概述
距离上一篇文章,已经过去快 3 个月了。春节之后,工作和生活上的事情都比较多,精力确实有限。当然,这些都只能算表层原因。更根本的原因是,我一直找不到一个足够值得写的切入点。
我一贯的写作主旨,都是总结并分享真实的实战经验,而不是为了写文章而写文章。对那些没有太多实际价值的知识点,我不会特意花时间去堆砌和整理。另一方面,这段时间 AI 技术迭代得非常快,我自己也开始更深度地拥抱 AI。从去年 Claude Code 爆火到现在,我越来越强烈地觉得:每个程序员都该认真花时间去学习、掌握并真正用起来。这也会成为我后续文章持续输出的一个方向。
回归正题。事情的背景是这样的:前段时间,有人反馈我们某个系统处理速度比较慢,用户体验不太好。排查之后发现,问题主要集中在两个典型场景上:
- 页面交互根据查询条件勾选全部按钮一次性几万条数据,批量处理生成 PDF 文件,最终再通过短信或邮件发送通知。虽然整体是异步处理,但底层实际仍是串行执行,所以非常慢。
- 每天凌晨需要处理上游同步过来的百万级订单数据,完成数据校验、维度补齐、清洗转换后,再写入我们自己的系统数据库,并要求在第二天业务开始前全部处理完成。
这类任务通常具备以下几个显著特征:
- 数据量大且吞吐要求高:动辄数十万甚至上百万条数据,需要在固定时间窗口内完成拉取、处理和投递。
- 处理逻辑重且耗时长:过程中往往会涉及数据校验、规则计算、维度补齐、聚合统计、状态变更等多个步骤。
- 处理链路长:不只是简单的数据库读写,还可能依赖缓存、消息队列、对象存储以及多个下游服务。
- 资源竞争明显:离线任务和在线业务共享部分基础资源,很容易互相争抢。
如果仍然沿用传统的"定时任务 + 循环处理"单机模式,系统很快就会遇到明显的性能瓶颈,例如:频繁 OOM、CPU 飙高、数据库连接池被打满,甚至因为深分页导致数据库查询彻底卡死。
为了解决这些问题,我们对系统做了一轮较深的异步化和分布式切片并行改造,最终将整体吞吐量提升了近 10 倍。本文就以一个真实业务场景------批量生成 PDF 文件并发送短信或邮件通知------为例,分享这套架构是如何从最初的传统设计,一步步演进到具备"自适应线程切片 + 一次性动态上报 + 数学守恒式分布式对账"能力的高性能批处理架构。
2. 核心架构设计演进
2.1 初代实现
在最早期,大家最容易想到的方案通常是:前端一次性提交一个包含上万条数据的处理任务,后端异步接收后,在后台慢慢执行。
坦白说,能意识到"异步化"已经比直接做成同步接口要好很多了,慢点无所谓,因为在不少团队里,大家默认会认为"大任务慢是正常的",只要最终能跑完就可以。但如果目标是做一个真正可扩展、可持续演进的批处理系统,仅仅"能跑完"显然是不够的。
串行处理的大致流程如下:
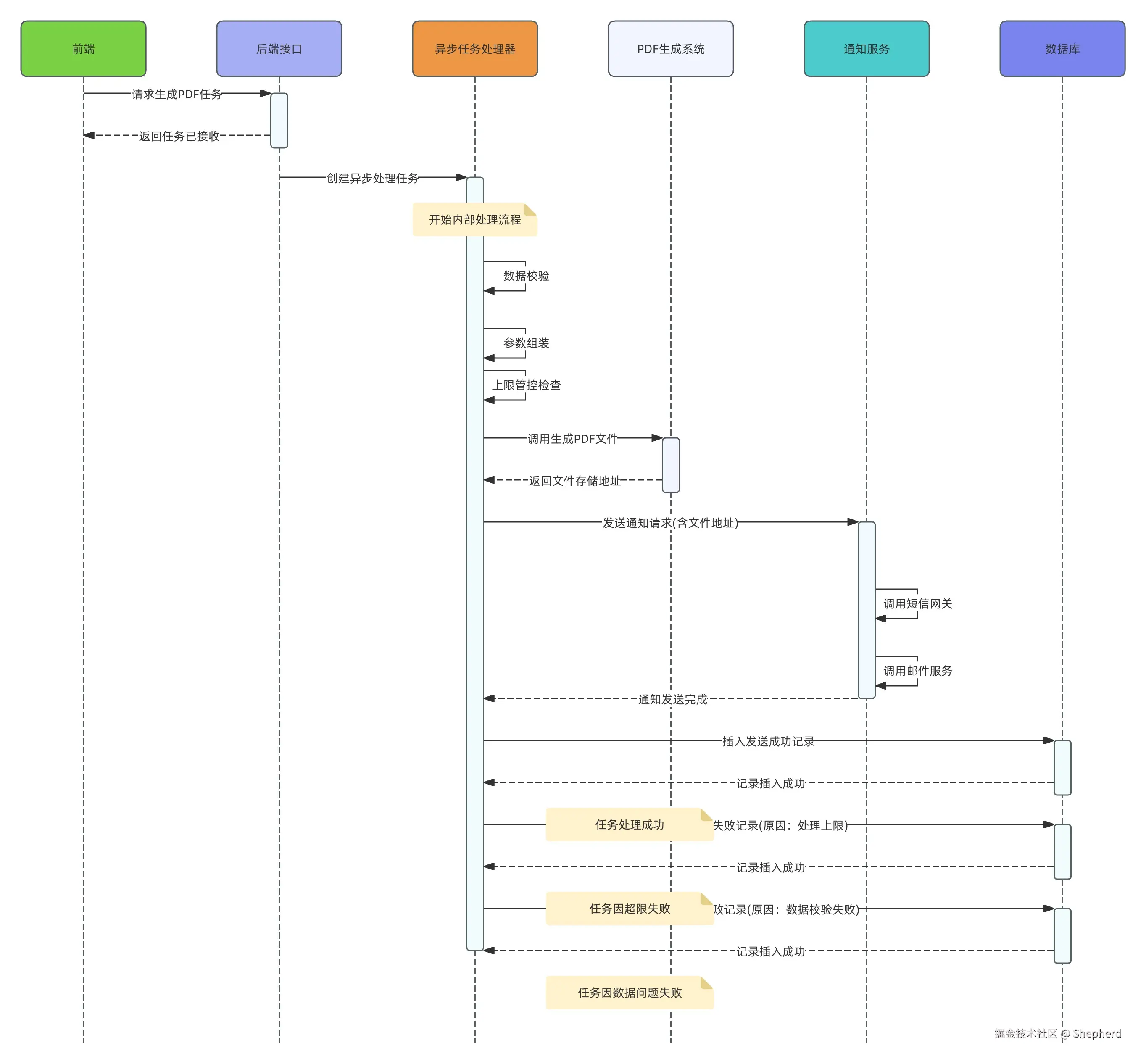
这种串行执行方式,吞吐量注定上不去。要解决单机吞吐瓶颈,靠的不是"更猛地跑",而是"更合理地跑"。在我看来,高并发、大批量数据处理要真正做好,架构演进至少需要遵循下面几个原则。
2.2 架构演进
2.2.1 将大任务拆成小任务,通过分布式调度做分片执行
我们使用分布式任务调度平台(如 XXL-JOB),利用其分片广播(Sharding)策略。
-
执行逻辑 :当调度触发时,调度中心向集群中的所有 Worker 节点广播任务。每个 Worker 节点获取到当前节点的
shardingIndex(当前分片项)和shardingTotal(总分片数)。 -
数据路由:SQL 查询时通过 ID 取模进行分片:
sqlSELECT * FROM tb_data WHERE 字段 = '查询条件' AND MOD(id, #{shardingTotal}) = #{shardingIndex}
这样一来,原本堆积在单机上的百万级数据,就能被分散到集群中的多个节点上并行处理,真正实现横向扩展。
XXL-JOB 获取"节点总数"和"当前节点索引"的方式如下:
ini
int nodeIndex = XxlJobHelper.getShardIndex();
int nodeTotal = XxlJobHelper.getShardTotal();工作原理说明
- 动态感知 :
shardTotal是 XXL-JOB 调度中心(Admin)根据当前自动注册 且健康的执行器节点数量动态计算的。如果你临时增加了 2 台机器,下一轮调度时shardTotal就会自动增加。 - 路由策略 :在 XXL-JOB 管理后台配置任务时, "路由策略"必须选择"分片广播" 。如果选择了其他策略(如轮询、随机),那么
shardTotal永远都是 1。
如果系统里没有现成的分布式调度平台,这个分片逻辑其实也并非完全做不了。只要系统本身具备服务注册中心(如 Nacos、Zookeeper 等),理论上都能实现类似的分片能力。如果连服务注册中心都没有,那就只能先把最基础的节点协调能力补起来了。我之前在分布式延时队列组件里就实现过一个简易版的服务注册中心,感兴趣的话可以看看这篇文章:破局延时任务(下):Spring Boot + DelayQueue 优雅实现分布式延时队列(实战篇)
分片逻辑 1.0
ID 取模的局限性 :如果查出来的数据 ID 分布不均匀,例如恰好全是偶数,而你又正好有 2 个节点,那么所有数据都会堆积在节点 0 上。另一方面,如果没有其他查询条件,直接通过 WHERE id % total = index 进行分片,往往无法有效走索引,容易触发全表扫描,性能会比较差。
当然,对于"每日凌晨处理前一天数据"这类批处理任务,ID 取模依然是比较适合的。因为通常都会带时间范围过滤,而且查出来的 ID 分布一般也不会极端失衡。
分片逻辑 2.0 :同步查出所有数据 ID,以 taskId 为 Key 存入 Redis,再由异步任务从中完成分片
ini
List<Long> sharding(Long taskId) {
// 获取 dataId,并按照升序排序
List<Long> idList = redisUtil.sGet(KeyCache.BATCH_SEND_PDF_TASK_LIST + taskId)
.stream()
.map(Long::parseLong)
.sorted()
.collect(Collectors.toList());
// 当前节点索引
int shardIndex = XxlJobHelper.getShardIndex();
// 总分片数
int shardTotal = XxlJobHelper.getShardTotal();
log.info("当前节点索引: {}, 总分片数: {}", shardIndex, shardTotal);
List<Long> dataIds = new ArrayList<>();
for (int i = 0; i < idList.size(); i++) {
if (i % shardTotal == shardIndex) {
dataIds.add(idList.get(i));
}
}
return dataIds;
}利用 Redis 集合作为数据媒介,在各个节点上通过内存计算,以一种更轻量、无锁的方式实现静态分片分配。这种设计很清爽。每个 Java 节点在拿到 dataIds 的那一刻,这台机器需要负责哪些数据就已经完全确定了,而且数据通常能够比较均匀地分布到各个节点上。
分片逻辑 3.0 :和 2.0 一样,先查出所有数据 ID 存入 Redis,但不再静态切分,而是批量从 Redis List 右侧弹出 ID。当 RPOP 返回空时,说明该任务的数据已经被抢空,当前节点结束执行。
arduino
while (true) {
// 1. 批量从队列右侧弹出 ID(Lua 脚本或管道,单次弹出 200 条)
List<String> detailIds = redisTemplate.execute(popLuaScript, Collections.singletonList(redisKey), String.valueOf(batchSize));
// 2. 如果队列空了,说明被所有节点瓜分完毕,直接退出
if (CollectionUtils.isEmpty(detailIds)) {
break;
}
// 3.任务处理
// ...
}相比前两种分片逻辑,这个方案有几个非常明显的优势:
优势一:天然具备"能者多劳"的动态负载均衡能力
- 原方案缺点:如果 2 个节点分片,通过 ID 取模各分 2500 条。如果节点 A 的机器性能好,处理得快,它干完活只能闲着;而节点 B 的机器卡顿,就会堆积。
- 新方案优势 :Redis List 充当了分布式任务池。哪个 Java 节点性能好、线程空闲得多,它从 Redis 里
RPOP拿到的 ID 就多。天然实现了动态负载均衡。
优势二:更能免疫扩容/缩容带来的分片震荡
- 原方案缺点 :如果在 XXL-JOB 执行过程中,你发现 5000 条处理太慢,临时拉起 2 台新机器(扩容)然后立即执行。此时
shardingTotal从 2 变成 4,SQL 取模逻辑立刻大乱,会导致不同节点抢到同一条数据。 - 新方案优势 :由于数据已经在 Redis 队列里了,你哪怕临时拉起 10 台机器一起去
RPOP,Redis 的单线程原子性也能保证一条数据绝不会被两个节点同时抢到。
以上几种分片方案并没有绝对的好坏,关键还是看哪一种更适合你的业务场景。Redis 方案虽然灵活,但如果任务数据量达到几十万甚至几百万条,直接同步塞入 Redis,很容易导致接口初始化阶段卡顿,还可能形成大 Key。再比如,有些业务场景要求同一个业务编号写入两次时,第一次插入、第二次更新覆盖,那么你就只能基于业务编号进行路由,保证同一个业务编号的数据始终落在同一个节点上顺序执行。
2.2.2 并行处理,但并发必须受控
如果一个任务链路里既有本地计算,又有数据库读写,又有远程调用,而且全部串在一个同步流程里,那么它的吞吐能力往往会非常有限。更好的方式,是把任务拆成多个阶段并通过多线程并行执行。
以上面的"批量生成 PDF 文件并发送短信通知"任务为例,数据之间没有前后依赖关系,因此在单节点内部继续做分片并行执行,就能够进一步提升吞吐量。
scss
// 按照 200 条一批进行切片发送
List<List<Data>> partitions = Lists.partition(dataList, 200);
// 每个切片异步发送
List<CompletableFuture<PartitionResult>> futures = partitions.stream()
.map(subdataList -> CompletableFuture.supplyAsync(() -> {
try {
// 执行单个切片发送逻辑,并返回该切片的执行结果
return doSendLetter(param, subdataList, session, orgSwitch);
} catch (Exception e) {
log.error("切片批次异步处理异常, data 数量: {}", subdataList.size(), e);
// 如果单片发生未捕获死锁或崩盘,整片计入失败
return new PartitionResult(0, subdataList.size());
}
}, threadExecutor))
.collect(Collectors.toList());
// 阻塞等待当前批次所有异步切片执行完毕
CompletableFuture.allOf(futures.toArray(new CompletableFuture[0])).join();并行处理固然重要,但"高并发"不等于"无限制开并发"。
一个典型问题是,很多系统只管把任务尽快发出去,却不关心下游是否接得住。结果就是上游产出速度远大于下游消费速度,队列迅速堆积,数据库连接数飙升,RPC 超时增加,重试流量又进一步放大系统压力,最终形成恶性循环。
所以,真正成熟的系统,不会简单把并发度写死在配置里,而是会根据队列堆积、平均耗时、下游错误率以及资源水位来做动态限流和并发调节。
2.2.3 尽量批量化,减少高频小 IO
很多任务吞吐上不去,并不是因为算法慢,而是因为 IO 模式太碎。
比如:
- 每处理一条记录就查一次数据库
- 每处理一条记录就调用一次远程接口
- 每处理一条记录就提交一次事务
这些"小而频繁"的操作,在低规模下可能没问题,但在大批量任务里几乎一定会成为系统杀手。因为真正消耗时间的往往不是业务代码本身,而是网络往返、连接竞争、事务提交和序列化开销。
实践中,通常建议按照 200~500 条作为一个批次进行处理。条数过多,可能导致 IN 查询无法有效命中索引;条数过少,又会带来过高的调用频率。
以上面任务为例,数据校验、参数对象组装、上限管控等逻辑,都应该通过批量查询一次性完成,而不是一条一条去数据库取。
尤其是在组装参数对象时,很多业务数据都来自多张表,需要根据任务的基础数据 data 关联其他表数据,最终拼装出完整的参数对象。
写法一:双重循环匹配
arduino
// 假设:List<User> listA 和 List<UserConfig> listB
// 需求:判断 listA 中的用户是否存在于 listB 中,存在则组装成 UserParam
List<UserParam> result = new ArrayList<>();
for (User user : listA) {
for (UserConfig config : listB) {
if (user.getId().equals(config.getUserId())) {
result.add(new UserParam(user, config));
break;
}
}
}时间复杂度: O(n × m)。
适用场景: 仅当两个 List 的数据量都非常小(比如各自只有几个、十几个元素)时才比较合适。只要数据量一上来,CPU 耗时就会迅速放大,生产环境里应尽量避免。
写法二:Stream API + Map 映射(强烈推荐)
scss
// 1. 将 listB 转换为 Map,方便快速通过 Key 获取 Value
Map<Long, UserConfig> configMap = listB.stream()
.collect(Collectors.toMap(UserConfig::getUserId, Function.identity(), (k1, k2) -> k1));
// 2. 遍历 listA,过滤并组装
List<UserParam> result = listA.stream()
.filter(user -> configMap.containsKey(user.getId()))
.map(user -> {
UserConfig config = configMap.get(user.getId());
return new UserParam(user, config);
})
.collect(Collectors.toList());时间复杂度: O(n + m),其中 n 和 m 分别为两个 List 的长度。
适用场景: 绝大多数常规业务场景都适用,尤其在十万级以下数据量时性能非常好。这本质上就是典型的空间换时间思路。很多时候,性能差距并不来自多复杂的算法,而是来自你在日常业务代码里,能不能及时识别并规避这类低效写法。
2.2.4 最终任务执行情况统计
由于数据被分散到不同的 Java 节点和不同的线程中独立处理,因此在统计"成功数""失败数"以及更新任务进度状态时,核心难点就在于:如何在高并发、分布式环境下,既能精准累加计数,又不把数据库压垮。
这里千万不能每处理完一条数据,就去执行一次数据库更新,例如 UPDATE task_main SET success_count = success_count + 1。这种做法会导致数据库因为剧烈的行锁竞争而迅速卡死。
正确的做法应该是:等当前节点分到的所有数据全部处理完,或者线程池里的任务全部执行完成之后,再一次性提交给数据库。
ini
// 收集发送结果
long successTotal = 0;
long failTotal = 0;
for (CompletableFuture<PartitionResult> future : futures) {
// 因为上面已经 join 过了,这里 getNow() 基本可以视为立即返回
PartitionResult result = future.getNow(new PartitionResult(0, 0));
successTotal += result.getSuccessCount();
failTotal += result.getFailCount();
}
// 处理任务进度
handleTaskProgress(param.getTaskId(), successTotal, failTotal);核心 SQL 设计(防止并发覆盖)
多台机器同时更新同一张主表时,如果直接使用 SET success_count = #{success},就会产生并发覆盖问题。因此这里必须依赖 MySQL 自身的原子累加能力:
xml
<!-- 局部节点更新 SQL -->
UPDATE task_main
SET
success_count = success_count + #{successInc},
fail_count = fail_count + #{failInc},
updated_at = NOW()
WHERE id = #{taskId}由于任务被拆分到了多个 XXL-JOB 节点,每个节点只知道"自己处理完了",但并不知道整个任务是否已经全部结束。那最终谁来负责把主表状态从 PROCESSING 改为 COMPLETED 呢?
方案 A:利用 Redis 计数器做"终态宣判"(最推荐)
在接口把数据写入 Redis 的同时,再额外存一个总件数 Key,例如:flow:task:total:{taskId} = 5000。每个节点在执行完上面的数据库累加之后,紧接着在 Redis 中扣减自己处理掉的总件数:
c
/**
* 处理任务进度
*/
void handleTaskProgress(Long taskId, long success, long fail) {
if (success == 0 && fail == 0) {
return;
}
asyncTaskService.incrementTaskCounts(taskId, success, fail);
long processedCount = success + fail;
// DECRBY 减去当前节点处理掉的总数
Long remaining = stringRedisTemplate.opsForValue()
.decrement("flow:task:total:" + taskId, processedCount);
// 如果返回值等于 0,说明当前节点是整个集群中最后一个干完活的节点
if (remaining != null && remaining <= 0) {
// 由当前节点发起终态修改
taskMainMapper.updateStatus(taskId, "COMPLETED");
// 清理 Redis 缓存
stringRedisTemplate.delete("flow:task:total:" + taskId);
log.info("任务 {} 全部处理完毕,由当前节点完成终态闭环", taskId);
}
}方案 B:利用数据库的字段求和进行"乐观锁判定"
如果不想在 Redis 里多加一个 Key,可以在节点干完活后,用一条带有 WHERE 条件的 SQL 去尝试收尾:
xml
<!-- 尝试将状态改为完成 -->
UPDATE task_main
SET
status = 'COMPLETED',
updated_at = NOW()
WHERE id = #{taskId}
AND (success_count + fail_count) = total_count -- 只有当两个计数器相加等于创建任务时的总数时,才允许变更为终态- 每个节点处理完后都可以尝试执行一次这个更新,只有最后一个把数值补满的节点,才会真正让这条 SQL 的
affected_rows > 0。
3. 应用层深度调优和高可用设计
无论应用层架构设计得多漂亮,最后往往都会卡在数据库上。针对存储层,我们做了两项比较关键的优化:
- 放弃传统 Limit Offset :海量数据下,
LIMIT 500000, 100会导致 MySQL 扫描大量无用数据块。我们改用游标/滚动查询 (Cursor Based Pagination),每次查询带上上一次处理的最大主键WHERE id > #{lastMaxId} ORDER BY id ASC LIMIT #{pageSize},查询效率恒定在毫秒级。 - 大事务化小 :繁重的业务逻辑(如 RPC、外部调用、复杂计算)绝不放在
@Transactional事务块内。只在最终需要更新状态、插入信函交互轨迹记录时,才开启极小的事务块,从而极大地缩减了数据库行锁的持有时间。
大批量任务和在线请求有一个非常大的区别:它更容易"跑很久",也更容易"中途出错"。一旦没有幂等、重试和断点恢复能力,高吞吐系统反而会更脆弱。
必须提前考虑的问题包括:
- 同一分片重复执行怎么办
- 下游超时后是否重试,重试几次
- 某个分片失败后是整批回滚还是单独补偿
- 任务执行到一半进程挂掉,是否可以从断点继续
- 长时间积压的任务怎么回收
真正成熟的批处理系统,衡量标准从来不只是"跑得快",还包括"失败后能不能快速恢复"。当然,也不是所有业务系统都需要把复杂度拉得这么满,最终还是要结合自己的业务场景做权衡。这部分就留给大家结合实际情况继续思考和补充了。
4. 总结
高并发批量任务的本质,其实就是对单机纵向性能(多线程并行、批量化降低 IO) 、集群横向协同(分布式调度) 以及结果对账与终态收敛(Redis 离场宣判) 的一次综合编排。
通过把调度、计算、记账这几个关键层次解耦,我们最终只依赖一套相对轻量的技术组合------XXL-JOB + Redis + MySQL------就支撑起了这类高并发、大批量、长链路复杂任务的稳定运行,并将整体吞吐量提升了近 10 倍。