🤖 从Token到Embedding:一篇文章搞懂大模型的「文字数学变形记」
一篇有温度的技术笔记------理解模型比写代码更重要
一、为什么你的Prompt这么贵?聊聊Token这个「计价刺客」
大家有没有发现,每次调用大模型API,账单上总是写着「总Token数:XXX」?
我刚开始用的时候就很困惑:Token到底是啥?它凭啥按它收费?
直到我踩了一个坑------用GPT-4翻译了一篇5000字的中文文章,花了20多块钱。我心想:不是说百万Token才几块钱吗?怎么这么贵?
后来一查才知道,不同语言的Token消耗差距大得惊人:
| 语言类型 | 字符/Token 比例 | 实际案例 |
|---|---|---|
| 英文 | 1字符 ≈ 0.3 Token | "Hello world" → 2个Token |
| 中文 | 1字符 ≈ 0.6 Token | "你好世界" → 4~6个Token |
| 代码 | 1字符 ≈ 0.2~0.5 Token | 关键字常被合并为单Token |
| 标点符号 | 视语境而定 | 句号可能独立成Token,也可能粘连 |
也就是说,你输入100个中文,差不多要消耗60个Token。加上输出的回复,一来一回,钱包就「瘦身」了。
所以理解Token,就是理解你的钱花在了哪里💰
二、为什么大模型非得「分词」?不能直接读文字吗?
这个问题,我问过身边很多刚入门的AI爱好者,大家的直觉都是:
「计算机不是能处理字符吗?直接读不就好了?」
答案是:不能。因为大模型是个「数学狂魔」,它只认数字,不认字。
简单来说,大模型的底层是神经网络 ,而神经网络的核心运算全是矩阵乘法。
你丢给它一个「你」字,它得先变成 [0.12, -0.34, 0.56, ...] 这样一串数字(向量),才能塞进各种复杂的数学公式里计算。
那为什么不直接把「你」字的Unicode编码 [20320] 丢进去?
因为语义不是靠字符编码决定的。「你」和「我」的Unicode数字很接近吗?不接近。但它们的语义关系却很紧密。如果直接用字符编码,模型学不到任何语义信息。
所以,大模型的做法是:
- 先分词(Tokenization):把文本切成一个个「语义单元」
- 再向量化(Embedding):把每个Token映射成一个高维向量
这样,语义相近的词,向量在空间里也靠得近。这就是大模型能理解你说话的「第一性原理」。
三、手撕Token:用代码看看文字是怎么被「肢解」的
光说不练假把式。我们来写一段代码,看看文本是怎么被编码成Token ID的。
javascript
import { getEncoding } from 'js-tiktoken';
// GPT系列模型用的官方编码器:cl100k_base
const enc = getEncoding('cl100k_base');
const text = "Hello, tiktoken ! 你好,世界";
// 编码:文本 → Token ID数组
const tokens = enc.encode(text);
console.log("Token IDs:", tokens);
console.log("Token数量:", tokens.length);
// 解码:Token ID数组 → 文本
const decodedText = enc.decode(tokens);
console.log("解码回文本:", decodedText);运行结果是这样的:
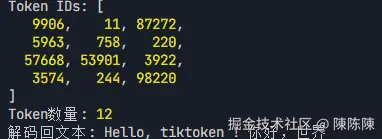
图:tiktoken对中英文混合文本的编码结果,可见中文被切分得更细碎
看到这个结果,你可能会有疑问:为什么"你好,世界"这4个中文字被切成了好几个Token,而"tiktoken"这个英文单词反而被保留为一个完整的Token?
这就涉及到BPE分词算法的一个反直觉之处:Token是语义单元,不是字。
让我们做一个直观的对比实验,看看不同语境下同一个词是如何被切分的:
| 输入文本 | BPE切分结果 | 为什么? |
|---|---|---|
"unhappiness"(英文) |
["un", "happi", "ness"] |
按词根逻辑切分(前缀+词干+后缀) |
"Transformer"(作为AI术语) |
["Transformer"] 或 ["Trans", "former"] |
高频专有名词常被整体保留 |
"变形金刚"(中文) |
["变形", "金刚"] |
按统计概率切分为两个常见语义单元 |
"北京市海淀区"(中文) |
["北京", "市", "海淀", "区"] |
地名和行政区划被拆分重组 |
核心洞察 :BPE的切分依据是统计概率------在训练语料中高频共现的字符序列会被合并为一个Token。所以"变形"和"金刚"在语料中经常一起出现,就被合并了;而"Transformer"作为一个专有名词在技术文档中出现频率极高,也可能被整体保留。
这就是BPE(Byte Pair Encoding)分词算法的威力------它会把高频出现的子词合并成一个Token,从而提升编码效率。
四、Tokenizer之后,Embedding才是真正的「语义变形记」
有了Token ID还不够,因为Token ID只是离散的数字编号(比如 9906),彼此之间没有数学上的「距离感」。
所以下一步,大模型会调用Embedding接口 ,把Token ID转换成稠密向量。
我用的阿里百炼的 text-embedding-v4 模型,它会把文本映射成 1024维 的向量。
javascript
import OpenAI from 'openai';
import dotenv from 'dotenv';
dotenv.config();
const client = new OpenAI({
apiKey: process.env.DASHSCOPE_API_KEY,
baseURL: 'https://dashscope.aliyuncs.com/compatible-mode/v1',
});
async function getEmbedding(text) {
try {
const res = await client.embeddings.create({
model: 'text-embedding-v4',
input: text,
dimensions: 1024 // 输出1024维向量
});
return res.data[0].embedding;
} catch (error) {
console.error("获取Embedding失败:", error);
throw error;
}
}
const vec = await getEmbedding("你好,世界");
console.log(vec.length); // 1024
console.log(vec.slice(0, 5)); // [0.023, -0.456, 0.789, ...]这1024个浮点数,就是文本在数学空间里的「坐标」。每个维度都代表了某种抽象的语义特征,比如:情感倾向、时态、主题类别等等。
但具体每个维度代表什么?没人知道。这就是深度学习的「黑盒」魅力------模型自己学出来的,我们只能观测,无法解释。
关键补充:Embedding不知道「谁在前谁在后」
但是!单纯的Embedding向量有一个致命缺陷:它不知道顺序。
想象一下,你把「你打我」和「我打你」分别编码成向量------如果没有额外信息,这两个向量的语义坐标可能非常接近,因为它们包含的Token(你、打、我)完全一样,只是顺序不同。
但「你打我」和「我打你」的意思完全相反!
为了解决这个问题,大模型在Embedding之后会做一件事:加上位置编码(Positional Encoding)。
Embedding告诉模型这个词是谁,位置编码告诉模型它在哪里。
模型会给每个Token的向量加上一个「位置信号」------早期Transformer用的是正弦波函数,现在很多模型用的是可学习的位置参数。这个信号让模型知道:「你」在第1位,「打」在第2位,「我」在第3位,从而区分出两个完全相反的意思。
五、余弦相似度:用数学判断两段文字「是不是一个意思」
有了向量,我们就可以做一件很酷的事情:计算两段文本的语义相似度。
最常用的方法是余弦相似度(Cosine Similarity),它的公式是:
css
cos(θ) = (A · B) / (|A| × |B|)翻译成人话就是:两个向量的夹角越小,说明它们越相似。
我们来实战一下:
javascript
function cosineSimilarity(vecA, vecB) {
let dot = 0, magA = 0, magB = 0;
for (let i = 0; i < vecA.length; i++) {
dot += vecA[i] * vecB[i];
magA += vecA[i] ** 2;
magB += vecB[i] ** 2;
}
return dot / (Math.sqrt(magA) * Math.sqrt(magB));
}
async function run() {
const text1 = "Andrej Karpathy LLM Tokenization 分词原理";
const text2 = "卡帕西讲解大模型BPE字词分词";
const text3 = "今天天气晴朗,适合出门散步";
const vec1 = await getEmbedding(text1);
const vec2 = await getEmbedding(text2);
const vec3 = await getEmbedding(text3);
console.log("text1 vs text2 相似度:", cosineSimilarity(vec1, vec2));
console.log("text1 vs text3 相似度:", cosineSimilarity(vec1, vec3));
console.log("text2 vs text3 相似度:", cosineSimilarity(vec2, vec3));
}
run();输出结果是:

图:余弦相似度计算对比------前两段文本语义高度相关,与无关文本得分差距明显
看到了吗?前两段文字虽然语言不同(中英文混合),但语义高度相关,余弦相似度高达0.66。而和「天气散步」完全不搭边,相似度只有不到0.2。
这就是Embedding的魔力------它跨越了语言的表面形式,直达语义的本质。
延伸应用:向量数据库与RAG(检索增强生成)
这种相似度计算能力,正是当下最火的RAG(检索增强生成) 技术的基石。
简单来说:
- 我们把大量文档切片,每段都通过Embedding变成向量,存入向量数据库
- 用户提问时,把问题也变成向量
- 去数据库里「找最像的片段」------就是余弦相似度最高的那些
- 把这些片段连同用户问题一起喂给大模型
这样一来,大模型就能基于你的私有知识库回答问题,而不只是依赖它的训练数据。
吴恩达在LangChain和RAG的教程中详细讲解了这套架构,如果对这个方向感兴趣,强烈推荐去了解一下------这是目前企业级AI应用最主流的落地方式。
六、整个流程串起来:一次大模型调用背后发生了什么?
当你输入 "你好,今天天气怎么样?" 时,大模型背后经历了这样一场「变形记」:
css
┌─────────────┐
│ 用户输入 │ "你好,今天天气怎么样?"
└──────┬──────┘
▼
┌─────────────┐
│ Tokenizer │ 分词 → [你, 好, 今天, 天气, 怎么样, ?]
└──────┬──────┘
▼
┌─────────────┐
│ Embedding │ 映射成 1024维 向量 [0.12, -0.34, ...]
└──────┬──────┘
▼
┌─────────────┐
│ + 位置编码 │ 给每个Token打上「位置标签」
└──────┬──────┘
▼
┌─────────────┐
│ Transformer │ 神经网络计算(自注意力、前馈网络......)
└──────┬──────┘
▼
┌─────────────┐
│ 解码器 │ 输出Token序列 → [今天, 天气, 晴朗, 适合, 出门]
└──────┬──────┘
▼
┌─────────────┐
│ 输出文本 │ "今天天气晴朗,适合出门"
└─────────────┘注意:整个过程,真正「烧钱」的运算都在Transformer那一步。而Tokenizer和Embedding只是前戏,但它们决定了模型能不能正确理解你的输入。
七、我的LLM学习路线图
如果你看到这里还意犹未尽,说明你也想系统地学LLM。我分享一下我的学习路径,弯路帮你踩过了,你照着走就行:
第一步:先搞懂「AI到底是个啥」
- 吴恩达 的《Generative AI for Everyone》------对非技术背景极其友好,1小时就能建立全局认知。建议直接看他2026年更新的最新课程,里面有关于Agent(智能体)的最新内容。
- Andrej Karpathy (特斯拉前AI总监、OpenAI创始成员)的3小时大模型入门视频------我愿称之为「大模型原理天花板」,经典必看 ,B站就有:www.bilibili.com/video/BV16c...
第二步:动手「用」起来,别光看
- 把日常重复性工作交给AI:写周报、翻译、代码注释
- 试试 Google NotebookLM,体验RAG的威力
- 关注 Google Veo 3.1 和 Sana------2026年最新发布的工具,据说职场效能提升10倍
- 用 Obsidian 搭建你的「第二大脑」,让AI帮你管理知识
第三步:做个人作品(Vibe Coding)
不要怕菜,直接上手做一个完整的项目:
- 一个AI聊天网站
- 一个微信小程序
- 一个Agent自动化工具
做完一个项目,比看100个教程都有用。
第四步:关注优质信息源
- 晓辉博士:专业有深度,不注水
- 42章经:商业视角解读AI
- 宝玉AI:Prompt Engineering实战,与时俱进
- 归藏:AI产品观察
八、最后:Token虽小,但它是理解大模型的「第一块砖」
从Tokenizer到Embedding,从Token ID到余弦相似度,这趟旅程让我深刻体会到:
大模型不是魔法,它只是一套精心设计的「数学翻译系统」。
它把人类的自然语言,翻译成高维空间的向量,再通过海量参数拟合出复杂的语义关系。而我们开发者要做的,就是理解这套翻译规则,然后优雅地调用它。
最后送大家一句话,也是Karpathy在视频里反复强调的:
"The most important skill in the AI era is not coding, but understanding what the model is actually doing."
(AI时代最重要的技能不是写代码,而是理解模型到底在做什么。)