作者:无哲
引言:
我们是阿里云日志服务 SLS 团队。SLS 是阿里云上的一站式日志与可观测平台,每天承载着海量企业日志的采集、存储、查询、分析与投递。过去十几年里,写入 LogStore 的日志一直都是不可变的。但最近,我们给它加上了对已有数据的原生 update 和 delete 能力。今天想借这篇文章,聊聊我们为什么要做这件事,以及背后的设计取舍。
前言
"日志能不能改?"
过去十几年,SLS 的答案一直很明确:不能,也不应该。
因为 LogStore 的底层是 Append-only 的设计,写下去就是历史,这也是日志系统在性能、稳定性、审计可信上的核心优势。
那这次,我们为什么要给它加上修改和删除的能力?
要回答这个问题,我们首先回顾一下这些年来日志的发展历程,可以看到日志的用途一直在不断地被拓展。
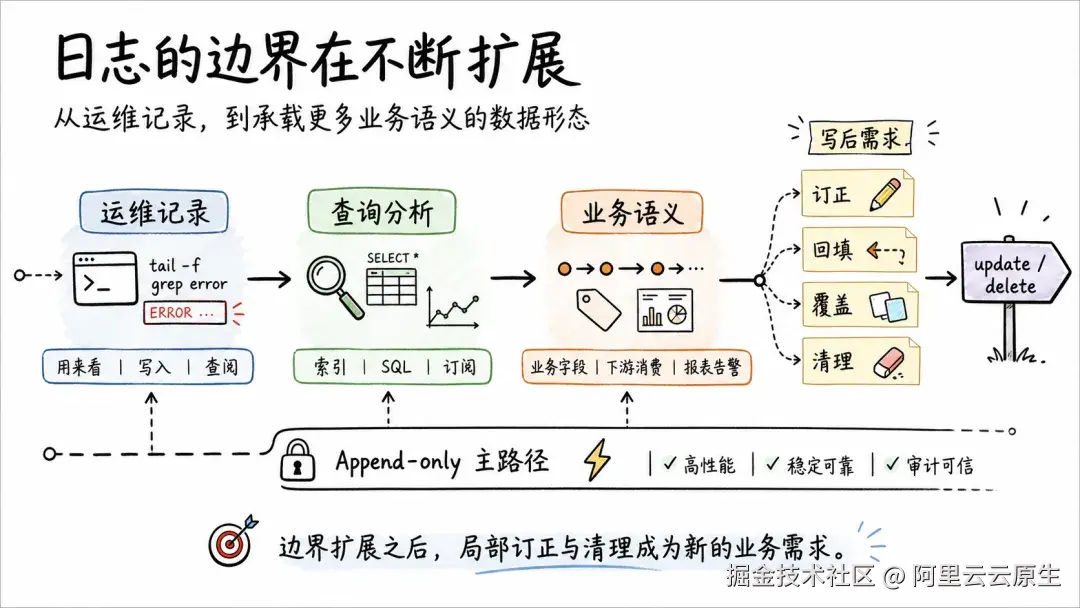
第一阶段:日志是用来看的
最早的日志就是给人看的。服务出问题了,登上机器 tail -f 一下,grep 几个关键字,看看哪一行报错。到了集中式日志系统这一代,"看日志"这件事被搬到了浏览器里,但本质没变:日志的生命周期仍然很简单,写入、查阅,然后在过期后被清理。
这种使用方式给日志系统带来了一个非常清晰的设计前提:只追加,不修改。
写入路径不需要锁,不需要版本对齐;存储布局天然按时间组织;下游消费者只要记录 offset,就能恢复消费进度。日志系统的高吞吐、低成本和稳定性,很大程度上都建立在这套规则之上。
第二阶段:日志是用来分析的
后来,日志开始被结构化、被索引、被查询分析。
SLS 也是在这一阶段不断补齐 SQL、SPL、聚合函数、机器学习算子、告警、仪表盘和投递消费等能力。日志不再只是排查问题时才会打开的文本,而是逐渐成为业务系统里的数据源。
风控系统订阅用户行为日志做实时规则匹配,监控系统基于网关日志计算 P99 和 QPS,安全团队在审计日志里做关联分析,BI 团队把交易日志聚合后喂给报表。
日志从"被人读",变成了"被程序读",持续进入分析、告警、报表和自动化消费链路。
但这一阶段仍然没有动摇 Append-only 的基础。写入路径依然是简单追加,只是在追加写之上增强了索引、计算和消费能力。SLS 要解决的问题,是让查询更快、分析更完整、订阅更顺畅,而不是去改变已经写入的数据本身。
第三阶段:"日志"承载了更多的业务场景
随着日志承载的业务语义越来越多,订正、回填、覆盖、清理这类过去很少出现在日志系统里的需求,也开始变得常见。
典型场景包括:
- 计量计费明细按账期生成后,月底因为优惠、退款或调账需要修正部分记录;
- AI Pipeline 产出的用户特征或内容标签,模型升级后需要对历史数据批量重算并覆盖旧结果;
- 风控系统上线新版评分规则后,发现旧规则对部分用户的风险等级评估偏低,需要批量修正;
- LLM / Agent 应用中的用户反馈、人工标注、质量评分等信息,通常在请求结束后延迟到达,需要回填至原始记录;
- 采集配置错误、测试流量误入生产后,需要按条件定向清理。
过去遇到这些需求,用户通常需要通过软删重写、外部 KV / 数据库补充可变字段,或者追加新记录再让下游自行合并等方式处理。方案可以走通,但链路更长,维护成本更高,一致性也更难保证。
如果 LogStore 能够原生支持局部更新和删除,这类场景就可以在 LogStore 内部完成闭环,不必再绕道外部系统。
设计取舍
仔细看前面这些场景,数据主体仍然具备典型的日志特征:持续产生、写入量大、天然按时间组织,通常是半结构化的;同时又需要查询、分析、告警、报表,也需要被下游消费和投递。
而正是这些特征,让 LogStore 逐步形成了今天的能力组合:弹性容量、灵活 Schema、高吞吐追加写、低成本存储、强查询分析,以及完善的消费和投递生态。
现在多了局部更新的需求,但核心特征没有变:仍然是大量追加为主、少量修正为辅。
因此这次 LogStore 原生支持 update/delete,核心设计原则是:追加写仍然是主路径,修改与删除是面向已有数据的补充路径。
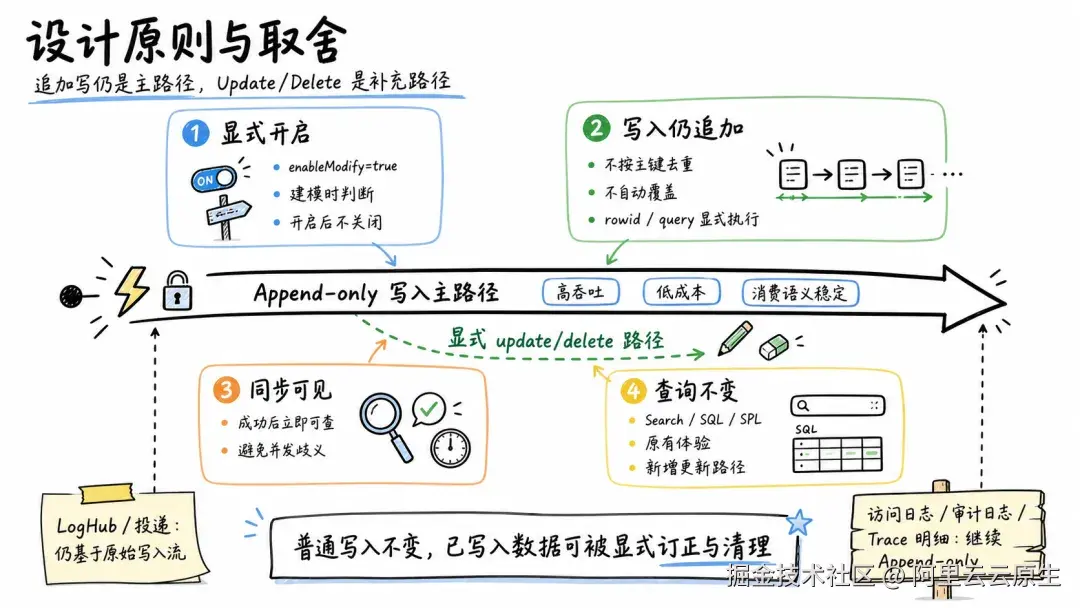
具体来说,体现在以下几个设计决策上。
1. 修改能力需要显式开启
只有在 LogStore 属性上设置 enableModify=true,才会启用修改与删除能力(开启后不支持再关闭)。
对于访问日志、审计日志、Trace 明细等不需要修改的数据,继续沿用 Append-only 模型即可。
2. 原始数据写入请求仍是 Append-Only
开启 enableModify=true 之后,新数据写入仍然是直接追加写,这意味着写入请求不会按某个业务主键去重,也不会自动覆盖已有记录。如果需要修改或删除已写入的数据,必须通过 update/delete 请求,显式地根据 __rowid__ 或查询条件执行。
这个设计确保了普通写入路径仍然保持高吞吐、低成本和稳定的消费语义。
相应地,实时消费 LogHub 和投递任务也仍然基于原始写入流,不感知后续修改或删除。
3. 修改和删除同步可见
普通写入为了保证高性能,索引是准实时构建的,从日志写入到可查询之间可能存在极短延迟。由于普通写入遵循 Append-Only 语义,这不会影响写入顺序。
本次新增的修改和删除操作,则是同步生效的。也就是说,接口返回成功后,后续查询分析即可看到对应效果。
这对于连续局部更新尤其重要:前一次 update 返回成功后,后一次 update 可以确保基于前一次更新后的结果继续生效,从而避免"后一次更新是否看到了前一次更新"的语义歧义。
4. 查询体验不变
开启 enableModify=true 之后,查询分析仍然通过 Search、SQL、SPL 完成,使用方式没有变化。
被修改或删除的数据,会在后续查询分析中体现对应结果。对于使用 LogStore 做检索、分析、报表和管理后台的业务来说,原有查询链路不需要因为 update/delete 能力而重构。
能力形态
开启 enableModify=true 后,LogStore 提供两个维度的修改和删除能力:按 __rowid__ 定点操作单条记录;按查询条件批量操作一批记录。

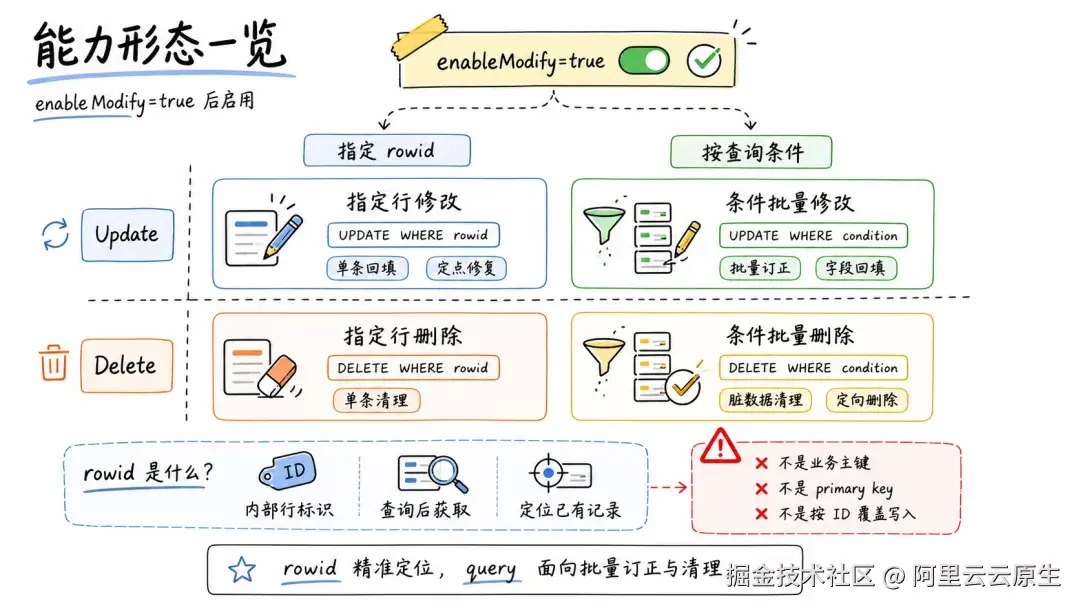
RowID:行级寻址标识
开启 enableModify=true 后,每条日志会被分配一个稳定的内部行标识 __rowid__。用户通过 Search、SQL 或 SPL 查询拿到 __rowid__,再用它精确指定要修改或删除哪一条。
需要注意的是,__rowid__ 是 LogStore 内部用于行寻址的标识,并不是业务主键,也不是数据库里的 primary key。它仅用于定位已经存在的记录,不能用于"按 ID 插入"或"按 ID 覆盖写入"。
因此,基于 __rowid__ 的操作更适合"先查后改"的场景。例如管理后台查出一批记录,用户选中其中一条,然后按 __rowid__ 精确回写。
按查询条件操作:用业务字段批量修正
如果希望按 request_id、batch_id、order_id、trace_id 等业务字段操作,可以使用按查询条件更新或删除的方式。
调用方只需要指定时间范围和 query 表达式,命中范围内的记录就会被一次性更新或删除。这种方式不需要先查询 __rowid__,只要能够用查询语句描述清楚"哪些记录需要改",就可以直接发起操作。
需要注意的是,按查询条件操作依赖查询条件命中数据。由于普通写入后的索引构建是异步的,通常需要等数据可查询后再执行修改或删除,因此它不适合"写完立即改"的场景。
另外,单次按查询条件的修改或删除最多命中 1 万行。实际使用中,建议按照业务维度拆分任务,例如按账期、按 batch、按用户、按实例或按时间窗口分批执行,避免一次操作范围过大。
典型场景
综合来看,适合在 LogStore 上使用 update/delete 的业务场景,通常具备以下特征:
- 数据有典型的日志特征。 持续产生、规模大、以追加写为主,需要检索和分析,同时存在相对低频的修正、回填或清理需求;
- 修改和写入之间有自然的时间间隔。 比如用户反馈延迟到达、模型按版本重算、月底账期调整;
- 每次修改的范围相对可控。 按
request_id、按批次、按账期,命中范围天然有限。
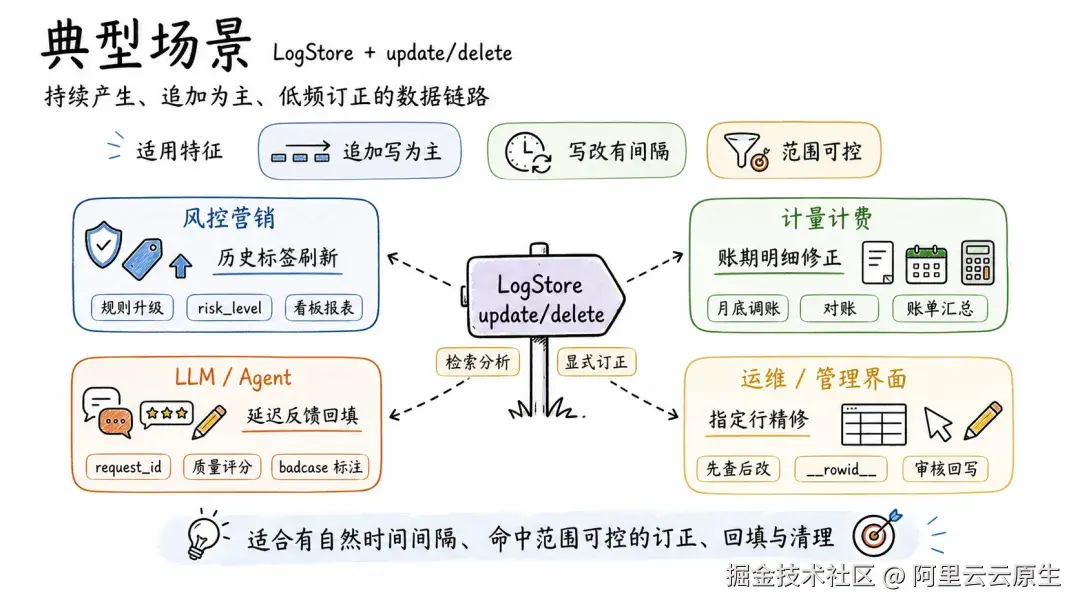
下面看几个典型场景。
风控营销:规则升级后的历史标签刷新
以风控场景为例,每笔交易写入 LogStore 时,可能会带上当时模型计算出的风险等级。风控团队上线新版评分规则后,如果发现旧规则对部分交易的风险评估偏低,就需要用新版逻辑刷新一批历史标签。
例如,把近 7 天某个商户的 risk_level 从 medium 订正为 high,让下游审核队列、风险看板和报表立刻反映新口径。
ini
client.update_logs(
project="risk",
logstore="transactions",
from_time=seven_days_ago,
to_time=now,
query='merchant_id: "M-2049" and risk_level: "medium"',
log_item={
"risk_level": "high",
"risk_model_version": "v3.2",
"re_evaluated_at": now,
},
)类似场景还包括营销渠道归因调整、实验分组策略修复、报表口径字段刷新、内容标签或用户画像重算。它们的共同点是:规则升级了,历史结果也需要跟着刷新。
计量计费:账期结算后的明细修正
计量计费明细按账期持续生成、写入 LogStore 用于汇总和对账。月底结算时,因为优惠核销、退款、客户协商或人工调账,可能需要修正部分记录。
这类场景天然适合 update/delete:调账通常发生在账期结束之后,写入和修改之间有明显时间间隔;修正范围也可以通过账期、用户 ID、实例 ID 等字段圈定,边界清晰。
例如,可以按 billing_period="2026-05" 和 instance_id="inst_8821" 圈定一批记录,只更新 amount、adjust_reason、adjusted_at 等字段。
调账结果直接体现在原始明细上,下游报表、汇总账单和审计查询自动看到修正后的数据。
LLM / Agent:延迟反馈的字段回填
LLM / Agent 应用的一次请求会产生大量过程数据。其中,执行明细,比如每个 step、每次 tool call,适合继续保持 Append-Only;但请求结束后延迟到达的信息,很适合回填到原始请求记录上。
这类信息包括用户点赞点踩、运营 badcase 标注、离线质量评分、人工审核结论等。
调用方式与前面类似,按 request_id + 时间范围定位到原始请求记录,将反馈字段回填上去即可。这样 Trace 详情仍然按 trace_id 聚合执行明细,反馈分析和质量评估可以直接查询请求记录上的字段。
运维/管理界面:指定行记录的精确修改
有些场景下,修改是由人在界面上触发的------客服在工单系统里把订单状态从"待处理"改为"已联系"、数据管理员查看采集到的标注数据并修正某条错误标签、运营在 badcase 管理后台对某条 LLM / Agent 请求补充审核意见。
这类操作的典型流程是"先查后改":界面通过 query 查出一批记录,这些记录里都会带有唯一的 __rowid__;用户选中其中一条修改后,保存时按 __rowid__ 精确定位回写。
ini
# 用户选中某条记录修改后,按 __rowid__ 精确回写
client.update_logs(
project="ops",
logstore="work-orders",
rowid="1|1048576|63", # 从查询结果中拿到的 __rowid__
log_item={
"status": "contacted",
"handler": "alice",
"handled_at": now,
},
)这种方式适合单条人工修正、审核回写、后台管理操作等场景。相比按业务字段重新圈定条件,__rowid__ 可以精确定位用户在界面上看到的那一条记录。
写在最后
回到最开始的问题:日志能不能改?
如果是传统意义上的运维日志------系统跑了什么、什么时候出了错------答案仍然是不应该改,不可变性本身就是它的价值。
但今天 LogStore 承载的远不止这些。越来越多的业务数据以日志的形态持续产生,它们需要 LogStore 的弹性、检索、分析和消费投递能力,同时又会在业务流程中产生回填、订正或清理需求。
对这类数据,原生的 update/delete 提供了一条直接的路径------不用再绕道外部系统,也不用牺牲 LogStore 本身的优势。
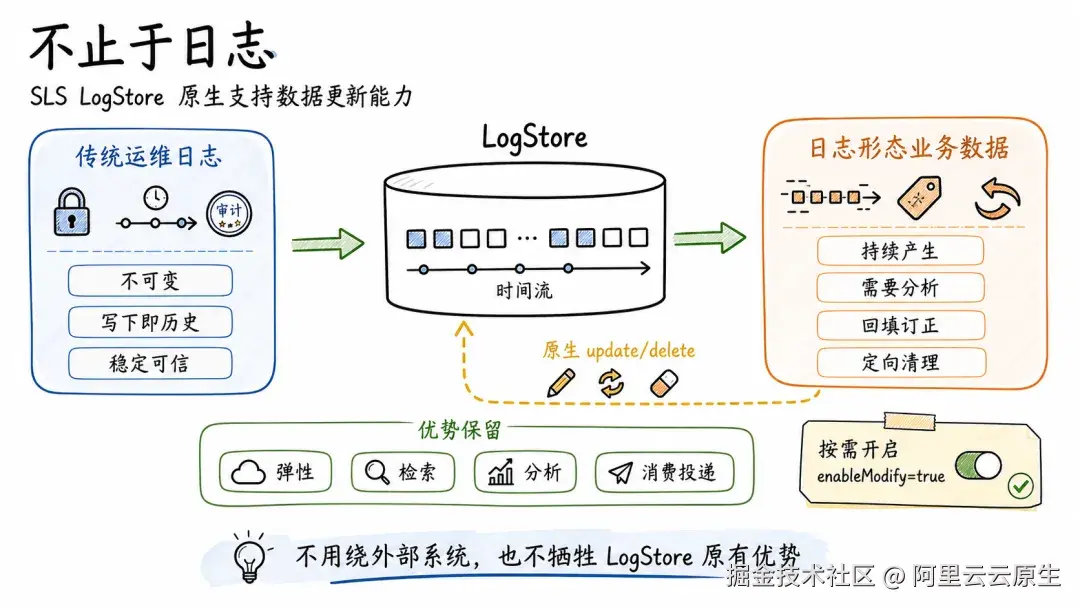
如果您的需求符合前面描述的特征,可以为您的 LogStore 开启 enableModify=true,解锁更多的场景可能。
具体开通方式、API 参数、限制清单与计费说明,请参考官方文档《修改与删除日志数据》:help.aliyun.com/zh/sls/modi...
如果您在使用过程中有任何疑问,欢迎提交工单咨询!