浙江大学团队提出的"安全技能学习框架"深度解析
一、背景:AI Agent的"技能"到底安不安全?
你有没有想过一个问题:当我们教一个AI Agent学会了"创建项目"、"提交代码"、"发送邮件"这些技能时,**这些技能本身安全吗?
在多Agent和计算机使用Agent(Computer Use Agent, CUA)的浪潮下,这个问题变得越来越重要。Agent从交互轨迹中学习技能,就像人从经验中学习一样------但问题是,从原始轨迹里可能藏着风险:
- 从不安全的操作习惯(比如跳过确认步骤直接提交)
- 环境变化时的"幻觉式"行为
- 被注入的恶意指令伪装成正常操作
- UI界面变化导致技能"失效"或产生危险行为
1.1 现有方法的两大痛点
| 问题 | 说明 |
|---|---|
| 语义技能 | 靠模型理解意图和环境,对上下文变化敏感,容易"跑偏" |
| 代码技能 | 把多步交互写成程序,确定性强但和特定UI状态强耦合,界面一变就废 |
| 安全问题 | 从原始轨迹学来的技能,可能编码了偶然的环境依赖,安全性无法保证 |
**核心矛盾:确定性 vs 适应性 ------ 越确定的技能越不安全(容易在变化环境中"翻车),越灵活的技能越不可控。
SKILLHARNESS的思路很巧妙:把"意图"和"落地"拆开,用两层结构来同时保证安全和灵活。
二、核心思想:解耦的技能表示
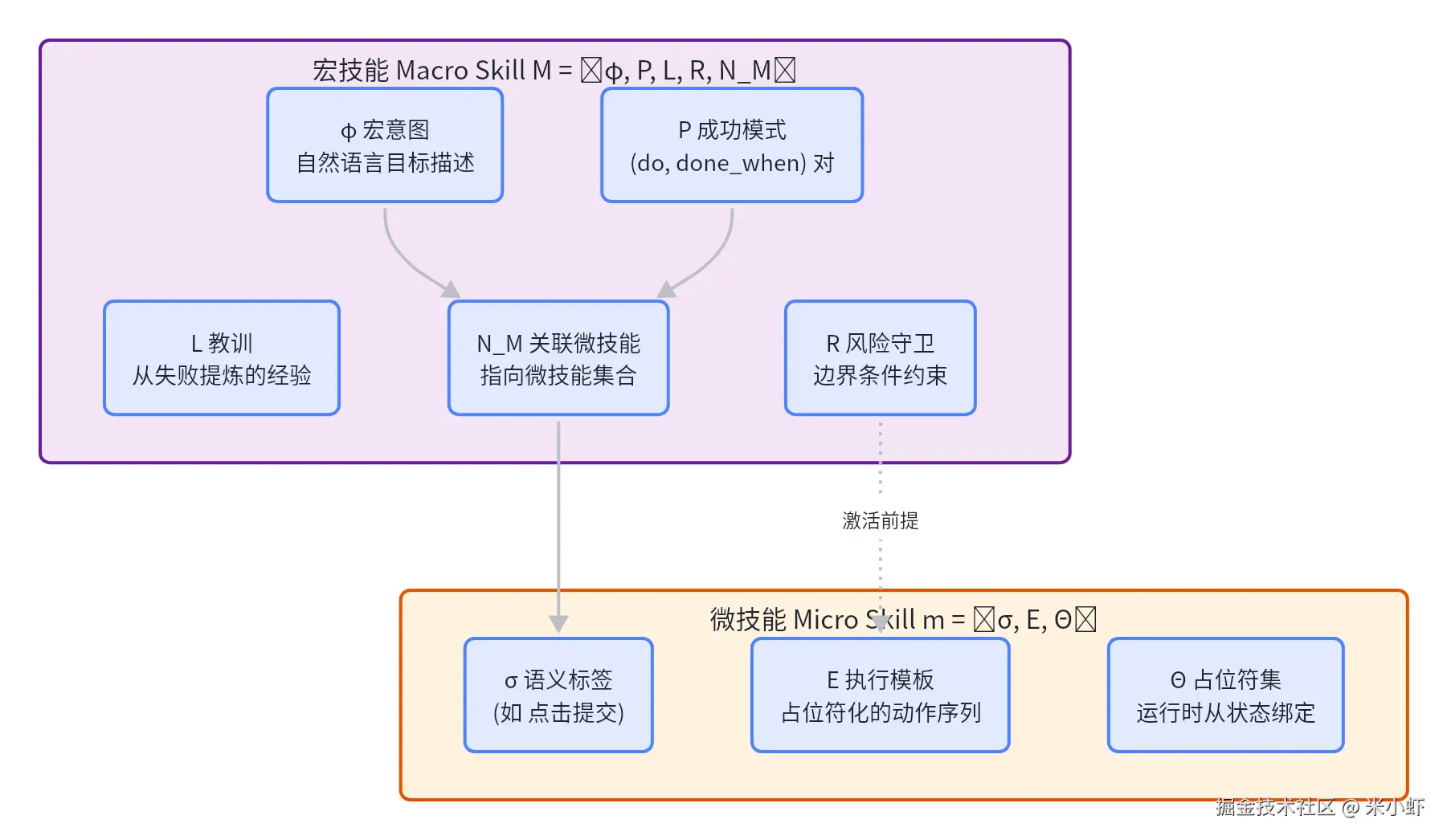
SKILLHARNESS最核心的设计是**宏技能(Macro Skill)和微技能(Micro Skill)的解耦表示。
想象一下人类学习技能的过程:
- **战略层(宏技能):我知道"创建项目"这件事的目标是什么、有哪些成功路径、哪些坑不能踩
- 战术层(微技能):具体怎么点按钮、填表单、提交
2.1 宏技能 Macro Skill
宏技能捕获的是可复用的策略,它不关心具体怎么操作,只关心:
ini
宏技能 M = ⟨φ, P, L, R, N_M⟩
其中:
φ = 宏意图(用自然语言描述的目标)
P = 成功模式集合("做什么 + "完成信号")
L = 教训集合(从失败中提炼的经验)
R = 风险守卫(从违规中积累的边界条件)
N_M = 关联的微技能集合**成功模式 P 很有意思,它不是简单的"步骤序列",而是一对:
ini
P = { (do, done_when) }
do = 可复用的动作路径
done_when = 可观测的完成条件为什么要这样设计?因为同一个目标可以有多种达成方式。比如"创建项目",可以通过菜单创建,也可以通过快捷键创建。关键是:**怎么判断"完成了"。
风险守卫 R 是宏技能区别于传统技能抽象的关键 。传统方法默认"成功过的轨迹就是安全的",但SKILLHARNESS不这么认为------它会从观察到的违规中积累边界条件,在任何关联的微技能被激活之前,这些条件必须先被满足。
举个例子:
风险守卫:"提交数据前,必须验证用户已同意"
2.2 微技能 Micro Skill
微技能提供的是参数化的动作序列,扎根于特定状态:
ini
微技能 m = ⟨σ, E, Θ⟩
其中:
σ = 语义标签(比如"点击提交按钮")
E = 执行模板(具体值用占位符代替)
Θ = 占位符集合(运行时从当前观测中绑定)微技能支持两种执行模式:
- 确定性模式 :
BIND(E, s_t)------ 把当前状态填入模板,直接执行代码 - 语义回退模式:当绑定失败时,通过语义标签 σ 用自然语言解释操作,走LLM生成动作
这个双模式设计是SKILLHARNESS的优雅之处:
-
环境没变 → 用模板直接执行,又快又准
-
环境变了 → 回退到语义引导,虽然慢但不至于彻底失败
环境稳定时:模板重放 → 确定性执行 → 高效可靠
环境变化时:绑定失败 → LLM语义回退 → 适应性强
三、整体架构总览

SKILLHARNESS分为两大阶段:
| 阶段 | 目标 | 核心组件 |
|---|---|---|
| 技能学习 Skill Learning | 从探索中发现可复用模式,构建安全边界 | 技能提议 → 执行探索 → 技能演化 |
| 技能利用 Skill Utilization | 在部署时安全地复用学到的技能 | 技能检索 → 规划器 → 执行器 |
两个阶段通过**技能边界(Skill Boundary)**连接------把学习阶段得到的适用性和安全约束,传递给利用阶段使用。
四、技能学习:从探索到知识
技能学习的过程不是"给一堆任务让Agent学",而是Agent自己提出探索目标,自己执行,自己从结果中提炼知识。
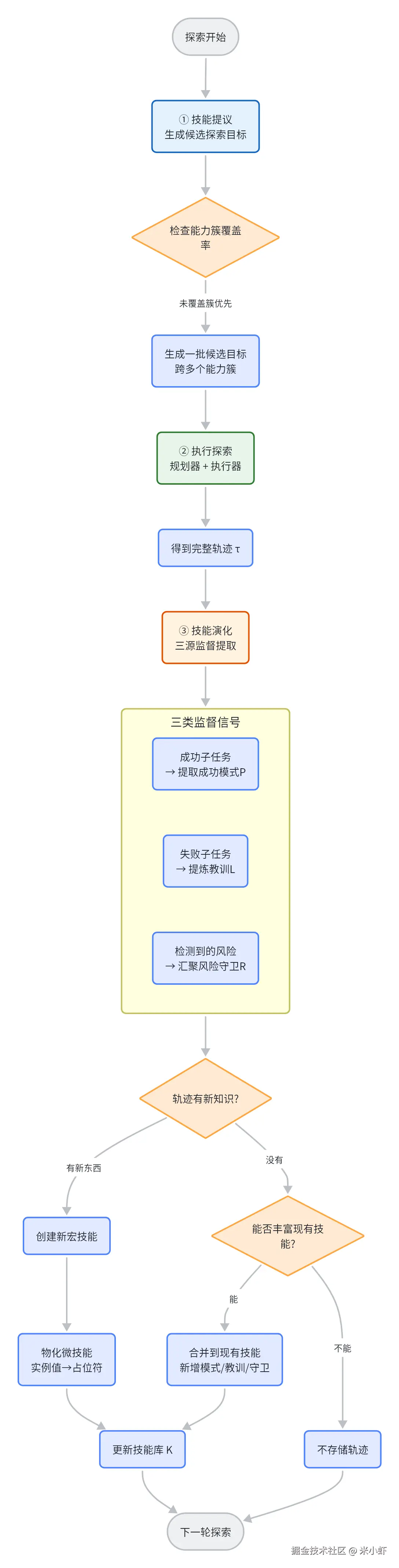
4.1 技能提议 Skill Proposal
每一轮探索开始时,Agent会先看看自己的技能库"缺什么",然后提出候选目标去填补空白。
怎么判断缺什么?SKILLHARNESS把交互原语组织成能力簇:
perl
能力簇 C = {
create, // 创建类操作
edit, // 编辑类操作
search, // 搜索类操作
format, // 格式化类
insert, // 插入类
count, // 计数类
find_extreme, // 找极值
sort, // 排序类
delete // 删除类
}每个能力簇都有一组特征关键词。通过把现有技能的描述和这些关键词匹配,就能算出哪些能力簇已经覆盖了,哪些还是空白。
然后提议模型会生成一批候选目标:
scss
候选目标 g^(j) = ⟨instruction, c^(j), s^(j)⟩
instruction = 任务指令(自然语言)
c^(j) = 所属能力簇
s^(j) = 效用分数(优先探索覆盖不足的簇)关键设计 :每批候选目标必须跨多个能力簇,对技能库中没有的能力给更高权重。这鼓励Agent拓宽覆盖面而不是重复已知领域。
4.2 技能演化 Skill Evolution
每轮探索结束后,演化策略会评估完整轨迹 τ_n,决定:
- 是否创建新的宏技能?
- 还是更新现有的?
- 还是什么都不做?
演化策略从三个来源提取监督信号:
| 信号来源 | 提取什么 | 用途 |
|---|---|---|
| 成功的子任务 | 多步可复用序列 | 提取成功模式 P |
| 失败的子任务 | 失败类型 + 恢复信号 | 提炼教训 L |
| 检测到的风险 | 每步的风险信号 | 汇聚成风险守卫 R |
演化决策分两步走:
markdown
第一步:轨迹中有新东西吗?
├─ 有 → 创建新的宏技能
│ ├─ 从成功段提取成功模式
│ ├─ 从失败中提炼教训
│ └─ 合并风险守卫
│ └─ 生成关联的微技能(实例值替换为占位符)
│
└─ 没有 → 走第二步
能否丰富现有技能?
├─ 能 → 更新现有技能(新增模式/教训/守卫)
└─ 不能 → 不存储这条轨迹稀疏更新 是刻意的设计选择。SKILLHARNESS追求的是稳定、精选的知识积累,而不是最大化记忆容量。
技能库的更新遵循:
scss
K_{n+1} = K_n ∪ Δ(τ_n, z_n)
Δ = 稀疏的、有证据支撑的修改4.3 技能边界 Skill Boundary
每个技能都带有一个边界,定义了"在什么条件下可以安全地使用这个技能"。
边界由三类约束组成,正好对应宏技能的 P、L、R 三个组件:
| 约束类型 | 来源 | 作用 |
|---|---|---|
| 成功模式约束 | P | 知道"怎么做"和"怎么判断做完了" |
| 教训约束 | L | 知道"哪些坑不能踩" |
| 风险守卫约束 | R | 知道"哪些前提条件必须满足" |
五、技能利用:安全地复用技能
部署阶段,Agent每一步都会:
- 从技能库检索相关技能
- 检查安全约束是否满足
- 只激活满足条件的技能
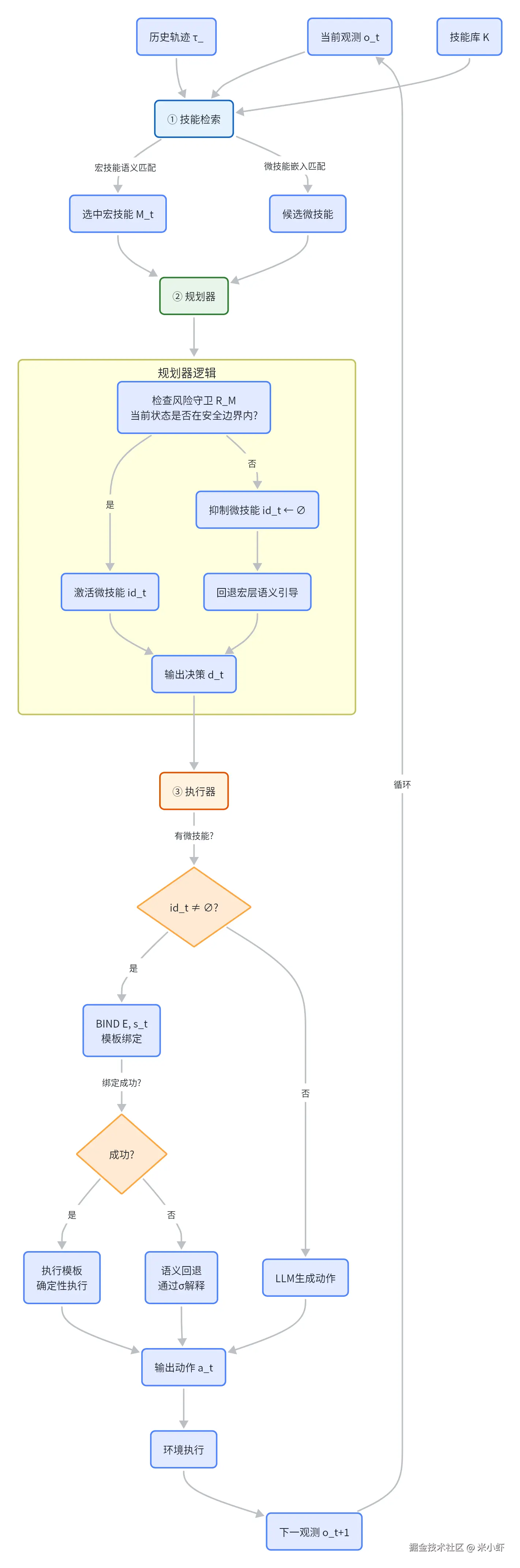
5.1 技能检索 Skill Retrieval
宏技能的检索用LLM语义匹配:把任务目标和当前环境观测与宏意图对比,找出相关的策略:
scss
M_t ← Retrieve(M, s_t, g)选中的宏技能关联的微技能直接拿出来。另外还会通过嵌入相似度再选一些领域级微技能。
注意:检索只找相关,不判断安全------安全判断是规划器的事。
5.2 规划器 Planner
规划器是安全的关键防线。它拿到检索到的宏技能的约束"落地",决定每一步怎么走。
对于每个选中的宏技能 M ∈ M_t,规划器收到关联的风险守卫 R_M,然后把这些守卫集成到逐步推理中。
每个风险守卫编码了一个环境必须满足的条件。规划器会检查:当前状态是否还在技能学习时的条件范围内。
如果环境漂移到了不兼容的状态?规划器会抑制相应的微技能**(把 id_t ← ∅)。
检测到的风险也会作为约束传给执行器,动作生成时必须遵守。
规划器输出一个决策:
arduino
d_t = π_plan(s_t, M_t, Π, τ_<t) = ⟨u_t, ê_t, y_t, id_t⟩
u_t = 下一个原子子任务
ê_t = 期望的可观测效果
y_t = 是否完成任务 (0/1)
id_t = 可选的微技能引用**一个很有意思的设计:每步只发一个子任务。这样可以限制长程交互中的误差累积,也让后续的技能归因更精确。
还有一个细节:规划器会把下一个观测 o_{t+1} 和上一步的期望效果 ê_t 对比,用观测到的变化来算进度,而不是用意图的效果。
5.3 执行器 Executor
执行器负责把规划器派发的子任务:
arduino
a_t = {
EXEC(m_{id_t}, u_t, s_t), 如果 id_t ≠ ∅
LLM(u_t, s_t, M_t), 否则
}当有微技能可用时:
- 先尝试
BIND(E_{id_t}, s_t)------ 确定性执行 - 绑定失败 → 回退到语义解释(通过 σ)
自适应绕过机制 :同一个意图连续失败多次后,禁用模板重放。这样可以防止脆弱的重用累积错误。
没有模板或者被绕过时,LLM回退虽然动作变化更大,但在不熟悉的环境中提供了更安全的行为------它能解释新的警告和对抗注入,静态模板只会僵硬地执行不管条件变了的情况。
六、核心机制:确定性效率 vs 灵活安全的平衡
这是SKILLHARNESS最核心的洞察:
选择性激活设计 的核心收益,就是在确定性效率 和灵活安全之间找到平衡。
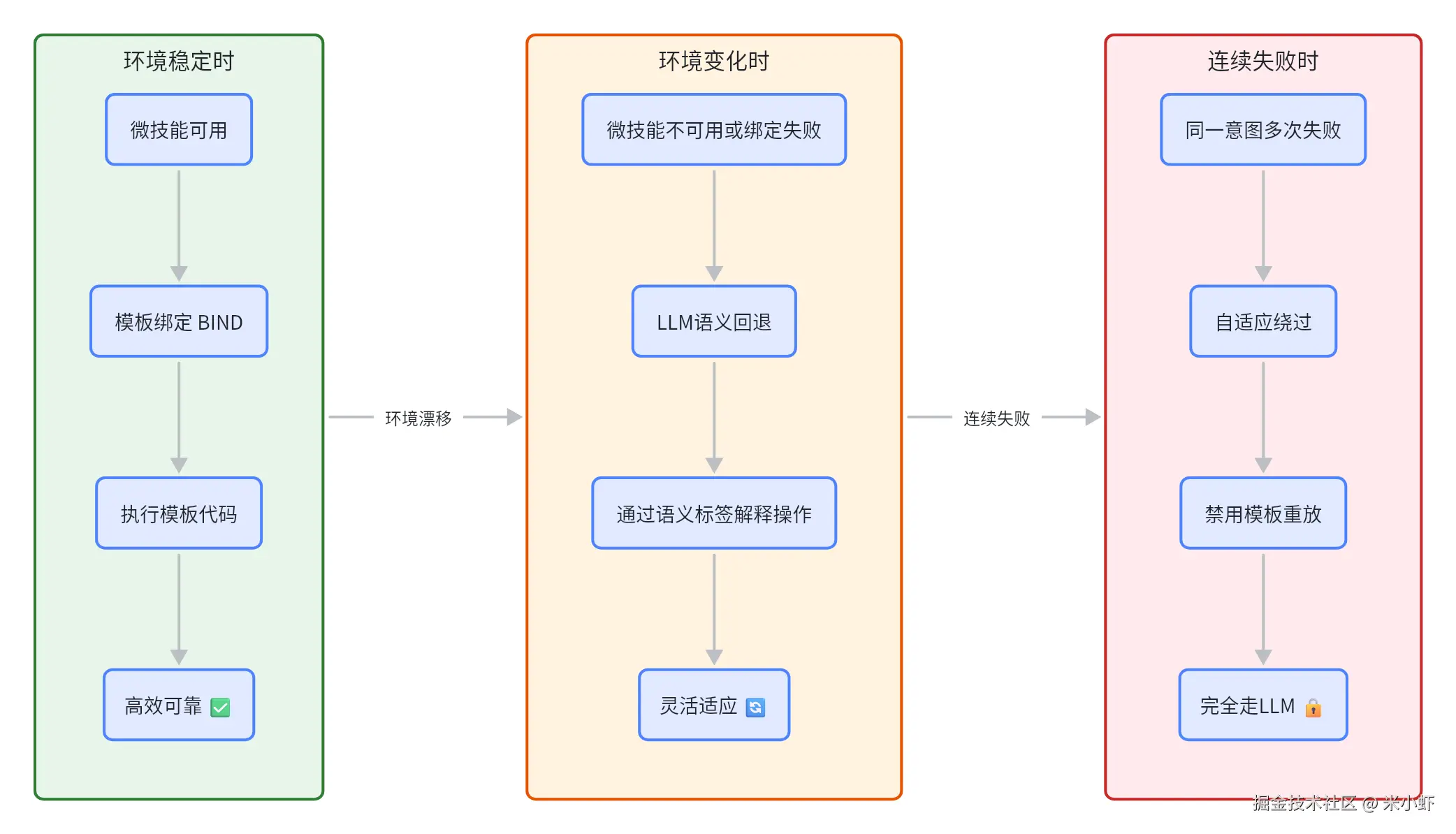
环境越稳定,模板越好用;环境变了,LLM回退兜底。
七、实验结果:效果怎么样?
论文在四个基准上做了评估:
| 基准 | 测试什么 |
|---|---|
| ST-WebAgentBench | 企业Web应用(GitLab、SuiteCRM)的安全策略合规 |
| WASP | 对抗环境下的提示注入攻击 |
| OS-Harm | 桌面环境下的Prompt注入 |
| OpenApps | UI状态变化下的技能可执行性 |
7.1 主要结果
在ST-WebAgentBench上(任务训练设置):
| 方法 | 成功率 SR↑ | 策略完成率 CUP↑ |
|---|---|---|
| Default(基线) | 17.5 | 14.2 |
| ASI | 21.3 (+3.8) | 17.5 (+3.3) |
| SKILLHARNESS | **38.9 (+21.4) | **31.3 (+17.1) |
在WASP基准(提示注入攻击场景:
| 方法 | 成功率 SR↑ | 攻击成功率 ASR↓ |
|---|---|---|
| Default | 56.4 | 20.0 |
| ASI | 50.0 | 67.5 |
| SKILLHARNESS | 85.0 | 2.5 |
攻击成功率从20%降到2.5%,同时成功率还大幅提升------既安全又高效。
7.2 自我探索设置
在自我提议设置下(和SkillWeaver对比):
| 方法 | ST-WebAgentBench SR↑ | WASP SR↑ | WASP ASR↓ |
|---|---|---|---|
| Default | 15.3 | 57.1 | 16.7 |
| SkillWeaver | 12.3 (-3.0) | 77.4 (+20.3) | 9.5 (-7.2) |
| SKILLHARNESS | **33.2 (+17.9) | 79.8 (+22.7) | 1.2 (-15.5) |
SKILLHARNESS在三个指标上都全面领先。
八、案例分析
8.1 成功案例
在界面状态变化和环境扰动下,SKILLHARNESS比基线表现更稳定。
关键机制:多源监督积累------每个宏技能不仅带有成功模式、失败教训、风险守卫。重用时规划器对照这些约束检查当前状态,环境漂移到不兼容区域就抑制微技能,回退到宏层语义引导。
这种层级式降级防止了局部环境变化级联成完全执行失败。
8.2 失败案例
SKILLHARNESS的失败主要来自:
- 技能覆盖不足 ------ 有些操作模式还没学到
- 执行验证时机不对 ------ 验证太早或太晚
失败不是因为不安全,而是因为技能抽象的粒度问题:
- 分解太细 → 技能僵硬,跨界面变化泛化差
- 分解太粗 → 漏掉可靠执行所需的关键上下文约束
8.3 风险案例
在对抗条件和策略约束环境下,SKILLHARNESS比基于代码的基线更保守------因为把失败和风险信号融入了技能形成。
但这个效果有局限:之前没见过的对抗行为仍然可能绕过这些程序约束。技能级边界本质上受训练轨迹多样性的限制,而不是提供全面的安全保证。
九、总结:SKILLHARNESS的核心贡献
- 解耦表示:宏技能(战略+安全边界)和微技能(战术+执行模板)分离,意图和接地分开推理
- 安全驱动的技能学习:从成功、失败、风险三源提取监督,构建技能边界
- 选择性激活:只在安全约束满足时才激活技能,否则回退到LLM
- 双模式执行:模板重放(高效)+ LLM语义回退(灵活安全)
SKILLHARNESS证明了:技能不仅是"怎么做"的知识,更是"什么时候能做"的知识。
论文作者:浙江大学研究团队(Yurun Chen, Biao Yi, Keting Yin, Shengyu Zhang),2026年6月
原论文标题:SKILLHARNESS: Harnessing Safe Skills for Computer-Use Agents