22 篇文章,2000+ 行 Java 代码,一个完整的工业 Agent MVP。回头看,最重要的不是哪行代码写得巧,而是反复踩坑后沉淀下来的六条原则。这篇文章是一次「回头看」------用原则串起所有经验。
系统全貌
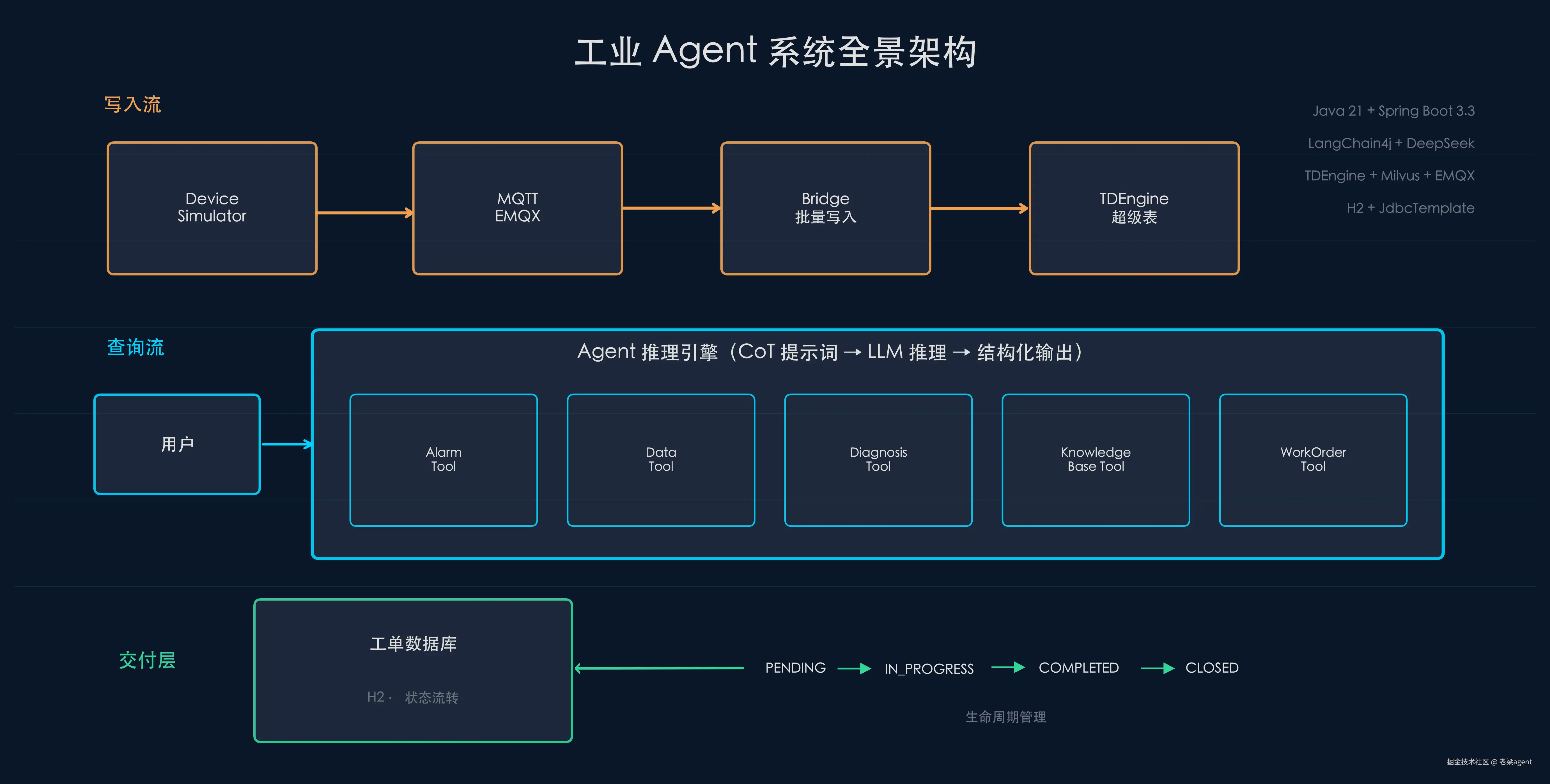
技术栈:Java 21 + Spring Boot 3.3 + LangChain4j 0.35 + DeepSeek + TDEngine + Milvus + EMQX + H2
原则 1:Tool 是真正的产品
大多数 AI Agent 项目从「选哪个模型」开始。工业 Agent 从「Tool 怎么设计」开始。
模型会换代,但 Tool 的接口设计、数据质量、错误处理才是系统长期价值的载体。 我换了两次模型,Tool 代码一行没改。
三个 Tool 设计准则:
| 准则 | 反例 | 正例 |
|---|---|---|
| Tool 做数据处理,LLM 做推理 | queryRaw() 返回 100 行原始数据 |
queryDeviceHistory() 返回 avg/max + latest |
| Tool 带领域知识 | 让 LLM 判断「振动 4.8 正常吗」 | Tool 标注 vibrationStatus: "CRITICAL" |
| Tool 描述 = 契约 | @Tool("查询数据") |
@Tool("查询过去1小时的统计摘要和最新数据点") |
原则 2:数据进入 Agent 前先「瘦身」
工业设备每秒产生数据点,直接喂给 LLM 是灾难。
yaml
原始数据 100 行 ≈ 2000 token → LLM 看不清趋势
聚合统计 + 最新值 ≈ 200 token → LLM 准确判断压缩比 10:1,判断准确率反而提升。 LLM 不是数据库------它对「一行行数字」不敏感,对「异常比例」「变化趋势」极其敏感。
实现方式:
- TDEngine 超级表 + SQL 窗口函数完成预聚合
- DeviceDataTool 只返回三个字段:latest / stats / alarms
- 正常范围标注(
normalRange,status)写在 Tool 代码里
原则 3:CoT 不是锦上添花,是必需品
没有 CoT 时的 Agent 行为:
- 同时查告警 + 查数据 + 检索知识,但结论跳步
- 数据不足时编造数值(「振动大概 4.5」)
- 不管设备是否有故障,每次都创建工单
加上 CoT 后:
python
@SystemMessage("""
思考路径:
1. 数据采集:queryDeviceAlarms + queryDeviceHistory
2. 知识检索:searchKnowledgeBase(如有异常)
3. 诊断分析:generateDiagnosis
4. 工单决策:仅在确认硬件故障时调用 createWorkOrder
5. 最终输出:状态 → 异常 → 诊断 → 建议 → 工单
""")CoT 的价值不是让 LLM「更聪明」,而是让它的推理过程可追溯、可调试、可修正。 工业场景下,你不知道「为什么这样判断」比「判断错了」更危险。
相关文章:21
原则 4:约束比能力更重要
最初 CoT 只写了「1→2→3→4→5」步骤,没有约束。LLM 每次都创建工单------不管有没有故障。
加上一句话后行为收敛:
「如果设备状态正常、无告警,不要创建工单」
这条规则没有一行代码------只是提示词中的一句中文。但它比任何 if (alarmCount > 0) 都灵活,因为 LLM 能理解「什么算正常」的语义边界。
在工业 Agent 中,告诉 LLM 不做什么,比告诉它做什么更有效。 三条必加的约束:
- 数据不足时,输出「无法判断」而不是编造
- 无告警不创建工单
- 涉及停机操作时,标注「需人工确认」
原则 5:持久化是闭环的终点
第一版 WorkOrderTool 用 ConcurrentHashMap 存工单。三个缺陷:
- 重启丢失
- 无法查历史
- 无状态流转
改成 H2 + JdbcTemplate 后:
objectivec
工单生命周期:PENDING → IN_PROGRESS → COMPLETED
↓ ↓
CANCELLED CLOSED| 版本 | 存储 | 重启后 | 历史查询 | 状态流转 |
|---|---|---|---|---|
| V1 | ConcurrentHashMap | 丢失 | ❌ | ❌ |
| V2 | H2 (JdbcTemplate) | 保留 | ✅ | ✅ |
Agent 的交付物不是「正确回答了问题」,而是「产出了可追溯的交付物」。 诊断是对的话术,工单是交付物。
相关文章:22
原则 6:RAG 填补 LLM 的工业盲区
通用 LLM 不知道「轴承温度高」和「齿轮箱温度高」是不同的问题。工业知识库补上这块。
arduino
用户:「轴承温度过高」
→ Embedding 检索 → 轴承温度过高 → 润滑油劣化/轴承磨损/负载过大
→ BM25 检索 → "轴承" 精确命中维修手册
→ RRF 融合 → Top-3 最相关维修方案
→ LLM 推理 → 结合实时数据给出根因关键决策:
- Embedding 模型选型 :
AllMiniLmL6V2384 维,ONNX 本地运行,不需要 API - 混合检索:Dense + BM25 → RRF 融合,比纯向量检索命中率提高 20%+
- 分块实验:500 chars 平衡了上下文完整性和检索精度
六条原则总结
| # | 原则 | 一句话 | 关键实现 |
|---|---|---|---|
| 1 | Tool 是产品 | 模型会换代,Tool 是长期资产 | @Tool 设计准则 |
| 2 | 数据瘦身 | 压缩 10:1,判断更准 | TDEngine 预聚合 |
| 3 | CoT 必需 | 可追溯比「猜对」重要 | ReAct 提示词 |
| 4 | 约束 > 能力 | 告诉 LLM 不做什么 | 负面约束句 |
| 5 | 持久化闭环 | Agent 交付物要留下来 | H2 + 状态流转 |
| 6 | RAG 补盲区 | LLM 不懂工业,知识库补 | Milvus + 混合检索 |
下一步
Phase 2(工业 MVP)到此结束。22 篇文章覆盖了从「第一个 Agent」到「工单闭环」的完整旅程。
Phase 3 进入进阶模式------多 Agent 路由、Supervisor、HITL、MCP 协议。从一个 Agent 变成多个 Agent 协作,从一问一答变成自主推理链。
代码仓库:github.com/LaoLiang-ag...
本文由 LaoLiang 原创,首发于掘金/知乎/微信公众号。转载请联系作者。