当我们在用AI工具解决某些问题或者开发某个需求的时候,除了会关心AI有没有完成这件事情,有没有出现什么错误之外,最受人关注的还是自己当前用了多少token,为什么呢?最直观的一点,因为这个关系到费用,特别是如果没了token,咱就有种什么事情都没法做了的感觉,就跟以前断网断电是一样的

那么有没有人想过什么是token?token是怎么生成的?我们为什么一直在说如何去节省token用量?
概念
token的中文名叫词元,是AI能理解的最小单位,这就好比一篇文章,我们人自己去读的话,会按照一个个词语或者单词去理解,但是AI不是这样的,AI会把一句话拆分成若干个碎片,一个完整的单词可能都会被拆分成两三个,每一个这样的碎片就是一个token,标点符号也算一个token
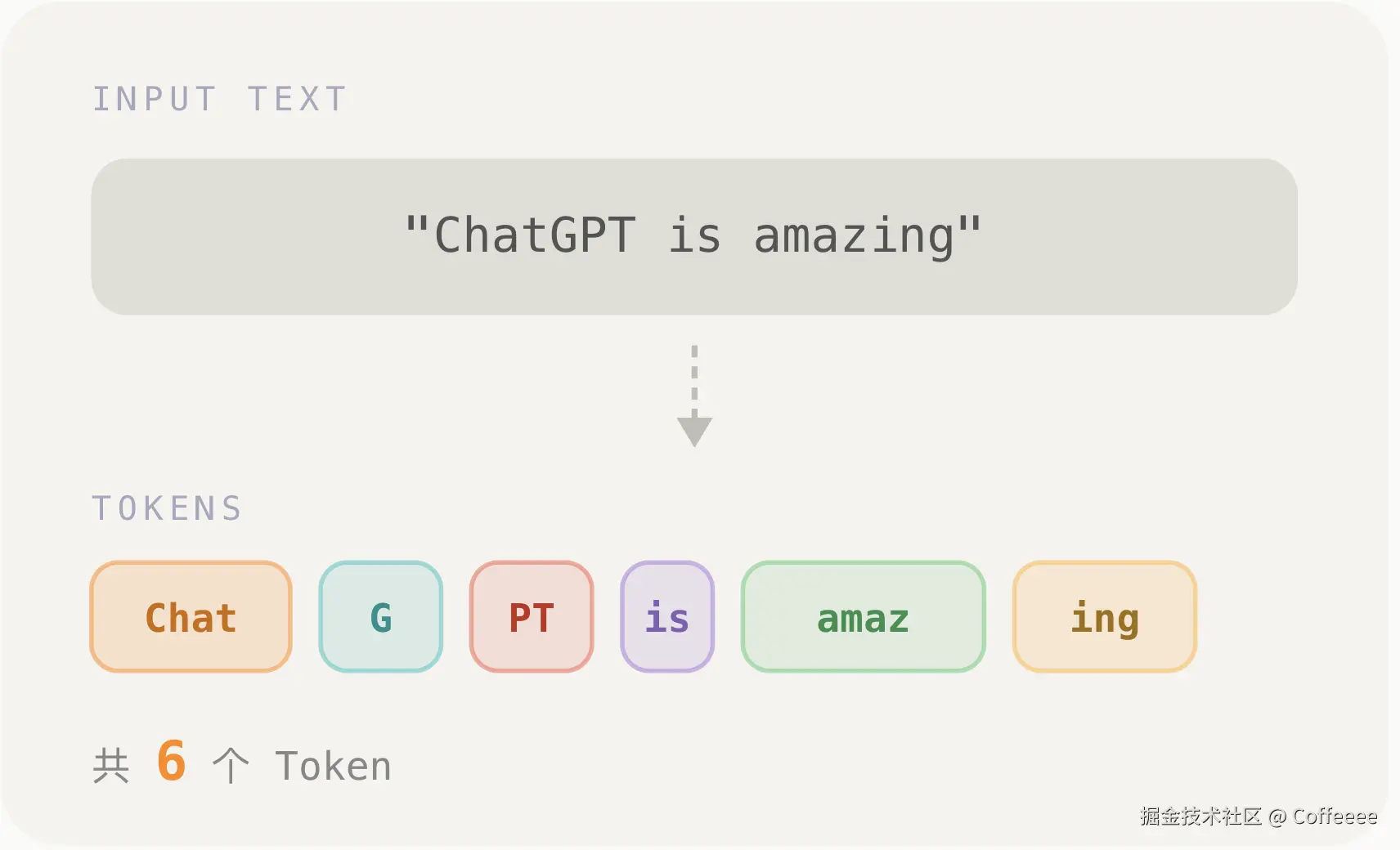
为了帮助理解,下面举两个常见例子来加深点印象
吃东西
每一口=一个token
这个大家都熟悉,每个人都要吃饭,假设你坐在一张餐桌上,桌上摆满了各种食物,你怎么吃呢?是一粒一粒米吃?那估计吃到过年都不一定吃完,或者一整盘一整盘往嘴里倒?那得噎着。正常都是一口一口吃,这里的每一口就是一个token,此时吃东西的人就是一个AI
耗费多少token=一顿饭吃了几口
我们正常吃一个小番茄,基本一口就吃完了,但是如果给你一个巨无霸大汉堡,应该没几个人可以一口解决吧?都会吃个几口,AI也是一样的,处理不同的文案,耗费的token是不一样的
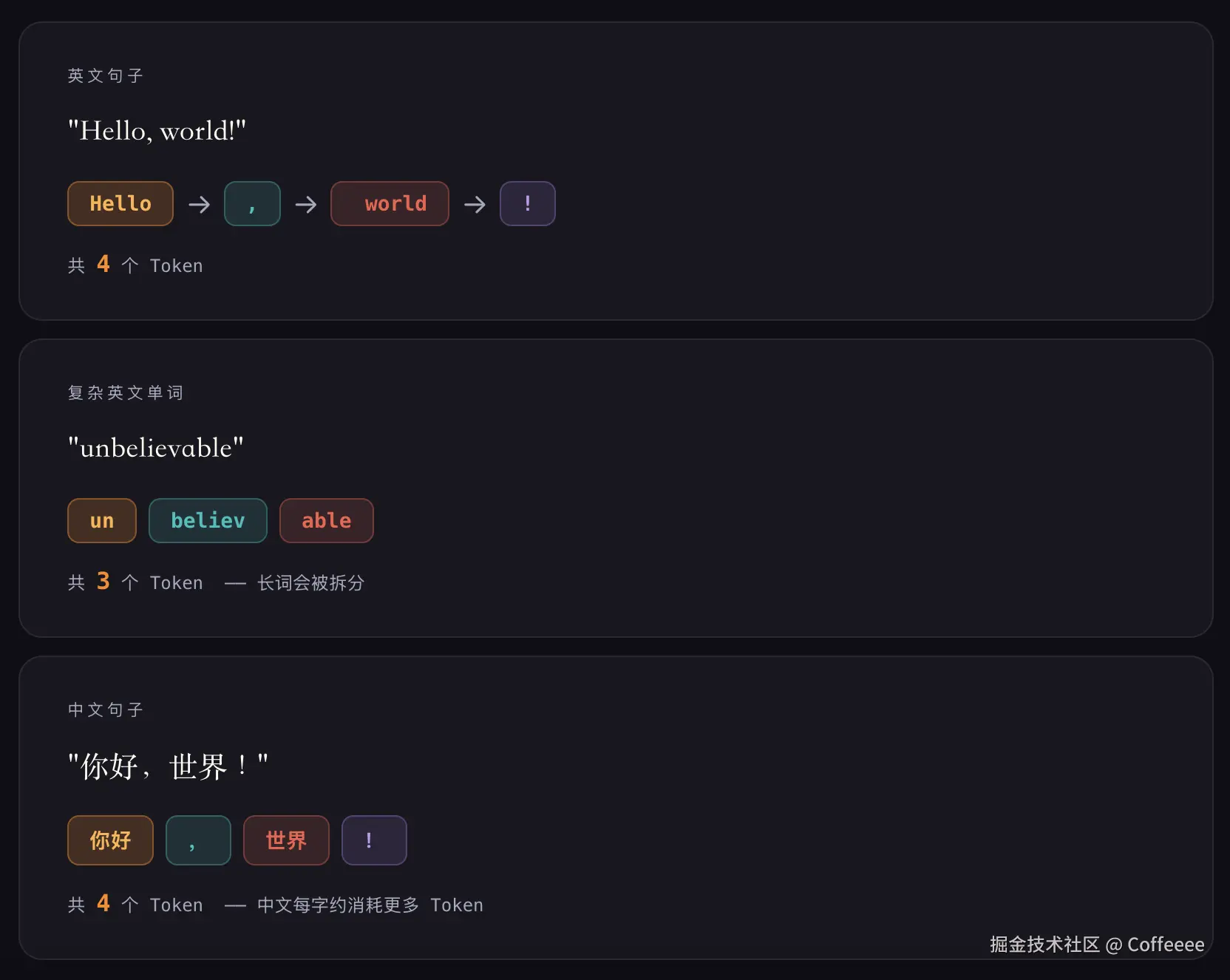
这种计算方式AI有自己的算法,叫BPE也叫字节对编码
| 内容 | 对应的食物 | 需要几口吃完 |
|---|---|---|
| bug | 小番茄 | 一口解决 |
| fix the bug | 巨无霸大汉堡 | 三口解决 |
| 修一下这个问题 | 带壳大螃蟹 | 需要好多口 |
上下文窗口=胃容量
前面说到了我们关心token的用量一个原因是跟费用相关,其实还有一个原因,那就是每一个会话窗口它都有大小,这个大小决定着一次能处理的最大token量,而不同的AI模型,它们的窗口大小也都是不一样的,就跟人一样,成人的胃口肯定比小孩要大一些
- GPT-3.5:约 4,000 Token
- GPT-4: 约32,000token
- GPT-4 Turbo:约 128,000 Token
- Claude 3.5:约 200,000 Token
所以当窗口"吃撑了"的时候会怎么办呢?肯定会先"吐掉"一些,才能"吃"进去新的信息,但是此时你就会发现,AI貌似得了遗忘症,记不清最早跟他说的一些话了
如何节省token
- 分批进食,分多次处理,别一次想把所有信息都塞进胃里,而不能暴饮暴食,一次性塞太多信息(点一整桌菜)
- 慢一点吃,给 AI 时间处理已有信息,别急着连续塞入,而不能吃太急,短时间内连续追问,胃来不及消化
- 按需点餐,只给 AI 真正需要的信息,不要有"反正容量够"的心态,而不能有吃自助餐的心态,反正不额外花钱就拼命点
- 一次吃完,把要求一次性说清楚,减少"再来一遍",而不能反复咀嚼同一道菜,让 AI 多次处理同样的内容
- 先尝后取,先确定需要什么,再上传对应内容,而不是什么菜都先夹一碗再说,上传一堆文件但大部分用不上
烤串
再来一个例子,天气慢慢变热了,大热天最舒服的一件事情就是坐在路边摊上点上几串肉串再喝点小凉啤,此时热爱AI的你看着手上的肉串,会不会觉得它十分的似曾相识,每一根竹签由于都是固定长度,就像是一个个上下文窗口
每块肉=一个token
如果竹签是上下文窗口的话,那么竹签上串的肉块就是token,可以看下琳琅满目的货柜,可以发现
- 一些小的肉块,比如螺肉,一个签儿上可以串很多,这些小肉块就像是我们输入的一些简单的英文单词
- 一些稍微大一点的肉块,比如里脊肉,鸡心之类的,只能串几块就串不下了,这些就像是比较复杂一点的英语单词,如unbelievable
- 在大一点的肉块,比如排骨,基本一个串上只能串两块肉,就像是一些非英语的语言,如中文,韩文
常见现象与如何避免
| 浪费行为 | 省 Token 的做法 |
|---|---|
| 串上全是"肥肉"(客套话、废话、重复内容) | 多串"瘦肉"(干货、核心信息),去掉"肥肉" |
| 每根签都要求串得满满当当(长输出) | 要求"小串":"简要回答"、"列出 3 点即可" |
| 让师傅反复烤同一根签(让 AI 重复生成) | 一次性说清楚要求,减少重烤 |
| 不同语言的肉混着串(中英混杂) | 尽量保持语言统一,混搭更占签 |
| 在对话里不断加新肉,把签撑断(超出上下文) | 及时开启新对话,换一根新签 |
总结
两个生活中的常见例子,介绍了什么是token以及与上下文窗口之间的关系,并且也总结了一些省token的一些方式,矫正一些不正确的行为,希望对你有所帮助