线性回归损失函数:从预测误差到训练目标
摘要 :上一篇我们建立了线性回归模型 y′=b+w1x1,但「模型好不好」仍需一个可量化的标准。本文围绕**损失函数(Loss)**展开,解释它如何衡量预测与真实值的差距,对比 L1/MAE 与 L2/MSE/RMSE 的差异,并结合汽车油耗示例说明如何在存在异常值时选择合适的损失。适合已了解线性回归基本方程的读者。
1. 为什么需要损失函数
在《线性回归简介》中,我们学会了用一条直线描述特征与标签的关系。模型可以预测,但预测准不准,必须有一个统一的度量。
损失(Loss) 就是这样一个数值指标:它描述模型预测值与真实标签之间的偏差。训练的目标,就是把损失尽可能压低------理想情况下接近 0,意味着预测与真实高度一致。
可以把损失理解为「模型到数据点的距离」。距离越大,模型越差;距离越小,模型越好。后续要学的梯度下降,本质上就是在损失曲面上寻找最低点。
2. 损失度量的是「距离」,不是「方向」
假设模型预测 23.1 MPG,真实值是 24 MPG,误差为 24−23.1=0.9。我们并不关心误差是正是负,只关心偏离了多远。
因此,所有损失函数都要先去掉符号,常用两种做法:
| 方法 | 含义 | 对应损失族 |
|---|---|---|
| 取绝对值 | 只保留偏离幅度 | L1 / MAE |
| 取平方 | 放大大误差、缩小小误差 | L2 / MSE |
在线性回归的散点图上,损失常表现为数据点到拟合直线的竖直距离 ------预测值与真实值在同一特征 x 下的纵向差距。
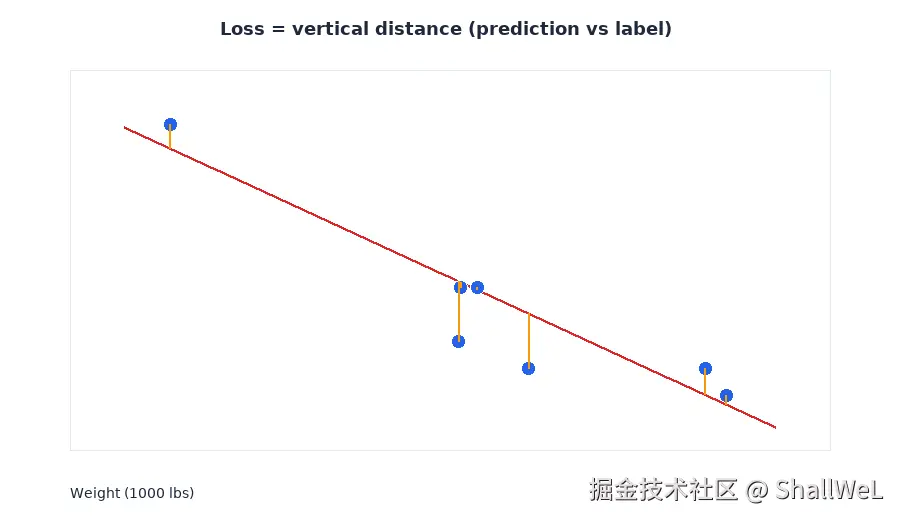
3. 五种常见损失:从 L1 到 RMSE
线性回归里最常见的损失类型如下表所示。记真实标签为 y,预测值为 y′,样本数为 N。
| 损失类型 | 英文 | 定义(单样本 / 多样本) | 特点 |
|---|---|---|---|
| L1 损失 | L1 Loss | ∑∥y−y′∥ | 对单个样本的绝对误差求和 |
| 平均绝对误差 | MAE | N1∑∥y−y′∥ | L1 在 N 个样本上的平均 |
| L2 损失 | L2 Loss | ∑(y−y′)2 | 对误差平方后求和 |
| 均方误差 | MSE | N1∑(y−y′)2 | L2 在 N 个样本上的平均,训练最常用 |
| 均方根误差 | RMSE | N1∑(y−y′)2 | MSE 开方,单位与标签一致 |
块级公式写法如下。
MAE(平均绝对误差):
MAE=N1i=1∑N∣yi−yi′∣
MSE(均方误差):
MSE=N1i=1∑N(yi−yi′)2
RMSE(均方根误差):
RMSE=MSE

3.1 L1 与 L2 的核心差异:平方效应
L1 与 L2 的本质差别在于是否平方。当误差较大时,平方会显著放大惩罚;当误差小于 1 时,平方反而让惩罚变小。
| 误差 e | L1 惩罚 ∥e∥ | L2 惩罚 e2 |
|---|---|---|
| 0.5 | 0.5 | 0.25 |
| 1.0 | 1.0 | 1.0 |
| 2.0 | 2.0 | 4.0 |
| 3.0 | 3.0 | 9.0 |
可见:误差为 2 时,L2 的惩罚是 L1 的 4 倍;误差越大,差距越悬殊。这也是 MSE 对离群点更敏感的根本原因。
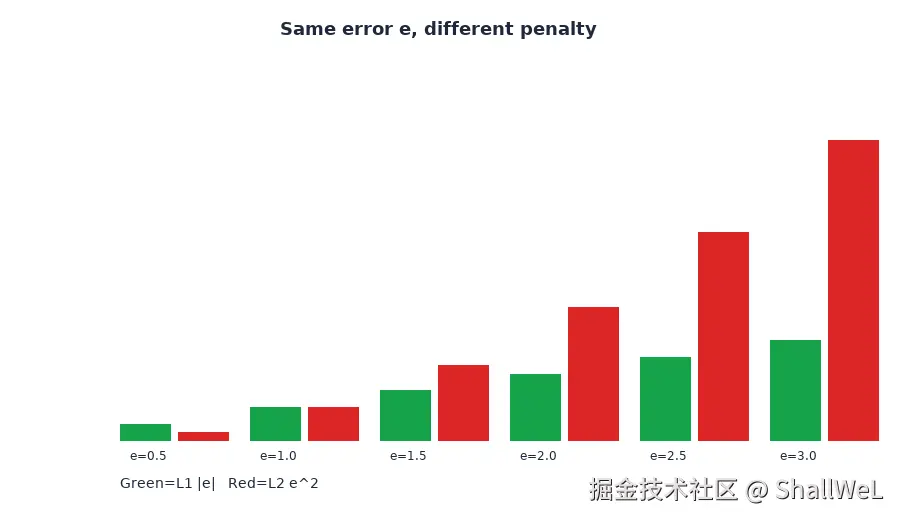
3.2 MAE 与 RMSE:为什么业务汇报常用 RMSE
MAE 表示平均误差幅度,直观好懂:「平均每条样本偏了多少个 MPG」。
RMSE 则更像误差的「典型散布程度」,对大误差更敏感。同一组预测下,MAE 与 RMSE 可能相差明显------若存在少数大偏差样本,RMSE 往往高于 MAE。
工程上的常见分工:
- 训练阶段:多用 MSE(光滑、可导,便于梯度下降)
- 评估与汇报:常用 RMSE(单位与标签一致,便于向业务方解释)
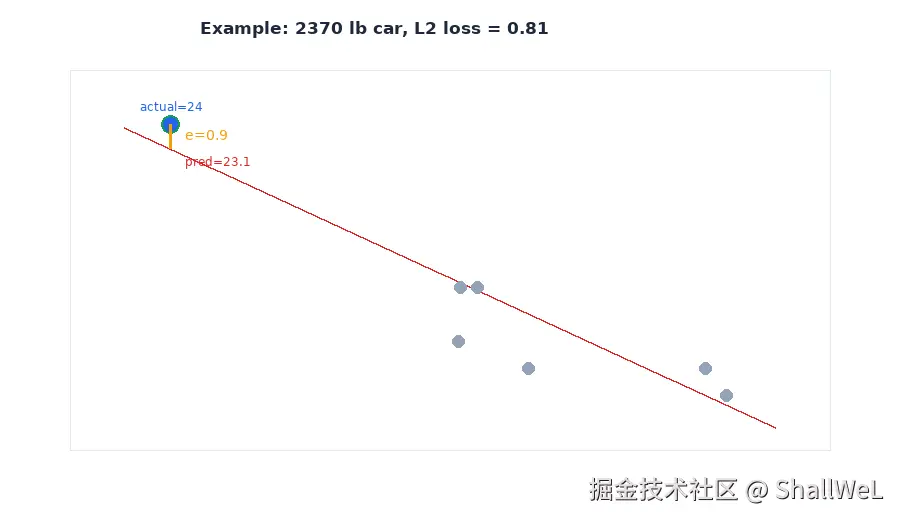
4. 手算示例:一辆 2370 磅的车
延续汽车油耗模型。上一篇拟合得到:
y′=34+(−4.6)×x1
其中 x1 为重量(千磅)。对重量 2370 磅(即 x1=2.37)的车辆:
| 步骤 | 计算 | 结果 |
|---|---|---|
| 预测 | 34+(−4.6)×2.37 | 23.1 MPG |
| 真实标签 | 数据记录 | 24 MPG |
| 误差 | 24−23.1 | 0.9 |
| L2 损失(单样本) | (0.9)2 | 0.81 |
| L1 损失(单样本) | ∥0.9∥ | 0.9 |
对全部 7 个样本,将各自的 L1 或 L2 损失求平均,就得到该模型在数据集上的 MAE 或 MSE。
5. 异常值 Outlier 如何影响损失选择
异常值有两层含义:
- 特征异常:如 8000 磅的轿车,超出常见重量范围;
- 预测异常:特征在正常范围内,但标签与模型预测严重不符,如 3000 磅却达到 40 MPG,而模型预测约 20 MPG。
异常值会牵动整条拟合直线往自己身上「靠拢」的程度,取决于你选用的损失。
5.1 MSE:更靠近异常值
MSE 对大误差施加平方级惩罚,优化时会更努力压低这些大偏差。结果是:拟合直线可能被少数离群点「拉」过去,整体更贴近异常值,却可能偏离大多数普通样本。
5.2 MAE:对异常值更稳健
MAE 按绝对值累加,大误差不会被平方放大。优化时模型更倾向于照顾多数样本的整体拟合,直线往往离异常值更远,但更贴近主体数据云。
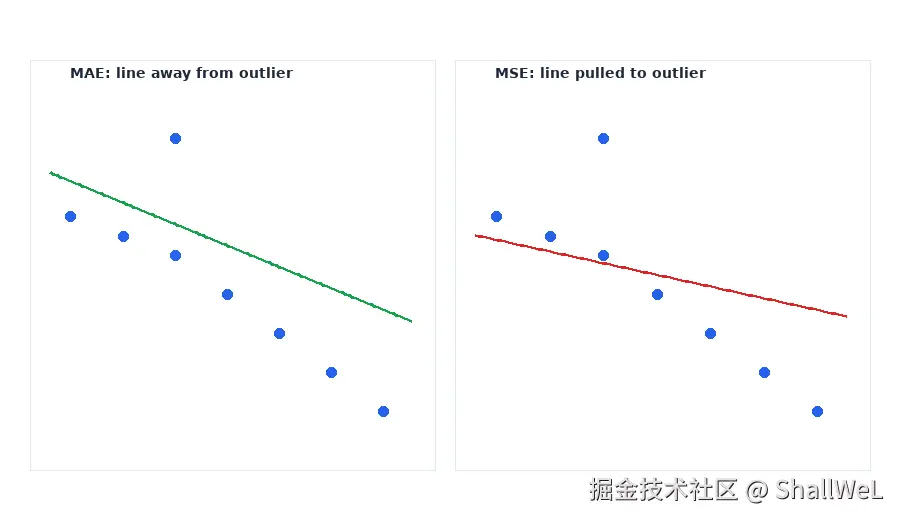
| 损失 | 拟合直线倾向 | 适用直觉 |
|---|---|---|
| MSE | 更靠近离群点,远离主体数据 | 相信异常值代表真实规律,需重点拟合 |
| MAE | 更远离离群点,贴近主体数据 | 认为异常值是噪声或录入错误,不宜主导模型 |
6. 如何为场景选择合适的损失
选择损失没有唯一正确答案,取决于数据分布、异常值含义和业务代价。
6.1 优先选 MSE 的情况
- 希望严厉惩罚大误差,不允许个别样本偏差过大;
- 认为离群点反映真实方差,模型应当覆盖;
- 需要光滑可导的损失面,便于梯度下降优化(MSE 在线性回归中尤为常见)。
训练时常用 MSE,汇报时可改用 RMSE,把数值还原到与标签相同的量纲。
6.2 优先选 MAE 的情况
- 数据中存在明显异常值,且你不希望它们主导模型;
- 希望损失更直接地表示「平均错了多少」;
- 对鲁棒性要求高,宁可牺牲对极端点的贴合。
6.3 决策参考
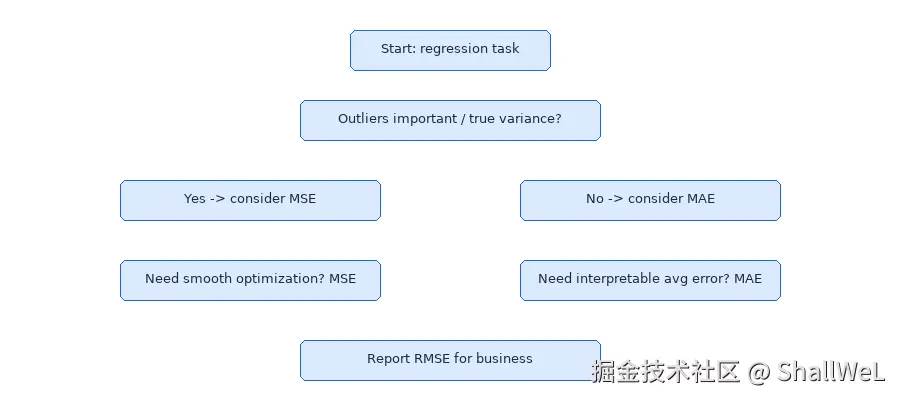
| 考量维度 | 倾向 MSE / RMSE | 倾向 MAE |
|---|---|---|
| 异常值 | 少,或异常值有意义 | 多,或视为噪声 |
| 优化需求 | 需要光滑损失便于求导 | 可接受非光滑(或换其他优化) |
| 业务解读 | 关注误差散布、大错代价高 | 关注平均偏差幅度 |
| 线性回归默认 | 多数框架默认 MSE | 需显式指定 |
7. 能力边界与常见误区
7.1 适用边界
- 本文讨论的 MAE、MSE、RMSE 主要面向回归任务;分类问题需用交叉熵等其它损失。
- 损失函数只衡量拟合程度,不直接等于业务价值。RMSE 低不代表部署后一定赚钱。
- 异常值是否保留,应结合数据采集流程判断,不能仅凭损失数值机械删除。
7.2 常见误区
| 误区 | 正解 |
|---|---|
| 「损失越小模型越好」 | 训练集损失低可能过拟合,需结合验证集 |
| 「MSE 和 RMSE 可以混为一谈」 | MSE 用于训练求导;RMSE 用于解释汇报 |
| 「有异常值就一定用 MAE」 | 若异常值是真实信号,MSE 反而更合适 |
| 「L1 损失 = MAE」 | L1 常指求和形式;MAE 是除以 N 后的平均 |
| 「误差为负说明损失为负」 | 损失通过绝对值或平方去掉符号,结果非负 |
8. 与训练流程的衔接
把损失放入上一篇的训练循环中,位置非常明确:
text
1. 准备数据
2. 初始化参数
3. 前向计算 -> 得到 y'
4. 计算损失 -> MAE 或 MSE(y', y) <-- 本篇核心
5. 反向求梯度
6. 更新参数
7. 重复直至收敛
8. 用 RMSE 等在验证集上评估第 4 步定义的「好」与「不好」,完全由损失函数刻画。下一篇将在此基础上讨论梯度下降------损失确定之后,参数究竟如何一步步被调到更优。
9. 关键术语速查
| 术语 | 一句话解释 |
|---|---|
| 损失 Loss | 量化预测值与真实值偏差的指标 |
| L1 损失 | 绝对误差之和 |
| MAE | 平均绝对误差,对异常值较稳健 |
| L2 损失 | 误差平方之和 |
| MSE | 均方误差,线性回归训练最常用 |
| RMSE | MSE 的算术平方根,单位与标签一致 |
| 异常值 Outlier | 特征或标签显著偏离主流分布的样本 |
| 残差 | 单样本的 y−y′,损失由其聚合而来 |
10. 小结
损失函数回答了训练中最关键的问题之一:模型错在哪里、错得有多严重。L1/MAE 与 L2/MSE 的差别,本质是「如何对待大误差」------平方放大还是绝对值一视同仁。结合异常值特性与业务目标做选择,才能让模型既拟合得好,又符合真实需求。
系列导航:
- 上一篇:【机器学习】(1)------ 线性回归
- 下一篇(预告):梯度下降------损失确定之后,参数如何被自动调到最优