《AI 知识卡片》第 02 期 · 一个参数,决定 AI 是严谨还是放飞
同一个问题,你问 AI 两遍:有时两次答得几乎一样,有时却差挺多?这个"时而稳定、时而多变",其实是可以调的。控制它的旋钮,就叫 temperature(温度)。
一句话:温度越低,AI 越稳定、越确定;温度越高,AI 越爱变花样、越放飞。

从 LLM 的工作原理讲起
要理解temperature,得先知道 LLM 每一步在做什么。
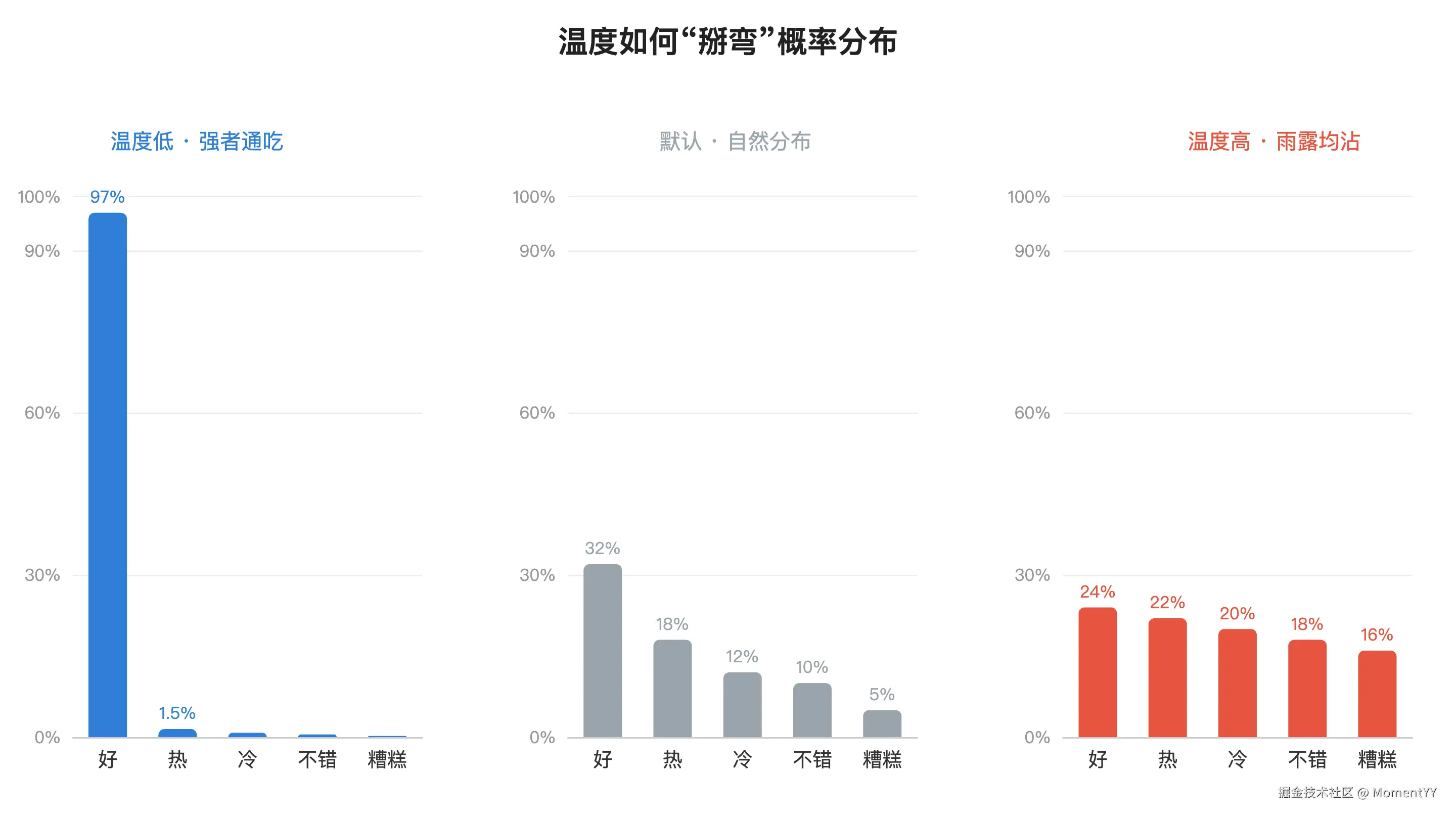
当 LLM 生成下一个字(token)时,它并不是直接写出一个答案,而是先算出"词汇表里每个 token 出现的概率"。比如给定前文"今天天气真",模型内部会算:好(32%)、热(18%)、冷(12%)、不错(10%)、糟糕(5%)、...(后面可能还有几万个候选,概率都很小)。
然后,它照着这张概率表来挑词 。而temperature,管的就是它挑得有多守规矩。
低温和高温的差别
你可以把温度理解成在调整这张表里"高分词和低分词的差距":
温度调低 :差距被拉大------本来领先的"好"会变得更强,几乎独占概率。于是 AI 每次都挑它,输出稳定、确定、可复现,但也保守、没惊喜。
温度调高 :差距被抹平------像"冷""糟糕"这些低分词也有了出头的机会。于是输出多样、有创意,但也更容易跑偏。
Temperature 就是用来"掰弯"这张概率表的旋钮 。温度低,强者通吃;温度高,雨露均沾。
那到底该怎么设
记住一句口诀就行:要"准"往低拧,要"创意"往高拧。
实战速查表:
| 场景 | temperature | 说明 |
|---|---|---|
| Agent 决策 / 工具调用 | 0 ~ 0.2 | 选错一步全盘乱,要最稳 |
| 分类 / 判断 | 0 | 要可复现,同样输入同样结果 |
| 信息提取 / 翻译 | 0 ~ 0.3 | 要忠实原文,不能自己加戏 |
| 代码 / SQL 生成 | 0 ~ 0.3 | 语法要严谨,不能瞎写 |
| 日常问答 / 内容总结 | 0.3 ~ 0.7 | 既准确又读得顺 |
| 文案 / 起名 / 写作 | 0.8 ~ 1.2 | 要多样、要有花样 |
| 头脑风暴 | 0.9 ~ 1.3 | 就指望它给点意外灵感 |
在代码里,它就是一个参数:
python
# 写作/起名等要多样 → 温度调高
client.chat.completions.create(model="gpt-4o", messages=[...], temperature=1.0)
# 调用工具/决策要准、要可复现 → 温度压到 0
client.chat.completions.create(model="gpt-4o", messages=[...], temperature=0)两个理解误区
误区一:
以为"温度越高 AI 越聪明"。高温只是让它更敢用冷门词,跟懂不懂、对不对没关系。该答错的,高温下照样错,只是错得更花哨。
误区二:
以为"调低温度能治胡说八道" 。压低温度能让它少乱来,但如果模型本来就记错了某个事实,低温只会让它更稳定地答错,稳定不等同于准确。治"幻觉"得靠别的办法(比如把资料喂给它、允许它说"不知道"),这个以后单独聊。
顺便认识几个"兄弟参数"
调 AI 时,温度常和下面几个参数一起出现,大致了解一下:
| 参数 | 职责 | 说明 |
|---|---|---|
temperature |
敢不敢变 | 本文主角,控制随机性高低 |
top_p(核采样) |
在多大范围里挑 | 只在概率最高的一小撮词里选,如 0.9 = 凑够 90% 概率就够,长尾词不看。值越小越保守 |
top_k |
在多大范围里挑 | 更直接,只在概率最高的 k 个词里选,如 50 = 只看前 50 个候选 |
max_tokens |
什么时候停 | 输出长度上限,防止啰嗦没完,也能控成本 |
stop |
什么时候停 | 碰到指定的词就立刻收笔,如遇到 "\n\n" 就停 |
最重要的一条:top_p和 temperature 一次只调一个,同时拧两个会互相干扰,结果反而难捉摸。
归类理解:temperature管"敢不敢变 ",top_p / top_k 管"在多大范围里挑 ",max_tokens / stop 管"什么时候停"。
一句话总结
temperature不改变 AI 懂多少,只改变它敢不敢"乱来"。要稳,压低它;要野,调高它。