前言
这不是一篇技术教程,而是一个产品创作者的完整记录------从脑子里一个模糊的想法,到上线一个包含用户端、API、后台管理、AI 集成的真实产品,全程用 Codex 协作完成。
一、引子:一个想法的诞生
我一直有一个困扰。
市面上缺一个让我能把目标「真正执行下去」的工具。
Notion 太自由,需要自己搭建模板,搭完模板就没动力执行了。待办清单太简单,只能记「今天要做什么」,解决不了「今天为什么要做这个」和「明天该做什么」。OKR 太企业级,适合团队管理,不适合个人日常。
我想要的东西其实很简单:
一个工具,我告诉它目标,它帮我拆成每天能做的事,然后每天提醒我、反馈我、最后和我一起复盘。
这个想法在我脑子里转了很久。但每次一想到要落地------前端要写页面、后端要搭接口、数据库要设计表、还要接 AI、还要做后台管理、还要部署------我就觉得一个人搞不定。
直到我遇到了 vibe coding。
准确地说,是遇到了能支持 vibe coding 的工具。
二、需求发掘:痛点不是想出来的,是聊出来的
这个产品的需求不是坐在电脑前拍脑袋想出来的。它来自两个地方:自己的失败经验 ,和和朋友的聊天。
从自己开始
我有过很多次「列了一个宏伟计划,然后三天就放弃了」的经历。
想健身,办了卡,去了两次,没了。想学英语,下了 App,打了三天卡,忘了。想存钱,月底一看,还是花超了。
每一次失败的原因其实差不多:
- 目标本身太模糊(「我要变健康」------什么叫健康?)
- 没有拆到「明天就能做」的程度(「我要每天锻炼」------练什么?多久?在哪?)
- 执行中没有反馈(打卡就是打个勾,然后呢?)
- 放弃了也没有复盘(下次继续犯同样的错)
和朋友聊
我发现这不是我一个人的问题。
和朋友吃饭时聊到这个话题,几乎每个人都有类似的经历。一个朋友说:
「我每次列计划都很兴奋,感觉人生要改变了。然后执行三天就没了,下次再列一个更兴奋的计划。」
另一个朋友说:
「我知道我应该做什么,但我就是不知道第一步从哪里开始。」
这些对话让我意识到:痛点不在「定目标」,而在「从目标到执行的第一公里」。
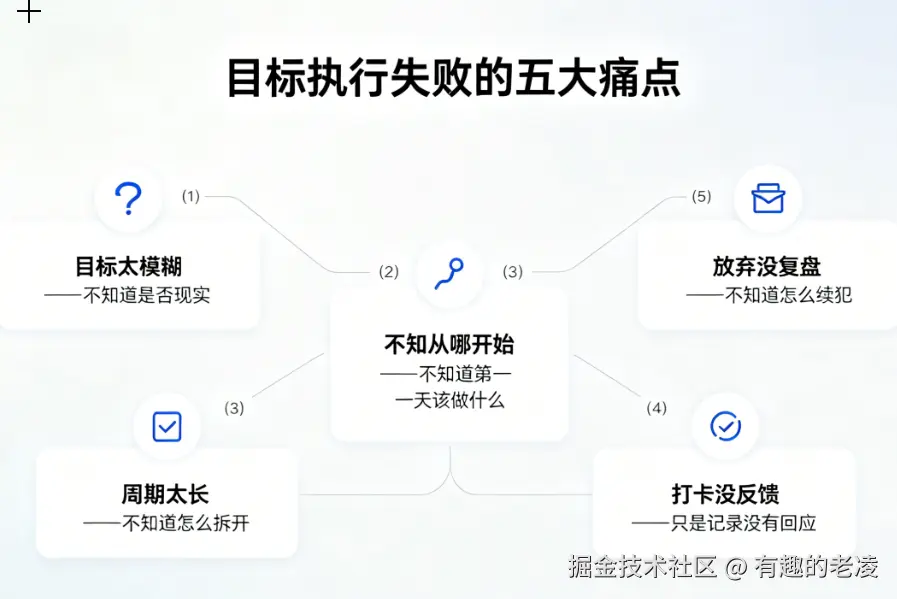
五个核心问题
我把这些观察整理成了五个问题,它们后来直接决定了产品的功能设计:
| # | 问题 | 产品回应 |
|---|---|---|
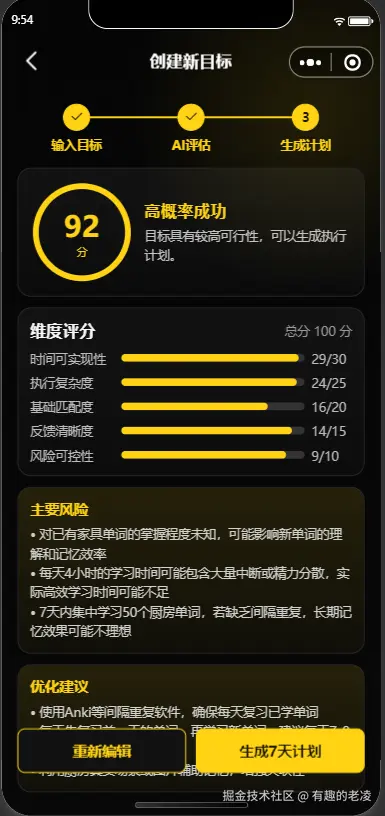
| 1 | 不知道目标是否现实 | AI 先评估可行性,给分数和建议 |
| 2 | 不知道第一天该做什么 | AI 把目标拆成每天的具体任务 |
| 3 | 不知道怎么把长周期拆开 | 计划分阶段(适应期 → 执行期 → 强化期 → 收尾) |
| 4 | 打卡只是记录,没有反馈 | AI 教练每天给出针对性反馈 |
| 5 | 失败了没有复盘,下次还犯 | 计划完成后自动生成最终复盘 |
产品的定位就这样出来了:一个 AI 帮你从「模糊目标」走到「每一天该做什么」的工具。
三、灵感启发:从碎片到产品
有了痛点,下一步是把它变成一个可交互的产品。这个过程不是线性的,更像是拼图------灵感碎片一块一块地拼起来。
最初的灵感碎片
碎片 1:让用户「说」目标,而不是「填」目标。
大多数目标管理工具的第一步是让你填表单:目标名称、截止日期、优先级、分类......还没开始执行就觉得累了。
我想要的体验是:用户上来就说一句话------「我想在三个月内减掉 10 斤」或者「我想半年内考过雅思 6.5」------剩下的交给 AI。
碎片 2:AI 是「教练」,不是「工具」
市面上大多数工具把 AI 定位成一个问答助手:你问它答。但在这个场景里,AI 应该是一个主动的角色------它帮你评估目标、生成计划、每天给你反馈、最后和你复盘。
碎片 3:闭环比功能重要
这个产品不需要很多功能。它只需要做好一件事:让用户从「我有一个目标」走到「我今天完成了该做的事」,然后再回到「我离目标更近了一步」。
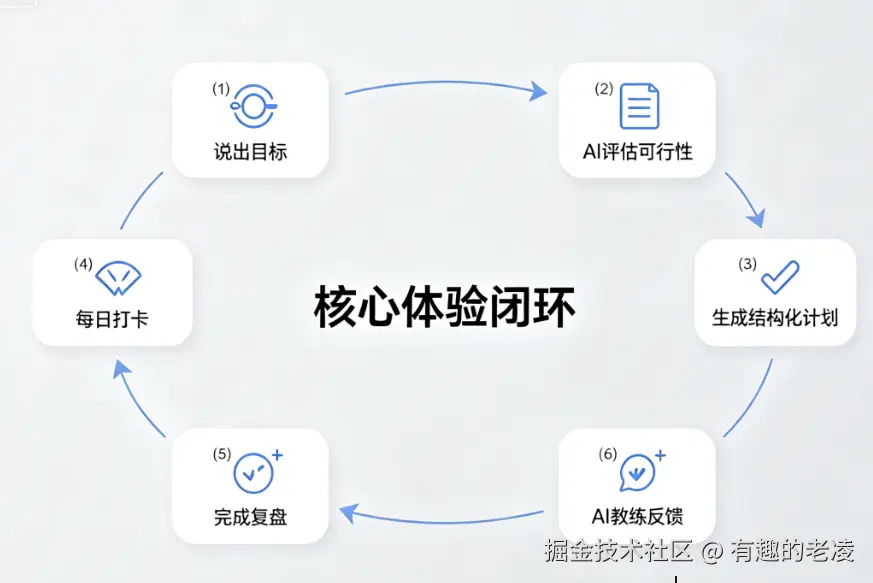
核心体验闭环
最终,产品的核心体验被设计成一个短的闭环:
说出目标 → AI 评估可行性 → 生成结构化计划 → 每日打卡 → AI 教练反馈 → 完成复盘这个闭环里最关键的环节不是「生成」,而是「执行」。所以数据库和后端不是为了保存一段 AI 文案,而是把 AI 结果拆成可操作的结构化数据------计划、阶段、天、任务、打卡、反馈、复盘。
产品名「一定能成」的由来
名字来自一个很直接的念头:不管是产品还是用户,都需要一个笃定的声音。
用户需要一个让他相信「这次能成」的工具。我自己也需要------一个从 0 到 1 用 AI 搭起来的项目,也说不准能不能成。所以这个名字既是给用户的,也是给自己的。
四、技术选型:为什么是 Codex
在确定用 Codex 之前,我试过两个其他的 AI 编码工具。
尝试过的工具
Claude Code
Claude 的对话能力很强,代码生成质量也不错。但在当时,它对中文项目的支持不够稳定------表注释、接口文档、提示词里的中文容易出现编码问题。而且在一个已经有一定结构的项目里持续迭代时,上下文保持得不够连贯------经常出现「之前说好的设计,换了一个对话就忘了」的情况。
Trae 国内版
Trae 对国内生态很友好,中文支持好,也理解国内常用的技术栈。但它的体验更偏向「从零生成」,在「对已有项目做持续修改和迭代」的场景下,流程不够顺畅。
为什么 Codex 最终胜出
Codex 最打动我的三点:
1. 项目级上下文
它不是单次问答。它在整个项目仓库里工作------读你的代码结构、理解你的命名规范、知道你的数据库表是怎么关联的。这意味着你可以说「在用户 API 里加一个查询今天是第几个打卡日的接口」,它知道去哪里加、怎么命名、和现有代码怎么对接。
2. 全栈覆盖
从一个想法到一个能跑起来的全栈项目,涉及:
- 数据库建表 + 迁移脚本
- 后端接口 + 路由 + 中间件
- 前端页面 + 组件 + 状态管理
- AI 集成 + 异常处理 + fallback 逻辑
- 后台管理系统
- 部署配置
- 测试用例 + 文档
Codex 一个工具贯穿了所有环节。切换成本几乎为零------不需要在前端框架、后端框架、数据库工具、AI SDK 之间频繁切换上下文。
3. 迭代式协作
这是最打动我的一点。Codex 的工作方式不是「你问一个问题,它给一个答案」,而是:
你先说一个想法,它生成一个版本;你跑起来看哪里不对;你补充体验要求;它继续改接口、改页面、改数据;最后沉淀成文档。
这个过程非常像身边坐着一个工程搭子:我负责判断方向、提出产品感受和验收标准,它负责把想法拆成代码、文件、接口和数据结构。
坦诚的边界
当然,Codex 也不是万能的。我的判断:
适合的场景:
- 从 0 到 1 的个人产品
- 原型快速验证
- 需要全栈能力但团队只有一个人的项目
- 对代码质量要求「够用即可,上线后持续优化」
不适合的场景:
- 高并发、高安全性要求的系统
- 遗留系统改造(它没有现成上下文)
- 需要深度性能优化的场景
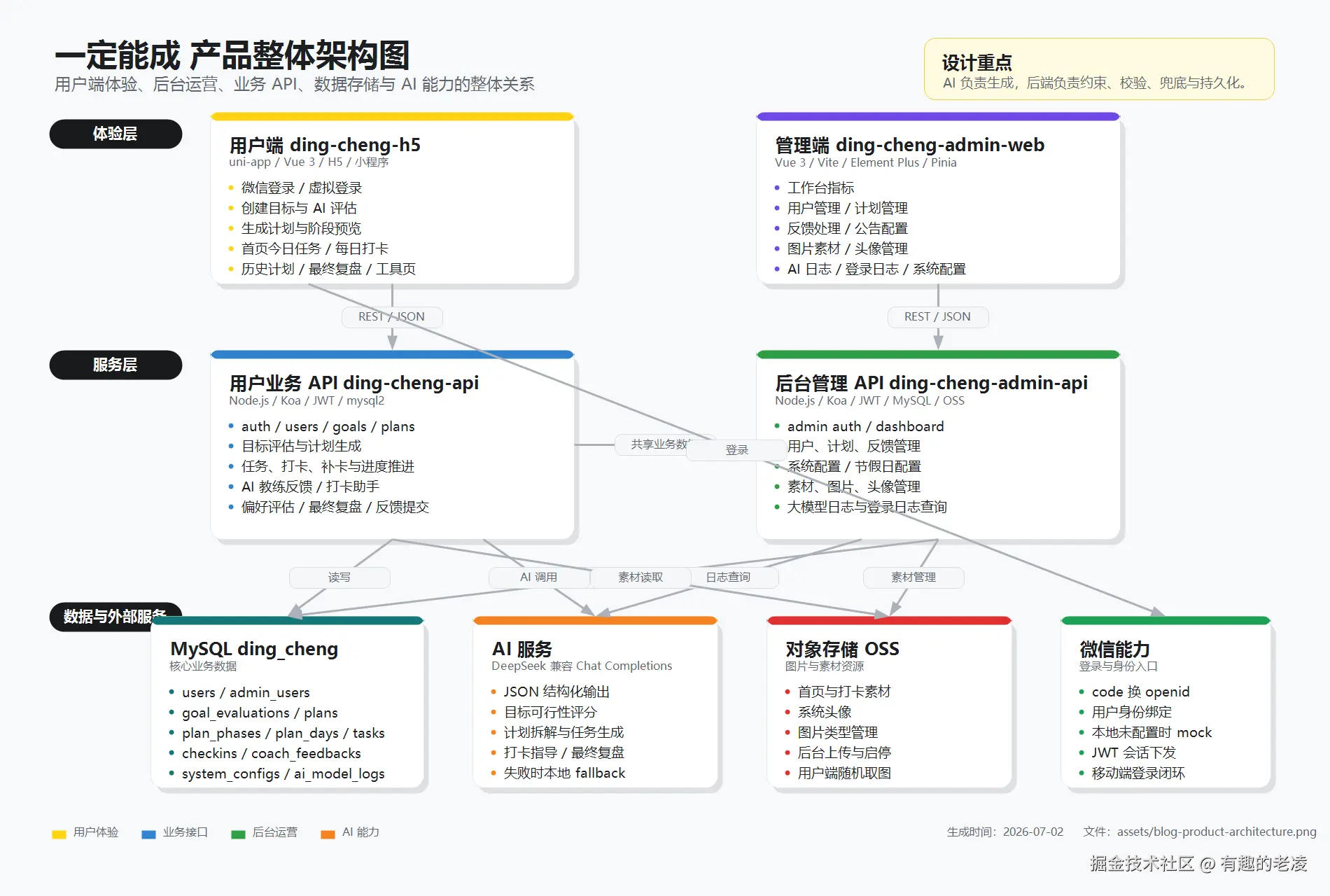
五、方案构思:AI 负责生成,人负责约束
这是整个产品设计里最重要的部分。
整体架构
scss
┌──────────────────┐ ┌──────────────────┐
│ 用户端 │ │ 管理端 │
│ (uni-app/H5) │ │ (Vue 3 + Element)│
└────────┬─────────┘ └────────┬──────────┘
│ │
▼ ▼
┌──────────────────┐ ┌──────────────────┐
│ 用户 API │ │ 管理 API │
│ (Koa + JWT) │ │ (Koa + JWT) │
└────────┬─────────┘ └────────┬──────────┘
│ │
└──────────┬──────────────┘
▼
┌──────────────────┐
│ MySQL │
│ (d_c_DB) │
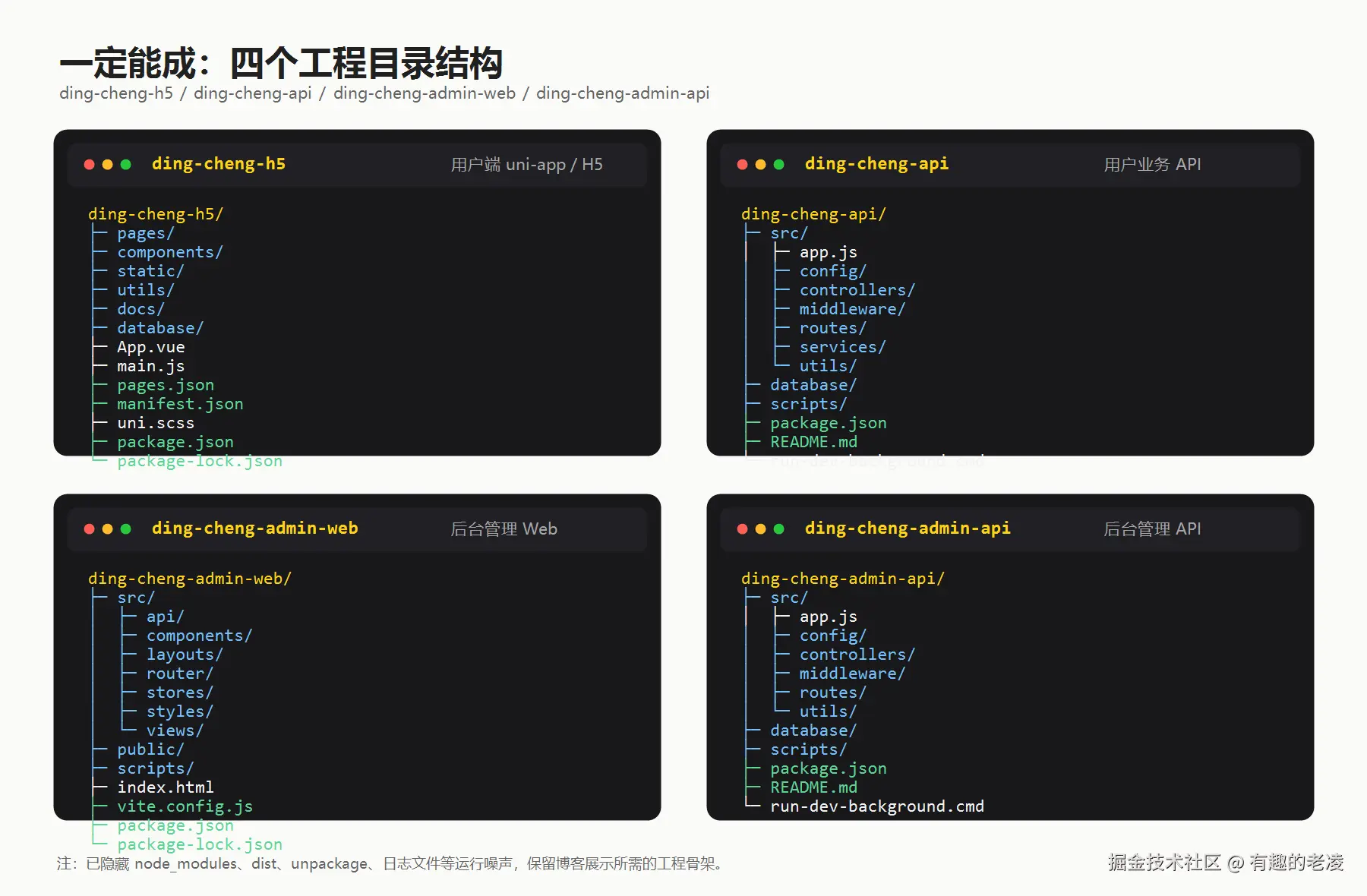
└──────────────────┘四个工程,共用同一个数据库。
为什么拆成四个工程?
职责分离。用户 API 挂了不影响管理端,管理端的大流量查询不影响用户服务。而且可以独立部署------实际上线后用户 API 和管理 API 就部署在不同的端口上。
为什么共用数据库?
一开始考虑过用户端和管理端用不同的数据库,然后通过接口同步。后来果断放弃了------对于一个人项目来说,增加一个数据同步层只会引入更多 Bug。共用数据库 + 合理的前后端校验,够简单、够可靠。
核心业务流程
bash
登录
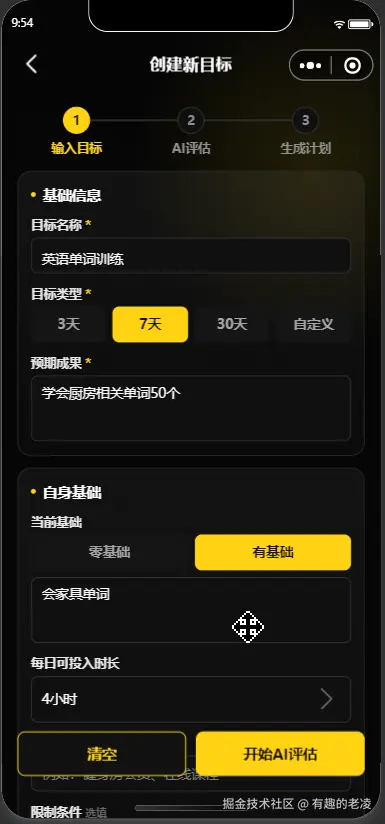
→ 创建目标(填表单:目标名称、周期、预期成果、每日可投入时间......)
→ POST /api/v1/goals/evaluate → AI 评估可行性(或本地 fallback)
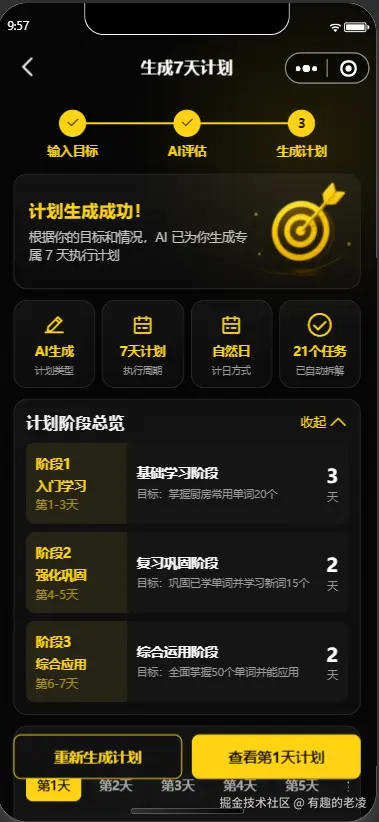
→ 分数 >= 60 → POST /api/v1/plans/generate → 生成计划
→ 首页展示活跃计划、今日任务、AI 教练反馈
→ 每日打卡 → 勾选任务 → 更新进度
→ 计划完成 → AI 生成最终复盘
→ 历史页查看所有计划状态AI 的边界设计:最核心的设计决策
一开始我很容易陷入一个误区:既然用了 AI,那是不是所有东西都让 AI 自由发挥?
后来我意识到------产品里真正可靠的 AI 不是「随便说」,而是「被约束后输出结构化结果」。
所以后端设计了几层保护:
1. AI 输出必须是 JSON,不能是 Markdown 文案
强制使用 DeepSeek 的 response_format: { type: 'json_object' }。如果 AI 返回的不是合法 JSON,直接走 fallback。
2. 所有输出必须经过 normalize 和校验
AI 可能返回字段缺失、格式不对、阶段天数不连续。所以后端有一个 normalize 层,专门做清洗:
- 字段长度截断
- 日期格式统一
- 阶段天数连续性校验
- 任务数量控制在合理范围
- 必填字段检查
3. 无 Key 或调用失败时走本地 fallback
AI_API_KEY 为空时,或者 AI 调用超时/返回异常时,系统自动走本地算法生成评估和计划。虽然质量不如 AI,但产品不会因此不可用。
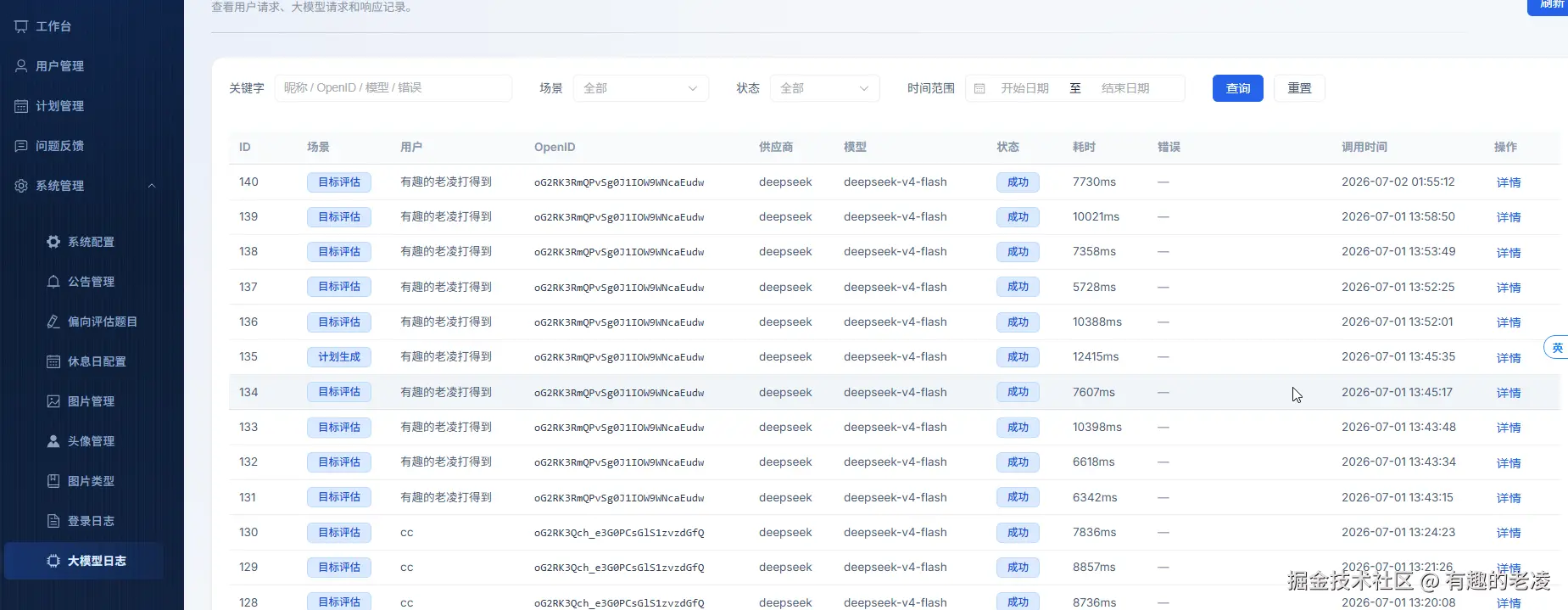
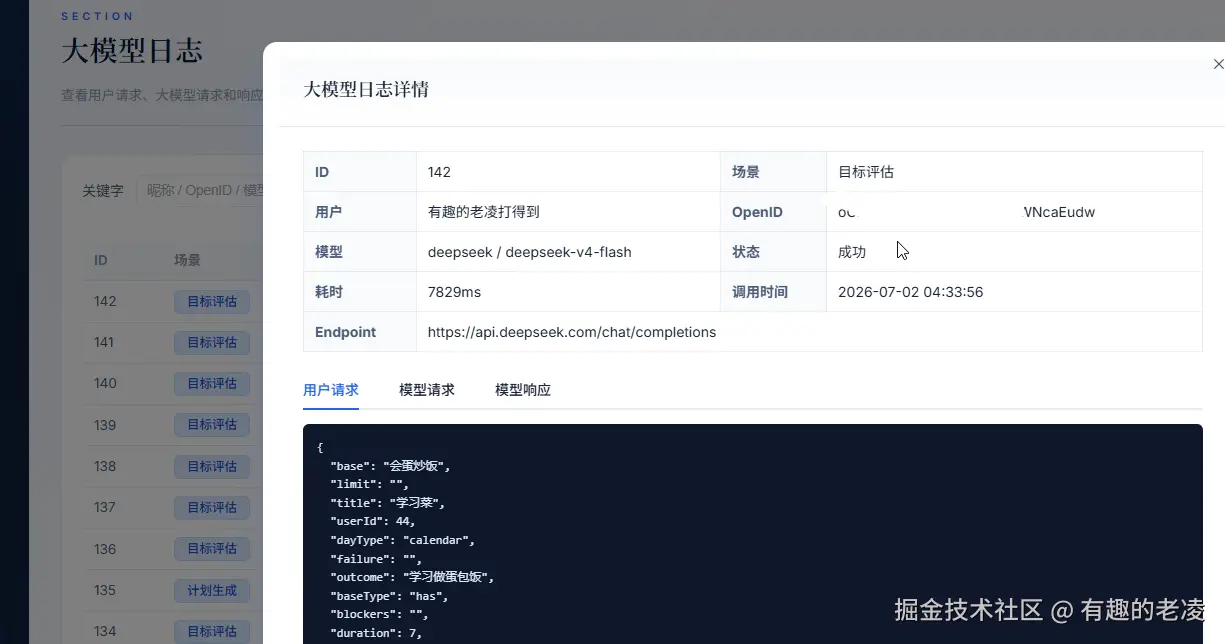
4. 每次调用都记录日志
每次 AI 调用(成功或失败)都写入 ai_model_logs 表,包含完整的请求、响应、耗时、状态。这为后续排查和限流提供了基础数据。
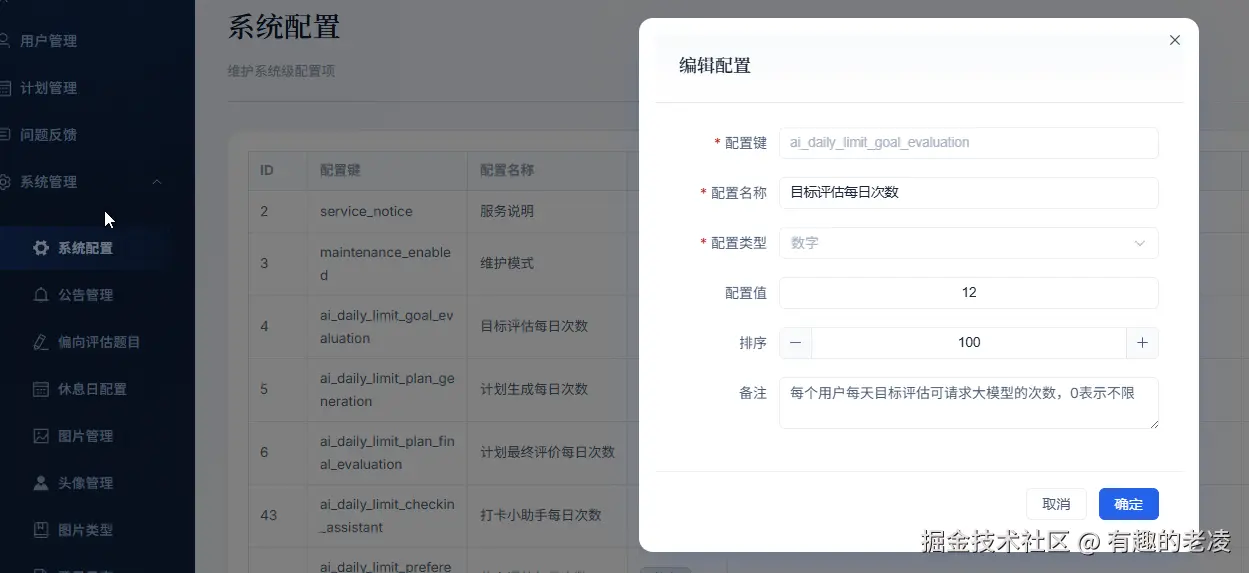
5. 每个场景有独立的每日调用限制
通过 system_configs 表配置每个场景的每日调用上限。防止某个用户刷接口把额度用完。
核心理念就一句话:AI 是「生成引擎」,产品边界由代码控制。

六、数据库设计:围绕「执行闭环」建模
数据库的设计原则很简单:一切为了让用户能把目标执行下去。
核心关系链
bash
users
→ goal_evaluations(目标评估)
→ plans(计划主表)
→ plan_phases(阶段)
→ plan_days(天)
→ tasks(任务)
→ checkins(打卡)
→ coach_feedbacks(教练反馈)
→ plan_final_evaluations(最终复盘)截图占位:MySQL 数据库中核心表的列表截图 ------ 展示 ding_cheng 库下的所有表名
截图占位:plans 表的字段结构截图 ------ 展示关键字段和类型
截图占位:tasks 表的几条示例数据截图 ------ 展示 AI 生成的任务数据结构
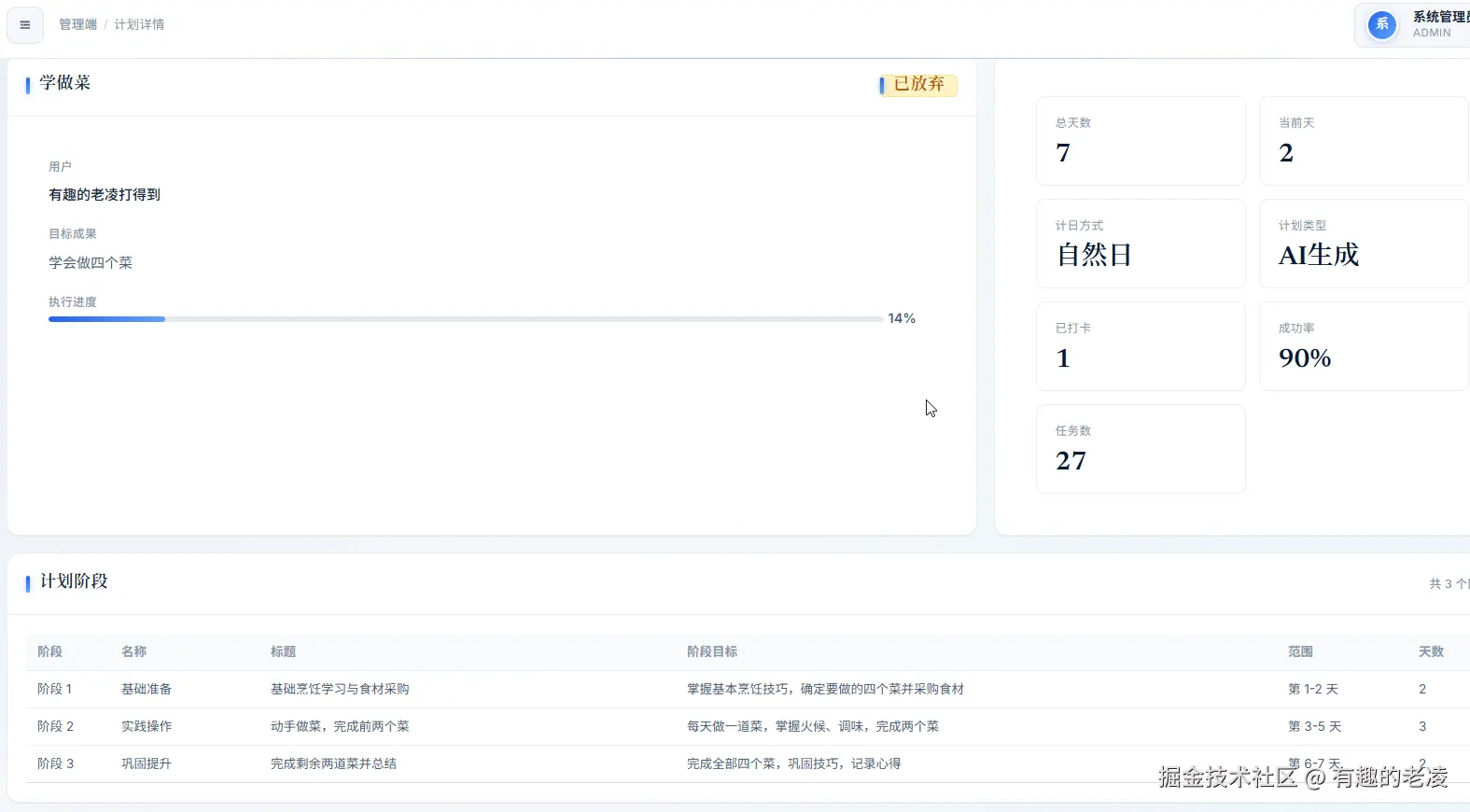
为什么拆成 4 层(计划 - 阶段 - 天 - 任务)
这是一个很早就做好的决定:AI 生成的不是一段文案,而是一棵结构树。
plans:计划整体,保存状态(active / completed / abandoned)plan_phases:阶段,比如「启动适应期」「稳定执行期」「强化提升期」「收尾复盘期」plan_days:每一天,绑定真实日期,支持后续补卡、跳过、统计tasks:每天的具体任务,用户打勾的就是这一层
这样设计的好处是:
- 用户看到的是今天要做的事,不是一大段计划文案
- 后台可以按阶段、按天、按任务维度做统计
- 后续支持补卡(补卡任务继承原始任务字段)
- 最终复盘时可以看到每天的执行质量
三种计日方式的设计背景
不同用户对「打卡频率」的需求不一样。所以设计了三种模式:
| 模式 | 说明 | 适用场景 |
|---|---|---|
calendar |
自然日,每天都打卡 | 短期冲刺、习惯养成 |
workday |
工作日打卡,跳过周末和法定节假日 | 学习计划、工作项目 |
rest_day |
休息日打卡(每 7 天只打 2 天) | 健身、运动(需要恢复日) |
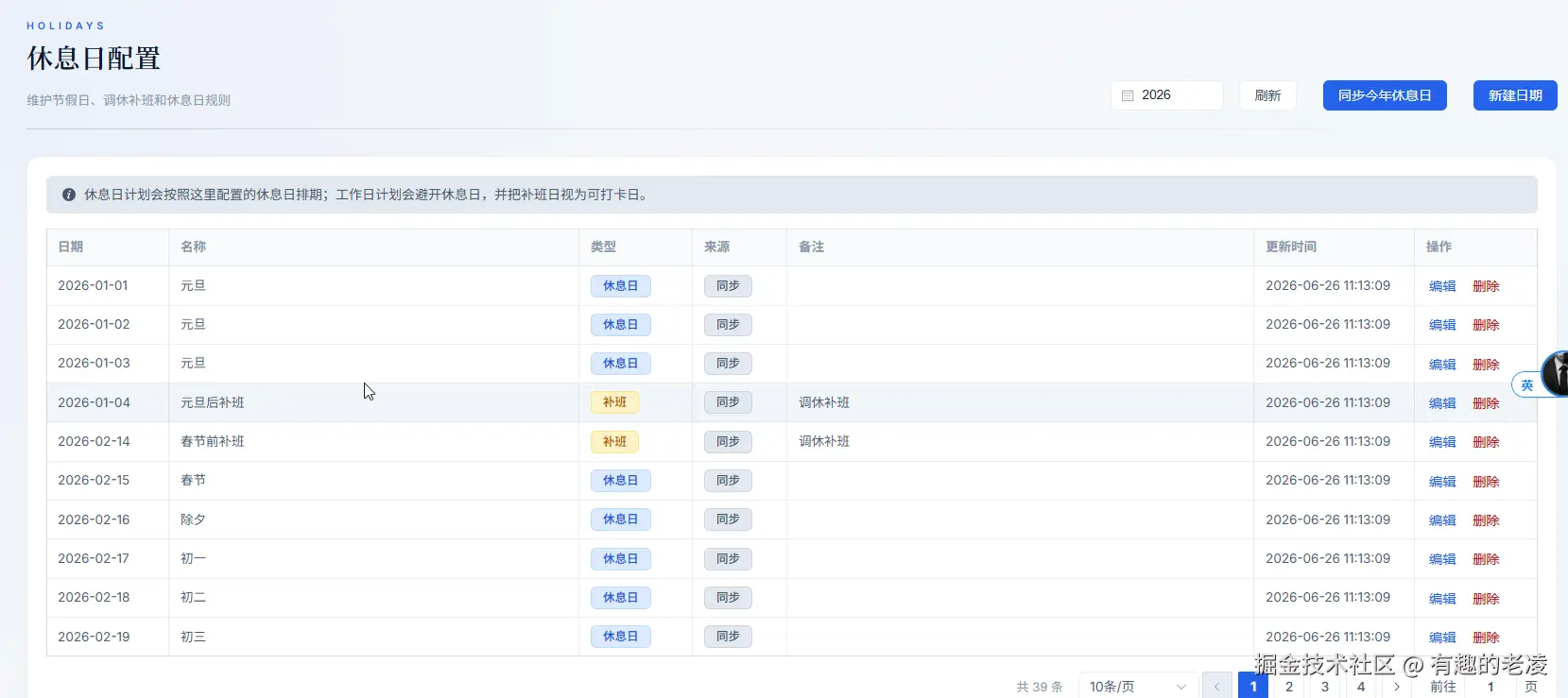
工作日模式带来一个额外的问题:中国的调休制度。 周末可能补班,工作日可能放假。所以需要一张 holiday_calendars 表,由管理员在后台配置,也支持年度同步。
打卡状态为什么是三级
不是简单的 true/false,而是三级状态:
completed:全部完成partial:部分完成incomplete:未完成
这样复盘时可以更真实地看到执行质量------「今天完成了 3 个任务中的 2 个」比「今天打卡失败」有更多信息量。
AI 日志表的设计意图
ai_model_logs 是上线后最有价值的表之一。每条记录包含:
- 用户 ID
- 场景(评估 / 生成计划 / 教练反馈 / 复盘 / 偏向评估)
- 供应商和模型名称
- 请求完整内容
- 响应完整内容
- 耗时(毫秒)
- 状态(成功 / 失败 / 部分成功)
没有这张表,AI 出问题时就只能靠猜。有了它,后台可以按场景、按用户、按时间段排查问题,还可以做用量统计和成本估算。
运营支撑表
除了核心业务表,还有一组从一开始就设计了的运营表:
| 表 | 用途 |
|---|---|
system_configs |
系统配置(AI 调用上限、站点名、功能开关) |
announcements |
公告(可配置展示时间、是否只显示一次) |
user_feedbacks |
用户反馈(和处理状态流转) |
avatars + 关联表 |
系统头像管理(支持按标签分类、排序) |
preference_assessment_* |
用户偏向评估题目和结果 |
这些表让项目从「能跑」变成「能运营」。
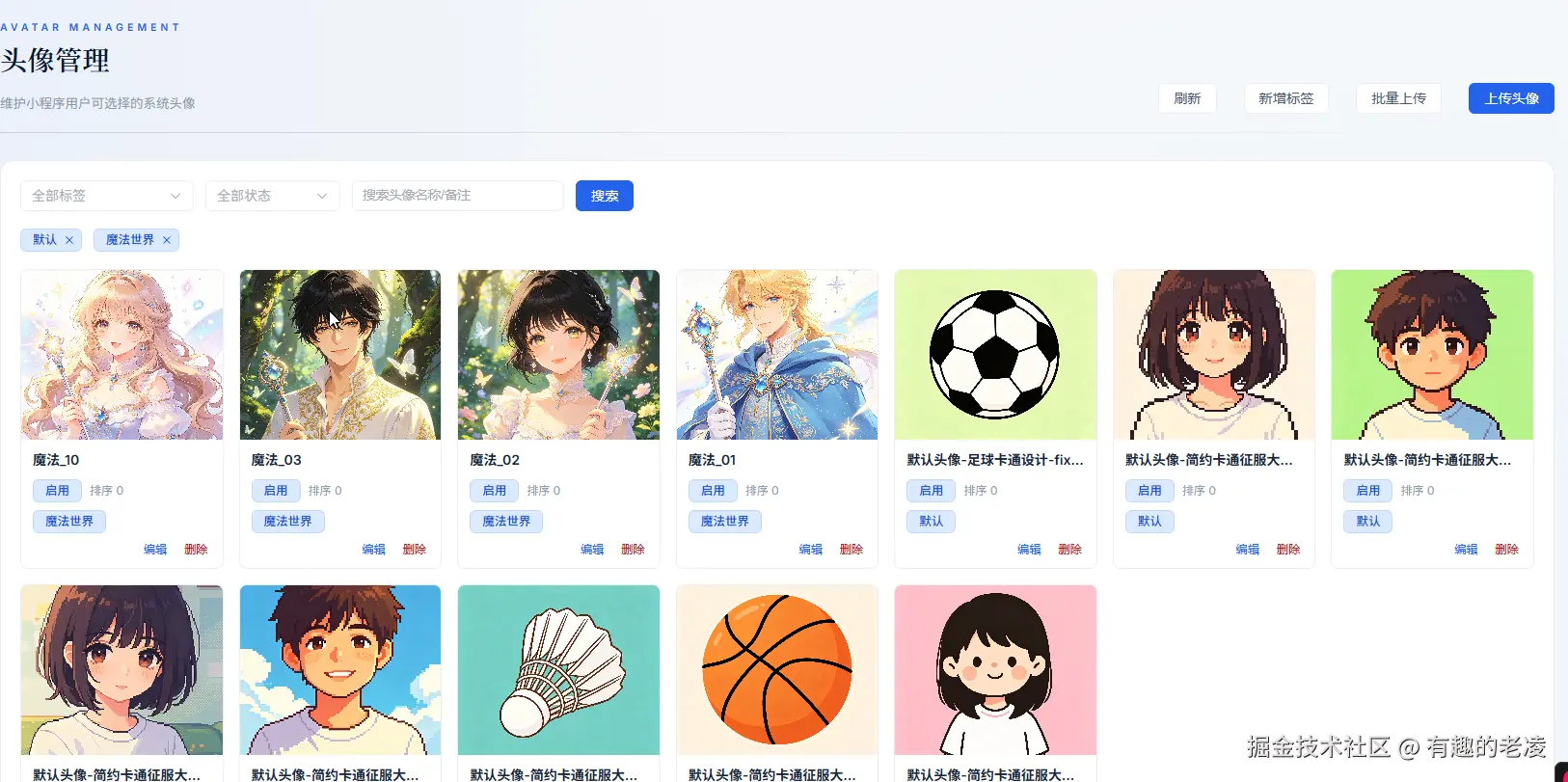
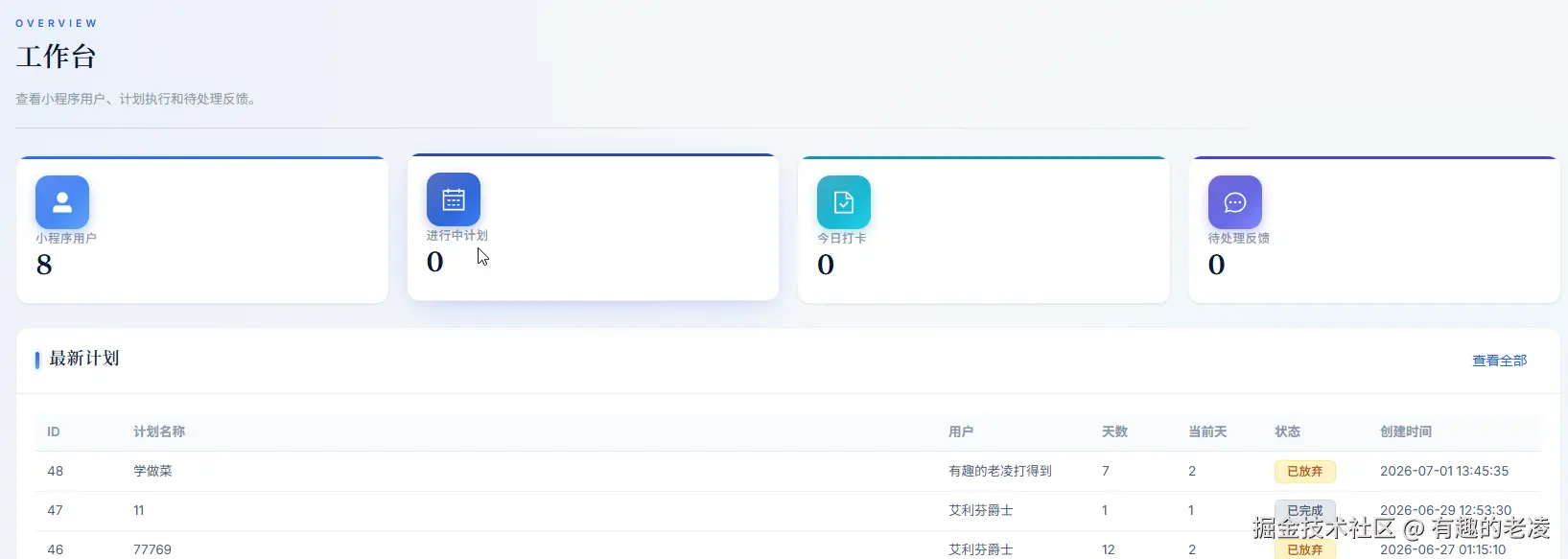
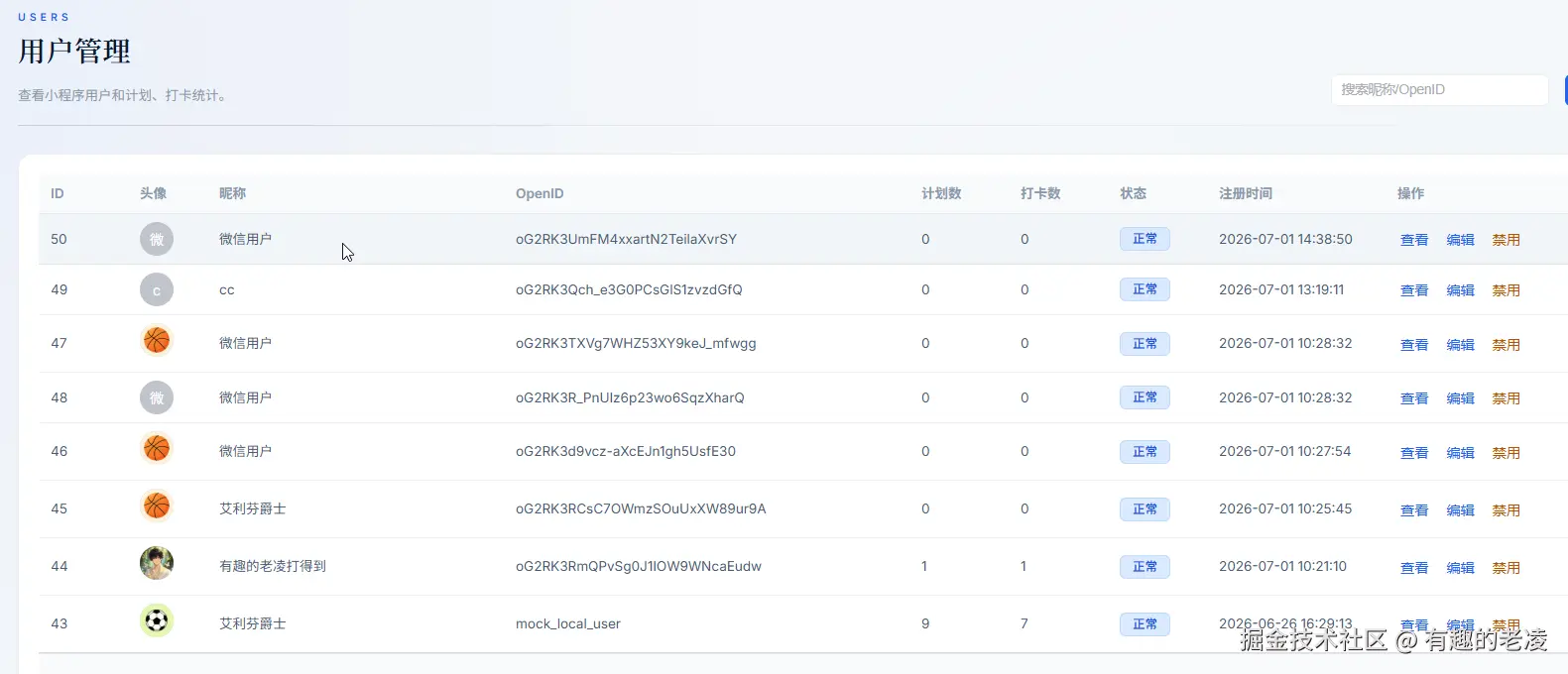
六章半:一个插曲------后台管理为什么要提前做
不算单独一章,但值得单独说一下。
很多个人项目会先只做用户端,后台「以后再说」。我这次在一开始就做了后台管理。
原因很简单:AI 产品需要观察。
我需要知道:
- 用户创建了什么目标?
- AI 返回了什么内容?格式对不对?
- 哪些调用失败了?为什么?
- 每个 AI 场景每天调用了多少次?
- 用户反馈了什么?有没有共性问题?
- 节假日配置是否正确影响了计划日期?
没有后台的时候,这些问题只能靠猜。有了后台------哪怕只是一个简单的列表页 + 日志查看------问题就变得可见了。
所以后台不是锦上添花,它是调试入口和运营入口。
七、Vibe Coding 的真实工作流
很多人好奇「和 AI 一起做产品」到底是什么感觉。我用一个真实的案例来说明。
一次典型的开发循环
以「打卡功能」为例,看看它是如何从想法变成代码的:
第 1 步:提出需求(口语化描述)
「我希望用户进入打卡页后,能看到今天的任务列表,勾选完成后点击提交,然后 AI 根据完成情况给一条反馈。」
第 2 步:Codex 理解需求 + 读现有代码
它不会直接开写。它会先读现有的项目结构------plans 表有什么字段、tasks 表怎么关联、有没有已存在的打卡相关接口、前端页面是用什么组件库。
第 3 步:生成方案
它会给出一个方案,包含:
- 后端需要新增的接口(
POST /api/v1/plans/:planId/checkins) - 数据库是否需要调整(已有的
checkins表够用) - 前端打卡页的组件结构
- AI 调用的时机和参数
第 4 步:我审核,调整方向
我会看方案是否合理。比如 AI 反馈的触发时机------是每次打卡都调 AI,还是只在某些条件下调?调用频率会不会太高?要不要加节流?
第 5 步:Codex 落地代码
涉及多个文件:
- 后端 controller、service、route
- 前端页面、组件、API 调用
- 可能还涉及数据库迁移脚本
第 6 步:启动服务验证
启动后端和前端,实际走一遍流程。发现问题------比如某个字段返回格式不对、页面在手机上展示异常------继续迭代。
角色转变
这个过程里,我的角色发生了有趣的转变。
传统开发模式下,我是「执行者」------每个接口、每个页面、每个字段都要自己写。节奏是:想清楚 → 写代码 → 测试 → 发现漏了什么 → 回去改。
Vibe coding 模式下,我更像是一个 「产品经理 + 验收者」------我负责说清楚要什么、判断做出来的对不对、决定下一步往哪个方向走。Codex 负责把想法变成代码。
这并不意味着我不需要懂技术。恰恰相反------要判断 AI 的方案好不好、代码稳不稳、数据结构合不合理,需要更强的技术判断力。
八、踩坑实录
做这个项目踩了不少坑。挑几个印象最深的说说。
坑 1:数据库在 ECS 上跑不动
项目开发阶段用的是本地 MySQL,一切正常。部署到阿里云 ECS 后,出了问题------数据库查询非常慢,一个简单的列表页要加载好几秒。
一开始以为是代码问题,各种加索引、优化 SQL、加缓存,效果有限。后来才发现是 ECS 的磁盘 IOPS 不够------MySQL 在云服务器上跑,尤其是突发性能实例(t5/t6),数据库操作一多就卡。
解决方案:把数据库从 ECS 自建 MySQL 迁移到阿里云 RDS。迁移后查询延迟从秒级降到毫秒级,效果立竿见影。
教训:对于数据库密集型应用,不要把数据库和应用挤在同一台低配 ECS 上。RDS 虽然多花点钱,但省下的排查时间远超成本。
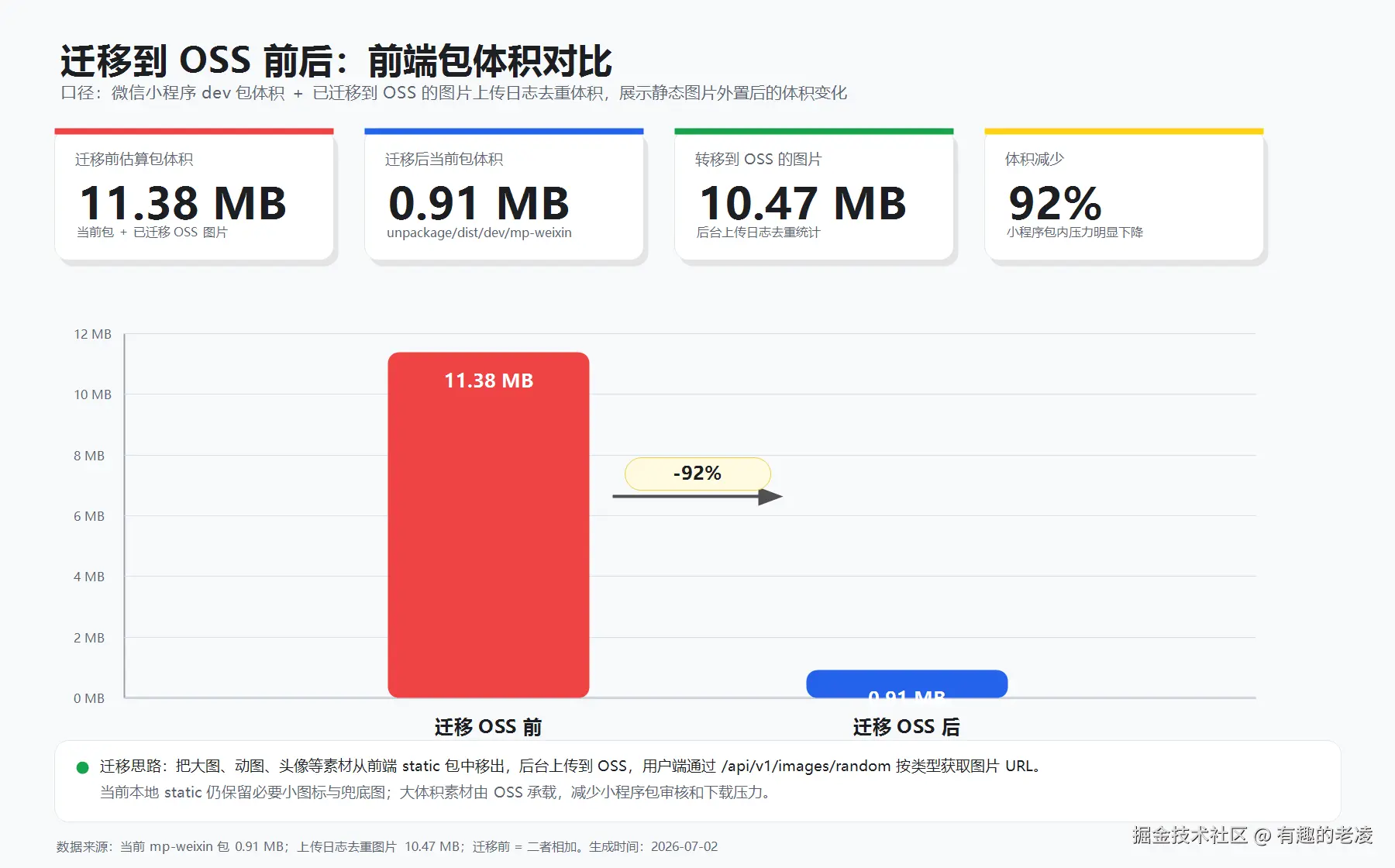
坑 2:静态图片打包导致包体积爆炸
用户端 H5 里用了一些素材图片------导航图标、AI 教练形象、目标分类图、空状态占位图。开发时觉得「本地引用方便」,全部放在 static/ 目录下直接打包。
结果第一次 build 出来,js 包体积大得离谱,首屏加载要七八秒。检查发现图片全部被 base64 打包进了 js 里。
解决方案:把所有静态图片上传到阿里云 OSS,前端通过 URL 引用。同时做了按类型管理(头像、图标、背景图......),后台可以随时替换和新增。
连带收获:OSS 上还顺带解决了用户头像的问题------用户上传的头像也存 OSS,后台可以管理所有素材。
坑 3:AI 输出不稳定
这是预期内的坑,但实际遇到时还是比想象中更频繁。
典型问题:
- AI 返回了 Markdown 格式而不是要求的 JSON
- JSON 字段缺失(比如没有返回
phase_name) - 阶段天数不连续(第 1 阶段覆盖 1-3 天,第 2 阶段从第 5 天开始,跳过了第 4 天)
- 任务数过多(某天列了 15 个任务,移动端根本展示不下)
解决方案:后端加了一个 normalize 层,专门做清洗和校验。这个层不信任 AI 的输出------它检查字段是否存在、格式是否正确、数据是否连续、数量是否在合理范围。不通过就走 fallback 或重新尝试。
截图占位:AI 返回的非法 JSON 日志截图 ------ 展示 AI 输出不规范的真实案例
截图占位:normalize 层代码截图 ------ 展示清洗和校验的核心逻辑
坑 4:前后端接口对齐
一个人做前后端分离项目时,最容易出现的问题就是「接口说好了,但实现的时候对不上」。
比如日期格式------后端返回 2026-06-19,前端期望的是 2026/06/19。比如状态枚举------后端用 active/completed/abandoned,前端代码里写的是 ACTIVE/DONE/ABANDONED。
没有两个人沟通的成本,但切换前端和后端上下文时,自己也会忘。
解决方案 :统一接口文档(项目里的 docs/api.md),每次改接口同步更新。后来养成了一个习惯------改完接口后,先跑一遍前端页面,确保所有字段都能正常渲染。
坑 5:文档滞后
项目的 README 和实际代码经常不同步。早期好几次出现「README 写的是旧接口路径,代码已经换了新路径」的情况。
教训:文档和代码一样需要被验证。后面我定了一个规则------AI 改了代码后,如果涉及接口变更或表结构变更,必须同步更新对应的文档。这个规则写进了每次改动的 checklist 里。
九、对 Vibe Coding 的重新理解
做完这个项目后,我对 vibe coding 有了更深的理解。
Vibe Coding 不是「AI 替代人」
网上有很多讨论 vibe coding 的帖子,一种常见的焦虑是「AI 会替代程序员」。
我的感受正好相反。
这个项目里,AI 承担的是执行层 的工作------写代码、建表、改文件、补充文档。但所有决策层的工作------产品边界怎么定、字段语义对不对、页面交互顺不顺、AI 输出是否可控------都是人做的。
所以分工其实是:
| 人负责 | AI 负责 |
|---|---|
| 产品方向判断 | 代码生成 |
| 功能边界定义 | 数据结构落地 |
| 体验验收 | 文件修改 |
| 决策和取舍 | 文档编写 |
| 质量把关 | 测试辅助 |
AI 不是替代者,它是一个高强度协作者。
Vibe Coding 改变了什么
它改变的不是「代码怎么写」,而是「从想到做之间的距离」。
以前一个想法从脑子里到上线,中间隔着搭框架、写接口、做页面、调数据库、部署上线------每件事都需要时间,而且切换上下文本身就很耗精力。
现在这个过程被压缩了。你可以先快速出一个版本,跑起来看看哪里不对,然后继续迭代。节奏从「先想清楚再做」变成了「先做出来,再看哪里不对,然后继续推」。
适合谁、不适合谁
适合这样的人:
- 有产品判断力,知道自己想要什么
- 能清晰表达需求(口语化就行,不需要技术术语)
- 愿意 review AI 的产出,不盲目信任
- 有一定的技术基础,能判断方案是否合理
不适合这样的人:
- 完全没有技术背景(仍然需要能判断方案质量)
- 不能清晰描述需求(AI 猜不到你在想什么)
- 不愿意看 AI 写的代码(信任但不验证,迟早出问题)

十、结语
「一定能成」是我第一次完整尝试 vibe coding 的产品。
它不是一个 demo。它有用户端(uni-app/H5)、有业务 API(Koa + MySQL)、有后台管理(Vue 3 + Element Plus)、有 AI 集成(DeepSeek)、有完整的测试用例(XMind)、有部署配置。
从一个想法到这些东西全部落地,如果用传统方式一个人做,我可能需要两个月,而且中间很容易因为某个环节卡住而放弃。
Vibe coding 把这段路走通了。
最大的收获不是「AI 帮我写了多少代码」,而是我第一次感受到:当想法可以被快速实现、验证和修改时,做产品的节奏会完全不同。
以前很多想法会停在脑子里------因为一想到要搭架构、写接口、做页面、调数据库,就开始犹豫。现在更像是:先做出来,再看它哪里不对,然后继续往前推。
不是代码变得不重要了,而是从想法到代码之间的阻力变小了。
而当阻力变小,一个人也可以更快地靠近自己真正想做的东西。
「一定能成」------这句话是给用户的,也是给自己的。
附录 A:常用 Prompt 示例
以下是在这个项目中实际使用过的 prompt 风格,供参考:
场景 1:提新需求
「我想加一个功能:用户进入『我的』页面后,可以看到自己的打卡统计------连续打卡天数、总打卡次数、总完成率。数据从 checkins 表统计。帮我设计接口和前端展示。」
场景 2:改现有功能
「现在打卡页的任务列表是上下滑动的,但我希望把已完成的任务自动归到底部,未完成的保持在上面,已完成的按完成时间倒序排列。只改前端,不改后端接口。」
场景 3:修 Bug
「创建计划时,如果用户填的 daily_time 是 0(表示没有固定时间),AI 生成的计划里 task 的 time_label 字段是 null,前端展示就崩了。帮我修一下------让 time_label 为 null 时前端显示『灵活安排』。」
场景 4:加数据库字段
「plans 表里没有记录计划总天数的字段,现在需要加一个 total_days。注意迁移脚本要是幂等的,已经存在的计划要补上这个值。」
附录 B:数据表速览
| 表 | 行数(参考) | 核心字段数 | 用途 |
|---|---|---|---|
users |
少 | 15+ | 用户信息 |
goal_evaluations |
少 | 20+ | 目标AI评估 |
plans |
少 | 20+ | 计划主表 |
plan_phases |
少 | 10+ | 计划阶段 |
plan_days |
少 | 10+ | 计划天 |
tasks |
中 | 15+ | 每日任务 |
checkins |
中 | 12+ | 打卡记录 |
coach_feedbacks |
中 | 10+ | AI教练反馈 |
ai_model_logs |
多 | 15+ | AI调用日志 |
system_configs |
少 | 6 | 系统配置 |
holiday_calendars |
中 | 8 | 节假日配置 |
完。