前言
上篇文章对基于 DeepAgents API 搭建的生产级代码助手智能体 DeepAgents Code 进行了源码导读,重点剖析了其客户端与服务端分离的设计模式。理解了整体架构之后,大家应该已经建立起一个宏观认知------但这个认知还不够落地,大家真正关心的是:一个生产级的智能体服务,它的服务端核心到底长什么样?
在 DeepAgents Code 这个 CLI 智能体项目中,智能体核心服务(Agent Server) 的设计与实现是整个系统的重中之重。得益于 DeepAgents SDK 提供的标准化 API,开发这样一个 Agent Server 的工作变得结构清晰,便于理解。不过一个生产环境中的工业级项目还是有很多的开发技巧------如何切换大模型?如何执行代码命令?如何进行多智能体开发?等都是必须考虑的问题。
今天这篇文章,笔者就带大家深入 DeepAgents Code 项目的 Agent Server 模块,看它的核心实现与设计思路。
在正式进入代码之前,先和大家分享一个高效的源码阅读方法:不要一上来就逐文件逐行啃代码,那样只会迷失在细节里。 更好的路径是------先思考"一个生产级智能体应该具备哪些功能、采用怎样的架构",然后实际试用一下 DeepAgents Code 智能体,带着真实的体感和疑问,再去探究"DeepAgents Code 究竟是如何实现这些功能的"。带着问题读源码,每一行代码都会变得有迹可循。
一、DeepAgents Code Agent Server核心设计
DeepAgents Code Agent Server 的核心源码位于项目目录下的 agent.py 文件中。在笔者看来,一个真正生产级别的智能体项目,至少要解决好以下四个核心问题:
- 大模型的接入与切换:如何对接不同模型提供商?如何在不中断服务的前提下动态切换模型?
- 工具函数的调用:如何定义、注册、调用工具?如何保证工具执行的安全性与可控性?
- 会话记忆的存储复用:用户的对话历史和状态如何跨轮次持久化?如何实现跨会话的记忆共享?
- 多智能体系统的编排:当单一智能体能力不足时,如何通过子智能体委派来扩展能力边界?
DeepAgents Code 基于DeepAgents API 的 create_deep_agent核心函数,通过其中间件机制、工具函数机制和子智能体机制等核心机制实现了上述的各种功能。
下图是 DeepAgents Code 智能体服务部分核心模块的结构关系图。在 agent.py 中,DeepAgent Code通过自定义的 create_cli_agent 函数完成了这一切的整合------大家先有个整体印象,接下来笔者会逐个模块展开讲解:
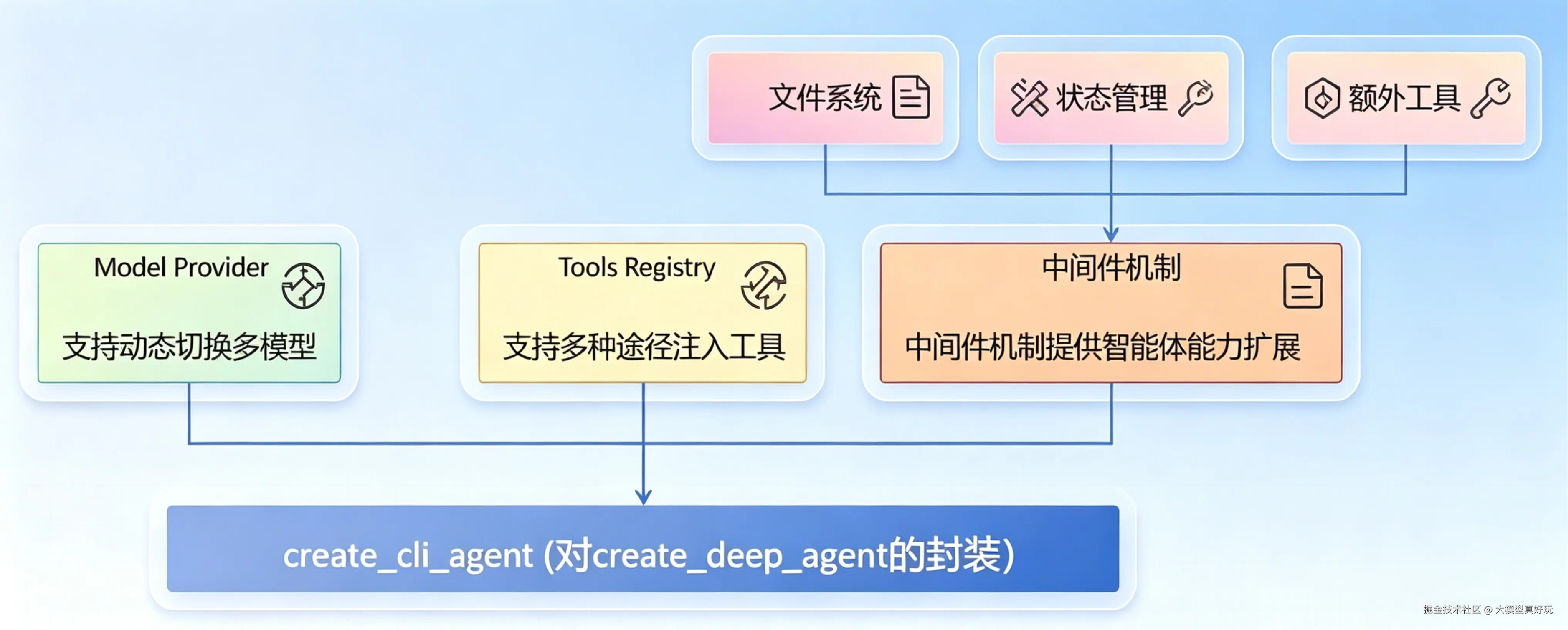
从上图可以清晰地看到,借助 DeepAgents API 的标准化能力,DeepAgents Code 的功能模块划分非常干净------每一层各司其职,互不越界。这正是优秀架构的魅力所在!
二、 DeepAgents Code Agent Server 核心模块讲解
有了宏观认知之后,接下来笔者将深入各个核心模块,逐一拆解它们的实现原理与技巧。
2.1 Model Provider: 模型服务
智能体最基础的能力就是接入大模型。DeepAgents Code 同样通过 create_deep_agent 的 model 参数传入模型实例,agent.py中相关代码如下:
python
agent = create_deep_agent(
model=model,
system_prompt=system_prompt,
tools=tools,
backend=composite_backend,
middleware=agent_middleware,
interrupt_on=interrupt_on,
context_schema=CLIContextSchema,
checkpointer=checkpointer,
subagents=all_subagents or None,
name=_sanitize_agent_message_name(assistant_id),
).with_config(config)model 参数传模型,这是 LangChain 最标准的用法之一,相信大家已经非常熟悉。但很多读者可能会产生一个疑问:在像 DeepAgents Code 这样的生产级 CLI 工具中,用户经常需要在不重启会话的情况下动态切换模型(比如从 GPT-4 切到 Claude 3.5),这部分是如何实现的? 从上面的代码看,模型似乎在一开始就"写死"了呀?
这里 DeepAgents Code 运用了一个非常巧妙的设计,核心思路分为两步:
第一步:通过上下文(Context)传递模型切换指令
大家注意 create_deep_agent 中的一个关键参数 context_schema=CLIContextSchema。这个参数定义了智能体运行时的动态上下文结构,其定义如下(位于 _cli_context.py):
python
class CLIContext(TypedDict, total=False):
model: str | None
"""Model spec to swap at runtime (e.g. 'provider:model')."""
model_params: dict[str, Any]
"""Invocation params (e.g. temperature, max_tokens) to merge."""
effective_model: str | None
"""Resolved provider:model spec actually in use."""
auto_approve: bool在智能体运行时,比如通过 agent.stream() 执行时,可以在 context 参数中携带用户指定的模型(代码位于 app.py):
python
context=CLIContext(
model=self._model_override,
model_params=self._model_params_override or {},
...
)这个 context 随后在 textual_adapter.py 中被传入 agent.astream() 调用,从而将"想切换到的目标模型"传递给执行层:
python
async for chunk in agent.astream(
stream_input,
stream_mode=["messages", "updates"],
subgraphs=True,
config=config,
context=context,
durability="exit",
):第二步:通过ConfigurableMiddleware中间件在运行时替换模型
仅有上下文传递还不够------真正负责"在模型调用前一刻执行替换"的,是 DeepAgents Code 自定义的 ConfigurableModelMiddleware 中间件(位于 configurable_model.py):
python
class ConfigurableModelMiddleware(AgentMiddleware):
"""Swap the model or per-call settings from `runtime.context`.
......
"""
def wrap_model_call( # noqa: PLR6301
self,
request: ModelRequest,
handler: Callable[[ModelRequest], ModelResponse],
) -> ModelResponse:该中间件通过 wrap_model_call 钩子在每次模型调用前拦截请求。其内部的核心逻辑包括:
- 从
runtime.context中读取要切换的模型; - 通过
model_matches_spec判断当前使用的模型是否与目标模型匹配; - 若不匹配,则调用
create_model()动态创建新模型实例; - 合并
model_params参数(如 temperature、max_tokens 等); - 跨提供商切换时自动清理不兼容的配置(比如从 Anthropic 切换到 OpenAI 时自动移除
cache_control相关参数); - 最后更新系统提示中的
### Model Identity部分,让新模型"知晓"自己的身份。
这套设计流程充分运用了 LangChain 的运行时上下文(Runtime Context) 与中间件(Middleware) 机制,实现了"模型切换不中断会话、无需重启服务"的丝滑体验。对中间件机制还不太熟悉的读者,可以回顾笔者之前的文章 LangChain 1.0 高阶特性。
2.2 Tool Registry:三种工具来源的统一管理
工具是智能体的"手脚",DeepAgents Code 的工具来源可以划分为以下三类:
| 来源 | 说明 | 典型工具 |
|---|---|---|
| 内置工具 | 硬编码在代码中的基础工具 | fetch_url、web_search、get_current_thread_id |
| MCP 工具 | 通过 MCP 协议从远程服务加载 | 用户自定义的 MCP 服务器工具 |
| 中间件注入工具 | DeepAgents SDK 运行时自动注入 | execute、read_file、write_file、edit_file |
内置工具 定义在 tools.py 文件中,包含 fetch_url(抓取网页内容)、web_search(网络搜索)和 get_current_thread_id(获取当前会话 ID)三个基础工具。
MCP 工具 通过 mcp_tools.py 实现。用户接入 MCP 服务后,DeepAgents Code 会从 MCP 服务端解析可用的工具列表并注入智能体。关于 MCP 的具体使用方式,大家可以参考笔者之前的文章 LangChain 1.0 高阶特性。
中间件注入工具 是三类工具中最为丰富的一类。笔者在之前的文章 LangChain DeepAgents 速通指南(四)------ FileSystem中间件:让AI Agent拥有系统级记忆管理能力 中曾提到,FileSystemMiddleware 会自动注入 ls、read_file、write_file、edit_file 等文件操作工具。而在 DeepAgents Code 中,除了文件系统中间件,还集成了代码执行中间件等其他组件,共同注入了诸如 execute(执行 Shell 命令)等能力。
这里有必要提及一下 get_current_thread_id 这个看似简单却很有意义的工具函数。它的使用场景主要有两个:
- LangSmith 追踪关联 :LangSmith 是 LangChain 的可观测性平台,通过
thread_id关联同一会话的所有 Trace。当智能体在运行过程中需要调用 LangSmith API(比如上报自定义指标、查询历史 Trace)时,它需要知道"我是谁"------这个工具让智能体可以主动获取thread_id,而非被动等待注入。 - MCP 工具集成 :某些 MCP 工具可能需要
thread_id来关联上下文。例如,一个外部记忆工具需要知道当前会话标识才能存取对应的状态数据。
这个设计的精妙之处在于:把"获取自身上下文信息"这件事从系统提示或工具参数的静态注入中解耦出来,变成一个可主动调用的工具。 智能体"按需获取"而非"被动接收",体现了更灵活的设计哲学。
2.3 Subagents:多智能体机制
笔者在之前的文章 LangChain DeepAgents 速通指南(六)------ DeepAgents SubAgent 子智能体机制 中已经详细介绍过 DeepAgents SDK 的子智能体机制。其核心思想是:通过 task 工具,主智能体可以将复杂任务委派给专门的子智能体执行,从而避免上下文过长、职责不清等问题。
DeepAgents Code 充分利用了 DeepAgents SDK 的这一原生能力,相关代码位于 subagents.py。用户可以在 agents_dir/{subagent_name}/AGENTS.md 中定义子智能体的能力描述,DeepAgents Code 在创建主智能体会自动将这些本地自定义的这些能力描述构建为对应的子智能体,并添加到 subagents 参数中。
除了本地自定义的子智能体,在 agent.py 中我们还可以看到如下代码:
ini
all_subagents: list[SubAgent | CompiledSubAgent | AsyncSubAgent] = [
*custom_subagents,
*(async_subagents or []),
]其中的 async_subagents 是在 config.toml 中配置的、部署在远程平台上的智能体服务。这意味着 DeepAgents Code 的子智能体体系同时考虑了两种场景:
- 本地自定义:用户可以在本地通过 Markdown 文件随时定义新的子智能体;
- 远程复用:用户也可以接入部署在远程平台上的智能体服务,实现能力的远程共享。
这种"本地定义 + 远程复用"的设计既保证了灵活性,又兼顾了扩展性,非常值得借鉴。
三、DeepAgents Code 中间件能力扩展
LangChain 1.0 版本引入的中间件(Middleware)机制,是整个LangChain智能体体系框架中最具工程价值的能力没有之一。在前面的系列文章中,大家已经看到 DeepAgents SDK 正是通过一系列中间件获得了任务规划、工具选择调用、文件系统操作等核心能力。DeepAgents Code 同样在此基础上做了大量扩展------甚至可以说,DeepAgents Code 中相当一部分代码都是在定义和组装中间件,这足以说明中间件在LangChain智能体开发体系中的地位。
下面笔者就为大家逐一拆解 DeepAgents Code 中几个代表性的中间件,看看它们各自解决了什么问题、又是如何巧妙实现的。
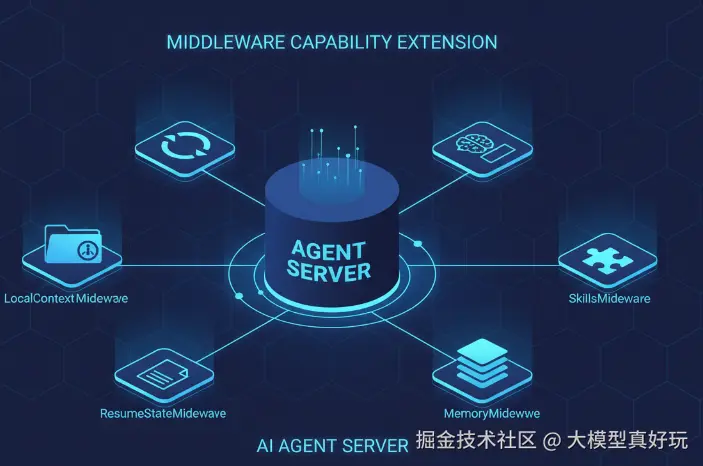
3.1 LocalContextMiddleware:让智能体更懂项目
LocalContextMiddleware的设计目的是负责向智能体注入本地环境上下文,让它"知道"自己当前在哪个项目中工作,而非一个"对项目一无所知"的通用助手。该中间件定义在 local_context.py 中,核心机制如下:
在每次模型调用前(before_model 钩子),中间件通过执行 Bash 检测脚本自动收集当前项目的环境信息,包括但不限于:
- Git 状态:当前分支、是否有未提交的更改、远程仓库信息;
- 项目结构:目录布局、关键文件是否存在;
- 包管理器类型:检测项目使用的是 npm、pip、cargo 还是其他工具。
这些信息在首次交互时自动检测,并在每次总结事件后增量更新,检测结果会持久化存储在智能体状态中。每次模型调用时,中间件会将当前环境快照附加到系统提示中。
3.2 ResumeStateMiddleware:会话恢复的额外助手
当用户中途关闭终端、之后通过 /threads 命令恢复之前的会话时,需要解决两个棘手的问题:
- 模型信息丢失 :LangGraph 检查点中只保存了消息记录,却没有记录"这些消息是哪个模型生成的"。假如原会话使用的是上下文窗口较大的模型(如
gpt-4o),恢复时却使用了默认的qwen2.5-72b,就可能因上下文窗口不足而导致截断,严重影响会话连续性。 - Token 计数丢失:界面状态栏需要显示当前会话的 Token 用量,但检查点中没有存储这个数据。重新计算需要遍历全部历史消息,性能开销大且不精确。
DeepAgents Code 在 resume_state.py 中定义了 ResumeStateMiddleware 来解决上述问题。它在每次模型调用完成后的 after_model 钩子中,提取本次调用的 Token 用量和当前模型信息,写入一个名为 ResumeState 的扩展状态:
python
class ResumeState(AgentState):
"""Extends agent state with per-checkpoint facts restored on resume."""
_context_tokens: Annotated[NotRequired[int], PrivateStateAttr]
"""Total context tokens from the model's last usage_metadata."""
_model_spec: Annotated[NotRequired[str], PrivateStateAttr]
"""provider:model spec effectively in use for the latest turn."""ResumeState 会随messages一起持久化到数据库中。当用户下次恢复会话时,中间件从检查点中还原 _context_tokens 、 _model_spec和messages,实现会话状态的无损恢复------模型一致、Token 计数准确,消息记录完全,用户感知不到任何中断。
3.3 MemoryMiddleware:跨会话的长期记忆
MemoryMiddleware 负责从 AGENTS.md 文件加载长期记忆并将其注入系统提示,让智能体在跨会话的场景下依然能保持上下文连贯性。(官方文档可参考:docs.langchain.com/oss/python/...)
DeepAgents Code 支持使用
AGENTS.md文件来定义智能体的持久化行为指令 。需要注意区分:这里的AGENTS.md是针对主智能体的全局记忆,而前文子智能体中提到的AGENTS.md则是放在特定子智能体目录下的专属定义------二者层级不同,但机制相通。
该中间件定义在 memory.py 中,其核心逻辑在 before_model 钩子中执行:
- 从配置的文件系统路径(包括用户级
~/.deepagents/和项目级.deepagents/)读取AGENTS.md文件内容; - 剥离 Markdown 中的 HTML 注释(这些注释往往用于开发者备注,不应暴露给模型);
- 将处理后的内容包装成
<agent_memory>标签,注入到 DeepAgents Code 的系统提示中。
DeepAgents Code 这种"文件即记忆"的设计让用户可以像编辑文档一样调整智能体的长期行为,无需修改任何代码。记忆内容跨会话生效,真正实现了"一次设定,处处生效"。
3.4 SkillsMiddleware: 技能系统的按需加载
技能(Skill)已成为当今智能体能力的基石。DeepAgents Code 中的 SkillsMiddleware 负责管理整个技能系统,其最大的特色是渐进式披露(Progressive Disclosure) 策略------先展示技能概览,用户显式调用时才加载完整指令,避免系统提示被海量技能详情撑爆。
该中间件的 before_model 钩子执行以下流程:
- 从多个目录(内置技能、用户级
~/.deepagents/<agent>/skills/、项目级.deepagents/skills/)扫描所有SKILL.md文件; - 解析每个文件的 YAML Frontmatter,提取技能名称、描述和触发条件;
- 构建技能列表摘要,按以下格式注入系统提示:
python
Available skills:
- /deploy: Deploy application to production
- /analyze: Analyze code quality当用户通过 /skill_name 显式调用某个技能时,中间件才从对应的 SKILL.md 中读取完整的指令内容并注入上下文------这就是"按需加载"的精髓所在。
3.5 FileSystemBackend、LocalShellBackend等:多优先级后端机制
在笔者之前的文章LangChain DeepAgents 速通指南(四)------ FileSystem中间件:让AI Agent拥有系统级记忆管理能力 笔者讲解过DeepAgents SDK内置的FileSystemMiddleware中间件,该中间件会自动注入 ls、read_file、write_file、edit_file 等文件操作工具,为 DeepAgents Code 提供最基础的文件系统交互能力。
在理解FileSystemMiddleware的过程中,大家也学习到了backend参数定义智能体的后端依赖。在agent.py中,DeepAgents Code 按照创建逻辑优先级依次尝试三种后端:
1. 远程沙箱模式(最高优先级)
当 sandbox 参数不为 None 时,直接使用远程沙箱后端(如 ModalSandbox、DaytonaSandbox)。此时所有文件操作和 Shell 执行均由远程沙箱提供,本地不创建任何 Backend。适用于需要隔离执行环境的场景,如运行不可信代码或需要访问云端资源的任务。
2. 本地 Shell 模式(默认)
当 enable_shell=True 且未配置沙箱时,创建 LocalShellBackend。它同时提供文件读写和 Shell 命令执行能力,通过 env 参数注入精心策划的环境变量(如 LANGSMITH_PROJECT),并通过 inherit_env=False 避免重复继承主进程环境,保证环境干净可控。这是本地开发的默认模式------DeepAgents Code 执行 Python 代码时,本质上就是通过这个 Backend 中的 execute 工具调用 python 命令来运行编写的 .py 文件。
3. 纯文件系统模式(受限)
当 enable_shell=False 时,退化为 FilesystemBackend,仅提供文件读写能力,不执行任何 Shell 命令。适用于"只需编辑文件、无需运行命令"的场景,安全性更高。
这三种模式的切换本质上是 能力降级 策略------沙箱 > Shell + 文件 > 纯文件。每个 Backend 都实现了统一的 BackendProtocol 接口,中间件层不关心具体实现,只通过统一接口调用。这种策略模式让 DeepAgents Code 可以在不同的安全级别与执行环境之间无缝切换,极大地增强了系统的适应能力。
以上就是本文的全部内容。到这里,大家应该对 DeepAgents Code 项目的智能体服务核心层有了全面的了解。关于DeepAgents Code 大家如果不想登录github下载的话可关注笔者的同名微信公众号大模型真好玩 ,每期分享涉及的代码均可在公众号私信: LangChain智能体开发免费获取。
四、总结
本篇文章笔者对 DeepAgents Code Agent Server 的核心模块进行了全面剖析。从运行时动态模型切换 的设计,到三类工具的统一管理 ,再到子智能体的双轨委派机制 ,每个模块都在解答生产级智能体必须直面的问题。而中间件机制更是将智能体能力扩展发挥到了极致:通过 LocalContextMiddleware 实现环境感知,通过 ResumeStateMiddleware 实现会话无损恢复,通过 MemoryMiddleware 赋予跨会话长期记忆,FileSystemMiddleware等中间件配合三种 Backend 的灵活切换,保障了不同安全级别的执行环境。
读到这里,大家应该能体会到:DeepAgents Code 并非对 DeepAgents API 的简单堆砌,而是一套精心设计的工程体系。 每一条中间件、每一层抽象背后,都有真实的工程约束在驱动。
在笔者的日常开发经验中,状态管理与记忆机制始终是智能体开发最核心也最棘手的环节。下一篇文章,笔者将专门深入 DeepAgents Code 的状态管理模块,解析其检查点机制、记忆分层与状态迁移设计,大家敬请期待~
本系列相关内容均列于笔者的专栏《深入浅出LangChain&LangGraph AI Agent 智能体开发》,该专栏适合所有对智能体开发感兴趣的学习者,无论之前是否接触过 LangChain。该专栏基于笔者在实际项目中的深度使用经验,系统讲解了使用LangChain/LangGraph如何开发智能体,目前已更新 47 讲,并持续补充实战与拓展内容。欢迎感兴趣的同学关注笔者的掘金账号与专栏,也可关注笔者的同名微信公众号大模型真好玩 ,每期分享涉及的代码均可在公众号私信: LangChain智能体开发免费获取。