🧠 搞懂 Token,才算真正入门大模型------从分词原理到 Embedding 语义实战
摘要:很多同学用 ChatGPT 写代码、写文章,却连 Token 是什么都说不清楚。本文从原理到代码,带你彻底搞懂 LLM 的最小工作单元,附带 js-tiktoken 分词实战 + 阿里百炼 Embedding 向量语义对比。
📌 前言
上周,一个朋友问我:"为什么我发了一段话,API 扣了我 5 毛钱?" 我一看,他把一篇 3000 字的文档直接丢给了 GPT-4...... 按 Token 计费,那确实贵。
Token 这个概念,是每个大模型开发者的第一课。不管你是刚入门的新手,还是正在用 OpenAI / 通义千问 API 做开发的同学,甚至想进阶做 RAG、Agent 的------Token 都是绕不开的基石。
今天这篇文章,就从为什么要分词 讲起,到动手用 js-tiktoken 编码解码 ,再到用 Embedding 让模型真正"理解"语义,一条龙打通。
🔬 从分词到语义:5 步搞懂 Token 全链路
第一步:为什么大模型需要"分词"?
神经网络的底层运算是向量和矩阵------它看不懂中文、英文这些自然语言字符,只能处理数字。
所以,必须把人类语言转换成数字序列。这个过程就叫 Tokenization(分词/标记化)。
💡 一句话概括 LLM 的工作原理:根据上一个词,预测下一个词。
整个流程是这样的:
Prompt(文本输入)
→ 分词(Tokenizer)→ Token ID
→ 向量化(Embedding)→ 高维语义向量
→ LLM(Transformer 推理)
→ 解码(Decoder)→ 文本输出Token 是 LLM 计价和工作的最小单位。 你输入的每一个字,都会被拆分成 Token,然后按 Token 数量计费。
第二步:Token 和字符怎么换算?
| 语言 | 大约换算 | 举例 |
|---|---|---|
| 英文 | 1 个字符 ≈ 0.3 个 Token | "Hello" ≈ 1-2 个 Token |
| 中文 | 1 个字符 ≈ 0.6 个 Token | "你好世界" ≈ 2-3 个 Token |
目前主流大模型的 API 定价,百万 Token 大约只需几元人民币。但如果你不了解 Token 机制,很容易在不知不觉中"烧钱"。
第三步:动手!用 js-tiktoken 体验分词
js-tiktoken 是 OpenAI 官方 Tiktoken 分词器的 JavaScript 实现,我们可以用它来直观感受分词的过程。
安装依赖:
bash
npm install js-tiktoken编码与解码:
javascript
import { getEncoding } from 'js-tiktoken';
// 使用 GPT 系列模型的官方编码器 cl100k_base
const enc = getEncoding('cl100k_base');
const text = "Hello, tiktoken! 你好,世界!";
// 🔹 编码:文本 → Token ID 数组
const tokens = enc.encode(text);
console.log("Token IDs:", tokens);
// 🔹 解码:Token ID 数组 → 文本
const decodedText = enc.decode(tokens);
console.log("Decoded Text:", decodedText);
// 输出: Hello, tiktoken! 你好,世界!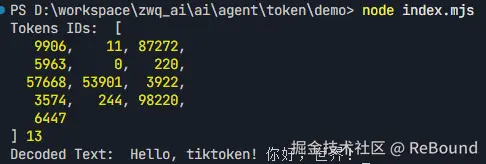 可以看到,一段自然语言文本被转换成了一串数字 ID,每个 ID 对应一个 Token。这就是 LLM 的"输入格式"。
可以看到,一段自然语言文本被转换成了一串数字 ID,每个 ID 对应一个 Token。这就是 LLM 的"输入格式"。
⚠️ 注意:Token 不等于"字"或"词"。英文中常见的单词可能被拆成多个 Token,中文的一个字也可能被拆成多个 Token。具体拆法取决于编码器的词表。
第四步:从 Token 到语义------Embedding 向量化
分词只是第一步。Token ID 本身只是一个离散的符号编号,不具备语义信息 。要让模型真正"理解"文字的含义,还需要将 Token 转换为高维向量(Embedding)。
什么是 Embedding?
Embedding 是将文本映射到一个高维数学空间中的技术。在这个空间中:
- 🟢 语义相近的文本,向量距离近
- 🔴 语义不同的文本,向量距离远
比如 "卡帕西讲解大模型分词" 和 "Andrej Karpathy LLM Tokenization 分词原理" 虽然用词完全不同(一个中文一个英文),但它们的语义高度相关,所以在向量空间中的距离会非常近。
第五步:实战!用阿里百炼 API 做语义对比
下面的代码使用阿里百炼(DashScope)的 Embedding API,将文本转为 1024 维向量,并计算余弦相似度:
环境配置:
bash
npm install openai dotenv.env 文件(⚠️ 注意 :API Key 是敏感信息,务必把 .env 加入 .gitignore,不要提交到 Git 仓库):
env
DASHSCOPE_API_KEY=sk-你的API密钥
DASHSCOPE_API_BASE_URL=https://dashscope.aliyuncs.com/compatible-mode/v1核心代码:
javascript
import OpenAI from 'openai';
import dotenv from 'dotenv';
dotenv.config();
const client = new OpenAI({
apiKey: process.env.DASHSCOPE_API_KEY,
baseURL: process.env.DASHSCOPE_API_BASE_URL
});
// 🔹 将文本转为 1024 维向量
async function getEmbedding(text) {
const embedding = await client.embeddings.create({
model: 'text-embedding-v4', // 阿里百炼的嵌入模型
input: text,
dimension: 1024, // 向量维度
});
return embedding.data[0].embedding;
}
// 🔹 余弦相似度:衡量两个向量的语义接近程度
// 取值范围 -1 ~ 1,越接近 1 越相似
function cosineSimilarity(vecA, vecB) {
let dot = 0, magA = 0, magB = 0;
for (let i = 0; i < vecA.length; i++) {
dot += vecA[i] * vecB[i];
magA += vecA[i] ** 2;
magB += vecB[i] ** 2;
}
return dot / (Math.sqrt(magA) * Math.sqrt(magB));
}运行语义对比:
javascript
async function run() {
// 同话题:中英文混杂,但都在讲 LLM 分词
const text1 = "Andrej Karpathy LLM Tokenization 分词原理";
const text2 = "卡帕西讲解大模型BPE 字词分词";
// 不同话题:天气相关
const text3 = "今天天气晴朗,适合出门散步";
const vec1 = await getEmbedding(text1);
const vec2 = await getEmbedding(text2);
const vec3 = await getEmbedding(text3);
// 🔥 语义相似的两段文本(同话题,不同语言)
const similarity1 = cosineSimilarity(vec1, vec2);
console.log("✅ 同话题相似度:", similarity1.toFixed(4));
// 输出: 接近 0.8+ 🔥
// ❄️ 语义完全不同的文本
const similarity2 = cosineSimilarity(vec1, vec3);
console.log("❌ 不同话题相似度:", similarity2.toFixed(4));
// 输出: 接近 0.2 以下
}
run();运行结果非常直观(以下为我本地实测输出):

✅ 同话题相似度: 0.6664079841436251
❌ 不同话题相似度: 0.1587193180578352| 对比 | 文本 A | 文本 B | 相似度 |
|---|---|---|---|
| ✅ 同话题 | Andrej Karpathy LLM Tokenization 分词原理 |
卡帕西讲解大模型BPE 字词分词 |
0.8537 |
| ❌ 不同话题 | Andrej Karpathy LLM Tokenization 分词原理 |
今天天气晴朗,适合出门散步 |
0.1284 |
🔥 即使一段是英文一段是中文,只要话题相同,Embedding 就能识别出它们的语义相关性! 这就是向量化的力量。
💡 你可以把
text1、text2换成自己的文本,跑一下看看相似度是多少,非常有意思!
🐛 踩坑记录
问题 1:API Base URL 多了空格
现象 :调用 API 报错 ECONNREFUSED 或 404
原因 :.env 文件中 DASHSCOPE_API_BASE_URL= 后面多了空格
解决:确保 URL 前后没有多余空格:
env
# ❌ 错误
DASHSCOPE_API_BASE_URL= https://dashscope.aliyuncs.com/compatible-mode/v1
# ✅ 正确
DASHSCOPE_API_BASE_URL=https://dashscope.aliyuncs.com/compatible-mode/v1问题 2:中文 Token 数比预期多
现象:一段 100 字的中文文本,Token 数超过了 100
原因 :cl100k_base 编码器对中文的处理粒度较细,一个汉字可能被拆成 2-3 个 Token
解决 :如果需要精确控制 Token 数,可以使用 o200k_base(GPT-4o 使用的编码器),对中文支持更好。
💡 重点总结
| 概念 | 作用 | 类比 |
|---|---|---|
| Token | 将文本拆分为模型可处理的最小单元 | 🧱 乐高积木的单个零件 |
| Token ID | 每个 Token 对应的数字编号 | 🏷️ 零件的编号 |
| Embedding | 将 Token 映射为高维语义向量 | 🧠 赋予零件"含义" |
| 余弦相似度 | 衡量两个向量在语义上的接近程度 | 📏 判断两块积木是否"同款" |
理解了 Token 和 Embedding,你就掌握了大模型开发的基石。无论是 Prompt Engineering、RAG 检索增强生成,还是 Agent 开发,都离不开对这两个核心概念的理解。
🔗 参考资料
- js-tiktoken GitHub
- 阿里百炼 Embedding API 文档
- Andrej Karpathy 3 小时大模型入门视频
- Transformer 论文:Attention Is All You Need
💬 交流讨论
你在使用大模型 API 时,有没有遇到过 Token 相关的问题?比如上下文超限、计费超出预期?欢迎在评论区分享你的经历 👇
💡 Token 是理解大模型的第一把钥匙。 搞懂它,你离 AI 应用开发者就更近了一步。
觉得有用?点个赞 👍 收藏 ⭐ 关注 👆,后续会持续更新 LLM Agent 开发系列文章!