大家好,我是大志。
Memory (记忆)几乎是所有 AI Agent 面试都会涉及的核心知识点。从短期记忆、长期记忆,到 Memory Summary、用户画像、记忆召回、记忆压缩,这些问题在面试中都非常高频,也是实际开发中绕不开的内容。
本篇文章我结合自己的学习和项目经验,整理了一份记忆管理 相关的高频面试题。不仅会介绍每个知识点是什么,还会结合实际开发场景,分享生产环境中常见的设计思路,希望能够帮助大家建立完整的 Memory 知识体系。
另外,完整的 AI Agent 面试题文档也已经同步到了 aiflowline.cn,大家可以结合文章一起阅读。
1、什么是短期记忆?
短期记忆指的是 Agent 在一次会话或一次任务执行过程中保存的上下文信息。比如对话消息记录、调用工具记录、工具返回结果,这些都属于短期记忆。
举个例子:
用户:帮我查一下北京今天的天气
助手:北京今天晴,最高温 28 度
用户:那明天呢?用户第二次提问中的"那"指的是北京天气,如果没有短期记忆,LLM 就不知道用户在问什么。
在 LangGraph v1.0 里,短期记忆通常通过 checkpointer 实现。每个线程都有自己的 thread_id,LangGraph 会把如消息记录等状态信息保存下来,下一轮调用时传入相同的 thread_id,就可以获取这些 state 信息,将这些 state 中存储的短期记忆信息传递给 LLM,LLM 就有了记忆。
2、什么是长期记忆?
长期记忆指的是可以跨会话、跨任务长期保存的上下文信息。在长期记忆中可以保存如:用户偏好、用户画像、常用配置、历史决策、项目背景等信息。
比如用户多次提到"我喜欢回答简洁一点",这个信息就适合进入长期记忆。下次用户重新打开一个新会话,LLM 仍然可以根据这个偏好调整回答方式。
短期记忆是某一次会话中的上下文信息,而长期记忆是跨越多轮甚至多次会话,能够被长期保存和重复利用的信息。
在 LangGraph v1.0 里,长期记忆通常通过 Store 实现。checkpointer 负责保存线程内的状态,Store 负责保存跨线程、跨会话的数据。
3、为什么需要记忆系统?
因为 LLM 本身是没有记忆的。每次开始一段新的对话,它都不知道我们是谁,也不知道之前聊过什么。如果没有记忆系统,每次需要重新介绍自己的需求、偏好以及历史对话信息。
有了记忆系统后,Agent 可以拥有以下能力:
- 理解上下文
用户说"继续"、"换一种方式"、"刚才那个方案",因为 LLM 通过记忆信息可以获取到对话记录,就能得知用户指的是什么。
- 减少重复提问
如果 Agent 已经了解用户的技术栈、语言偏好、业务背景,就不需要每次都让用户重新提供。
- 支持复杂任务
在很多 Agent 应用中,任务不是一轮完成的,比如写代码、查资料、分析数据都需要执行多步流程,都需要利用记忆保存中间状态。
- 个性化回答
不同用户的使用习惯不同,有的人要详细的回答,有的人要简略的回答,有的人需要以最通俗的方式去回答,通过长期记忆可以让 Agent 直接按照用户风格个性化回答。
4、为什么不能直接把所有历史消息记录放进 Prompt?
最重要的原因是 LLM 对话的上下文窗口有限。LLM 能接收的 Prompt 长度是有限的。消息记录越来越多后,即使模型支持很长上下文,也不可能无限放到 Prompt 中,将所有历史消息记录都放到 Prompt 中,可能产生以下问题:
- 成本高
Prompt 越长,调用成本越高,响应也越慢。很多历史内容其实对当前问题没有帮助,会浪费大量 Token。
- 噪声多
历史记录里有大量无关信息,LLM 可能被干扰,反而找不到当前问题的重点。
- 容易产生冲突
早期对话内容可能已经过期,比如以前用 MySQL,现在改成 PostgreSQL。如果全部传给 LLM,LLM 可能不知道应该参考哪一条。
- 隐私和安全风险更高
不是所有的对话内容都适合放到 Prompt 中,尤其是涉及隐私性强的内容。
更合理的做法是,将完整记忆信息保存起来,每次对话时,只召回当前任务真正需要的部分。也就是通过摘要、检索、过滤和排序,把相关记忆放进 Prompt,而不是把所有历史消息直接进去。
5、如何设计一个合理的 Memory 架构?
一个比较常见的 Memory 架构,一般会分成四层:
- 短期记忆
保存当前对话的消息、工具调用结果、中间变量等。在 LangGraph v1.0 里,这一层通过 checkpointer 实现。
- 长期记忆
保存跨会话的信息,比如用户偏好、用户画像、项目背景、业务事实等。在 LangGraph v1.0 里,这一层通过 Store 来实现。
- 历史消息检索
当用户发起新请求时,系统需要从历史消息记录中找出相关内容。这里可以用关键词检索、向量检索、标签过滤,也可以组合使用。
- 记忆写入管理
不是所有内容都应该写入记忆。系统要判断哪些信息值得保存,哪些信息应该更新,哪些信息已经过期,哪些信息不能保存。
6、如何实现短期记忆?
短期记忆要做的是保存最近几轮的消息记录和一些中间状态,在下一轮对话中能获取到这些状态信息。如果自己实现短期记忆,可以用 session_id 或 thread_id 作为 key,把消息列表保存到 Redis、数据库。
存储结构如下:
json
{
"thread_id": "user-001-chat-001",
"messages": [
{"role": "user", "content": "帮我查北京天气"},
{"role": "assistant", "content": "北京今天晴"}
]
}下一轮用户继续提问时,再根据 thread_id 取出历史消息,再和提问一起传给 LLM。
在 LangGraph v1.0 中,可以使用 checkpointer 来实现短期记忆。开发时可以用基于内存的 InMemorySaver,生产环境一般会使用基于数据库的版本,如 PostgresSaver。
示例如下:
python
from langgraph.checkpoint.memory import InMemorySaver
from langgraph.graph import StateGraph
checkpointer = InMemorySaver()
app = graph.compile(checkpointer=checkpointer)
config = {
"configurable": {
"thread_id": "user-001-chat-001"
}
}
app.invoke(
{"messages": [{"role": "user", "content": "你好"}]},
config=config,
)同一个 thread_id 再次调用时,LangGraph 会自动恢复之前的状态。如果用 LangChain v1.0 的 create_agent,也是类似思路:
python
from langchain.agents import create_agent
from langgraph.checkpoint.memory import InMemorySaver
checkpointer = InMemorySaver()
agent = create_agent(
model="gpt-5.5",
tools=[],
checkpointer=checkpointer,
)
agent.invoke(
{"messages": [{"role": "user", "content": "我叫张三"}]},
config={"configurable": {"thread_id": "chat-001"}},
)除此之外,短期记忆要注意控制长度。不能无限保存所有历史消息记录,通常会进行内容摘要或只保留最近几轮对话信息。
7、如何实现长期记忆?
长期记忆要做的是跨会话保存记忆信息,因此长期记忆不能依赖 thread_id 等会话 ID,所以长期记忆一般要绑定到 user_id、tenant_id 或业务对象 ID 上。
例如:
python
user_id = u_001
namespace = memories/u_001保存的信息可能是:
json
{
"preferred_language": "中文",
"answer_style": "简洁直接",
"tech_stack": ["Python", "LangGraph", "Redis"]
}在 LangGraph v1.0 里,长期记忆通常用 Store 来实现,示例如下:
python
from langgraph.store.memory import InMemoryStore
store = InMemoryStore()
namespace = ("memories", "user-001")
store.put(
namespace,
"preference",
{"answer_style": "简洁直接"},
)
memory = store.get(namespace, "preference")开发时可以用基于内存的 InMemoryStore,生产环境里,Store 后面一般会使用基于数据库的实现,如 PostgresStore。
8、如何实现用户画像?
构建用户画像本质上是把用户在对话中给出的稳定的、有用的信息进行结构化保存。
例如如下的用户画像字段:
json
{
"user_id": "u_001",
"role": "后端开发工程师",
"language": "中文",
"tech_stack": ["Python", "FastAPI", "LangGraph"],
"answer_preference": "先给结论,再解释原因",
"business_context": "正在做企业知识库问答系统"
}用户画像的数据来源一般有以下三种。
- 用户明确说明
例如:"以后都用中文回答""我是 Java 后端"。这种信息可信度比较高,可以直接写入或经过确认后写入。
- 从多轮对话中归纳
比如用户多次要求"别写太复杂",系统可以归纳出用户偏好简洁回答。
- 从业务系统同步
例如用户的角色、部门、权限、购买套餐等,这类信息应该直接从业务系统同步。
实现时要注意两点。
- 画像要结构化
不要只保存一段长文本,否则后面很难检索、更新和判断冲突。
- 画像要可更新
用户偏好会变,比如技术栈会变,回答风格可能也会变。用户画像最好带上更新时间和来源。
json
{
"key": "answer_preference",
"value": "简洁直接",
"source": "user_explicit",
"updated_at": "2026-06-16"
}9、如何实现记忆召回?
记忆召回就是在用户提问时,从记忆信息中匹配与当前问题相关的记忆信息。
常见的记忆召回有三种:
- 规则召回
根据 user_id、memory_type、标签等条件直接查询。例如用户画像、语言偏好、权限信息,这类不需要向量检索,直接按 key 查就行。
- 关键词召回
适合查找包含明确关键词的记忆,比如项目名、产品名、错误码。
- 向量召回
适合语义相似的场景。比如用户问"上次那个接口超时的问题",不一定包含原始记忆里的关键词,但语义接近,可以用 embedding 检索。
实际项目中通常会混合使用:
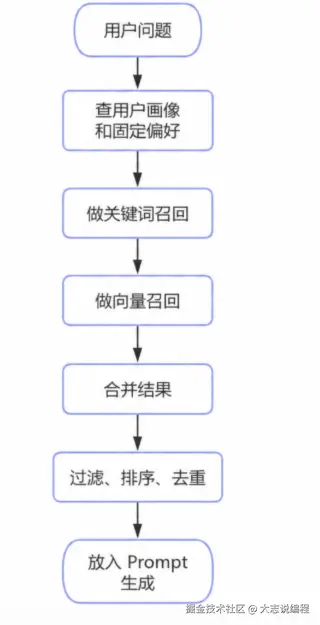
召回后不要直接全部传给 LLM,一般还要做排序,还会考虑相关性、重要性、新旧程度、可信来源、是否和当前任务冲突,最终只选少量最有用的记忆放入 Prompt。
10、如何避免无关记忆被召回?
在使用向量数据库进行相似度检索时,会寻找"语义相似"的内容,但语义相似不代表当前任务需要。比如用户问"Python 内存优化",可能召回到很多历史讨论 Python 的内容,但这些内容对完成当前任务没有任何帮助。
常见的处理方式有以下几种:
- 加过滤条件
召回前先按用户、项目、记忆类型过滤,避免跨用户、跨项目召回。
python
user_id = 当前用户
project_id = 当前项目
memory_type in [preference, fact, summary]- 给记忆打标签
保存时就标好类型,召回时按类型获取,例如:
preference:用户偏好
profile:用户画像
project:项目背景
task:任务摘要
fact:事实信息- 设置检索最小相似度
低于最小相似度的文本直接丢弃。
- 做二次重排
先召回最相关的一批记忆信息,再用 reranker 或 LLM 进行相关性的重排序。
- 限制数量
即使召回了多条记忆信息,也只取最相关的几条。
11、如何做记忆压缩?
当记忆信息达到一定数量时,需要对记忆信息进行压缩,记忆压缩的前提是在不丢掉关键信息的前提下,减少上下文长度和存储成本。
常见压缩方式有以下几种:
- 窗口截断
只保留最近 N 轮对话,适合简单聊天场景。
只保留最近 10 条消息。
更早的消息不直接进入 Prompt。- 摘要压缩
把早期对话总结成一段摘要,替代完整消息。
rust
前 30 轮对话 -> 一段会话摘要
最近 5 轮对话 -> 原文保留- 结构化提取
从对话中提取关键信息,比如用户偏好、项目背景、关键决策,进行结构化存储。
json
{
"preference": "回答要简洁",
"project": "企业知识库问答系统",
"decision": "使用 LangGraph 编排 Agent 流程"
}- 去重合并
如果多条记忆表述的内容相同,那么就对内容进行合并。
- 按重要性保留
将重要的内容保留,将闲聊等不重要内容丢弃。
12、如何做 Memory 摘要?
Memory Summary(记忆摘要)本质上就是利用 LLM 将历史对话压缩成一段更短、更重要的内容,用来代替大量历史消息,从而减少 Token 消耗,同时保留上下文。
比如历史对话如下:
erlang
用户:你好。
AI:你好,有什么可以帮助你?
用户:我叫大志,是一名 Java 开发工程师。
AI:好的。
用户:最近在学习 AI Agent。
AI:不错。
用户:我准备写 LangChain 系列公众号文章。
......
(几十轮聊天)经过摘要之后,可以变成:
用户叫大志,是一名 Java 后端开发工程师,
目前主要学习 AI Agent、LangChain、LangGraph,
正在编写 LangChain 系列公众号文章。只需要摘要传递给 LLM,LLM 就可以快速了解上下文,而不需要再读取几十轮聊天记录。
在实际 Agent 开发中,通常不会每轮对话都做摘要,因为 LLM 总结本身也需要消耗 Token,常见策略包括:
- 按消息数量触发
例如最近消息超过 20 轮,生成一次摘要,这是最常见的方案。
- 按 Token 数量触发
例如历史消息超过 8000 Token,开始生成摘要,相比按轮数,这样做更有利于控制上下文 Token 数量。
- 滑动窗口摘要
保留最近 10 条消息和历史摘要形成如下结构:总结 + 最近消息,这样既能保留长期上下文,又不会丢失最新对话细节,因此也是目前很多 Agent 框架采用的方案。
摘要的生成,通常会调用一次 LLM,让模型总结历史对话,示例如下:
bash
请总结下面的历史聊天内容。
要求:
1、保留用户长期信息
2、保留用户目标
3、保留重要事实
4、删除寒暄内容
5、删除重复信息
6、输出简洁摘要
历史聊天:
{{history}}模型返回:
用户是一名 Java 开发工程师,
目前正在学习 AI Agent,
持续编写 LangChain 系列公众号文章,
希望内容通俗易懂,偏实战。然后将该摘要保存下来,作为后续 Prompt 的一部分。
13、Redis 在记忆体系中的作用是什么?
Redis 在记忆体系里主要适合做高频访问、需要快速返回的热点信息的存储。
常见用途有以下四个:
- 保存会话缓存
比如当前会话的最近消息、临时状态、中间结果。Redis 读写快,适合频繁访问。
- 保存热点记忆
有些长期记忆虽然存放在数据库里,但访问非常频繁,可以缓存到 Redis,减少数据库压力。
- 做过期控制
Redis 天然支持 TTL,适合保存有生命周期的记忆。
- 做分布式锁或任务状态
多个 Agent 实例同时处理同一个用户或任务时,可以用 Redis 控制并发,避免状态被覆盖。
好啦,今天这期 记忆管理 相关的面试题就到这里。后面我会每周至少更新 1 期面试题系列 ,想看后续 【AI Agent 进阶面试题】 的朋友,欢迎关注「大志说编程」!
觉得有用的话,转发给正在面试的小伙伴,咱们下期见~