AI Agent 组成:像人一样思考的智能体
© 2026 by ethan.tan(谭明)· All Rights Reserved · 图解第一版 · 2026.07.02
一句话定位 :AI Agent 的目标,是让 AI 像人一样感知、思考、记忆、行动,自主解决我们的各种问题。
时代判断 :MLLM(多模态大模型)已足够强大,某些领域可达专业级别。结论很朴素------拥抱 AI、拥抱变化。
全局架构图
在展开各层之前,先给出一张全局架构总览------以 MLLM 为中心,把感知、大脑、思考方式、记忆、动作、能力协作、Skill 全部画在一张图上,看清它们如何连接成一个像人一样思考的智能体:
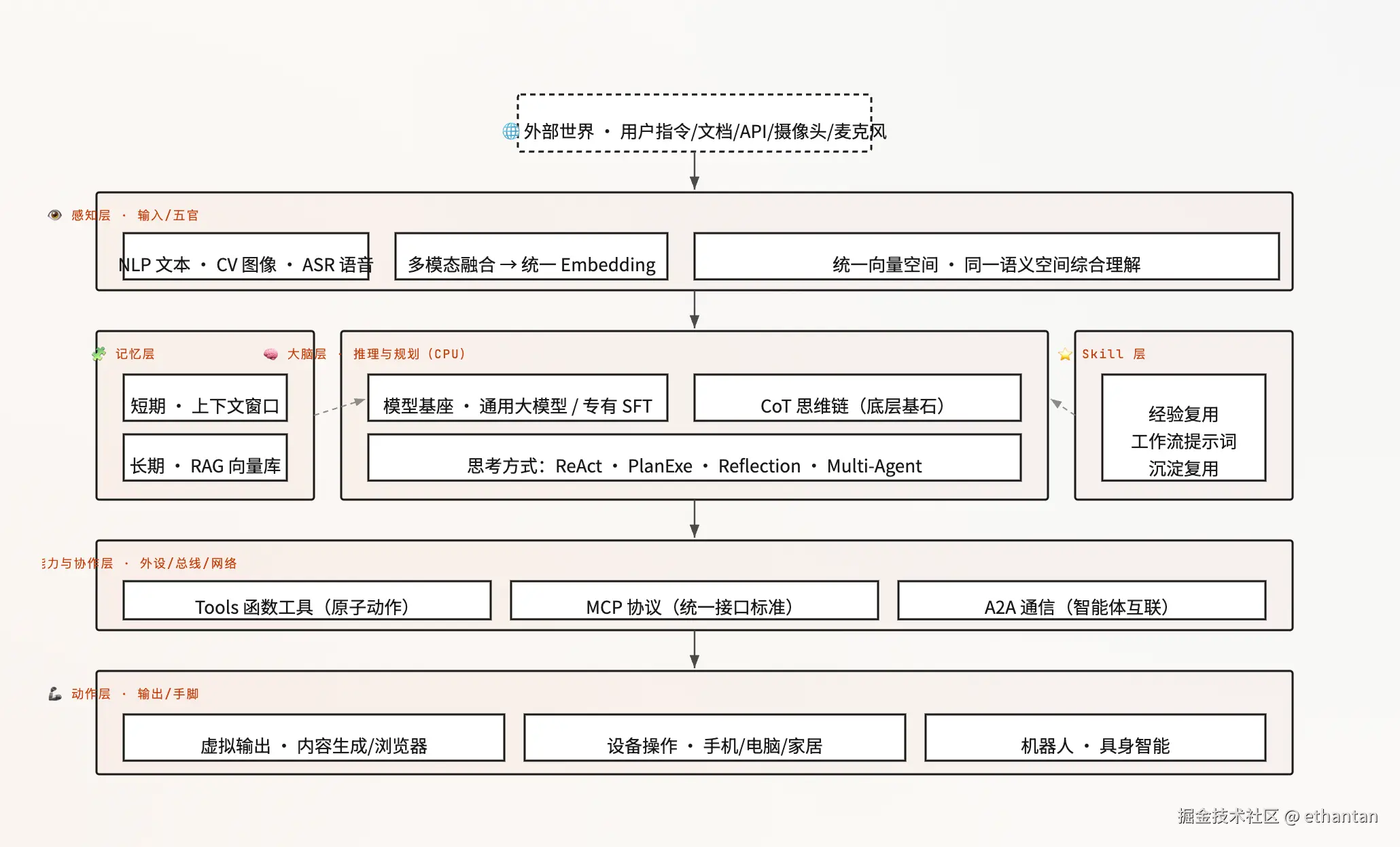
读图指引(从左上到右下、由内到外):
-
中心是大脑:MLLM 作为"CPU",承担推理与规划,是一切的中枢。
-
认知闭环:外部世界 → 感知 → 大脑 → 动作 → 影响世界,动作结果再沉淀进记忆,记忆又反哺大脑------构成持续循环。
-
大脑的两个支撑:一靠"模型基座"提供算力,二靠"思考方式"组织推理与行动的逻辑,CoT 是二者共同的底层基石。
-
记忆横贯:短期↔长期互通,供大脑读写;RAG 解决"知识装不下"。
-
能力协作外接:Tools/MCP/A2A 让大脑能动手、能联网、能与其他 Agent 协同。
-
Skill 注入:把可复用经验固化成技能包,随时注入大脑复用。
-
编排框架托底:LangGraph→LangChain→Deep Agents 三层把上述理念工程化落地。
这张图是全文的"地图"------后面每一章都是对图中某一块的展开拆解。建议先看懂这张总图,再深入各层细节。
目录
- 引言:新计算机组成原理
- 一、感知与动作:输入与输出层
- 二、聪明的大脑:计算与模型基座
- 三、思考方式:控制流
- 四、记忆层:存储与检索
- 五、能力、协作与连接:外设与总线
- 六、Skill:经验的复用
- 七、编排框架落地:从思维到工程
- 八、落地场景:赋能替代,人工兜底
- 结束语
引言:新计算机组成原理
AI Agent 的目标,是让 AI 像人一样感知、思考、记忆、行动 。普通 LLM 是"问一句答一句"的被动工具;Agent 是能自主规划、调用工具、持续记忆、动态调整的主动执行者。差别在于它有"手脚"(动作/工具)、有"记性"(记忆)、有"章法"(思考方式)。
理解 Agent 最好的方式,是把它看成一台**"新计算机"**,同时对照两个参照系:人(模仿对象)和传统计算机(工程载体)。
| 人 | 传统计算机 | AI Agent | 本质 |
|---|---|---|---|
| 眼 / 耳(感官) | 输入设备(键盘/鼠标) | 感知层(NLP/CV/ASR) | 接收外部信息 |
| 手 / 口(肢体与语言) | 输出设备(显示器/打印机) | 动作层(虚拟输出/设备/机器人) | 作用于外部世界 |
| 大脑 | CPU | 聪明的大脑(LLM/MLLM) | 核心计算与推理 |
| 思维方式 / 方法论 | 控制器 / 程序 | 思考方式 | 组织推理与行动的逻辑 |
| 记忆(短期/长期) | 内存 / 硬盘 | 记忆层 | 状态与知识存储 |
| 工具 / 工具箱 | 外设 / 总线 | MCP / Tools | 连接外部工具与系统 |
| 语言 / 协作 | 网络协议 | A2A(Agent to Agent) | 智能体间通信 |
| 专业技能 / 经验 | 软件库 / 经验 | Skill | 经验复用 |
这张表是全文的钥匙:Agent 的每一层都能在人身上找到对应。后面每一章都会回到"人 vs Agent"这条主线。
四模块认知循环:业界主流的理论框架
上述映射有学界与业界的理论背书。主流 LLM Agent 架构综述与"感知-大脑-行动-记忆"四模块框架一脉相承,本文以此为骨架,把"思考方式"独立成章、"动作"并入感知层,扩展为完整结构:
感知环境 → 进行思考 → 采取行动 → 形成记忆 →(利用记忆指导下一轮思考与行动)→ 循环-
感知(Perception) ------Agent 的"五官":从用户指令、文件、数据库、API 返回结果,甚至摄像头/麦克风的原始数据中捕获信息,转化为大脑可理解的结构化信息。
-
大脑(Brain) ------Agent 的"中枢神经系统",核心是 LLM:负责推理(Reasoning)与规划(Planning),理解用户最终意图,将复杂任务分解为可执行子任务。
-
行动(Action) ------Agent 的"手脚":通过调用工具(Tools)与外部世界交互(搜索、计算、代码执行、机器人控制等)。
-
记忆(Memory) ------Agent 学习与进化的关键:短期记忆存当前任务上下文,长期记忆存跨任务的知识、经验与用户偏好。
四模块构成一个持续循环的认知闭环,这也是 Agent 区别于"一次性问答"的根本所在:
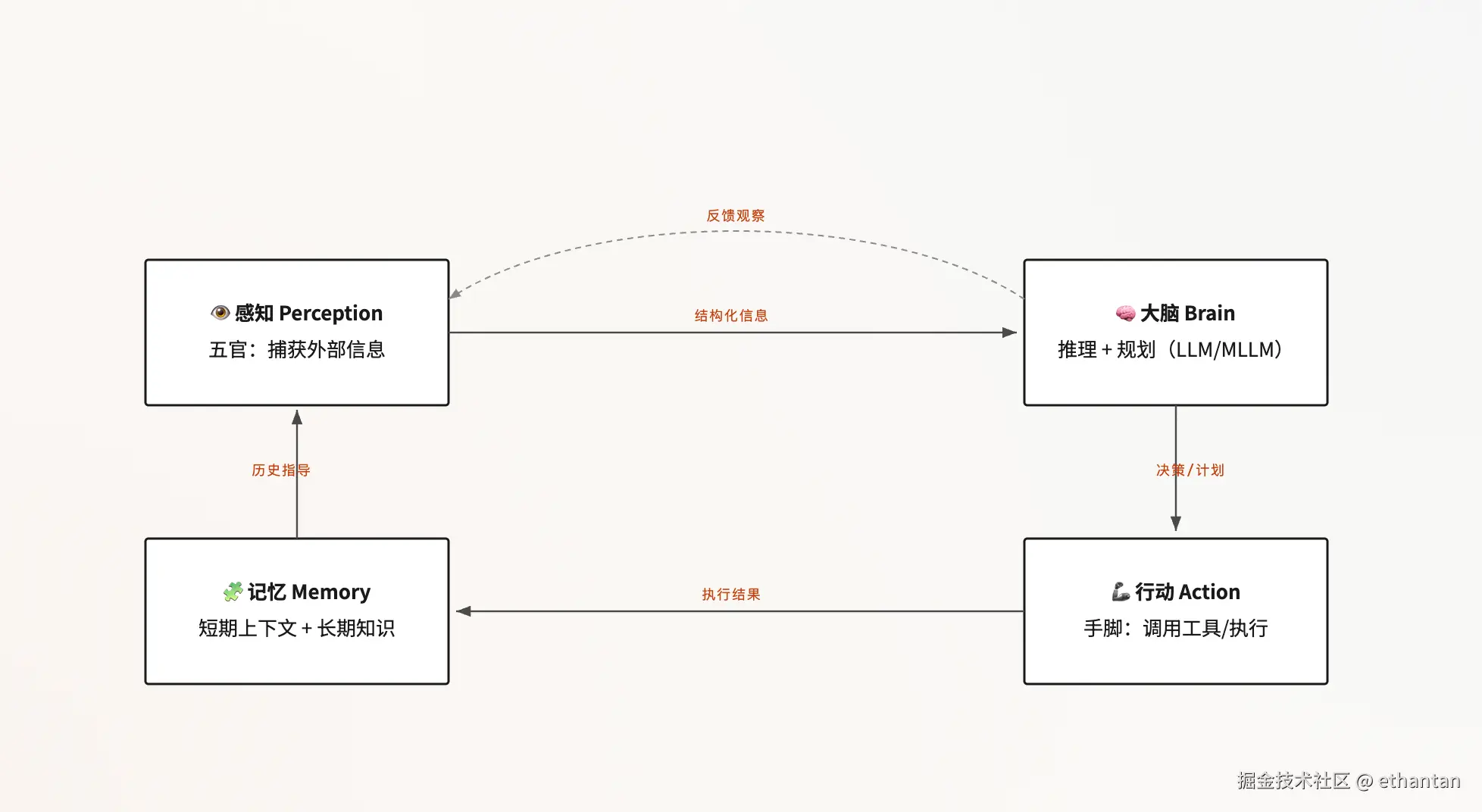
架构演进的本质 :Agent 架构已从"单一模型封装"演进为一套模块化的系统 ,核心思想是借鉴人类认知模式,将能力解耦为既独立又协同的模块。下面以 MLLM 为中心逐层拆解。
一、感知与动作:输入与输出层
人要做事,先要能"感知"环境(看、听、读),再能"动作"产生结果(说、写、操作)。这两层构成 Agent 与世界的交互边界。
1. 感知层(输入)
感知是 Agent 接收外部信息的入口。三类输入模态,正是人的三类感官的机器化:
| 人的感官 | Agent 感知 | 能力 |
|---|---|---|
| 眼睛看 | 视觉(图像/图片输入) | 图像理解、OCR 文档识别 |
| 耳朵听 | 听觉(语音音频输入) | ASR 语音转文字 |
| 读文字/说话 | NLP(自然语言输入) | 文本意图解析,当前最成熟的通道 |
多模态信息的统一表征------感知模块的首要任务,是把异构数据源统一为大脑可处理的形式:
-
信息来源:文本(指令/网页/文档/代码)、图像(图表/照片/UI 截图)、音频(语音/环境声)、视频(图像+音频动态流)、结构化数据(API 的 JSON、数据库表格)。
-
统一编码 :各模态通过专属编码器转换为统一的高维向量(Embeddings),文本用 Transformer、图像用 ViT、音频用 Whisper 等。统一向量让大脑能在同一语义空间中综合理解不同模态。
关键技术与对应:
| 技术 | 对应感官 | 作用 |
|---|---|---|
| NLP | 读/说 | 意图识别、实体提取、情感分析、长文本理解 |
| CV | 看 | UI 操作 Agent 定位按钮/输入框;机器人识别障碍物 |
| ASR | 听 | 语音交互,智能客服/智能家居的关键 |
| 多模态融合 | 综合 | 通过交叉注意力(Cross-Attention)实现跨模态深层关联,产生"1+1>2"效果 |
趋势:多模态融合。一个 MLLM 同时吃下文本、图像、语音,避免多模型拼接的信息损耗。人不会把"看"和"听"拆成两个独立系统,Agent 也不该。
人 vs Agent:人的感官天然融合且带常识;Agent 的多模态仍需刻意拼接,易丢失跨模态关联。
2. 动作层(输出)
Agent 要能"动手做事",按作用对象分三类,能力从虚拟走向实体:
| 人的行动 | Agent 动作 | 能力 |
|---|---|---|
| 写字 / 画画 / 用电脑 | 虚拟输出 | 内容生成(文本/图片/视频/文件)、浏览器自动化 |
| 用手机 / 开关电器 | 设备操作 | 手机/电脑控制、智能家居等硬件操控 |
| 身体劳作 / 操作机械 | 机器人 | 软硬件协同执行实体动作(具身智能) |
三类动作递进展开:
-
虚拟输出:内容生成、浏览器自动化。
-
设备操作:手机/电脑控制、智能家居等硬件操控。
-
机器人:软硬件协同执行实体动作(具身智能)。
工具(Tool):能力的无限扩展
动作层落地为工具调用。通过组合工具,Agent 突破 LLM 自身限制完成多步骤任务。常见工具类型:
| 工具类型 | 例子 |
|---|---|
| 信息获取 | 搜索引擎、数据库查询、天气/股票/新闻 API |
| 计算与分析 | 计算器、代码解释器、数据分析库 |
| 内容生成 | 图像生成、语音合成 |
| 应用控制 | 发邮件、创建日历事件、操作 CRM |
| 物理世界交互 | 控制机器人、无人机、智能家居 |
三类动作从数字世界逐步延伸到物理世界。具身智能是 Agent 的终极形态------让 AI 不仅"在线上思考",更能"在线下行动"。
人 vs Agent:人在物理世界的精细操作远超当前 Agent,但 Agent 在虚拟输出和跨设备并行操控上已占优势。
二、聪明的大脑:计算与模型基座
大脑是 Agent 的核心计算单元。这一层分两部分:算力类型 和模型基座。
1. 三类算力:从判断到多模态的演进
"大脑"经历了一条清晰的演进路径------分类器 → LLM → MLLM。每一次跃迁都突破上一阶段的瓶颈。
演进三阶段:
阶段一·分类器------传统机器学习,解决边界明确的分类问题。轻量、确定、成本低,但每个任务都需专门数据训练,不会生成与推理。
阶段二·LLM------通用推理与生成引擎,是 Agent 的"主脑"。一个模型应对万千任务,但只懂文本,无法感知多模态信息。
阶段三·MLLM------在 LLM 基础上统一处理文本、图像、语音等多种模态,是"全能大脑"的演进方向,也是本文架构的中心。
演进对照表:
| 阶段 | 代表 | 大致时间 | 突破 | 局限 |
|---|---|---|---|---|
| 分类器 | 传统 ML | 1950s--2010s | 学会分门别类 | 专用、需重训、不会生成 |
| LLM | 大语言模型 | 2018--2022 | 通用、能理解意图 | 只懂文本、无感知 |
| MLLM | 多模态大模型 | 2023--今 | 看听说想统一 | 当下中心节点,持续演进 |
修正说明:LLM 时代起点以 2018 年 GPT-1、BERT 为标志;2017 年是 Transformer 论文发表年份,是地基而非时代本身。CoT 论文发表于 2022 年 1 月。
大脑演进链可视化:
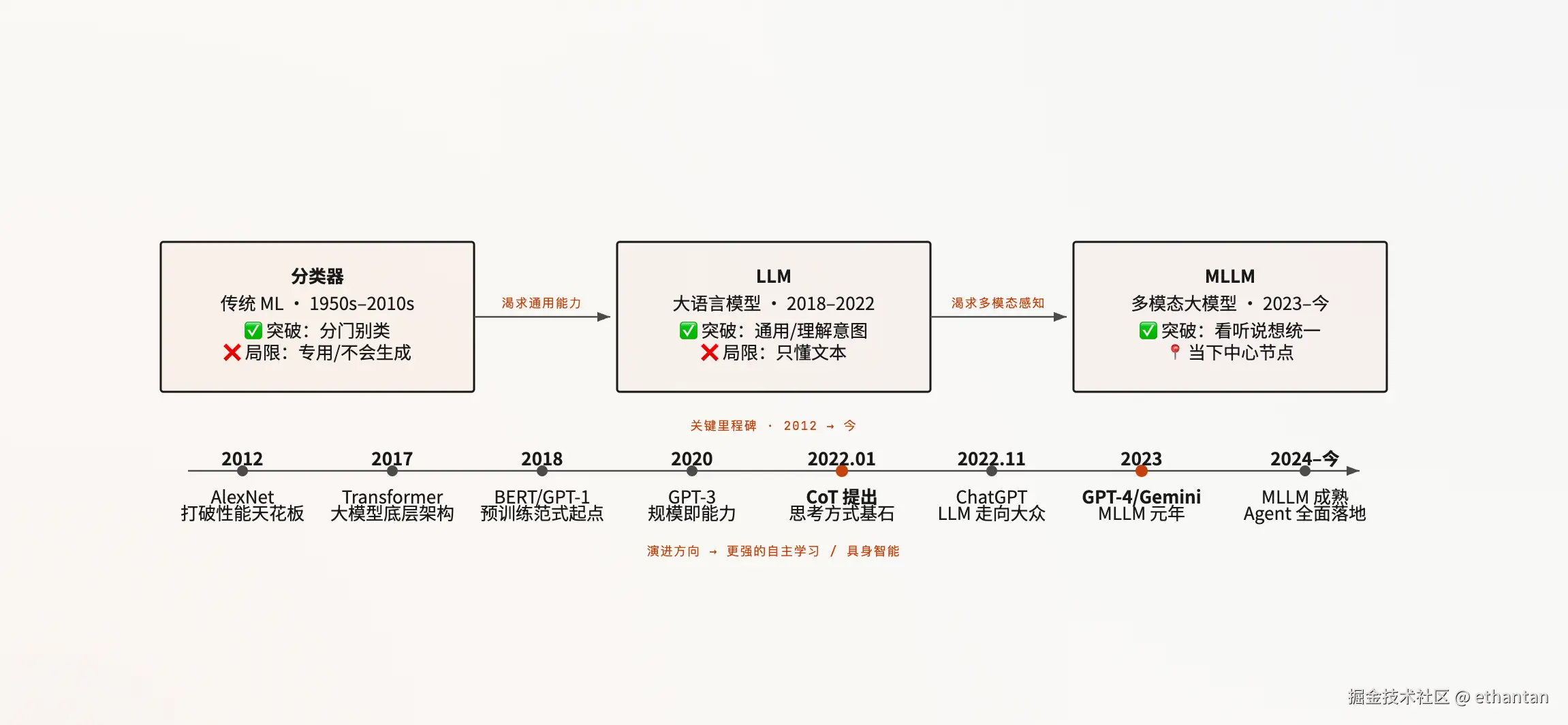
关键里程碑:
-
2012:AlexNet 打破分类器时代性能天花板。
-
2017:Transformer 论文发表,成为大模型底层架构。
-
2018:BERT / GPT-1 确立预训练范式。
-
2020:GPT-3 验证"规模即能力"。
-
2022.01:CoT 提出,是第三章所有思考方式的底层基石。
-
2022.11:ChatGPT 让 LLM 走向大众。
-
2023:GPT-4 / Gemini 引入多模态,MLLM 元年。
-
2024--今:MLLM 趋于成熟,催生 Agent 全面落地。
分类器解决"是什么",LLM 解决"怎么办",MLLM 解决"全能感知与决策"。三者是能力跃迁的演进链。
人 vs Agent:人的大脑靠直觉与常识,能耗低、能举一反三;Agent 靠统计模式,强在广度与速度,弱在因果理解和物理常识。
底层基石:思维链(CoT)
在进入具体思考方式之前,先理解它们共同的底层技术------思维链(CoT) 。由 Google 研究人员于 2022 年 1 月提出,核心是引导 LLM 在回答前先生成一步步推理过程,提升多步逻辑问题的准确性。
Zero-shot CoT 示例:
Q:一个篮子里有 5 个苹果,小明拿走 2 个,又放回 1 个,现在有几个?
A:Let's think step by step.
一开始 5 个 → 拿走 2 个剩 3 个 → 放回 1 个剩 4 个 → Final Answer: 4
CoT 为 Agent 的思考提供了结构化表达,是后续复杂思考方式的基础。
2. 模型基座与延伸阅读:《从零构建大模型》
模型能力来自两类基座:
-
通用大模型基座:ChatGPT / DeepSeek / GLM / Kimi / 豆包 等------开箱即用的通用能力。
-
专有模型 :在通用基座之上做预训练 + 监督微调(SFT) ,注入行业知识,适合通用模型覆盖不到的专业领域。
选型逻辑:能用通用基座就用;垂直领域精度不够时,才上专有微调。
想真正读懂"分类器 → LLM → MLLM"的演进链,以及模型基座背后的内部结构,推荐延伸阅读《从零构建大模型》------它从准备数据、架构设计、预训练、微调到指令对齐,逐步拆解大模型是如何被"垒"起来的。我们把书中的核心脉络画成两张流程图:第一张讲清"输入到输出"的主链路,第二张讲清"能力如何扩展" 。
图 1:大模型核心工作链路
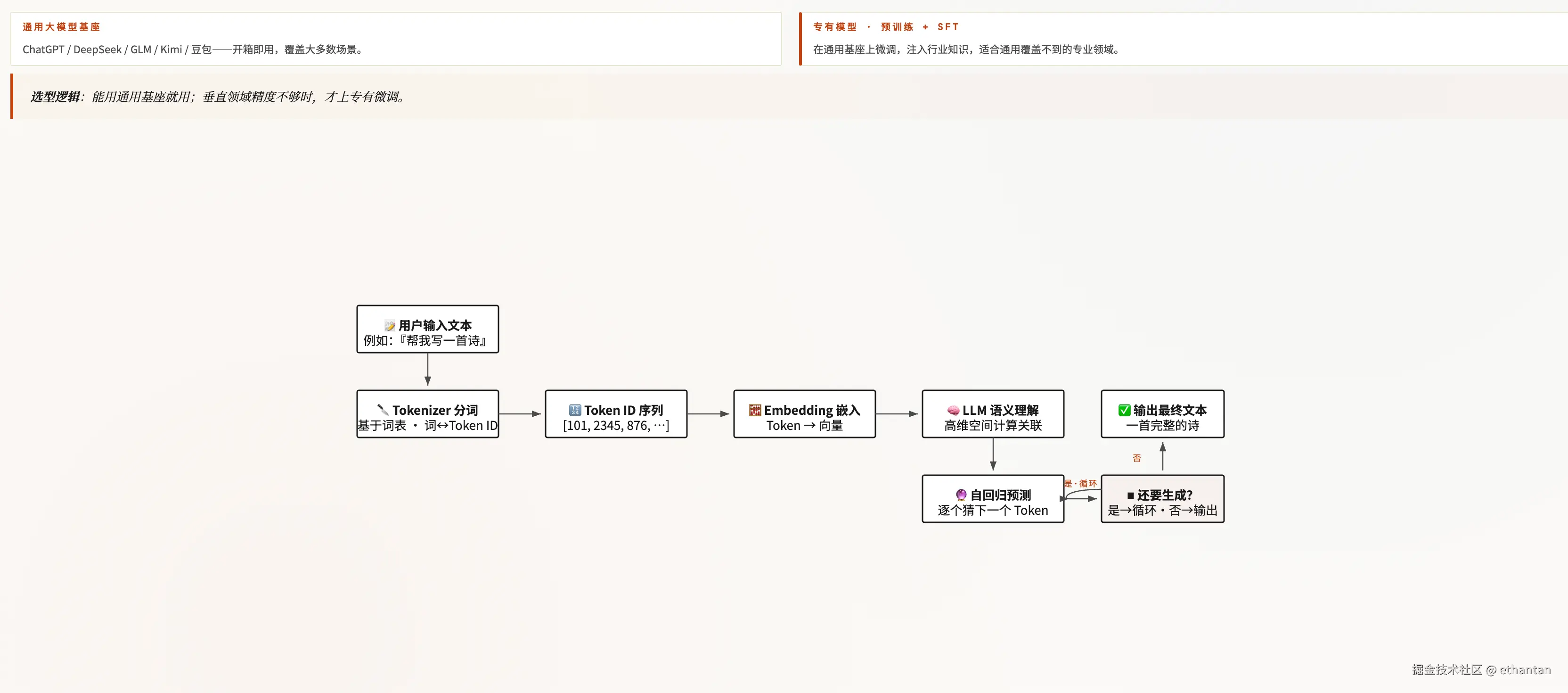
读图要点:大模型本质是"把文字切成 token,把 token 转成向量,再靠自回归一个 token 一个 token 地预测出来"。
三、思考方式:控制流
这是 Agent 区别于普通 LLM 的灵魂。
普通 LLM 是"一次性问答"。Agent 是循环式的"推理 → 行动 → 观察" ,能根据中间结果动态调整。决定"怎么循环"的逻辑,就是思考方式。
四种思考方式各有清晰边界:
① ReAct
机制 :Thought → Action → Observation 循环,每走一步根据观察决定下一步。由普林斯顿大学与 Google 共同提出,是目前应用最广泛的 Agent 思考方式,核心是把 CoT 与工具调用结合。
关键约束 :必须提前确定退出条件,否则会陷入无限循环。
优势:动态适应、可解释可控、强纠错能力。某步失败时,Agent 能在下一轮补救(换关键词重搜、换 API)。
挑战:需多次与 LLM 和工具交互,延迟与成本较高。
适用:探索性强、不确定性高的任务(开放研究、信息检索、调试排查)。
流程图 ------Thought → Action → Observation 循环,靠"退出条件"收敛:

② Plan-and-Execute
机制:先做全局规划,把任务拆解为有序步骤,再逐步执行。
特点:全局性好;任务明确时效率高、成本低。
与 ReAct 的权衡 :ReAct 局部灵活但可能偏离全局;PlanExe 全局清晰但灵活性差,执行中环境变化时计划可能需调整。成熟实现通常带 replan(重规划) 机制。
适用:流程相对标准、步骤可预见的任务。
流程图------先规划后执行的两阶段,带 replan 修正回路:

③ Reflection
机制 :生成初版 → 识别缺陷 → 改进优化,迭代提升。以 Reflexion 和 LATS 为代表。
特点:先有再优------先解决"有没有",再解决"好不好"。
适用:质量导向、可迭代打磨的任务(代码生成、文案写作、方案设计)。
流程图------"生成 → 反思 → 改进"的自我迭代循环:

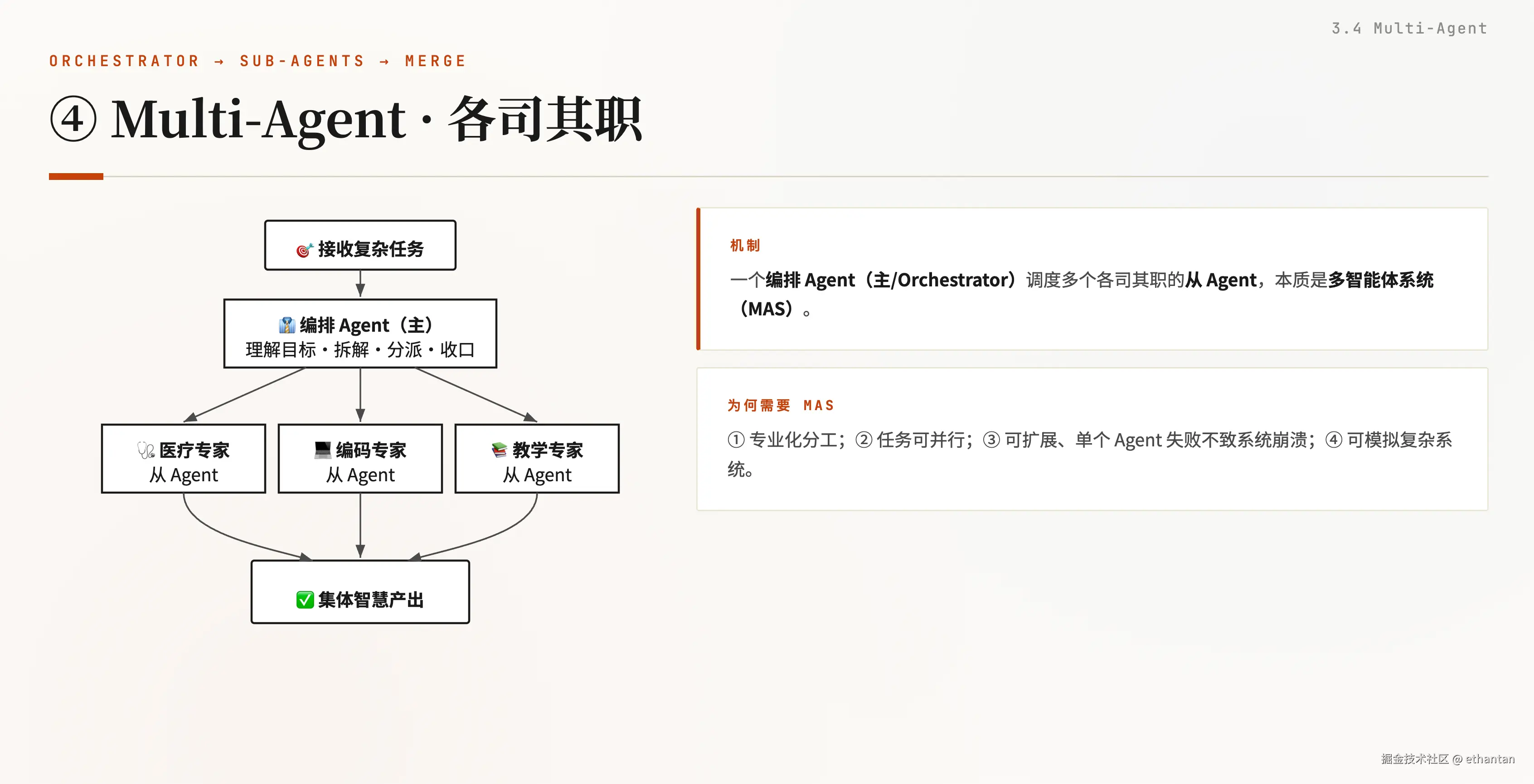
④ Multi-Agent
机制 :一个编排 Agent(主/Orchestrator) 调度多个各司其职的从 Agent ,本质是多智能体系统(MAS) 。
为何需要 MAS:① 专业化分工;② 任务可并行;③ 可扩展、单个 Agent 失败不致系统崩溃;④ 可模拟复杂系统。
流程图------编排 Agent 拆解分派、从 Agent 各司其职、结果汇总收口:
四种方式的对比与选型
| 思考方式 | 核心逻辑 | 全局性 | 优势 | 劣势 | 适用场景 | 类比 |
|---|---|---|---|---|---|---|
| ReAct | 走一步看一步 | 弱(局部) | 动态适应、可解释、强纠错 | 成本高、延迟大 | 探索性、不确定任务 | 职业规划走一步看一步 |
| PlanExe | 先规划再执行 | 强(全局) | 结构化、任务明确时效率高 | 灵活性差、难应对意外 | 标准流程、可预见任务 | 先拆解再行动 |
| Reflection | 先有再优 | 中(迭代) | 自我学习迭代、输出质量高 | 进一步增加成本延迟 | 质量导向、可打磨任务 | 敏捷开发迭代 |
| Multi-Agent | 各司其职 | 强(分工) | 专业分工、并行、可扩展 | 协调复杂 | 复杂、跨领域任务 | 团队专业分工 |
选型原则:任务越不确定 → 越偏 ReAct;任务越标准 → 越偏 PlanExe;质量要求越高 → 叠加 Reflection;复杂度越高 → 走 Multi-Agent。
实践中组合使用:复杂系统可先用 PlanExe 制定宏观计划,每个宏步骤用 ReAct 处理细节,关键节点后引入 Reflection 检查。
人 vs Agent:这四种方式把人无意识的思维习惯显式化。人擅长"元认知",知道自己在用什么方式想问题;Agent 的思考方式仍是预设的,需要人选择。
四、记忆层:存储与检索
记忆是 Agent 的状态存储。没有记忆,Agent 每次对话都从零开始,无法学习、无法理解用户偏好。按作用范围分两层:短期记忆和长期记忆。
1. 按作用范围分两级
① 会话级记忆
短期记忆存当前任务上下文,随任务结束而消失,主要形式是对话历史。
实现方式:直接利用 LLM 的上下文窗口。当对话过长时需压缩:
-
滑动窗口:只保留最近 N 轮。
-
摘要:周期性总结对话,用摘要替代冗长历史。
② 跨会话 / 持久记忆
长期记忆存跨任务、跨会话的信息,核心技术是 RAG。按部署形态分三种:
-
个人多端迁移:个人记忆 + Markdown 文件 + 记忆衰退机制。
-
本地隐私部署 :
SQLite + 向量检索。 -
生产级分布式:保证分布式环境下的记忆一致性。
RAG(检索增强生成)
LLM 上下文窗口有限,装不下所有知识。RAG 的解决思路是为 LLM 外挂一个知识库:生成前先从外部数据库检索最相关信息,作为额外上下文喂给 LLM。机制是"按需取用",而非"全量塞进大脑"。
RAG 四步机制(以"用户喜欢喝拿铁"为例):
| 步骤 | 动作 | 示例 |
|---|---|---|
| ① 存储 | 把长期记忆经嵌入模型转为高维向量,存入向量数据库 | "我喜欢喝拿铁" → 向量入库 |
| ② 检索 | 后续对话出现相关线索时,把问题同样转为向量做相似度搜索 | "帮我推荐咖啡" → 召回"喜欢拿铁" |
| ③ 增强 | 把检索到的记忆作为上下文,连同问题一起发给 LLM | 已知信息:用户喜欢喝拿铁 |
| ④ 生成 | LLM 基于增强后的上下文生成个性化回答 | "或许一杯经典拿铁是不错的选择" |
RAG 四步机制流程图:

2. 存储底座
-
传统存储:Markdown 文档;数据库 ES / Redis / PostgreSQL 等。
-
RAG 向量库:向量数据库,用于语义检索。
主流向量数据库对比(2026) :
| 数据库 | 类型 | 核心优势 | 主要应用场景 |
|---|---|---|---|
| Pinecone | 商业云服务 | 全托管,开箱即用,性能稳定 | 快速原型验证、中小企业应用 |
| Milvus | 开源 | 分布式架构,高可扩展性,功能丰富 | 大规模生产环境、高扩展性要求场景 |
| Weaviate | 开源 | 多模态支持,内置多种 Embedding 模型,GraphQL 接口 | 复杂数据类型、多模态检索应用 |
| ChromaDB | 开源 | 轻量级,Python 原生,开发友好 | 本地开发、数据科学实验、小型应用 |
| Redis | 开源/商业 | 内存数据库,延迟极低,功能多样(结合 RediSearch) | 实时性要求极高的场景、已有 Redis 系统 |
实战中常混合检索(向量 + 关键词)以兼顾语义和精确匹配。
人 vs Agent:人的记忆有情感加权和联想触发,且会主动遗忘无关细节;Agent 的记忆靠显式存储与召回,精确无损但缺乏情感与情境联想。
| 记忆维度 | 人 | Agent | 对比要点 |
|---|---|---|---|
| 短期 | 工作记忆(约 7±2 项) | 会话级记忆(上下文窗口) | Agent 容量更大但易溢出丢失 |
| 长期 | 经验、技能、情感记忆 | 持久记忆(MD/SQLite/向量库) | Agent 精确无损,人靠联想重构 |
| 检索 | 联想 + 情感触发 | RAG 向量/关键词检索 | Agent 可全量召回,人召回率低但相关性高 |
| 遗忘 | 主动遗忘 | 需设计衰退机制 | 遗忘是人的降噪优势 |
| 跨端 | 无法迁移 | 多端同步 | Agent 可迁移 |
记忆层是 Agent 结构性超越人类的领域------精确、无损、跨端、可迁移。代价是需要主动设计衰退机制,否则"记得太多"反而稀释相关性。
五、能力、协作与连接:外设与总线
感知让 Agent 能"输入",大脑让 Agent 能"想",动作让 Agent 能"输出"。连接外部工具、与其他 Agent 协作,还需要连接层。
三层演进总览------从"单体能力"走向"协同网络",三类基础设施逐级放大 Agent 的边界:
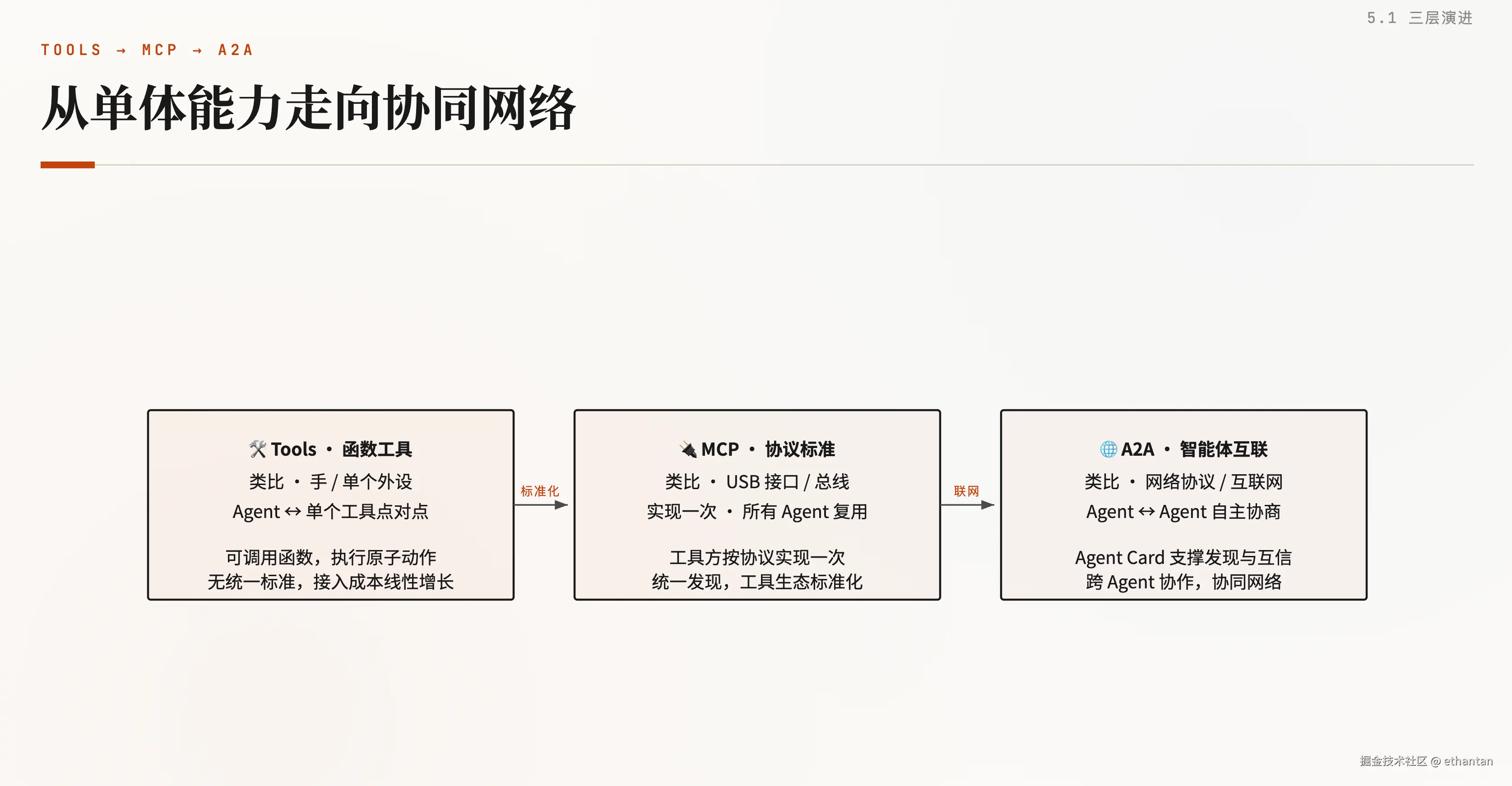
| 连接层 | 类比 | 作用 | 范围 | 代表 |
|---|---|---|---|---|
| Tools | 手 / 单个外设 | 可调用函数,执行查询、计算等原子动作,无统一标准 | 单体能力 | Function Calling |
| MCP | USB 接口 / 总线 | 工具方按协议实现一次,所有 Agent 复用,统一发现与管理 | 工具生态标准化 | stdio / SSE |
| A2A | 网络协议 / 互联网 | Agent Card 支撑发现、互信与跨 Agent 协作 | 协同网络 | Agent Card |
1. Tools
Agent 可调用的具体函数,执行查询、计算、外部操作等原子动作。没有统一标准时,每个 Agent 各自对接,接入成本随工具数线性增长。
2. MCP
MCP(Model Context Protocol)由 Anthropic 于 2024 年开源发布,把"工具"变成"即插即用的外设"。工具方实现一次 MCP Server,任意支持 MCP 的 Agent 即可接入。
MCP 核心三要素:
| 要素 | 作用 |
|---|---|
| Resources | 向 Agent 暴露的可读数据 |
| Tools | 可执行函数,Agent 主动调用 |
| Prompts | 预设提示模板,标准化交互 |
边界补充:MCP Prompts 是工具方向外暴露的"可复用交互模板";第六章的 Skill 是 Agent 内部沉淀的"工作流提示词 + 领域知识"。
3. A2A
A2A(Agent2Agent Protocol)由 Google 提出,让不同厂商、框架的 Agent 能彼此发现、协商、委派任务,构建"智能体互联网"。
Agent Card:每个 Agent 发布标准化名片,声明能力、端点、认证方式、支持的输入输出。
协作四步:发现 → 协商 → 委派 → 回传。
MCP vs A2A:MCP 解决"Agent 如何用工具"(纵向接入),A2A 解决"Agent 如何找 Agent"(横向协作)。
Multi-Agent 系统的架构模式
三种架构模式的核心差异,可以概括为**"谁说了算"和"Agent 之间怎么通信"**。下图把三种常见模式并列展示:
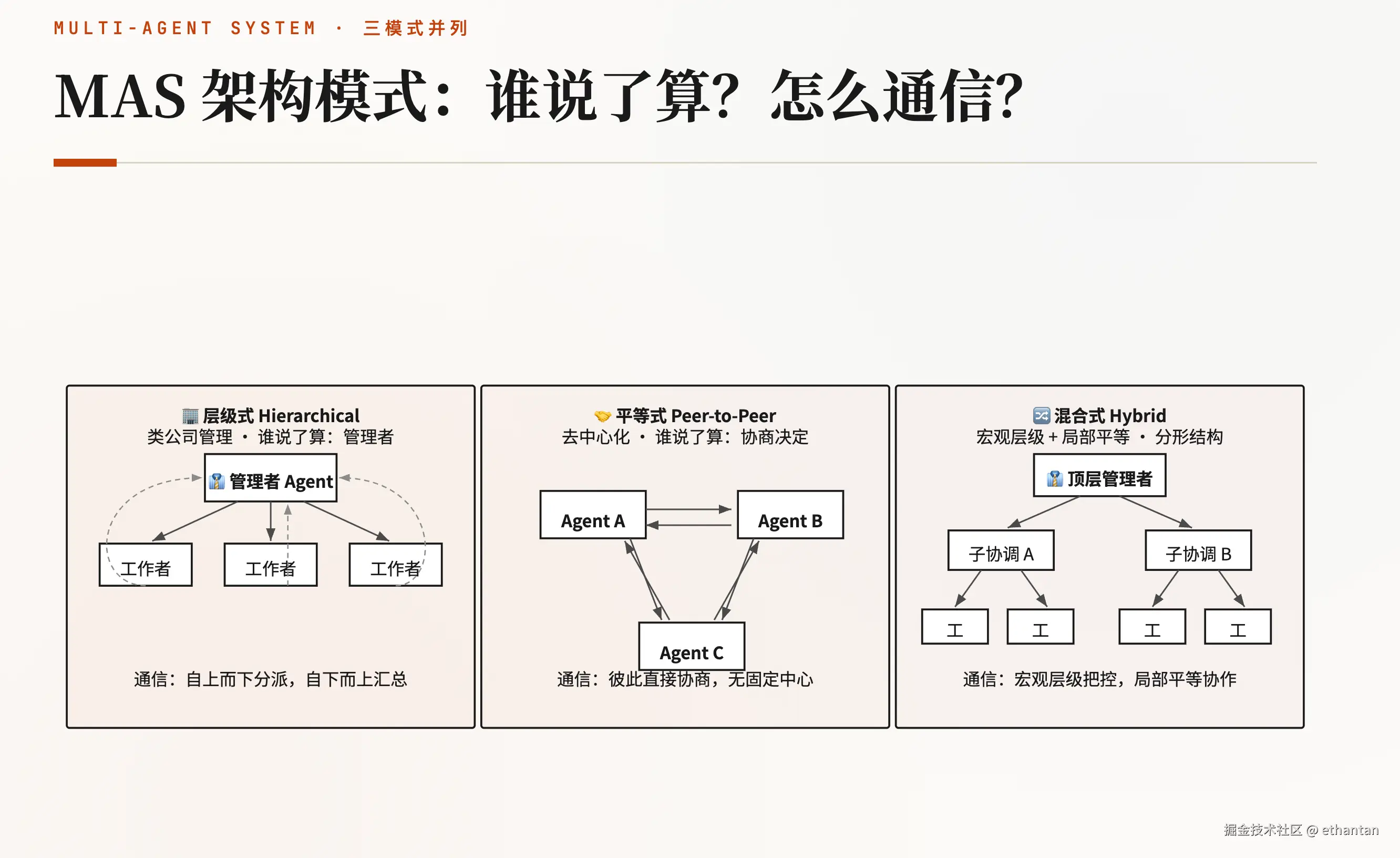
读图指引:
-
层级式:一个管理者 Agent 居中,负责任务拆解与结果汇总;结构清晰、最易落地,类似传统管理架构。
-
平等式:Agent 之间没有固定中心,彼此直接协商;灵活但一致性难保证,适合需要频繁对齐的开放协作。
-
混合式:宏观上用层级把控方向,局部让工作者 Agent 平等协作;大型复杂系统常用这种"分形"结构。
| 架构模式 | 结构 | 特点 | 典型代表 |
|---|---|---|---|
| 层级式 | 管理者 Agent 分解任务并分派给工作者 Agent,结果汇总上报 | 类公司管理结构,最常见 | AutoGen |
| 平等式 | 所有 Agent 地位平等,直接通信协商 | 去中心化、灵活 | CrewAI |
| 混合式 | 宏观层级式管理,局部平等协作 | 兼取两者优点 | --- |
三者关系:Tools 是手,MCP 是接口标准,A2A 是网络协议。从单体能力走向协同网络。
5. 共识:Agent 协作的语义基础
协议(A2A)解决了 Agent "能通信",但没解决"能对齐"------同一件事,不同 Agent 的理解可能完全不一样。这就是共识要解决的问题。
什么是共识?
在没有全局指令的情况下,多个实体对同一件事形成一致判断的能力。人靠语言、历史、文化、默契来达成;Agent 则需要显式的对齐机制。
共识在 AI Agent 中的三个层次:
| 层次 | 场景 | 核心机制 | 当前成熟度 |
|---|
| 单 Agent 内部 | 跨对话保持一致的判断标准 | Skill 固化逻辑、记忆保留历史参照 | ✅ 相对成熟 |
| 多 Agent 之间 | 不同角色 Agent 对目标和标准对齐 | 编排 Agent 强制分配;或平等式共享上下文的共识协商 | ⚠️ 层级式成熟,平等式仍早期 |
| 人与 Agent 之间 | 人的需求被 Agent 正确理解,Agent 输出被人认可 | Human-in-the-loop 介入修正 + 共同对齐的判断基准 | ⚠️ 兜底方案成熟,深度对齐仍瓶颈 |
共识是 Agent 从"能用"走向"可靠"的一道坎。
单 Agent 靠 Skill 和记忆能稳定输出,相对容易。但多 Agent 在没有统一大脑时如何自协商达成一致、以及人与 Agent 之间在语义层面的深度对齐,是当前工程化的核心瓶颈。
从本质上看,人机协作中"人负责的事"就是不断与 AI 达成共识的过程------人把需求澄清给 Agent,Agent 把产出解释给人,每一轮交互都是在缩小共识缺口。当共识断裂时,人工兜底(第八章)就是最后的对齐机制。
这正是"成为驾驭 AI 的人"的含义------不是把任务丢给 Agent 就结束,而是在每一轮对齐中持续校准共识。
六、Skill:经验的复用
把可复用能力封装成 Skill,避免每次从零开始。
1. Skill 的结构
一个标准的 Skill 通常包含三部分:
| 组成部分 | 内容 | 作用 |
|---|---|---|
| 元数据 | name、description、tags、version、author | 让 Agent 发现和判断是否激活 |
| 指令 | 角色设定、工作流步骤、约束条件、输出规范 | 指导 Agent 如何执行任务 |
| 资源 | 模板文件、参考文档、示例代码、数据源 | 为执行提供素材 |
2. Skill 解决的问题
问题一:重复劳动
每次对话 Agent 都从零理解任务,同样的流程反复消耗 token。Skill 把"怎么做"固化下来,一次封装、多次复用。
问题二:质量不稳定
不同场景下 Agent 的输出质量高度依赖 prompt 质量,Skill 把最佳实践标准化,保证稳定输出。
问题三:经验难沉淀
人的经验随对话消失,团队的最佳实践无法传承。Skill 让经验从隐性变为显性,成为可积累的资产。
问题四:跨工具迁移难
不同平台(Claude Code、Cursor、DeepSeek)的交互方式不同,Skill 通过统一规范让知识跨工具流转。
与记忆的区别:记忆存"发生过什么" (如用户偏好、历史记录),Skill 存"该怎么做" (如代码审查流程、数据分析框架)。
七、编排框架落地:从思维到工程
思考方式是"思维",编排框架是"工具"。本节以 LangChain 官方的 Deep Agents 为主线,把"思考方式 / 记忆 / Skill / 能力协作"逐一对到工程组件上。
1. 三层架构
| 层级 | 代表 | 核心能力 | 解决什么 |
|---|---|---|---|
| Runtime | LangGraph | 图编排、持久化、状态管理、流式输出、人机回路 | 复杂流程控制与执行引擎 |
| Framework | LangChain | 模型抽象、create_agent(ReAct 循环 + 工具调用)、工具接口、中间件 |
单 Agent 基础能力标准化 |
| Harness | Deep Agents | 规划、虚拟文件系统、子智能体、记忆、技能 | 端到端复杂任务的可靠性 |
三层的关系可以理解为"底座 → 中间件 → 应用套件":LangGraph 负责状态流转与图编排,LangChain 负责把 LLM + 工具封装成标准 Agent,Deep Agents 则在前两层之上提供长任务、记忆、文件系统、子智能体等开箱即用的复杂任务能力。

读图指引:
-
最底层 LangGraph:提供图编排、状态管理、持久化、流式输出、人机回路------是所有 Agent 运行的"操作系统"级引擎。
-
中间层 LangChain :把 LLM、工具、Prompt 打包成标准化 Agent(主要是
create_agent的 ReAct 循环),让单一 Agent 能力可复用。 -
最上层 Deep Agents:面向端到端复杂任务,提供规划、子智能体、虚拟文件系统、长期记忆、Skill、人工兜底等高级能力。
-
依赖方向:Deep Agents 的组件向下调用 LangChain 的 Agent / 工具 / Prompt 能力;LangChain 的 Agent 又跑在 LangGraph 的状态图与持久化机制之上。
Deep Agents 不是 LangGraph 的替代品,而是架在 LangGraph runtime + LangChain framework 之上的"应用套件"。简单任务用 LangChain 单层即可,端到端复杂任务才需要 Deep Agents。
LangGraph 如何构建一张图
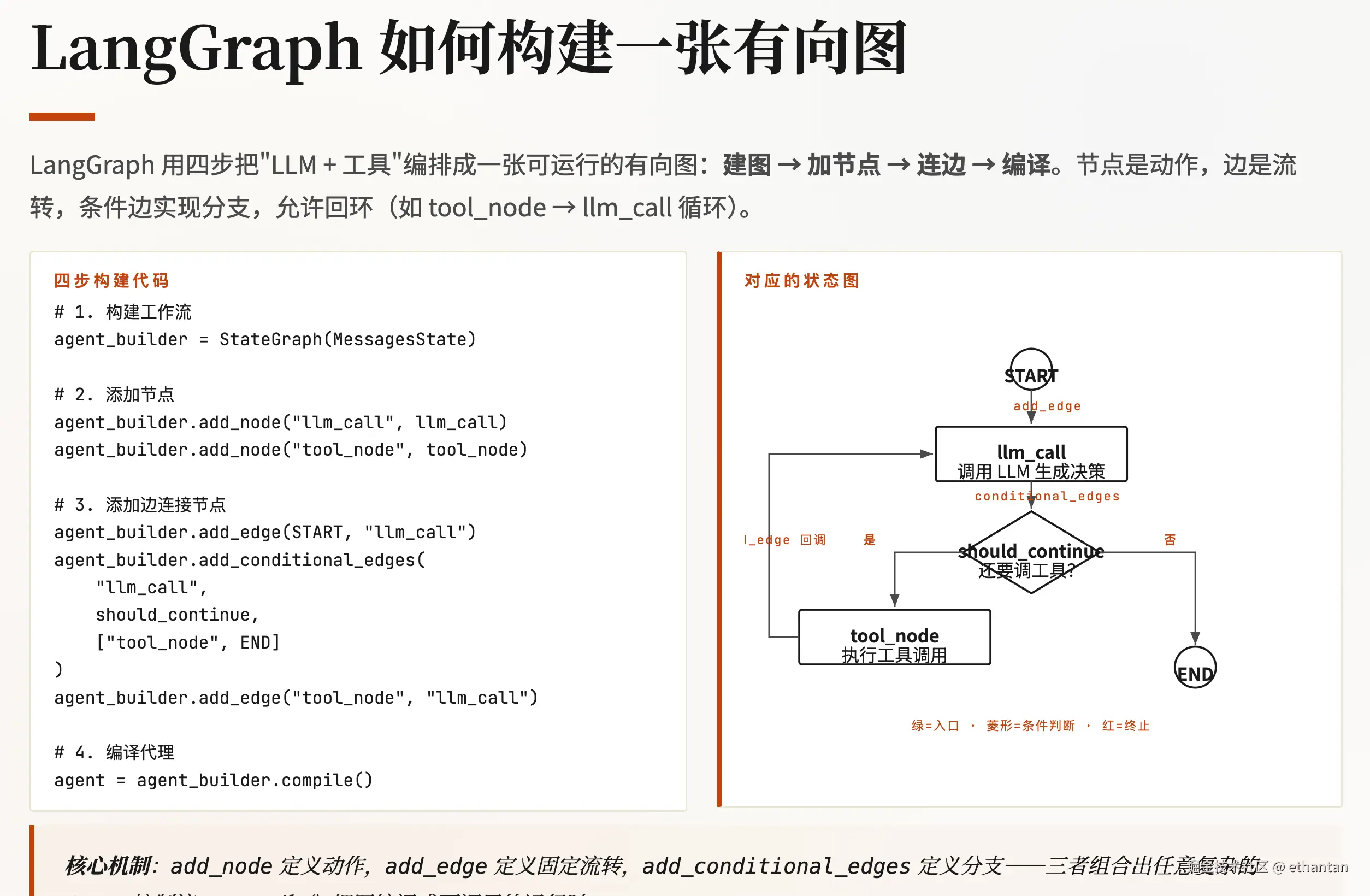
LangChain create_agent 的核心能力
LangChain 的 create_agent 系列函数(create_react_agent、create_tool_calling_agent 等)是把"一个 LLM + 一组工具"封装成可运行 Agent 的工厂函数,核心职责是:
-
绑定工具(Tools):把函数/封装好的工具注入到 LLM 可调用的作用域里。
-
构造提示模板(Prompt):把系统提示词、角色设定、工具描述按固定格式拼好喂给模型。
-
实现 ReAct 循环 :让模型在每一轮先输出
Thought,再决定调用哪个工具的Action,拿到Observation后再进入下一轮------也就是第三章讲的Thought → Action → Observation。 -
状态流转:维护多轮对话状态,把每次工具返回结果重新塞进上下文,直到满足退出条件给出最终答案。
一句话概括:
create_agent不是某一种思考方式,而是把 ReAct 思考方式 + 工具调用 + 状态维护 打包成一行代码即可启动的"标准 Agent 启动器"。它吃的是模型和工具,吐出的是一个能循环推理-行动的 Agent。LangGraph 则再往上走一层:把这条循环链路变成可视化的状态图节点,支持分支、并发、持久化和人机回路。
2. Deep Agents 四大能力支柱
| 能力支柱 | 关键组件 | 对应本文原理 |
|---|---|---|
| 执行环境 | 虚拟文件系统、Tools/MCP、代码沙箱、流式输出 | 动作层、能力协作 |
| 上下文管理 | 技能、长期记忆、摘要与上下文卸载、提示缓存 | 记忆、Skill |
| 委派 | write_todos、task |
PlanExe、Multi-Agent |
| 控制 | interrupt_on、文件系统权限 |
人工兜底 |
3. 虚拟文件系统
传统 Agent 把大段信息塞进 prompt,导致上下文膨胀。Deep Agents 用文件系统做 Context Engineering:让 Agent 按需读取、分门别类存储,而非把所有资料同时摊在桌上。
目前文档内提到三类机制:
-
六大文件操作 :
ls、read_file、write_file、edit_file、glob、grep------ 这是 Agent 与虚拟文件系统交互的原子命令。 -
大结果自动卸载:工具调用返回的内容超过 token 阈值时,完整内容写入文件系统,对话历史只保留文件路径 + 内容预览,避免 prompt 暴涨。
-
历史自动总结:当上下文达到窗口上限且没有可卸载的内容时,生成摘要替代原始对话,并把原始对话写入文件系统留存。
安全隔离:文件系统之上的执行沙箱
虚拟文件系统解决"上下文怎么管",但 Agent 经常要执行代码、调用命令行或访问网络,必须解决"执行是否安全"的问题。工程上通常按隔离强度分层选择沙箱:
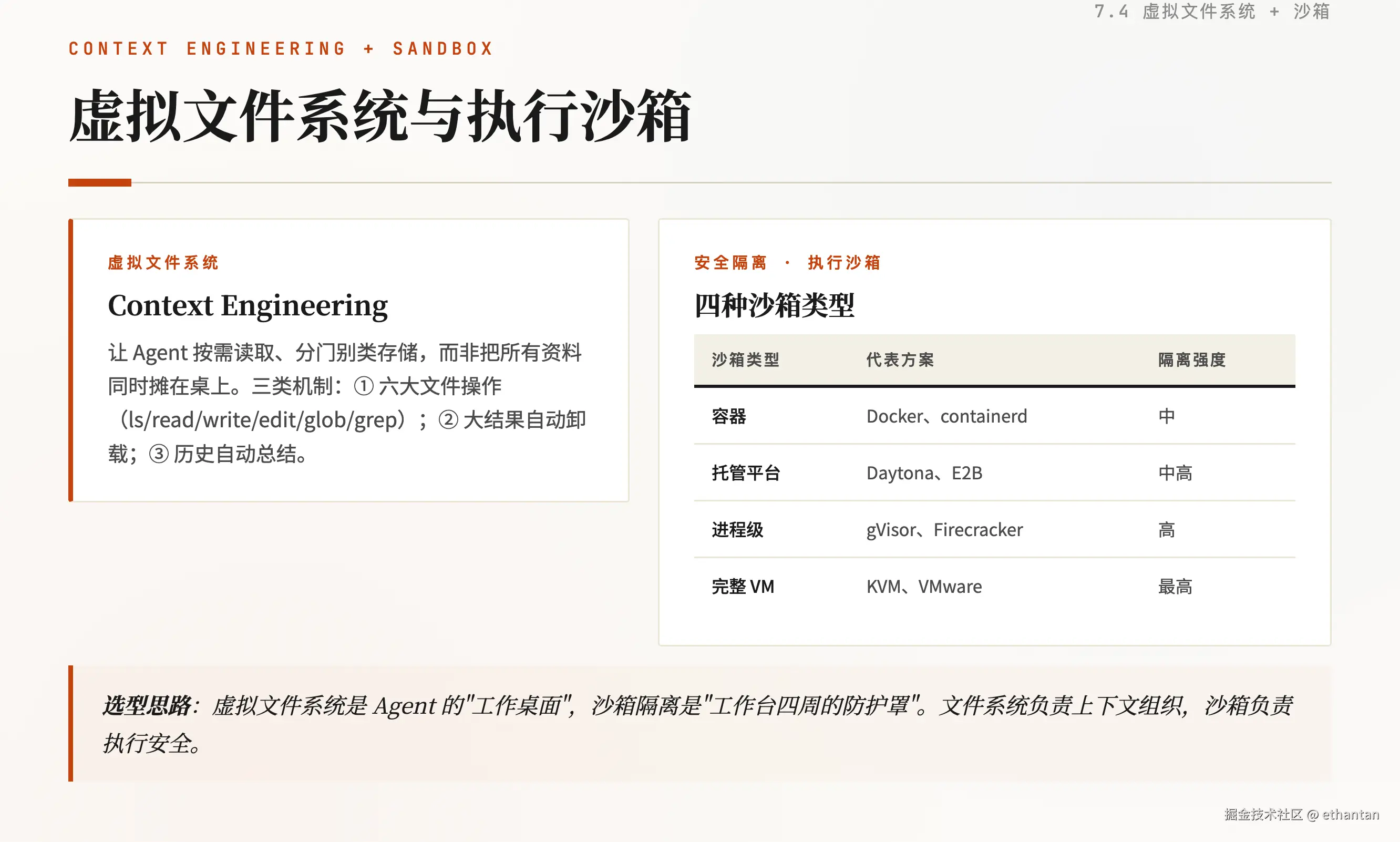
选型思路:虚拟文件系统是 Agent 的"工作桌面",沙箱隔离是"工作台四周的防护罩"。二者互补------文件系统负责上下文组织,沙箱负责执行安全。普通文档处理可不用沙箱;一旦 Agent 需要执行用户提交的代码、访问外部网络或操作敏感数据,就必须把运行环境放进沙箱。
虚拟文件系统是上下文管理的基础设施,是 Deep Agents 相对普通 ReAct 循环最本质的升级。
4. 任务规划write_todos:Plan-and-Execute 的工程化
机制 :调用 create_deep_agent() 时自动注入 write_todos 工具,无需手动配置。每个任务含 subject(标题)、description(描述)、status(状态)三字段,状态线性流转:pending → in_progress → completed。
执行三阶段:制定计划(全 pending)→ 逐步执行(标记状态)→ 动态调整(执行中发现新需求可新增/调整任务)。
对应第三章的思考方式 :本质是 Plan-and-Execute(PlanExe) ,但不是严格两阶段分离------Agent 可在执行中修改计划,是"带动态调整能力的 PlanExe"(呼应前文提到的 replan 机制)。
关键设计 :任务清单持久化在 Agent State 中,而非对话历史。这意味着即使对话历史被总结压缩,清单依然完整------它充当 Agent 的"北极星",解决长任务"做着做着忘了目标"的问题。
5. 子智能体task:用隔离上下文解决膨胀
机制 :内置 task 工具,主智能体派发子任务给专门的子智能体执行。
解决的核心问题 :上下文窗口膨胀 。子智能体拥有独立的 context window ,自主执行后只把单一最终报告返回主智能体------中间的所有搜索、文件读取、试错过程都被隔离在子智能体自己的上下文里,不污染主智能体。
对应第三章的思考方式:Multi-Agent(各司其职)。主智能体负责编排,子智能体负责专职执行,上下文天然隔离。
洞察 :这是"分而治之"在 Agent 上的实现------主智能体的上下文保持精炼(只装规划和结果摘要),繁重探索丢给子智能体。子智能体是上下文管理的另一把利器,与文件系统卸载互补:文件系统卸"数据",子智能体卸"过程"。 教程中还有"异步子智能体"(async subagents)进一步实现并行化。
6. 技能 Skills:渐进式披露 + 跨工具标准
规范 :Deep Agents 的 Skill 格式正朝着开放规范演进(如 SKILL.md 约定:YAML frontmatter 元数据 + Markdown 指令正文)。该理念与 Claude Code、OpenAI Codex、Cursor 等工具中的 skills / instructions 文件相似,但生态仍在演化,实际跨工具迁移时应核对各平台的具体 schema。
渐进式披露(Progressive Disclosure)三级加载------这是 Skill 最核心的设计决策:
| 级别 | 加载内容 | 时机 | 成本 |
|---|---|---|---|
| L1 Metadata | 仅 frontmatter(name + description) | 启动时注入系统提示词 | 20 个 Skill 约几百 token |
| L2 Instructions | 完整 SKILL.md 正文 | Agent 按 description 判断匹配后才加载 | 按需 |
| L3 Resources | references/、assets/ 下文件 | 指令引用时由 LLM 自行决定读取 | 按需 |
关键点 :
description是 Agent 决定是否激活 Skill 的唯一依据------Agent 不会提前读正文来匹配。这保证了 Skill 数量增长时启动开销仅线性增加,可"无限扩展"。
类比:教程原文------"Skills 之于 AI Agent,就像 npm 包之于 Node.js"。工具(Tools)是原子操作(搜一次、读一个文件);Skill 是"多步骤工作流 + 领域知识 + 模板资源"的打包复用。这正是第六章"经验复用"的工程落地。
7. 长期记忆:memory.md + LangGraph Store
机制 :通过 memory= 参数声明记忆文件路径(如 memory.md、preferences.md),Agent 启动时自动加载到系统提示词。记忆写入 /memories/ 路径,经 StoreBackend 持久化到 LangGraph Store(开发用 InMemoryStore,生产用 PostgresStore),跨会话保留。
命名说明 :Deep Agents 文档示例中可能使用
AGENTS.md作为记忆/偏好文件。为避免与"AGENTS.md 全局 Agent 配置协议"混淆,本文示例改用memory.md。若你所在项目的 Deep Agents 模板确实使用AGENTS.md,请将其视为该框架下的持久化记忆文件约定,与全局配置协议不是一回事。
自我更新 :Agent 在对话中学到新信息时,用内置 edit_file 更新记忆文件,变更持久化到下次对话------Agent 能"自我进化",发展出自己的专业能力。
隔离 :通过 namespace 按 assistant_id(Agent 级)、user_id(用户级)、org_id(组织级)隔离,支持多用户隔离与组织级共享。
三者关系(共用同一套文件操作接口,靠路径前缀和后端区分) :
| 维度 | 虚拟文件系统 workspace | 技能 Skills | 长期记忆 Memory |
|---|---|---|---|
| 存储后端 | StateBackend | StoreBackend | StoreBackend |
| 生命周期 | 单次对话内 | 跨对话持久 | 跨对话持久 |
| 内容性质 | 临时工作文件 | 程序性记忆(怎么做) | 语义记忆(知道什么) |
洞察 :记忆、技能、文件系统共用同一套 read/write/edit 接口,只是存储后端和路径前缀不同。这套统一抽象是 Deep Agents 设计的精妙之处------第四章讲"记忆"、第六章讲"Skill",在工程上其实是同一个文件系统的三种用法。
8. 编排框架全景与选型
除 LangChain/LangGraph/Deep Agents 这条官方主线外,生态中还有更多编排框架:
| 框架 | 定位 | 适合谁 |
|---|---|---|
| LangGraph | 运行时引擎,图编排 | 需要极致可控性的开发者 |
| LangChain | 框架积木,单 Agent 能力 | 构建自定义 Agent 的开发者 |
| Deep Agents | 应用套件,开箱即用 | 需要可靠落地复杂任务的团队 |
| Dify | 低代码可视化编排 | 快速搭建、业务验证 |
| AutoGen Studio / Flowise 等 | 低代码 / 可视化平台 | 少写代码、快速原型验证 |
| Claude Desktop / Claude Code | 开箱即用 Agent 体验 | 直接使用 Agent 的终端用户 |
框架选型同样问题驱动:要极致灵活可控 → LangChain/LangGraph;要快速落地降门槛 → Dify;要开箱即用 → 平台型产品。三层不是越多越好------简单任务用 LangChain 单层即可,端到端复杂任务才需要 Deep Agents 这类 Harness,盲目上高层架构只引入不必要复杂度。
回到"人 vs Agent" :Deep Agents 的每一项能力都是在补人类认知的短板------write_todos补"长任务易跑偏"、子智能体补"注意力有限"、虚拟文件系统补"工作记忆容量小"、Skill 补"经验难传承"。工程上,这些就是"把人脑的好习惯外化成机器不会忘的机制"。
9. 延伸:OpenViking------字节开源的 Agent 上下文数据库
火山引擎(字节跳动)开源的 OpenViking 与 Deep Agents 思路高度一致:它不是向量数据库,而是面向 AI Agent 的上下文数据库,解决 Agent 上下文"怎么统一组织、按需加载、自我迭代"的问题。
核心差异一句话说清楚:
向量数据库(如 Milvus、Pinecone、VikingDB)解决"向量怎么存、怎么检索快";OpenViking 解决的是更上层的问题------Agent 的上下文怎么像文件系统一样被管理。二者是"文件系统"与"硬盘"的关系。
五个核心特性(与 Deep Agents 几乎同款思路的另一种工业实现):
| 核心特性 | 说明 | 对应 Deep Agents 机制 |
|---|---|---|
| 📁 文件系统管理范式 | 将记忆、资源、技能统一映射至 viking:// 虚拟目录,通过 ls / find 进行标准化定位与管理。 |
虚拟文件系统 (VFS) |
| 🧠 分层上下文加载 (L0/L1/L2) | 采用预生成分级摘要策略:从概览 (L0) 到详情 (L2) 按需加载,显著降低 Token 消耗。 | Skill 渐进式披露 (L1/L2/L3) |
| 🔍 目录递归检索 | 遵循"意图分析 → 目录定位 → 向量检索 → 子目录下钻 → 结果聚合"的高精度检索链路。 | 上下文卸载 + RAG |
| 👁️ 可视化检索轨迹 | 完整记录并展示目录浏览与文件定位路径,实现检索过程的可观测性与可调试性。 | 文件系统天然路径追踪 |
| 🔄 自动会话管理与自迭代 | 会话结束后异步分析执行结果与用户反馈,自动更新用户画像 (memory.md) 及 Agent 经验库。 |
长期记忆存储 (LangGraph Store) |
与 VikingDB 的关系 :VikingDB 是字节云端的向量数据库服务,OpenViking 可把它作为存储底座------开源版可本地跑,商业版借 VikingDB 实现大规模存储与高性能检索。这再次印证:向量库是基础设施,上下文数据库是更上层的 Agent 基建。
背书与表现(据火山引擎官方资料,早期数据仅供参考):开源了 VLDB 2026 论文《VikingMem: A Memory Base Management System for Stateful LLM-based Applications》的核心能力子集;官方称在 LoCoMo 用户记忆基准上准确率从 57.21% 提升到 80.32%,Token 消耗减少 63.2%。
一句话收口 :OpenViking 与 Deep Agents 殊途同归------都在用"文件系统范式 + 分层按需加载 + 记忆自迭代"回答同一个问题:长跑的 Agent,上下文该怎么管? Deep Agents 是 LangChain 官方套件(深度集成 LangGraph runtime),OpenViking 是字节独立开源实现(多模型 Provider、本地可跑、学术有据)。两条路线验证了同一件事:上下文工程正在成为 Agent 时代的新基础设施。
Deep Agents vs OpenViking 对照图------两套实现,同一套上下文工程理念:

八、落地场景:赋能替代,人工兜底
核心判断:有需要"人"和"流程"的地方,都可以用 MLLM 赋能、替代。
分工边界:Agent 赋能替代,人工负责兜底。
这是整套架构落地时的关键设计------Agent 可以自主完成大量执行工作,但在"做什么"和"对不对"的层面,人仍是不可替代的决策者:
-
Agent 负责:执行、生成、初筛、流转。
-
人负责:需求的生产与澄清、审核与校验、决策与兜底。
为什么人工兜底不可替代?
因为每个人都是独一无二的。每个人的认知、经历、价值观各不相同,这些差异塑造了各自的需求判断和价值取向。Agent 可以高效地执行"怎么做",但无法替代人决定"做什么"以及"做得好不好"------后者需要人对自身处境的独特理解和对质量的独立判断。
人工兜底不是技术上的妥协,而是对"人的不可替代性"的确认。这与第五章"共识"的讨论一脉相承------人与 Agent 在协作中持续对齐理解,最终由人把握方向和质量。
工程实现 :LangGraph 提供interrupt/interrupt_on,Deep Agents 提供文件系统权限与人工介入点。建议在高风险环节(转账、发布、删除、对外承诺)显式设置 Human-in-the-loop,而不是仅在策略层强调"人工兜底"。
结束语
1. 在这个新的航海时代,成为驾驭 AI 的人(人机协调),而不是被替代的人。
AI Agent 的本质是"像人一样思考的智能体",但它终究是工具。真正决定价值的,是能否把 Agent 用好------人机协调,而非人机对抗。
2. 每一轮的技术变更,都会带来新的生产力,也带来新的机会和岗位。
从分类器到 LLM,从单 Agent 到 Multi-Agent,每一次范式迁移都淘汰了一批旧岗位,也诞生了一批新岗位(Prompt 工程师、Agent 编排师、Skill 设计师......)。趋势不可逆,但趋势中永远有机会------关键不是抗拒变化,而是站在变化的有利一侧。
3. 未来已来:四大演进方向
站在 2026 年回望与前瞻,AI Agent 的技术架构正朝以下方向持续演进:
-
更强的自主学习能力:未来 Agent 不仅使用预定义工具,还能自主发现和学习新工具------通过阅读 API 文档自动学会调用新服务,甚至通过观察人类操作自我泛化出新技能。
-
从数字世界到物理世界:随着具身智能发展,Agent 的"行动"将不局限于调用 API 和操作软件,而是能控制机器人、无人机等物理实体在现实中完成任务,成为连接数字智能与物理现实的关键桥梁。
-
边缘化与去中心化:为保护隐私、降低延迟,越来越多轻量级 Agent 将部署在边缘设备(手机、汽车、智能眼镜);同时基于 A2A 等开放协议的"智能体互联网"逐渐形成,海量去中心化 Agent 彼此发现、协商、协作,构成前所未有的全球智能网络。
-
人机协同的深度融合:未来架构更注重"人在环路(Human-in-the-loop)"设计------Agent 不再完全取代人类,而是作为人类的"超级助理"或"认知外骨骼",在人类监督引导下工作,可随时介入、修正行为,形成无缝的人机协同工作流。