本文复盘一个直播间复杂页面下的前端性能问题:视频首帧已经不是唯一指标,直播间里的常驻业务能力也要尽快完整可用。
在直播间里,视频出来只是第一步。互动入口、活动挂件、状态展示、战报类组件、连麦和 PK 相关入口、打点和异常监控,也会一起影响用户对"直播间是否完整可用"的判断。
这次优化的目标很明确:
text
把常用子应用加载时间从约 1500ms 优化到 1000ms 内。阶段性结果里,某个常驻功能的挂载时间从 1550ms 降到了 890ms,其他子应用加载基本不受影响。
| 指标 | 优化前 | 优化后 | 变化 |
|---|---|---|---|
| 常驻功能挂载时间 | 1550ms | 890ms | -660ms |
| 常用子应用目标 | 约 1500ms | 1000ms 内 | 达成阶段目标 |
| 其他子应用 | 基线状态 | 基本不受影响 | 未明显牺牲其他链路 |
这类优化很少靠一个银弹解决。真正有价值的部分,是把一个看起来很散的加载问题,拆成几条可持续治理的链路:
- 网络链路;
- 缓存和 CDN;
- DNS / TCP / TLS 预连接;
- 字体和图片;
- 打点和异常监控;
- 业务代码;
- 公共依赖和构建体系。
1. 先把指标收窄:优化对象到底是什么
复杂页面性能优化最容易跑偏的一点,是一上来就说"页面慢"。
但直播间里至少有几类不同指标:
| 指标 | 关注点 |
|---|---|
| 白屏时间 | 页面是否尽快有内容 |
| 视频首帧 | 直播画面是否尽快出现 |
| 子应用挂载完成 | 常驻业务能力是否可用 |
| 完整可交互 | 用户能否完整操作直播间 |
这些指标都重要,但不能混在一起优化。
这次专项先把问题收敛成:
text
常驻子应用什么时候挂载完成。这个指标比"直播间慢"更具体,也更适合拆解。它能帮助我们判断到底是网络链路拖慢、资源阻塞、代码过重,还是低优先级逻辑抢了关键路径。
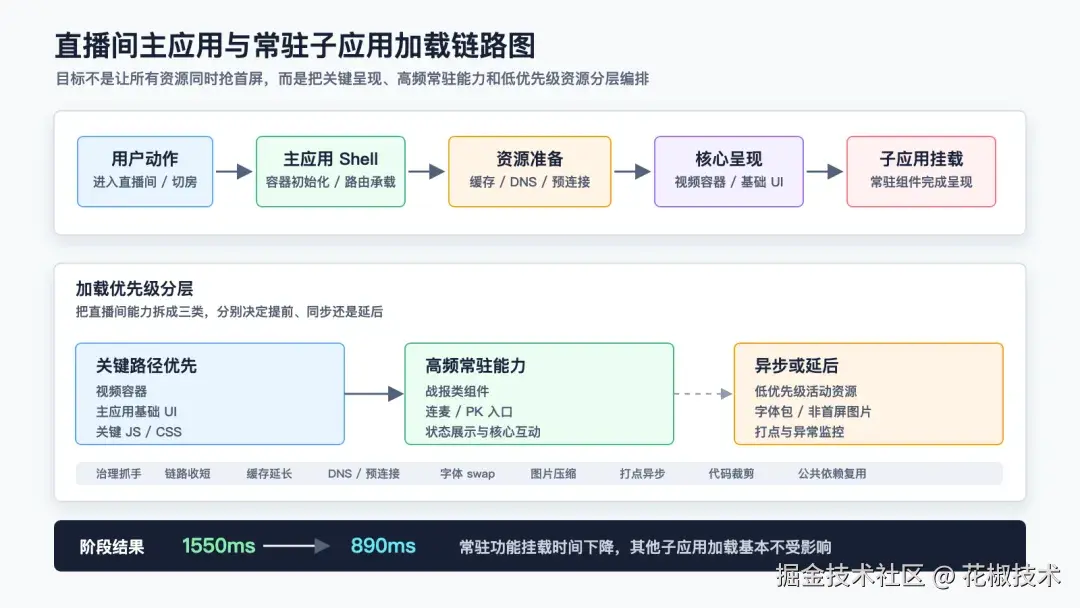
2. 第一步不是优化,而是先把加载过程量出来
性能优化最怕凭感觉。
感觉上像网络慢,最后可能是字体阻塞;感觉上像组件慢,最后可能是打点和监控抢了首屏资源;感觉上像业务代码慢,最后可能是资源链路多绕了一层。
所以第一阶段先做两件事。
第一,增加子应用加载时间打点。
至少要把这些节点记录下来:
text
子应用开始加载
-> 资源请求开始 / 结束
-> 业务初始化开始 / 结束
-> 组件挂载完成
-> 首次可见 / 可交互第二,对页面加载过程做链路拆解。
原始数据里,直播间主体链路和某些常驻功能都能看到明显的挂载完成时间。比如直播间主体挂载完成在 1500ms 量级,个别效果类子应用挂载完成甚至超过 2000ms。
到这里,问题才从"慢"变成可以分析的几类成本:
- 资源请求是否多走了一层链路;
- 缓存时间是否过短;
- DNS、TCP、TLS 是否每次都重新付成本;
- 字体、图片和脚本是否同时阻塞关键呈现;
- 打点和监控是否应该延后初始化;
- 业务代码是否加载了当前场景不需要的内容。
3. 网络链路:先减少不必要的绕路
第一类优化是网络链路。
这次专项里,一个关键动作是把活动相关资源从原有链路切到更直接的业务域名链路,省掉中间代理层。
这类动作对用户不可见,但对加载链路很实际:
- 少一层转发;
- 少一次不必要的连接和等待;
- 资源路径更稳定;
- 异常排查更直接;
- 缓存和 CDN 策略更容易收敛。
很多复杂页面不是某一段代码特别慢,而是资源链路长期演进后变复杂了。域名、代理、CDN、缓存规则、历史兼容策略叠在一起,单看每一层都合理,合起来就会变慢。
所以网络链路优化的核心不是"换个域名",而是让高频资源走更短、更稳定、更容易缓存和排查的路径。
同时,可以对高频关键资源补 DNS / TCP / TLS 预加载能力。
示例代码如下,域名为脱敏示意:
html
<link rel="dns-prefetch" href="//static.example.com">
<link rel="preconnect" href="https://static.example.com" crossorigin>这里要注意边界:预连接不是越多越好。
直播间依赖的资源域名很多,如果所有域名都提前连接,反而会浪费连接资源,影响真正关键的请求。它更适合用于高频、稳定、首屏或常驻组件一定会依赖的资源。
4. 缓存和 CDN:让重复访问不要每次从头来
直播间常驻子应用有一个特点:用户在直播间内停留、切换、返回时,部分页面和资源会被重复使用。
如果每次都按全新页面加载处理,成本会被反复付出。
这次方案里,把页面缓存时间从 60s 调整到 90s。
这个动作看起来很小,但背后是典型取舍:
| 策略 | 收益 | 风险 |
|---|---|---|
| 缓存时间过短 | 版本更新更及时 | 重复访问收益不明显 |
| 缓存时间过长 | 复用收益更高 | 可能带来一致性和回滚问题 |
| 适度延长缓存 | 兼顾复用和更新 | 需要结合业务可接受范围 |
所以这里不是简单把缓存拉满,而是在直播间业务可接受的范围内,让常用页面和资源更容易复用。
CDN 侧也做了基础治理:
- 开启
br或gzip压缩,减少资源传输体积; - 收敛历史 CDN 链路,让静态资源加载路径更稳定;
- 统一关键资源缓存策略,降低排查成本。
这类优化不够"炫",但很适合放进基础治理。因为它改善的是整条资源链路,不只是一两个组件。
5. 资源加载:字体、图片、打点都要给关键路径让路
第三类优化,是资源加载顺序。
直播间页面里,有些资源必须尽早加载,比如核心 JS、CSS、关键业务组件依赖的图片。
但也有一些资源,不应该和关键呈现抢时间。
5.1 字体:不要阻塞内容展示
字体是典型例子。
如果字体加载阻塞内容展示,用户看到的就是空白或延迟呈现。
这次方案里使用了 font-display: swap,让页面优先展示内容,字体后续再替换:
css
@font-face {
font-family: "LiveRoomFont";
src: url("/fonts/live-room.woff2") format("woff2");
font-display: swap;
}同时也可以考虑延迟字体包加载,让关键 JS 和 CSS 先走。
5.2 图片:小体积也会叠成真实等待
活动和常驻组件经常会带很多图片资源。
如果图片体积控制不好,网络传输和解码都会拖慢页面。方案里加入了自动图片压缩,并把部分内联图片从约 10KB 压到约 2KB。
单个数字不大,但直播间里资源数量一多,很多"小体积"加在一起,就会变成真实等待。
5.3 打点和异常监控:不能删,但可以后移
打点和异常监控对线上质量很重要,不能粗暴删掉。
但它们也不能在最关键的呈现阶段抢资源。
更合理的策略是:
- 能异步加载的打点尽量异步;
- 历史冗余打点能删就删;
- 错误监控不要阻塞关键路径;
- 低优先级逻辑延后执行;
- 核心异常仍然保留必要兜底。
这其实是直播间性能优化里很常见的取舍:
text
不是不要监控,而是让监控不要挡在用户看到内容之前。6. 业务代码:真正难的是把"当前不用的东西"拿出去
网络和资源优化之后,业务代码层会暴露出更长期的问题:
text
直播间活动和常驻组件太多,代码会自然变重。项目资料里提到,页面 JS 代码使用率大约只有 35%。这说明用户进入某个直播间场景时,下载和解析的代码里,有不少并没有参与当前场景。
这会带来两个方向。
第一,删除当前不再需要的代码。
这句话听起来像废话,但在长期业务里并不容易。很多活动、组件、兼容逻辑和兜底代码都曾经有存在理由。要删掉它们,需要代码分析、场景确认和回归验证。
第二,重新安排常驻业务的位置。
有些常驻能力每次都要用,而且对用户感知很重要。如果继续作为低优先级子应用被动加载,就会一直拖在后面。
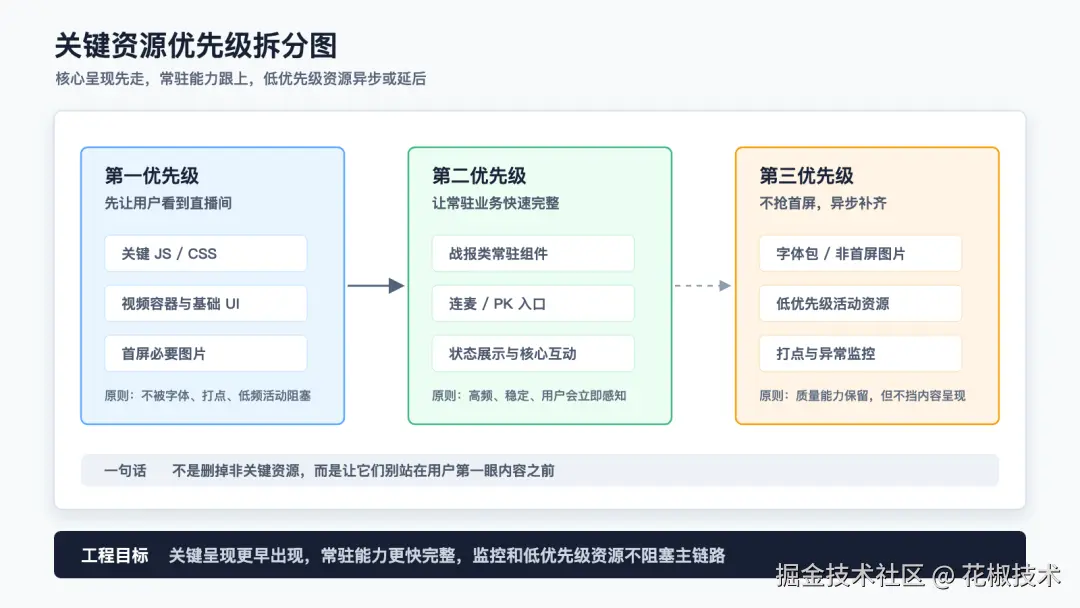
更合理的思路是按优先级分层:
| 层级 | 内容 | 加载策略 |
|---|---|---|
| P0 | 视频、关键容器、首屏必须呈现的常驻能力 | 主链路优先 |
| P1 | 高频稳定业务,如部分连麦、PK、战报类能力 | 提前加载或靠近主应用 |
| P2 | 低频活动、非关键展示、弱首屏依赖能力 | 按需加载 |
| 公共层 | Vue、公共库、打点模块等 | 抽取复用,避免重复加载 |
这里也有反向风险。
如果所有业务都塞进主应用,主包会越来越重,最终又回到另一个性能问题。
所以重点不是"把子应用都前置",而是建立一套分层机制:
- 高频、稳定、首屏相关的能力,更靠近主链路;
- 低频、活动型、非关键能力,延后或按需加载;
- 可以复用的公共依赖,抽出来共享;
- 当前场景不用的代码,不进入首屏关键路径。
这也是后续考虑升级构建体系、用 Module Federation 提取公共类库的原因。
当 Vue、公共库、打点模块这类依赖能被更好地复用,多个子应用之间就不必重复加载同一批基础能力。
7. 优化结果:不是把一个组件往前抢,而是重新编排优先级
阶段总结里,常驻功能"战报牌"的挂载时间从 1550ms 优化到 890ms。
这个数字说明专项优化有效。
但另一个条件同样重要:
text
其他子应用加载基本不受影响。因为直播间不是单组件页面。把一个组件提前,如果代价是其他组件明显变慢,或者视频首帧被影响,就不是完整收益。
这次优化的价值在于,它不是简单把资源往前抢,而是重新做了一次优先级编排:
- 视频和关键呈现优先;
- 常驻高频能力提前;
- 低优先级资源后移;
- 公共依赖复用;
- 网络和缓存成本降低;
- 监控和打点不阻塞关键路径。
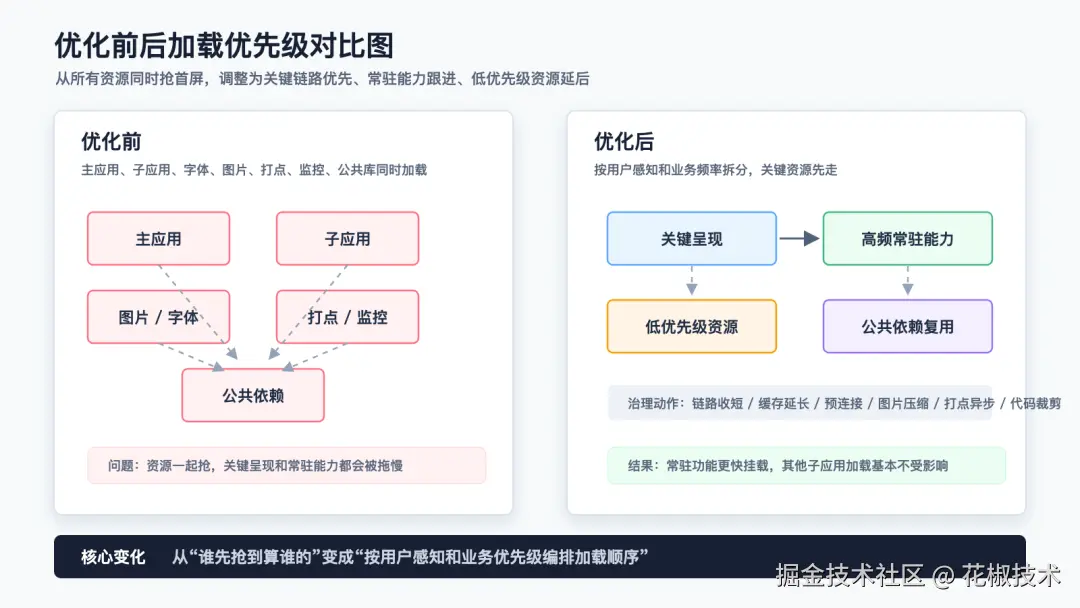
可以简化理解成:
text
优化前:
主应用、子应用、图片、字体、打点、监控、公共库一起抢资源
优化后:
关键呈现优先
-> 高频常驻能力优先
-> 低优先级资源延后
-> 公共依赖复用8. 这类优化最容易踩的几个坑
8.1 指标没定义清楚,就开始堆优化项
页面慢、加载卡、体验差,都不是足够清晰的工程指标。
先确认优化对象是:
- 视频首帧;
- 子应用挂载;
- 完整可交互;
- 某个业务组件呈现;
- 还是用户某个关键操作链路。
指标不清楚,后面很容易变成"网络也改一点、缓存也改一点、代码也删一点",最后很难判断收益来自哪里。
8.2 预连接和预加载做过头
dns-prefetch、preconnect、预加载都能降低等待,但不是越多越好。
关键判断是:
text
这个资源是不是高频、稳定、首屏或常驻能力一定依赖?如果不是,就应该谨慎前置。
8.3 把所有常驻能力都塞回主应用
把高频常驻能力靠近主链路是有效的,但不能把所有业务都塞进主包。
否则短期看某个组件更快了,长期看主应用越来越重,后面每个新业务都会继续把首屏拖慢。
8.4 为了性能牺牲可观测性
打点和监控会带来成本,但不能因为追求加载速度就直接删除关键观测。
更好的做法是:
- 核心异常保留;
- 非关键打点异步;
- 冗余打点清理;
- 监控初始化不要阻塞关键路径。
8.5 只做一次专项,不留下机制
性能优化如果只靠一次专项,很容易回弹。
真正要沉淀的是:
- 加载时间打点;
- 资源体积分析;
- 关键路径优先级;
- 缓存和 CDN 策略;
- 公共依赖复用;
- 构建体系升级;
- 新业务接入规范。
这样后续新组件接入时,才不会重新把页面拖慢。
9. 可复用 checklist
如果你也在做复杂页面或直播间业务的加载优化,可以按这个顺序排查。
指标定义
- 当前优化对象是白屏、首帧、子应用挂载,还是完整可交互?
- 指标口径有没有打点?
- 是否能看到优化前后的分位数据或阶段耗时?
网络链路
- 关键资源是否多走了代理或历史链路?
- 高频资源是否有更短、更稳定的路径?
- DNS / TCP / TLS 是否可以对关键域名做预连接?
- 预连接域名是否过多?
缓存和 CDN
- 页面和静态资源缓存时间是否过短?
- CDN 压缩是否开启,如
br/gzip? - 静态资源链路是否收敛?
- 缓存策略是否兼顾版本更新和回滚?
资源加载
- 字体是否阻塞内容展示?
- 图片是否有压缩、懒加载和体积上限?
- 打点和异常监控是否阻塞关键路径?
- 低优先级逻辑是否可以延后?
业务代码
- 当前场景实际用到多少 JS?
- 历史活动、兼容逻辑、兜底代码是否可以清理?
- 高频常驻能力是否应该更靠近主链路?
- 低频活动是否可以按需加载?
- 公共依赖是否重复加载?
长期机制
- 是否有新业务接入性能规范?
- 是否有资源体积门禁?
- 是否有加载耗时监控面板?
- 是否能定位某个子应用拖慢了主链路?
- 是否把专项经验沉淀进构建和接入流程?
10. 总结
这次直播间常驻子应用加载优化,表面上看是把某个功能的挂载时间从 1550ms 降到 890ms。
但更底层的经验是:
text
复杂直播间页面的性能优化,不能只盯一个页面、一个接口或一个组件。它需要把直播间当成一条完整链路来看:
- 主应用怎么启动;
- 子应用怎么挂载;
- 资源怎么请求;
- 字体和图片怎么让路;
- 打点和监控什么时候初始化;
- 公共依赖怎么复用;
- 常驻业务和低频活动怎么分层。
当这些问题被拆开之后,优化就不再依赖一次性"猛改",而可以变成持续治理。
对直播业务来说,这类工作很基础,也很值得做。
因为用户不会关心背后少了一层代理、提前做了 DNS 解析、压缩了几 KB 图片、延后了哪个打点脚本。
用户只会感受到一件事:
text
直播间是不是更快地完整起来了。花椒技术交流群
还在孤军研究 AI 工程化、AI 编程、Agent 落地,没人同行交流、没人拆解实战?
这里汇聚一线技术从业者,专注代码评审、企业内部 AI 助手真实实战落地。
想紧跟 AI 前沿动态、交流工程落地经验、少走踩坑弯路,欢迎直接加入「花椒技术交流群」。
群内专属福利拉满:每日精选研发向 AI 行业日报、文章独家延伸资料、文中未展开的技术细节,全部同步共享。

若二维码失效,可添加微信:LZ_Aug25,备注「技术群」,我会手动拉你进群。