作者: 吴炳锡,Databend Labs 联合创始人,腾讯 TVP 成员。长期关注数据库、湖仓和云原生数据基础设施,当前主要参与开源云原生湖仓 Databend 的产品与方案落地。
从 2026 年 Snowflake Summit 和 Databricks Data+AI Summit 看,两家公司都不再只讲传统湖仓了。大会关键词已经从 SQL 性能、存储成本、数据治理,扩展到 Agent、AI Gateway、Context、Ontology、MCP、Guardrails、Agent Identity、Cost Control 和 Real-time Serving。
这很容易让人产生一个问题: Snowflake 和 Databricks 是不是在"远离湖仓"?
我的判断相反:他们不是在放弃湖仓,而是在把湖仓从数据存算平台,升级为面向 AI Agent 的数据控制面布局。
过去湖仓解决的是:数据能不能被存、被算、被查。
Agent 时代还要回答:
-
AI 能不能理解数据?
-
Agent 能不能安全调用数据?
-
业务动作能不能基于数据可靠执行?
这篇文章就从两家 2026 Summit 的产品路线、传统湖仓与 Agent 湖仓的需求变化及 Agent 智能湖仓三层架构实现做一个交流。
2026 Summit 两家路线对比
| Snowflake 2026 | Databricks 2026 | |
|---|---|---|
| 主题 | Agentic Enterprise / Making AI Real | Apps and agents that work |
| 业务 Agent | CoWork | Genie One |
| 开发者 Agent | CoCo | Genie Code / Agent Bricks |
| 上下文层 | Horizon Context / Cortex Sense | Genie Ontology |
| 语义指标 | Semantic Views / Semantic Studio | Unity Catalog Metrics |
| AI 治理 | AI Agent Identity / Horizon Guardrails | Unity AI Gateway |
| Operational DB | Snowflake Postgres / Crunchy Data | Lakebase |
| OLTP/OLAP 打通 | Postgres Mirroring / pg_lake / Unistore | LTAP |
| 实时分析 | Interactive workloads / Dynamic Tables / Snowflake RT | Lakehouse RT / Reyden |
| 开放性 | Iceberg + Polaris + OSI + MCP | Delta + Iceberg + open agent frameworks |
| 战略基因 | Enterprise data cloud + governed SaaS-like platform | Open lakehouse + ML/AI platform |
从这张表可以对比上看出,两家公司虽然产品命名不同、技术基因不同,但战略方向已经非常接近:业务入口从 BI 变成 Agent,数据目录从 metadata catalog 变成 AI governance/control plane,湖仓底座开始向 operational data 和 real-time serving 延伸。Snowflake 更偏「受控的一体化企业平台」,Databricks 更偏「开放的开发者与 AI 平台」。它们竞争的核心,也从谁的 SQL 更快、谁的存储更便宜,转向谁能提供更完整的上下文、语义、权限、工具治理和 Agent 运行时控制。
传统湖仓和 Agent 需求对比
| 维度 | 传统湖仓海量数据处理 | Agent 场景 |
|---|---|---|
| 核心对象 | 数据集 / 表 / pipeline | 用户意图 / 业务任务 |
| 主要用户 | 数据工程师、分析师、BI、数据科学家 | 业务用户、运营、销售、财务、客服、开发者 |
| 输入 | 数据源、SQL、任务调度 | 自然语言、业务事件、上下文、目标 |
| 输出 | 表、指标、报表、特征、模型数据 | 答案、报告、解释、建议、自动动作 |
| 数据规模 | TB / PB 级大规模扫描和加工,同一租户下百万张表 | 通常是相关数据切片 + 多源上下文 |
| 优化目标 | 吞吐、成本、稳定性、查询性能 | 准确率、可信度、低延迟、可解释、可控 |
| 系统边界 | 湖仓内部为主 | 跨湖仓、SaaS、文档、邮件、API、工具 |
| 关键资产 | 表、分区、文件、作业、指标表 | semantic metrics、ontology、glossary、lineage、memory、policy |
| 治理重点 | 谁能看什么数据 | Agent 代表谁、能看什么、能调用什么工具、能执行什么动作 |
| 验收方式 | SLA、刷新时间、查询耗时、数据质量 | eval set、答对率、幻觉率、权限违规率、用户采纳率 |
| 失败形式 | pipeline 失败、数据延迟、查询慢 | 答错、编造、用错口径、越权、错误执行动作 |
| 成本模型 | scan、compute、storage、job runtime | token、retrieval、tool call、agent loop、data scan、real-time serving |
可以说湖仓和 Agent 都是面向的数据,但两者的使用者不一样,以至于了出现各种不同的量化指标。
在传统湖仓解决什么:
-
数据接入;
-
存储;
-
计算 & 数据加工;
-
建模;
-
BI;
-
ML;
Agent 场景需要:
Agent 不只是查数据,而是要完成任务。
-
CFO 问毛利为什么下降;
-
销售问帮我准备客户 QBR;
-
数据平台问昨天哪些 pipeline 异常;
需要面对的是:
-
基础的多模型接入(AI Gateway)
-
上下文语义
-
Agent 权限,可以调用工具,可以执行什么动作
Agent 场景不只是把数据捞出来, 这个也问题也不只是Text 2 SQL,也是一个复杂的工程。在这里面两家公司都抛出了不同的解决方案。 整体看这个架构分为了三层,我们一起看看。
Agent 智能湖仓三层架构
Snowflake 和 Databricks 在 Agent 湖仓架构上基本是一样的: 数据面(Data Plane)、上下文面(Context Plane)、智能体控制面(Agent Control Plane)
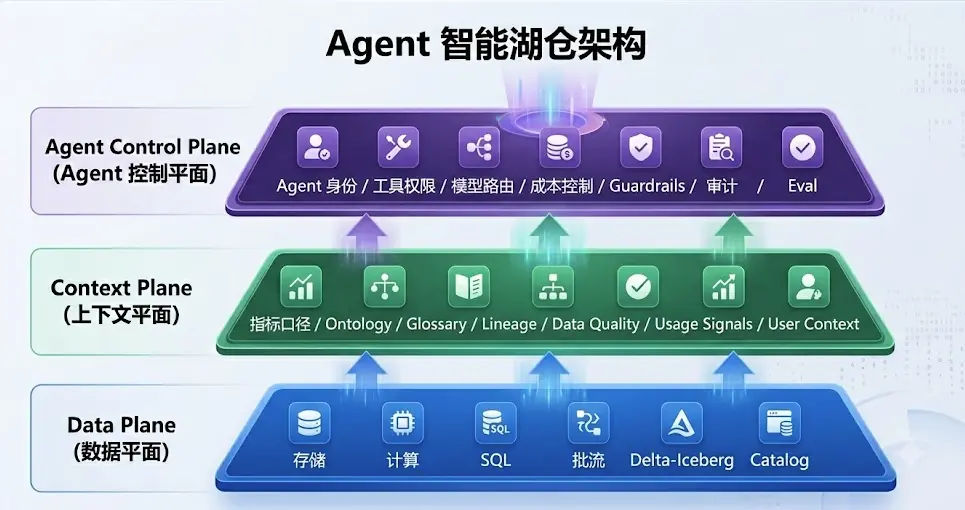
第一层: Data Plane ,解决「数据能不能被存储和计算」
Data Plane 是传统湖仓的核心,也是 Snowflake 和 Databricks 起家的地方,目前集中在 SQL 为王的竞争中。
-
数据存储;
-
计算执行;
-
SQL 查询;
-
批处理和流处理;
-
表;
-
基础 catalog;
-
数据接入、清洗、建模;
-
性能和成本优化;
过去十年,湖仓竞争大多发生在这一层:谁的 SQL 更快,谁的弹性更好,谁的存储成本更低,谁对开放格式支持更好。Snowflake 的传统优势是企业级数仓、弹性计算、数据共享、治理体验;Databricks 的传统优势是 Spark、Delta Lake、开放 Lakehouse、ML/AI 工作负载。
但到了 2026 年,只解决 Data Plane 已经不够了。原因是 Agent 并不是直接消费「表」和「文件」,而是要完成一个业务任务。它需要知道:该用哪个指标、哪个口径、哪个数据源可信、当前用户有没有权限。这就需要第二层
第二层: Context Plane , 解决「AI 能不能理解业务语义」
Context Plane 是 Agent 时代最关键的一层。传统湖仓里,数据虽然已经被存起来、算出来,但对于 AI 来说,这些表和字段仍然只是低语义的信息。比如一个表叫 fact_order,一个字段叫gmv,模型并不知道:
-
GMV 在这家公司到底怎么算;
-
它是否含税;
-
是否包含退款;
-
是否包含取消订单;
-
哪个表才是官方可信表;
-
哪些字段有质量问题;
-
这个指标和哪些 dashboard / 下游报表有关;
-
销售口径和财务口径是否一致。
所以 Agent 要想给出可信答案,必须依赖 Context Plane。
Context Plane 包括:
-
指标口径;
-
semantic metrics;
-
ontology;
-
商业术语;
-
表和字段描述;
-
数据血缘;
-
data quality signals;
-
usage signals;
-
certified datasets;
-
user / role context;
-
agent memory;
这也是为什么 Snowflake 在讲 Horizon Context / Cortex Sense,Databricks 在讲 Genie Ontology / Unity Catalog Metrics。通过上述的技术,把原来工程师理解的: 业务语义,指标口径,数据血缘,质量信号和使用经验,变成 AI Agent 可以消费的上下文。 如果没有 Context Plane,Agent 就会退化成一个会写 SQL 的聊天框。它可能能查出一个数,但很难保证用的是正确表、正确口径和正确上下文。
第三层: Agent Control Plane ,解决「AI 能不能安全上生产」
有了数据和上下文,还不够。 Agent 一旦进入生产环境,就不只是回答问题,必须在权限、成本和审计边界内执行任务。。它可能会:
-
访问敏感数据;
-
跨系统查询;
-
调用 CRM、Jira、Slack、邮件;
-
生成报告;
-
开工单;
-
触发审批;
-
甚至写回业务系统。
这时平台必须回答一组新问题:
-
这个 Agent 是谁?
-
它代表哪个用户?
-
它能看哪些数据?
-
它能调用哪些工具?
-
它能不能把数据发出去?
-
它调用模型花了多少钱?
-
它是否被 prompt injection 攻击?
-
它的每一步能否审计?
-
它答错了,能不能被评估和纠正?
这就是 Agent Control Plane 要解决的问题。
Agent Control Plane 包括:
-
agent identity;
-
per-agent RBAC;
-
tool access control;
-
MCP governance;
-
model routing;
-
spend cap / budget;
-
guardrails;
-
prompt injection 防护;
-
data exfiltration detection;
-
audit log;
-
eval / benchmark;
-
human-in-the-loop approval。
Snowflake 对应推出 AI Agent Identity、Horizon Guardrails、Natoma MCP Gateway;Databricks 推 Unity AI Gateway、Agent Bricks、Omnigent。
依据三层对两家产品做一个映射参考
| 分层 | 解决问题 | Snowflake 对应的产品/能力 | Databricks 对应的产品/能力 |
|---|---|---|---|
| Data Plane | 数据能不能存、算、查 | Snowflake Warehouse、Dynamic Tables、Iceberg、Polaris、Datastream、OpenFlow、Snowflake PostgreSQL | Lakehouse、Delta Lake、Iceberg、Spark、Lakeflow、Lakebase、Lakehouse RT |
| Context Plane | AI 能不能理解数据 | Horizon Context、Cortex Sense、Semantic Views、Semantic Studio、Horizon Catalog | Genie Ontology、Unity Catalog Metrics、Business Glossary、Domains、Unity Catalog |
| Agent Control Plane | Agent 能不能安全上生产 | AI Agent Identity、Horizon AI Guardrails、AI Security Posture Management、Natoma MCP Gateway、AI Cost Controls、CoWork / CoCo governance | Unity AI Gateway、Agent Bricks、Omnigent、Catalog Federation、Automatic Identity Management、Genie governance |
Snowflake 和 Databricks 都在从底层 Data Plane 向上补 Context Plane 和 Agent Control Plane。
为什么 Snowflake / Databricks 必须从湖仓上移到 Agent 智能湖仓
在 Snowflake 口号还是ONE PLATFORM THAT POWERS THE DATA CLOUD, Databricks 是 One open platform for data analytics 时,两者原来是一个 SQL 为切入,另一个以 spark 为切入。分别独占一部分,但后面两者基本是越来越近,也是直接开启 Benchmark 模式。
Databricks 直接的性能测试提出了: Cost Over Time ,SQL 更快更省钱
Snowflake 比稳的提出了: Costly Admin hour , 投入时间更少
但底层计算能力上限很容易达到,过分的 benchmark 产出的效益并不明显;
另外其它湖仓的产品的成熟,例如: Databend 从 Day One 就定义在 Snowflake like , 代码开源从性能测试上看也优于 Snowflake ,和 Snowflake 保持了90%+ 的兼容度,同期云数仓、开源分析引擎、Lakehouse 引擎、流处理和实时数据平台也在不断演进包括: Clickhouse,Databend, BigQuery, Redshift, DuckDB, Dremio, Athena, Trino, Spark, Flink, RisingWave , TiDB Lake 可以这些产品的展状态,也给两者带来非常大的压力,在单纯湖仓, SQL 性能和成本,这些方向很容易卷的就是给云厂家打工。
再次随着 AI 的出现,原来数据分析的行为也在发生着变化:
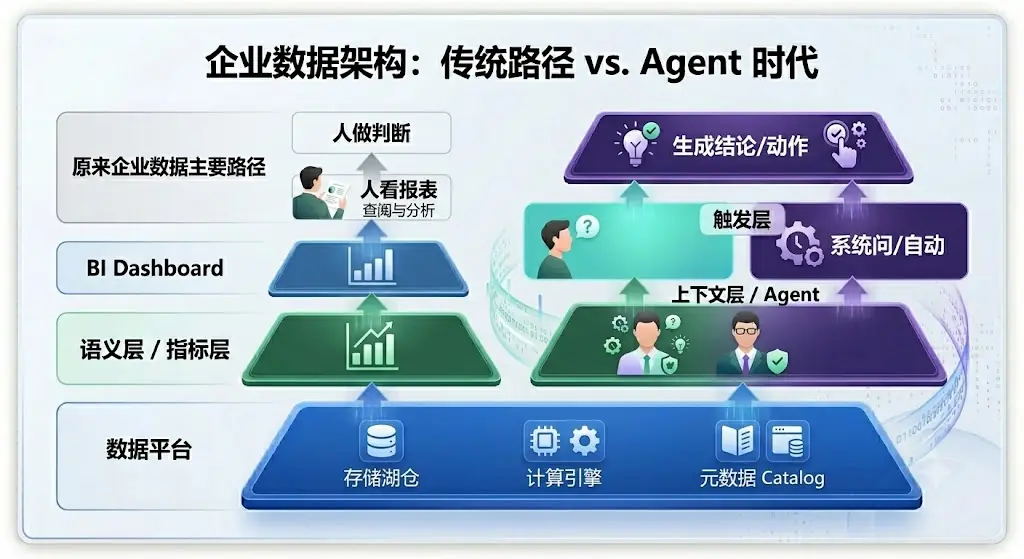
在当前 Agent 成为新的工作入口, 如何方便 Agent 接入到湖仓平台也变的更加重要,而通过系统的工程给 AI 能提供一套完整的语义,权限管理,上下文,成本控制和审计也成为产品更重要的一部分。
所以,Snowflake 和 Databricks 不是在放弃湖仓。它们真正看到的是:传统湖仓的 Data Plane 已经不够支撑下一代企业 AI。Agent 时代,湖仓必须向上长出 Context Plane 和 Agent Control Plane。过去,湖仓的核心 KPI 是: 数据能不能被统一存储、治理和分析。未来,Agent 湖仓的核心 KPI 会变成:业务问题能不能被准确回答,业务动作能不能被安全执行。这也是为什么两家公司都在密集发布 Agent、Ontology、AI Gateway、MCP、Guardrails、Identity、Cost Control 相关能力。它们不是偏离湖仓,而是在重定义湖仓的边界。
最后 对 Snowflake 和 Databricks 来说,目标是成为企业 AI Agent 的控制面。让 AI Agent 能够在可信数据、明确语义和可控权限之上,安全地完成业务任务。来快速抢占 AI Agent 入口。
对 Databend 机会不是复制 Snowflake CoWork 或 Databricks Genie,去做一个完整的企业 AI 工作台,而是把自己做成 Agent-ready data platform 的底层执行与上下文供给层。
这意味着,在外部 Agent、AI Gateway、BI Copilot 或开发者工具之下,Databend 可以承担三类角色:
第一,作为开放的数据执行层,让 Agent 以 SQL / API 的方式访问可信数据;
第二,作为低成本的上下文供给层,承载 JSON、trace、日志、文档、向量等多形态数据;
第三,作为 Snowflake-like 但更开放的替代底座,通过 S3-native、Parquet-native、开源内核和更透明的成本模型,降低企业把 Agent 接入数据平台的复杂度和成本。
最终,我依然相信湖仓还是星辰大海。也欢迎更多开发者、创业者和基础设施团队一起,创造更好用、更开放、更可信的数据基础架构。湖仓下一站不只是更快的 SQL,也不只是更便宜的存储,而是: 让 AI Agent 能够在可信数据、明确语义和可控权限之上,安全地完成业务任务。这会是下一代数据平台竞争的核心。