上一篇(MAI-03)讲了 Scaling Ladder 和 EG:架构或数据改动划不划算,要在多个模型尺寸上对照 loss 和算力成本。本篇只回答:30T 语料从哪来、怎么处理、和「干净数据」在工程上指什么。
报告 §2.4 把语料拆成网页 HTML、PDF、书籍期刊、公开 GitHub 几条管线,共用抽取、去重、过滤、分桶那一套流程。和 MAI-01「学而非抄」一致:The Pile、RedPajama 等开源训练包不进炉,预训练不用 LLM 合成语料,crawl 里还要主动剔 AI 生成内容。
微软发布时讲的 clean data,在报告 §2.4 里是一串可执行的 in-house 步骤:爬取、抽取、去重、过滤、分桶、ablation,从源数据到进 mix 都在内部完成。具体买了哪些第三方包、供应商是谁,报告出于隐私和法律原因不写(§2.4.1),却把 HTML、PDF、GitHub 各管线的筛选步骤和规模数字写得很细。
数据从哪来:六大类 + 知识截止日
30T 主预训练 + 3.55T mid-training 的语料,覆盖(§2.4):
| 类型 | 说明 |
|---|---|
| 网页 HTML | 自有爬虫 + Common Crawl |
| 网页 PDF | 教育、技术、专业文档 |
| 公开 GitHub | 代码为主,约 7.4T token 量级(处理前) |
| 书籍与期刊 | 出版社/第三方授权 |
| 新闻、多语、领域资料 | 同样经爬取、抽取、去重后进 mix |
Table 4 按源写了知识截止日------各源 cutoff 不同,不是全库统一一个日期:
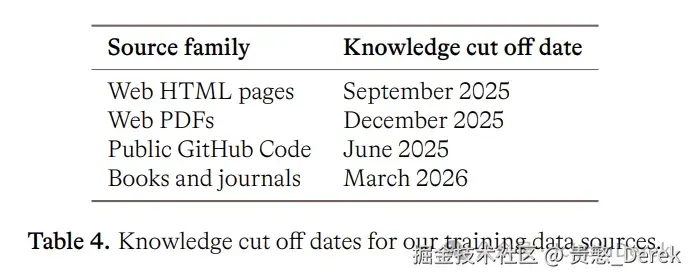
Table 4:各训练源 knowledge cutoff(Web HTML 2025-09,Web PDF 2025-12,GitHub 2025-06,书籍期刊 2026-03)
网页 HTML 到 2025 年 9 月,GitHub 到 2025 年 6 月,书籍期刊到 2026 年 3 月;Web PDF 单独到 2025 年 12 月。晚于对应 cutoff 的内容,不会进入该源的 pretrain。
明确不用的:微软产品/服务的私人客户数据(除用户明确 opt-in 或协议覆盖);常见 ML 托管站(huggingface.co 及镜像)从网页源剔除,减轻评测题渗进训练的风险。
授权与治理:能说的边界
§2.4.1 写了几条和语料直接相关的规矩:
- 网页:自有爬虫,遵守 robots.txt 及 meta/HTML 控制;排除违反微软 Responsible AI 政策、USTR「 notorious markets」名单的源。
- 第三方数据:经商业协议采购,尽调试权属和使用权,但不披露供应商名称。
- 训练前全库过 PII 风险与安全过滤。
报告里的「干净」主要指处理链和授权说得清楚:爬什么、怎么滤、第三方怎么采买,每一步能对上规则。他们也承认 AI 检测会漏、去重做不到满分;内部改数据仍主要看私有 NLL(MAI-03),不用公开 benchmark 当日常依据。
网页 HTML:从 1.2 万亿页到可训文档
Figure 4 把 HTML 管线画成一条总线:上方 Proprietary Crawl 与 Common Crawl 两路并进,先过 Trafilatura 抽正文、内容过滤、MD5 精确去重和 MinHash 模糊去重,再跨源去重并生成 embedding;下方拆成 General Web (质量模型 + 英文底部 70% 过滤)、STEM 、Code 、Key Domains 四条子管线,最后汇入 Central Pipeline 做去污和 AI 内容过滤。下面按两路 crawl 写 Appendix B 里的漏斗数字。
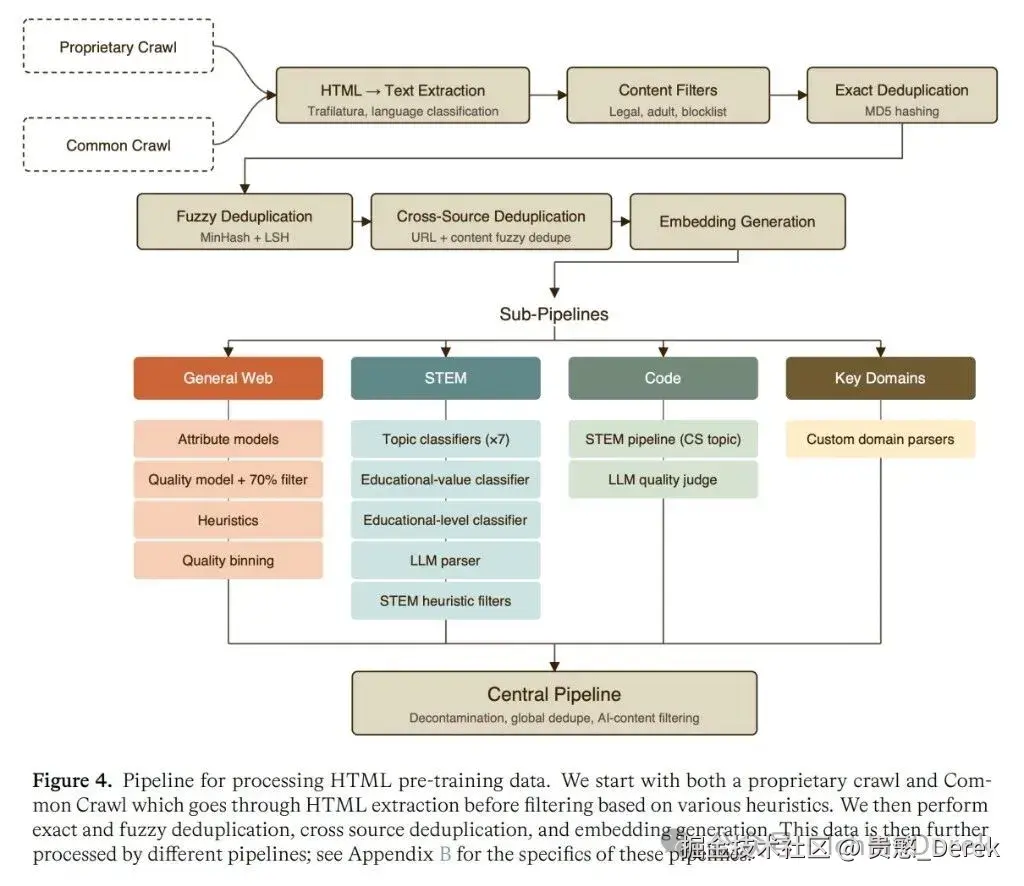
Figure 4:HTML 预训练数据处理管线(自有 crawl + Common Crawl → 去重 → embedding → 四条子管线 → Central Pipeline)
自有爬虫 约 1.2 万亿 页面抓取 → 默认用 Trafilatura 抽正文 + 语言识别 → 政策/成人内容/与 PDF 重叠/黑名单过滤 → 7940 亿 页。
接着:
- AI 生成内容检测:专有模型打分 + 人工抽查域名,高 AI 浓度域名整域剔除;
- 精确去重 (MD5):7940 亿 → 4230 亿 文档;
- 模糊去重 (MinHash LSH,阈值 0.8):英文约 734 亿 、非英文 1165 亿 文档。
Common Crawl
约 3000 亿页 → 每 URL 只留最新快照 → 约 1000 亿 → 同样过滤、去重 → 与自有库合并后再做 URL/内容级去重 → Common Crawl 这一路约 242 亿 页。
通用英文网页
embedding 属性模型(教育价值、事实可靠性、写作质量、推理含量等)→ 质量模型砍掉 英文底部 70% → 再加 Gopher 式启发式 → 自有 crawl 约 46 亿 、Common Crawl 约 28 亿 英文文档进入 mix 候选。
筛到最后,自有 crawl 约 46 亿、Common Crawl 约 28 亿英文文档才进 mix 候选,前面还隔着 AI 检测、两轮去重、embedding 质量切分和 Gopher 过滤。
抽取:没有万能解析器
§2.4.2 里有个反复出现的麻烦:数学、代码、表格在网页上格式很不统一,通用抽取器常常把公式和代码块弄丢,只留下周围正文。
他们按源选法:
| 方法 | 用在哪 |
|---|---|
| 结构化解析 | 标准 HTML/XML schema |
| 手工 BeautifulSoup 抽取 | 结构稳定、价值高的域名 |
| LLM/agent 处理 | 难规范化处------只能保留或删除原文片段,不能生成新字 |
| 原样训练 | 如 Wikipedia wikitext:工具不成熟时,宁可 3× 冗长 也保留完整 markup |
理科类网页单独走一套抽取:Trafilatura 保不住公式时,自研 HTML→Markdown,MathML/LaTeX 规范化,按 section 切分,LLM 只对每段做留或删,不能改写,更不能生成新字,再 OpenWebMath 风格清洗。产出英文 STEM 约 680B token(数学相关 76B);多语 STEM 再加 760B token(数学高质量约 58B)。
预训练阶段不用 LLM 合成的段落当训练 token,但允许 LLM 在管线里做过滤和标注------刚才 STEM 抽取里的留删就是这类用法,写进语库的仍是 crawl 下来的原文。
计算机主题网页沿用上面的 STEM 抽取流程,再用 Qwen3-30B 给文档打质量分------prompt 用 GEPA 在约 2000 条人工标注上调过,启发式过滤之后留下约 233B token。
去重:五层冗余,大模型更怕重复
稀疏大模型记性强:同一内容在语料里重复出现,模型容易整块记住,跨域泛化反而变差。§2.4.3 因此把去重当成 scaling 问题,不只是删垃圾。从删样板说起,依次过精确去重、MinHash 近重复、模板页清理和 embedding 语义聚类。
- 样板删除:导航栏、页脚、侧栏等跨页重复块;
- 精确重复:字节/哈希级;
- 模糊重复 :MinHash LSH,相似度 ≥0.8;
- 模板页:计算器站、批量生成页------骨架化后整族删除;
- 语义重复:Qwen3-Embedding-0.6B 聚类,每簇只留少量代表(代码里经典题解大量撞车)。
跨数据集去重(global drop-order)
多源之间预先排好 数据集优先级 。同一内容在多个源里被 fuzzy/语义去重判为重复时,只留在优先级最高的那个源,其余源里的副本删掉。改一个源的配比或处理链,可能把「有效 token」悄悄挪到另一源------所以数据 ablation 必须带着 drop-order 一起分析(MAI-05 讲 mix 时会再详讲)。
报告里多次实验看到,去重做得严,预训练 NLL 和下游推理榜会一起涨------重复多了,大模型会更早吃满语料里的 unique 信息,后面 scaling 受益有限。
过滤与分桶:为「配比」服务
§2.4.4 的目标是把杂 corpus 变成 可控制的桶:质量档、语言、主题、教育层级、源类型等。
手段组合:
- 元数据:域名、GitHub 路径;PDF 还会读 creator、producer 字段,用来拦 SEO spam;
- 启发式规则:滤 OCR 乱码、STEM 用的数学友好过滤、按路径或内容识别生成代码;
- 学习型分类:fastText 和 embedding 模型,给语言、主题、教育价值、质量等打分;
- 难例交给 prompted LLM:例如按 section 决定留删、给质量打分;
- 人工抽查容易出错的样本,把典型 failure mode 标出来,再拿去训分类器和 LLM judge;
过滤去掉 spam、低质段和违规内容;分桶给语料贴上质量、语言、主题、教育层级等标签。没有这一层,后面没法按源族做 mix ablation、逐桶调权重------配比怎么选,留到 MAI-05。
GitHub:7.4T 代码的三张表
公开 GitHub 处理前约 7.4T token,按 files、commits、PRs 三类打包,共享同一套过滤、去重、去污和质量打分:
| 数据集 | 内容 | 打包后约 token |
|---|---|---|
| Files | 各 repo 文件最新版,按 repo 深度优先拼序列 | 1.26T |
| Commits | 每 repo 最近 10K commit;前缀为改前文件(mask),训练 patch | 4.5T |
| PRs | 标题、body、review、issue、有序 commit patch 等 | 1.19T |
共享处理要点:
- 去掉
node_modules、_pb2.py、.d.ts等生成物与二进制; - SHA-512 精确去重 + MinHash + embedding 语义去重;
- 对 推理训练/评测用编程题 去污;
- PR 额外对 SWE-bench Verified 去污------删掉 benchmark 用到的 PR。
Commits 和 PR 都用同一套做法:改动前的文件内容放在前面,不算训练目标;后面那段 patch 才是模型要学的部分,格式是 git diff 或 search-and-replace。
PDF 与书籍
Web PDF(B.2):约 100 亿文档 → 启发式+分类器 → 6.2 亿进深度处理;Azure Document Intelligence OCR → 公式/表格规范化、去参考文献、SEO spam 过滤 → 模糊去重后约 1.8T 英文 + 1.85T 多语 token。
书籍期刊(B.3):按供应商定制 ingestion → 统一文本 → OCR 清洗 → 去重 → LLM 打主题/质量标签供 mix 使用(标注,不是合成正文)。
数据也要走 ablation
§2.4.5 要求每个源处理完都要 ablation,在 scaling ladder 上量有没有真增益------和 MAI-03 讲架构改动时是同一套梯子。两种做法:
- 单源 ablation :把目标源 加权到 mix 的 50%,从头训,看边际贡献;
- 梯子 ablation :在完整 mix 里去掉/替换某源,用 scaling ladder 外推 最终 30T scale 下的效果。
报告在 §2.4 里多次写到:认真迭代数据质量,对预训练 NLL 和下游推理任务都很要紧,不能指望单靠把 token 数顶上去。
「干净数据」对你意味着什么
若你做企业应用
溯源、授权、PII、剔除 AI 垃圾页,在企业场景里往往比 public benchmark 更早被问到;报告 abstract 把这类 in-house 处理称作 enterprise-grade data。
若你做研究或中小团队
全抄 in-house 爬虫不现实;可搬走的是 分层逻辑:
- 评测/训练去污(20-gram、HF 域剔除、SWE PR 剔除);
- 多级去重(精确 → 模糊 → 语义);
- 用 EG / 单源 50% ablation 验证一批数据是否真值;
- LLM 只当 filter/label,不把生成段当预训练语料。
全链路 in-house 意味着要自己养 crawl、dedup、分类和质量 ablation 的团队,中间产物占存储,embedding 和 fuzzy dedup 吃算力,书籍期刊还要走采购和法律尽调。The Pile、RedPajama 整包不在选项里,上面这些投入省不掉。
三条 takeaway
1. 干净 = 全链路 in-house,且不用开源包、不用 LLM 合成、剔 AI 页
不开源训练包、不 LLM 合成预训练、尽力剔 AI 生成 crawl;LLM 可用于抽取决策,但不扩写进语料。
2. 去重是能力问题,不是卫生问题
大 MoE 怕重复;跨源 drop-order 让「加了一份数据」的真实效果取决于优先级设计。
3. 质量迭代靠 ablation,不靠 gut
单源 50% 与 ladder forecast,和 MAI-03 同一套 EG 流程衔接。
局限
§2.4.1 不披露完整数据源和供应商名单,外部也没法逐条复现 mix 权重;能读到的是各管线的处理步骤和漏斗数字。AI 检测和去重都会漏,报告因此主要靠私有 NLL 跟踪迭代,而不是只看公开 benchmark。
Appendix B 对网页、GitHub 写得很细,新闻等领域只有几笔,多半是篇幅分配,不是说这些源可忽略。Table 4 各源 cutoff 之后的内容,不会进对应 pretrain;更晚的信息要靠 mid-training 和后面 RL 阶段补。30T 说的是主 pretrain 一共消耗多少 token,和各源 knowledge cutoff 是两套数字。
下一篇
MAI-05 讲数据配比:183 个小模型、61 种 mixture、Pareto frontier(Figure 5,§2.5)------在「炼好的桶」之间,权重怎么选才不是拍脑袋。本篇是炼;下一篇是配。
依据:Microsoft AI, MAI-Thinking-1: Building a Hill-Climbing Machine §2.4, Table 4, Figure 4, Appendix B (B.1--B.4)。