遇到的问题及思考:
1. Dataloader中 collate_fn 作用:
核心作用就是自定义批处理逻辑 。当 DataLoader 从 Dataset 中取出 batch_size 个样本后,不会直接堆叠,而是把它们全部交给 collate_fn 函数,由这个函数进行处理最终返回给模型的数据。
可以用于在Bert模型构建dataloader时,将文本转为张量
2.训练过程中如何缓解过拟合?
训练过程中,评估在验证集上的表现。
acc在多个迭代中,不再提升,停止训练。
多个迭代的次数,可以任务设置,称为patience 耐心器
1.项目背景
对于今日头条来说, 正对不同的用户推送不同的新闻类别. 比如男生的历史, 军事, 足球等, 女生的财经, 八卦, 美妆等. 如果能将用户更感兴趣的类别新闻主动筛选出来, 并进行推荐阅读, 那么点击量, 订阅量, 付费量都会有明显增长
基于上述业务需求背景, 字节内部在今日头条app的推荐系统模块中, 需要内嵌一个子任务: 将短文本自动进行多分类, 然后像快递一样的"投递"到对应的"频道"中, 因此"投满分项目"应运而生。
2.数据集

2.1 数据集介绍
2.1.1 日志数据
**定义:**公司应用日常打印、记录的日志信息。通常以非结构化或半结构化形式存储(如TXT、JSON、EXCEL),捕捉用户行为、系统操作或错误信息。
例如包括用户行为埋点日志、app系统性能埋点日志(例如API响应时间)、广告埋点日志、搜索埋点日志等等。
特点:
数据较为驳杂,和数据无关的内容较多,需要处理
数据量较大,每日亿级至十亿级行甚至更多
2.1.2 业务数据
**定义:**业务数据是公司核心业务流程生成的数据,结构化存储在数据库(如MySQL、Hive),记录业务实体或交易,字段明确,更新频率较低。
例如:订单类数据记录用户付费行为(如订阅会员、打赏),用户类数据记录用户信息和画像(如年龄、兴趣偏好)
**特点:**结构化,数据量中等(百万至千万级行)
2.1.3 第三方数据
**定义:**从外部公司购买、公开数据集或API获取的数据,非公司内部生成,格式多样,质量参差不齐。
例如:电信运营商提供的用户画像数据,基于用户通话、流量使用、地理位置等生成兴趣标签、消费能力、行为特征,增强推荐系统精准性。
**特点:**格式多样,数据量小至中等(千行至百万级行等)。且需整合清洗,可能涉及费用。
2.1.4 项目数据概览
本次是属于内部项目,实际项目中的数据来源有多种情况,本次的数据是公司数据平台提供成品数据:

第一类: 内部项目,公司内部数据部门提供
- 情况1: 数据平台有预处理, 提供的是"成品数据".
- 情况2: 数据平台没有预处理, 只告诉开发人员"数据路径".
- 情况3:数据平台有部分数据,但需要增加第三方数据.
- 情况4: 原始数据就没有, 需要开发人员沟通不同部分, 来最终得到数据.
第二类: TOB项目,甲方提需求, 并提供数据
- 情况1: 甲方有预处理数据, 提供的基本是"半成品数据".
- 情况2: 甲方只负责"埋点", 后续数据需要开发人员处理.
- 情况3: 甲方数据"匮乏", 甚至数据"缺失".
第三类: 其他
- 实际可能还存在其他情况,这里不继续拓展。
2.1.5 投满分项目数据集
以下是投满分项目数据集,这里快速预览
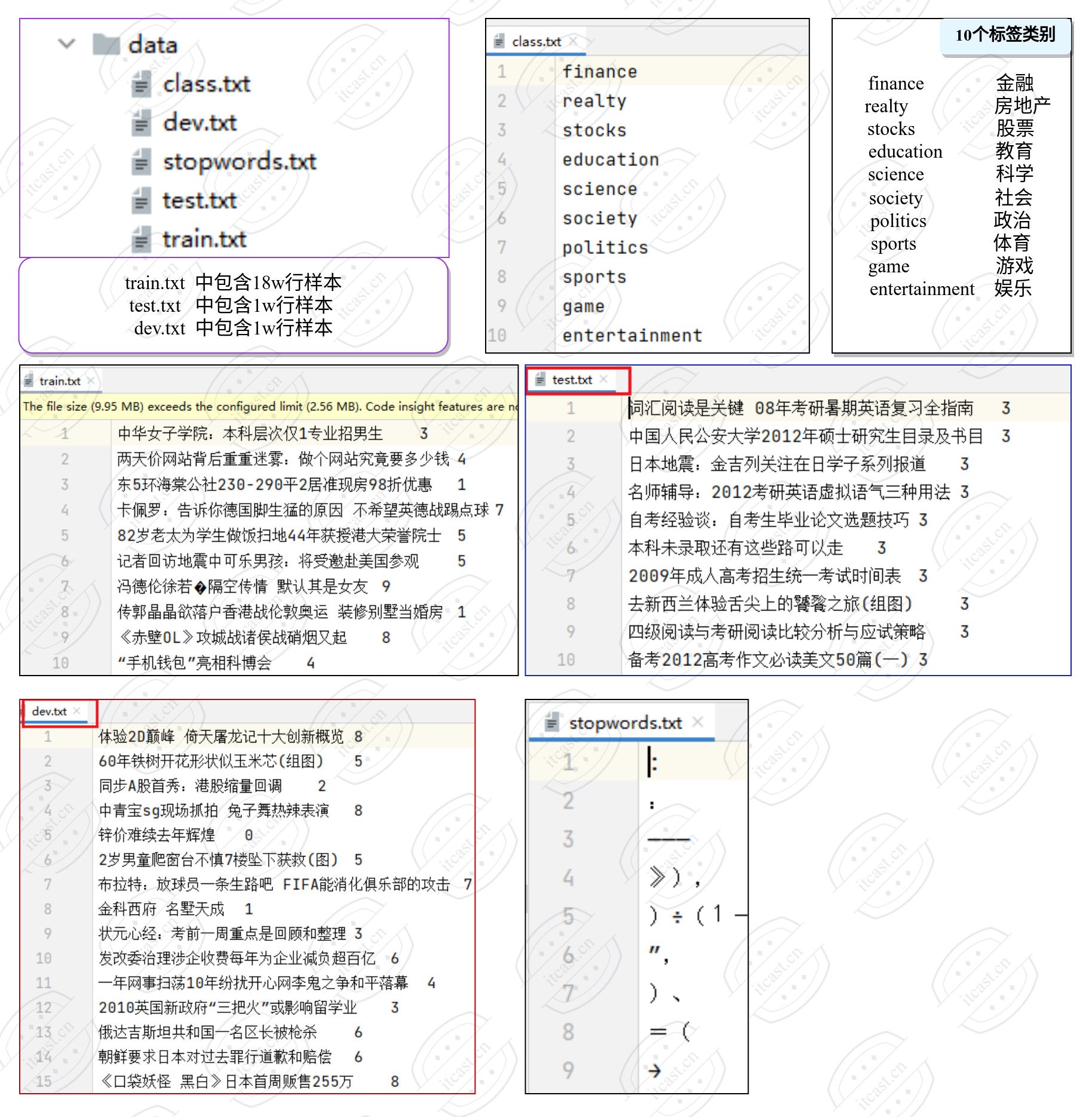
数据文件:
数据位置:D:\course\nlp_classifier\TMF\05-code-edit\01-data
class.txt 为标签文件,包含10个类别标签, 每行一个标签, 为英文单词的展示格式.
train.txt 为18w条样本,10个类别,每个类别是1.8w。每行包括两列, 第一列为文本, 第二列是标签, 中间用\t作为分隔符.
test.txt 为1w条样本,每行包括两列, 第一列为文本, 第二列是标签, 中间用\t作为分隔符.
dev.txt 为1w条样本,每行包括两列, 第一列为文本, 第二列是标签, 中间用\t作为分隔符.
2.2 数据集分析
2.2.1 代码逻辑图
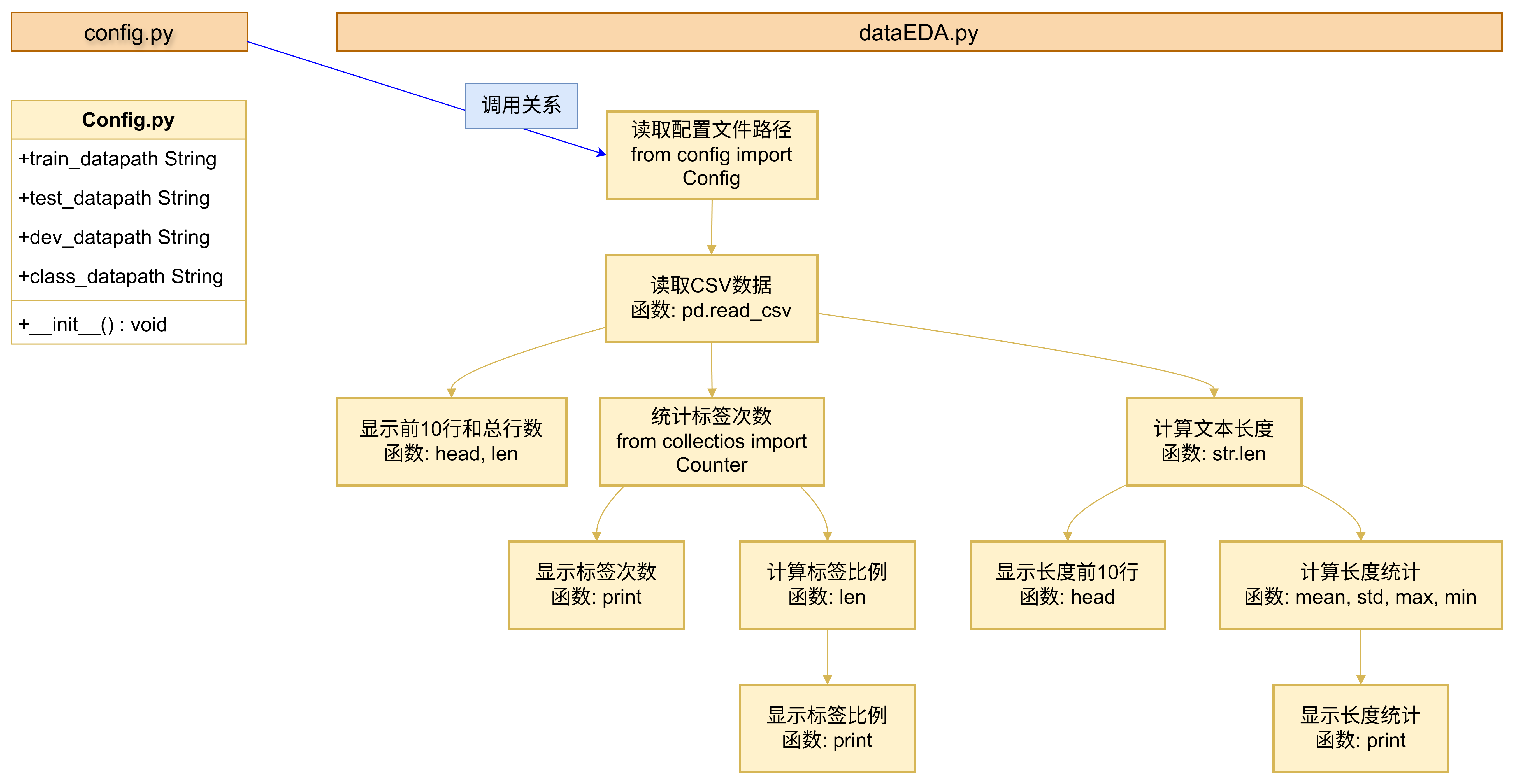
2.2.2 代码实现
python
class EDAConfig(object):
def __init__(self):
self.rf_test_path = r'D:\python\project\python_adv\pythonProject\toumanfen\RandomForest\data\test.csv'
self.rf_dev_path = r'D:\python\project\python_adv\pythonProject\toumanfen\RandomForest\data\dev.csv'
self.rf_train_path = r'D:\python\project\python_adv\pythonProject\toumanfen\RandomForest\data\train.csv'
if __name__ == '__main__':
config = EDAConfig()
print(config.test_path)
python
import pandas as pd
import jieba
from config.DataConfig import EDAConfig
def preprocess(path, handler_path):
# 读取数据
data = pd.read_csv(path, sep="\t", names=["text", "label"])
# 数据分词
# 每行分词、join
# 添加分词后数据到原始数据
def tokenizer(text):
return " ".join(jieba.lcut(text))
data["words"] = data["text"].apply(tokenizer)
# 保存
data.to_csv(handler_path, index=False)
if __name__ == '__main__':
cng = EDAConfig()
# path = r'D:\python\project\python_adv\pythonProject\toumanfen\data\test.txt'
# handler_path = r'./data/test.txt'
preprocess(cng.test_path, cng.rf_test_path)
preprocess(cng.train_path, cng.rf_train_path)
preprocess(cng.dev_path, cng.rf_dev_path)3.模型训练与部署
3.1 随机森林模型
为什么要做基线模型**(Baseline Model)**?
①快速验证任务可行性:基线模型通常简单高效,能够快速验证数据和任务的可行性,为后续优化提供方向。
②提供性能参考:基线模型的性能为后续复杂模型(如深度学习模型)提供对比基准,衡量改进效果。
③降低开发成本:基线模型实现简单,能在资源有限的情况下快速构建一个可用的解决方案。
④发现问题:通过基线模型的训练和评估,可以发现潜在的一些问题,例如数据质量问题。
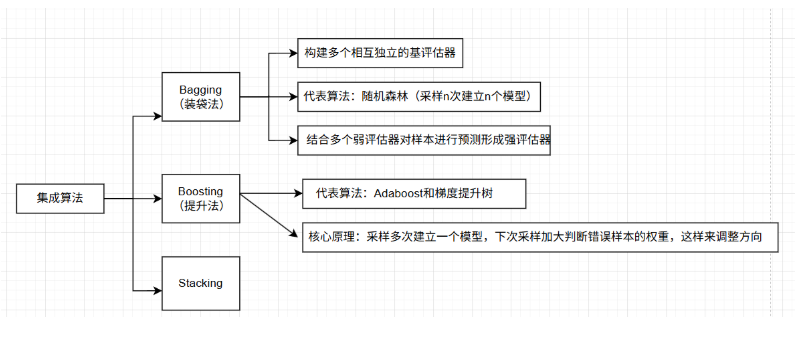
3.1.1 原理
-
定义:将多棵树集成的一种算法
-
基本组成:决策树(弱学习器)
-
随机森林如何体现随机性?
-
随机样本随机
-
随机特征随机
-
-
随机森林的算法构建过程?
-
从提供的数据中随机抽样出不同的子集(样本及特征的随机抽取),来建立多棵不同的决策树
-
按照Bagging的规则对单棵决策树的结果进行集成
注意:回归任务取平均值;分类任务遵循少数服从多数的原则
-
3.1.2 如何实现将文本转化为数值向量的向量化?
实现步骤:
① 构建词表: 计算每个词对应 TF-IDF 数值,
② 文本按行转换:将文本的每一行的每个词根据词表转换为TF-IDF 数值,填充在对应索引位置:
c1,0,0,c2...cn
文本行中分词后,行向量的长度等于词表大小
c1,c2,cn分别为行中分词对应的TF-IDF值,将其填到对应的索引处,其它地方用0补充
③ 转换后文本 \[行数,词表个数]
TF-IDF介绍:
TF-IDF(term frequency--inverse document frequency,词频-逆向文件频率)是一种将文本转化为数值向量的向量化方法。它由两部分组成,TF 和 IDF。
- TF 为term frequency,即词频。衡量一个词在一篇文章里出现的频率(出现的次数除以文章总词数)。
- 逆文档频率(inverse document frequency):IDF 用来衡量一个词在所有文章中的"独特性",在所有文档中出现的次数。如果一个词只在少数文章中出现(很罕见),它就更能代表这些文章的特殊内容,IDF 分数高,说明它很重要;如果一个词几乎每篇文章都有(很常见),它对区分文章内容没太大帮助,IDF 分数低,说明它不重要。
TF-IDF 计算:
① TF
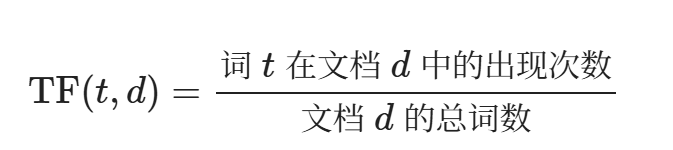
② IDF
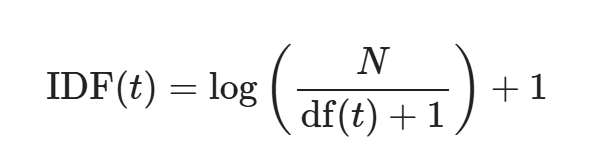
参数:
( N ): 总文档数。
df ( t ) 的文档数:含有指定词的文档树
示例:IDF("本科") =log(5/2) +1 ≈ 0.398
③ TF-IDF = TF * IDF,值越大,对应的词就越重要
3.1.3 代码实现
**① 配置文件:**config/DataConfig.py
python
class EDAConfig(object):
def __init__(self):
# 随机森林模式文件
self.rf_test_path = r'D:\python\project\python_adv\pythonProject\toumanfen\RandomForest\data\test.csv'
self.rf_dev_path = r'D:\python\project\python_adv\pythonProject\toumanfen\RandomForest\data\dev.csv'
self.rf_train_path = r'D:\python\project\python_adv\pythonProject\toumanfen\RandomForest\data\train.csv'
# 随机森岭模型保存
self.rf_transformer = r'D:\python\project\python_adv\pythonProject\toumanfen\RandomForest\model\transform.pkl'
self.rf_estimator = r'D:\python\project\python_adv\pythonProject\toumanfen\RandomForest\model\estimator.pkl'
# 随机森林预测结果保存
self.rf_predict_path = r'D:\python\project\python_adv\pythonProject\toumanfen\RandomForest\data\predict.csv'② txt文件处理为csv文件,并进行分词
python
import pandas as pd
import jieba
from config.DataConfig import EDAConfig
def preprocess(path, handler_path):
# 读取数据
data = pd.read_csv(path, sep="\t", names=["text", "label"])
# 数据分词
# 每行分词、join
# 添加分词后数据到原始数据
def tokenizer(text):
return " ".join(jieba.lcut(text))
data["words"] = data["text"].apply(tokenizer)
# 保存
data.to_csv(handler_path, index=False)
if __name__ == '__main__':
cng = EDAConfig()
# path = r'D:\python\project\python_adv\pythonProject\toumanfen\data\test.txt'
# handler_path = r'./data/test.txt'
preprocess(cng.test_path, cng.rf_test_path)
preprocess(cng.train_path, cng.rf_train_path)
preprocess(cng.dev_path, cng.rf_dev_path)③ 模型训练
python
import jieba
import pandas as pd
import numpy as np
from sklearn.feature_extraction.text import TfidfVectorizer
from config.DataConfig import EDAConfig
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score
import joblib
cng = EDAConfig()
# 获取数据
data = pd.read_csv(cng.rf_dev_path)
# print(data.head())
text = data["words"]
# print(text)
label = data["label"]
# print(label)
# 停用词
stop_list = open(file=cng.stopwords_path, encoding="UTF-8").read().strip().split()
# 转换文本为向量
transformer = TfidfVectorizer(stop_words=stop_list)
features = transformer.fit_transform(text)
print(features)
print(features.toarray().shape)
data1 = features.toarray()[0]
print([i for i in data1 if i != 0])
# 划分数据集
x_train, x_test, y_train, y_test = train_test_split(features, label, test_size=0.2, random_state=22)
# 模型实例化
estimator = RandomForestClassifier()
# 训练
estimator.fit(x_train, y_train)
# 预测
y_pred = estimator.predict(x_test)
print(accuracy_score(y_true=y_test, y_pred=y_pred))
# 模型保存
with open(cng.rf_estimator, mode="wb") as f:
joblib.dump(estimator, f)
with open(cng.rf_transformer, mode="wb") as f:
joblib.dump(transformer, f)
print("模型保存完成")④ 模型预测
python
import pandas as pd
from config.DataConfig import EDAConfig
import joblib
cng = EDAConfig()
# 读取数据
data = pd.read_csv(cng.rf_test_path)
# print(data.head())
x = data["words"]
# 特征工程
with open(file=cng.rf_transformer, mode="rb") as f:
transformer = joblib.load(f)
features = transformer.transform(x)
print(features.toarray().shape)
# 模型预测
with open(file=cng.rf_estimator, mode="rb") as f:
estimator = joblib.load(f)
y_pred = estimator.predict(features)
# 预测结果报错
data["predict"] = y_pred
data.to_csv(cng.rf_predict_path)⑤ 使用Flask部署接口封装
server 端
python
from flask import Flask, request, jsonify
import pandas as pd
import joblib
import jieba
from config.DataConfig import EDAConfig
import warnings
warnings.filterwarnings("ignore")
# step1:初始化Flask应用
app = Flask(__name__)
cng = EDAConfig()
# step2:加载模型和向量化器
print("加载模型和向量化器...")
with open(cng.rf_estimator, 'rb') as f:
model = joblib.load(f)
with open(cng.rf_transformer, 'rb') as f:
tfidf = joblib.load(f)
# step3:加载标签映射
print("加载标签映射...")
with open(cng.class_path, 'r') as f:
label_names = [line.strip() for line in f if line.strip()]
label_map = {i: name for i, name in enumerate(label_names)}
print("标签映射:", label_map)
# step4:定义分词函数
def cut_sentence(s):
"""对输入文本进行结巴分词,并限制前30个词"""
return ' '.join(list(jieba.cut(s))[:30])
# step5:模型接口封装
@app.route("/predict", methods={"POST"})
def predict():
try:
data = request.get_json()
sentence = data.get('sentence', "")
if not sentence:
return jsonify({"error": "请输入句子"}), 400
processed_sentence = cut_sentence((sentence))
print("处理后的句子:", processed_sentence)
if isinstance(processed_sentence, str):
processed_sentence = [processed_sentence]
features = tfidf.transform(processed_sentence)
print("TF-IDF特征形状:", features.shape, "非零特征数:", features.nnz)
if features.nnz == 0:
return jsonify({"error": "输入句子无有效特征,请检查输入或停用词"}), 400
prediction = model.predict(features)[0]
print("模型预测值:", prediction)
predicted_label = label_map.get(int(prediction), "未知标签")
print("模型预测值的映射:", predicted_label)
return jsonify({"predicted_label": predicted_label})
except Exception as e:
print(e)
if __name__ == '__main__':
app.run(host='0.0.0.0', port=8002, debug=True)client 端
python
import requests
import json
if __name__ == "__main__":
try:
# url
url = "http://127.0.0.1:8002/predict"
# 输入句子
input_data = {"sentence": "超一流玩家必玩 黑神话孙悟空上线"}
# 调用flask api
response = requests.post(
url,
json=input_data
)
# 检查请求是否成功
response.raise_for_status()
# 解析API响应
result = response.json()
if 'predicted_label' in result:
print(f"预测结果:{result['predicted_label']}")
else:
print("返回结果不符合条件")
except requests.exceptions.RequestException as e:
print(f"无法连接到API:{str(e)}")3.2 fasttext模型
3.2.1 为什么使用fasttext?
因fasttext采用霍夫曼树、负采样,所以在处理数据量大的任务时,处理效率最高,可以使用其作为模型预测速率的参照标准
fasttext 封装较为全面,代码实现简单,可以快速进行构建、验证。
3.2.2 代码实现
① 数据处理
实现步骤:
判断文件是否存在
读取文件
id2name
获取fasttext支持的data(label_ + text(使用空格隔开))
将行按制表符拆分为 text,label
text 拆分 -> 按空格join
label(label) + 按空格join的text
保存text
python
import os, jieba
from config.FasttextCng import Config
conf = Config()
# 判断文件是否存在
if not os.path.exists(conf.dev_path) or not os.path.exists(conf.test_path) or not os.path.exists(conf.dev_path):
raise f"file not find!"
namelist = open(file=conf.class_path, encoding="UTF-8").read().strip().split()
id2name = {id: name for id, name in enumerate(namelist)}
# print(id2name)
def build_ft_data(path, flag_cut=True):
data = []
# 读取文件
with open(file=path, encoding="UTF-8", mode="r") as f:
# 获取fasttext支持的data(_label__ + text(使用空格隔开))
while True:
content = f.readlines(1024 * 1024)
if not content:
break
data.extend(content)
# 文件按照词或者单词子拆分->拼接为 __label__name text 格式
datas = []
for line in data:
text, label = line.split("\t")
if flag_cut:
text_list = jieba.lcut(text)
else:
text_list = list(text)
text_str = " ".join(text_list)
label_name = f"__label__{id2name[int(label)]}"
datas.append(label_name + " " + text_str)
return datas
# 保存text
def save_data(input_path, target_path, flag_cut):
datas = build_ft_data(input_path, flag_cut)
with open(target_path, encoding="UTF-8", mode="w") as f:
f.write("\n".join(datas))
print(f"{target_path}处理完毕!")
if __name__ == '__main__':
save_data(input_path=conf.test_path, target_path=conf.ft_test_word, flag_cut=True)
save_data(input_path=conf.dev_path, target_path=conf.ft_dev_word, flag_cut=True)
save_data(input_path=conf.train_path, target_path=conf.ft_train_word, flag_cut=True)
save_data(input_path=conf.test_path, target_path=conf.ft_test_char, flag_cut=False)
save_data(input_path=conf.dev_path, target_path=conf.ft_dev_char, flag_cut=False)
save_data(input_path=conf.train_path, target_path=conf.ft_train_char, flag_cut=False)② 字维度实现模型训练、评估、预测
python
import fasttext, datetime, os
from config.FasttextCng import Config
conf = Config()
# 模型训练
# model = fasttext.train_supervised(input=conf.ft_dev_char)
model = fasttext.train_supervised(input=conf.ft_dev_char,
autotuneValidationFile=conf.ft_dev_char,
autotuneDuration=30,
verbose=3)
# 模型预测
print(model.predict("《 赤 壁 O L 》 攻 城 战 诸 侯 战 硝 烟 又 起"))
# 模型评估
test_result = model.test(conf.ft_test_char)
print(test_result)
# 模型保存
# file_path = os.path.join(conf.ft_model_char, f"ft_char_default_{str(datetime.datetime.now())}.bin")
file_path = os.path.join(conf.ft_model_char, f"ft_char_auto_{str(datetime.datetime.now())}.bin")
model.save_model(file_path)
# 获取词表
print(model.get_words())
# 获取词维度
print(model.get_dimension())③ 词的维度实现模型训练、评估、预测
python
import fasttext, datetime, os
from config.FasttextCng import Config
conf = Config()
# 模型训练
# model = fasttext.train_supervised(input=conf.ft_dev_char)
model = fasttext.train_supervised(input=conf.ft_dev_word,
autotuneValidationFile=conf.ft_dev_word,
autotuneDuration=90,
verbose=3)
# 模型预测
print(model.predict("《 赤壁 OL 》 攻城 战 诸侯 战 硝烟 又 起"))
# 模型评估
test_result = model.test(conf.ft_test_word)
print(test_result)
# 模型保存
# file_path = os.path.join(conf.ft_model_char, f"ft_char_default_{str(datetime.datetime.now())}.bin")
file_path = os.path.join(conf.ft_model_char, f"ft_word_auto_{str(datetime.date.today())}.bin")
model.save_model(file_path)
# 获取词表长度
print(len(model.get_words()))
# 获取词维度
print(model.get_dimension())
'''
# 输出
(('__label__game',), array([1.00000882]))
(10000, 0.8143, 0.8143)
25130
1000
'''④ api模型部署
- 第一步: 编写服务端逻辑代码.
- 第二步: 启动Flask服务. (http://127.0.0.1:8003)
- 第三步: 编写客户端端代码,客户端发起请求
服务端:
python
import fasttext
import jieba
from flask import Flask, request, jsonify
# 实例化flask应用
app = Flask(__name__)
# 加载训练好的模型
# model = fasttext.load_model(
# r"D:\python\project\python_adv\pythonProject\toumanfen\FasttextMod\model\ft_word_auto_2026-06-24.bin")
model = fasttext.load_model(r"D:\python\project\python_adv\pythonProject\toumanfen\FasttextMod\model\ft_char_auto_20260624.bin")
# 定义路由
@app.route("/predict", methods=["POST"])
def main_server():
try:
data = request.get_json()
sentence = data.get('text', "")
if not sentence:
return jsonify({"error": "请输入句子"}), 400
# processed_sentence = " ".join(jieba.lcut((sentence)))
processed_sentence = " ".join(list((sentence)))
res = model.predict(processed_sentence)
# 获取预测结果
res = res[0][0][9:] # res[0][0].replace("__label__","")
return jsonify({"predicted_label": res})
except Exception as e:
print(e)
if __name__ == "__main__":
app.run(host="0.0.0.0", port=8003)客户端:
python
import requests
import time
# 定义url和传入数据
url = "http://127.0.0.1:8003/predict"
data = {"text": "公共英语(PETS)写作中常见的逻辑词汇汇总"}
headers = {"Content-Type": "application/json"}
# 计时
start_time = time.time()
# 向服务发送请求
res = requests.post(url, json=data, headers=headers)
# 获取处理时间(转换为毫秒)time.time()得到的是秒
cost_time_ms = (time.time() - start_time) * 1000
# 打印返回结果
print(f"输入文本:{data['text']}")
print(f"分类结果:{res.text}")
print(f"单条样本预测的耗时:{cost_time_ms:.1f}ms")3.3 Bert模型
3.3.1 为什么使用Bert预训练模型?
Bert模型基于tranform的编码器,双向编码获取上下文信息,可以更好的理解、提取文本含义,适用于文本分类、翻译、语义理解相关任务
3.3.2 代码实现:
实现步骤:
1.构建dataloader
读取数据文件
构建dataset
class Dataset(Dataset):
输入样本(特征,目标)
def self.init(self, data)
返回样本个数
def self.len()
按索引返回特征、目标值
def self.getitem(self, idx)
构建dataset
def collate_fn()
Dataloader(dataset,batch_size,shuffle,collate_fn)
- 模型构建
2.1 定义模型类:class BuildModel(nn.Model)
定义模型结构---都有那些层、每个层的输入、输出个数
def init()
前向传播
def forward()
3.模型训练、模型评估
模型实例化
加载dataloader
优化器、损失
遍历轮次、批次
模型预测
计算损失
反向传播、梯度更新
模型评估------准确率则进行保存
4.模型预测
模型加载
数据处理------转换为张量(使用预训练模型词表,BertTokenizer.from_pretrained(self.pretrain_bert_dir))
数据预测
添加softmax,输出每个输出的概率
输出分类名称、及类别对应的概率
① 配置文件
python
import os
from transformers import BertModel, BertTokenizer, BertConfig
import torch
import datetime
current_time = datetime.datetime.now().date().today().strftime("%Y%m%d")
class ConfigBert(object):
def __init__(self):
"""
配置类,包含模型和训练所需的各种参数。
"""
# 模型名称
self.model_name = "bert"
# 测试集
self.test_path = r'D:\python\project\python_adv\pythonProject\toumanfen\data\test.txt'
# 验证集
self.dev_path = r'D:\python\project\python_adv\pythonProject\toumanfen\data\dev.txt'
# 训练集
self.train_path = r'D:\python\project\python_adv\pythonProject\toumanfen\data\train.txt'
# 禁止词
self.stopwords_path = r'D:\python\project\python_adv\pythonProject\toumanfen\data\stopwords.txt'
# 类别文件
self.class_path = r'D:\python\project\python_adv\pythonProject\toumanfen\data\class.txt'
# csv文件保存
# 测试集
self.test_csv = r'D:\python\project\python_adv\pythonProject\toumanfen\Bert_model\data\test.csv'
# 验证集
self.dev_csv = r'D:\python\project\python_adv\pythonProject\toumanfen\Bert_model\data\dev.csv'
# 训练集
self.train_csv = r'D:\python\project\python_adv\pythonProject\toumanfen\Bert_model\data\train.csv'
# 类别名称
self.class_list = []
with open(self.class_path, 'r', encoding='utf-8') as f:
for line in f:
self.class_list.append(line.strip())
# 模型训练结果保存路径
self.model_save_dir = r"D:\python\project\python_adv\pythonProject\toumanfen\Bert_model\model"
# self.model_save_dir = r"D:\python\project\python_adv\pythonProject\toumanfen\Bert_model_distill\model"
# 如果路径不存在,构造路径
if not os.path.exists(self.model_save_dir):
os.mkdir(self.model_save_dir)
# 模型保存
self.model_save_path = os.path.join(self.model_save_dir, self.model_name + current_time + ".pt")
# 量化后模型保存
self.model_quantization_path = os.path.join(self.model_save_dir, self.model_name + current_time + "_p.pt")
# 剪枝后模型保存
self.model_prune_path = os.path.join(self.model_save_dir, self.model_name + current_time + "_prune.pt")
# 训练设备,如果GPU可用,则为cuda,否则为cpu
self.device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# 类别数
self.num_classes = len(self.class_list)
# epoch数
self.num_epochs = 2
# mini-batch大小
self.batch_size = 28
# 每句话处理成的长度(短填长切)
self.padding_size = 32
# 学习率
self.learning_rate = 5e-5
# 预训练BERT模型的路径
self.pretrain_bert_dir = r"D:\python\project\python_adv\pythonProject\toumanfen\Bert_model\model\bert-base-chinese"
# BERT模型的分词器
self.tokenizer = BertTokenizer.from_pretrained(self.pretrain_bert_dir)
# BERT模型的配置文件
self.bert_config = BertConfig.from_pretrained(os.path.join(self.pretrain_bert_dir, "config.json"))
# BERT模型的隐藏层大小
self.hidden_size = 768
# 词表大小
self.vocab_size = self.bert_config.vocab_size
if __name__ == "__main__":
conf = ConfigBert()
print(conf.bert_config)
# input_size = conf.tokenizer.convert_tokens_to_ids((["你", "好", "中国"]))
# print(input_size)
print(conf.vocab_size)② 构建dataloader
python
import torch
from tqdm import tqdm
from config.BertConfig01 import ConfigBert
from torch.utils.data import DataLoader, Dataset
conf = ConfigBert()
# 数据读取
def get_data(path):
data = []
content = []
with open(file=path, encoding="UTF-8", mode="r") as f:
while True:
datas = f.readlines(1024 * 1024)
if not datas:
break
content.extend(datas)
# print(content)
# tqdm添加进度条,desc 添加备注
for line in tqdm(content, desc="数据加载中"):
text, label = line.strip().split("\t")
data.append((text, int(label)))
return data
# 创建dataset
class NewsDataset(Dataset):
def __init__(self, data):
self.data = data
def __len__(self):
return len(self.data)
# idx 代表数据样本的索引(Index)
def __getitem__(self, idx):
x = self.data[idx][0]
y = self.data[idx][1]
return x, y
# dataloader
class NewsDataloader(object):
# 自定义批处理逻辑,
def collate_fn(self, batch):
# 获取文本和标签
texts = [item[0] for item in batch]
labels = [item[1] for item in batch]
# 文本转id,获取input_ids,attention_mask
token_ids = conf.tokenizer.batch_encode_plus(texts,
padding=True,
truncation=True,
return_tensors="pt")
input_ids = token_ids["input_ids"]
attention_mask = token_ids["attention_mask"]
# label转换为tensor
# print(labels, type(labels))
labels = torch.tensor(labels)
return input_ids, attention_mask, labels
# 读取数据-> dataset---> dataloader-> collate_fn
def build_dataloader(self):
# 训练集
train_data = get_data(conf.train_path)
train_dataset = NewsDataset(train_data)
train_dataloader = DataLoader(dataset=train_dataset, batch_size=conf.batch_size, shuffle=True,collate_fn=self.collate_fn)
# 验证集
dev_data = get_data(conf.dev_path)
dev_dataset = NewsDataset(dev_data)
dev_dataloader = DataLoader(dataset=dev_dataset, batch_size=conf.batch_size, shuffle=False, collate_fn=self.collate_fn)
# 测试集
test_data = get_data(conf.test_path)
test_dataset = NewsDataset(test_data)
test_dataloader = DataLoader(dataset=test_dataset, batch_size=conf.batch_size, shuffle=False, collate_fn=self.collate_fn)
return train_dataloader, dev_dataloader, test_dataloader
if __name__ == '__main__':
# train_data = get_data(conf.train_path)
# train_dataset = NewsDataset(train_data)
# print(train_dataset[0])
dataloader = NewsDataloader()
train_dataloader, dev_dataloader, test_dataloader = dataloader.build_dataloader()
for input_ids, attention_mask, labels in dev_dataloader:
print("input_ids", input_ids)
print("attention_mask", attention_mask)
print("labels", labels)
# print(i)
break③ 模型训练、评估
python
from Bert_model.model.bert_model import BuildModel
from data_loader import NewsDataloader
from config.BertConfig01 import ConfigBert
from torch.optim import AdamW
from torch import nn
import torch
from sklearn.metrics import accuracy_score, f1_score, classification_report
from tqdm import tqdm
def train(conf, train_dataloader, dev_dataloader, model):
# 优化器
optimizer = AdamW(params=model.parameters(), lr=0.0001)
# 损失
error = nn.CrossEntropyLoss()
best_f1 = 0
# 遍历轮次、批次
for epoch in range(conf.num_epochs):
# 训练模式
model.train()
loss_sum = 0
iter_num = 0
for id, (input_ids, attention_mask, labels) in tqdm(enumerate(train_dataloader), desc=f"{epoch} 训练中:"):
# 模型预测
y_pred = model(input_ids, attention_mask)
# 计算损失
loss = error(y_pred, labels)
loss_sum += loss.item()
iter_num += 1
# 反向传播、更新梯度
optimizer.zero_grad()
loss.backward()
optimizer.step()
# 模型评估
if id // 10 == 0 and id != 0:
acc, f1, report = evalu_model(dev_dataloader, model=model)
print(f"id{id}:{acc}")
if f1 > best_f1:
best_f1 = f1
# 模型保存
torch.save(model.state_dict(), conf.model_save_path)
if id > 20:
break
print(f"loss, {loss_sum / iter_num:.2f}")
# 模型评估
def evalu_model(dataloader, model):
model.eval()
y_preds = []
trues = []
# 遍历batch
with torch.no_grad():
i = 0
for input_ids, attention_mask, labels in dataloader:
# 模型预测
logits = model(input_ids, attention_mask)
# print(logits)
y_pred = torch.argmax(logits, dim=-1)
y_preds.extend(y_pred.numpy())
trues.extend(labels.numpy())
i += 1
if i > 10:
break
# 评估结果输出
acc = accuracy_score(y_true=trues, y_pred=y_preds)
f1 = f1_score(y_true=trues, y_pred=y_preds, average="macro", zero_division=0)
report = classification_report(y_true=trues, y_pred=y_preds, zero_division=0)
return acc, f1, report
if __name__ == '__main__':
# 配置文件
conf = ConfigBert()
# 加载数据
dataloader = NewsDataloader()
train_dataloader, dev_dataloader, test_dataloader = dataloader.build_dataloader()
model = BuildModel()
# 模型训练
train(conf=conf, train_dataloader=dev_dataloader, dev_dataloader=test_dataloader, model=model)
# 模型评估
# model.load_state_dict(torch.load(conf.model_save_path))
# acc, f1, report = evalu_model(dataloader=test_dataloader, model=model)
# print(acc)
# print(report)④ 模型预测
python
from config.BertConfig01 import ConfigBert
import torch
from Bert_model.model.bert_model import BuildModel
def model_pred(texts):
conf = ConfigBert()
# 模型加载
# model = BuildModel()
# weight = torch.load(conf.model_save_path)
# 加载量化后模型
model = torch.load(conf.model_quantization_path, weights_only=False)
# model.load_state_dict(weight)
# 文本数据处理
if isinstance(texts, str):
texts = [texts]
tokens = conf.tokenizer(text=texts,
return_tensors="pt",
return_attention_mask=True,
max_length=512, # BERT最大序列长度
# 截断超长文本
truncation=True,
padding=True)
input_ids = tokens["input_ids"]
attention_mask = tokens["attention_mask"]
# 求取概率、转换为用户可识别数据
logits = model(input_ids, attention_mask)
# 概率
possible = torch.softmax(logits, dim=-1)
pred_id = torch.argmax(logits, dim=-1)
# 预测值转换为类名名称
class_name = [conf.class_list[id] for id in pred_id.numpy()]
# print(class_name)
# 将类别名称与类名的概率进行对应
prob_name = [possible[i][id] for i, id in enumerate(pred_id)]
# 结果整合
results = []
for i in range(len(texts)):
results.append(
{
"text": texts[i],
"类别id": pred_id[i].item(),
"类别名称": class_name[i],
"概率": prob_name[i].item()
}
)
return results
if __name__ == '__main__':
texts = ["日本1比1瑞典 淘汰赛将战巴西", "苹果涨价iPhone未涨 官方回应"]
print(model_pred(texts))⑤ 模型部署------使用Flask
服务端:
python
from flask import Flask, request, jsonify
from predict_bert import model_pred
# 创建Flask应用
app = Flask(__name__)
# 定义路由,接收POST请求并进行推理
@app.route('/predict', methods=["POST"])
def predict_endpoint():
data = request.get_json()
# 验证输入是否存在且包含'text字段
if not data or 'text' not in data:
return jsonify({
"error": "请求必须包含text字段,值为字符串或者字符串列表"
}), 400
# 获取输入文本
texts = data['text']
# 验证输入类型(字符串或者列表)
if not isinstance(texts, (str, list)):
return jsonify({
"error": 'text必须是字符串或者字符串列表'
}), 400
# 如果是列表,检查每个元素是否为字符串
if isinstance(texts, list):
for text in texts:
if not isinstance(text, str):
return jsonify({
"error": "text必须是字符串"
}), 400
# 调用predict函数
results = model_pred(texts)
# 检查预测结果
if not results:
return jsonify({
"error": "预测失败,可能输入文本无效或模型不可用"
}), 500
# 返回预测结果
return jsonify(results), 200
# 如果脚本作为主程序运行,则启动Flask应用
if __name__ == '__main__':
app.run(host='0.0.0.0', port=8004)客户端:
python
import requests
import time
# 定义请求url和传入的data
url = "http://127.0.0.1:8004/predict"
data = {"text": "体验2D巅峰 倚天屠龙记十大创新概览"}
start_time = time.time()
# 向服务发送post请求
res = requests.post(url, json=data)
cost_time = time.time() - start_time
print(f'res:{res}')
# 打印返回的结果
print('文本类别: ', res.json())
print(f'单条样本耗时: {cost_time:.1f}ms')4.模型压缩
4.1 模型压缩
4.1.1 模型压缩简介
在保证一些模型性能损耗不大的情况下,使得模型尽可能的小,就是我们要解决的问题。而让模型规模变小,我们称之为模型压缩 。如何解决大模型在低资源设备硬件上提升推理效率就是模型压缩意义。
4.1.2 模型压缩的四种主流技术
Pruning 剪枝:一种将深度神经网络参数置为零,从而提升计算效率。在 深度神经网络中,许多参数是冗余的,因为它们在训练期间贡献不大。因此,在训练之后,可以从网络中删除这些参数,而对准确性的影响很小。
Quantization 量化:例如,权重存储为 32 位浮点数,即fp32。量化通过减少每个权重所需的位数来压缩原始网络。例如,权重可以量化为 fp16 位、int8 位甚至 int4 位。通过减少使用的位数,可以显著减小 DNN 的大小,且加速推理速度。
Knowledge distillation 知识蒸馏:使用较小的模型替换原来大的模型
Low-rank factorization 低秩因式分解 : 模型训练时使用,通过添加分支
4.1.3 模型压缩前后对比
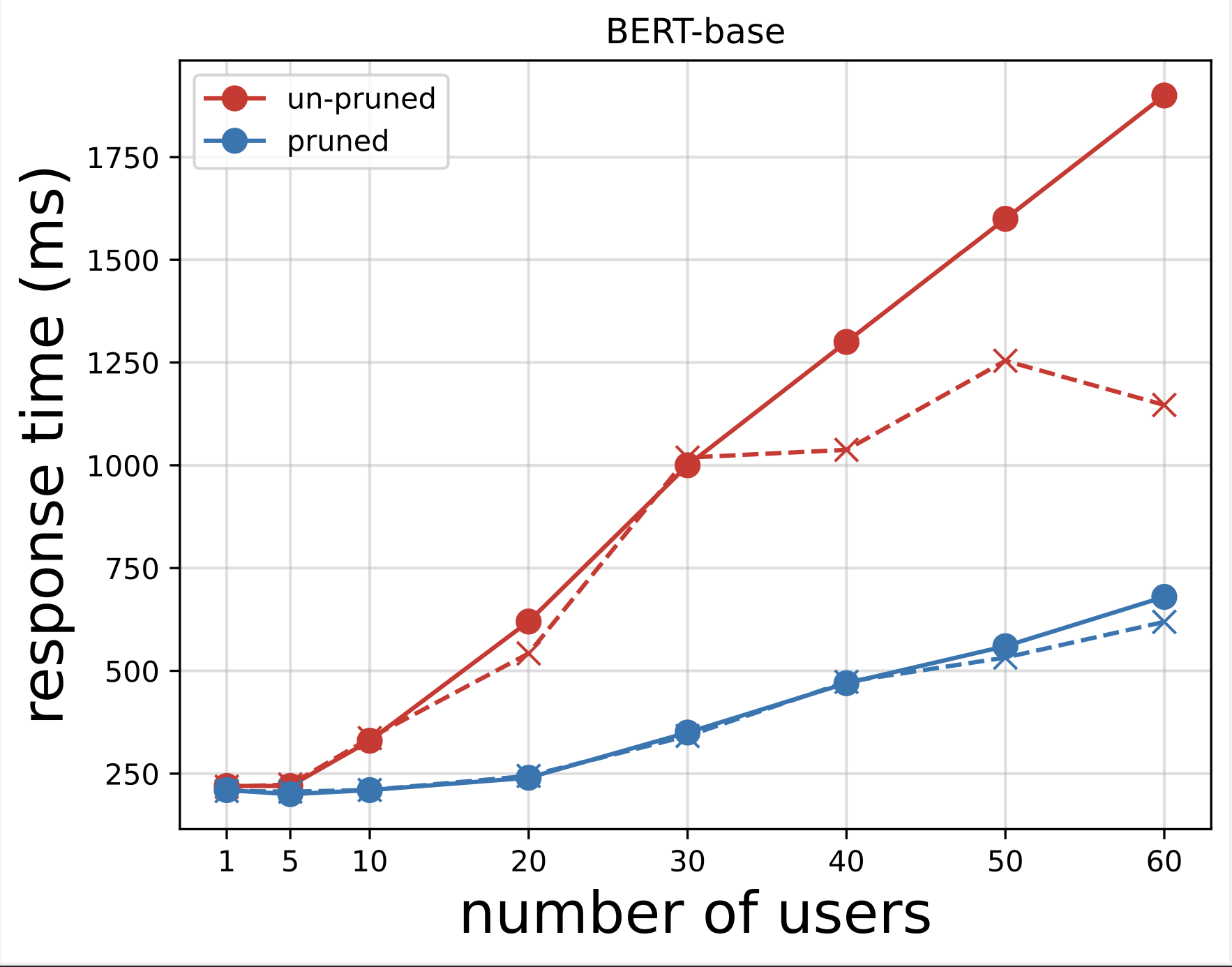
bert剪枝前后的推理响应时间:
剪枝(将部分无用参数设为0)之后模型的处理耗时随着数据增加明显下降
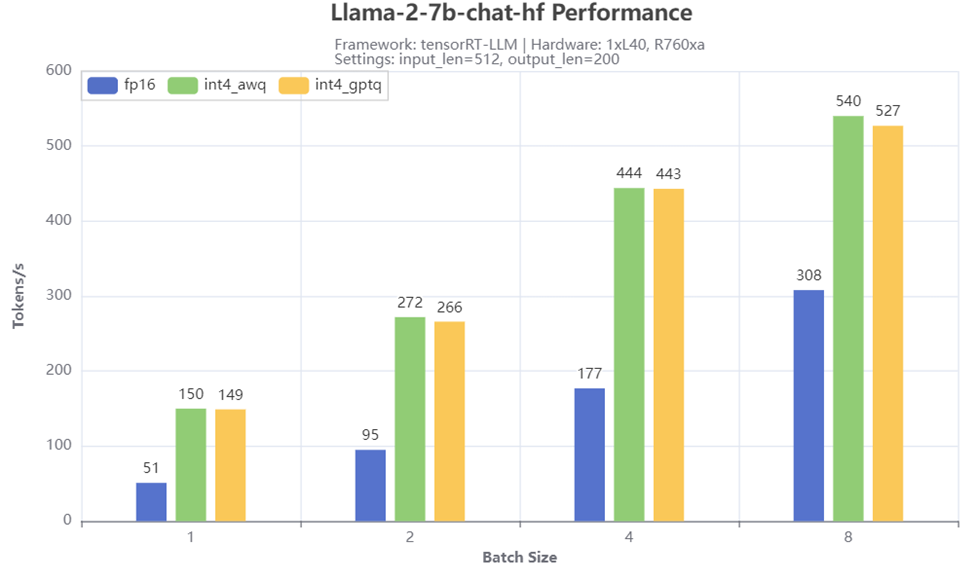
Llama量化前后的推理响应时间对比:
量化(float->int,数据精度下降)之后,每秒处理的tokens数明显提升
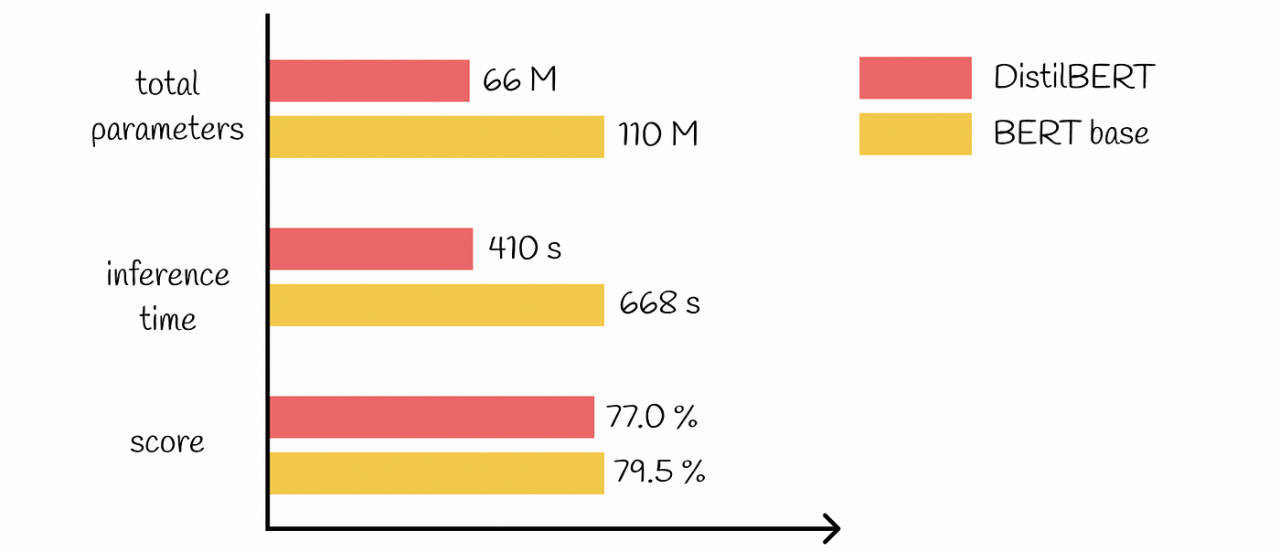
bert蒸馏前后的推理、参数对比:
DistilBERT:蒸馏后模型。蒸馏之后参数量下降、效率提升、准确率下降
4.2 模型量化
4.2.1 什么是模型量化
**作用:**在不改变参数数量的情况下,通过降低参数的精度(比特位、字节数),从而提升计算效率
**量化过程:**例如将float32的映射到int8
① 取每一层float数绝对数最大的数,scale = 绝对数最大的数 / 127(int8的最大值)
② 实现量化:float数 * scale = 量化后的映射到int8上的值,值需进行取证
层级之间: 量化-计算-反量化------下一层------>量化-计算-反量化,每一层的量化系数scale不同
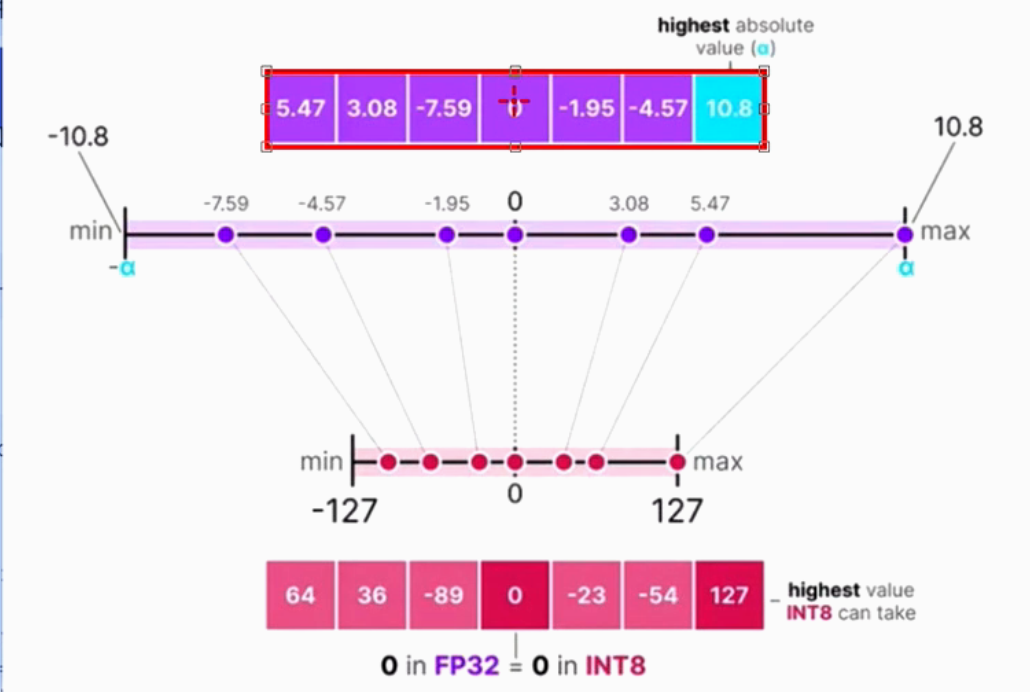
4.2.2 量化的三种方式
- 通俗的理解, 就是将模型的参数精度进行降低操作, 用更少的比特位(torch.qint8)代替较多的比特位(torch.float32), 从而缩减模型, 并加速推断速度.
【了解】训练中量化:训练过程中,模型量化贯穿前、后向传播
【了解】静态量化:模型预测环节使用,scale 值是固定的,一般从验证集中提取出,获取难度较大,所以一般不使用
**【重要】动态量化:**模型预测环节使用,scale 值动态计算调整,使用简单。
4.2.3 pytorch代码实现量化
python
from config.BertConfig01 import ConfigBert
from data_loader import NewsDataloader
from Bert_model.model.bert_model import BuildModel
import torch
from train_model import evalu_model
conf = ConfigBert()
# 模型加载、加载dataloader
weights = torch.load(conf.model_save_path)
model = BuildModel()
model.load_state_dict(weights)
print("量化前:", model)
dataloader = NewsDataloader()
train_dataloader, dev_dataloader, test_dataloader = dataloader.build_dataloader()
# 模型量化
q_model = torch.quantization.quantize_dynamic(model, {torch.nn.Linear}, dtype=torch.qint8)
print("量化后:", q_model)
# 模型评估
acc, f1, report = evalu_model(dataloader=test_dataloader, model=q_model)
print(acc, f1, report)
# 模型保存
torch.save(q_model, conf.model_quantization_path)
print("模型保存成功!")4.3 知识蒸馏
4.3.1 与量化进行对比:
量化是通过降低数据的精度,如将float32降为int8从而减少字符长度、计算复杂度。一般作用与预测时,而不是训练时。
蒸馏是通过让小的模型向大的已训练好的模型学习,从而使小模型具有那模型的能力,最终使用小模型来替换大模型,从而做到提升处理效率。
4.3.2 蒸馏的介绍:
**概念:**通过"教师-学生"框架,把大而复杂的高性能教师模型的知识迁移到小而轻量的学生模型中,在大幅降低参数量和计算成本的同时,让学生模型性能高度逼近教师模型。
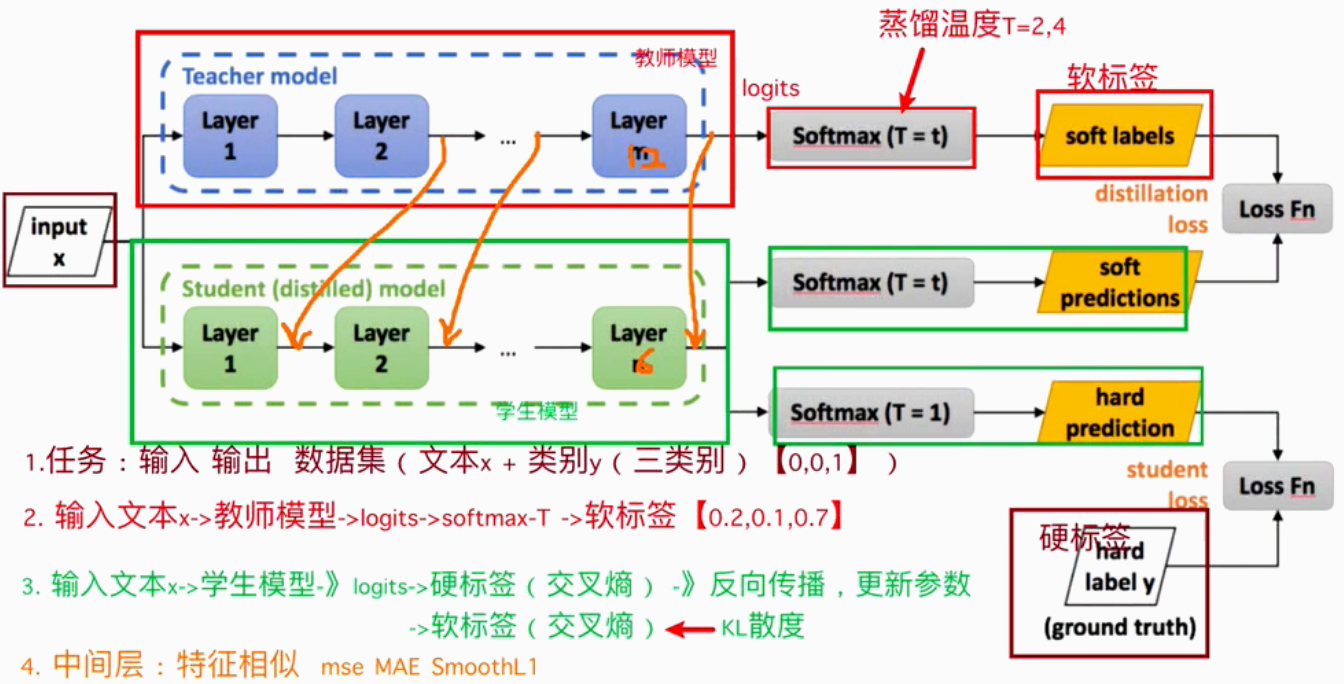
4.3.3 软损失计算过程:
softmax-T计算公式:
参数:
Pi:软标签,学生模型学习的目标值。
zi :logits 模型的预测结果,未进行softmax 或 torch.argmax()
T : 蒸馏温度,一般选2或4
温度参数(Temperature Parameter,T):
当T值取1:softmax-T 公式就是一般softmax公式
当T值接近于0:softmax-T 公式的退化为类似 one-hot编码
当T值越大:softmax-T 公式的输出结果变得平缓,起到保留相似信息的作用
当T值取无穷大:softmax-T 公式演变为均匀分布
损失计算公式:
4.3.4 中间层:
**概念:**本质上是让学生模型不仅学习"最终答案",还要学习教师模型"解题的思路和过程"
如何计算损失?
hard_loss = hard_error(student_logits, teacher_logits)
学生模型隐藏层与老师层隐藏层输出,计算mse损失
inter_loss = F.mse_loss(student_hidden, teacher_hidden)
loss = alpha * inter_loss + (1 - alpha) * hard_loss
什么时候使用?
教师模型与学生模型同架构时使用
4.3.5 实现步骤:
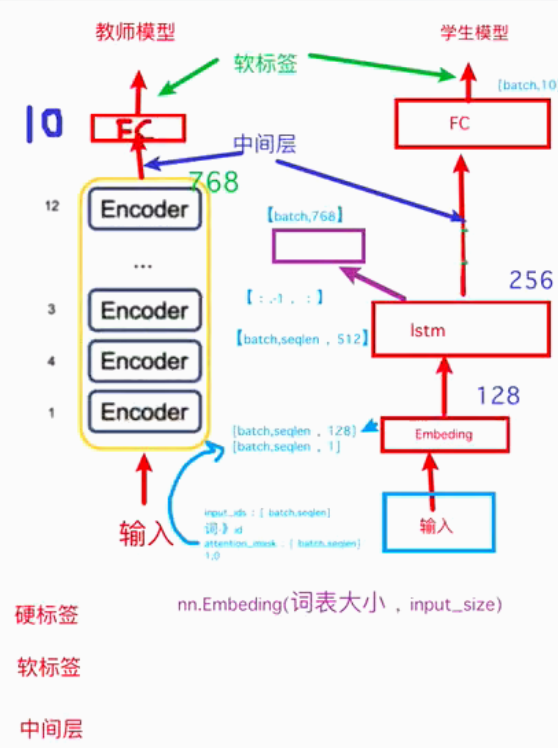
4.3.6 蒸馏的架构:
4.3.7 代码实现
步骤分析:
一、模型构建:
老师模型:
加载预训练模型
nn.Line() 输出层
① 当训练、计算 中间层损失时,返回 logits 和 pooled
② 当训练、计算 硬损失和软损失时,前向传播不仅过中间层,输出层只返回 logits
学生模型:
nn.embedding
lstm层
中间层
输出层
① 当训练、计算 中间层损失时,输出层返回 logits 和 lstm的hidden
② 当训练、计算 硬损失和软损失时,前向传播不仅过中间层,输出层只返回 logits
二、构建dataset、dataloader,和之前一样
三、模型蒸馏
主要区别:硬损失、软损失、中间层在计算损失有区别,其它步骤一致
- 数据加载
2.优化器、损失
3.遍历轮次、批次
3.1 模型预测
注意点:老师模型预测时,可以节省内存,不进行梯度更新(with torch.no_grad())
3.2 反向传播、梯度更新
① 硬损失:
hard_error:nn.CrossEntropyLoss() 交叉熵损失
hard_loss = hard_error(logits, labels)
② 软损失:
teacher_softmaxT = F.softmax(teacher_logits / T, dim=-1)
student_softmaxT = F.softmax(logits / T, dim=-1)
soft_loss = F.kl_div(student_softmaxT, teacher_softmaxT) * T * T
loss = alpha * soft_loss + (1 - alpha) * hard_loss
③ 中间层损失:
hard_loss = hard_error(student_logits, teacher_logits)
学生模型隐藏层与老师曾隐藏层输出,计算mse损失
inter_loss = F.mse_loss(student_hidden, teacher_hidden)
loss = alpha * inter_loss + (1 - alpha) * hard_loss
3.3 模型评估------使用验证机进行评估
当准确率、f1-score增大是更新模型
3.4 提前停止
当连续指定次数,预测结果准确率下降或不变时,提前结束训练,防止过拟合
模型蒸馏与模型训练时,只是计算损失时不同,distill时
① 模型构建
构建Bert模型
python
from config.BertConfig01 import ConfigBert
from transformers import BertModel
from torch import nn
from Bert_model.data_loader import NewsDataloader
conf = ConfigBert()
class BuildModel(nn.Module):
def __init__(self):
super().__init__()
self.bert = BertModel.from_pretrained(conf.pretrain_bert_dir, config=conf.bert_config)
self.fc = nn.Linear(in_features=conf.hidden_size, out_features=conf.num_classes)
# 前向传播
def forward(self, input_ids, attention_mask, return_hidden=False):
output, pooled = self.bert(input_ids=input_ids, attention_mask=attention_mask, return_dict=False)
out = self.fc(pooled)
if return_hidden:
return out, pooled
return out
if __name__ == '__main__':
model = BuildModel()
print(model)
dataloader = NewsDataloader()
train_dataloader, dev_dataloader, test_dataloader = dataloader.build_dataloader()
for input_ids, attention_mask, labels in dev_dataloader:
# print(input_ids)
out, pooled = model(input_ids, attention_mask, return_hidden=True)
# print(out.shape)
# print(out)
print(pooled.shape)
print(pooled)
break构建lstm模型
python
from torch import nn
from config.BertConfig01 import ConfigBert
from config.lstmConfig import LSTMConfig
from Bert_model_distill.data_loader import NewsDataloader
bert_conf = ConfigBert()
lstm_conf = LSTMConfig()
class BuildModel(nn.Module):
def __init__(self):
super().__init__()
# 嵌入层
self.embed = nn.Embedding(num_embeddings=bert_conf.vocab_size, embedding_dim=lstm_conf.embed_size)
# lstm层
self.lstm_layer = nn.LSTM(input_size=lstm_conf.embed_size,
hidden_size=lstm_conf.hidden_size,
num_layers=lstm_conf.num_layers,
batch_first=True,
dropout=lstm_conf.dropout,
bidirectional=True)
# 中间层映射层
self.inter_layer = nn.Linear(in_features=lstm_conf.hidden_size * 2, out_features=bert_conf.hidden_size)
# 输出层
self.out_layer = nn.Linear(in_features=lstm_conf.hidden_size * 2, out_features=lstm_conf.num_classes)
# 前向传播
def forward(self, input_ids, attention_mask, return_hidden=False):
# id->vector
emb = self.embed(input_ids)
# lstm
attention_mask = attention_mask.unsqueeze(-1)
# 屏蔽序列中的填充(Padding)数据,防止其对 LSTM 的特征提取和后续计算产生干扰
emb = emb * attention_mask
output, _ = self.lstm_layer(emb)
# 提取序列的最后一个时间步的输出
output = output[:, -1, :]
# 中间层映射层
hidden = self.inter_layer(output)
# out
logits = self.out_layer(output)
if return_hidden:
hidden = self.inter_layer(output)
return logits, hidden
return logits
if __name__ == '__main__':
dataloader = NewsDataloader()
train_dataloader, dev_dataloader, test_dataloader = dataloader.build_dataloader()
model = BuildModel()
for input_size, attention_mask, label in train_dataloader:
logits, hidden = model(input_size, attention_mask, return_hidden=True)
print(logits.shape)
print(hidden.shape)
break② 构建dataloader、dataset
python
import torch
from tqdm import tqdm
from config.BertConfig01 import ConfigBert
from torch.utils.data import DataLoader, Dataset
conf = ConfigBert()
# 数据读取
def get_data(path):
data = []
content = []
with open(file=path, encoding="UTF-8", mode="r") as f:
while True:
datas = f.readlines(1024 * 1024)
if not datas:
break
content.extend(datas)
# print(content)
# tqdm添加进度条,desc 添加备注
for line in tqdm(content, desc="数据加载中"):
text, label = line.strip().split("\t")
data.append((text, int(label)))
return data
# 创建dataset
class NewsDataset(Dataset):
def __init__(self, data):
self.data = data
def __len__(self):
return len(self.data)
# idx 代表数据样本的索引(Index)
def __getitem__(self, idx):
x = self.data[idx][0]
y = self.data[idx][1]
return x, y
# dataloader
class NewsDataloader(object):
# 自定义批处理逻辑,
def collate_fn(self, batch):
# 获取文本和标签
texts = [item[0] for item in batch]
labels = [item[1] for item in batch]
# 文本转id,获取input_ids,attention_mask
token_ids = conf.tokenizer.batch_encode_plus(texts,
padding=True,
truncation=True,
return_tensors="pt")
input_ids = token_ids["input_ids"]
attention_mask = token_ids["attention_mask"]
# label转换为tensor
# print(labels, type(labels))
labels = torch.tensor(labels)
return input_ids, attention_mask, labels
# 读取数据-> dataset---> dataloader-> collate_fn
def build_dataloader(self):
# 训练集
train_data = get_data(conf.train_path)
train_dataset = NewsDataset(train_data)
train_dataloader = DataLoader(dataset=train_dataset, batch_size=conf.batch_size, shuffle=True,collate_fn=self.collate_fn)
# 验证集
dev_data = get_data(conf.dev_path)
dev_dataset = NewsDataset(dev_data)
dev_dataloader = DataLoader(dataset=dev_dataset, batch_size=conf.batch_size, shuffle=False, collate_fn=self.collate_fn)
# 测试集
test_data = get_data(conf.test_path)
test_dataset = NewsDataset(test_data)
test_dataloader = DataLoader(dataset=test_dataset, batch_size=conf.batch_size, shuffle=False, collate_fn=self.collate_fn)
return train_dataloader, dev_dataloader, test_dataloader
if __name__ == '__main__':
# train_data = get_data(conf.train_path)
# train_dataset = NewsDataset(train_data)
# print(train_dataset[0])
dataloader = NewsDataloader()
train_dataloader, dev_dataloader, test_dataloader = dataloader.build_dataloader()
for input_ids, attention_mask, labels in dev_dataloader:
print("input_ids", input_ids)
print("attention_mask", attention_mask)
print("labels", labels)
# print(i)
break③ 模型蒸馏
python
import torch
from tqdm import tqdm
from config.BertConfig01 import ConfigBert
from torch.utils.data import DataLoader, Dataset
conf = ConfigBert()
# 数据读取
def get_data(path):
data = []
content = []
with open(file=path, encoding="UTF-8", mode="r") as f:
while True:
datas = f.readlines(1024 * 1024)
if not datas:
break
content.extend(datas)
# print(content)
# tqdm添加进度条,desc 添加备注
for line in tqdm(content, desc="数据加载中"):
text, label = line.strip().split("\t")
data.append((text, int(label)))
return data
# 创建dataset
class NewsDataset(Dataset):
def __init__(self, data):
self.data = data
def __len__(self):
return len(self.data)
# idx 代表数据样本的索引(Index)
def __getitem__(self, idx):
x = self.data[idx][0]
y = self.data[idx][1]
return x, y
# dataloader
class NewsDataloader(object):
# 自定义批处理逻辑,
def collate_fn(self, batch):
# 获取文本和标签
texts = [item[0] for item in batch]
labels = [item[1] for item in batch]
# 文本转id,获取input_ids,attention_mask
token_ids = conf.tokenizer.batch_encode_plus(texts,
padding=True,
truncation=True,
return_tensors="pt")
input_ids = token_ids["input_ids"]
attention_mask = token_ids["attention_mask"]
# label转换为tensor
# print(labels, type(labels))
labels = torch.tensor(labels)
return input_ids, attention_mask, labels
# 读取数据-> dataset---> dataloader-> collate_fn
def build_dataloader(self):
# 训练集
train_data = get_data(conf.train_path)
train_dataset = NewsDataset(train_data)
train_dataloader = DataLoader(dataset=train_dataset, batch_size=conf.batch_size, shuffle=True,collate_fn=self.collate_fn)
# 验证集
dev_data = get_data(conf.dev_path)
dev_dataset = NewsDataset(dev_data)
dev_dataloader = DataLoader(dataset=dev_dataset, batch_size=conf.batch_size, shuffle=False, collate_fn=self.collate_fn)
# 测试集
test_data = get_data(conf.test_path)
test_dataset = NewsDataset(test_data)
test_dataloader = DataLoader(dataset=test_dataset, batch_size=conf.batch_size, shuffle=False, collate_fn=self.collate_fn)
return train_dataloader, dev_dataloader, test_dataloader
if __name__ == '__main__':
# train_data = get_data(conf.train_path)
# train_dataset = NewsDataset(train_data)
# print(train_dataset[0])
dataloader = NewsDataloader()
train_dataloader, dev_dataloader, test_dataloader = dataloader.build_dataloader()
for input_ids, attention_mask, labels in dev_dataloader:
print("input_ids", input_ids)
print("attention_mask", attention_mask)
print("labels", labels)
# print(i)
break④ 模型预测
python
from config import lstmConfig, BertConfig01
import torch, os
from Bert_model_distill.model.lstm_model import BuildModel
from Bert_model import train_model
def model_pred(texts, path="soft"):
lstm_conf = lstmConfig.LSTMConfig()
conf = BertConfig01.ConfigBert()
# 模型加载
# model = BuildModel()
# weight = torch.load(os.path.join(lstm_conf.distill_model_save_dir, f"model_{path}_best.pt"), weights_only=False)
# weight = torch.load(lstm_conf.distill_model_save_dir, weights_only=False)
# 加载量化后模型
# model = torch.load(conf.model_quantization_path, weights_only=False)
# model.load_state_dict(weight)
# 剪枝
model = train_model.BuildModel()
weight = torch.load(conf.model_prune_path, weights_only=False)
model.load_state_dict(weight)
# 文本数据处理
if isinstance(texts, str):
texts = [texts]
tokens = conf.tokenizer(text=texts,
return_tensors="pt",
return_attention_mask=True,
max_length=512, # BERT最大序列长度
# 截断超长文本
truncation=True,
padding=True)
input_ids = tokens["input_ids"]
attention_mask = tokens["attention_mask"]
# 求取概率、转换为用户可识别数据
logits = model(input_ids, attention_mask)
# 概率
possible = torch.softmax(logits, dim=-1)
pred_id = torch.argmax(logits, dim=-1)
# 预测值转换为类名名称
class_name = [conf.class_list[id] for id in pred_id.numpy()]
# print(class_name)
# 将类别名称与类名的概率进行对应
prob_name = [possible[i][id] for i, id in enumerate(pred_id)]
# 结果整合
results = []
for i in range(len(texts)):
results.append(
{
"text": texts[i],
"类别id": pred_id[i].item(),
"类别名称": class_name[i],
"概率": prob_name[i].item()
}
)
return results
if __name__ == '__main__':
texts = ["日本1比1瑞典 淘汰赛将战巴西", "苹果涨价iPhone未涨 官方回应"]
path = "soft"
print(model_pred(texts, path))4.4 【了解】模型减枝
什么是模型的剪枝?
模型剪枝是一种通过裁剪掉冗余参数来减少模型大小和计算量的方法。在模型剪枝中,通常通过剪枝算法识别出模型中对任务贡献较小的参数,并将其从模型中移除。模型剪枝的目标是保持模型的性能不受明显影响的情况下减少参数数量和计算复杂度。
实现:将冗余参数设为0,并不是直接去掉
如何确定那些参数可以剪掉?如何判断那些权重不重要?
常用的评估标准包括权重的L1/L2范数(绝对值大小)、梯度大小或激活值等。
按照重要性排序后,将低于设定阈值的部分裁剪掉。
在实际操作中,为了避免精度骤降,通常采用渐进式剪枝,即每次只剪除一小部分,并不断迭代此步骤。
模型剪枝的主要分类:
根据剪枝粒度和策略的不同,模型剪枝主要分为以下几类:13
- 非结构化剪枝(权重剪枝):直接针对单个权重进行操作。通常基于权重的重要性(如绝对值大小)进行排序,将接近于0或不重要的权重置为0,从而生成稀疏矩阵。这种方法压缩率极高,但产生不规则的稀疏性,通常需要专门的硬件支持才能实现推理加速。
- 结构化剪枝:以整个神经元、通道(Channel)或卷积核(Filter)为单位进行移除。这种方法保持了模型结构的完整性,剪枝后的模型可以直接在现有的通用硬件(如CPU/GPU)和推理框架上运行并获得真实的加速效果,是工程落地中最常用的方式。
- 动态剪枝:在模型推理过程中,根据不同的输入数据动态地调整网络结构或激活特定的神经元(如Top-K激活机制)。这种方式允许模型按需计算,在保持准确性的同时进一步减少计算开销。
代码实现:
BERT 全局非结构化剪枝:对所有 encoder 层注意力权重剪枝 30%,L1 范数。
python
import torch
from config.BertConfig01 import ConfigBert
from Bert_model.model.bert_model import BuildModel
from torch.nn.utils import prune
from data_loader import NewsDataloader
from train_model import evalu_model
conf = ConfigBert()
dataloader = NewsDataloader()
train_dataloader, dev_dataloader, test_dataloader = dataloader.build_dataloader()
# 加载训练好的参数
model = BuildModel()
weight = torch.load(conf.model_save_path, weights_only=False)
model.load_state_dict(weight)
acc, f1, report = evalu_model(dataloader=test_dataloader, model=model)
print("剪枝前:", acc, f1, report)
# print(model.bert.encoder.layer[0].attention.self.query.weight)
# 确认要剪枝的参数
parameters_to_prune = [
(model.bert.encoder.layer[i].attention.self.query, "weight") for i in range(12)
]
# print(parameters_to_prune)
# 剪枝参数:比例、参数、l1范式
prune.global_unstructured(
parameters=parameters_to_prune,
pruning_method=prune.L1Unstructured,
amount=0.3
)
# 剪枝remove
for layer, param in parameters_to_prune:
prune.remove(layer, param)
# print(model.bert.encoder.layer[0].attention.self.query.weight)
# 统计剪枝之后0的比例
acc, f1, report = evalu_model(dataloader=test_dataloader, model=model)
print("剪枝后:", acc, f1, report)
# 模型保存
torch.save(model.state_dict(), conf.model_prune_path)
print("模型保存成功!")