【机器学习】万字长文详解集成学习 Ensemble Learning:从 Bagging、Boosting 到 Stacking 的全解析
文章目录
- [【机器学习】万字长文详解集成学习 Ensemble Learning:从 Bagging、Boosting 到 Stacking 的全解析](#【机器学习】万字长文详解集成学习 Ensemble Learning:从 Bagging、Boosting 到 Stacking 的全解析)
-
- [1 什么是 Ensemble Learning?](#1 什么是 Ensemble Learning?)
- [2 集成学习的基本思想](#2 集成学习的基本思想)
-
- [2.1 构造多个基学习器](#2.1 构造多个基学习器)
- [2.2 组合多个模型的预测结果](#2.2 组合多个模型的预测结果)
- [3 集成学习的三大主流方法:Bagging、Boosting、Stacking](#3 集成学习的三大主流方法:Bagging、Boosting、Stacking)
-
- [3.1 Bagging:并行式集成学习](#3.1 Bagging:并行式集成学习)
-
- [3.1.1 Bagging 的核心思想](#3.1.1 Bagging 的核心思想)
- [3.1.2 Bootstrap 有放回采样](#3.1.2 Bootstrap 有放回采样)
- [3.1.3 Bagging 的预测方式](#3.1.3 Bagging 的预测方式)
- [3.1.4 Bagging 的代表算法:随机森林](#3.1.4 Bagging 的代表算法:随机森林)
- [3.1.5 使用 scikit-learn 实现随机森林分类](#3.1.5 使用 scikit-learn 实现随机森林分类)
- [3.1.6 Bagging 的优缺点](#3.1.6 Bagging 的优缺点)
- [3.2 Boosting:串行式集成学习](#3.2 Boosting:串行式集成学习)
-
- [3.2.1 Boosting 的核心思想](#3.2.1 Boosting 的核心思想)
- [3.2.2 什么是弱学习器?](#3.2.2 什么是弱学习器?)
- [3.2.3 Boosting 的基本流程](#3.2.3 Boosting 的基本流程)
- [3.2.4 AdaBoost](#3.2.4 AdaBoost)
- [3.2.5 GBDT](#3.2.5 GBDT)
- [3.2.6 XGBoost、LightGBM 和 CatBoost](#3.2.6 XGBoost、LightGBM 和 CatBoost)
- [3.2.7 Boosting 的优缺点](#3.2.7 Boosting 的优缺点)
- [3.3 Stacking:模型融合的高级方法](#3.3 Stacking:模型融合的高级方法)
-
- [3.3.1 Stacking 的核心思想](#3.3.1 Stacking 的核心思想)
- [3.3.2 Stacking 的基本流程](#3.3.2 Stacking 的基本流程)
- [3.3.3 使用 scikit-learn 实现 Stacking](#3.3.3 使用 scikit-learn 实现 Stacking)
- [3.3.4 Stacking 的优缺点](#3.3.4 Stacking 的优缺点)
- [3.4 Voting:最简单的集成方式](#3.4 Voting:最简单的集成方式)
-
- [3.4.1 Hard Voting](#3.4.1 Hard Voting)
- [3.4.2 Soft Voting](#3.4.2 Soft Voting)
- [3.4.3 使用 scikit-learn 实现 Voting](#3.4.3 使用 scikit-learn 实现 Voting)
- [3.5 Bagging、Boosting、Stacking 对比](#3.5 Bagging、Boosting、Stacking 对比)
- [4 集成学习中的常见参数](#4 集成学习中的常见参数)
-
- [4.1 n_estimators](#4.1 n_estimators)
- [4.2 learning_rate](#4.2 learning_rate)
- [4.3 max_depth](#4.3 max_depth)
- [4.4 subsample](#4.4 subsample)
- [4.5 colsample_bytree](#4.5 colsample_bytree)
- [5 关于集成学习在实际应用时的一些建议](#5 关于集成学习在实际应用时的一些建议)
-
- [5.1 一些情景下的应用建议](#5.1 一些情景下的应用建议)
- [5.2 集成学习的注意事项](#5.2 集成学习的注意事项)
- [5.3 面试常见问题](#5.3 面试常见问题)
-
- [5.3.1 Bagging 和 Boosting 有什么区别?](#5.3.1 Bagging 和 Boosting 有什么区别?)
- [5.3.2 随机森林为什么不容易过拟合?](#5.3.2 随机森林为什么不容易过拟合?)
- [5.3.3 XGBoost 为什么效果好?](#5.3.3 XGBoost 为什么效果好?)
- [5.3.4 Stacking 为什么容易数据泄漏?](#5.3.4 Stacking 为什么容易数据泄漏?)
- [5.3.5 集成学习一定比单模型好吗?](#5.3.5 集成学习一定比单模型好吗?)
- [6 完整示例:对比多个集成模型效果](#6 完整示例:对比多个集成模型效果)
- [7 总结](#7 总结)
1 什么是 Ensemble Learning?
Ensemble Learning ,中文通常称为 集成学习 ,是一种非常重要的机器学习思想。它的核心思想是不依赖单个模型做决策,而是训练多个模型,并将它们的预测结果组合起来,从而获得更稳定、更准确、更鲁棒的最终模型。
在机器学习中,一个模型可能会因为训练数据、特征选择、模型结构、参数设置等原因产生误差。集成学习的目标就是通过多个模型协同工作,降低单个模型的不确定性。
举一个生活中的例子:假设你要判断一家公司是否值得投资。你可以只听一个专家的意见,也可以同时参考多位专家的判断,然后综合他们的观点做决定。通常情况下,多个专家的综合意见会比单个专家更可靠。
机器学习中的集成学习也是类似的思想。在机器学习建模过程中,我们经常会遇到以下问题:
- 单个模型容易过拟合;
- 单个模型对训练数据变化敏感;
- 单个模型预测结果不够稳定;
- 某些模型偏差较大;
- 某些模型方差较大;
- 数据噪声较多,模型容易受到干扰。
集成学习通过组合多个模型,可以有效缓解这些问题。从误差角度来看,模型的泛化误差通常可以拆分为:
泛化误差 = 偏差 B i a s + 方差 V a r i a n c e + 噪声 N o i s e 泛化误差 = 偏差 Bias + 方差 Variance + 噪声 Noise 泛化误差=偏差Bias+方差Variance+噪声Noise
其中:
- 偏差 Bias:模型过于简单,无法很好拟合真实规律;
- 方差 Variance:模型对训练数据过于敏感,泛化能力差;
- 噪声 Noise:数据中本身存在的随机误差,通常无法完全消除。
集成学习有效的关键在于两个条件:
- 基学习器要有一定准确性:如果每个模型都完全随机预测,那么集成起来也没有意义。每个基模型至少应该比随机猜测好一些。
- 基学习器之间要有差异性 :如果所有模型都完全一样,那么集成结果和单个模型没有区别。好的集成模型希望基学习器之间具有一定差异性。
差异性可以来自:
- 不同的训练样本;
- 不同的特征子集;
- 不同的模型结构;
- 不同的超参数;
- 不同的数据预处理方式;
- 不同的随机种子。
这也是为什么随机森林比单棵决策树更稳定,因为随机森林中的每棵树都不完全相同。
不同类型的集成学习方法,主要解决的问题也不同:
| 方法 | 主要思想 | 主要降低 |
|---|---|---|
| Bagging | 多个模型并行训练,结果平均或投票 | 方差 |
| Boosting | 多个模型串行训练,后一个模型关注前一个模型的错误 | 偏差 |
| Stacking | 多个不同模型作为一级模型,再用一个模型融合结果 | 综合提升 |
2 集成学习的基本思想
集成学习包含两个步骤:
2.1 构造多个基学习器
基学习器,也叫 base learner,指的是参与集成的单个模型。常见的基学习器包括:
- 决策树;
- 逻辑回归;
- 支持向量机;
- KNN;
- 神经网络;
- 朴素贝叶斯;
- 线性回归;
- 随机森林中的单棵树;
- GBDT 中的单棵树。
基学习器可以是同一种模型,也可以是不同类型的模型。
① 如果多个基学习器属于同一种模型,这类集成通常叫做同质集成。例如随机森林中有很多棵决策树。
关于随机森林模型的介绍,可以参见我写的这一篇文章:【数学建模】随机森林算法详解:原理、优缺点及应用 。
②如果多个基学习器来自不同模型,这类集成通常叫做异质集成。例如同时使用逻辑回归、随机森林、XGBoost、SVM,再做融合。
2.2 组合多个模型的预测结果
集成学习需要将多个模型的输出进行组合。对于分类任务,常见方式包括:
- 投票法 Voting;
- 加权投票 Weighted Voting;
- 概率平均;
- 加权概率平均;
- 使用元学习器进行融合。
对于回归任务,常见方式包括:
- 简单平均;
- 加权平均;
- 使用元模型预测最终结果。
3 集成学习的三大主流方法:Bagging、Boosting、Stacking
3.1 Bagging:并行式集成学习
3.1.1 Bagging 的核心思想
Bagging 是 Bootstrap Aggregating 的缩写。它的核心思想是:从原始训练集中有放回地随机采样,构造多个不同的训练子集,然后分别训练多个模型,最后将这些模型的结果进行平均或投票 。
Bagging 的训练过程是并行 的,也就是说多个基模型之间没有依赖关系 。
Bagging 通常用于降低模型方差,使模型更加稳定。
3.1.2 Bootstrap 有放回采样
Bagging 中非常重要的一个概念是 Bootstrap Sampling ,也就是有放回采样 。
假设原始训练集有 N 条数据。每次从这 N 条数据中随机抽取一条,抽完之后再放回,然后继续抽取,重复 N 次,得到一个新的训练子集。
由于是有放回采样,所以:
- 某些样本可能会被重复抽到;
- 某些样本可能一次都没有被抽到;
- 每个子集都和原始数据集相似,但又不完全相同。
这样就可以训练出多个存在差异的模型。
3.1.3 Bagging 的预测方式
对于分类任务 ,最终类别 = 多个模型预测结果的多数投票。
例如有 5 个模型预测某个样本:
text
模型1:正类
模型2:正类
模型3:负类
模型4:正类
模型5:负类最终正类有 3 票,负类有 2 票,所以输出正类。
对于回归任务 ,最终预测值 = 多个模型预测值的平均值。
例如:
text
模型1预测:80
模型2预测:82
模型3预测:78
模型4预测:81
模型5预测:79最终结果为:
text
(80 + 82 + 78 + 81 + 79) / 5 = 803.1.4 Bagging 的代表算法:随机森林
随机森林 Random Forest 是 Bagging 思想最经典的代表算法。随机森林由多棵决策树组成,每棵树使用不同的训练样本和特征子集进行训练。
随机森林相比普通决策树有明显优势:
- 不容易过拟合;
- 预测结果更稳定;
- 对异常值和噪声不太敏感;
- 可以处理高维特征;
- 可以输出特征重要性。
随机森林引入了两种随机性:
- 样本随机:每棵树使用 Bootstrap 采样得到的样本;
- 特征随机:每次节点分裂时,只从部分特征中选择最优特征。
正是这两种随机性,使得每棵树之间存在差异,从而提升集成效果。
关于随机森林模型的介绍,可以参见我写的这一篇文章:【数学建模】随机森林算法详解:原理、优缺点及应用 。
3.1.5 使用 scikit-learn 实现随机森林分类
python
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score
# 加载数据
iris = load_iris()
X = iris.data
y = iris.target
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42
)
# 构建随机森林模型
model = RandomForestClassifier(
n_estimators=100,
max_depth=None,
random_state=42
)
# 训练模型
model.fit(X_train, y_train)
# 预测
y_pred = model.predict(X_test)
# 评估准确率
acc = accuracy_score(y_test, y_pred)
print("Accuracy:", acc)其中:
n_estimators表示森林中树的数量;max_depth表示每棵树的最大深度;random_state用于控制随机性,保证实验可复现。
3.1.6 Bagging 的优缺点
优点:
- 可以有效降低模型方差;
- 模型更加稳定;
- 不容易过拟合;
- 支持并行训练,效率较高;
- 适合高方差模型,例如决策树。
缺点:
- 对降低偏差帮助有限;
- 模型解释性较差;
- 模型数量较多时,预测速度可能变慢;
- 对弱模型的提升不如 Boosting 明显。
3.2 Boosting:串行式集成学习
3.2.1 Boosting 的核心思想
Boosting 是另一类非常重要的集成学习方法。它的核心思想是:多个弱学习器按顺序 训练,后一个模型重点学习前一个模型预测错误的样本,最终将多个弱学习器组合成一个强学习器。
Boosting 和 Bagging 的最大区别在于:
- Bagging 中的模型是并行 训练的,Boosting 中的模型是串行训练的;
- Bagging 主要降低方差 ,Boosting 主要降低偏差。
3.2.2 什么是弱学习器?
弱学习器指的是性能只比随机猜测略好一点的模型。例如在二分类任务中,随机猜测准确率大约是 50%。如果某个模型准确率是 55%,它就可以看作一个弱学习器。
Boosting 的强大之处在于:即使每个模型都很弱,只要它们不断纠正前面模型的错误,最终也可以组合成一个性能很强的模型 。(降低偏差)
3.2.3 Boosting 的基本流程
Boosting 的训练过程:
- 初始化样本权重;
- 训练第一个弱学习器;
- 根据预测错误调整样本权重;
- 错误样本权重变大,正确样本权重变小;
- 训练下一个弱学习器;
- 重复上述过程;
- 将多个弱学习器加权组合,得到最终模型。
3.2.4 AdaBoost
AdaBoost 是最早也最经典的 Boosting 算法之一。AdaBoost 的基本思想是:对于前一个模型分类错误的样本,提高其权重;对于分类正确的样本,降低其权重。后续模型会更加关注难分类样本。
AdaBoost 的特点:
- 每轮训练都会调整样本权重;
- 错误率低的模型拥有更大的投票权重;
- 最终模型是多个弱分类器的加权组合。
使用 scikit-learn 实现 AdaBoost:
python
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split
from sklearn.ensemble import AdaBoostClassifier
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import accuracy_score
# 加载数据
data = load_breast_cancer()
X = data.data
y = data.target
# 划分数据集
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42
)
# 定义弱学习器
base_model = DecisionTreeClassifier(max_depth=1)
# 构建 AdaBoost 模型
model = AdaBoostClassifier(
estimator=base_model,
n_estimators=100,
learning_rate=0.5,
random_state=42
)
# 训练模型
model.fit(X_train, y_train)
# 预测
y_pred = model.predict(X_test)
# 评估
acc = accuracy_score(y_test, y_pred)
print("Accuracy:", acc)说明:
max_depth=1的决策树也叫决策树桩;n_estimators表示弱学习器数量;learning_rate表示每个弱学习器的贡献缩放比例。
3.2.5 GBDT
GBDT 的全称是 Gradient Boosting Decision Tree,即梯度提升决策树 。GBDT 也是 Boosting 家族中的经典算法。它的核心思想是:每一轮训练一个新的决策树,用来拟合前一轮模型的残差或负梯度方向。
对于回归任务,残差可以简单理解为:残差 = 真实值 - 当前模型预测值。
例如真实房价为 100 万,当前模型预测为 80 万,那么残差为 20 万。下一棵树就会重点学习这个 20 万的误差。
GBDT 的最终预测结果是多个树的累加:
最终预测 = 初始预测 + 第1棵树预测 + 第2棵树预测 + ... + 第M棵树预测
使用 scikit-learn 实现 GBDT 分类:
python
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split
from sklearn.ensemble import GradientBoostingClassifier
from sklearn.metrics import accuracy_score
# 加载数据
data = load_breast_cancer()
X = data.data
y = data.target
# 划分数据集
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42
)
# 构建 GBDT 模型
model = GradientBoostingClassifier(
n_estimators=100,
learning_rate=0.1,
max_depth=3,
random_state=42
)
# 训练模型
model.fit(X_train, y_train)
# 预测
y_pred = model.predict(X_test)
# 评估
acc = accuracy_score(y_test, y_pred)
print("Accuracy:", acc)3.2.6 XGBoost、LightGBM 和 CatBoost
在实际工程中,Boosting 系列算法非常常用,尤其是以下三个模型:
1. XGBoost
XGBoost 是 Extreme Gradient Boosting 的缩写,是 GBDT 的高效工程实现和改进版本。它的特点包括:
- 支持正则化;
- 支持并行计算;
- 支持缺失值处理;
- 支持列采样;
- 训练速度快;
- 泛化能力强。
2. LightGBM
LightGBM 是微软提出的一种高效梯度提升框架。它的特点包括:
- 训练速度非常快;
- 内存占用较低;
- 适合大规模数据;
- 使用直方图算法;
- 使用 Leaf-wise 生长策略;
- 对高维稀疏特征表现较好。
3. CatBoost
CatBoost 是 Yandex 开源的 Boosting 算法。它的特点包括:
- 对类别特征支持较好;
- 减少特征预处理成本;
- 对类别型数据表现优秀;
- 对参数不敏感,默认效果通常较好。
3.2.7 Boosting 的优缺点
优点:
- 通常预测精度很高;
- 可以有效降低偏差;
- 能够处理复杂非线性关系;
- 在结构化数据任务中表现非常强;
- XGBoost、LightGBM、CatBoost 在工业界和竞赛中应用广泛。
缺点:
- 模型串行训练,并行化不如 Bagging 简单;
- 对噪声和异常值较敏感;
- 参数较多,调参成本较高;
- 模型解释性相对较弱;
- 训练不当容易过拟合。
3.3 Stacking:模型融合的高级方法
3.3.1 Stacking 的核心思想
Stacking,也叫堆叠泛化,是一种更灵活的集成学习方法。它的核心思想是:先训练多个不同的基础模型,然后将这些模型的预测结果作为新的特征 ,再训练一个二级模型来学习如何融合这些结果。
Stacking 通常包含两层,第一层是多个 base model ,第二层是一个 meta model :
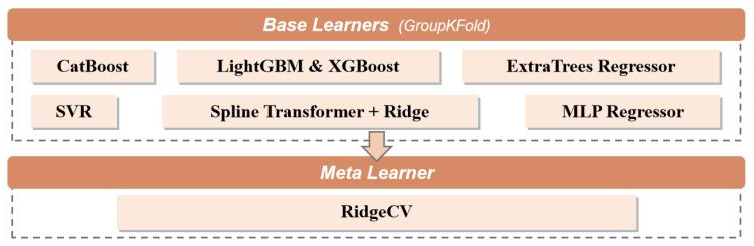
例如第一层有三个模型:Random Forest、XGBoost、Logistic Regression,它们分别对样本做预测,得到三个预测结果:
text
模型1预测概率:0.82
模型2预测概率:0.76
模型3预测概率:0.68然后将这些预测结果组成新的特征:
text
[0.82, 0.76, 0.68]再交给第二层模型,例如逻辑回归,输出最终预测结果。
3.3.2 Stacking 的基本流程
Stacking 的训练过程通常如下:
- 将训练集划分为 K 折;
- 对每个基础模型进行 K 折训练;
- 得到每个训练样本的 out-of-fold 预测结果;
- 使用这些预测结果作为新的训练特征;
- 训练第二层元模型;
- 测试时,先让基础模型预测,再让元模型融合结果。
因为如果直接用基础模型在训练集上的预测结果训练元模型,容易产生数据泄漏。基础模型已经见过这些训练样本,所以它在训练集上的预测结果可能过于乐观。元模型如果基于这些结果训练,就会产生过拟合。
因此,Stacking 通常使用 K 折交叉验证生成 out-of-fold 预测 ,使得某个样本的预测结果必须来自没有见过它的模型,这样可以更真实地模拟测试集上的预测情况。
3.3.3 使用 scikit-learn 实现 Stacking
python
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier, GradientBoostingClassifier, StackingClassifier
from sklearn.linear_model import LogisticRegression
from sklearn.svm import SVC
from sklearn.metrics import accuracy_score
# 加载数据
data = load_breast_cancer()
X = data.data
y = data.target
# 划分数据
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42
)
# 第一层基础模型
base_models = [
("rf", RandomForestClassifier(n_estimators=100, random_state=42)),
("gbdt", GradientBoostingClassifier(random_state=42)),
("svc", SVC(probability=True, random_state=42))
]
# 第二层元模型
meta_model = LogisticRegression(max_iter=1000)
# Stacking 模型
model = StackingClassifier(
estimators=base_models,
final_estimator=meta_model,
cv=5
)
# 训练
model.fit(X_train, y_train)
# 预测
y_pred = model.predict(X_test)
# 评估
acc = accuracy_score(y_test, y_pred)
print("Accuracy:", acc)3.3.4 Stacking 的优缺点
优点:
- 可以融合不同类型模型的优势;
- 通常效果较好;
- 模型组合非常灵活;
- 适合竞赛和复杂业务场景;
- 能够充分利用多个模型的预测信息。
缺点:
- 实现复杂度较高;
- 训练成本较大;
- 容易产生数据泄漏;
- 解释性较差;
- 模型部署复杂度较高。
3.4 Voting:最简单的集成方式
除了 Bagging、Boosting、Stacking,Voting 也是一种常见的集成方法。Voting 的思想非常简单,即同时训练多个模型,然后通过投票或概率平均得到最终结果。
Voting 主要分为两种:Hard Voting 和 Soft Voting。
3.4.1 Hard Voting
Hard Voting 指的是多数投票。例如三个模型分别预测:
text
模型1:类别 A
模型2:类别 B
模型3:类别 A最终类别为 A。
3.4.2 Soft Voting
Soft Voting 指的是概率平均。例如三个模型预测某个样本属于正类的概率分别为:
text
模型1:0.8
模型2:0.7
模型3:0.6最终正类概率为:
text
(0.8 + 0.7 + 0.6) / 3 = 0.7如果阈值为 0.5,则最终预测为正类。
Soft Voting 通常比 Hard Voting 更稳定,因为它利用了模型输出的概率信息。
3.4.3 使用 scikit-learn 实现 Voting
python
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split
from sklearn.ensemble import VotingClassifier, RandomForestClassifier
from sklearn.linear_model import LogisticRegression
from sklearn.svm import SVC
from sklearn.metrics import accuracy_score
# 加载数据
data = load_breast_cancer()
X = data.data
y = data.target
# 划分数据
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42
)
# 定义多个模型
clf1 = LogisticRegression(max_iter=1000)
clf2 = RandomForestClassifier(n_estimators=100, random_state=42)
clf3 = SVC(probability=True, random_state=42)
# Soft Voting
model = VotingClassifier(
estimators=[
("lr", clf1),
("rf", clf2),
("svc", clf3)
],
voting="soft"
)
# 训练
model.fit(X_train, y_train)
# 预测
y_pred = model.predict(X_test)
# 评估
acc = accuracy_score(y_test, y_pred)
print("Accuracy:", acc)3.5 Bagging、Boosting、Stacking 对比
| 对比项 | Bagging | Boosting | Stacking |
|---|---|---|---|
| 训练方式 | 并行 | 串行 | 分层 |
| 代表算法 | 随机森林 | AdaBoost、GBDT、XGBoost、LightGBM | StackingClassifier |
| 主要目标 | 降低方差 | 降低偏差 | 融合多模型优势 |
| 基学习器关系 | 相互独立 | 前后依赖 | 第一层输出给第二层 |
| 对噪声敏感度 | 较低 | 较高 | 取决于模型设计 |
| 并行能力 | 强 | 较弱 | 中等 |
| 过拟合风险 | 较低 | 中等到较高 | 中等到较高 |
| 实现复杂度 | 中等 | 中等到较高 | 较高 |
| 典型应用 | 随机森林 | XGBoost、LightGBM、CatBoost | 比赛模型融合 |
4 集成学习中的常见参数
4.1 n_estimators
表示基学习器数量。
在随机森林、AdaBoost、GBDT、XGBoost、LightGBM 中都很常见。
一般来说:
n_estimators太小,模型能力不足;n_estimators太大,训练成本增加;- 对于 Boosting,过大还可能导致过拟合。
4.2 learning_rate
主要出现在 Boosting 算法中。
它控制每个弱学习器对最终结果的贡献大小。
一般来说:
learning_rate较小,模型学习更慢,但可能泛化更好;learning_rate较大,模型学习更快,但可能过拟合;- 通常需要和
n_estimators一起调节。
4.3 max_depth
表示树模型的最大深度。
- 深度越大,模型越复杂;
- 深度越小,模型越简单;
- 深度过大容易过拟合;
- 深度过小容易欠拟合。
在随机森林中,单棵树可以适当深一些。在 Boosting 中,通常使用较浅的树。
4.4 subsample
表示每轮训练使用的样本比例,如 subsample = 0.8 表示每轮只使用 80% 的训练样本。
它可以增加随机性,降低过拟合风险。
4.5 colsample_bytree
常见于 XGBoost 和 LightGBM,表示每棵树使用的特征比例。例如 colsample_bytree = 0.8 表示每棵树只使用 80% 的特征。
这样可以增加模型差异性,提高泛化能力。
5 关于集成学习在实际应用时的一些建议
5.1 一些情景下的应用建议
- 数据量较小时,可以优先考虑:
- 随机森林;
- AdaBoost;
- GBDT;
- 简单 Voting;
- 简单 Stacking。
数据量较小时,过于复杂的集成模型容易过拟合。
- 数据量较大时,可以优先考虑:
- LightGBM;
- XGBoost;
- CatBoost;
- 随机森林。
其中 LightGBM 在大规模数据上训练速度较快。
- 类别特征较多时,可以优先考虑:
- CatBoost;
- LightGBM;
- 经过编码后的 XGBoost。
CatBoost 对类别特征支持较好,通常可以减少人工特征编码成本。
5.2 集成学习的注意事项
1. 不要盲目堆模型
集成学习不是模型越多越好。如果多个模型高度相似,增加模型数量并不会带来明显提升,反而会增加训练和部署成本。
2. 注意数据泄漏
在 Stacking 中尤其要注意数据泄漏问题。
先用整个训练集训练基础模型,再用基础模型对训练集预测,最后训练元模型的做法会导致元模型看到过于乐观的预测结果。
正确做法是使用 K 折交叉验证生成 out-of-fold 预测结果。
3. 注意训练成本
集成学习通常比单模型更耗费计算资源,尤其是模型数量很多、数据量很大、特征维度很高、使用多层 Stacking 或复杂调参策略等情况下。在实际项目中,需要平衡模型效果和工程成本。
4. 注意模型解释性
集成模型通常比单模型更难解释。如果业务场景对解释性要求很高,例如金融风控、医疗诊断等,需要结合:
- 特征重要性;
- SHAP;
- LIME;
- PDP;
- 业务规则分析。
5.3 面试常见问题
5.3.1 Bagging 和 Boosting 有什么区别?
Bagging 是并行训练多个模型,主要用于降低方差;Boosting 是串行训练多个模型,后一个模型关注前一个模型的错误,主要用于降低偏差。
5.3.2 随机森林为什么不容易过拟合?
随机森林通过样本随机和特征随机训练多棵决策树,然后对结果进行投票或平均。单棵树可能过拟合,但多棵树的平均结果可以降低方差,因此整体更稳定。
5.3.3 XGBoost 为什么效果好?
XGBoost 在 GBDT 基础上进行了多方面优化,包括正则化、二阶梯度信息、列采样、缺失值处理、并行计算等,因此在很多结构化数据任务上表现优秀。
5.3.4 Stacking 为什么容易数据泄漏?
如果基础模型先在整个训练集上训练,再对同一训练集预测,并将这些预测结果用于训练元模型,那么元模型实际上使用了"被基础模型见过的数据",预测结果会过于乐观,导致数据泄漏。
5.3.5 集成学习一定比单模型好吗?
不一定。集成学习通常能提升模型稳定性和预测精度,但前提是基学习器要有一定准确性,并且模型之间要有差异性。如果多个模型都很差,或者模型之间高度相似,集成效果可能并不好。
6 完整示例:对比多个集成模型效果
下面使用乳腺癌数据集,对比随机森林、AdaBoost、GBDT 和 Stacking 的效果。
python
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
from sklearn.ensemble import (
RandomForestClassifier,
AdaBoostClassifier,
GradientBoostingClassifier,
StackingClassifier
)
from sklearn.tree import DecisionTreeClassifier
from sklearn.linear_model import LogisticRegression
from sklearn.svm import SVC
# 1. 加载数据
data = load_breast_cancer()
X = data.data
y = data.target
# 2. 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(
X, y,
test_size=0.2,
random_state=42
)
# 3. 定义模型
models = {
"RandomForest": RandomForestClassifier(
n_estimators=100,
random_state=42
),
"AdaBoost": AdaBoostClassifier(
estimator=DecisionTreeClassifier(max_depth=1),
n_estimators=100,
learning_rate=0.5,
random_state=42
),
"GBDT": GradientBoostingClassifier(
n_estimators=100,
learning_rate=0.1,
max_depth=3,
random_state=42
)
}
# 4. 定义 Stacking 模型
base_models = [
("rf", RandomForestClassifier(n_estimators=100, random_state=42)),
("gbdt", GradientBoostingClassifier(random_state=42)),
("svc", SVC(probability=True, random_state=42))
]
stacking_model = StackingClassifier(
estimators=base_models,
final_estimator=LogisticRegression(max_iter=1000),
cv=5
)
models["Stacking"] = stacking_model
# 5. 训练并评估
for name, model in models.items():
model.fit(X_train, y_train)
y_pred = model.predict(X_test)
acc = accuracy_score(y_test, y_pred)
print(f"{name}: {acc:.4f}")输出结果可能类似:
text
RandomForest: 0.9649
AdaBoost: 0.9737
GBDT: 0.9561
Stacking: 0.9825注意:具体结果可能会因为 scikit-learn 版本、随机种子、数据划分方式不同而略有差异。
7 总结
集成学习是机器学习中非常重要的一类方法,它通过组合多个模型来提升整体预测能力。
本文主要介绍了以下内容:
- Ensemble Learning 的基本概念;
- 集成学习为什么有效;
- Bagging 的原理和随机森林;
- Boosting 的原理和 AdaBoost、GBDT;
- XGBoost、LightGBM、CatBoost 的基本特点;
- Stacking 的原理和实现;
- Voting 的简单融合方式;
- 集成学习的参数、应用场景和注意事项;
- 使用 scikit-learn 完成集成学习实战。
简单总结:
text
Bagging:多个模型并行训练,降低方差,代表算法是随机森林。
Boosting:多个模型串行训练,降低偏差,代表算法是 AdaBoost、GBDT、XGBoost、LightGBM。
Stacking:多层模型融合,利用不同模型的优势,常用于竞赛和复杂业务场景。
Voting:最简单的模型融合方法,适合快速构建 baseline。在实际项目中,集成学习是一种非常强大的建模工具。尤其是在结构化数据任务中,随机森林、XGBoost、LightGBM、CatBoost 往往可以作为非常重要的 baseline 模型。
集成学习在实际业务中应用非常广泛,尤其适合结构化数据任务。常见应用包括:
- 信用评分;
- 风控建模;
- 欺诈检测;
- 用户流失预测;
- 推荐系统;
- 广告点击率预测;
- 医疗风险预测;
- 房价预测;
- 销售额预测;
- 金融量化建模;
- Kaggle、天池等机器学习竞赛。
在表格型数据任务中,XGBoost、LightGBM、CatBoost 经常是非常强的 baseline。
不过,集成学习并不是万能的。使用时需要综合考虑:
- 模型效果;
- 训练成本;
- 推理速度;
- 可解释性;
- 数据泄漏风险;
- 部署复杂度。
合理使用集成学习,往往能够显著提升机器学习模型的表现。