在第019章里我们生成了一个数字人模特"小一",本来想着先通过给"小一"换装、换背景,来个大家讲一下图像编辑模型的使用。
后来又考虑到图像编辑是一个大的知识点,只是简单搭一个基础的图像编辑模型的工作流的话优点太浅了,太深的话一是我自己目前前的知识储备也有些不够,再一个一下深入到这里面去的话一时半会是出不来的。
后来就觉得先来个语音的生成,把数字人的音色给设计出来。下面再去写一段广告词,把数字人要说的话给克隆出来,最后再通过一个视频模型让数字人动起来。
这样我们很快就能完成,从一个从基础的图片、再到配音、再到数字人的宣传视频的完整的的项目,这样大家也更容易有成就感。
等我们把这个简单的项目完成了,大家也就对ComfyUI有了一个基础的了解,我们后面再去啃图片编辑这个大的知识点,可能更好一些。
好了,废话说完,开始进入今天的正题:Qwen3-TTS模型的音色设计。
一、Qwen3-TTS的介绍
官方介绍:https://qwen.ai/blog?id=qwen3tts-0115
详细的介绍大家可以复制上面的链接,最好能仔细看看官方的介绍,里面有很多示例音色我么都是可以直接用的。
Qwen3-TTS 是由Qwen开发的一系列功能强大的语音生成,全面支持音色克隆、音色创造、超高质量拟人化语音生成,以及基于自然语言描述的语音控制,为开发者与用户提供最全面的语音生成功能。
这里不得不夸一夸阿里,国内就模型开源这一块,阿里那是当之无愧的No.1。文书生图又Z-Image/Qwen2511,图像编辑有Qwen2512,语音有Qwen3-TTS,视频有Wan2.2,可以说一个阿里支撑起了国内开源社区的大半壁江上。
再一个也是因为阿里贡献的VAE,我们才能再国外的Flux模型上用中文的。
二、ComfyUI-Qwen-TTS插件下载
要使用Qwen3-TTS我们先需要给自己的ComfyUi下载一个名为"ComfyUI-Qwen-TTS"的插件。
1、打开GitHub,搜索"ComfyUI-Qwen-TTS"
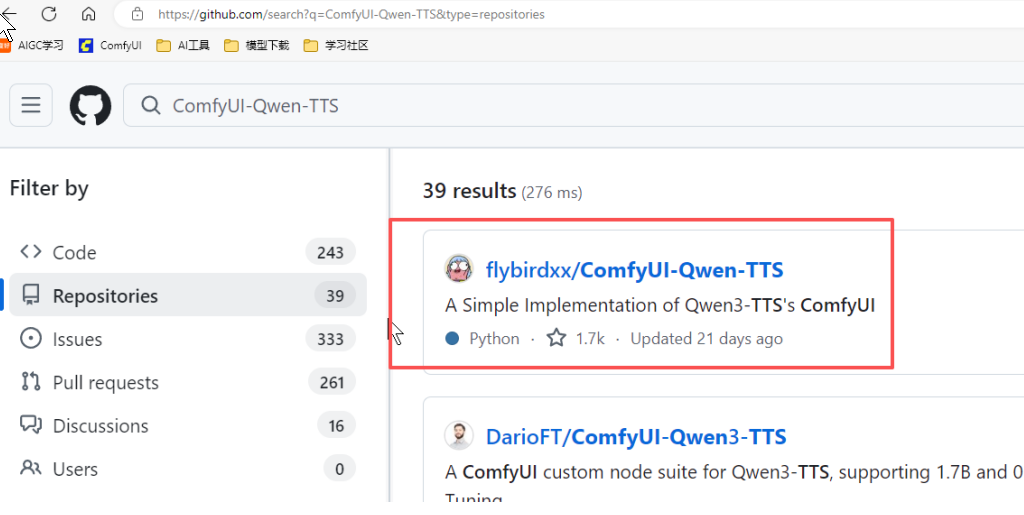
2、先把插件下载下来
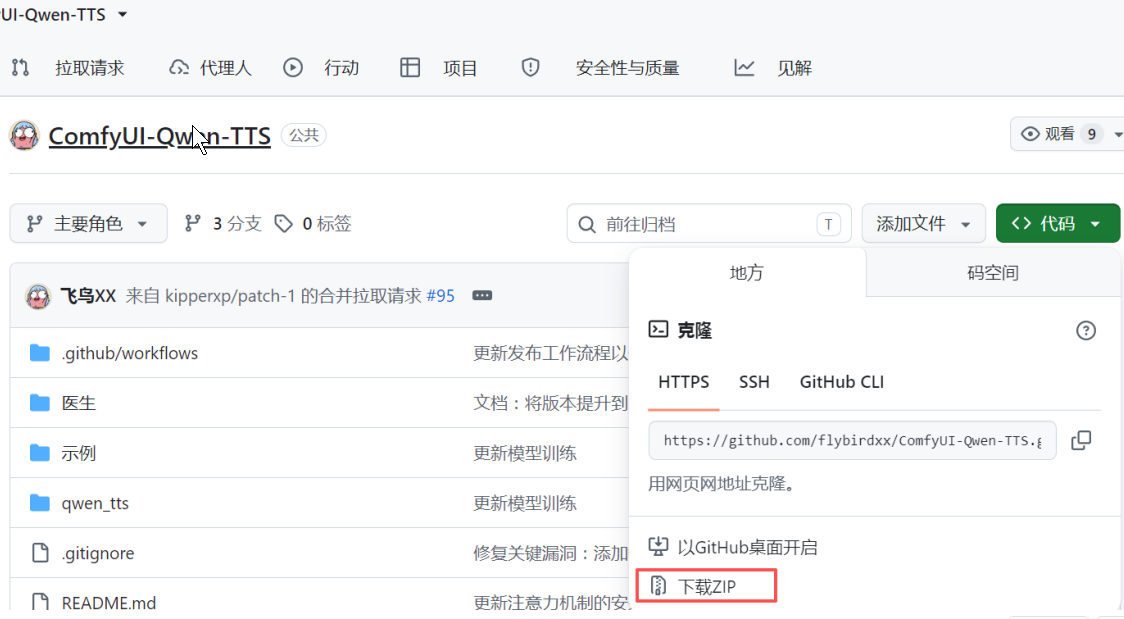
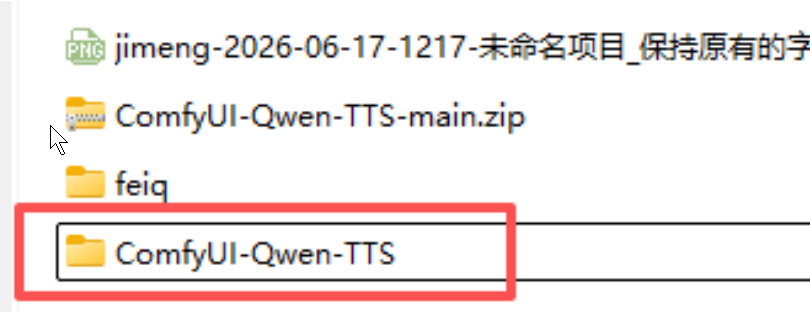
3、把我们把下载下来的压缩包解压(用7-zip工具),解压后把自带的后缀-main去掉。
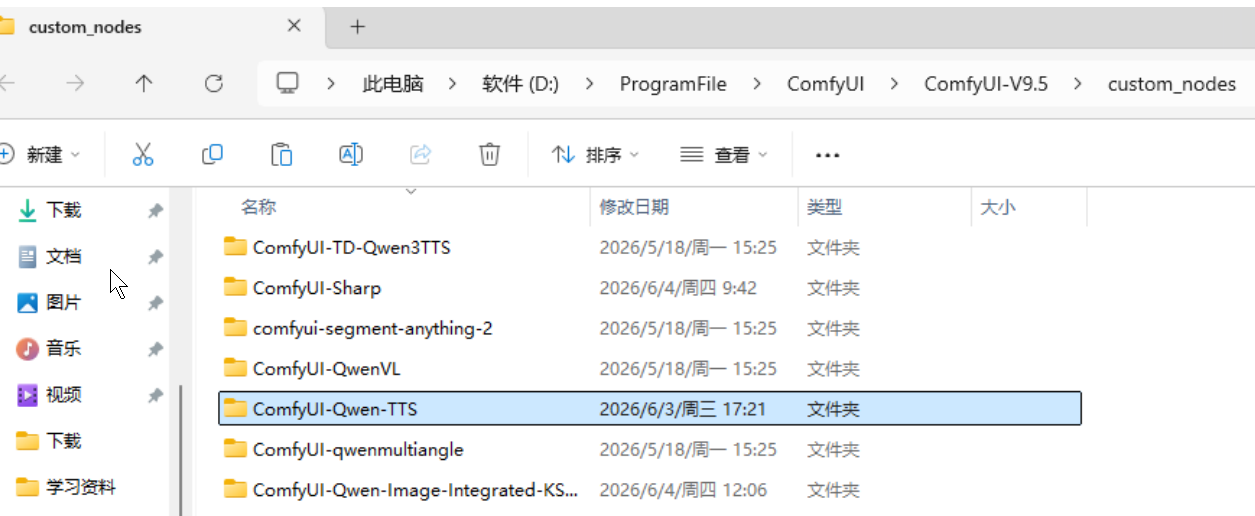
4、最后把"ComfyUI-Qwen-TTS"复制到ComfyUI安装目录的"custom_nodes"中
5、部署完成以后,仔细看看GitHub上关于插件的介绍,可以看到他有个提醒说是这个插件只支持Transformers5.0以下的版本,5.0以上的不兼容。
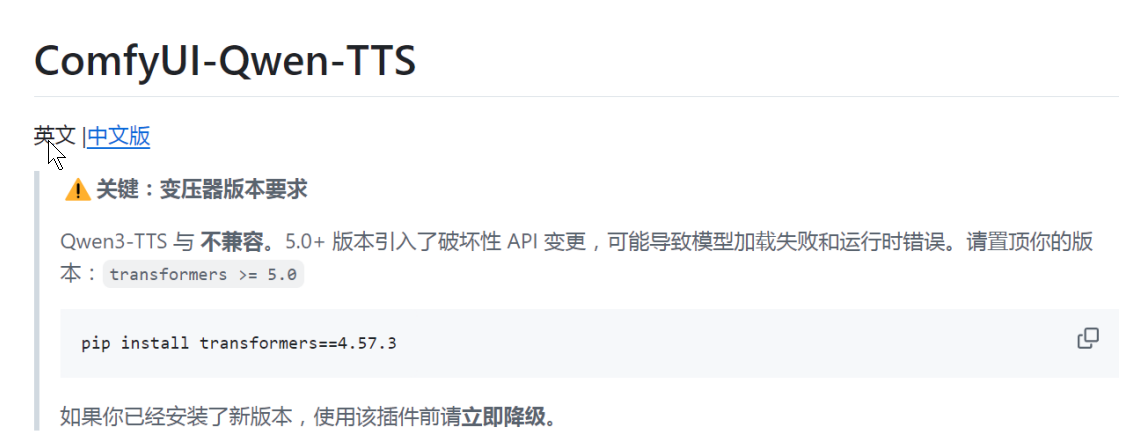
那么这个Transformers是个什么东西呢?
transformers 是 Hugging Face 开发的 Python 开源 AI 工具库,是目前大模型、语音、文本类 AI 程序的底层核心依赖包。 简单说:所有 Qwen 通义千问、Llama、语音 TTS、文生图描述、翻译、聊天大模型,底层几乎都靠它加载和运行模型权重。
transformers5.0 及以上版本官方重构了底层代码,改动了大量函数接口(破坏性 API 变更) 。
Qwen3-TTS 插件是基于 4.x 系列接口开发的,新版库找不到原来的函数,直接加载失败、运行报错;所以插件强制要求锁定 4.57.3 这类 4.x 旧版本。
可以把Qwen3-TTS想象成一个游戏,而transformers就是这个游戏的驱动。
6、那么如何查看我们的ComfyUI中的Transfroms版本是否符合要求呢?
(1)先启动ComfyUI的启动窗口>>高级选项>>启动命令提示符,如下图:
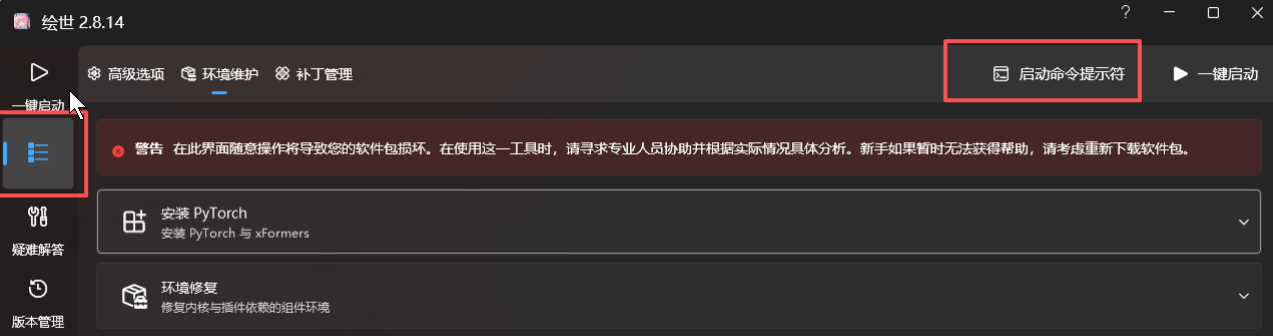
(2)在打开的窗口中输入"python -m pip show transformers"
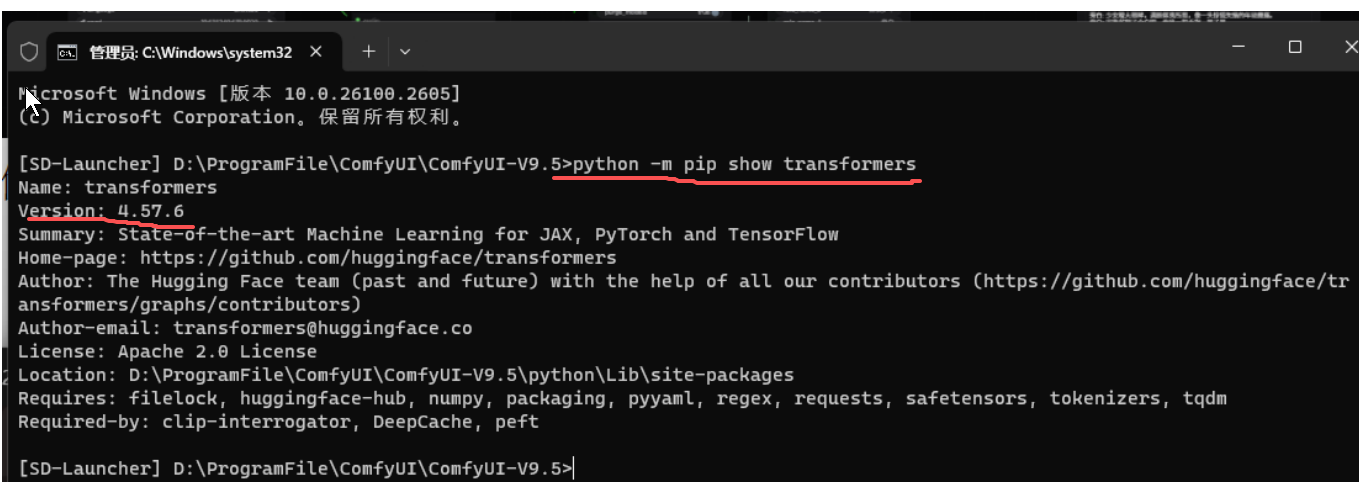
我们可以看到图中,我的版本是"4.57.6"符合要求,如果大家和我一样用的是秋叶9.5的集合包,那就不会存在问题。
7、继续从这个介绍往下看,给了两个runninghub上的示例工作流,不过这两个链接是runninghub的海外版,我们可以点击进去看看他的地址是www.runninghub.ai,海外版我们用起来不太方面,把.ai的后缀改成.cn就是国内的runninghub的网站了,大家可以进去自己看看试一试。

二、音色设计的模型下载
关于模型下载,官方提供了两个版本"1.7B"和"0.6B",其中"1.7B"需要6G以上的显存。

要搭建音色设计的工作流,我们需要下载两个模型"Qwen3-TTS-12Hz-1.7B-VoiceDesign "和"Qwen3-TTS-Tokenizer-12Hz"。我的电脑是16G的显存,我选择1.7B。
Qwen3-TTS-12Hz-1.7B-VoiceDesign(主语音生成模型):这是语音生成主干大模型 ,负责两大核心任务:
(1)音色定制 :解析你输入的音色描述词(如 "成熟御姐嗓音,充满诱惑"),生成对应声线特征;
(2)文本转语音波形计算 :结合文本、音色特征,生成 12Hz 规格的声学频谱,最终输出完整人声音频
Qwen3-TTS-Tokenizer-12Hz (分词编码器):Tokenizer = 分词 / 文本编码器,作用是把人类文字转换成模型能看懂的数字 Token 序列。
(1)对中文、标点、语气词做切分;
(2)将文字映射为专用数字编码,输入给上面的 VoiceDesign 模型;
(3)附带语音专用词汇表、特殊标记(停顿、语调控制符),保证断句、语气自然。
我们先下载"Qwen3-TTS-12Hz-1.7B-VoiceDesign", 莫塔社区(www.modelscope.cn)搜索**"Qwen3-TTS-12Hz-1.7B-VoiceDesign"。**
这个就不用找ComfyUI的量化版本了,直接进第一个官方原版。
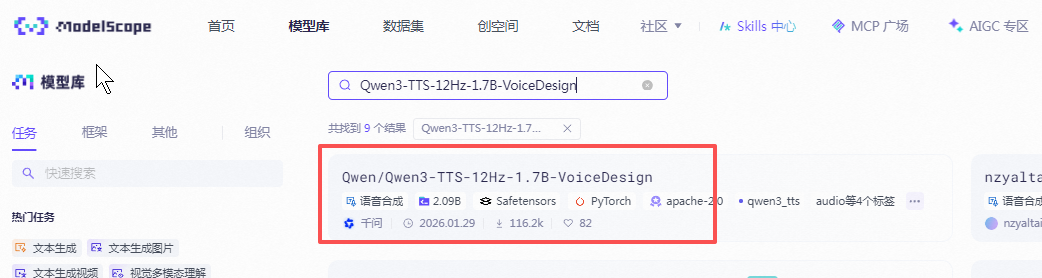
这个模型的下载和我们前面下载"Z-Image"有点区别,需要将整个模型完整的下载下来,而不是像Z-Image那样只下载一个蒸馏过的量化版本的的文件。
我们需要点击,右侧的"下载模型",如下图: 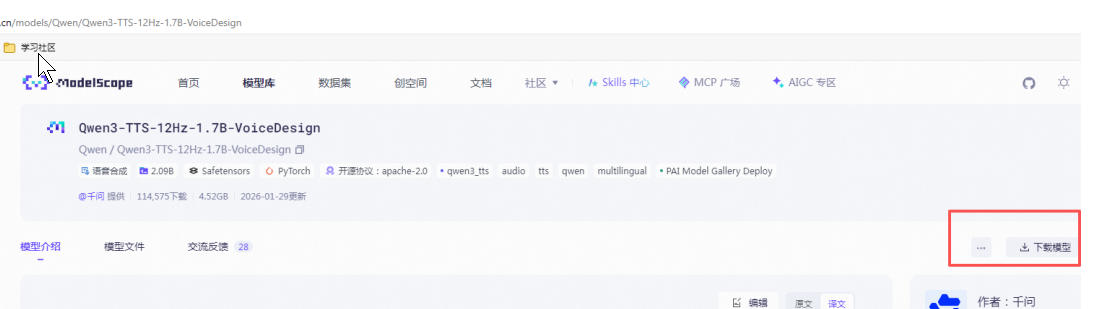
点击以后会在界面的右侧出现一个,操作指引。
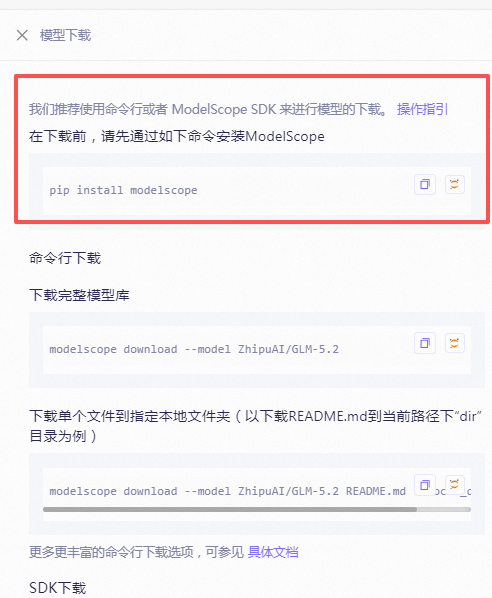
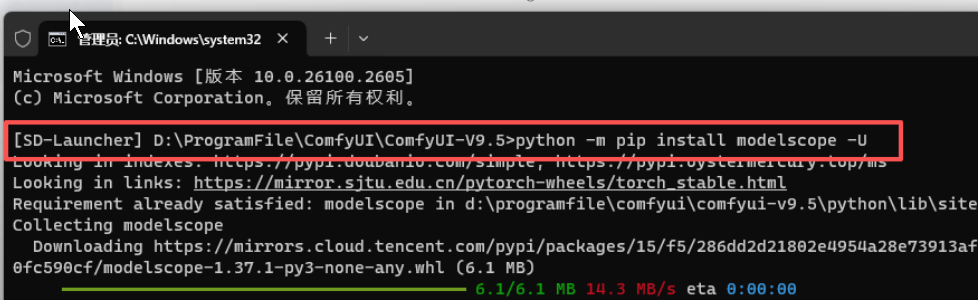
我们先看第一个"提示我们先安装ModelScope ",上面给的指令是"pip install modelscope",但由于我们用的不是官方版的ComfyUi,而是秋叶版的集合包,所以我们需要把指令改一下,改为"python -m pip install modelscope -U"。
具体操作如下:
在comfyUI启动界面>>高级选项>>启动命令提示符,打开Dos窗口
"ModelScope"安装完成以后,继续往下看"下载模型的操作指引",找到SDK下载:(如下图)
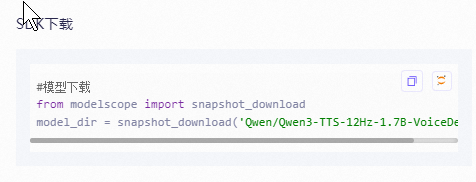
这个代码不能直接用,我们需要改一下,如下:
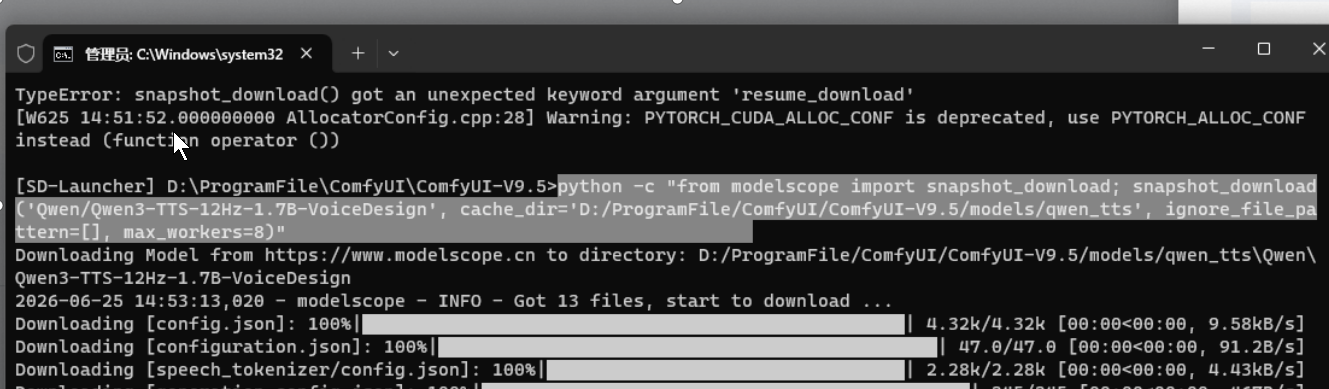
python -c "from modelscope import snapshot_download; snapshot_download('Qwen/Qwen3-TTS-12Hz-1.7B-VoiceDesign',cache_dir='D:/ProgramFile/ComfyUI/ComfyUI-V9.5/models/qwen_tts', ignore_file_pattern=\[\], max_workers=8)"
我给大家解释一下,这段代码的含义:
python -c
"from modelscope import snapshot_download;
///注意把绿色部分用魔塔网站SDK下载里面的绿色部分替换
snapshot_download('Qwen/Qwen3-TTS-12Hz-1.7B-VoiceDesign',
////这段是让直接下载到指定位置省的我们再复制转移,你需要改成你自己的位置
cache_dir='D:/ProgramFile/ComfyUI/ComfyUI-V9.5/models/qwen_tts',
////完整作用:下载模型时,不跳过仓库里任意文件,把全部文件完整下载到本地。
ignore_file_pattern=\[\]
////多线程参数旧版兼容,保留用来提升下载速度
max_workers=8 "
我自己在下载的时候出了点问题如下图:

有一项一直没跑完,我如果重复执行命令,会出现下面这样:

其实主要文件已经下载完成了,最后这个进度条是Windows 系统下 modelscope 创建符号链接没有完成,可以不用管,继续下载:'Qwen/Qwen3-TTS-Tokenizer-12Hz',下载方法和上面的方法一样,只需要注意SDK中的链接即可。
下载完成后,我们进去文件路径,会发现里面有一些临时文件(就是上面那个没下载完的进度条造成的),手动修改一下。
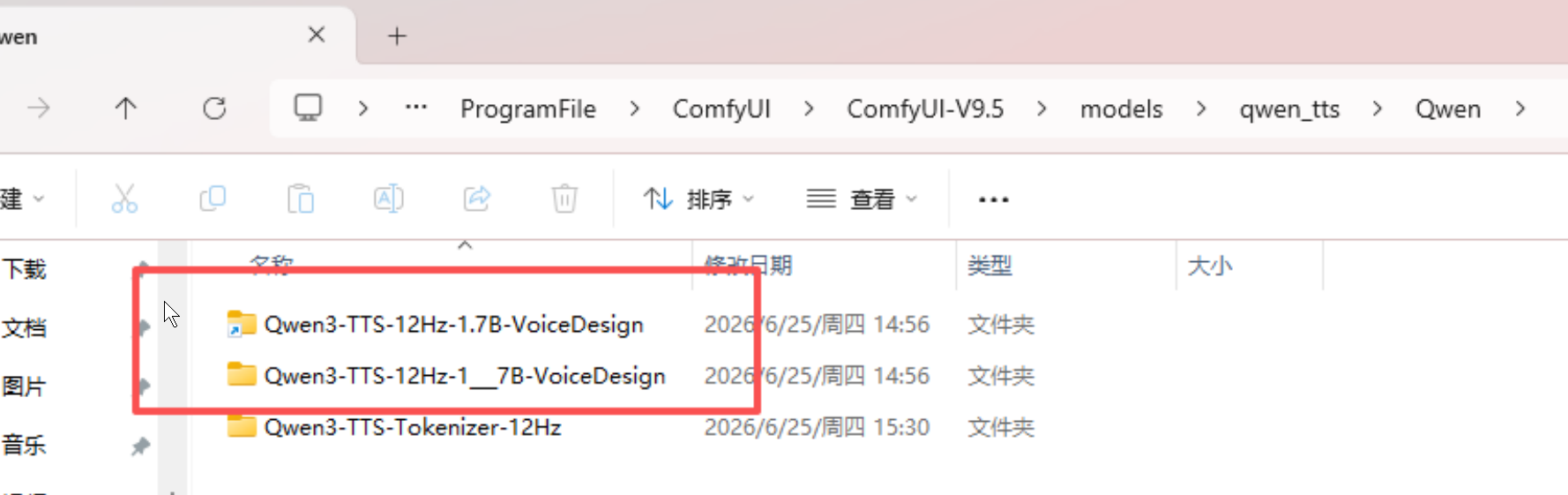
注意把qwen_tts的文件夹名称改为"Qwen3-TTS-Models"然后把Qwen3-TTS-12Hz-1.7B-VoiceDesign(4.2G) 和 Qwen3-TTS-Tokenizer-12Hz(650M)这两个文件夹直接放到"Qwen3-TTS-Models"的文件下面。
为什么把qwen_tts的文件夹名称改为"Qwen3-TTS-Models",因为自己最开始看的学习资料里是"qwen_tts",结果我弄完自己去工作流里实际运行的时候报错了,提示我模型路径不对需要改成"Qwen3-TTS-Models"。
正确的存放路径如下:
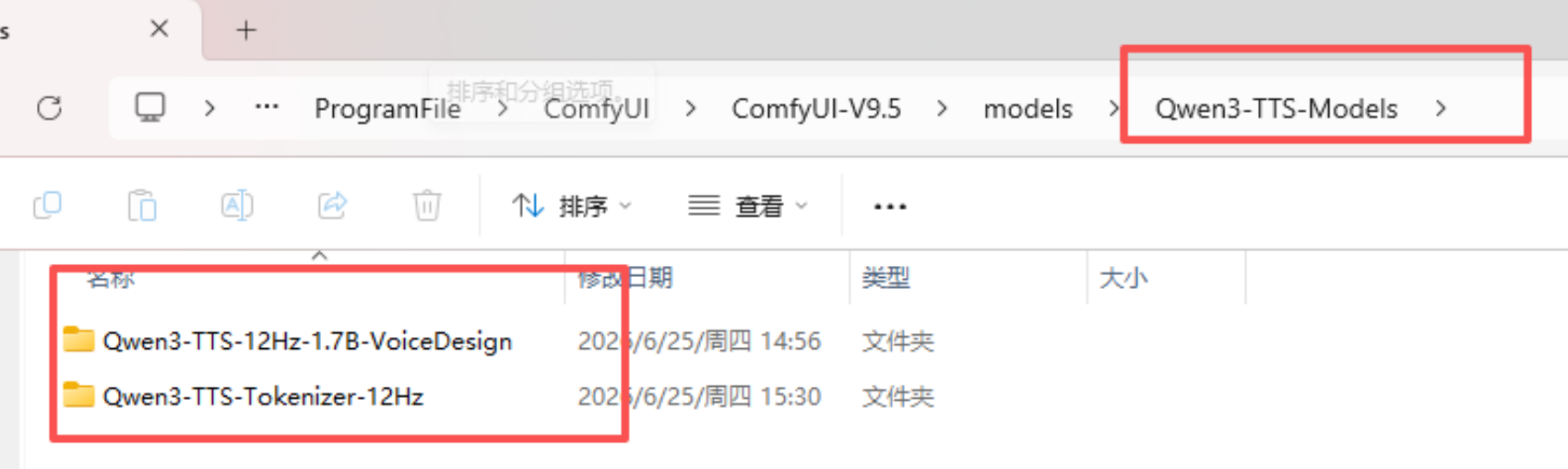
到这里我们把所有需要准备的工作就准备完成了,下一步就是搭建音色设计的工作流出了,我们下一章继续。