📚 本系列系统梳理了 Java 开发的详细知识点,从基础语法到工程实践层层递进,内容详实成体系,建议先收藏再慢慢阅读,方便日后随时回顾查阅。
前言
前一篇讲的是以 RabbitMQ 为代表的"传统"消息队列模型------Exchange 路由、Queue 收件箱。Kafka 虽然也叫"消息队列",但它的底层设计思路完全不同:Kafka 本质上是一个"分布式的、可持久化的日志(Log)系统",消息队列只是它最常见的使用方式之一。
这种设计差异,决定了 Kafka 在吞吐量 、消息保留方式 、消费模型上和 RabbitMQ 有本质区别------这也是面试里"Kafka 和 RabbitMQ 有什么区别"这道题的根源。这篇就把这些原理讲清楚。
1. 核心概念
先建立一张全景图,再逐个解释每个名词:
Kafka 集群(多个 Broker)
└── Topic: "order-events"
├── Partition 0 [msg0, msg1, msg2, msg3, ...] ← 每个分区内部是一个有序的"日志文件"
├── Partition 1 [msg0, msg1, msg2, ...]
└── Partition 2 [msg0, msg1, msg2, msg3, msg4, ...]
Producer ──写入──► Topic 的某个 Partition
Consumer Group "points-service-group"
├── Consumer A ──消费── Partition 0
├── Consumer B ──消费── Partition 1
└── Consumer C ──消费── Partition 2| 概念 | 说明 |
|---|---|
| Broker | Kafka 集群中的一台服务器,一个集群通常由多台 Broker 组成 |
| Topic | 消息的逻辑分类,类似 RabbitMQ 的 Queue,但只是一个名字,真正存数据的是下面的 Partition |
| Partition(分区) | Topic 被切分成多个分区,每个分区是一个独立的、按写入顺序排列的日志文件,是 Kafka 并行处理的基本单位 |
| Offset(偏移量) | 消息在分区内的"序号",从0开始递增,类似数组下标------一旦写入,永不改变 |
| Producer | 生产者,决定一条消息写到 Topic 的哪个 Partition |
| Consumer | 消费者,从某个 Partition 按 Offset 顺序读取消息 |
| Consumer Group(消费者组) | 多个 Consumer 组成一个组,一起消费同一个 Topic,组内每个分区只会被组内一个 Consumer 消费 |
2. 为什么 Kafka 吞吐量这么高
这是 Kafka 区别于 RabbitMQ 最核心的部分------RabbitMQ 设计目标是"灵活的路由 + 低延迟的小规模消息",Kafka 设计目标是"海量数据的高吞吐写入与读取"。靠的是几个底层技巧:
2.1 顺序写磁盘
很多人以为"写磁盘=慢",但慢的是随机写 (磁头来回寻道)。Kafka 的每个 Partition 在磁盘上就是一个只追加(append-only)的文件 ------新消息永远写在文件末尾,这种顺序写的速度可以接近内存写入速度,甚至比某些"随机写"的内存操作还快。
Partition 0 对应的日志文件:
[msg0][msg1][msg2][msg3] ← 新消息永远追加在这里,不会修改/删除中间的内容2.2 页缓存(Page Cache)+ 零拷贝(Zero Copy)
写入时 :Kafka 调用 write() 把消息写到操作系统的页缓存(Page Cache,可以理解成内存里的一块缓冲区)就立刻返回,不等真正写入磁盘。剩下的事交给操作系统------操作系统会在后台找合适的时机(比如数据积累到一定量、或者过了一段时间),把这些内存里的数据批量刷到磁盘上。
你可以理解成:Kafka 只负责"把数据递给操作系统",至于操作系统什么时候真正落盘,Kafka 不关心、也不用等。这一步省掉的,就是"每条消息都要等磁盘真正写完才能继续"的等待时间。
读取时 :消费者来读消息,正常流程是"磁盘 → 操作系统内存 → 应用程序内存 → 网络发送缓冲区 → 网卡",数据要被来回搬好几次。Kafka 用了 sendfile 这个系统调用后,数据可以从操作系统内存直接送到网卡,不用先搬进 Kafka 进程自己的内存里再搬出去------少了一趟"进出应用程序"的搬运过程,这就是"零拷贝"。
简化理解:原来是"快递先卸到你家客厅,你再搬上车";零拷贝相当于"快递直接从仓库装上车",省掉了"卸到客厅"这一步多余的搬运。
2.3 批量发送与压缩
Producer 不会"来一条消息就发一次网络请求",而是先把消息放进一个本地缓冲区,攒成一批(batch)之后再一次性发出去,并且可以对整个批次进行压缩(如 Snappy/LZ4)。批量+压缩既减少了网络请求次数,又减少了传输的数据量。
什么时候触发发送
缓冲区里的消息满足下面任一条件,就会被打包发送:
| 配置 | 作用 |
|---|---|
batch.size |
这一批消息攒够了多少字节(默认16KB),攒够就发 |
linger.ms |
即使没攒够,最多再等多久也要发出去(默认0,可以调大让"攒批"效果更明显) |
可以理解成"攒够一车货 or 等到发车时间,哪个先到就先发车"------batch.size 是"装满"的条件,linger.ms 是"超时"的条件,避免消息因为一直凑不够一批而迟迟发不出去。
小结一句话:RabbitMQ 为了支持灵活路由和复杂特性,设计更"重";Kafka 把模型简化成"顺序写的日志文件",用最朴素的数据结构换取了极高的吞吐量。
3. Partition 与顺序性
3.1 一条消息写到哪个 Partition
Producer 发送消息时,可以指定一个 key(比如 orderId),Kafka 会用 hash(key) % 分区数 来决定写入哪个分区------这和 31 数据结构底层原理 里 HashMap 用 hash & (capacity-1) 决定桶位置是同一个思路:相同的 key,永远落到同一个分区。
如果不指定 key,Kafka 会轮询各个分区,尽量让数据均匀分布。
3.2 顺序性:分区内有序,分区间不保证
这是 Kafka 顺序性的关键结论,也是面试常考点:
| 范围 | 是否保证顺序 |
|---|---|
| 同一个 Partition 内 | 保证------消息严格按写入顺序排列,Offset 递增 |
| 跨 Partition | 不保证------Partition 0 和 Partition 1 之间的消息没有先后关系 |
实际应用 :如果要求"同一个订单的多条消息必须按顺序处理",给消息指定 key = orderId,这样这个订单的所有消息都会进入同一个分区 ,分区内天然有序。这正是 30 消息队列 第8节里提到的"用分区Key保证局部顺序"的具体实现方式。
4. Consumer Group:消费者组
4.1 分区与消费者的分配关系
一个 Topic 的多个 Partition,会被分配 给同一个 Consumer Group 内的多个 Consumer------一个分区只能被组内一个消费者消费(但一个消费者可以消费多个分区)。
下面以 Topic order-events(3 个 Partition)为例,看三种不同的 Consumer 数量会怎样分配:
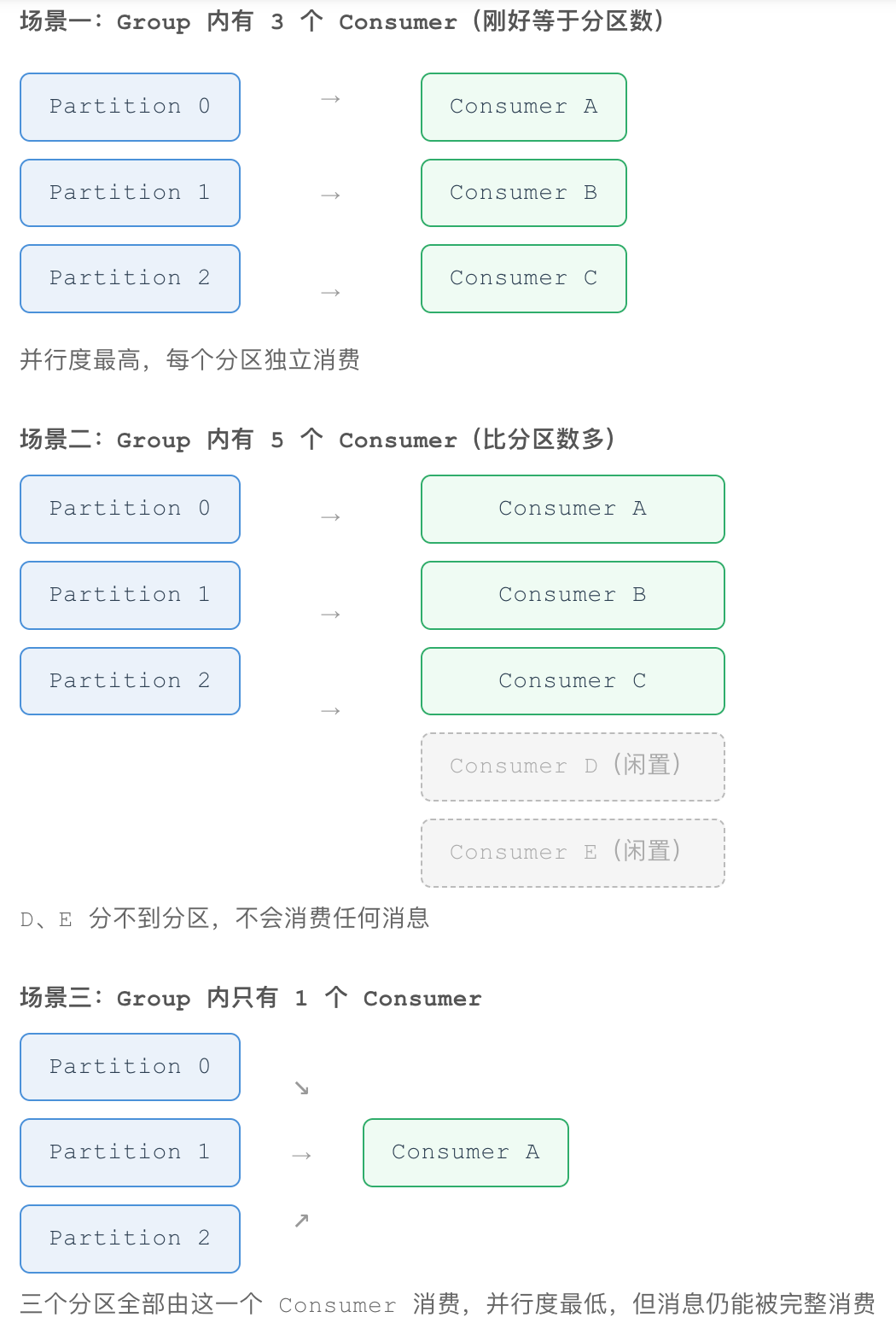
结论 :分区数决定了一个 Consumer Group 内最大的并行消费能力------消费者数量超过分区数,多出来的消费者会空闲。这也是为什么 Kafka 的 Topic 在创建时就要规划好分区数,后续增加分区相对麻烦(且会打乱原有的 key→分区映射)。
小贴士
分区数是不是等于消费者数才最好? 不一定------更推荐分区数略多于当前消费者数:
| 关系 | 结果 |
|---|---|
| 分区数 = 消费者数 | 并行度刚好打满,没有闲置,但没有扩容空间 |
| 分区数 > 消费者数 | 仍能打满当前并行度,未来加机器时新消费者可以直接分走多余分区 |
| 分区数 < 消费者数 | 多出来的消费者闲置,浪费资源 |
因为分区数创建后很难修改(改了会打乱 key→分区的映射,破坏顺序性),所以一般按"未来可能扩到多少台机器"留出冗余,而不是卡死在"刚好相等"。
一个 Consumer 能同时消费不同的 Topic 吗? 可以。一个消费者实例可以订阅多个 Topic:
java
@KafkaListener(topics = {"order-events", "payment-events"}, groupId = "points-service")
public void handle(ConsumerRecord<String, Object> record) {
// 根据 record.topic() 判断是哪个 Topic 的消息,分别处理
}比如积分服务既要关心"订单创建",也要关心"支付成功",两种事件都会影响积分计算------一个消费者订阅两个 Topic 即可,不需要为每个 Topic 单独起一个消费者实例。
4.2 多个 Consumer Group:广播效果
Consumer Group 到底是什么
回到 8.3 节的代码,@KafkaListener(groupId = "points-service") 里的 groupId 就是 Consumer Group 的"名字"。Kafka 并不关心这个名字背后有几个实例、叫什么------它只记录一件事:这个 groupId 在每个分区上,消费到第几条(Offset)了 ,记在 __consumer_offsets 里(5.1节)。
所以本质上,Consumer Group = 一个独立的"消费进度" 。多个 Consumer 实例如果填了同一个 groupId ,Kafka 就认为它们是"一伙的",会把分区分给它们、共享同一份消费进度(4.1节的分配逻辑);如果填了不同的 groupId ,Kafka 就认为这是完全独立的另一拨消费者,会给它单独维护一份消费进度,从头开始读。
为什么需要这个设计
因为 Kafka 的消息消费后不会被删除 (7节提到,按 retention 保留一段时间)。这意味着同一条消息,理论上可以被读很多次------但"读到第几条了"这个进度,必须有人来记录,否则每次都不知道该从哪开始读。
groupId 就是用来回答"这是谁在读、读到哪了"------不同的下游服务(积分、短信、数据分析)各自起一个不同的 groupId,就能各自独立地、完整地消费同一份消息流,互不影响 。这正好呼应 30 消息队列 第1节讲的"解耦"------下游服务的数量、是否在线,生产者完全不用关心。
如果有多个不同的 Consumer Group 都订阅了同一个 Topic,每个 Group 最终都会读到完整的一份消息:
Topic "order-events"
├── Consumer Group "points-service" ← 自己的消费进度,最终会读完所有消息
├── Consumer Group "sms-service" ← 自己的消费进度,最终会读完所有消息
└── Consumer Group "analytics" ← 自己的消费进度,最终会读完所有消息不同的 Group 是"同时"收到消息的吗?
不是"同时",而是"各自独立、各按各的节奏" 。消息写入 Topic 后,一直躺在磁盘的日志文件里,谁来读、什么时候读,完全取决于每个 Group 自己的消费进度:
points-service处理很快,可能消息一来就立刻读到了analytics这个 Group 如果是"每小时批量跑一次",那它可能等一小时后才一次性读取这期间积累的所有消息- 两者读的是同一份数据 ,但读取的时间点完全不相关------这就是为什么说 Kafka 更像"数据管道":数据放在那,谁什么时候来取、取多快,是消费者自己的事,和生产者、和其他消费者都没关系
记忆方式 :组内是"竞争消费"(分区分配给组内成员,各消费各的一部分);组间是"各自独立的完整副本"(每个组都能读到全部消息,但读取时机互不相关,不是广播意义上的"同时推送")。
4.3 Rebalance(重平衡)
当 Consumer Group 内的消费者数量发生变化(比如新增一个实例、或者某个实例宕机),Kafka 会重新分配分区和消费者的对应关系,这个过程叫 Rebalance。Rebalance 期间该 Group 内的消费会短暂停止------这也是为什么 Kafka 消费者实例不建议频繁重启。
5. Offset:消费进度怎么记录
Offset 是消息在分区内的"序号"。Consumer 消费消息后,需要记录"我已经消费到第几条了",这样下次重启时才能从正确的位置继续,而不是从头消费一遍。
5.1 Offset 存在哪
Kafka 自己维护了一个特殊的内部 Topic,叫 __consumer_offsets,专门用来存储每个 Consumer Group 在每个 Partition 上消费到的 Offset。
记录的形式大致是 (groupId, partition) → offset,比如:
(groupId="points-service", partition=0) → offset=105
(groupId="points-service", partition=1) → offset=98
(groupId="points-service", partition=2) → offset=112关键点:每个分区只有一条进度记录,记录是和 groupId 绑定的,不是和某个具体的 Consumer 实例绑定。组内哪个实例当前负责这个分区,就由哪个实例去更新这条记录------如果发生 Rebalance(比如某个实例宕机,分区被重新分配给另一个实例),新实例会接着上次记录的 offset 继续读,不会重复也不会跳过(前提是之前正确提交了)。
不同的 groupId 则是完全独立的一套记录,互不影响------这也是为什么 4.2 节里不同的 Consumer Group 可以各自独立地、完整地消费同一个 Topic。
5.2 自动提交 vs 手动提交
| 方式 | 配置 | 风险 |
|---|---|---|
| 自动提交 | enable.auto.commit=true(默认),每隔一段时间自动提交当前已读取到的 Offset |
如果消息"读取到了"但还没处理完 就自动提交了 Offset,随后处理失败/进程宕机,重启后这条消息不会被重新消费------消息丢失 |
| 手动提交 | enable.auto.commit=false,业务处理完成后调用 consumer.commitSync() |
处理完才提交,更可靠;但如果提交之前处理完了又宕机,重启后会重复消费这条消息 |
这和 30 消息队列 第7节讲的"幂等性"是同一个问题------Kafka 默认提供的是"至少一次"语义,业务侧仍然需要处理重复消费。
6. 副本机制:数据可靠性
6.1 Leader 与 Follower
为了防止某台 Broker 宕机导致数据丢失,每个 Partition 会有多个副本(Replica),分布在不同的 Broker 上:
Partition 0:
Broker 1: Leader ← Producer/Consumer 只和 Leader 交互
Broker 2: Follower ← 被动从 Leader 同步数据
Broker 3: Follower ← 被动从 Leader 同步数据- 所有读写请求只打到 Leader
- Follower 持续从 Leader 拉取数据,保持同步
- 如果 Leader 所在的 Broker 宕机,Kafka 会从 Follower 中选出一个新的 Leader(前提是这个 Follower 数据是同步的)
旁注 :这种"一个 Leader 处理写入、Follower 同步数据、达到一定数量才算安全"的模式,和 ZooKeeper 的 ZAB 协议、Raft 是同一类思想。但这里的 Leader/Follower 同步是 Kafka 自己实现的,针对每个 Partition;ZooKeeper(老版本 Kafka 依赖它,2.8+ 的 KRaft 模式已替换)解决的是另一件事------集群元数据管理和"谁来决定每个 Partition 的 Leader 是谁"(即 Controller 选举)。两者思路相通,但层次不同。
6.2 ISR(In-Sync Replicas)
ISR 指的是"和 Leader 数据保持同步的副本集合"(包括 Leader 自己)。如果某个 Follower 因为网络问题、处理太慢,长时间落后于 Leader,会被踢出 ISR------这意味着它暂时不参与"选举新 Leader"和"判断消息是否写入成功"的过程,直到追上进度重新加入。
6.3 acks 参数:生产者的可靠性级别
Producer 发送消息时,acks 参数决定"Broker 返回成功响应"的时机,直接影响可靠性 vs 延迟的权衡:
acks 值 |
含义 | 可靠性 | 延迟 |
|---|---|---|---|
acks=0 |
Producer 发出去就不管了,不等任何确认 | 最低,可能丢消息 | 最低 |
acks=1(默认) |
只要 Leader 写入成功就返回确认 | 中等------如果 Leader 刚写完就挂了,还没同步给 Follower,消息丢失 | 中等 |
acks=all(或-1) |
等 ISR 中所有副本都写入成功才返回确认 | 最高------只要 ISR 中有一个副本存活,消息就不会丢 | 最高 |
配合 min.insync.replicas(ISR 最少要有几个副本)一起使用,acks=all + min.insync.replicas=2 是金融级场景常见的配置组合------即使丢了一台 Broker,数据依然安全。
一个更通用的视角
acks 这个参数,其实是分布式系统里一个通用权衡的具体体现 :副本数越多、要求确认的副本越多 → 数据越不容易丢(可靠性高),但要等更多机器写完才能返回(延迟越高)。这个权衡在很多地方都能看到同样的影子:
| 场景 | "多确认=可靠但慢" 的体现 |
|---|---|
Kafka acks |
acks=0最快但可能丢;acks=all最慢但最安全 |
| MySQL 主从复制 | 异步复制最快但主库宕机可能丢数据;半同步复制(至少1个从库确认)更安全但主库要等从库 ack |
| 分布式锁/选举(ZooKeeper/Raft) | 写入需要"过半节点确认"才算成功,本质也是用延迟换安全 |
| 微服务里的同步调用 vs 异步消息(28 微服务入门) | 同步调用能立刻知道结果但要等下游处理完;异步发消息快但"成功"只代表"消息发出去了" |
一句话 :分布式系统里几乎所有"可靠性保证",代价都是"多等一会儿"------acks=all 只是这个通用原则在 Kafka 里的一个具体参数化体现。
7. Kafka vs RabbitMQ:原理层面的对比
结合前面的原理,重新总结两者的核心差异:
| 维度 | RabbitMQ | Kafka |
|---|---|---|
| 底层模型 | Exchange 路由 + Queue(内存/磁盘结构相对复杂) | 分区日志文件(顺序写,结构极简) |
| 吞吐量 | 万级/秒 | 百万级/秒 |
| 消息有序性 | 单个 Queue 内有序 | 单个 Partition 内有序 |
| 消息消费后 | 默认被删除(ACK后) | 不会删除,按配置的保留时间/大小保留,多个消费者组可重复消费同一份数据 |
| 消费方式 | Broker 主动推送给 Consumer | Consumer 主动拉取(pull),自己控制消费速度 |
| 路由灵活性 | 高(Direct/Topic/Fanout 多种 Exchange) | 低(基本就是按 key 分区) |
| 典型场景 | 业务系统间解耦、任务队列 | 日志采集、埋点数据、流处理、大数据管道 |
一个常被忽略但很重要的区别 :RabbitMQ 的消息一旦被消费确认,就从 Queue 里删除了;Kafka 的消息消费后依然保留在磁盘上 (根据 retention 配置,比如保留7天)。这意味着 Kafka 里同一条消息可以被多个不同的消费者组在不同时间重复读取------这也是为什么 Kafka 常被用作"数据管道":上游写一次,下游各个系统按自己的节奏各读各的。
8. Spring Boot 基本使用
8.1 依赖
xml
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka</artifactId>
</dependency>8.2 生产者
java
@Service
@RequiredArgsConstructor
public class OrderEventProducer {
private final KafkaTemplate<String, Order> kafkaTemplate;
public void sendOrderCreated(Order order) {
// 第一个参数是 Topic,第二个参数是 key(决定分区),第三个是消息内容
kafkaTemplate.send("order-events", String.valueOf(order.getId()), order);
}
}key 传的是 order.getId()------保证同一个订单的多条消息(创建、支付、发货)会进入同一个分区,分区内有序。
8.3 消费者
java
@Component
public class OrderEventConsumer {
@KafkaListener(topics = "order-events", groupId = "points-service")
public void handle(Order order) {
System.out.println("收到订单事件,处理积分逻辑:" + order.getId());
}
}groupId = "points-service" 就是 Consumer Group 的名字------如果另一个服务(比如短信服务)也订阅这个 Topic,但用了不同的 groupId(如 "sms-service"),两个服务会各自收到完整的消息流,互不影响(对应第4.2节"组间广播")。
8.4 配置
yaml
spring:
kafka:
bootstrap-servers: localhost:9092
producer:
acks: all # 对应第6.3节
consumer:
group-id: points-service
auto-offset-reset: earliest # 该 group 第一次消费时,从最早的消息开始读
enable-auto-commit: false # 对应第5.2节,手动提交更可靠9. 小结
| 主题 | 核心要点 |
|---|---|
| 核心模型 | Kafka = 分布式的、可持久化的日志文件;Topic 是逻辑名字,Partition 是真正存数据的单位 |
| 高吞吐原因 | 顺序写磁盘 + 页缓存/零拷贝 + 批量发送压缩 |
| 顺序性 | 分区内严格有序,分区间不保证;用 key 让同一业务实体的消息进同一分区 |
| Consumer Group | 组内竞争消费(一个分区只给一个消费者),组间广播(每个组拿到完整数据) |
| 分区数的意义 | 决定一个 Group 内的最大并行度,消费者数 > 分区数时会有消费者闲置 |
| Offset | 记录消费进度,存在 __consumer_offsets;自动提交可能丢消息,手动提交可能重复消费 |
| 副本与可靠性 | Leader/Follower + ISR;acks=0/1/all 决定生产者侧的可靠性与延迟权衡 |
| vs RabbitMQ | Kafka吞吐量更高、消费后消息不删除、可被多组重复消费;RabbitMQ路由更灵活、消费后即删除 |
面试高频组合 :Kafka 和 RabbitMQ 的区别、Partition 与顺序性、Consumer Group 的分配关系、acks 参数的权衡------这几个点把"原理"讲透了,基本就能应对大部分关于 Kafka 的提问。具体的运维(如何扩分区、如何调优页缓存)属于"用到时再查"的范畴,新人不必现在深究。
🎯 如果这篇文章对你有帮助,别忘了点赞、收藏、关注三连!关注我,让你在 Java 学习的道路上不迷路,持续为你带来成体系的 Java 干货~