在政企、能源、工业等视觉AI项目全面走向信创与国产化的当下,很多架构师和算法工程师在面对"国产化替代"时,最头疼的就是硬软件选型与算力估算。以前依赖通用GPU和现成生态(如CUDA),代码直接跑,算力闭眼选。而换到国产NPU视觉算法生态后,芯片特性、算力单位、模型转换路径全部换代,选型一旦失误,项目极易卡在"解码卡死"或"延迟爆表"的边缘。
作为一名长期在一线摸爬滚打的边缘计算与AI视频分析部署顾问,今天我们就来一次性盘透:面对瑞芯微 、算能 、昇腾适配等主流国产化路径,如何做到精准选型与科学的算力估算。
一、 选型结论先行:别盲目跟风,看场景下药
在项目初期,不需要急着去算多少个TOPS(每秒万亿次操作),先看你的业务形态属于以下哪一种,直接对号入座:
-
边缘计算盒子(嵌入式NPU): 如果项目属于高分布式、单点路数少(如1-16路)、网络带宽受限、要求本地闭环的场景(例如:智慧加油站、施工现场安全帽检测、智慧零售门店),直接选边缘盒子。这类场景数据不出场、单点综合成本极低,且能实现低延迟的"本地存活"。
-
通用GPU服务器: 如果你的项目属于纯后方中心化大并发、处于模型频繁迭代的研发期、或者需要运行超大参数量模型(如多模态、大模型VLM),且没有严格的硬性国产化合规指标,优先选择通用GPU服务器。
-
国产NPU服务器/高密边缘阵列: 如果项目明确要求100%国产化信创合规,且属于中大型集中式解析场景(如智慧城市、大厂园区千路视频汇聚) ,应当选择基于昇腾 (如Atlas 800系列)或算能(如微服务器阵列)的国产算力服务器。它们在底层算力密度和高并发视频流处理上,是目前替代传统GPU的最优解。
二、 影响国产NPU算力的7大核心变量
在国产NPU视觉算法的实际落地中,算力绝对不是一个静态的"硬件数字",而是由业务层多个动态变量共同决定的。
下面这张参数配置表,梳理了决定系统成败的7大核心变量,并给出了推荐配置方向与调优建议:
核心参数配置与调优指南
| 核心变量 | 参数含义 | 推荐值/推荐策略 | 错误示例 | 调优建议(避坑绝招) |
|---|---|---|---|---|
| 路数 (Channels) | 硬件同时接入并解析的摄像头视频流总数。 | 根据芯片规格划分等级。如单片RK3588推荐4-8路复杂算法;算能/昇腾单卡推荐16-32路。 | 盲目堆砌路数。在一台4路标称的盒子上强行接入16路,导致系统OOM(内存溢出)奔溃。 | 路数决定了硬件的基础编解码压力(VDEC),选型时编解码芯片能力要留出20%以上的余量。 |
| 分辨率 (Resolution) | 输入视频流的像素尺寸,直接决定模型前处理的数据输入量。 | 推荐维持在 1080P (1920×1080)。非特殊场景(如超远距离人脸/车牌识别),切勿盲目上4K。 | 全路数采用4K画质推流,导致NPU前处理(Resize、BGR转换)耗尽了CPU与内存带宽。 | 如果摄像头是4K,可在前端摄像头配置副码流(1080P/720P)输出给算法,主码流仅用于存储。 |
| 帧率 (Framerate) | 视频每秒传输的图像张数(FPS)。 | 边缘检测业务推荐 10-15 FPS 。工业质检或极速抓拍推荐 25-60 FPS。 | 认为必须25帧全帧率推理。这会导致算力出现2-3倍的无意义浪费。 | 绝大部分安防与行为分析(如抽烟、摔倒、反光衣),10 FPS的动作连续性已经完全足够。 |
| 算法复杂度 | 模型本身的参数量和计算量(如FLOPs),以及网络的骨干结构(如YOLOv5 vs YOLOv10)。 | 选择经过低比特量化(INT8/INT16)优化的轻量化目标检测与追踪网络。 | 直接将服务器端的FP32高精度大模型不加裁剪地转成NPU模型的.rknn或.bmodel。 |
利用国产芯片配套工具链进行剪枝与INT8感知量化训练(QAT),通常可以在保持98%以上精度的情况下,提升3-5倍速度。 |
| 抽帧策略 | 跳过无用帧的图像过滤机制(如等间隔抽帧、关键帧解码、动态运动检测抽帧)。 | 推荐等间隔抽帧(如隔2帧抽1帧)或基于运动向量(Motion Vector)的关键帧解码。 | 每一帧都送入NPU进行推理,即便画面连续几小时没有任何物体移动。 | 在软件层引入轻量级背景差分法。画面无人员/车辆变动时,NPU转入休眠/低频探测模式,有异动再触发全频推理。 |
| 多算法叠加 | 单路视频流上同时运行的算法数量(如同时测安全帽+抽烟+区域入侵)。 | 单路流并发算法不推荐超过3种;若要多算法叠加,建议采用**"1个通用检测主模型 + N个分类子模型"**的级联架构。 | 对同一路流,串行或者并起来跑5个完全独立的YOLO模型。 | 采用多任务网络(Multi-task Learning)或者级联架构。检测到人之后,再裁剪ROI区域送入"抽烟/电话"轻量分类器,避免重复全图特征提取。 |
| 告警实时性 | 产生违规行为到系统报出数据的时间差要求。 | 消防/明火/高空抛物:秒级(≤1−2s)。人员聚集/离岗:分钟级。 | 认为所有算法都必须毫秒级响应。为了追求0.1秒的响应,盲目拉高整体算力预算。 | 合理设置业务缓冲队列。利用平均响应时间代替绝对实时,通过异步队列平摊偶发的计算峰值。 |
三、 科学的算力和硬件估算方法
不要相信任何"1路视频 = 1 TOPS"的民科公式。在瑞芯微 、算能 、昇腾适配的实际项目工程中,我们需要通过"业务变量清单"进行分步拆解。
算力评估三步走流程
步骤 1:梳理基础业务吞吐量
首先列出你的项目底层物理指标:
总处理像素吞吐量=路数×输入分辨率像素×实际推理帧率(抽帧后)
例如:16路、1080P、经抽帧后实际每路每秒只推理10帧。
吞吐量=16×(1920×1080)×10≈3.31×108 像素/秒
步骤 2:对标模型单帧开销
查阅你在芯片工具链(如RKNN-Toolkit、SOPHON SDK、MindStudio)中将模型成功转换后的基准性能报告。看看在特定芯片上,单张输入尺寸(如 640×640)的模型单次前向传播(Forward Pass)实际消耗的时间(毫秒)。 假设该轻量模型在目标NPU单核上的INT8推理耗时为 15ms,这意味着单核每秒理论最大吞吐为 151000≈66帧。
步骤 3:综合解算与冗余校准
计算所需的处理核心数或芯片数:
理论所需帧率=16路×10帧/路/秒=160帧/秒
理论核心数=160帧/66帧/核≈2.42核
💡 关键修正(顾问经验谈): 实际部署中,你必须为**视频硬解码(VDEC)、图像前处理(Resize/Format Convert)、多目标追踪算法(BYTETracker等CPU消耗大户)**留出至少 30% - 40% 的算力与内存带宽余量。 因此,上述2.42核的理论值,实际落地推荐选择具备 4核NPU 的硬件节点(如两颗双核芯片,或单台性能富余的边缘盒子)。
下面的推理流水线图,展示了视频流从输入到最终输出的完整生命周期。可以看出,NPU模型推理(your model runs here)只是整个链路的一部分,前期的视频流多路复用(Multiplexer)与解码缓存同样是消耗硬件资源的关键一环:
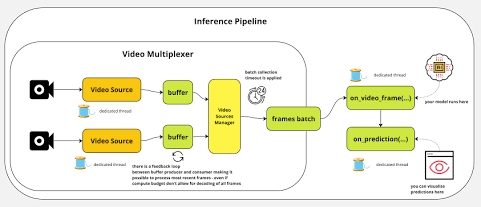
典型的视觉AI推理流水线(Inference Pipeline)架构图. 来源:Roboflow Inference
四、 边缘盒子 vs GPU服务器 vs 国产NPU 选型对比
为了方便给业主或技术总监做汇报,可以直接参考以下维度的综合对比表:
| 对比维度 | 边缘计算盒子 (嵌入式) | 通用GPU服务器 (如x86+xDA) | 国产NPU服务器/盒子 (瑞芯微/算能/昇腾) |
|---|---|---|---|
| 部署位置 | 靠近摄像头的边缘侧、弱电箱、现场机房 | 园区中心机房、云端数据中心 | 中心机房、各级信创边缘机房/节点 |
| 初期成本 | 极低。单点硬件成本几千元,无机房配套要求。 | 高。单台服务器数万至数十万元起。 | 中等至高。初期有工具链适配改造成本,但硬件性价比正在快速追平。 |
| 并发能力 | 单机并发低(通常1-32路)。 | 极高(单机可承载上百路复杂算法)。 | 灵活。既有4-8路的低功耗边缘端,也有支持高密插卡的百路级服务器。 |
| 维护难度 | 节点分散,依赖设备云管平台进行远程固件与算法更新。 | 集中维护,运维技术成熟,配套工具完善。 | 视部署形态而定。目前主流厂商均已提供完善的K8s/容器化纳管方案。 |
| 扩展性 | 水平扩展方便,增加区域只需"加盒子"。 | 垂直扩展强,可直接插卡,但受限于机房功耗和空间。 | 兼具两者优势。既支持边缘集群横向扩展,也支持中心侧算力扩容。 |
| 数据安全性 | 极高。原始视频流不出场,本地解析,仅上传结构化告警文本。 | 存在带宽压力。所有视频需跨网段汇聚,敏感数据传输风险高。 | 极高。符合国家信创安全合规要求,从底层芯片到软件全栈自主可控。 |
五、 规范化项目选型落地流程
视觉分析项目的落地是一个系统工程,千万不要一上来就买硬件。请严格遵循以下工程路径:
[1. 需求确认] ──> [2. 视频源盘点] ──> [3. 算法清单理清] ──> [4. 测试验证与量化] ──> [5. 试点上线]-
需求确认: 明确是要"0.1秒见火就报",还是"一小时统计一次区域人数"。实时性期望直接决定了你的抽帧策略和算力底线。
-
视频源盘点: 现场调研摄像头的真实分辨率、编码格式(H.264还是H.265)、网络丢包率。国产NPU最怕不规范的RTSP流导致的解码花屏。
-
算法清单理清: 盘点单路流上到底要重叠多少算法。是否有长周期算法(如安全帽检测)与短周期算法(如人脸识别)的动静结合?
-
测试验证与量化: 利用芯片厂家的仿真工具(如昇腾仿真器、瑞芯微RKNN simulator),将模型转为INT8后跑一下Benchmark,拿到真实耗时与精度衰减数据。
-
试点上线: 选取3-5路典型环境流进行为期1-2周的恶劣环境测试(如夜间低照度、雨雪天气),观察误报率及硬件散热稳定性。
六、 避开这4个高频踩雷误区
在顾问咨询中,我发现80%的项目延期或硬件重购,都是因为踩了以下几个雷:
-
❌ 误区一:只看标称TOPS,以为数字大就稳了。 各个厂家的TOPS定义不同(有的指INT8,有的指FP16)。更重要的是,NPU利用率(Utilization)才是关键。如果算力调度写得差,或者模型中有NPU不支持的自定义算子(如某些特殊的Activation层),计算会频繁退化到CPU上执行,导致性能断崖式下跌。
-
❌ 误区二:只盯着显卡/GPU型号看,忽略了视频解码芯片(VDEC)。 视觉AI的第一步是"解码"。很多国产芯片标称AI算力惊人,但硬解码能力(VDEC)有限。如果你的算法运行很快,但解码芯片卡死在多路H.265 1080P的图像并发解码上,NPU就会一直"嗷嗷待哺",整体吞吐量根本上不去。
-
❌ 误区三:忽略了边缘环境的散热与恶劣工况。 工业现场、配电房或室外弱电箱在夏天的温度可能高达 50∘C−60∘C。如果选型时用了普通的家用/商用级无风扇盒子,硬件很快会因为触发过热保护而自动降频,标称 6 TOPS 瞬间缩水成 2 TOPS,引发严重的丢帧和告警延迟。
-
❌ 误区四:忽略了网络抖动对流媒体的影响。 网络一旦出现连续丢包,解码器就会收到大量网络坏包,导致解码出来的图片在内存中呈现"花屏"或"绿屏"。算法对这类坏图进行推理,会产生极其严重的误报。软件架构上必须设计完备的断线重连与坏帧剔除机制。
结语与技术支持
国产化替代不是简单的"换个硬件买单",而是一场从底层模型编译到上层流媒体工程的协同优化。在进行瑞芯微 、算能 或昇腾适配时,吃透算法参数含义、选择合理的抽帧策略,往往能帮你省下超过 50% 的不必要硬件预算。
如果你正在负责相关的国产化AI视觉项目交付,在模型转换、算力低比特量化(INT8/INT16)或者多路流工程架构上遇到跨不过去的坎,欢迎访问壹合原码官网获取部署支持,向我们的专业顾问团队获取一对一的技术攻坚与定制化落地硬件方案。