AgentBound 深度解析:AI Agent 不只要"有权限",还要有可验证的行为治理
TL;DR
- 场景:AI Agent 已经走出聊天框,开始代替用户在企业系统里执行退款、发布、邮件、资金转账、CRM 操作等高风险动作;传统 OAuth/IAM/RBAC 只能回答"能不能访问",回答不了"这次该不该执行"。
- 结论:AgentBound(arXiv 2026-06-29,eBay Inc. + 独立研究者)提出在"授权之后、执行之前"插一道确定性运行时治理层,把 Agent 动作抽象成 canonical action,由委托授权 + owner 签名行为宪法 + 站点动作契约三类权威做保守合成,输出 Permit / Review / Deny,并附带可密码学验证的 governance receipt。
- 产出:一份围绕"高风险动作该不该发生"的行为治理框架------canonical action 抽象、三权威保守合成、governance receipt、standing delegation + 短期 task token、AgentBound-Bench 评估指标,以及七个低配版落地步骤。
关键词:AgentBound、行为治理、canonical action、governance receipt、standing delegation、AgentBound-Bench、AI Agent 安全、OWASP ASI 2026、可审计授权、review 状态、保守合成、运行时宪法、站点动作契约、可验证执行凭证、企业级 Agent 架构、policy as code、eBay Agent 安全、2026 AI Agent 治理、constitutional AI 运行时化、Zanzibar、Cedar、OPA、Microsoft Agent Governance Toolkit、permission ≠ execution。
版本矩阵
| 功能 / 概念 | 状态 | 说明 |
|---|---|---|
| AgentBound 论文提交(2026-06-29) | ⚠️ 待验证 | 用户提供的元数据;联网未命中独立 arXiv 摘要页,标注待核 |
| canonical action(统一动作语义) | ✅ 已验证 | 工程上对应的就是 typed tool call + risk metadata,已被 Microsoft Agent Governance Toolkit、AWS Bedrock AgentCore 等采用 |
| 委托授权层(OAuth / IAM / RBAC / ABAC) | ✅ 已验证 | Google Zanzibar、AWS Cedar、OPA 是工业界主流实现 |
| owner 签名行为宪法(runtime behavioral constitution) | ✅ 已验证 | 区别于 Anthropic 训练阶段的 Constitutional AI,是运行时签名规则 + policy as code;已落地于 OPA Rego / Cedar policy |
| 站点动作契约(site action contract) | ✅ 已验证 | 对应工具元数据(可逆性、副作用、资金影响、外部消息),被 OpenAPI + x- 扩展与 Agent Governance Toolkit 采用 |
| Permit / Review / Deny 三态治理 | ✅ 已验证 | 在 Microsoft Agent Governance Toolkit v3.1.0 中明确引入 agt verify 与人工复核流程 |
| 保守合成(最严格判断支配) | ✅ 已验证 | 类似 fail-secure / deny-by-default 设计,Cedar、OPA 默认拒绝模式同思路 |
| governance receipt(可验证执行凭证) | ✅ 已验证 | 实现路径包括 append-only 数据库 + 哈希链 + 签名字段,OWASP ASI08(软件及资料完整性失效)要求可追溯证据 |
| standing delegation + 短期 task token | ✅ 已验证 | OAuth 2.0 Token Exchange + DPoP + SPIFFE/SPIRE 工作负载身份已能支撑类似分层 |
| AgentBound-Bench | ⚠️ 待验证 | 论文提出的基准,公开搜索未命中独立结果页,标注待核 |
| OWASP Top 10 for Agentic Applications 2026(ASI 前缀) | ✅ 已验证 | 2025-12 正式发布,2026-02 被修订确认 ASI 前缀 |
| Microsoft Agent Governance Toolkit | ✅ 已验证 | github.com/microsoft/agent-governance-toolkit,v3.1.0 已发布(2026-04),最后一次 commit 2026-06-06 |
| Zanzibar / SpiceDB / Cedar / OPA / Permify | ✅ 已验证 | 全部为真实开源工业级授权服务 |
| Anthropic Constitutional AI(区分) | ✅ 已验证 | 训练阶段方法;AgentBound 行为宪法是运行时版本,两者层级不同 |
一句话概括:
text
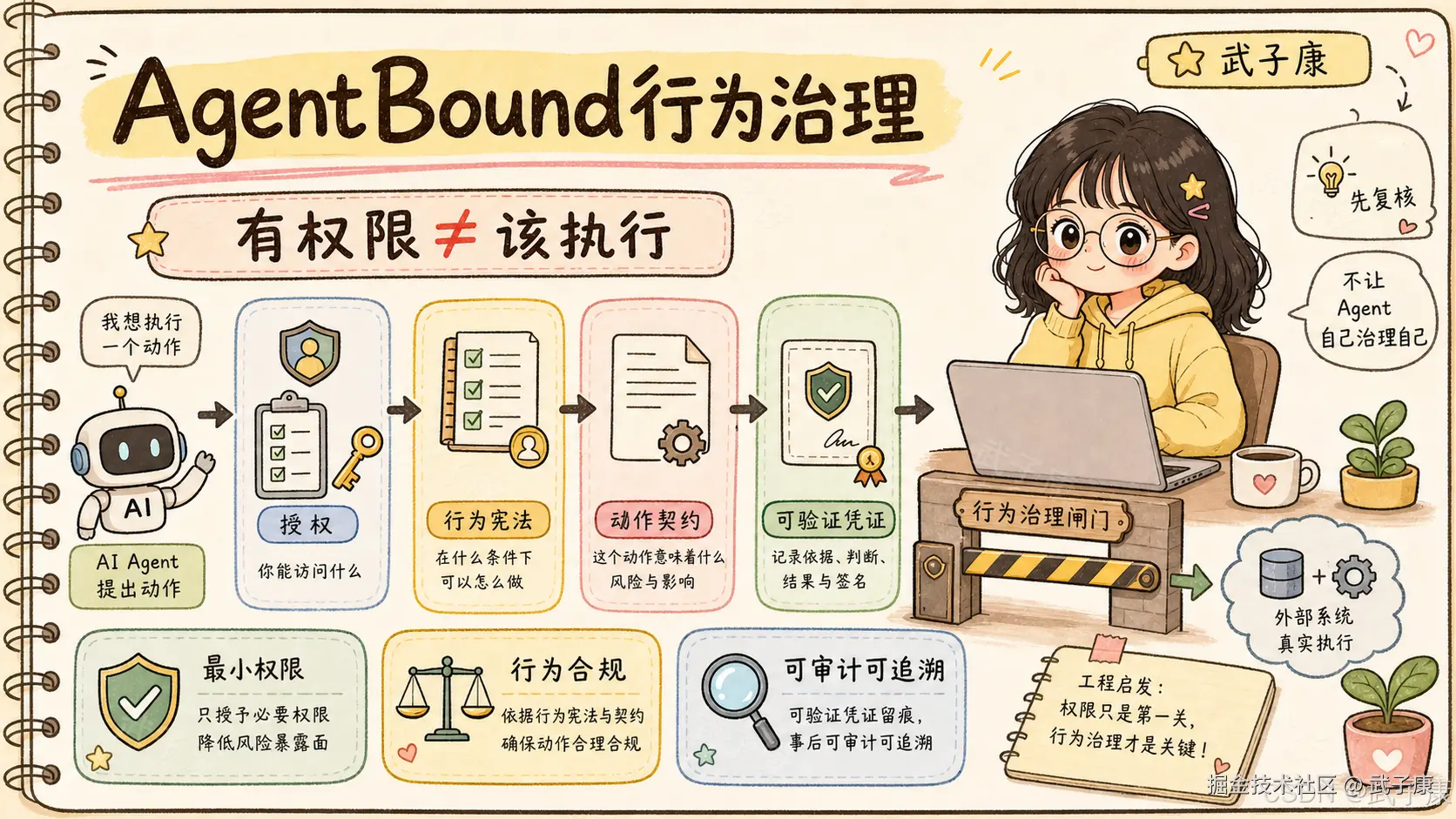
身份认证回答"你是谁",授权系统回答"你能访问什么",AgentBound 试图回答"这次动作到底该不该发生"。1. 问题变了:Agent 在权限范围内也会做错事
传统系统安全通常从两个问题开始。
第一个问题是认证:调用者是谁?比如服务账号、JWT、SPIFFE/SPIRE、工作负载身份。
第二个问题是授权:它能访问什么?比如 OAuth scope、IAM policy、RBAC、ABAC、OPA、Cedar、Zanzibar 类权限系统。
这些能力很重要,但 AI Agent 进入执行型软件之后,风险不再只来自"越权访问"。一个更棘手的问题是:Agent 完全在授权范围内行动,却违反了用户真实意图、组织流程或现场上下文。
比如一个客服 Agent 有退款 API 权限,金额也没有超过 token 允许的上限。传统授权系统可能会放行。但如果用户的行为规则要求"超过 200 美元必须经理复核",或者站点动作契约标记"退款不可逆且会触发财务出账",那么这次动作就不应该直接执行。
再比如一个内容运营 Agent 有发布权限,但它准备发布的内容包含未经审核的客户信息。权限系统只能回答"它能不能发布",很难回答"这篇内容在当前上下文里是否符合发布边界"。
这就是论文所说的 behavioral governance failure:行为治理失败。
它不是身份系统失败,也不是授权系统失败,而是访问控制和真实行为约束之间出现了空白。
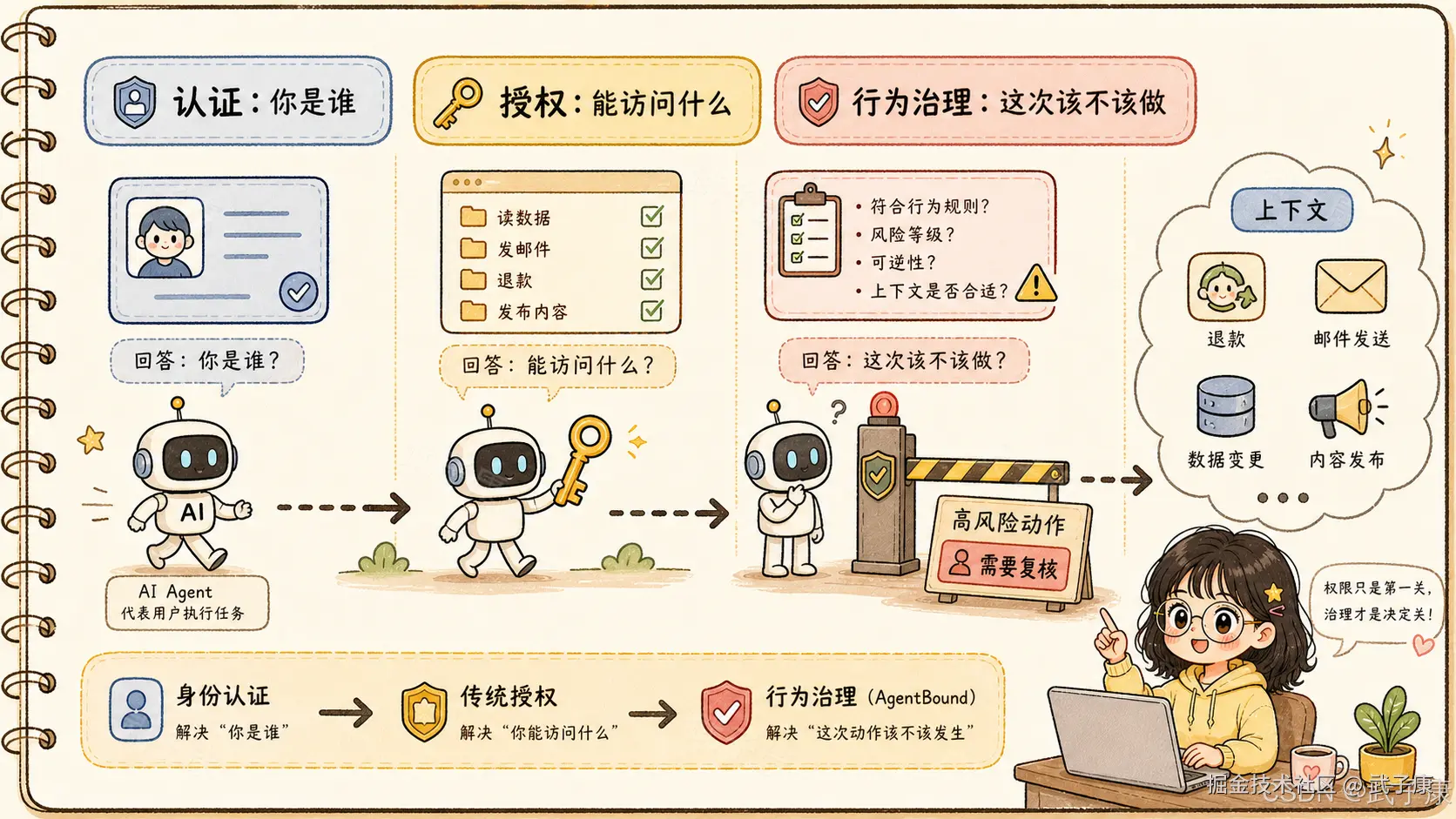
2. AgentBound 的位置:授权之后,执行之前
AgentBound 的定位很工程化。
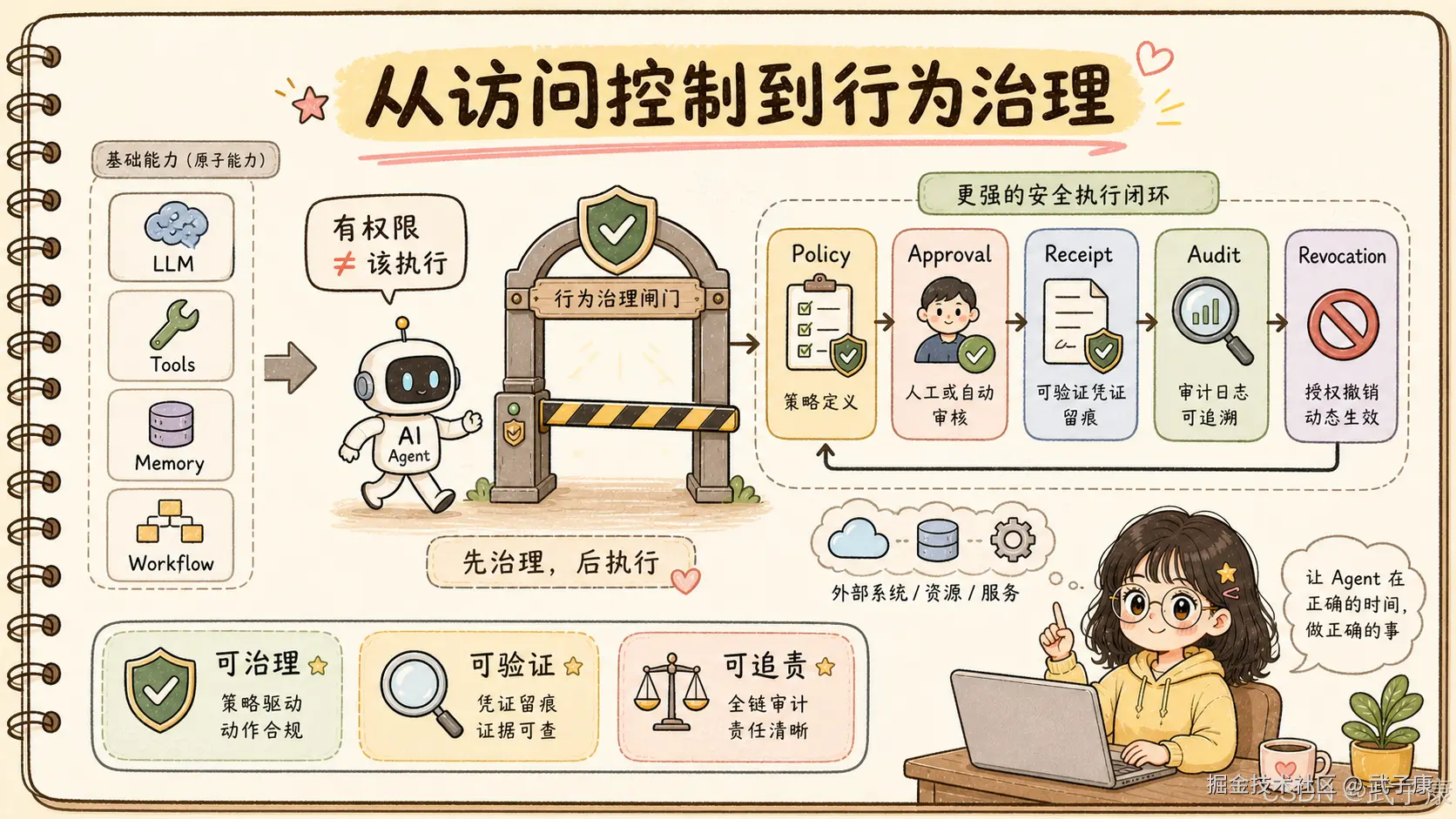
它不试图替代模型对齐,也不假设 LLM 会自己治理自己。论文明确把 Agent Runtime 视为不可信组件:Agent 可以规划,可以提出动作,但不能自己决定高风险动作是否合规。
所以 AgentBound 被放在执行边界上:
text
Agent 生成动作
-> 身份认证
-> 结构性授权
-> AgentBound 行为治理
-> 外部系统真正执行这个位置很关键。
如果治理发生在模型生成阶段,就容易被 prompt injection、上下文污染、模型误判影响。如果治理只发生在事后日志阶段,就已经太晚了。AgentBound 的思路是让所有 consequential action 在出门之前经过一个不可绕过的、确定性的治理服务。
它的输出也不是简单的 allow / deny,而是三种状态:
text
Permit:允许执行
Review:需要人工复核或额外流程
Deny:拒绝执行现实系统里 Review 非常重要。很多动作不是绝对不能做,而是需要审批、确认、脱敏、延迟执行或选择可回滚方案。
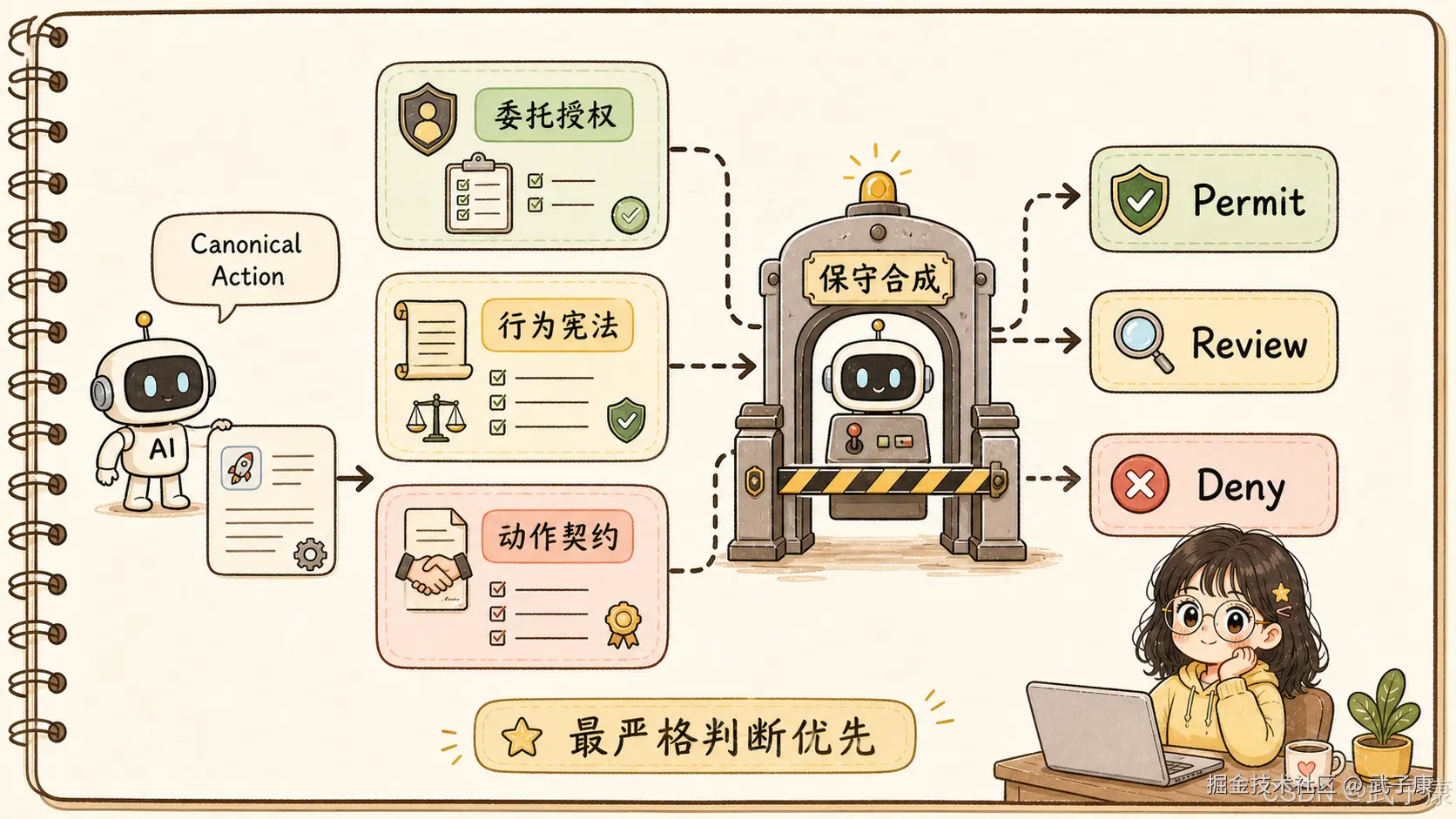
3. 三套权威:授权、行为宪法、站点动作契约
AgentBound 的判断来自三类独立权威。
第一类是 delegated authorization,委托授权。
它回答传统权限问题:Agent 是否有结构性权限?token 是否有效?scope 是否覆盖?资源边界是否匹配?金额上限是否允许?
第二类是 owner-signed behavioral constitution,由所有者签名的行为宪法。
这个概念很有意思。它不是训练阶段的 Constitutional AI,而是运行时的、由用户或组织定义并签名的行为规则。比如:
text
金额超过 500 美元必须人工确认。
外发邮件涉及客户隐私时必须脱敏。
公开发布内容必须经过审核。
低置信度推断不能触发不可逆操作。
晚上 8 点后不得自动执行资金转移。这些规则不是"能不能访问某个 API",而是"在什么条件下可以怎样行动"。
第三类是 site action contract,站点动作契约。
它描述目标系统中某个动作的真实含义。比如这个 API 是只读还是写入?是否可逆?是否公开可见?是否会触发财务影响?是否会向外部发送消息?风险等级是什么?
如果把 Agent 的动作看成一次调用,那么 action contract 就是对这个调用后果的语义标注。没有它,治理层很难知道一个普通函数名背后到底意味着什么。
4. Canonical Action:先把动作翻译成统一格式
AgentBound 不直接处理各种工具调用的原始格式,而是把它们抽象成 canonical action。
一个 canonical action 至少要描述:
text
operation:要做什么
resource:作用在哪个资源上
parameters:关键参数是什么
risk:风险等级和风险属性
context:当前上下文举例来说,客服 Agent 准备退款时,治理层不应该只看到:
json
{
"tool": "refund",
"amount": 300
}它应该看到更完整的动作语义:
json
{
"operation": "issue_refund",
"resource": "order_123",
"parameters": {
"amount": 300,
"currency": "USD",
"customer_id": "cust_a"
},
"risk": {
"financial": true,
"irreversible": true,
"external_effect": true
},
"context": {
"confidence": 0.74,
"complaint_type": "delivery_delay",
"manager_online": true
}
}这个统一动作会被送给不同权威判断。每个权威返回 judgment,包括 verdict、constraints、obligations、provenance。
用简单话说,Agent 先提出"我要做什么",AgentBound 再把它变成可治理、可审计、可复验的动作对象。
5. 保守合成:不是投票,而是最严格判断支配结果
AgentBound 最值得工程团队借鉴的一点,是它没有把多个权威的判断做平均投票。
它采用保守合成原则:最严格的判断支配最终结果。
如果授权系统允许,但行为宪法要求人工复核,最终就是 Review。
如果授权系统允许,行为宪法允许,但站点动作契约认为这是高风险不可逆动作,最终可以是 Deny。
如果某一个权威拒绝,其他权威不能把它"投票救回来"。
可以把它理解为:
text
Deny 优先级最高。
Review 不能被 Permit 覆盖。
Permit 只有在所有必要权威都不反对时才成立。约束取交集,义务会累积,溯源必须保留。这样的设计有一个重要好处:任何治理权威都不能扩大其他权威定义的边界。
这和很多业务系统里的"权限通过就执行"完全不同。AgentBound 的逻辑是:权限只是第一关,它只能证明你可以碰这个资源,不能证明你现在应该这么做。
6. Governance Receipt:不是日志,而是可验证证据
AgentBound 另一个关键设计是 governance receipt,治理凭证。
普通日志记录的是:
text
Agent 在某个时间做了某件事。好一点的日志会记录:
text
系统当时允许了这件事。但对企业级 Agent 来说,这还不够。因为真正追责时,审计者会继续问:
text
当时用的是哪一版行为规则?
哪个 token 或 delegation 生效?
站点动作契约是哪一版?
每个权威分别给了什么判断?
为什么最终是 Permit、Review 或 Deny?
这些证据有没有被篡改?
第三方能不能独立复算?AgentBound receipt 试图把这些问题一次性绑定起来。
论文中 receipt 可以理解为:
text
Receipt = Action + Governance + Judgments + Outcome + Signatures它会记录标准动作、授权引用、行为宪法版本和哈希、站点动作契约版本、各个权威的判断、最终结果,以及签名信息。凭证由 Agent 先签名,再由 AgentBound 服务反签名,最终写入 append-only、tamper-evident 的审计账本。
这和普通 observability 的区别很大。
Tracing 记录"发生了什么"。Governance receipt 记录"为什么当时系统认为它可以发生",并且允许独立复验。
这也是 AgentBound 论文里反复强调的变化:治理过程不只是被信任,而是可以被验证。
7. Standing Delegation:长期 Agent 不能拿一个大 token 裸跑
AgentBound 还处理了一个很现实的问题:长期运行 Agent。
很多 Agent 不是用户点一下才运行,而是周期性、异步、长时间工作。例如:
text
每天检查邮件并回复。
每小时监控库存并补货。
每周生成财务报告。
定期扫描客服工单并自动退款。这类 Agent 不可能每次都要求用户在线授权。但如果给它一个长期大权限 token,又会引入巨大风险。策略更新怎么办?用户撤销怎么办?token 泄露怎么办?上下文风险变化怎么办?
AgentBound 提出的方案是 standing delegation,长期委托,但不直接等于长期执行权。
它把授权拆成两层。
第一层是长期 standing delegation,表示用户确实允许这个 Agent 在最大范围内长期工作。它包含 Agent 身份、最大权限范围、执行周期、过期时间和 owner 签名。
第二层是每次执行前生成的短期 task delegation。每个周期开始时,系统刷新当前行为宪法,生成短生命周期的任务 token,并把当时最新策略哈希写进去。
这样长期 Agent 可以异步运行,但每次执行都受到最新策略约束。用户更新规则,不需要重新部署 Agent。用户撤销 standing delegation,后续任务 token 就无法继续生成。短期 token 泄露,暴露窗口也有限。
8. AgentBound-Bench:评估治理层,而不是评估 Agent 会不会做题
论文还提出了 AgentBound-Bench。
它不是评估 Agent 能不能完成任务,而是评估治理层能不能正确拦截、解释和验证动作。
输入包括:
text
canonical action payload
结构性授权上下文
签名行为宪法版本
远程站点动作契约指标包括:
text
治理判断准确率
违规逃逸率
receipt 验证成功率
治理延迟开销其中最关键的是 violation escape rate,也就是违规动作绕过治理并实际执行的比例。
不过要注意,当前论文更像系统架构与形式化治理框架,完整的大规模实证结果并不是它最强的部分。写工程方案时,不能把它包装成已经完成大规模工业验证的标准答案。
9. 它不是什么:不要把 AgentBound 神化
AgentBound 不是模型对齐。
模型对齐试图让模型在生成计划、理解指令、权衡风险时更可靠。AgentBound 不改变模型内部推理,只看模型提出的动作,并在动作出门前做治理判断。
AgentBound 不是 prompt injection 防御。
论文明确把 prompt injection、jailbreak、底层模型对齐失败、硬件侧信道泄漏列为范围外。它可以拦住某些被注入诱导出来的危险动作,但它不负责阻止注入本身。
AgentBound 不是普通权限系统。
权限系统判断有没有权访问。AgentBound 进一步判断这次访问在当前上下文中是否应该发生。
AgentBound 也不是普通日志系统。
日志通常记录结果。AgentBound receipt 记录策略版本、判断过程、签名链和可重放证据。
更准确的定位是:
text
AgentBound 是 Agent 执行边界上的确定性行为治理层。10. 工程落地:不一定一上来就做完整密码学 receipt
如果你正在做企业 Agent、自动化客服、财务流程、邮件系统、CRM、运维机器人、内容发布 Agent,AgentBound 的方向很值得参考。但落地时不一定一开始就把论文里的所有组件做满。
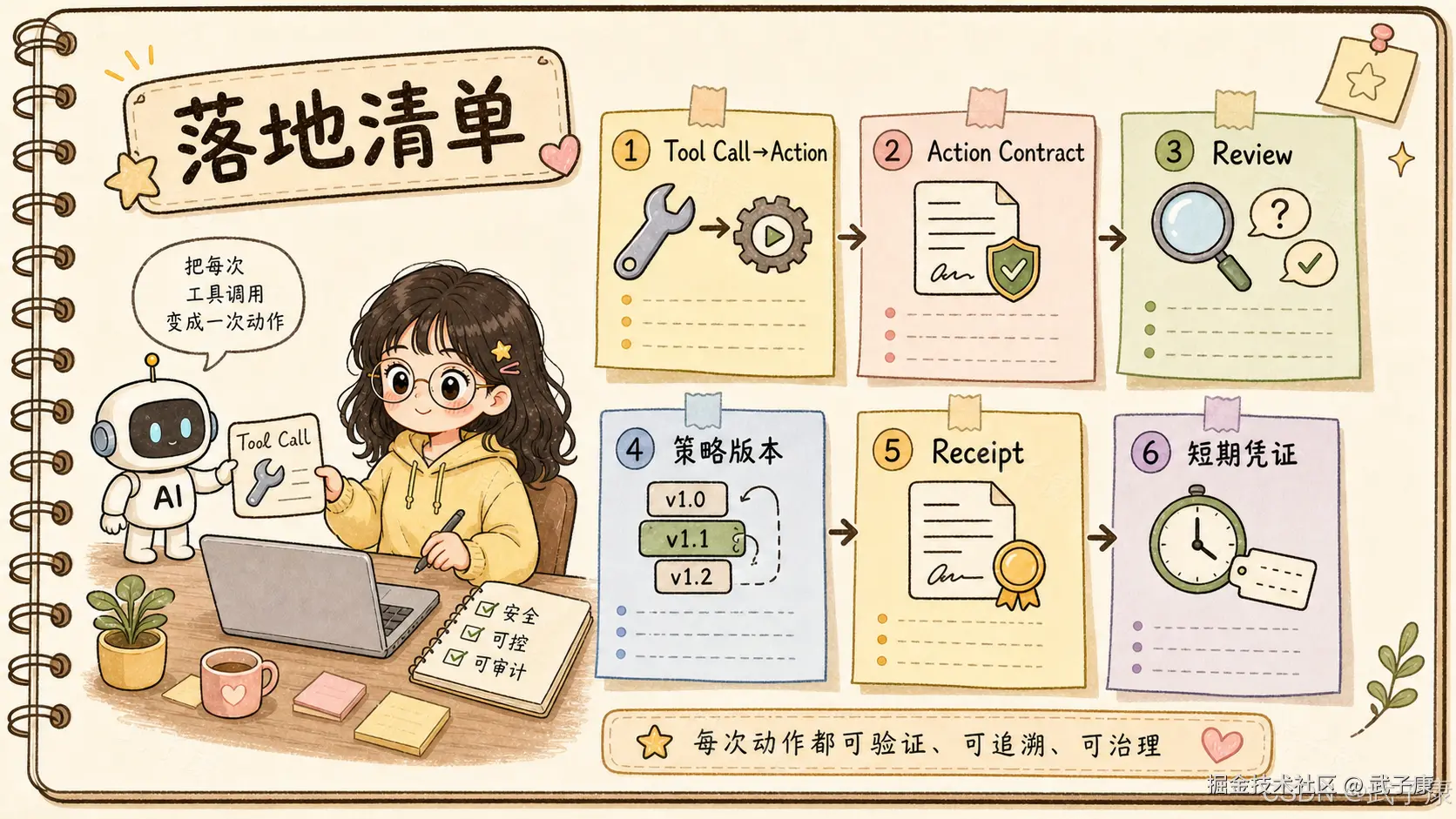
一个实用的低配版本,可以先做七件事。
第一,把所有 tool call 统一抽象成 action。
不要让每个工具自己散落处理权限、风险和日志。至少统一记录 operation、resource、parameters、risk、context。
第二,把权限和行为规则分开。
"能不能访问接口"是一层,"这次动作是否符合用户/组织意图"是另一层。
第三,为每个工具定义 action contract。
明确工具是只读还是写入,是否可逆,是否外发,是否涉及资金、隐私、公开发布、账号配置或生产系统。
第四,引入 Review 状态。
不要只有 allow / deny。高风险动作常常需要人工确认、审批流、二次验证、脱敏或延迟执行。
第五,记录策略版本。
未来一旦出问题,必须知道当时是哪版规则允许了这个动作。
第六,对高风险动作生成不可篡改审计记录。
早期可以用数据库 append-only 表、哈希链、签名字段。成熟后再演进到更严格的 receipt 机制。
第七,长期 Agent 必须短 token 化。
不要给长期运行 Agent 一个永不过期的大权限 token。应该采用长期授权根 + 短期任务凭证 + 每次执行刷新策略。
11. 一个直观例子:客服 Agent 自动退款
假设有一个电商客服 Agent,用户授权它自动处理售后。
某天它准备执行:
text
给客户 A 退款 300 美元。传统授权系统看到:
text
Agent 有退款权限。
300 美元低于 500 美元上限。
token 有效。于是可能允许。
AgentBound 会继续问:
text
授权权威:是否有退款权限?有。
行为宪法:300 美元是否需要经理审批?如果规则写着超过 200 美元需要复核,结果是 Review。
站点动作契约:退款是否不可逆?是否触发财务出账?是高风险动作。最终组合结果就是 Review。
动作不会直接执行,而是进入人工审批。同时系统生成 receipt:Agent 是谁、退款动作是什么、授权 token 是哪个、行为宪法是哪一版、站点契约是哪一版、为什么最终是 Review、谁签了名。
这才是 AgentBound 的实际意义:不是阻止 Agent 做事,而是让 Agent 在真实系统里被安全地委托。
12. 局限:必要但不充分
AgentBound 的前提很强。
第一,它假设所有高风险动作都必须经过治理层。如果 Agent 可以绕过 AgentBound 直接调用外部 API,系统保证就失效。
第二,它依赖行为宪法和站点动作契约的质量。如果规则写得模糊、覆盖不足、风险分类错误,AgentBound 也只能执行错误规则。
第三,它不能直接解决 prompt injection。它治理的是动作边界,不是输入污染本身。
第四,它依赖可信计算基。AgentBound 服务、签名密钥、策略仓库、审计账本都必须安全。
第五,论文目前更偏框架和设计,完整大规模实证结果仍需要后续实现和 benchmark 工具来支撑。
所以不能把 AgentBound 理解成"Agent 安全终极方案"。它更像是企业级 Agent 架构里必要但不充分的一层。
13. 总结:Agent 安全边界要从访问控制升级到行为治理
AgentBound 最有价值的地方,不是某个复杂算法,而是把 Agent 安全问题重新拉回了系统工程。
当 Agent 只是聊天机器人时,错误主要是回答质量问题。
当 Agent 连接工具时,错误开始变成执行风险。
当 Agent 长期运行并代表用户做事时,错误就变成治理、审计和责任问题。
未来可靠的 Agent 系统,不能只有:
text
LLM + Tools + Memory + Workflow还必须有:
text
Identity
Authorization
Policy
Approval
Action Contract
Audit Receipt
Replay Verification
RevocationAgentBound 的提醒很清楚:不要让 Agent 自己治理自己。
Agent 可以规划,可以提出动作,可以解释理由,但高风险动作是否应该执行,必须由外部、确定性、可审计、可复验的治理层来判断。
FAQ
AgentBound 和 OAuth / IAM 的区别是什么?
OAuth / IAM 主要回答"Agent 能不能访问某个资源"。AgentBound 进一步回答"这个已授权动作在当前上下文里是否应该执行"。它是授权之后、执行之前的行为治理层。
AgentBound 能防 prompt injection 吗?
不能直接防。论文明确把 prompt injection 和 jailbreak 列为范围外。AgentBound 可以在注入诱导出高风险动作时尝试拦截动作,但它不是输入侧安全方案。
governance receipt 和普通日志有什么区别?
普通日志记录事件结果。governance receipt 绑定动作、策略版本、各权威判断、最终结果和签名,目标是让第三方可以独立复验当时的治理过程。
工程团队最应该先借鉴哪一点?
先把高风险 tool call 统一抽象成 action,再为每个工具定义 action contract,并加入 Review 状态。不要让"有权限"直接等于"可以执行"。
错误速查卡(AgentBound / 行为治理工程化)
| 症状 | 根因 | 定位 | 修复 |
|---|---|---|---|
| Agent 在 OAuth scope 内正常调用退款,却违反了"超过 200 美元需复核"的业务规则 | 把"权限通过"直接当成"应该执行",缺少运行时行为规则层 | 看 audit 日志,只能看到 allow;看不到当时触发的是哪条宪法 | 引入 owner-signed behavioral constitution(OPA Rego / Cedar policy),把退款金额阈值、外发脱敏、不可逆动作等规则集中签名管理 |
| 高风险动作(如退款、转账、群发邮件)一次性自动执行,事后才发现问题 | 只有 allow / deny 两态,缺少 Review 中间状态 |
审计回溯发现 receipt 中 verdict 直接是 Permit,无人工复核记录 | 治理层引入 Permit / Review / Deny 三态,对高风险动作强制 Review + 人工确认 / 二次校验 |
| 不同治理判断相互冲突,无法决定谁优先 | 多权威按投票或平均分合成,存在"被投票救回"的危险 | 单个权威 verdict 是 Permit,但最终结果还是 Permit;事实上站点契约标了高风险 | 改用保守合成:Deny > Review > Permit,约束取交集,义务累积,溯源保留 |
| 长期 Agent 拿着永久大 token 跑,越权累积风险无法快速回收 | 没有 standing delegation + 短期 task delegation 分层 | token 过期时间 = "never";策略更新后 Agent 还在用旧规则 | 拆分长期授权根(owner 签名、过期时间、最大边界)+ 每次执行生成短期 task token,token 内写入当时策略哈希 |
| 事后审计只能复述"Agent 做了某事",无法复验"当时为什么允许" | 只有日志,没有可验证执行凭证 | 日志只有 action / result,没有 policy_version / judgment / signature | 高风险动作生成 governance receipt:Action + Governance + Judgments + Outcome + Signatures,写入 append-only 账本 |
| prompt injection 诱导 Agent 触发高风险动作,传统权限系统放行 | 治理只发生在模型生成之后 / 外部系统之前,但缺乏"动作出门前"的强制门 | 看 prompt 链路正常,看权限链也正常,但 receipt 标注 Review 后才能继续 | 在 Agent Runtime 与外部 API 之间强制插一道确定性治理服务;该服务绕过则视为违规 |
| 同一个退款 API 在不同业务上下文里风险不一样,系统却按同一规则处理 | 站点动作契约缺失或不完整,治理层看不到"这个调用是写入 / 不可逆 / 资金影响" | 工具元数据只有 function name,没有 risk metadata | 给每个 tool / API 定义 site action contract:可逆性、外部效应、资金影响、隐私等级、风险评级 |
| 策略更新后,老 receipt 还能"自圆其说",无法证明当下规则 | receipt 没绑定策略版本和哈希 | 审计调取历史 receipt 看不到当时 policy_version / policy_hash | receipt 必须包含 behavior constitution version + hash、site action contract version + hash,签名后写入审计账本 |
| AgentBound / 治理层本身被绕过,Agent 直接调外部 API | 治理服务是旁路而不是必经路径 | 流量监控发现 Agent 出口流量不经过治理网关 | 把治理服务设计为执行边界上不可绕过的 sidecar / gateway;旁路调用视为违规并告警 |
| 团队把 AgentBound 当成"Agent 安全终极方案",忽视其它攻击面 | 误把行为治理覆盖到模型对齐、prompt injection、硬件侧信道 | 内部把"上线 AgentBound"等同于"Agent 100% 安全" | 明确范围:AgentBound 管的是"动作出门前该不该执行",其它层(模型对齐、输入侧安全、密钥管理、供应链)继续独立投入 |