一、MySQL主从同步基础概念
1. 主从同步作用
将一台MySQL数据库的数据变更操作,自动同步到一台或多台MySQL从库,拆分两类服务器角色:
- Master(主服务器):负责接收客户端读写访问,记录所有数据变更
- Slave(从服务器):自动拉取主库变更日志,重放SQL实现数据同步
2. 主从同步核心原理
- Master端 :开启
binlog二进制日志,所有增删改、建库建表等写操作都会完整记录在binlog中;查询SELECT操作不会写入binlog。 - Slave端双线程工作机制
Slave_IO线程(IO线程):远程连接Master,读取主库binlog日志内容,写入本机relay-log中继日志Slave_SQL线程(SQL线程):读取本机relay-log中继日志,依次执行日志内SQL语句,最终和主库数据保持一致
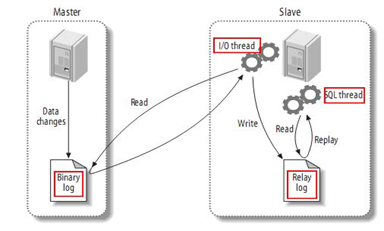
注意!主从两个数据库一定要先保持一致(最好做一次完全备份)
3. 主流主从同步架构模式
- 一主一从:单主库搭配单从库,基础实验架构
- 一主多从:单主库,多台从库分担读请求(常用于备份极为重要的数据)
- 链式复制(级联复制):主→从A→从B,从A同时充当下游从B的主库(此配置更加麻烦,需允许从A主机线程中的sql语句也要写入binlog文件。此方式应用较少)
- 互为主从(双主):两台服务器互相作为对方的主、从,适合双活扩展场景
4. 通用搭建总步骤
Master主服务器操作流程
- 修改配置文件,开启binlog二进制日志、配置唯一
server_id - 创建专门用于主从同步的用户,授予
REPLICATION SLAVE权限 - 全库备份现有数据,传输给从库,保证搭建前主从基础数据完全一致
Slave从服务器操作流程
- 修改配置文件,设置唯一
server_id(从库可不开启binlog) - 导入主库备份文件,完成数据还原(实现主从结构前保证服务器数据结构的统一)
- 执行
CHANGE MASTER TO语句,绑定主库连接信息,搭建主从关系 - 启动
START SLAVE同步进程,使用SHOW SLAVE STATUS \G校验同步状态
二、实操1:一主一从搭建
环境规划
- 主服务器Master:192.168.8.100
- 从服务器Slave1:192.168.8.101
1. Master主机完整操作
(1)安装并启动MySQL服务
bash
[root@master ~]# dnf -y install mysql-server mysql
[root@master ~]# systemctl start mysqld
[root@master ~]# systemctl enable mysqld(2)修改配置开启binlog、设置server_id
bash
[root@master ~]# vim /etc/my.cnf.d/mysql-server.cnf
[mysqld]
server-id=100
log_bin=master重启服务并校验日志文件生成:
bash
[root@master ~]# systemctl restart mysqld
[root@master ~]# ls /var/lib/mysql/master.*
/var/lib/mysql/master.000001 /var/lib/mysql/master.index(3)修改root初始密码
bash
[root@master ~]# mysqladmin -uroot password '123qqq...A'(4)master主服务器创建同步用户并授权
- 用户授权(用户slave1 ,密码为slavepwd,这个用户用于从服务器连接主服务器同步数据)
- 使用
mysql_native_password插件验证该用户的密码
-**REPLICATION SLAVE**表示使用户拥有向主服务器复制的权限
sql
mysql> CREATE USER 'slave1'@'%' IDENTIFIED with mysql_native_password BY 'slavepwd';
mysql> GRANT REPLICATION SLAVE ON *.* TO 'slave1'@'%';该用户只需要在主服务器创建,从服务器不需要
(5)查看主库binlog日志点位(搭建从库必须参数)
sql
mysql> SHOW MASTER STATUS ;
+---------------+----------+--------------+------------------+-------------------+
| File | Position | Binlog_Do_DB | Binlog_Ignore_DB | Executed_Gtid_Set |
+---------------+----------+--------------+------------------+-------------------+
| master.000002 | 984 | | | |
+---------------+----------+--------------+------------------+记录File日志文件名、Position偏移量,后续从库绑定主库需要。
(6)全库备份并传输至从库
备份master主机上的数据并拷贝到从服务器
bash
[root@master ~]# mysqldump -hlocalhost -uroot -p'123qqq...A' -A > ab1.sql
[root@master ~]# scp ab1.sql 192.168.8.101:/root2. Slave1主机完整操作
(1)安装MySQL,配置唯一server_id
bash
[root@slave1 ~]# dnf -y install mysql-server mysql
[root@slave1 ~]# vim /etc/my.cnf.d/mysql-server.cnf
[mysqld]
server_id=101
[root@slave1 ~]# systemctl restart mysqld(2)设置root密码
bash
[root@slave1 ~]# mysqladmin -uroot password '123qqq...A'(3)还原主库备份数据
bash
[root@slave1 ~]# mysql -uroot -p'123qqq...A' < /root/ab1.sql(4)slave1绑定主库连接信息,启动同步
- slave1指定主服务器信息:
sql
#指定主服务器信息
#MASTER_HOST= 指定主服务器的IP地址
#MASTER_USER= 指定主服务器授权用户
#MASTER_PASSWORD= 指定授权用户的密码
#MASTER_LOG_FILE= 指定主服务器binlog日志文件(到master上查看)
#MASTER_LOG_POS= 指定主服务器binlog日志偏移量(去master上查看)进行配置:
sql
mysql> CHANGE MASTER TO
-> MASTER_HOST="192.168.8.100",
-> MASTER_USER="slave1",
-> MASTER_PASSWORD="slavepwd",
-> MASTER_LOG_FILE="master.000002",
-> MASTER_LOG_POS=984;
-- 启动SLAVE进程
mysql> START SLAVE;
-- 查看主从同步状态
mysql> SHOW SLAVE STATUS \G校验标准:
Slave_IO_Running: Yes、Slave_SQL_Running: Yes,两项全为Yes代表同步正常。
若某一项写错,直接针对该项修改即可。
假设IP地址写错了,直接修改对应内容即可:mysql> CHANGE MASTER TO MASTER_HOST="192.168.8.100"'(但注意需要先stop slave再进行修改,修改完再start slave)
3. 一主一从同步验证
- Master创建数据库
sql
mysql> CREATE DATABASE sre;- Slave查询确认库同步生成
sql
mysql> SHOW DATABASES;
+--------------------+
| Database |
+--------------------+
| information_schema |
| mysql |
| performance_schema |
| sre |
| sys |
+--------------------+- Master创建表、插入数据
sql
mysql> CREATE TABLE sre.t1(id INT,name CHAR(10));
mysql> INSERT INTO sre.t1 VALUES(1,"Sam");
mysql> INSERT INTO sre.t1 VALUES(2,"Jack");- Slave查询校验数据同步
sql
mysql> SELECT * FROM sre.t1;
+------+------+
| id | name |
+------+------+
| 1 | Sam |
| 2 | Jack |
+------+三、实操2:一主多从搭建
其实一主多从配置和一主一从完全一致,只是有以下几个差异点:
所有节点 server_id 不能重复;
从库越多,主库推送日志压力越大;
多从可做流量分层隔离,提升读负载与容灾能力。
环境新增从库Slave2:192.168.8.102
1. Master操作:重新全量备份
一主多从新增从库前,需要重新备份当前全量数据,同步给新从库:
bash
[root@master ~]# mysqldump -uroot -p'123qqq...A' -A > ab2.sql
[root@master ~]# scp ab2.sql 192.168.8.102:/root再次查看主库最新binlog点位:
sql
mysql> SHOW MASTER STATUS;
+---------------+----------+--------------+------------------+-------------------+
| File | Position | Binlog_Do_DB | Binlog_Ignore_DB | Executed_Gtid_Set |
+---------------+----------+--------------+------------------+-------------------+
| master.000001 | 1599 | | | |
+---------------+----------+--------------+------------------+2. Slave2主机完整操作
不必重复创建授权用户,之前创建的授权用户可被多个从主机使用
(1)安装MySQL,配置独立server_id
bash
[root@slave2 ~]# dnf -y install mysql-server mysql
[root@slave2 ~]# vim /etc/my.cnf.d/mysql-server.cnf
[mysqld]
server_id=102
[root@slave2 ~]# systemctl restart mysqld
[root@slave2 ~]# systemctl enable mysqld(2)导入主库最新全量备份
bash
[root@slave2 ~]# mysql < /root/ab2.sql(3)绑定主库、启动同步
sql
mysql> CHANGE MASTER TO
-> MASTER_HOST="192.168.8.100",
-> MASTER_USER="slave1",
-> MASTER_PASSWORD="slavepwd",
-> MASTER_LOG_FILE="master.000001",
-> MASTER_LOG_POS=1599;
mysql> START SLAVE;
mysql> SHOW SLAVE STATUS \G3. 一主多从同步验证
- Master新增表并写入数据
sql
mysql> CREATE TABLE sre.t2(id INT,name CHAR(10),male ENUM("male","female"));
mysql> INSERT INTO sre.t2 VALUES(1,"Sam","male");
mysql> INSERT INTO sre.t2 VALUES(2,"Janner","female");- Slave1校验数据
sql
mysql> USE sre;
mysql> SHOW TABLES;
mysql> SELECT * FROM sre.t2;
+------+--------+--------+
| id | name | male |
+------+--------+--------+
| 1 | Sam | male |
| 2 | Janner | female |
+------+--------+--------+- Slave2校验数据(和Slave1数据完全一致)
sql
mysql> USE sre;
mysql> SHOW TABLES;
mysql> SELECT * FROM sre.t2;
+------+--------+--------+
| id | name | male |
+------+--------+--------+
| 1 | Sam | male |
| 2 | Janner | female |
+------+--------+--------+四、MySQL三大主从复制模式
复制模式定义:主库执行写操作后,何时给客户端返回执行结果,核心区分等待从库同步的逻辑。
1. 异步复制(MySQL默认模式)
- 流程:主库执行写入→写入binlog→立即返回客户端,不会等待任何从库同步完成,后台异步推送日志给从库。
- 优点:主库写入性能极高,无等待延迟
- 缺点:主从存在数据延迟;若主库宕机,未同步至从库的数据会永久丢失,数据一致性无保障
2. 全同步复制
- 流程:主库执行写入→推送binlog至所有从库,等待全部从库完成relay-log重放、确认同步完成后,才返回客户端结果。
- 优点:主从数据完全一致,无丢失风险
- 缺点:写入性能大幅下降,从库数量越多、网络越差,主库等待耗时越长
3. 半同步复制
- 流程:主库执行写入,等待至少一台从库接收binlog日志并确认后,就返回客户端,无需等待全部从库。
- 优点:兼顾性能与数据安全,至少一台从库保存完整变更日志
- 缺点:若唯一确认的从库故障,会导致等待时间变长
五、读写分离技术(MaxScale代理)
- 使用模板机克隆实验虚拟机(配置如下信息,配置IP地址信息,这里不再重复演示)
- master和slave2继续沿用上方主从关系

1. MaxScale基础介绍
- 开发厂商:MariaDB(MySQL同源兄弟公司)
- 核心作用:数据库中间件代理,自动实现写请求转发主库、读请求转发从库,完成读写分离
- 安装包:
maxscale-24.02.1-1.rhel.8.x86_64.rpm(点击自行下载)
主从进行读写分离之后,分别提供不同的服务,主提供写服务(如create,insert,delete等),从提供读服务(如select)
2. MaxScale完整部署流程
(1)MaxScale主机安装软件
bash
[root@maxscale ~]# dnf -y localinstall maxscale-24.02.1-1.rhel.8.x86_64.rpm(2)备份并修改核心配置文件
bash
[root@maxscale ~]# cp /etc/maxscale.cnf /etc/maxscale.cnf.bak
[root@maxscale ~]# vim /etc/maxscale.cnf配置文件分段说明:
(需要修改配置的部分都加了注释)
ini
...
12 [maxscale]
13 threads=auto
...
#指定要代理的数据库服务器,[server2]部分需要自己手工定义
21 [server1]
22 type=server
23 address=192.168.8.100 #指定主服务器地址
24 port=3306
25 [server2]
26 type=server
27 address=192.168.8.102 #指定从服务器地址
28 port=3306
...
#指定监控用户maxscalemon,用于登录后端服务器,检查服务器的运行状态和主从状态
47 [MariaDB-Monitor]
48 type=monitor
49 module=mariadbmon
50 servers=server1,server2 #上边的定义的主机
51 user=maxscalemon #指定监控用户
52 password=123qqq...A · #指定监控用户的密码
53 monitor_interval=2s
...
86 #[Read-Only-Service] #只读服务不需要,这段全部注释
87 #type=service
88 #router=readconnroute
89 #servers=server1
90 #user=service_user
91 #password=service_pw
92 #router_options=slave
...
#定义读写分离服务器配置
99 [Read-Write-Service]
100 type=service
101 router=readwritesplit
102 servers=server1,server2 #指定读写分离服务器
103 user=maxscalerouter #指定路由用户
104 password=123qqq...A #指定路由用户密码
...
#只读服务配置信息加上注释
118 #[Read-Only-Listener]
119 #type=listener
120 #service=Read-Only-Service
121 #protocol=mariadbprotocol
122 #port=4008
...
#读写分离配置信息,默认端口号为4006
124 [Read-Write-Listener]
125 type=listener
126 service=Read-Write-Service
127 protocol=mariadbprotocol
128 port=4006监控用户(maxscalemon):后台定时巡检所有后端数据库 ,检测节点是否存活、主从角色、同步是否正常,给读写路由提供状态判断依据,不处理业务 SQL
路由用户(maxscalerouter):代理业务客户端转发所有业务 SQL ,将写请求路由到主库、读请求分发到从库,实际执行数据增删改查操作
(3)后端主、从库创建两类专用账号
- 根据/etc/maxscale.cnf配置要求,需要在master主机和slave主机授权用户
- maxscalemon用户,密码为123qqq...A
- maxscalerouter用户,密码为123qqq...A
- 创建监控用户maxscalemon,用于登录后端服务器,检查服务器的状态
- 创建路由用户maxscalerouter,检测客户端的用户名和密码在后端数据库中是否存在
- REPLICATION SLAVE:该权限能够同步数据,查看从服务器上slave的状态;
- REPLICATION CLIENT:该权限可以获取数据库服务的状态(数据库服务是否允许,主从是否正常,服务器是否存活)
监控用户:maxscalemon(监控账号)
权限需求:REPLICATION SLAVE、REPLICATION CLIENT,用于检测主从同步状态、服务在线状态
Master主机执行(因为之前做过主从同步,从库会自动同步账号,因此无需在从库重复操作)
sql
mysql> CREATE USER 'maxscalemon'@'%' IDENTIFIED WITH mysql_native_password BY '123qqq...A';
mysql> GRANT REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO 'maxscalemon'@'%';路由用户:maxscalerouter(路由校验账号)
权限需求:仅需要查询mysql系统库,校验客户端账号密码是否存在
sql
mysql> CREATE USER 'maxscalerouter'@'%' IDENTIFIED WITH mysql_native_password BY '123qqq...A';
mysql> GRANT SELECT ON mysql.* TO 'maxscalerouter'@'%';补充:若主从同步未生效,Slave2需要手动创建上述两个账号并授权。
(4)启动MaxScale服务
bash
[root@maxscale ~]# systemctl restart maxscale
[root@maxscale ~]# systemctl enable maxscale
[root@maxscale ~]# ss -mtulp | grep :40063. 读写分离功能测试
(1)- master主机授权测试用户
sql
[root@master ~]# mysql -uroot -p'123qqq...A'
mysql> CREATE USER 'sam'@'%' IDENTIFIED WITH mysql_native_password BY '123qqq...A';
mysql> GRANT ALL ON . TO 'sam'@'%';(2)- maxscale充当客户端访问读写分离服务器
bash
#安装mysql连接命令
[root@maxscale ~]# dnf -y install mysql
#注意使用P指定端口
[root@maxscale ~]# mysql -h192.168.8.99 -P4006 -usam -p"123qqq...A"
mysql> CREATE DATABASE study; #创建study库
mysql> CREATE TABLE study.t1(id INT,name VARCHAR(20)); #创建表
mysql> INSERT INTO study.t1 VALUES(1,'tom'); #插入数据分别在Master、Slave2查询,数据同步存在。
(3)验证查看数据
- master主机验证查看数据
sql
[root@master ~]# mysql -uroot -p'123qqq...A'
mysql> SELECT * FROM study.t1;
+------+------+
| id | name |
+------+------+
| 1 | tom |
+------+------+- slave主机验证查看数据
bash
[root@slave2 ~]# mysql -uroot -p''123qqq...A'
mysql> SELECT * FROM study.t1;
+------+------+
| id | name |
+------+------+
| 1 | tom |
+------+------+(4)读操作分流验证(核心读写分离效果)
做了读写分离,所以如果配置成功,我们在从服务器插入jerry的数据,主服务器肯定没有jerry;此时我们在maxscale主机查询,能看到在从主机新插入的jerry数据,就能说明我们查看的数据来自于从服务器。
- 直接登录Slave2手动插入一条数据(仅从库本地存在,不会同步回主库)
sql
mysql> INSERT INTO study.t1 VALUES(2,"jerry");- 通过MaxScale代理执行查询,能查到Slave独有的jerry数据,证明SELECT读请求转发至从库:
sql
mysql> SELECT * FROM study.t1;
+------+-------+
| id | name |
+------+-------+
| 1 | tom |
| 2 | jerry |
+------+-------+六、全文核心总结
- MySQL主从同步依靠binlog+relay-log双日志、IO+SQL双线程实现数据复制,必须保证全库备份初始化主从数据、所有实例
server_id唯一。 - 一主一从、一主多从是最常用生产架构,搭建核心命令:
CHANGE MASTER TO、START SLAVE、SHOW SLAVE STATUS \G。 - 异步、半同步、全同步三种复制模式,性能与数据安全性成反比,默认异步复制。
- MaxScale作为MariaDB官方中间件,监听4006端口自动完成读写分离,写流量走主库、读流量分发从库,部署需要监控账号与路由校验账号两套专用权限。
- 读写分离验证关键手段:手动单独写入从库独有数据,通过代理查询能读取即代表读请求分流从库,分离生效。