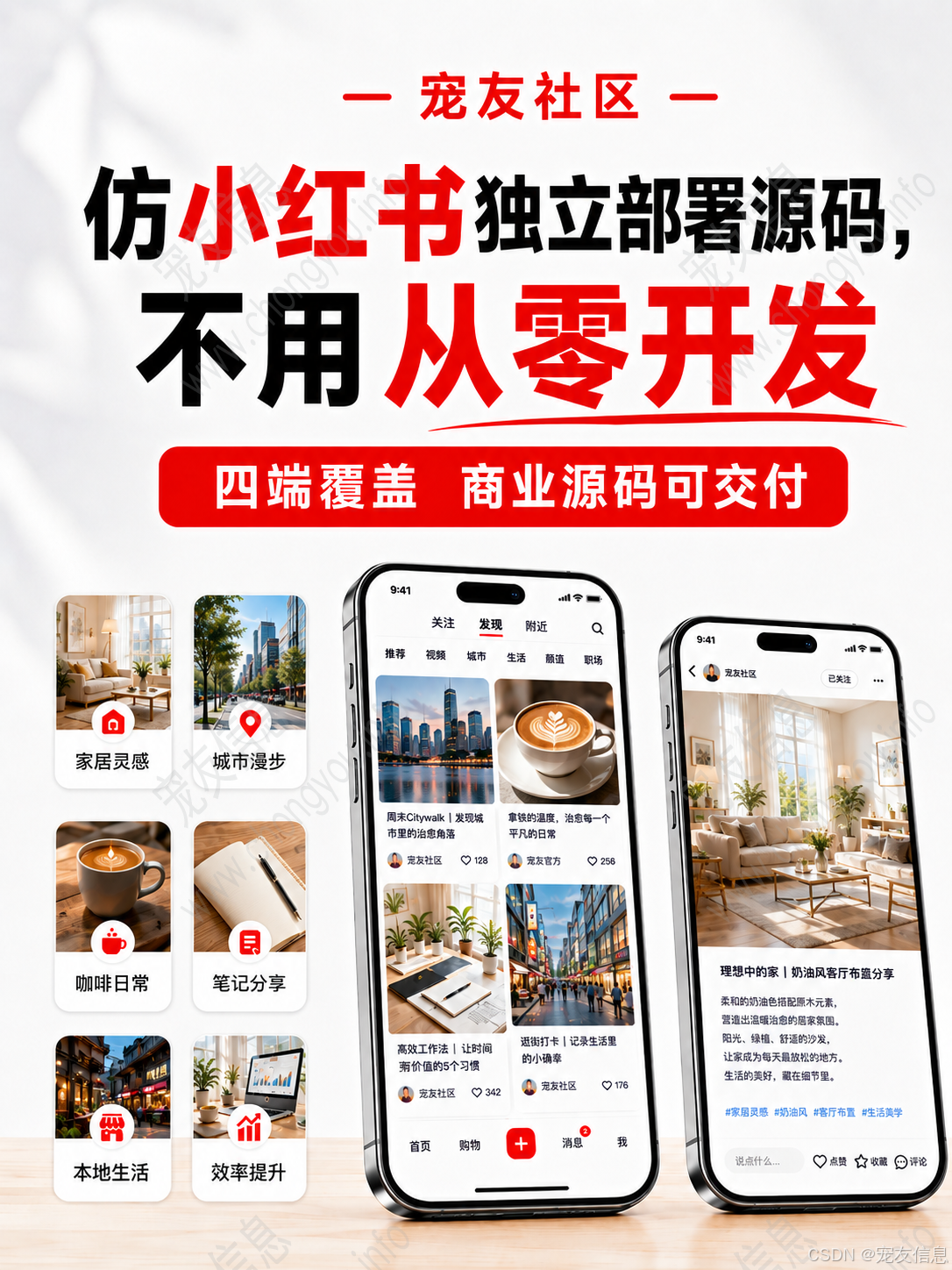
仿小红书类产品做起来最容易被低估的地方,不是图文发布、短视频发布、多图上传、点赞评论、收藏关注这些功能本身,而是数据量上来以后,系统会不会开始变慢、变乱、变得难以维护。
内容越来越多后,发现页瀑布流加载变慢,热门搜索不准,内容搜索结果延迟明显;用户互动变多后,点赞数、收藏状态、未读消息、订单状态在 APP、小程序、H5 之间出现不一致。表面看是功能问题,底层其实是缓存、搜索、消息、任务调度和接口结构没有设计好。
本文以 Spring Boot 仿小红书源码架构为基础,围绕两个典型痛点展开:
第一个痛点是内容流失控,第二个痛点是多端状态不同步。相关功能包括图文发布、短视频发布、双列瀑布流、内容搜索、热门搜索、点赞评论、收藏关注、单聊消息、系统通知、商品订单、在线支付等,都会放在技术链路中分析。
一、内容越多,发现页、搜索页和瀑布流越容易失控
仿小红书系统最核心的流量入口通常是发现页、关注页、附近页和搜索页。刚开始数据量少时,直接查数据库也能跑;一旦内容数量、图片数量、短视频数量、用户互动数量增加,问题会集中出现。
发现页加载慢,通常不是前端页面写得慢,而是后端接口每次都要查内容表、用户表、点赞表、收藏表、评论表,再拼接封面图、作者信息、互动状态。搜索页卡顿,也不只是搜索框的问题,而是标题、正文、话题、商品、分类都挤在数据库里做模糊查询。双列瀑布流重复数据、漏数据,则多半和分页方式有关。
如果继续使用普通分页和数据库 LIKE 查询,内容越多,接口越容易变成性能瓶颈。
1. 内容发布不能只写一张内容表
图文发布、短视频发布、多图上传、话题标签、草稿保存,看起来都是发布功能,但后端不能简单地把所有字段塞进一张表里。
更合理的方式是拆成内容主表、资源表、话题关系表、分类表、草稿表。内容主表保存核心信息,资源表保存图片、视频、封面、宽高、时长等信息,话题关系表负责内容和话题标签之间的绑定。
这样做的好处是内容详情可以完整读取,瀑布流列表又可以只读取轻量字段,避免每次列表查询都拉取大量正文和资源信息。
javascript
// 内容发布时只处理主流程,图片视频、话题关系拆到独立方法中
@Transactional
public Long createPost(PostCreateDTO dto, Long userId) {
Post post = new Post();
post.setUserId(userId);
post.setTitle(dto.getTitle());
post.setSummary(dto.getSummary());
post.setCategoryId(dto.getCategoryId());
post.setType(dto.getType()); // 图文或短视频
post.setAuditStatus(AuditStatus.WAITING);
post.setCreateTime(LocalDateTime.now());
postMapper.insert(post);
postMediaService.saveMediaList(post.getId(), dto.getMediaList());
postTopicService.bindTopics(post.getId(), dto.getTopicIds());
return post.getId();
}图片和视频资源建议上传到对象存储,数据库只保留资源地址和元数据。短视频内容需要额外保存封面图、播放地址、视频时长。双列瀑布流需要图片宽高,否则前端无法稳定计算卡片高度,容易出现页面跳动。
草稿保存也不应该和正式发布混在一起。草稿可以保存编辑中的标题、正文、多图、话题标签和分类,但不进入内容审核,不写搜索索引,也不进入发现页。
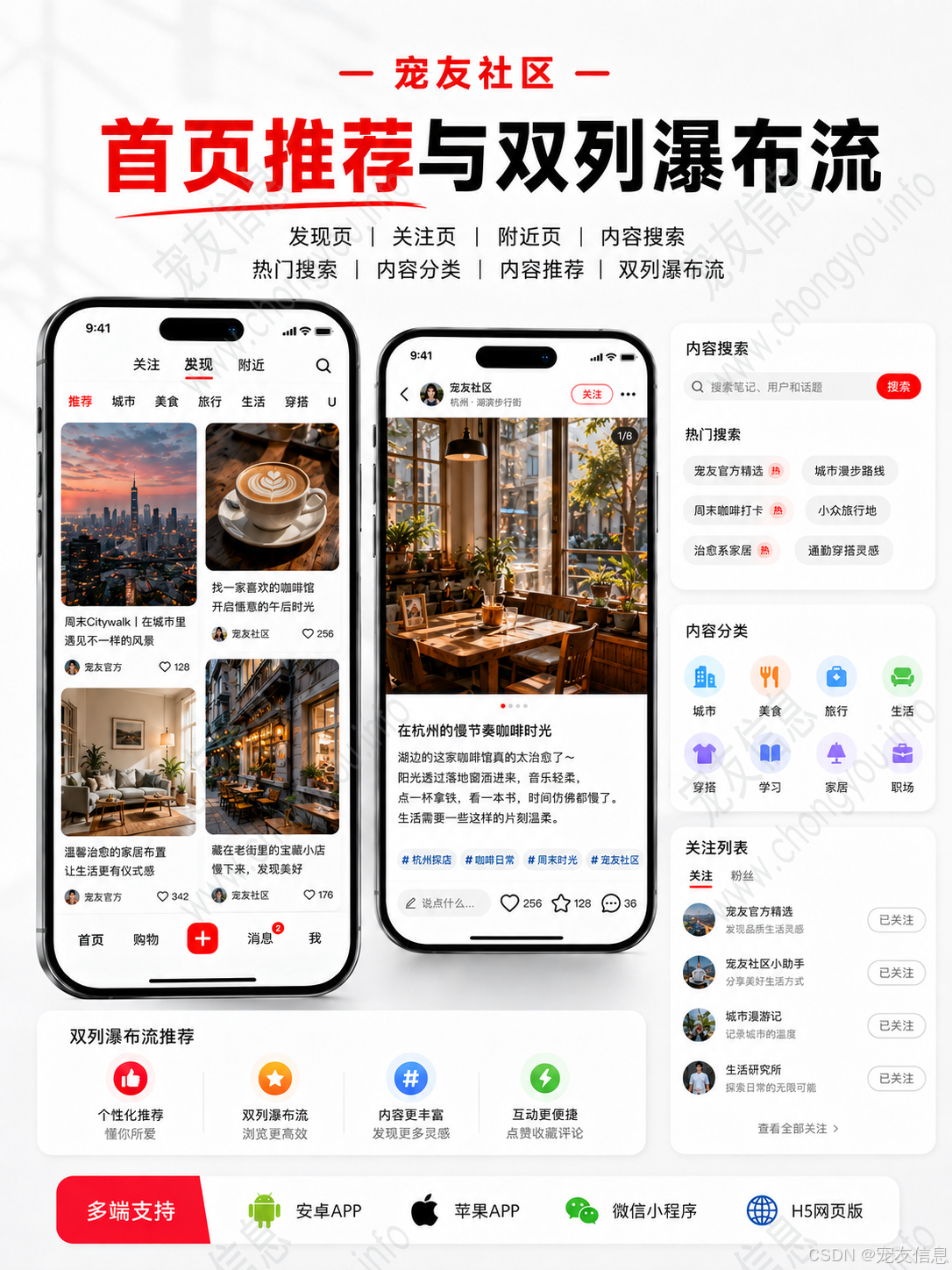
2. 双列瀑布流最怕普通分页
仿小红书页面常见双列瀑布流布局。很多系统一开始使用 pageNum + pageSize,数据少时没问题,内容增长后就会出现重复、漏数据、顺序不稳定。
原因很简单:用户在下拉加载时,数据库中的内容还在不断新增。如果第一页和第二页之间插入了新内容,传统分页的偏移量就会变化,用户看到的数据就可能重复。
内容流更适合游标分页。发现页可以使用推荐分数和内容 ID,关注页可以使用发布时间和内容 ID,附近页可以结合距离、发布时间和内容 ID。
javascript
// 关注页内容流:使用 createTime + id 做游标,避免普通分页带来的重复数据
public List<PostCardVO> queryFollowFeed(Long userId,
LocalDateTime lastTime,
Long lastId,
Integer limit) {
List<Long> followUserIds = followService.queryFollowUserIds(userId);
LambdaQueryWrapper<Post> wrapper = new LambdaQueryWrapper<>();
wrapper.in(Post::getUserId, followUserIds)
.eq(Post::getStatus, PostStatus.NORMAL);
if (lastTime != null && lastId != null) {
wrapper.and(w -> w.lt(Post::getCreateTime, lastTime)
.or()
.eq(Post::getCreateTime, lastTime)
.lt(Post::getId, lastId));
}
wrapper.orderByDesc(Post::getCreateTime)
.orderByDesc(Post::getId)
.last("limit " + limit);
return postMapper.selectList(wrapper)
.stream()
.map(this::toPostCardVO)
.toList();
}瀑布流接口不适合返回过重数据。列表页只需要标题、封面、作者昵称、头像、点赞数、收藏状态、内容类型、图片比例等字段。评论列表、正文详情、视频播放地址等可以进入详情页后再加载。
如果列表接口一次性返回正文、全部图片、全部评论、商品详情、用户完整资料,后期接口会越来越慢,前端也会越来越难处理。
3. 热门搜索和内容搜索不能只靠数据库
仿小红书系统通常会有内容搜索、热门搜索、商品搜索、话题搜索、分类筛选。数据库 LIKE 可以应付早期数据,但当标题、正文、话题、商品名称都需要检索时,查询效率和结果排序都会变差。
EasyES 更适合承担搜索索引。内容审核通过后,将标题、摘要、话题、分类、作者昵称、封面图、发布时间等字段写入索引。商品上架后,将商品名称、分类、价格区间、状态等字段写入商品索引。
搜索时先查索引,再根据内容 ID 回库补充当前用户是否点赞、是否收藏、是否关注作者等状态。这样搜索模块负责检索,业务数据库负责状态补充,边界更清楚。
热门搜索不适合每次都查数据库统计。可以用 Redis ZSet 记录关键词热度。
javascript
// 热门搜索词统计:搜索一次增加一次权重
public void addSearchKeyword(String keyword) {
if (!StringUtils.hasText(keyword)) {
return;
}
redisTemplate.opsForZSet()
.incrementScore("xhs:hot:search", keyword.trim(), 1);
}
public Set<String> getHotSearchKeywords() {
return redisTemplate.opsForZSet()
.reverseRange("xhs:hot:search", 0, 9);
}这里还要注意一个细节:内容状态变化后,搜索索引必须同步变化。内容被删除、审核未通过、设置隐藏后,如果索引没有同步处理,用户仍然可能在搜索结果中看到异常内容。
4. Redis缓存不是越多越好,关键是缓存边界
发现页、热门内容、热门搜索、浏览记录、点赞数、收藏数,都适合结合 Redis。但缓存不能无边界使用,否则很容易出现缓存数据和数据库数据不一致。
例如内容被审核拦截后,发现页缓存中不能继续出现这条内容;用户取消收藏后,内容详情页不能还显示已收藏;作品被删除后,个人主页和搜索结果中都要同步变化。
比较稳妥的方式是将 Redis 用在三类场景中:
第一类是热点读取,例如发现页推荐池、热门搜索词、热门内容榜单。
第二类是高频计数,例如浏览数、点赞数、收藏数。
第三类是短期状态,例如短信验证码、登录 Token、未读消息数、临时草稿。
高频计数可以先写 Redis,再通过 Quartz 定时任务批量同步到数据库。同步任务要注意幂等性,不能因为任务重复执行导致浏览数、点赞数重复增加。
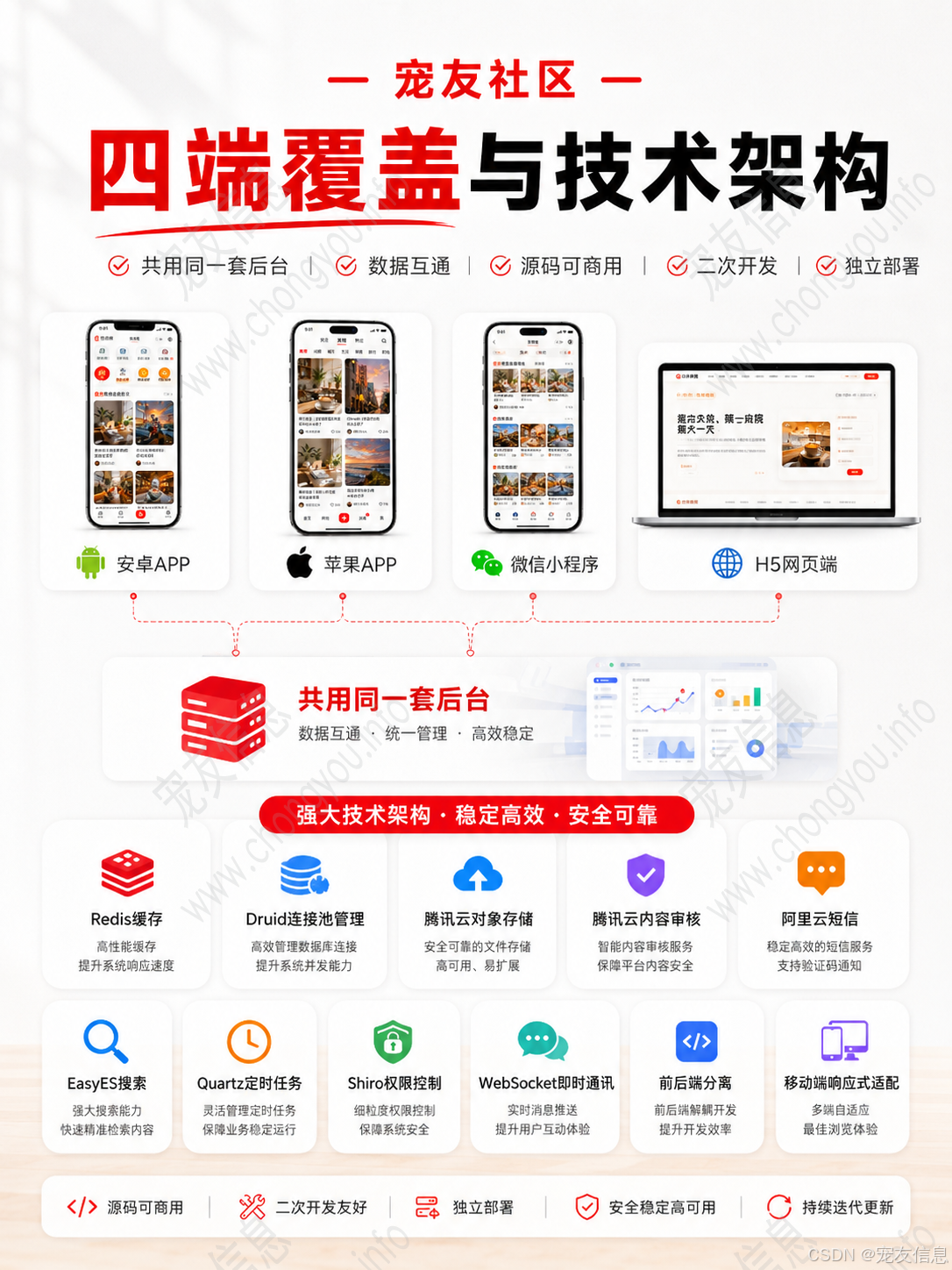
二、多端设备状态不同步,用户体验会迅速变乱
仿小红书系统如果覆盖安卓 APP、苹果 APP、微信小程序、H5 网页端,最容易出现的问题就是状态不同步。
用户在 APP 点赞一条内容,小程序端打开后仍然显示未点赞;用户在 H5 收藏商品,APP 收藏管理里没有更新;用户在小程序支付订单,H5 订单页仍然是待支付;用户在 APP 读了私信,H5 端未读数还挂着。
这类问题不是页面问题,而是后端状态模型、消息机制和接口设计没有统一。
1. 多端共用后台,接口字段必须统一
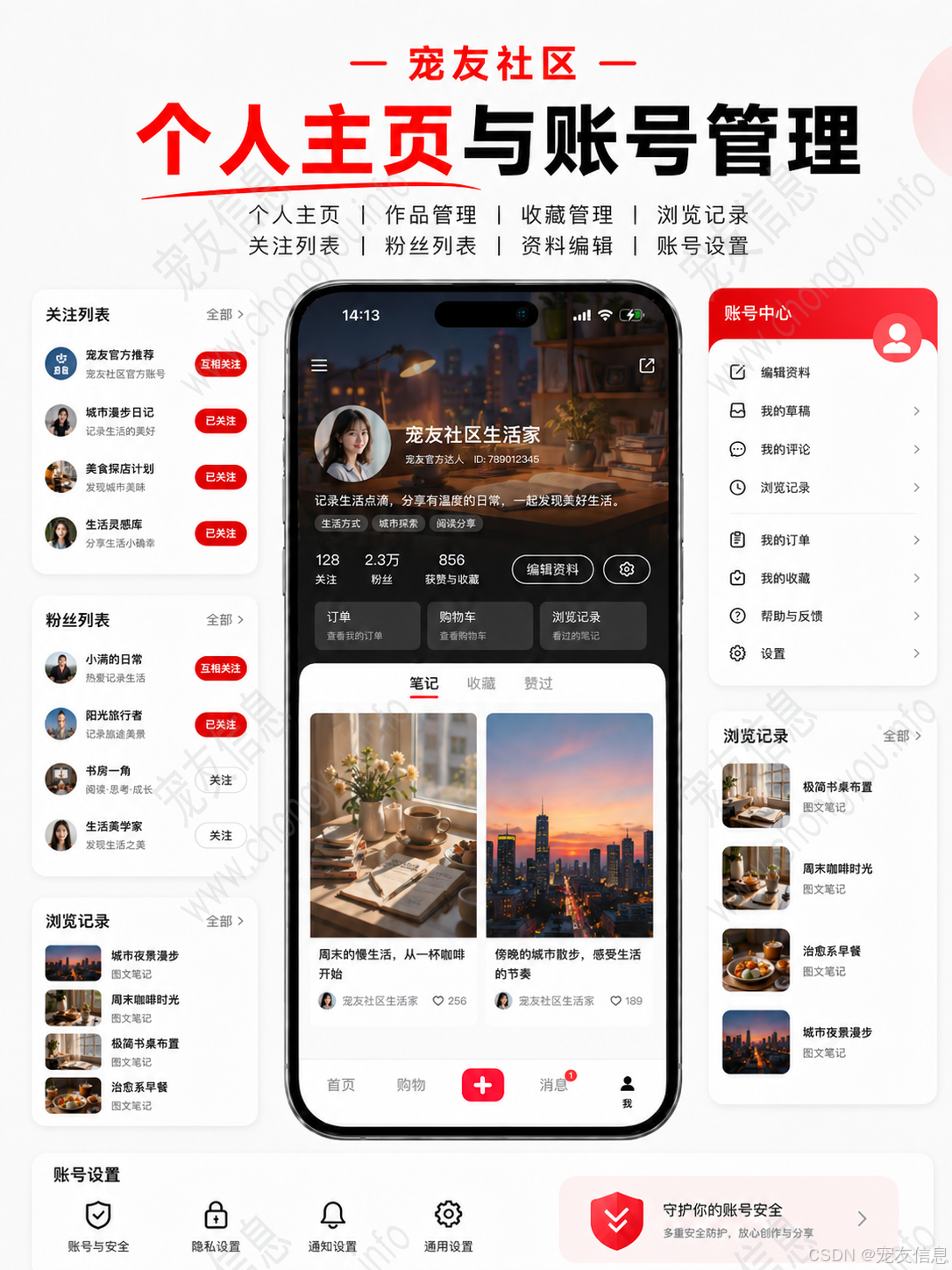
四端展示可以不同,但接口结构不能各写各的。内容详情、用户主页、收藏管理、浏览记录、关注列表、粉丝列表、商品详情、订单管理,都应来自同一套后台数据。
例如内容详情接口不仅要返回内容本身,还要返回当前用户的互动状态:
当前用户是否点赞、是否收藏、是否关注作者;内容是否可见;评论数量是否最新;作者主页信息是否可展示。这样 APP、小程序和 H5 才能根据同一套数据渲染出一致状态。
如果某一端自己维护点赞状态,另一端从数据库查状态,很快就会出现数据不一致。
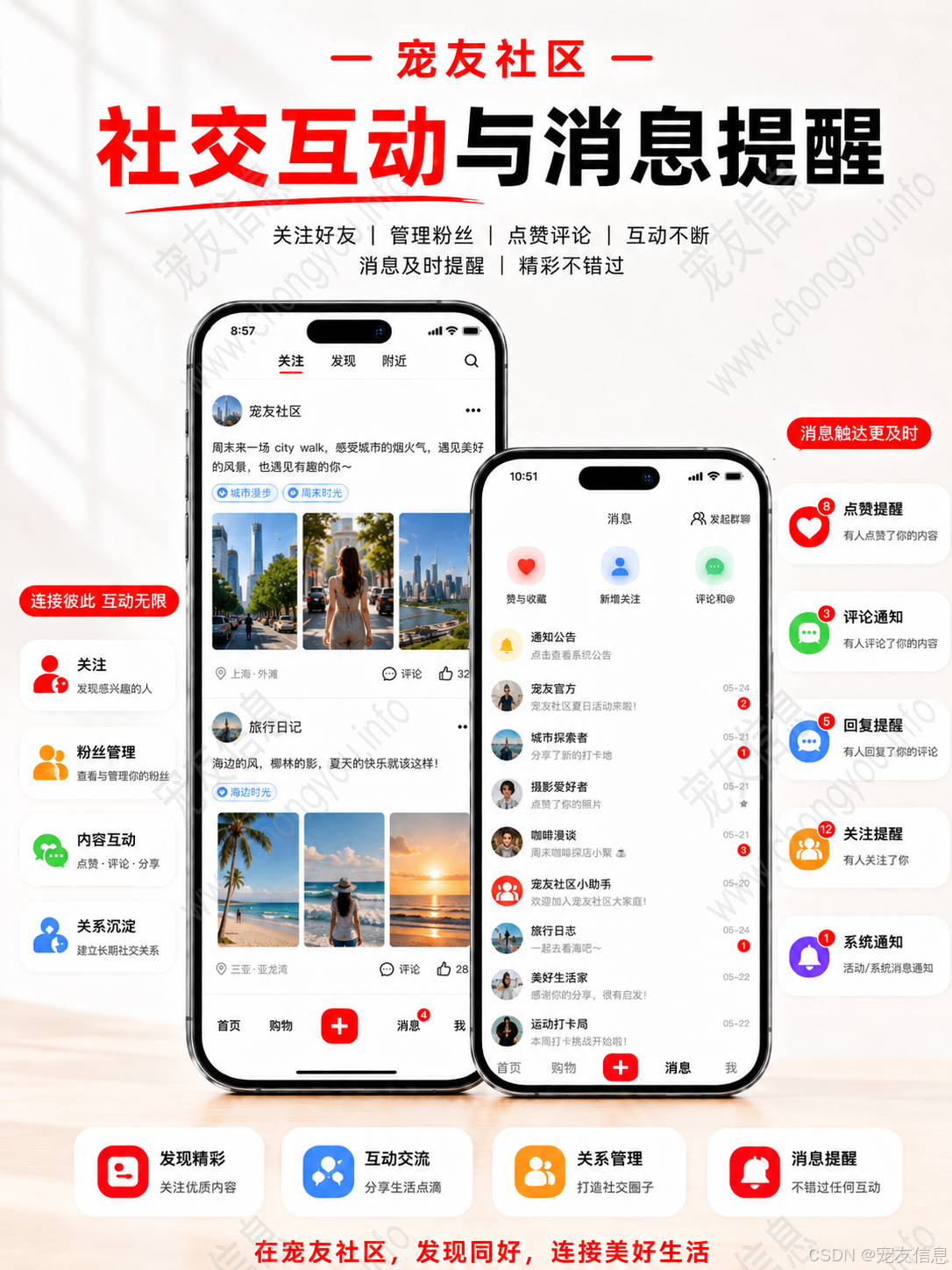
2. 点赞、收藏、关注要有关系表约束
点赞、收藏、关注、粉丝管理这些功能都属于用户关系数据。它们不能只靠前端状态,也不能只靠缓存计数。
点赞表应记录 user_id、target_id、target_type;收藏表应记录 user_id、content_id;关注表应记录 user_id 和 follow_user_id。为了防止重复点击导致脏数据,需要建立联合唯一索引。
例如点赞内容和点赞评论可以共用 target_type 区分。收藏内容、浏览记录、作品管理也可以通过关系表和内容状态进行组合查询。
点赞数和收藏数可以用 Redis 加速,但用户是否点赞、是否收藏这类判断必须有稳定的数据来源。否则多端切换时,状态很容易混乱。
3. WebSocket负责实时,数据库负责可靠
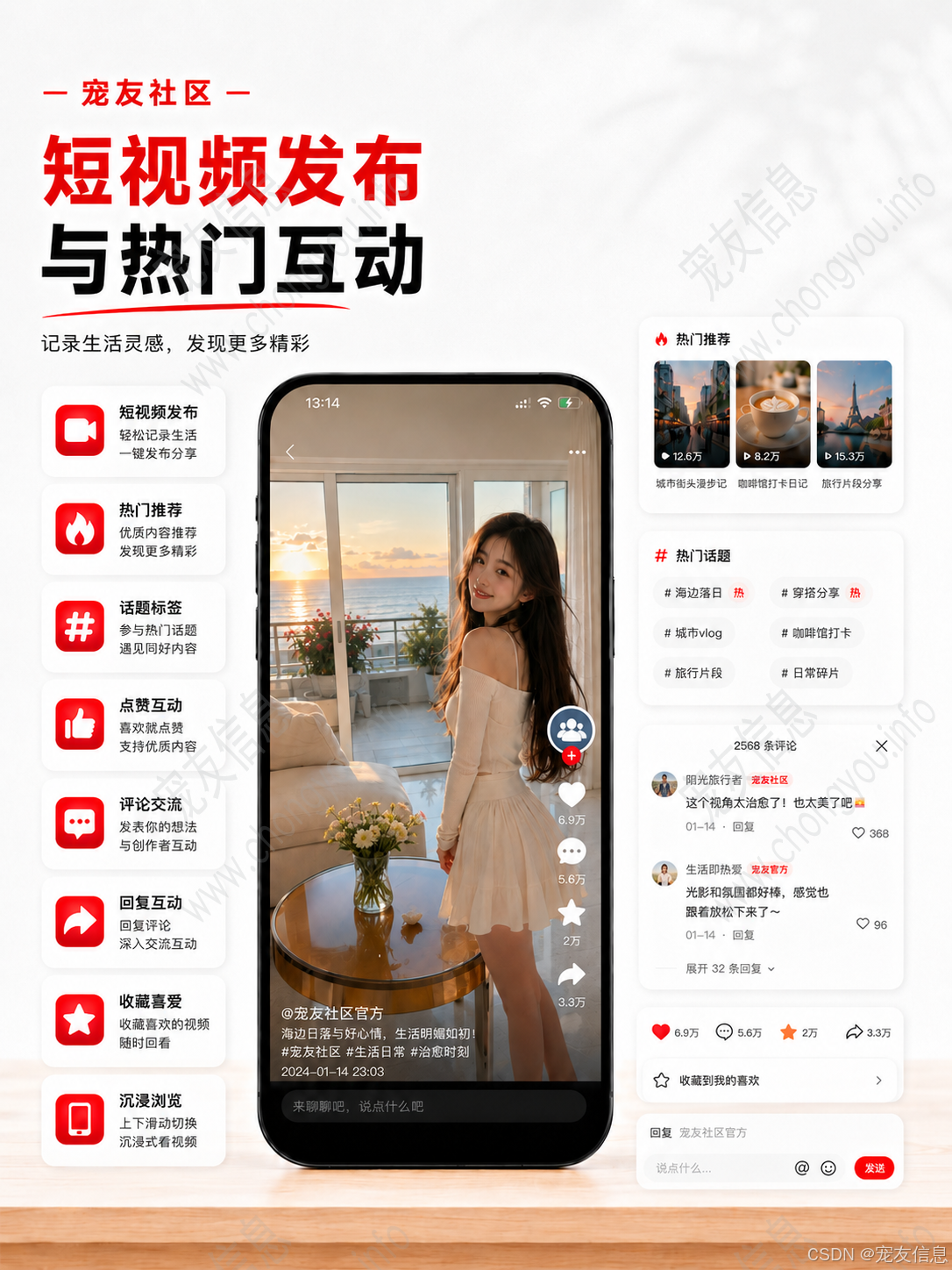
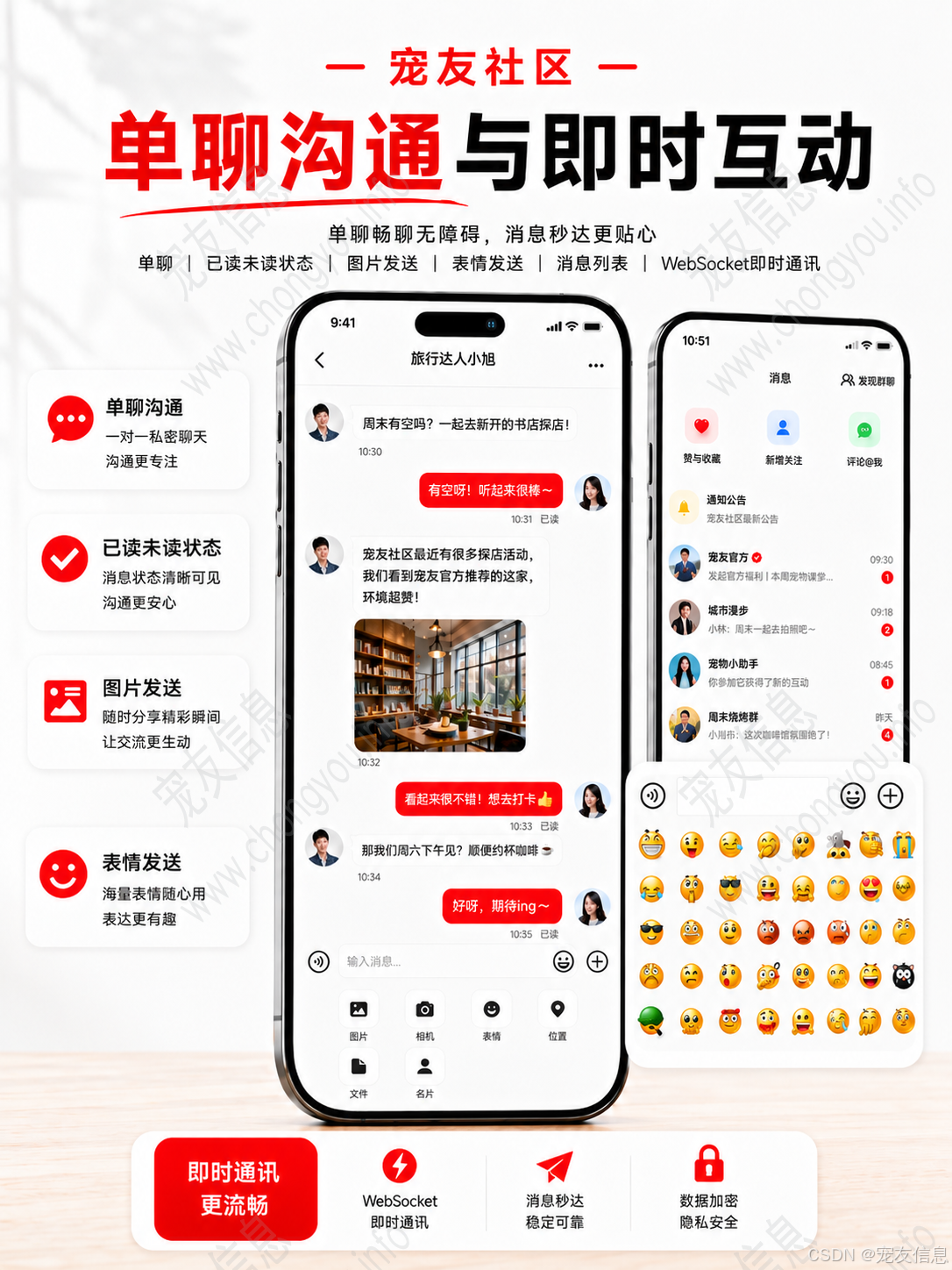
单聊、消息已读未读、图片发送、表情发送、系统通知、评论通知、点赞提醒、关注提醒,都需要消息体系支撑。
WebSocket 可以解决在线实时推送,但不能替代数据库。消息发送时,正确顺序应该是先保存消息,再推送消息。如果先推送后入库,一旦连接异常或写库失败,就可能出现消息丢失。
私信单聊和系统通知可以分开设计。单聊消息关注会话、发送者、接收者、消息内容、已读未读;系统通知关注触发类型,例如评论、点赞、关注、系统提醒。
未读数可以放在 Redis 中加速读取,但用户进入会话后,需要同步修改数据库中的已读状态。这样用户切换到 H5 或小程序时,未读状态才能保持一致。
4. 订单状态必须以后端为准
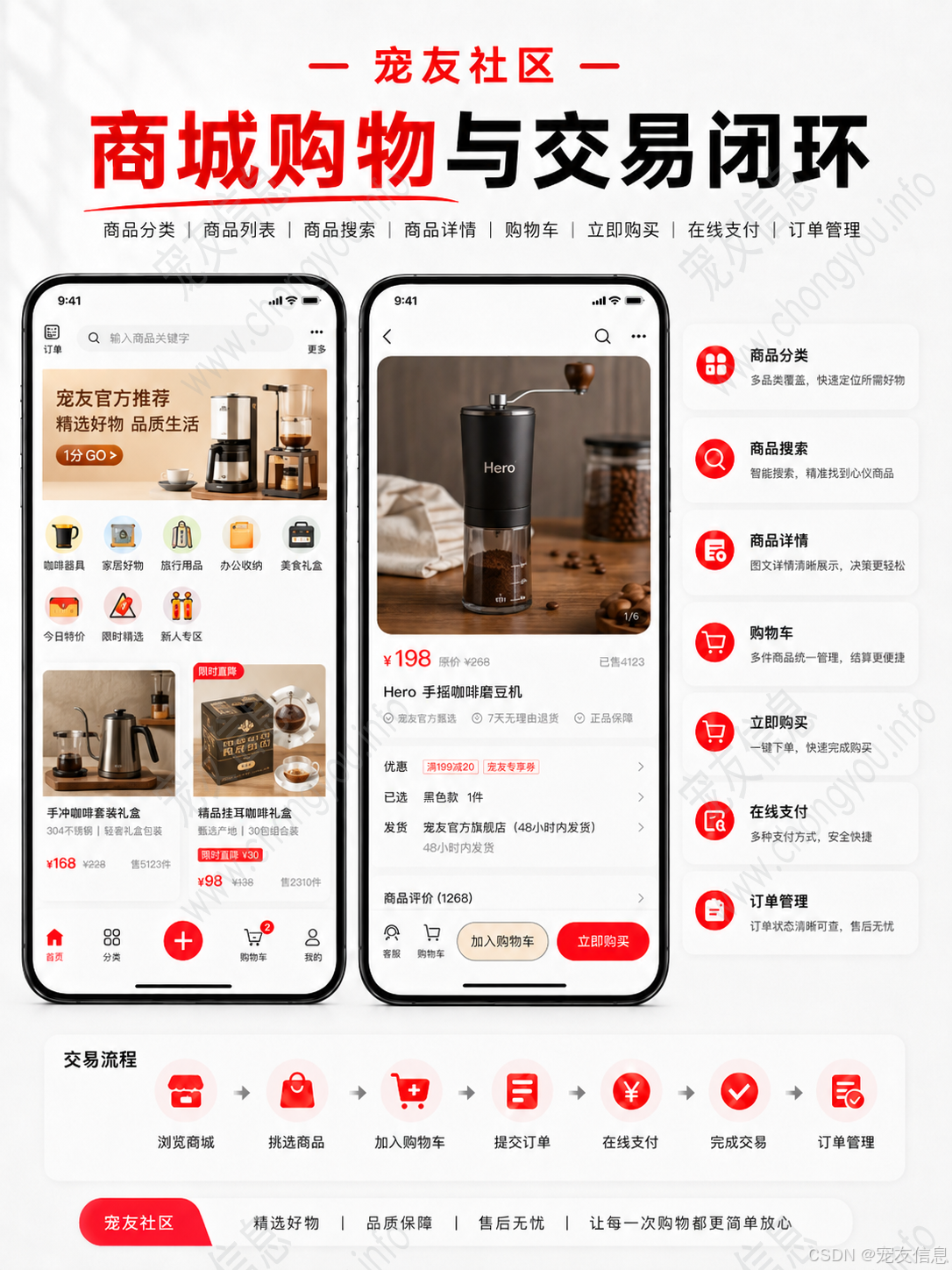
商品分类、商品列表、商品详情、商品搜索、购物车、立即购买、订单管理、在线支付,这些交易功能对状态一致性要求更高。
用户提交订单后,订单进入待支付状态。支付完成后,不能只靠前端跳转页面修改订单状态,而应以后端支付回调为准。后端收到回调后,校验订单号、支付金额、支付状态,再更新订单表。
如果用户在微信小程序支付成功,但 APP 端订单仍然显示待支付,大概率是订单状态没有统一由后端维护,或者支付回调处理不完整。
Quartz 可以定时扫描超时未支付订单,将其改为已取消。这里同样要保证幂等性,防止重复关闭订单或重复释放库存。
5. 权限和账号设置不能只放在页面层
账号设置、资料编辑、个人主页、作品管理、收藏管理、关注列表、粉丝列表,都涉及用户身份。后台的内容分类、商品分类、订单管理、系统通知则涉及角色权限。
Shiro 可以用于登录认证和接口鉴权。在前后端分离架构中,权限不能只依赖前端隐藏按钮。只要接口存在,就必须在后端判断当前用户是否有权限访问。
普通用户只能管理自己的资料、作品、收藏和浏览记录;后台账号根据角色控制内容分类、商品分类、订单、系统通知等操作。这样即使多个端同时访问,也能保持同一套权限规则。
技术链路如何串起来
围绕这两个痛点,仿小红书源码中的核心技术可以这样理解:
Spring Boot 负责组织后端业务接口;Redis 处理热点内容、热门搜索、未读数、验证码和高频计数;EasyES 处理内容、话题、商品搜索;WebSocket 处理单聊和在线通知;Quartz 处理浏览记录落库、订单超时关闭、热门数据刷新和索引修复;Shiro 处理登录认证和权限边界;Druid 管理数据库连接并辅助慢 SQL 监控;对象存储处理图片、短视频和封面文件;内容审核处理图文、图片、视频发布前的检测。
这些技术不是为了堆栈完整,而是分别对应系统中的风险点。
Redis 对应内容流高频读取。
EasyES 对应搜索性能下降。
WebSocket 对应消息实时触达。
Quartz 对应异步数据沉淀。
Shiro 对应多角色权限边界。
对象存储对应图片视频资源压力。
内容审核对应内容发布链路安全。
当内容量、用户量、互动量、订单量不断增加时,真正拉开差距的不是某个页面写得多像,而是这些底层链路能不能保持稳定。
模块拆分建议
为了避免后期代码混乱,仿小红书源码不适合把内容、用户、互动、消息、订单都写在一个大模块里。更清晰的方式是按照业务边界拆分。
javascript
content 图文、短视频、多图、话题、分类、草稿
feed 发现页、关注页、附近页、瀑布流推荐
search 内容搜索、热门搜索、商品搜索、话题搜索
interact 点赞、评论、回复、收藏、浏览记录
user 个人主页、资料编辑、关注列表、粉丝列表
im 单聊、图片消息、表情消息、已读未读
notice 系统通知、评论通知、点赞提醒、关注提醒
goods 商品分类、商品列表、商品详情
order 购物车、立即购买、订单管理、在线支付
system 账号设置、权限角色、接口鉴权
task 定时任务、缓存同步、索引修复
file 图片视频上传、对象存储
audit 文本审核、图片审核、视频审核这样的拆分能减少模块之间的互相影响。内容发布只关心内容入库、资源绑定、审核状态和索引同步;互动模块只关心点赞、评论、收藏、关注关系;消息模块只关心单聊、通知和未读状态;订单模块只关心商品、购物车、支付和订单流转。
如果模块边界混乱,后期改一个点赞提醒,可能影响评论通知;改一个搜索字段,可能影响内容发布;改一个订单状态,可能影响商品详情。系统越复杂,这种隐患越明显。
两个问题决定仿小红书系统能否稳定运行
第一个问题是内容流能不能承受数据增长。图文、短视频、多图、话题、分类、推荐、搜索、热门内容都会不断放大接口压力。如果没有 Redis 缓存、EasyES 搜索、游标分页和合理表结构,发现页和搜索页很容易先出问题。
第二个问题是多端状态能不能保持一致。点赞、收藏、关注、私信、通知、订单、支付、浏览记录、个人主页都涉及状态同步。如果 APP、小程序、H5 各自维护状态,或者后端没有统一接口和统一数据模型,用户切换端之后就会看到混乱的数据。
仿小红书源码的技术重点,最终会落到内容流、搜索流、互动流、消息流和订单流这几条链路上。只要这几条链路设计不清楚,功能越多,问题出现得越快。