EXISTS谓词
1、理论
1.1、什么时谓词
SQL的保留字中,有很多被归为谓词一类。例如,"=、<、>"等比较谓词,以及BETWEEN、LIKE、IN、ISNULL等。在写SQL语句时我们几乎离不开这些谓词,那么到底什么是谓词呢?几乎每天都在用,但是突然被问起来时却答不上来的人应该不少吧。当然,我们说的谓词和主语/谓语中的谓语,以及英语中的动词是不一样的。
实际上,谓词是一种特殊的函数,其返回值是真值。前面提到的每个谓词,返回值都是 true、false或者 unknown(一般的谓词逻辑里没有 unknown,但是SQL采用的是三值逻辑,因此具有三种真值)。
谓词逻辑提供谓词是为了判断命题(可以理解成陈述句)的真假。例如,我们假设存在"x是男的"这样的谓词,那么我们只要指定x为"小明"或者"小红",就能判断命题"小明是男的""小红是男的"是真命题还是假命题。在谓词逻辑出现之前,命题逻辑中并没有像这样能够深入调查命题内部的工具。谓词逻辑的出现具有划时代的意义,原因就在于为命题分析提供了函数式的方法。
在关系数据库里,表中的一行数据可以看作一个命题。
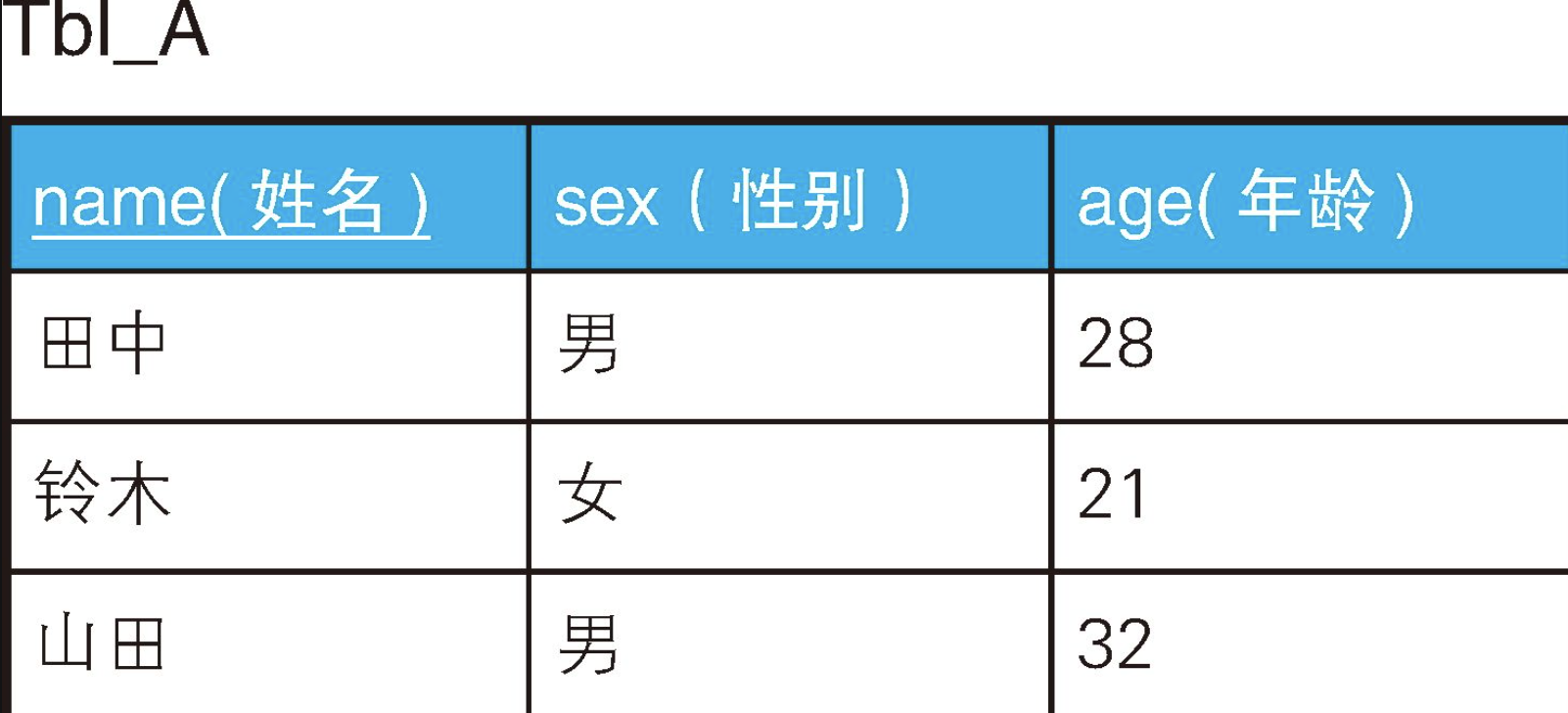
例如,这张表里第一行数据就可以认为表示这样一个命题:田中性别是男,而且年龄是28岁。表常常被认为是行的集合,但从谓词逻辑的观点看,也可以认为它是命题的集合(=陈述句的集合)。
同样,我们平时使用的WHERE子句,其实也可以看成由多个谓词组合而成的新谓词。只有能让WHERE子句的返回值为真的命题,才能从表(命题的集合)中查询到。
1.2、实体的阶层
同样是谓词,但是与 =、BETWEEN等相比,EXISTS的用法还是大不相同的。概括来说,区别在于"谓词的参数可以取什么值"。
"x = y"或"x BETWEEN y"等谓词可以取的参数是像"13"或者"本田"这样的单一值,我们称之为标量值。而EXISTS可以取的参数究竟是什么呢?从下面这条SQL语句来看,EXISTS的参数不像是单一值。
sql
SELECT id
FROM Foo F
WHERE EXISTS (
SELECT *
FROM Bar B
WHERE F.id=B.id
);不过,看不出来也不用苦恼。因为如果有人问SUM()函数的参数是什么,我们只要看一下括号里的内容就知道了。同样地,看一下EXISTS()的括号中的内容,我们就能知道它的参数是什么。现在再看上面的SQL语句,就能知道它的参数是下面这样一条SELECT子句。
sql
SELECT *
FROM Bar B
WHERE A.id = T2.id换言之,参数是行数据的集合。之所以这么说,是因为无论子查询中选择什么样的列,对于EXISTS来说都是一样的。在EXISTS的子查询里,SELECT子句的列表可以有下面这三种写法。
- 通配符:
SELECT * - 常量:
SELECT '这里的内容任意' - 列名:
SELECT col
但是,不管采用上面这三种写法中的哪一种,得到的结果都是一样的。
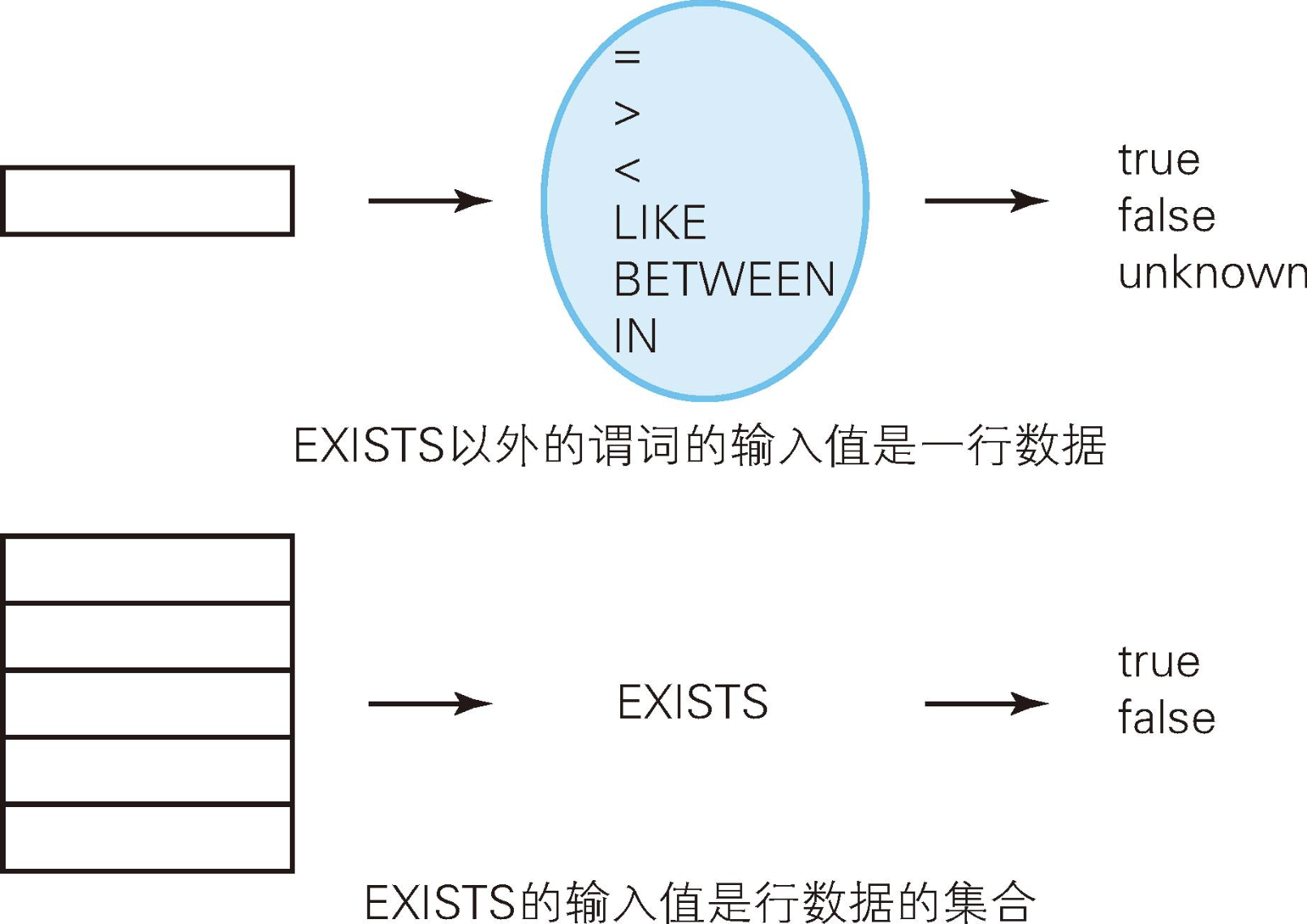
从上图和前文我们可以知道,EXISTS的特殊性在于输入值的阶数(输出值和其他谓词一样,都是真值)。
谓词逻辑中,我们可以根据输入值的阶数对谓词进行分类。
=或者BETWEEN等输入值为一行的谓词叫作"一阶谓词"- 而像
EXISTS这样输入值为行的集合的谓词叫作"二阶谓词"。阶(order)是用来区分集合或谓词的阶数的概念。 - 三阶谓词=输入值为"集合的集合"的谓词
- 四阶谓词=输入值为"集合的集合的集合"的谓词
我们可以像上面这样无限地扩展阶数,但是SQL里并不会出现三阶以上的情况,所以不用太在意。
使用过List、Haskell等函数式语言或者Java的可能知道"高阶函数"这一概念。它指的是不以一般的原子性的值为参数,而以函数为参数的函数。这里说的"阶"和谓词逻辑里的"阶"是一个意思("阶"的概念原本就源于集合论和谓词逻辑)。
EXISTS因接受的参数是集合这样的一阶实体(entity)而被称为二阶谓词,但是谓词也是函数的一种,因此我们也可以说EXISTS是高阶函数。
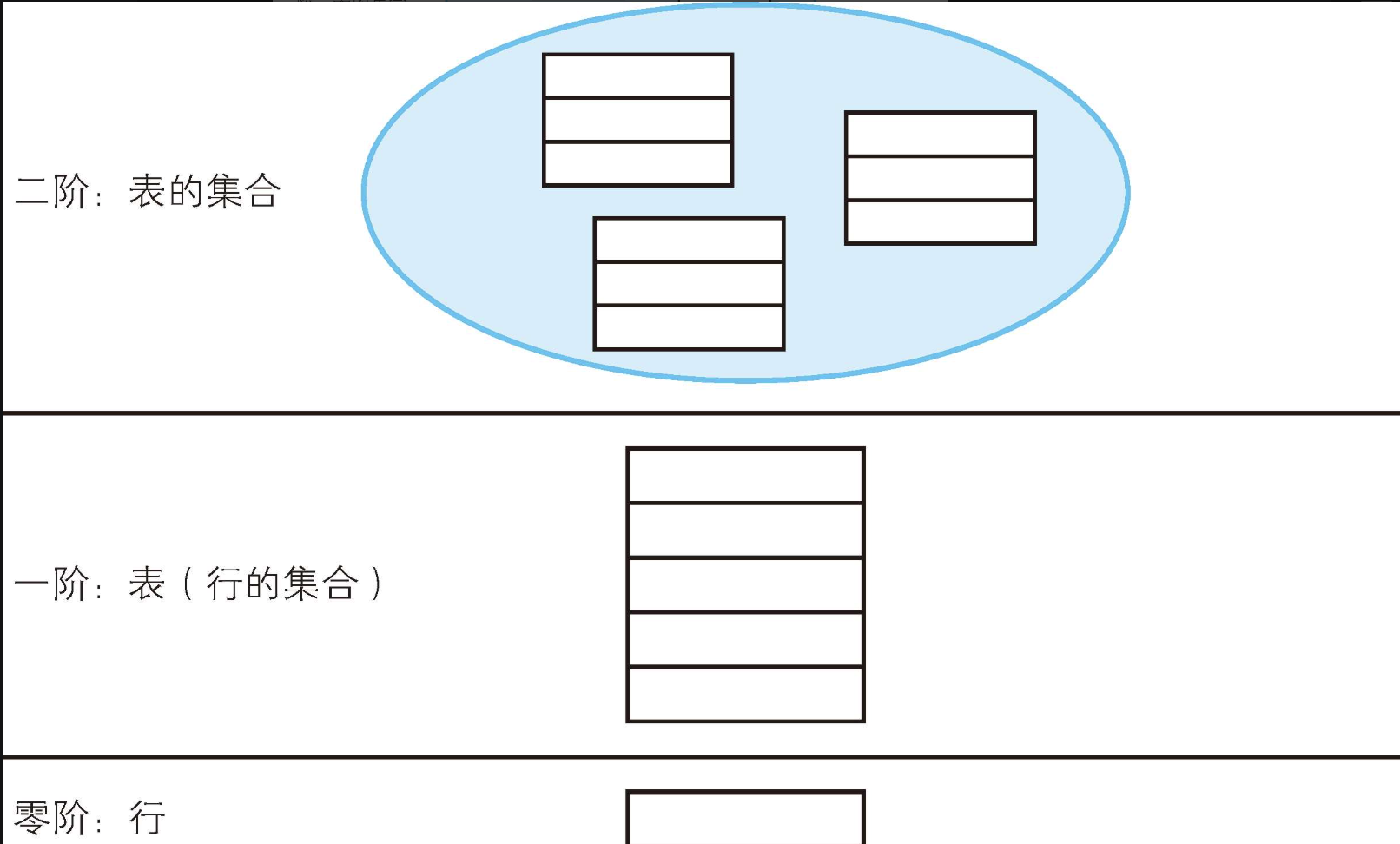
SQL中采用的是狭义的"一阶谓词逻辑",这是因为SQL里的EXISTS谓词最高只能接受一阶的实体作为参数。如果想要支持二阶、三阶等更高阶的实体,SQL必须提供相应的支持。理论上这也是可以做到的,只是目前还没有实现。
如果将来SQL能支持二阶谓词逻辑,那么我们就能对表进行量化。正如C.J.戴特所说插图,现在的SQL只能进行"是否存在包含供应商S1的行?"这样的查询,而如果能支持二阶谓词逻辑,那么就能够表达更复杂的查询,比如"是否存在包含供应商S1的表?"等。这样一来,SQL的查询能力就能提升一个等级。到那时,SQL作为一门编程语言将有质的飞跃。
1.3、全称量化和存在量化
从这些我们可以知道,形式语言没必要同时显式地支持EXISTS和FORALL两者。但是实际上,我们希望这两者能同时获得支持,因为有些问题适合使用EXISTS来解决,而有的问题适合使用FORALL。
例如,SQL支持EXISTS,但不支持FORALL,于是会有一些查询只能选择用EXISTS,那么代码写起来就会非常麻烦。
谓词逻辑中有量词(限量词、数量词)这类特殊的谓词。我们可以用它们来表达一些这样的命题:
- 所有的 x都满足条件P
- 存在(至少一个)满足条件P的 x。
前者称为"全称量词",后者称为"存在量词"。
也许大家已经明白了,SQL中的EXISTS谓词实现了谓词逻辑中的存在量词。然而遗憾的是,对于与本节核心内容有关的另一个全称量词,SQL却并没有予以实现。C.J.戴特在自己的书里写了FORALL谓词,但实际上SQL里并没有这个实现。
但是没有全称量词并不算是SQL的致命缺陷,因为全称量词和存在量词只要定义了一个,另一个就可以被推导出 来。
因此在SQL中,为了表达全称量化,需要将"所有的行都满足条件P"这样的命题转换成"不存在不满足条件P的行"。就像C.J.戴特所说,虽然SQL里有全称量词会很方便,但是既然SQL并没有实现它,我们也就没有办法了。
2、实例
2.1、存在量化:查询表中"不"存在的数据
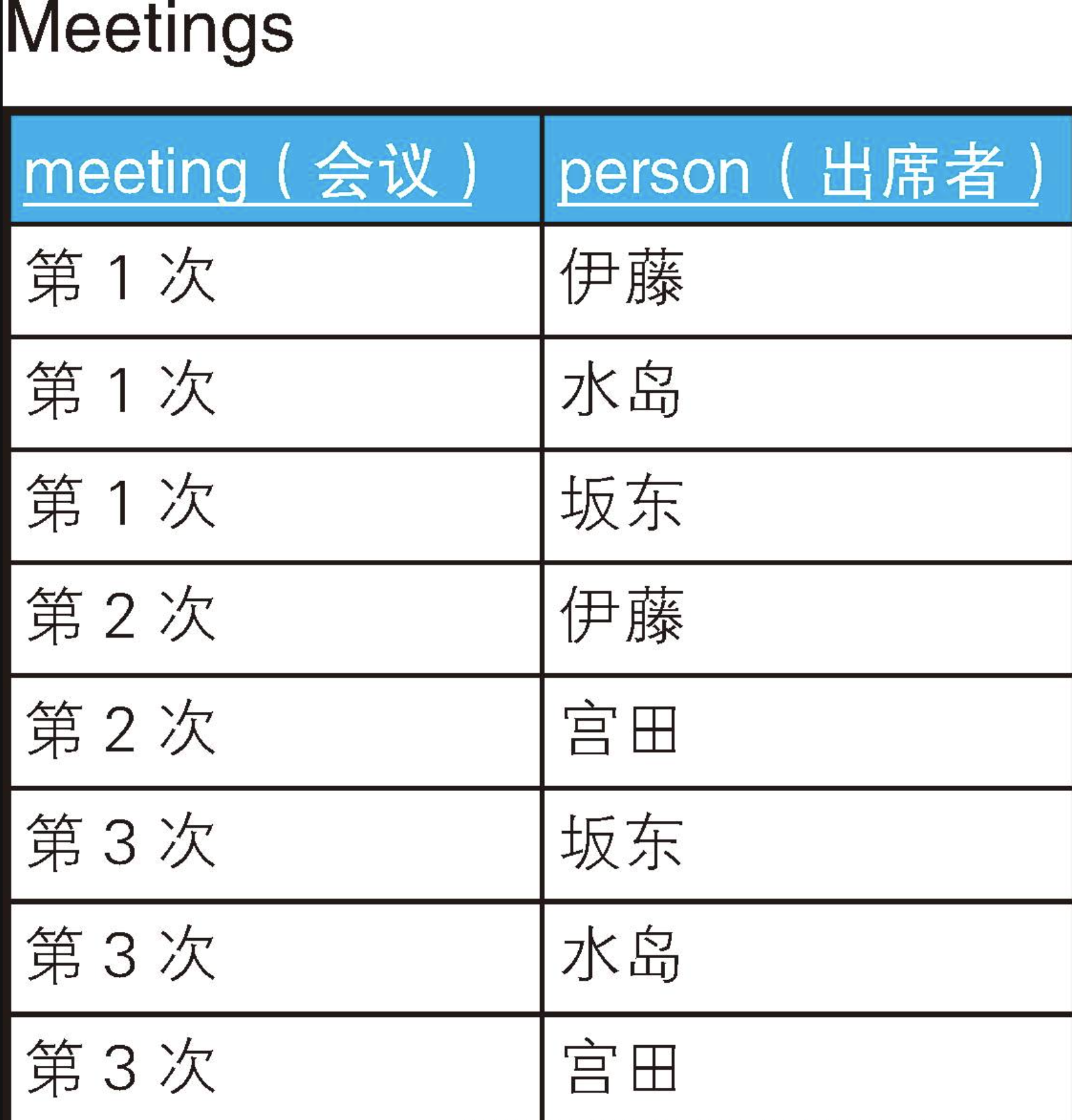
我们从数据库中查询数据时,一般是从表里存在的数据中选出满足某些条件的数据。但是在有些情况下,我们不得不从表中查找出"不存在的数据"。这听起来可能很奇怪,但是这种需求并不算少。例如下面这样的情况,大家是不是也遇到过呢?
sql
CREATE TABLE Meetings (
meeting CHAR(32) NOT NULL,
person CHAR(32) NOT NULL,
PRIMARY KEY (meeting, person)
);
INSERT INTO Meetings VALUES('第1次', '伊藤');
INSERT INTO Meetings VALUES('第1次', '水岛');
INSERT INTO Meetings VALUES('第1次', '坂东');
INSERT INTO Meetings VALUES('第2次', '伊藤');
INSERT INTO Meetings VALUES('第2次', '宫田');
INSERT INTO Meetings VALUES('第3次', '坂东');
INSERT INTO Meetings VALUES('第3次', '水岛');
INSERT INTO Meetings VALUES('第3次', '宫田');显然,从这张表中求出"参加了某次会议的人"是很容易的。但是,如果反过来求"没有参加某次会议的人",该怎么做呢?例如,伊藤参加了第1次会议和第2次会议,但是没有参加第3次会议;坂东没有参加第2次会议。也就是说,目标结果如下所示,是各次会议缺席者的列表(假设没有全部缺席的人)。
sql
meeting person
---------- --------
第 1 次 宫田
第 2 次 坂东
第 2 次 水岛
第 3 次 伊藤我们并不是要根据存在的数据查询"满足这样那样条件"的数据,而是要查询"数据是否存在"。从阶层上来说,这是更高一阶的问题,即所谓的"二阶查询"。这种时候正是EXISTS谓词大显身手的好时机。思路是先假设所有人都参加了全部会议,并以此生成一个集合,然后从中减去实际参加会议的人。这样就能得到缺席会议的人。
所有人都参加了全部会议的集合可以通过下面这样的交叉连接来求得。
sql
SELECT DISTINCT m1.meeting, m2.person
FROM Meetings m1 cross join Meetings m2;
+---------+--------+
| meeting | person |
+---------+--------+
| 第3次 | 伊藤 |
| 第2次 | 伊藤 |
| 第1次 | 伊藤 |
| 第3次 | 坂东 |
| 第2次 | 坂东 |
| 第1次 | 坂东 |
| 第3次 | 水岛 |
| 第2次 | 水岛 |
| 第1次 | 水岛 |
| 第3次 | 宫田 |
| 第2次 | 宫田 |
| 第1次 | 宫田 |
+---------+--------+结果是3(次)× 4(人),一共12行数据。然后,我们从这张表中减掉实际参会者的集合,即表Meetings中存在的组合即可。
sql
-- 求出缺席者的 SQL 语句(1):存在量化的应用
SELECT DISTINCT m1.meeting, m2.person
FROM Meetings m1 cross join Meetings m2
where not exists (
select *
from Meetings m3
where m1.meeting = m3.meeting and m2.person = m3.person
);
+---------+--------+
| meeting | person |
+---------+--------+
| 第3次 | 伊藤 |
| 第2次 | 坂东 |
| 第2次 | 水岛 |
| 第1次 | 宫田 |
+---------+--------+如上所示,我们的需求被直接翻译成了SQL语句,意思很好理解。这道例题还可以用集合论的方法来解答,即像下面这样使用差集运算。
sql
-- 求出缺席者的 SQL 语句(2):使用差集运算
SELECT M1.meeting, M2.person
FROM Meetings M1, Meetings M2
EXCEPT
SELECT meeting, person
FROM Meetings;通过以上两条SQL语句的比较,我们可以明白,NOTEXISTS直接具备了差集运算的功能。
2.2、全称量化:习惯"肯定双重否定"之间的转换
接下来,我们练习一下如何使用EXISTS谓词来表达全称量化。这是EXISTS的用法中很具有代表性的一个用法。通过这一部分内容的学习,希望大家能习惯从全称量化"所有的行都 ××"到其双重否定"不 ×× 的行一行都不存在"的转换。
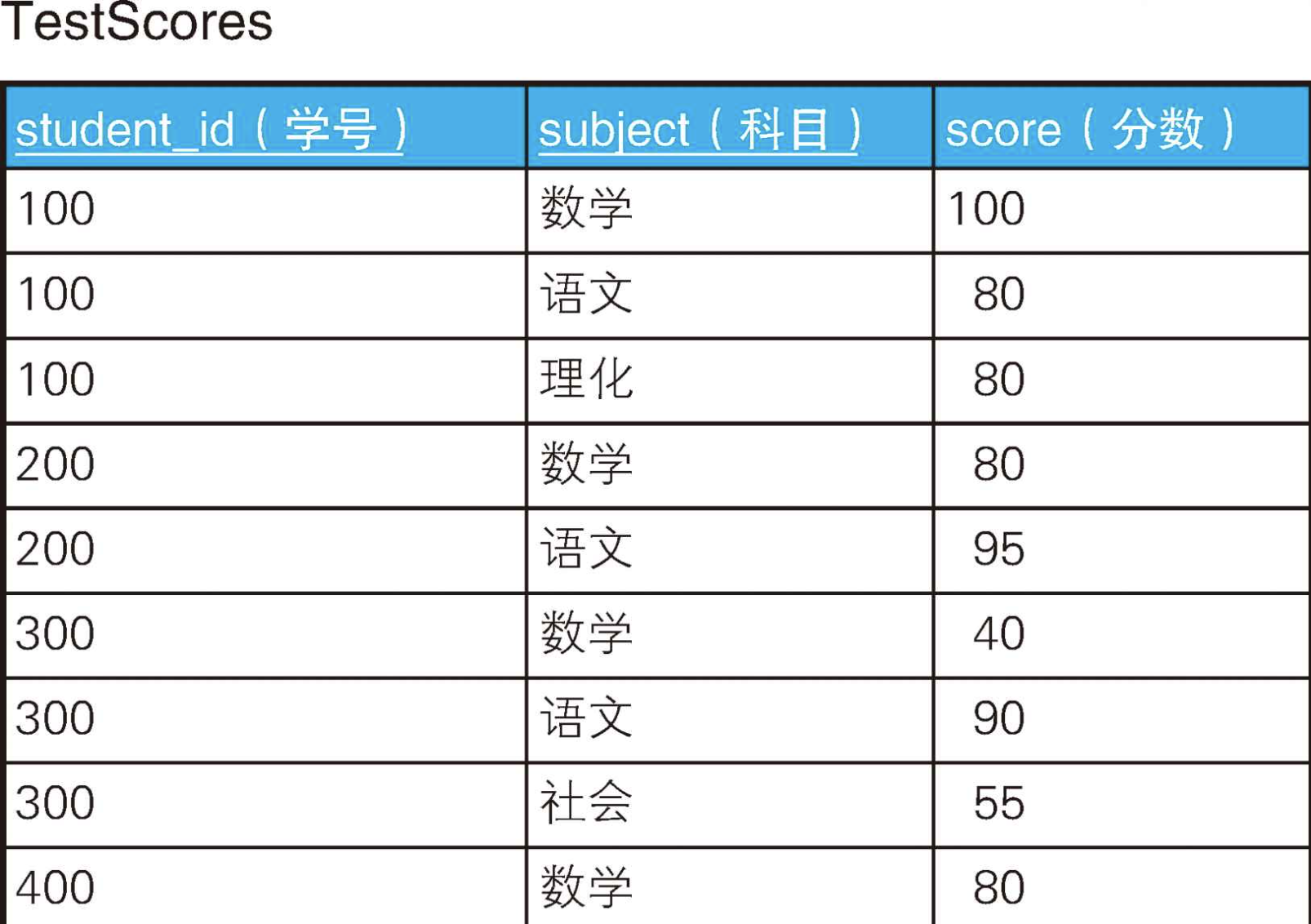
sql
CREATE TABLE TestScores (
student_id INTEGER,
subject VARCHAR(32) ,
score INTEGER,
PRIMARY KEY(student_id, subject)
);
INSERT INTO TestScores VALUES(100, '数学',100);
INSERT INTO TestScores VALUES(100, '语文',80);
INSERT INTO TestScores VALUES(100, '理化',80);
INSERT INTO TestScores VALUES(200, '数学',80);
INSERT INTO TestScores VALUES(200, '语文',95);
INSERT INTO TestScores VALUES(300, '数学',40);
INSERT INTO TestScores VALUES(300, '语文',90);
INSERT INTO TestScores VALUES(300, '社会',55);
INSERT INTO TestScores VALUES(400, '数学',80);我们先来看一个简单的问题:请查询出所有科目分数都在50分以上的学生。答案是学号分别为100、200、400的3人。学号为300的学生语文和社会两科目都在50分以上,但是数学考了40分,所以不符合条件。
解法是,将查询条件所有科目分数都在50分以上 转换成它的双重否定没有一个科目分数不满50分,然后用NOT EXISTS来表示转换后的命题。
sql
select distinct student_id
from TestScores ts1
where not exists ( -- 不存在满足以下条件的行
select *
from TestScores ts2
where ts2.student_id = ts1.student_id
and ts2.score < 50 -- 分数不满50分的科目
);
+------------+
| student_id |
+------------+
| 100 |
| 200 |
| 400 |
+------------+接下来,我们把条件改得复杂一些再试试。请思考一下如何查询出满足下列条件的学生。
- 数学的分数在80分以上。
- 语文的分数在50分以上。
结果应该是学号分别为100、200、400的学生。这里,学号为400的学生没有语文分数的数据,但是也需要包含在结果里。像这样的需求,我们在实际业务中应该会经常遇到,但是乍一看可能会觉得它不太像是全称量化的条件。
如果改成下面这样的说法,大家可能一下子就能明白它是全称量化的命题了。
某个学生的所有行数据中,如果科目是数学,则分数在80分以上;如果科目是语文,则分数在50分以上。"
没错,这其实是针对同一个集合内的行数据进行了条件分支后的全称量化。SQL语句本身是支持根据不同行表示条件分支的,例如可以通过下页这个具有两个条件分支的CASE表达式来表示条件分支。
sql
CASE WHEN subject = '数学' AND score >= 80 THEN 1
WHEN subject = '语文' AND score >= 50 THEN 1
ELSE 0 END对于满足条件的行,该CASE表达式会返回1,否则返回0。这可以看作是在创建一个判断某行是否满足条件的函数。实际上,这确实也是一种"特征函数"。特征函数的相关内容会在下一节中详细介绍。言归正传,接下来,我们只需要像下面这样把语句里的条件反过来就可以了。
sql
select distinct student_id
from TestScores ts1
where subject in ('数学', '语文')
and not exists (
select *
from TestScores ts2
where ts2.student_id = ts1.student_id
and 1 = case when subject = '数学' and score < 80 then 1
when subject = '语文' and score < 50 then 1
else 0 end
);
+------------+
| student_id |
+------------+
| 100 |
| 200 |
| 400 |
+------------+这里解释一下这段代码。首先,数学和语文之外的科目不在我们考虑范围之内,所以通过IN条件过滤一下。然后,通过子查询来描述"数学80分以上,语文50分以上"这个条件。
接下来,我们思考一下如何排除掉没有语文分数的学号为400的学生。这里,学生必须两门科目都有分数才行,所以我们可以加上用于判断行数的HAVING子句来实现。
sql
select distinct student_id
from TestScores ts1
where subject in ('数学', '语文')
and not exists (
select *
from TestScores ts2
where ts2.student_id = ts1.student_id
and 1 = case when subject = '数学' and score < 80 then 1
when subject = '语文' and score < 50 then 1
else 0 end
)
group by student_id
having count(*) = 2;
+------------+
| student_id |
+------------+
| 100 |
| 200 |
+------------+像上面这样简单地修改一下就可以了。请注意,这里已经以学号为列进行了聚合,所以SELECT子句里的DISTINCT就不需要了。
更加简单取巧的写法:
sql
SELECT student_id
FROM TestScores
WHERE (subject = '数学' AND score >= 80)
OR (subject = '语文' AND score >= 50)
GROUP BY student_id
HAVING COUNT(DISTINCT subject) = 2;
+------------+
| student_id |
+------------+
| 100 |
| 200 |
+------------+2.3、全称量化:集合与谓词------哪个更强大
下面继续练习全称量化。EXISTS和HAVING有一个地方很像,即都是以集合而不是个体为单位来操作数据的。实际上,两者在很多情况下是可以互换的,用其中一个写出的查询语句,大多时候也可以用另一个来写。接下来,我们通过比较来了解一下它们各自的优点和缺点。
假设存在下面这样的项目工程管理表。
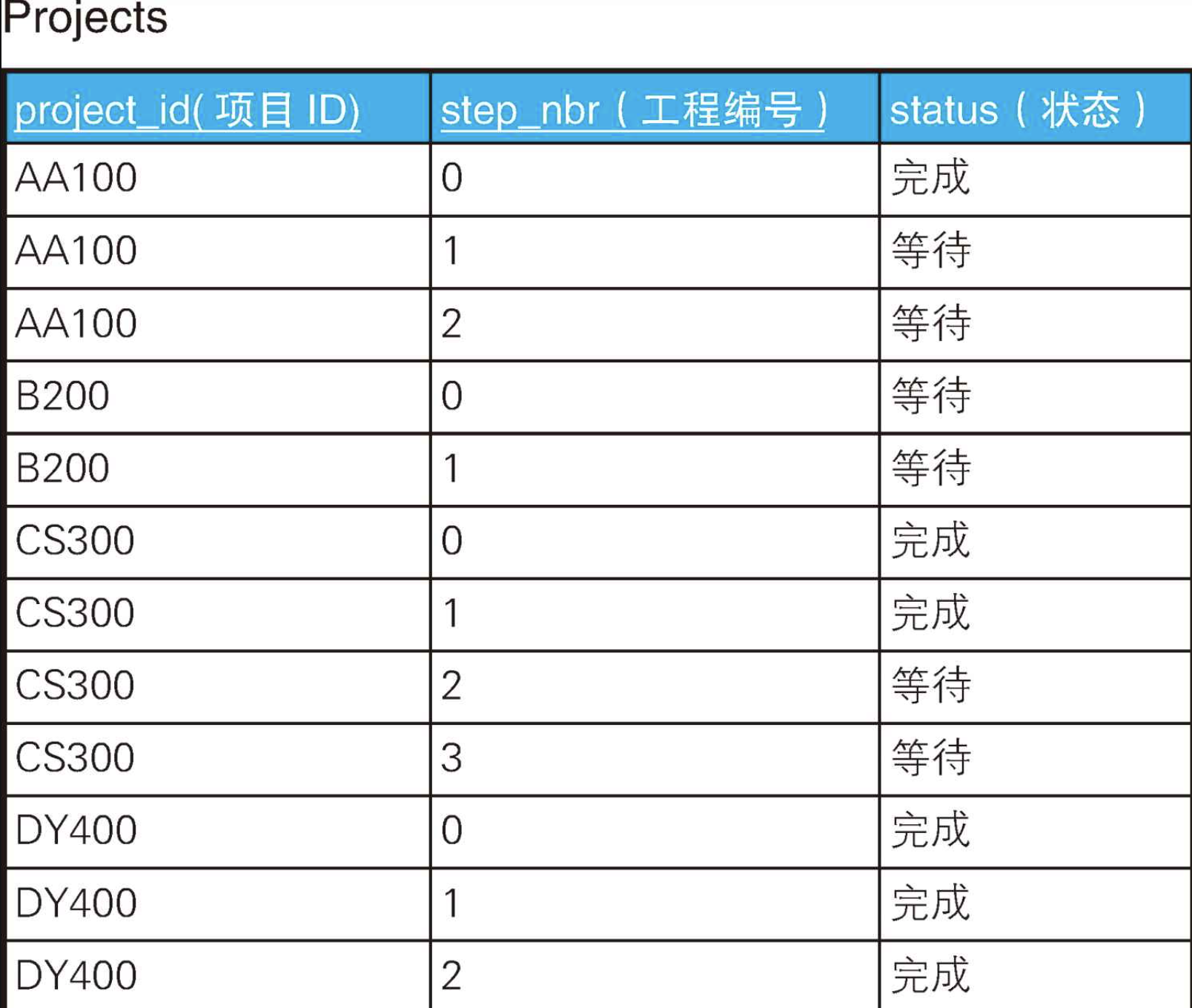
sql
CREATE TABLE Projects (
project_id VARCHAR(32),
step_nbr INTEGER ,
status VARCHAR(32),
PRIMARY KEY(project_id, step_nbr)
);
INSERT INTO Projects VALUES('AA100', 0, '完成');
INSERT INTO Projects VALUES('AA100', 1, '等待');
INSERT INTO Projects VALUES('AA100', 2, '等待');
INSERT INTO Projects VALUES('B200', 0, '等待');
INSERT INTO Projects VALUES('B200', 1, '等待');
INSERT INTO Projects VALUES('CS300', 0, '完成');
INSERT INTO Projects VALUES('CS300', 1, '完成');
INSERT INTO Projects VALUES('CS300', 2, '等待');
INSERT INTO Projects VALUES('CS300', 3, '等待');
INSERT INTO Projects VALUES('DY400', 0, '完成');
INSERT INTO Projects VALUES('DY400', 1, '完成');
INSERT INTO Projects VALUES('DY400', 2, '完成');这张表的主键是"项目ID,工程编号"。工程编号从0开始,我们不妨认为0号是需求分析,1号是基本设计......虽然这张表中的工程编号最大只到3,但是有可能也会有4及以后的编号。已经完成的工程,其状态列的值是"完成";等待上一个工程完成的工程,其状态列的值是"等待"。
这里的问题是,要从这张表中查询出哪些项目已经完成到了工程1。我们明显可以看出,只完成到工程0的项目AA100和还没有开始的项目B200不符合条件,而项目CS300符合条件。项目DY400已经完成到了工程2,是否符合条件有点微妙,我们先按它不符合条件来实现。
sql
-- 查询完成到了工程 1 的项目:面向集合的解法
SELECT project_id
FROM Projects
GROUP BY project_id
HAVING COUNT(*) = SUM(CASE WHEN step_nbr <= 1 AND status = '完成' THEN 1
WHEN step_nbr > 1 AND status = '等待' THEN 1
ELSE 0 END);
+------------+
| project_id |
+------------+
| CS300 |
+------------+因为这里的重点不是讲解HAVING子句,所以就不通过维恩图去分析了。下面简单地解释一下这段代码:针对每个项目,将工程编号为1以下且状态为"完成"的行数,和工程编号大于1且状态为"等待"的行数加在一起,如果它们的和等于该项目数据的总行数,则该项目符合查询条件。
那么,这道例题用谓词逻辑该如何解决呢?其实这道例题也能看作全称量化的一个特例。与上一道例题相比,这道例题稍微复杂一点,但是思路是一样的。请把查询条件看作下面这样的全称量化命题。
某个项目的所有行数据中,如果工程编号是1以下,则该工程已完成;如果工程编号比1大,则该工程还在等待
这个条件仍然可以用CASE表达式来描述。
sql
step_status = CASE WHEN step_nbr <= 1
THEN '完成'
ELSE '等待' END最终的SQL语句会采用上面这个条件的否定形式,因此代码如下所示。
sql
-- 查询完成到了工程 1 的项目:谓词逻辑的解法
SELECT *
FROM Projects P1
WHERE NOT EXISTS (
SELECT status
FROM Projects P2
WHERE P1.project_id = P2. project_id -- 以项目为单位进行条件判断
AND status <> CASE WHEN step_nbr <= 1 -- 使用双重否定来表达全称量化命题
THEN '完成'
ELSE '等待' END);
+------------+----------+--------+
| project_id | step_nbr | status |
+------------+----------+--------+
| CS300 | 0 | 完成 |
| CS300 | 1 | 完成 |
| CS300 | 2 | 等待 |
| CS300 | 3 | 等待 |
+------------+----------+--------+虽然两者都能表达全称量化,但是与HAVING相比,使用了双重否定的NOT EXISTS的代码看起来不是那么容易理解,这是它的缺点。但是这种写法也有优点。第一个优点是性能好。只要有一行满足条件,查询就会终止,不一定需要查询所有行的数据。而且还能通过连接条件使用project_id列的索引,这样查询起来会更快。第二个优点是结果里能包含的信息量更大。如果使用HAVING,结果会被聚合,我们最多能获取项目ID,而如果使用NOTEXISTS,则能获取集合里的所有元素。
2.4、对列进行量化:查询全是1的行
不好的表在设计上一般会存在一些典型的问题。例如没有主键且允许重复的行存在,或者是完全忽略掉列应该作为"属性"来定义的这个习惯,让某一列拥有了多个含义。还有一种是像下面这样只是单纯地存储了数组的表。对于这样的表,数据库工程师看到就会忍不住叹一口气:"啊,怎么又来了!"
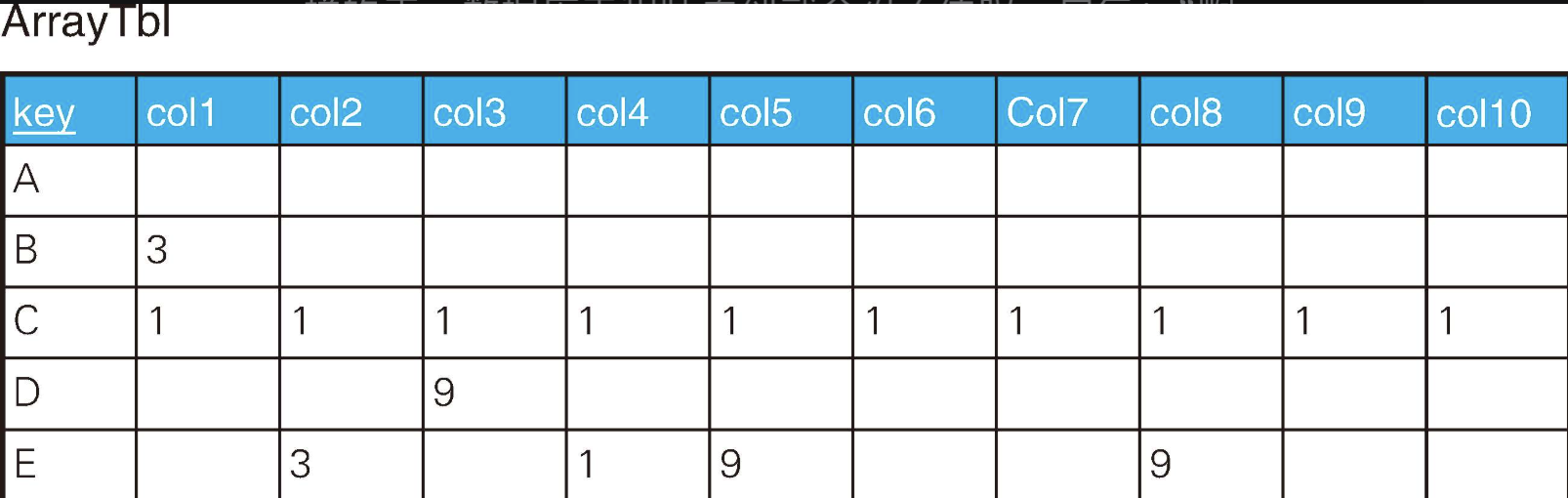
sql
CREATE TABLE ArrayTbl (
keycol CHAR(1) PRIMARY KEY,
col1 INTEGER,
col2 INTEGER,
col3 INTEGER,
col4 INTEGER,
col5 INTEGER,
col6 INTEGER,
col7 INTEGER,
col8 INTEGER,
col9 INTEGER,
col10 INTEGER
);
-- 都是NULL
INSERT INTO ArrayTbl VALUES('A', NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL);
INSERT INTO ArrayTbl VALUES('B', 3, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL);
-- 都是1
INSERT INTO ArrayTbl VALUES('C', 1, 1, 1, 1, 1, 1, 1, 1, 1, 1);
-- 至少有一个9
INSERT INTO ArrayTbl VALUES('D', NULL, NULL, 9, NULL, NULL, NULL, NULL, NULL, NULL, NULL);
INSERT INTO ArrayTbl VALUES('E', NULL, 3, NULL, 1, 9, NULL, NULL, 9, NULL, NULL);说这张表的设计不好的原因是,数组中的元素可以自由地增加或者减少,而表中的列却不能这样。即便只是增加或减少1列,都非常麻烦。相反,行的增加或者减少却对系统几乎没有什么影响。因此在设计表时有一条原则:让列具有一定的扩展性。数组中的元素不应该对应表中的列,而是应该对应行。
如果你能理解"表是对现实世界中的实体的抽象"这一关系模型理论,很自然就会明白这种思考方式。如果只是生成上面这样的表,那么使用SQL:1999中引入的数组类型也不失为一个办法。
好了,就算我们盯着有问题的表发牢骚,它也不会变得好起来。如果不能改变表的结构,那么接受这一点并继续想其他办法才是有意义的。
在使用这种模拟数组的表时遇到的需求一般是下面这两种形式。
- 查询"都是1"的行。
- 查询"至少有一个9"的行。
EXISTS谓词主要用于进行"行方向"的量化,而对于这个问题,我们需要进行"列方向"的量化。虽然这里不能用EXISTS,但是实际上可以像下面这样解决。
sql
--"列方向"的全称量化:不优雅的解法
SELECT *
FROM ArrayTbl
WHERE col1 = 1
AND col2 = 1
·
·
·
AND col10 = 1;这种解法不是很优雅(但是也没有错),还可以改进。只有10列的话还可以忍受,如果增加到50列、100列,那么这种SQL语句就会变得太长而让人难以阅读。但是不用担心,SQL语言其实还准备了一个谓词,帮助我们进行"列方向"的量化。
sql
-- "列方向"的全称量化:优雅的解法
select *
from ArrayTb1
where 1 = all(col1, col2, col3, col4, col5, col6, col7, col8, col9, col10);在PostgreSQL或MySQL中,ALL谓词和ANY谓词只可以用于子查询,所以这段代码执行时会发生语法错误。PostgreSQL中可以对数组类型使用ALL谓词,因此代码可以正常执行。
这条SQL语句将"col1 ~ col10的全部列都是1"这个全称量化命题直接翻译成了SQL语句,既简洁又很好理解。
反过来,如果想表达"至少有一个9"这样的存在量化命题,可以使用ALL的反义谓词ANY。
sql
SELECT *
FROM ArrayTbl
WHERE 9 = ANY (col1, col2, col3, col4, col5, col6, col7, col8, col9, col10);或者也可以使用IN谓词代替ANY。
sql
SELECT *
FROM ArrayTbl
WHERE 9 IN (col1, col2, col3, col4, col5, col6, col7, col8, col9, col10);人们一般是像col1 IN (1, 2, 3)这样来使用IN谓词的,左边是列名,右边是值的列表。可能有人不太习惯前面那种左右颠倒了的写法,但是其实这种写法也是被允许的。
但是,如果左边不是具体值而是NULL,这种写法就不行了。
sql
-- 查询全是 NULL 的行:错误的解法
SELECT *
FROM ArrayTbl
WHERE NULL = ALL (col1, col2, col3, col4, col5, col6, col7, col8, col9, col10);不管表里的数据是什么样的,这条SQL语句的查询结果都是空。这是因为,ALL谓词会被解释成col1 = NULL AND col2 = NULL AND ... col10 = NULL。这种情况下,我们需要使用COALESCE函数。
sql
-- 查询全是 NULL 的行:正确的解法
SELECT *
FROM ArrayTbl
WHERE COALESCE(col1, col2, col3, col4, col5, col6, col7, col8, col9, col10)IS NULL;3、案例
3.1、数组表------行结构表
i列表示数组的下标,因此主键是"key, i"。
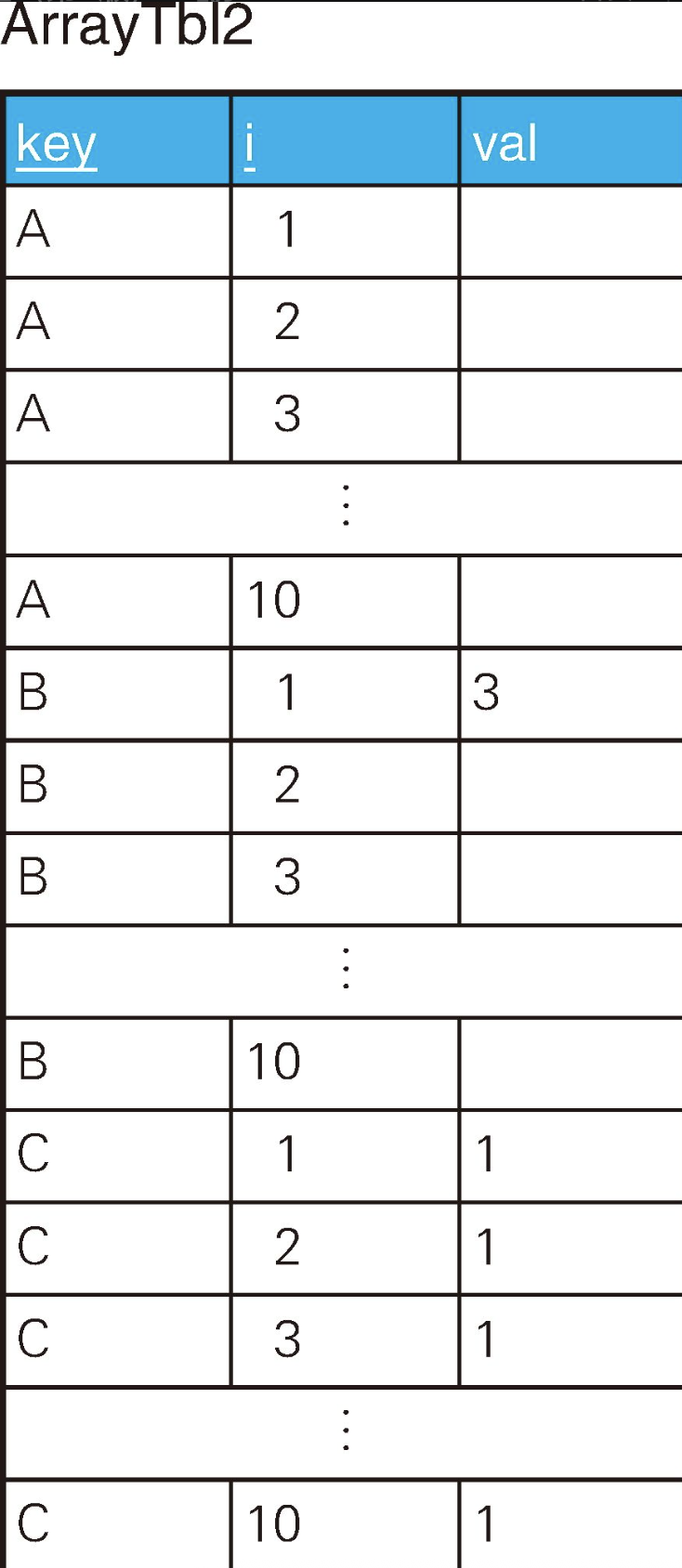
sql
CREATE TABLE ArrayTbl2 (
`key` CHAR(1) NOT NULL,
i INTEGER NOT NULL,
val INTEGER,
PRIMARY KEY (`key`, i)
);
/* A全为NULL、B仅有一个为非NULL、C全为非NULL */
INSERT INTO ArrayTbl2 VALUES('A', 1, NULL);
INSERT INTO ArrayTbl2 VALUES('A', 2, NULL);
INSERT INTO ArrayTbl2 VALUES('A', 3, NULL);
INSERT INTO ArrayTbl2 VALUES('A', 4, NULL);
INSERT INTO ArrayTbl2 VALUES('A', 5, NULL);
INSERT INTO ArrayTbl2 VALUES('A', 6, NULL);
INSERT INTO ArrayTbl2 VALUES('A', 7, NULL);
INSERT INTO ArrayTbl2 VALUES('A', 8, NULL);
INSERT INTO ArrayTbl2 VALUES('A', 9, NULL);
INSERT INTO ArrayTbl2 VALUES('A',10, NULL);
INSERT INTO ArrayTbl2 VALUES('B', 1, 3);
INSERT INTO ArrayTbl2 VALUES('B', 2, NULL);
INSERT INTO ArrayTbl2 VALUES('B', 3, NULL);
INSERT INTO ArrayTbl2 VALUES('B', 4, NULL);
INSERT INTO ArrayTbl2 VALUES('B', 5, NULL);
INSERT INTO ArrayTbl2 VALUES('B', 6, NULL);
INSERT INTO ArrayTbl2 VALUES('B', 7, NULL);
INSERT INTO ArrayTbl2 VALUES('B', 8, NULL);
INSERT INTO ArrayTbl2 VALUES('B', 9, NULL);
INSERT INTO ArrayTbl2 VALUES('B',10, NULL);
INSERT INTO ArrayTbl2 VALUES('C', 1, 1);
INSERT INTO ArrayTbl2 VALUES('C', 2, 1);
INSERT INTO ArrayTbl2 VALUES('C', 3, 1);
INSERT INTO ArrayTbl2 VALUES('C', 4, 1);
INSERT INTO ArrayTbl2 VALUES('C', 5, 1);
INSERT INTO ArrayTbl2 VALUES('C', 6, 1);
INSERT INTO ArrayTbl2 VALUES('C', 7, 1);
INSERT INTO ArrayTbl2 VALUES('C', 8, 1);
INSERT INTO ArrayTbl2 VALUES('C', 9, 1);
INSERT INTO ArrayTbl2 VALUES('C',10, 1);一个实体对应10行数据,所以上面的表省略了一部分以方便显示。A、B、C的元素和正文中是一样的。key为A的行val全都是NULL,key为B的行中只有i=1的行val是3,其他的都是NULL,key为C的行val全部都是1。
请思考一下如何从这张表中选出val全是1的key。答案是C。这次,我们要按"行方向"进行全称量化,所以使用EXISTS谓词。严格来说,这个问题还是相当复杂的,如果能注意到问题在哪里,那你就是高级水平了。
sql
select distinct `key`
from ArrayTbl2 a
where not exists (
select *
from ArrayTbl2 b
where a.`key` = b.`key`
and (val != 1 or b.val is null)
);
-> ^I^I^I^I^I^I^I^IELSE '等待' END);
+-----+
| key |
+-----+
| C |
+-----+
-- 其他解法1 :使用ALL谓词
SELECT DISTINCT key
FROM ArrayTbl2 A1
WHERE 1 = ALL (
SELECT val
FROM ArrayTbl2 A2
WHERE A1.key = A2.key
);
-- 其他解法2 :使用HAVING子句
SELECT `key`
FROM ArrayTbl2
GROUP BY `key`
HAVING SUM(CASE WHEN val = 1 THEN 1 ELSE 0 END) = 10;
-- 其他解法3 :在HAVING子句中使用极值函数
SELECT `key`
FROM ArrayTbl2
GROUP BY `key`
HAVING MAX(val) = 1
AND MIN(val) = 1;3.2、求质数
质数是自然数的一种,它的定义是除了1和它自身之外不存在正约数(也就是说,除了1和它自身之外不能被任何自然数除尽)且大于1的自然数。
虽然质数的定义很简单,但是由于它有很多有趣的性质,所以长期以来都吸引着很多人来研究。那么请用SQL求一下质数。因为质数有无限多个,所以这里把范围限定在100以内。我们先准备一张存储了1 ~ 100的所有自然数的表Numbers。
如果把100以内的质数从小到大排列出来,那么就是下面这些。请用SQL求出它们。
2, 3, 5, 7, 11, 13, 17,..., 83, 89, 97
sql
CREATE TABLE Digits (
digit INTEGER PRIMARY KEY
);
INSERT INTO Digits VALUES (0);
INSERT INTO Digits VALUES (1);
INSERT INTO Digits VALUES (2);
INSERT INTO Digits VALUES (3);
INSERT INTO Digits VALUES (4);
INSERT INTO Digits VALUES (5);
INSERT INTO Digits VALUES (6);
INSERT INTO Digits VALUES (7);
INSERT INTO Digits VALUES (8);
INSERT INTO Digits VALUES (9);
DROP TABLE Numbers;
CREATE TABLE Numbers AS
SELECT D1.digit + (D2.digit * 10) AS num
FROM Digits D1 CROSS JOIN Digits D2
WHERE D1.digit + (D2.digit * 10) BETWEEN 1 AND 100;
sql
-- 解法:用NOT EXISTS表达全称量化
SELECT num AS prime
FROM Numbers AS Dividend
WHERE num > 1
AND NOT EXISTS (
SELECT *
FROM Numbers AS Divisor
WHERE Divisor.num <= Dividend.num / 2
AND Divisor.num <> 1
AND MOD(Dividend.num, Divisor.num) = 0)
ORDER BY prime;
+-------+
| prime |
+-------+
| 2 |
| 3 |
| 5 |
| 7 |
| 11 |
| 13 |
| 17 |
| 19 |
| 23 |
| 29 |
| 31 |
| 37 |
| 41 |
| 43 |
| 47 |
| 53 |
| 59 |
| 61 |
| 67 |
| 71 |
| 73 |
| 79 |
| 83 |
| 89 |
| 97 |
+-------+