
🔥承渊政道: 个人主页
❄️个人专栏: 《C语言基础语法知识》 《数据结构与算法》 《C++知识内容》 《Linux系统知识》 《算法刷题指南》 《测评文章活动推广》 《大模型语言路线学习》 《MySQL数据库学习》
✨逆境不吐心中苦,顺境不忘来时路!✨ 🎬 博主简介:

在Web开发中,数据库几乎是所有业务系统的核心组成部分.无论是用户登录、文章发布、订单查询,还是后台管理,本质上都离不开程序对数据库的访问.而对于初学者来说,MySQL不只是"会写几条查询语句"这么简单,更重要的是理解一次网站请求从浏览器发出后,数据是如何经过服务端、连接数据库、执行操作并最终返回结果的.本文将围绕 MySQL 数据库访问这一主线,结合连接池的基本原理,梳理一个简易网站中的数据流动过程.我们会先了解程序为什么需要连接数据库,再说明频繁创建和关闭数据库连接会带来什么问题,进而引出连接池的作用.最后,通过"浏览器/网页 → 服务端 → 连接池 → 数据库 → 响应返回"的流程,帮助你建立一个更完整、更清晰的后端数据访问认知.如果你已经学过一些 MySQL 基础语法,但对"网站到底是怎么用数据库的""连接池为什么能提升性能""一次请求背后发生了什么"还不够清楚,那么这篇文章可以作为一个很好的入门梳理.

目录
- 1.MySQL访问
- [2.MySQL connect](#2.MySQL connect)
- 3.MySQL图形化界面工具访问
- 4.MySQL连接池原理与简易网站数据流动是如何进行的
-
- 4.1为什么需要连接池
- 4.2连接池的基本思想
- 4.3连接池的工作流程
- 4.4连接池中连接的状态
- 4.5连接池的核心参数
- 4.6连接池带来的好处
- 4.7简易网站数据流动过程
- [4.8结合 C API 理解数据库访问流程](#4.8结合 C API 理解数据库访问流程)
- 4.9连接池中的"关闭连接"是什么意思
- 4.10一个简单例子
1.MySQL访问
MySQL访问,简单来说,就是客户端程序通过账号、密码、主机地址和端口连接 MySQL 服务器,然后对数据库进行操作.这里的客户端可以是MySQL命令行工具,也可以是 Java 程序、Python 程序、Navicat、DataGrip 等数据库连接工具.
一次完整的 MySQL 访问通常包含几个关键要素:
text
用户名 + 主机地址 + 密码 + 数据库权限例如:
bash
mysql -uconnector -p这条命令表示使用 connector 用户登录 MySQL,执行后系统会提示输入密码.
1.1创建数据库用户
在MySQL中,用户并不是只由用户名决定,而是由:
sql
'用户名'@'主机'共同决定.
例如下面这条语句创建了一个只能从本机登录的用户:
sql
CREATE USER 'connector'@'localhost' IDENTIFIED BY 'DbConn@2025#X';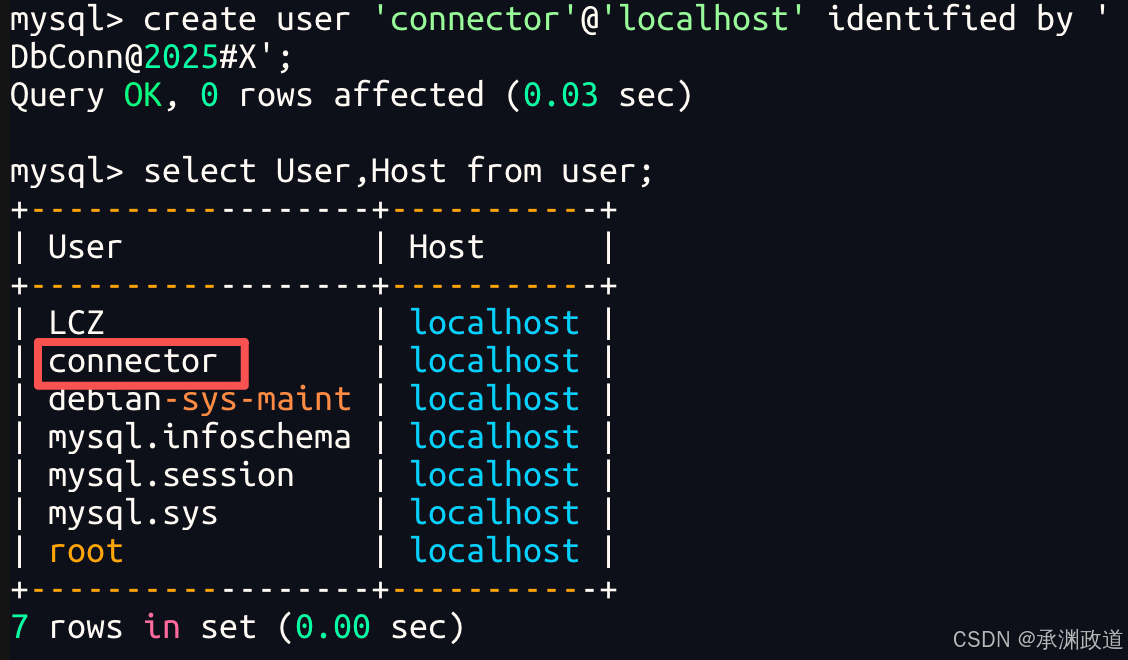
其中:
text
connector 表示用户名
localhost 表示只能从本机连接
DbConn@2025#X 表示登录密码如果写成:
sql
'connector'@'%'则表示允许该用户从任意主机连接 MySQL.
1.2给用户授权
用户创建完成后,默认不一定有操作数据库的权限,所以还需要授权.
例如给 connector 用户授权访问 conn 数据库中的所有表:
sql
GRANT ALL ON conn.* TO 'connector'@'localhost';
含义是:
text
conn.* 表示 conn 数据库下的所有表
ALL 表示拥有所有常用操作权限
connector 表示被授权的用户
localhost 表示该用户从本机登录时生效授权后可以刷新权限:
sql
FLUSH PRIVILEGES;
1.3登录MySQL
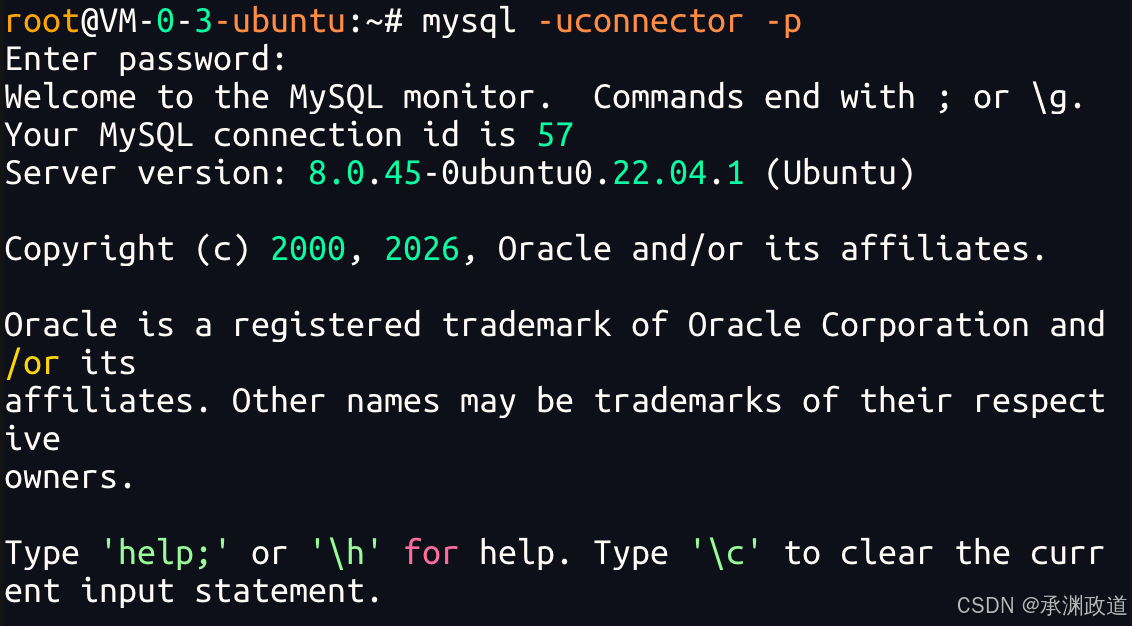
授权完成后,可以使用下面的命令登录:
bash
mysql -uconnector -p输入密码后,如果成功进入:
text
mysql>说明连接 MySQL 成功.
1.4选择数据库并操作数据
登录成功后,可以查看数据库:
sql
SHOW DATABASES;选择要使用的数据库:
sql
USE conn;查看当前数据库中的表:
sql
SHOW TABLES;查询数据:
sql
SELECT * FROM 表名;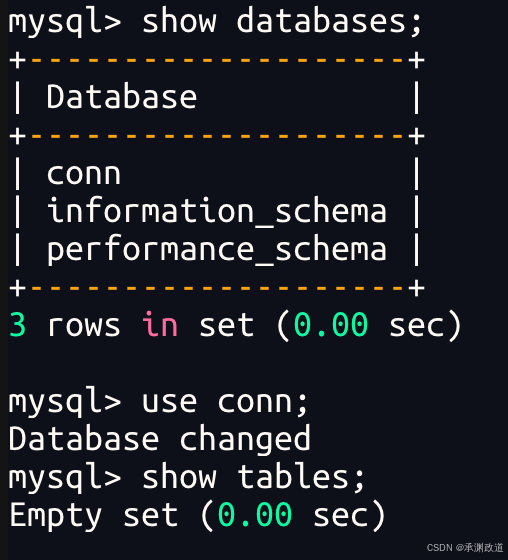
1.5MySQL访问的本质流程
从整体上看,一次 MySQL 访问过程大致如下:
text
客户端发起连接
↓
MySQL验证用户名、主机和密码
↓
检查用户是否有数据库权限
↓
执行SQL语句
↓
返回执行结果也就是说,MySQL访问并不是简单地"输入密码进入数据库",它背后其实经历了身份认证、权限校验、SQL执行和结果返回几个步骤.
MySQL 访问的核心是:先创建用户,再分配权限,最后通过客户端连接数据库并执行 SQL 操作.在实际开发中,程序访问数据库时也遵循同样的流程,只不过命令行操作会变成代码中的数据库连接配置.理解这个过程,有助于后面继续学习 JDBC、数据库连接池以及网站数据流动原理.
2.MySQL connect
MySQL connect 可以理解为:客户端与 MySQL 服务器建立连接.只有连接成功之后,客户端或程序才能继续执行SQL语句,比如查询、插入、修改、删除数据.
mysql的基础,我们之前已经学过,后面我们只关心使用.
要使用C语言连接mysql,需要使用mysql官网提供的库,大家可以去官网下载.
我们使用C接口库来进行连接
要正确使用,我们需要做一些准备工作:
保证mysql服务有效.
在官网上下载合适自己平台的mysql connect库,以备后用.

在命令行中,最常见的连接方式是:
bash
mysql -uconnector -p含义如下:
text
mysql 启动 MySQL 客户端
-uconnector 使用 connector 用户登录
-p 表示需要输入密码执行后会提示输入密码:
text
Enter password:输入正确密码后,如果看到:
text
mysql>说明已经成功连接到 MySQL.
1.指定主机和端口连接
如果 MySQL 不在本机,或者需要明确指定连接地址,可以写成:
bash
mysql -hlocalhost -P3306 -uconnector -p参数说明:
text
-hlocalhost MySQL服务器地址
-P3306 MySQL端口号
-uconnector 用户名
-p 输入密码其中 3306 是 MySQL 默认端口.
2.连接指定数据库
如果要登录后直接进入某个数据库,例如 conn,可以这样写:
bash
mysql -hlocalhost -P3306 -uconnector -p conn连接成功后,相当于已经执行了:
sql
USE conn;3.连接失败的常见原因
用户不存在
例如你创建的是:
sql
'connector'@'localhost'那就只能本机连接.如果你用远程主机连接,可能会失败.
可以查看用户:
sql
SELECT User, Host FROM mysql.user WHERE User = 'connector';密码错误
如果密码输入错误,会出现类似:
text
Access denied for user 'connector'@'localhost'可以重新设置密码:
sql
ALTER USER 'connector'@'localhost' IDENTIFIED BY 'DbConn@2025#X';没有权限
用户能登录,不代表能访问所有数据库.如果访问 conn 数据库,需要授权:
sql
GRANT ALL ON conn.* TO 'connector'@'localhost';
FLUSH PRIVILEGES;4.MySQL 连接的本质流程
一次 MySQL 连接大致经历下面几个步骤:
text
客户端发起连接
↓
指定用户名、主机、端口
↓
MySQL验证账号和密码
↓
检查用户权限
↓
连接成功,进入 mysql> 命令行
↓
执行 SQL 操作MySQL connect 的核心就是:使用指定用户连接到 MySQL 服务器,并通过权限校验后操作数据库.
常用连接命令可以记住这一条:
bash
mysql -hlocalhost -P3306 -uconnector -p如果只是在本机学习,也可以简写为:
bash
mysql -uconnector -p2.1Connector/C使用
我们下载下来的库格式如下:
bash
├── include
│ ├── big_endian.h
│ ├── byte_order_generic.h
│ ├── byte_order_generic_x86.h
│ ├── decimal.h
│ ├── errmsg.h
│ ├── keycache.h
│ ├── little_endian.h
│ ├── m_ctype.h
│ ├── m_string.h
│ ├── my_alloc.h
│ ├── my_byteorder.h
│ ├── my_compiler.h
│ ├── my_config.h
│ ├── my_dbug.h
│ ├── my_dir.h
│ ├── my_getopt.h
│ ├── my_global.h
│ ├── my_list.h
│ ├── my_pthread.h
│ ├── mysql
│ │ ├── client_authentication.h
│ │ ├── client_plugin.h
│ │ ├── client_plugin.h.pp
│ │ ├── get_password.h
│ │ ├── plugin_auth_common.h
│ │ ├── plugin_trace.h
│ │ ├── psi
│ │ │ ├── mysql_file.h
│ │ │ ├── mysql_idle.h
│ │ │ ├── mysql_mdl.h
│ │ │ ├── mysql_memory.h
│ │ │ ├── mysql_ps.h
│ │ │ ├── mysql_socket.h
│ │ │ ├── mysql_sp.h
│ │ │ ├── mysql_stage.h
│ │ │ ├── mysql_statement.h
│ │ │ ├── mysql_table.h
│ │ │ ├── mysql_thread.h
│ │ │ ├── mysql_transaction.h
│ │ │ ├── psi_base.h
│ │ │ ├── psi.h
│ │ │ └── psi_memory.h
│ │ ├── service_my_snprintf.h
│ │ └── service_mysql_alloc.h
│ ├── mysql_com.h
│ ├── mysql_com_server.h
│ ├── mysqld_ername.h
│ ├── mysqld_error.h
│ ├── mysql_embed.h
│ ├── mysql.h
│ ├── mysql_time.h
│ ├── mysql_version.h
│ ├── my_sys.h
│ ├── my_xml.h
│ ├── sql_common.h
│ ├── sql_state.h
│ ├── sslopt-case.h
│ ├── sslopt-longopts.h
│ ├── sslopt-vars.h
│ └── typelib.h
└── lib
├── libmysqlclient.a
├── libmysqlclient_r.a -> libmysqlclient.a
├── libmysqlclient_r.so -> libmysqlclient.so
├── libmysqlclient_r.so.18 -> libmysqlclient.so.18
├── libmysqlclient_r.so.18.3.0 -> libmysqlclient.so.18.3.0
├── libmysqlclient.so -> libmysqlclient.so.18
├── libmysqlclient.so.18 -> libmysqlclient.so.18.3.0
└── libmysqlclient.so.18.3.0其中 include 包含所有的方法声明,lib包含所有的方法实现(打包成库).
尝试链接mysql client.
通过 mysql_get_client_info() 函数,来验证我们的引入是否成功.
cpp
#include <stdio.h>
#include <mysql.h>
int main()
{
printf("mysql client Version: %s\n", mysql_get_client_info());
return 0;
}至此引入库的工作已经做完,接下来就是熟悉接口.
2.2MySQL接口介绍
2.2.1初始化mysql_init()
在使用 C/C++ 程序访问 MySQL 时,第一步通常不是直接连接数据库,而是先调用:
c
mysql_init()它的作用是:初始化一个 MySQL 连接对象,为后续连接数据库做准备.
也就是说,mysql_init() 只是"准备连接对象",并不会真正连接 MySQL 服务器.
1.函数原型
c
MYSQL *mysql_init(MYSQL *mysql);参数说明:
text
mysql MySQL连接对象指针返回值:
text
成功:返回 MYSQL* 类型的连接对象指针
失败:返回 NULL2.常见写法
最常用的写法是传入 NULL:
c
MYSQL *conn = mysql_init(NULL);含义是:让 MySQL 客户端库自动分配并初始化一个连接对象.
完整判断写法:
c
MYSQL *conn = mysql_init(NULL);
if (conn == NULL) {
printf("MySQL 初始化失败\n");
return 1;
}3.mysql_init()的作用
mysql_init() 主要完成以下准备工作:
text
创建 MYSQL 连接对象
初始化连接相关的内部数据
为后续 mysql_real_connect() 做准备可以把它理解为:
text
申请并初始化一个数据库连接句柄后面真正连接数据库时,还需要调用:
c
mysql_real_connect()4.基本使用流程
一个简单的 MySQL C API 连接流程如下:
c
#include <stdio.h>
#include <mysql/mysql.h>
int main() {
MYSQL *conn = mysql_init(NULL);
if (conn == NULL) {
printf("MySQL 初始化失败\n");
return 1;
}
conn = mysql_real_connect(
conn,
"localhost",
"connector",
"123456",
"conn",
3306,
NULL,
0
);
if (conn == NULL) {
printf("MySQL 连接失败\n");
return 1;
}
printf("MySQL 连接成功\n");
mysql_close(conn);
return 0;
}5.代码说明
c
MYSQL *conn = mysql_init(NULL);表示初始化一个 MySQL 连接对象.
c
mysql_real_connect(...)表示真正连接 MySQL 数据库.
c
mysql_close(conn);表示关闭连接并释放相关资源.
6.mysql_init()和 mysql_real_connect()的区别
| 函数 | 作用 | 是否连接数据库 |
|---|---|---|
mysql_init() |
初始化连接对象 | 否 |
mysql_real_connect() |
连接 MySQL 服务器 | 是 |
mysql_close() |
关闭连接 | 否,释放连接资源 |
所以不要误以为调用了 mysql_init() 就已经连接数据库了.
mysql_init() 是 MySQL C API 访问数据库的第一步,它负责初始化一个 MYSQL 连接对象.只有初始化成功后,程序才能继续调用 mysql_real_connect() 去真正连接 MySQL 数据库.
它在整个访问流程中的位置可以理解为:
text
mysql_init()
↓
mysql_real_connect()
↓
mysql_query()
↓
mysql_store_result()
↓
mysql_close()简单来说,mysql_init() 的作用就是:先把连接对象准备好,为后续访问 MySQL 打基础.
2.2.2连接数据库mysql_real_connect
在调用 mysql_init() 初始化连接对象之后,下一步就需要使用:
c
mysql_real_connect()来真正连接 MySQL 数据库服务器.
mysql_init() 只是创建并初始化连接对象,而 mysql_real_connect() 才会根据主机地址、用户名、密码、数据库名、端口号等信息,向MySQL服务器发起连接请求.
1.函数原型
c
MYSQL *mysql_real_connect(
MYSQL *mysql,
const char *host,
const char *user,
const char *passwd,
const char *db,
unsigned int port,
const char *unix_socket,
unsigned long client_flag
);参数说明:
| 参数 | 说明 |
|---|---|
mysql |
mysql_init() 返回的连接对象 |
host |
MySQL 服务器地址,例如 "localhost" |
user |
数据库用户名 |
passwd |
数据库密码 |
db |
要连接的数据库名 |
port |
MySQL 端口,默认是 3306 |
unix_socket |
Unix Socket 连接方式,一般填 NULL |
client_flag |
客户端连接选项,一般填 0 |
返回值:
text
成功:返回 MYSQL* 连接对象
失败:返回 NULL2.基本用法
c
MYSQL *conn = mysql_init(NULL);
if (conn == NULL) {
printf("MySQL 初始化失败\n");
return 1;
}
conn = mysql_real_connect(
conn,
"localhost",
"connector",
"DbConn@2025#X",
"conn",
3306,
NULL,
0
);
if (conn == NULL) {
printf("MySQL 连接失败\n");
return 1;
}
printf("MySQL 连接成功\n");这段代码表示:使用 connector 用户连接本机 3306 端口上的 conn 数据库.
3.参数逐个解释
localhost
c
"localhost"表示连接本机 MySQL.
如果 MySQL 在其他服务器上,可以写服务器 IP:
c
"192.168.1.100"connector
c
"connector"表示数据库用户名.
这个用户需要提前在 MySQL 中创建:
sql
CREATE USER 'connector'@'localhost' IDENTIFIED BY 'DbConn@2025#X';数据库密码
c
"DbConn@2025#X"表示 connector 用户的密码.
如果 MySQL 开启了密码强度策略,像 123456 这种简单密码可能会创建失败,所以建议使用复杂一点的密码.
数据库名
c
"conn"表示连接成功后默认使用 conn 数据库.
如果这个数据库不存在,需要先创建:
sql
CREATE DATABASE conn;并给用户授权:
sql
GRANT ALL ON conn.* TO 'connector'@'localhost';
FLUSH PRIVILEGES;端口号
c
3306MySQL 默认端口就是 3306.
如果你的 MySQL 配置了其他端口,需要改成对应端口.
4.完整示例代码
c
#include <stdio.h>
#include <mysql/mysql.h>
int main() {
MYSQL *conn = mysql_init(NULL);
if (conn == NULL) {
printf("MySQL 初始化失败\n");
return 1;
}
conn = mysql_real_connect(
conn,
"localhost",
"connector",
"DbConn@2025#X",
"conn",
3306,
NULL,
0
);
if (conn == NULL) {
printf("MySQL 连接失败:%s\n", mysql_error(conn));
return 1;
}
printf("MySQL 连接成功\n");
mysql_close(conn);
return 0;
}5.连接失败的常见原因
用户名或密码错误
如果用户名或密码不正确,连接会失败.
可以在命令行中先测试:
bash
mysql -uconnector -p用户 Host 不匹配
如果你创建的是:
sql
'connector'@'localhost'那么它只能从本机连接.
如果程序不是在MySQL所在机器上运行,需要创建:
sql
CREATE USER 'connector'@'%' IDENTIFIED BY 'DbConn@2025#X';并授权:
sql
GRANT ALL ON conn.* TO 'connector'@'%';
FLUSH PRIVILEGES;数据库不存在
如果代码里写的是:
c
"conn"但 MySQL 中没有这个数据库,也会连接失败.
可以查看数据库:
sql
SHOW DATABASES;没有权限
用户存在,但没有访问 conn 数据库的权限,也会失败.
授权方式:
sql
GRANT ALL ON conn.* TO 'connector'@'localhost';
FLUSH PRIVILEGES;6.mysql_real_connect()在访问流程中的位置
完整流程可以理解为:
text
mysql_init()
↓
mysql_real_connect()
↓
mysql_query()
↓
mysql_store_result()
↓
mysql_fetch_row()
↓
mysql_close()其中:
text
mysql_init() 初始化连接对象
mysql_real_connect() 连接数据库
mysql_query() 执行 SQL
mysql_store_result() 保存查询结果
mysql_fetch_row() 读取结果数据
mysql_close() 关闭连接mysql_real_connect() 是 MySQL C API 中真正负责连接数据库的函数.它会根据主机地址、用户名、密码、数据库名和端口号等信息,向MySQL服务器发起连接请求.
简单来说:
text
mysql_init() 是准备连接对象
mysql_real_connect() 是真正连接数据库只有 mysql_real_connect() 执行成功后,程序才能继续执行 SQL 语句,对数据库进行增删改查操作.
2.2.3下发mysql命令mysql_query
连接数据库成功后,程序就可以通过:
c
mysql_query()向 MySQL 服务器发送 SQL 命令.
它的作用是:把一条 SQL 语句从 C/C++ 程序发送给 MySQL 服务器执行.
也就是说,mysql_real_connect() 负责连接数据库,而 mysql_query() 负责执行 SQL.
1.函数原型
c
int mysql_query(MYSQL *mysql, const char *stmt_str);参数说明:
| 参数 | 说明 |
|---|---|
mysql |
已经连接成功的 MySQL 连接对象 |
stmt_str |
要执行的 SQL 语句字符串 |
返回值:
text
成功:返回 0
失败:返回非 0如果执行失败,可以使用:
c
mysql_error(conn)查看错误原因.
2.执行 SQL 命令
例如查询 user 表中的数据:
c
mysql_query(conn, "SELECT * FROM user");例如插入一条数据:
c
mysql_query(conn, "INSERT INTO user(name, age) VALUES('张三', 18)");例如修改数据:
c
mysql_query(conn, "UPDATE user SET age = 20 WHERE name = '张三'");例如删除数据:
c
mysql_query(conn, "DELETE FROM user WHERE name = '张三'");3.基本使用方式
c
int ret = mysql_query(conn, "SELECT * FROM user");
if (ret != 0) {
printf("SQL 执行失败:%s\n", mysql_error(conn));
return 1;
}
printf("SQL 执行成功\n");这里的 conn 是前面通过 mysql_real_connect() 获取到的数据库连接对象.
4.完整示例代码
c
#include <stdio.h>
#include <mysql/mysql.h>
int main() {
MYSQL *conn = mysql_init(NULL);
if (conn == NULL) {
printf("MySQL 初始化失败\n");
return 1;
}
conn = mysql_real_connect(
conn,
"localhost",
"connector",
"DbConn@2025#X",
"conn",
3306,
NULL,
0
);
if (conn == NULL) {
printf("MySQL 连接失败:%s\n", mysql_error(conn));
return 1;
}
printf("MySQL 连接成功\n");
int ret = mysql_query(conn, "SELECT * FROM user");
if (ret != 0) {
printf("SQL 执行失败:%s\n", mysql_error(conn));
mysql_close(conn);
return 1;
}
printf("SQL 执行成功\n");
mysql_close(conn);
return 0;
}5.mysql_query()执行查询语句
如果执行的是:
sql
SELECT * FROM user;这类查询语句,mysql_query() 只负责把SQL发给MySQL执行.
如果想拿到查询结果,还需要继续调用:
c
mysql_store_result()例如:
c
mysql_query(conn, "SELECT * FROM user");
MYSQL_RES *res = mysql_store_result(conn);所以查询流程一般是:
text
mysql_query()
↓
mysql_store_result()
↓
mysql_fetch_row()6.mysql_query()执行增删改语句
如果执行的是:
sql
INSERT
UPDATE
DELETE这类语句,一般不需要获取结果集,只需要判断是否执行成功.
例如:
c
int ret = mysql_query(conn, "INSERT INTO user(name, age) VALUES('李四', 22)");
if (ret == 0) {
printf("插入成功\n");
} else {
printf("插入失败:%s\n", mysql_error(conn));
}7.mysql_query()在访问流程中的位置
完整的 MySQL C API 访问流程可以理解为:
text
mysql_init()
↓
mysql_real_connect()
↓
mysql_query()
↓
mysql_store_result()
↓
mysql_fetch_row()
↓
mysql_close()其中:
| 函数 | 作用 |
|---|---|
mysql_init() |
初始化连接对象 |
mysql_real_connect() |
连接 MySQL 数据库 |
mysql_query() |
发送 SQL 命令 |
mysql_store_result() |
保存查询结果 |
mysql_fetch_row() |
读取一行数据 |
mysql_close() |
关闭数据库连接 |
mysql_query() 是 MySQL C API 中用于下发 SQL 命令的函数.只要数据库连接成功,就可以通过它向 MySQL 服务器发送查询、插入、修改、删除等 SQL 语句.
简单来说:
text
mysql_real_connect() 负责连接数据库
mysql_query() 负责执行 SQL 命令如果执行的是查询语句,还需要配合 mysql_store_result() 和 mysql_fetch_row() 获取结果;如果执行的是增删改语句,只需要判断返回值是否为 0 即可.
2.2.4获取执行结果mysql_store_result
当我们使用:
c
mysql_query(conn, "SELECT * FROM user");向 MySQL 下发查询命令后,MySQL 服务器会执行 SQL,并产生查询结果.
但是要注意:mysql_query() 只负责执行 SQL,并不会直接把结果取出来.如果想在程序中获取查询结果,就需要调用:
c
mysql_store_result()它的作用是:把 MySQL 服务器返回的查询结果保存到客户端内存中,方便后续逐行读取数据.
1.函数原型
c
MYSQL_RES *mysql_store_result(MYSQL *mysql);参数说明:
| 参数 | 说明 |
|---|---|
mysql |
已经连接成功的 MySQL 连接对象 |
返回值:
text
成功:返回 MYSQL_RES* 结果集对象
失败:返回 NULL其中 MYSQL_RES 可以理解为:查询结果集.
2.基本使用方式
c
int ret = mysql_query(conn, "SELECT * FROM user");
if (ret != 0) {
printf("SQL 执行失败:%s\n", mysql_error(conn));
return 1;
}
MYSQL_RES *res = mysql_store_result(conn);
if (res == NULL) {
printf("获取结果失败:%s\n", mysql_error(conn));
return 1;
}这段代码的含义是:
text
先执行 SELECT 查询
↓
再调用 mysql_store_result() 获取查询结果
↓
结果保存到 MYSQL_RES 结构中3.mysql_store_result()只适合查询语句
通常只有执行 SELECT 这类查询语句时,才需要调用:
c
mysql_store_result()例如:
sql
SELECT * FROM user;如果执行的是:
sql
INSERT
UPDATE
DELETE
CREATE
DROP这类不返回结果集的 SQL,一般不需要调用 mysql_store_result().
例如:
c
mysql_query(conn, "INSERT INTO user(name, age) VALUES('张三', 18)");这种情况下只需要判断 mysql_query() 是否执行成功即可.
4.获取结果后还需要读取数据
mysql_store_result() 只是把结果集保存下来,还没有真正一行一行地读取数据.
如果要读取结果中的每一行,需要继续使用:
c
mysql_fetch_row()基本流程如下:
text
mysql_query()
↓
mysql_store_result()
↓
mysql_fetch_row()示例:
c
MYSQL_RES *res = mysql_store_result(conn);
MYSQL_ROW row;
while ((row = mysql_fetch_row(res)) != NULL) {
printf("%s\n", row[0]);
}其中:
text
MYSQL_RES 表示整个查询结果集
MYSQL_ROW 表示结果集中的一行数据
row[0] 表示当前行的第一列
row[1] 表示当前行的第二列5.完整示例代码
c
#include <stdio.h>
#include <mysql/mysql.h>
int main() {
MYSQL *conn = mysql_init(NULL);
if (conn == NULL) {
printf("MySQL 初始化失败\n");
return 1;
}
conn = mysql_real_connect(
conn,
"localhost",
"connector",
"DbConn@2025#X",
"conn",
3306,
NULL,
0
);
if (conn == NULL) {
printf("MySQL 连接失败:%s\n", mysql_error(conn));
return 1;
}
printf("MySQL 连接成功\n");
int ret = mysql_query(conn, "SELECT * FROM user");
if (ret != 0) {
printf("SQL 执行失败:%s\n", mysql_error(conn));
mysql_close(conn);
return 1;
}
MYSQL_RES *res = mysql_store_result(conn);
if (res == NULL) {
printf("获取结果失败:%s\n", mysql_error(conn));
mysql_close(conn);
return 1;
}
MYSQL_ROW row;
while ((row = mysql_fetch_row(res)) != NULL) {
printf("%s\n", row[0]);
}
mysql_free_result(res);
mysql_close(conn);
return 0;
}6.释放结果集
使用 mysql_store_result() 获取结果集后,最后一定要释放:
c
mysql_free_result(res);因为 mysql_store_result() 会把查询结果保存到客户端内存中,如果不释放,可能造成内存浪费.
对应关系可以这样理解:
text
mysql_store_result() 获取并保存结果集
mysql_free_result() 释放结果集占用的内存7.在访问流程中的位置
完整流程如下:
text
mysql_init()
↓
mysql_real_connect()
↓
mysql_query()
↓
mysql_store_result()
↓
mysql_fetch_row()
↓
mysql_free_result()
↓
mysql_close()各函数作用:
| 函数 | 作用 |
|---|---|
mysql_init() |
初始化连接对象 |
mysql_real_connect() |
连接 MySQL 数据库 |
mysql_query() |
下发 SQL 命令 |
mysql_store_result() |
获取并保存查询结果 |
mysql_fetch_row() |
逐行读取结果数据 |
mysql_free_result() |
释放结果集 |
mysql_close() |
关闭数据库连接 |
mysql_store_result() 用于获取 SELECT 查询语句的执行结果.它会把 MySQL 服务器返回的数据保存到客户端内存中,形成一个 MYSQL_RES 结果集对象.
简单来说:
text
mysql_query() 负责执行 SQL
mysql_store_result() 负责获取查询结果
mysql_fetch_row() 负责读取每一行数据因此,在 C/C++ 程序访问 MySQL 时,mysql_store_result() 是连接 SQL 执行和数据读取之间的重要一步.
2.2.5获取结果行数mysql_num_rows
在使用 mysql_store_result() 获取查询结果集之后,如果想知道这次查询一共返回了多少行数据,可以使用:
c
mysql_num_rows()它的作用是:获取查询结果集中数据的行数.
例如执行:
sql
SELECT * FROM user;如果查询结果有 5 条记录,那么 mysql_num_rows() 返回的就是 5.
1.函数原型
c
my_ulonglong mysql_num_rows(MYSQL_RES *result);参数说明:
| 参数 | 说明 |
|---|---|
result |
mysql_store_result() 返回的结果集对象 |
返回值:
text
返回结果集中数据的行数返回类型是:
c
my_ulonglong它可以表示比较大的行数.
2.基本使用方式
c
MYSQL_RES *res = mysql_store_result(conn);
if (res == NULL) {
printf("获取结果失败:%s\n", mysql_error(conn));
return 1;
}
my_ulonglong rows = mysql_num_rows(res);
printf("查询结果共有 %llu 行\n", rows);这段代码表示:先获取查询结果集,然后统计结果集中一共有多少行数据.
3.完整示例代码
c
#include <stdio.h>
#include <mysql/mysql.h>
int main() {
MYSQL *conn = mysql_init(NULL);
if (conn == NULL) {
printf("MySQL 初始化失败\n");
return 1;
}
conn = mysql_real_connect(
conn,
"localhost",
"connector",
"DbConn@2025#X",
"conn",
3306,
NULL,
0
);
if (conn == NULL) {
printf("MySQL 连接失败:%s\n", mysql_error(conn));
return 1;
}
printf("MySQL 连接成功\n");
int ret = mysql_query(conn, "SELECT * FROM user");
if (ret != 0) {
printf("SQL 执行失败:%s\n", mysql_error(conn));
mysql_close(conn);
return 1;
}
MYSQL_RES *res = mysql_store_result(conn);
if (res == NULL) {
printf("获取结果失败:%s\n", mysql_error(conn));
mysql_close(conn);
return 1;
}
my_ulonglong row_count = mysql_num_rows(res);
printf("查询结果共有 %llu 行\n", row_count);
mysql_free_result(res);
mysql_close(conn);
return 0;
}4.它和 mysql_fetch_row()的关系
mysql_num_rows() 是获取总行数:
c
my_ulonglong row_count = mysql_num_rows(res);mysql_fetch_row() 是逐行读取数据:
c
MYSQL_ROW row;
while ((row = mysql_fetch_row(res)) != NULL) {
printf("%s\n", row[0]);
}可以这样理解:
text
mysql_num_rows() 统计结果集中有多少行
mysql_fetch_row() 一行一行读取结果数据5.注意事项
mysql_num_rows() 一般用于 SELECT 查询结果.
它通常要配合:
c
mysql_store_result()一起使用.
流程是:
text
mysql_query()
↓
mysql_store_result()
↓
mysql_num_rows()
↓
mysql_fetch_row()如果执行的是:
sql
INSERT
UPDATE
DELETE这类语句,不能用 mysql_num_rows() 判断影响了多少行.
对于增删改操作,应该使用:
c
mysql_affected_rows(conn);例如:
c
my_ulonglong affected = mysql_affected_rows(conn);
printf("受影响的行数:%llu\n", affected);mysql_num_rows() 用于获取 SELECT 查询结果中的总行数.它需要在 mysql_store_result() 获取结果集之后使用.
简单来说:
text
mysql_store_result() 获取结果集
mysql_num_rows() 获取结果集中的行数
mysql_fetch_row() 逐行读取结果数据它常用于判断查询是否有数据,例如:
c
if (mysql_num_rows(res) == 0) {
printf("没有查询到数据\n");
} else {
printf("查询到了数据\n");
}2.2.6获取结果列数mysql_num_fields
在使用 mysql_store_result() 获取查询结果集之后,如果想知道这次查询结果中一共有多少列,可以使用:
c
mysql_num_fields()它的作用是:获取结果集中的字段数量,也就是列数.
例如执行:
sql
SELECT id, name, age FROM user;这个查询结果有 id、name、age 三列,所以 mysql_num_fields() 返回值就是 3.
MySQL 官方文档中对它的说明也是:返回结果集中的列数.
1.函数原型
c
unsigned int mysql_num_fields(MYSQL_RES *result);参数说明:
| 参数 | 说明 |
|---|---|
result |
mysql_store_result() 返回的结果集对象 |
返回值:
text
返回结果集中的列数返回类型是:
c
unsigned int2.基本使用方式
c
MYSQL_RES *res = mysql_store_result(conn);
if (res == NULL) {
printf("获取结果失败:%s\n", mysql_error(conn));
return 1;
}
unsigned int field_count = mysql_num_fields(res);
printf("查询结果共有 %u 列\n", field_count);这段代码的含义是:
text
先获取查询结果集
↓
再统计结果集中有多少列3.完整示例代码
c
#include <stdio.h>
#include <mysql/mysql.h>
int main() {
MYSQL *conn = mysql_init(NULL);
if (conn == NULL) {
printf("MySQL 初始化失败\n");
return 1;
}
conn = mysql_real_connect(
conn,
"localhost",
"connector",
"DbConn@2025#X",
"conn",
3306,
NULL,
0
);
if (conn == NULL) {
printf("MySQL 连接失败:%s\n", mysql_error(conn));
return 1;
}
printf("MySQL 连接成功\n");
int ret = mysql_query(conn, "SELECT * FROM user");
if (ret != 0) {
printf("SQL 执行失败:%s\n", mysql_error(conn));
mysql_close(conn);
return 1;
}
MYSQL_RES *res = mysql_store_result(conn);
if (res == NULL) {
printf("获取结果失败:%s\n", mysql_error(conn));
mysql_close(conn);
return 1;
}
unsigned int field_count = mysql_num_fields(res);
printf("查询结果共有 %u 列\n", field_count);
mysql_free_result(res);
mysql_close(conn);
return 0;
}4.和mysql_num_rows()的区别
| 函数 | 作用 | 统计对象 |
|---|---|---|
mysql_num_rows() |
获取结果行数 | 有多少条记录 |
mysql_num_fields() |
获取结果列数 | 每条记录有多少个字段 |
例如查询结果是:
text
+----+--------+-----+
| id | name | age |
+----+--------+-----+
| 1 | 张三 | 18 |
| 2 | 李四 | 20 |
+----+--------+-----+那么:
text
mysql_num_rows(res) 返回 2
mysql_num_fields(res) 返回 35.配合mysql_fetch_row()使用
mysql_num_fields() 常用来控制循环,遍历一行中的每一列:
c
MYSQL_ROW row;
unsigned int field_count = mysql_num_fields(res);
while ((row = mysql_fetch_row(res)) != NULL) {
for (unsigned int i = 0; i < field_count; i++) {
printf("%s\t", row[i] ? row[i] : "NULL");
}
printf("\n");
}这里:
text
row[i] 表示当前行的第 i 列数据需要注意的是,数据库中的 NULL 值在 C API 中可能表现为 NULL 指针,所以输出时最好判断一下:
c
row[i] ? row[i] : "NULL"6.在访问流程中的位置
完整流程如下:
text
mysql_init()
↓
mysql_real_connect()
↓
mysql_query()
↓
mysql_store_result()
↓
mysql_num_rows()
↓
mysql_num_fields()
↓
mysql_fetch_row()
↓
mysql_free_result()
↓
mysql_close()其中:
| 函数 | 作用 |
|---|---|
mysql_init() |
初始化连接对象 |
mysql_real_connect() |
连接 MySQL 数据库 |
mysql_query() |
下发 SQL 命令 |
mysql_store_result() |
获取并保存查询结果 |
mysql_num_rows() |
获取结果行数 |
mysql_num_fields() |
获取结果列数 |
mysql_fetch_row() |
逐行读取结果数据 |
mysql_free_result() |
释放结果集 |
mysql_close() |
关闭数据库连接 |
mysql_num_fields() 用于获取查询结果集中的列数,通常在 mysql_store_result() 之后调用.
简单来说:
text
mysql_num_rows() 看有多少行
mysql_num_fields() 看有多少列
mysql_fetch_row() 逐行读取数据它最常见的用途是:在不知道查询结果有多少列的情况下,配合循环把每一行的所有字段都打印出来.
2.2.7获取列名mysql_fetch_fields
在使用 mysql_store_result() 获取查询结果集之后,如果想拿到查询结果中的列名,可以使用:
c
mysql_fetch_fields()它的作用是:获取结果集中所有字段的信息,包括字段名、表名、字段类型、字段长度等.
其中最常用的就是获取列名:
c
fields[i].name1.函数原型
c
MYSQL_FIELD *mysql_fetch_fields(MYSQL_RES *result);参数说明:
| 参数 | 说明 |
|---|---|
result |
mysql_store_result() 返回的结果集对象 |
返回值:
text
返回 MYSQL_FIELD* 类型的字段数组可以把它理解为:
text
查询结果中的所有列信息2.基本使用方式
c
MYSQL_RES *res = mysql_store_result(conn);
unsigned int field_count = mysql_num_fields(res);
MYSQL_FIELD *fields = mysql_fetch_fields(res);
for (unsigned int i = 0; i < field_count; i++) {
printf("%s\t", fields[i].name);
}
printf("\n");这段代码的作用是:打印查询结果中的所有列名.
例如执行:
sql
SELECT id, name, age FROM user;输出可能是:
text
id name age3.完整示例代码
c
#include <stdio.h>
#include <mysql/mysql.h>
int main() {
MYSQL *conn = mysql_init(NULL);
if (conn == NULL) {
printf("MySQL 初始化失败\n");
return 1;
}
conn = mysql_real_connect(
conn,
"localhost",
"connector",
"DbConn@2025#X",
"conn",
3306,
NULL,
0
);
if (conn == NULL) {
printf("MySQL 连接失败:%s\n", mysql_error(conn));
return 1;
}
printf("MySQL 连接成功\n");
int ret = mysql_query(conn, "SELECT * FROM user");
if (ret != 0) {
printf("SQL 执行失败:%s\n", mysql_error(conn));
mysql_close(conn);
return 1;
}
MYSQL_RES *res = mysql_store_result(conn);
if (res == NULL) {
printf("获取结果失败:%s\n", mysql_error(conn));
mysql_close(conn);
return 1;
}
unsigned int field_count = mysql_num_fields(res);
MYSQL_FIELD *fields = mysql_fetch_fields(res);
for (unsigned int i = 0; i < field_count; i++) {
printf("%s\t", fields[i].name);
}
printf("\n");
MYSQL_ROW row;
while ((row = mysql_fetch_row(res)) != NULL) {
for (unsigned int i = 0; i < field_count; i++) {
printf("%s\t", row[i] ? row[i] : "NULL");
}
printf("\n");
}
mysql_free_result(res);
mysql_close(conn);
return 0;
}4.MYSQL_FIELD结构体常用成员
mysql_fetch_fields() 返回的是一个字段数组,数组中的每个元素都是一个 MYSQL_FIELD 结构体.
常用成员如下:
| 成员 | 说明 |
|---|---|
name |
字段名,也就是列名 |
table |
字段所在的表名 |
db |
字段所在的数据库名 |
type |
字段类型 |
length |
字段长度 |
flags |
字段属性标记 |
最常用的是:
c
fields[i].name它表示第 i 列的列名.
5.配合mysql_num_fields()使用
mysql_fetch_fields() 一般不会单独使用,而是配合:
c
mysql_num_fields()一起使用.
因为 mysql_fetch_fields() 只返回字段数组,而我们还需要知道这个数组一共有多少个元素.
c
unsigned int field_count = mysql_num_fields(res);
MYSQL_FIELD *fields = mysql_fetch_fields(res);
for (unsigned int i = 0; i < field_count; i++) {
printf("%s\t", fields[i].name);
}6.和mysql_fetch_row()的关系
可以这样理解:
text
mysql_fetch_fields() 获取列名
mysql_fetch_row() 获取每一行的数据例如查询结果是:
text
+----+--------+-----+
| id | name | age |
+----+--------+-----+
| 1 | 张三 | 18 |
| 2 | 李四 | 20 |
+----+--------+-----+那么:
c
mysql_fetch_fields()获取的是:
text
id name age而:
c
mysql_fetch_row()获取的是:
text
1 张三 18
2 李四 207.注意事项
如果SQL中使用了别名:
sql
SELECT name AS username FROM user;那么:
c
fields[i].name获取到的是:
text
username也就是说,name 获取的是查询结果显示出来的列名.
如果想获取原始字段名,可以使用:
c
fields[i].org_namemysql_fetch_fields() 用来获取查询结果中的字段信息,最常见的用途就是获取列名.
它通常配合下面几个函数一起使用:
text
mysql_store_result() 获取结果集
mysql_num_fields() 获取列数
mysql_fetch_fields() 获取列名
mysql_fetch_row() 获取每一行数据简单来说:
text
mysql_fetch_fields() 负责拿表头
mysql_fetch_row() 负责拿数据行所以,在打印完整查询结果时,一般会先用 mysql_fetch_fields() 打印列名,再用 mysql_fetch_row() 逐行打印数据.
2.2.8获取结果内容mysql_fetch_row
在使用 mysql_store_result() 获取查询结果集之后,如果想真正拿到每一行的数据,就需要使用:
c
mysql_fetch_row()它的作用是:从结果集中一行一行地读取数据内容.
前面的函数分工可以这样理解:
text
mysql_query() 执行 SQL
mysql_store_result() 获取结果集
mysql_fetch_row() 读取结果集中的每一行数据1.函数原型
c
MYSQL_ROW mysql_fetch_row(MYSQL_RES *result);参数说明:
| 参数 | 说明 |
|---|---|
result |
mysql_store_result() 返回的结果集对象 |
返回值:
text
成功:返回 MYSQL_ROW 类型的一行数据
失败或没有更多数据:返回 NULL其中 MYSQL_ROW 本质上可以理解为一个字符串数组:
text
row[0] 表示当前行第 1 列
row[1] 表示当前行第 2 列
row[2] 表示当前行第 3 列2.基本使用方式
c
MYSQL_ROW row;
while ((row = mysql_fetch_row(res)) != NULL) {
printf("%s\n", row[0]);
}这段代码表示:从结果集中不断读取一行数据,直到没有数据为止.
如果查询结果是:
text
+----+--------+-----+
| id | name | age |
+----+--------+-----+
| 1 | 张三 | 18 |
| 2 | 李四 | 20 |
+----+--------+-----+那么第一次读取时:
text
row[0] = "1"
row[1] = "张三"
row[2] = "18"第二次读取时:
text
row[0] = "2"
row[1] = "李四"
row[2] = "20"3.配合列数读取所有字段
如果不知道查询结果有多少列,可以先用:
c
mysql_num_fields()获取列数,然后循环打印每一列:
c
MYSQL_ROW row;
unsigned int field_count = mysql_num_fields(res);
while ((row = mysql_fetch_row(res)) != NULL) {
for (unsigned int i = 0; i < field_count; i++) {
printf("%s\t", row[i] ? row[i] : "NULL");
}
printf("\n");
}这里要注意:
c
row[i] ? row[i] : "NULL"是为了防止数据库字段值为 NULL.如果不判断,直接打印 NULL 指针,程序可能会出问题.
4.完整示例代码
c
#include <stdio.h>
#include <mysql/mysql.h>
int main() {
MYSQL *conn = mysql_init(NULL);
if (conn == NULL) {
printf("MySQL 初始化失败\n");
return 1;
}
conn = mysql_real_connect(
conn,
"localhost",
"connector",
"DbConn@2025#X",
"conn",
3306,
NULL,
0
);
if (conn == NULL) {
printf("MySQL 连接失败:%s\n", mysql_error(conn));
return 1;
}
printf("MySQL 连接成功\n");
int ret = mysql_query(conn, "SELECT * FROM user");
if (ret != 0) {
printf("SQL 执行失败:%s\n", mysql_error(conn));
mysql_close(conn);
return 1;
}
MYSQL_RES *res = mysql_store_result(conn);
if (res == NULL) {
printf("获取结果失败:%s\n", mysql_error(conn));
mysql_close(conn);
return 1;
}
unsigned int field_count = mysql_num_fields(res);
MYSQL_ROW row;
while ((row = mysql_fetch_row(res)) != NULL) {
for (unsigned int i = 0; i < field_count; i++) {
printf("%s\t", row[i] ? row[i] : "NULL");
}
printf("\n");
}
mysql_free_result(res);
mysql_close(conn);
return 0;
}5.同时打印列名和内容
实际开发或学习测试时,经常会先打印列名,再打印每一行数据.
c
MYSQL_FIELD *fields = mysql_fetch_fields(res);
unsigned int field_count = mysql_num_fields(res);
for (unsigned int i = 0; i < field_count; i++) {
printf("%s\t", fields[i].name);
}
printf("\n");
MYSQL_ROW row;
while ((row = mysql_fetch_row(res)) != NULL) {
for (unsigned int i = 0; i < field_count; i++) {
printf("%s\t", row[i] ? row[i] : "NULL");
}
printf("\n");
}这样输出效果类似:
text
id name age
1 张三 18
2 李四 206.在访问流程中的位置
完整的 MySQL C API 查询流程如下:
text
mysql_init()
↓
mysql_real_connect()
↓
mysql_query()
↓
mysql_store_result()
↓
mysql_num_fields()
↓
mysql_fetch_fields()
↓
mysql_fetch_row()
↓
mysql_free_result()
↓
mysql_close()其中:
| 函数 | 作用 |
|---|---|
mysql_init() |
初始化连接对象 |
mysql_real_connect() |
连接数据库 |
mysql_query() |
下发 SQL 命令 |
mysql_store_result() |
获取查询结果集 |
mysql_num_fields() |
获取结果列数 |
mysql_fetch_fields() |
获取列名 |
mysql_fetch_row() |
获取每一行数据 |
mysql_free_result() |
释放结果集 |
mysql_close() |
关闭数据库连接 |
mysql_fetch_row() 用来从查询结果集中逐行读取数据.它通常配合 mysql_store_result()、mysql_num_fields() 一起使用.
简单来说:
text
mysql_store_result() 拿到整个结果集
mysql_fetch_row() 从结果集中一行一行取数据
row[i] 获取当前行第 i 列的内容所以,mysql_fetch_row() 是真正把查询结果内容取出来的关键函数.
2.2.9关闭mysql链接mysql_close
当程序访问完MySQL数据库后,需要调用:
c
mysql_close()它的作用是:关闭数据库连接,并释放连接对象占用的相关资源.
前面我们通过 mysql_init() 初始化连接对象,通过 mysql_real_connect() 连接数据库,最后就需要用 mysql_close() 结束这次连接.
1.函数原型
c
void mysql_close(MYSQL *sock);参数说明:
| 参数 | 说明 |
|---|---|
sock |
已经创建的 MySQL 连接对象 |
返回值:
text
无返回值也就是说,mysql_close() 只负责关闭连接,不需要判断返回值.
2.基本使用方式
c
MYSQL *conn = mysql_init(NULL);
// 连接数据库
conn = mysql_real_connect(
conn,
"localhost",
"connector",
"DbConn@2025#X",
"conn",
3306,
NULL,
0
);
// 使用完数据库后关闭连接
mysql_close(conn);这表示程序访问完数据库后,主动断开与 MySQL 服务器的连接.
3.为什么要关闭连接?
数据库连接是一种资源,程序连接 MySQL 时,服务器和客户端都会维护连接状态.
如果连接使用完后不关闭,可能会造成:
text
连接资源被长期占用
服务器连接数过多
内存资源浪费
后续连接失败
程序资源泄漏所以数据库访问完成后,应该及时关闭连接.
4.完整示例代码
c
#include <stdio.h>
#include <mysql/mysql.h>
int main() {
MYSQL *conn = mysql_init(NULL);
if (conn == NULL) {
printf("MySQL 初始化失败\n");
return 1;
}
conn = mysql_real_connect(
conn,
"localhost",
"connector",
"DbConn@2025#X",
"conn",
3306,
NULL,
0
);
if (conn == NULL) {
printf("MySQL 连接失败\n");
return 1;
}
printf("MySQL 连接成功\n");
mysql_query(conn, "SELECT * FROM user");
MYSQL_RES *res = mysql_store_result(conn);
if (res != NULL) {
MYSQL_ROW row;
unsigned int field_count = mysql_num_fields(res);
while ((row = mysql_fetch_row(res)) != NULL) {
for (unsigned int i = 0; i < field_count; i++) {
printf("%s\t", row[i] ? row[i] : "NULL");
}
printf("\n");
}
mysql_free_result(res);
}
mysql_close(conn);
return 0;
}5.注意释放顺序
如果查询语句产生了结果集,应该先释放结果集,再关闭数据库连接:
c
mysql_free_result(res);
mysql_close(conn);不要只关闭连接而忘记释放结果集.
推荐顺序是:
text
执行 SQL
↓
获取结果集
↓
读取结果数据
↓
释放结果集
↓
关闭数据库连接6.在完整访问流程中的位置
text
mysql_init()
↓
mysql_real_connect()
↓
mysql_query()
↓
mysql_store_result()
↓
mysql_num_fields()
↓
mysql_fetch_fields()
↓
mysql_fetch_row()
↓
mysql_free_result()
↓
mysql_close()其中:
| 函数 | 作用 |
|---|---|
mysql_init() |
初始化连接对象 |
mysql_real_connect() |
连接 MySQL 数据库 |
mysql_query() |
下发 SQL 命令 |
mysql_store_result() |
获取查询结果集 |
mysql_fetch_row() |
读取结果内容 |
mysql_free_result() |
释放结果集 |
mysql_close() |
关闭 MySQL 连接 |
mysql_close() 是 MySQL C API 访问流程中的最后一步,用来关闭数据库连接并释放相关资源.
简单来说:
text
mysql_real_connect() 负责建立连接
mysql_query() 负责执行 SQL
mysql_close() 负责关闭连接在普通数据库访问中,每次连接使用完都应该关闭;而在连接池中,连接通常不会真正关闭,而是归还给连接池继续复用.
3.MySQL图形化界面工具访问
除了使用命令行和 C/C++ 程序访问 MySQL,我们还可以通过图形化数据库管理工具来连接 MySQL.图形化界面访问更加直观,适合查看数据库、管理表结构、执行 SQL、导入导出数据等操作.
常见的 MySQL 图形化工具有:
text
Navicat
DataGrip
DBeaver
MySQL Workbench
SQLyog这些工具虽然界面不同,但访问 MySQL 的本质是一样的:通过主机地址、端口号、用户名和密码连接 MySQL 服务器.
1.图形化访问需要的连接信息
使用图形化工具连接 MySQL 时,一般需要填写以下信息:
| 配置项 | 示例 | 说明 |
|---|---|---|
| 主机地址 | localhost |
MySQL 所在服务器地址 |
| 端口号 | 3306 |
MySQL 默认端口 |
| 用户名 | connector |
登录 MySQL 的用户 |
| 密码 | DbConn@2025#X |
用户对应的密码 |
| 数据库 | conn |
要访问的数据库,可选 |
如果 MySQL 安装在本机,主机地址一般填写:
text
localhost或者:
text
127.0.0.12.创建连接
以图形化工具为例,一般操作流程如下:
text
打开图形化工具
↓
新建 MySQL 连接
↓
填写主机、端口、用户名、密码
↓
测试连接
↓
连接成功后保存对应的连接信息可以写成:
text
主机:localhost
端口:3306
用户名:connector
密码:DbConn@2025#X
数据库:conn点击"测试连接"后,如果提示连接成功,就说明图形化工具已经可以访问 MySQL.
3.使用图形化界面查看数据库
连接成功后,可以在左侧看到数据库列表,例如:
text
conn
mysql
information_schema
performance_schema
sys其中,自己创建并使用的数据库一般是:
text
conn展开数据库后,可以看到其中的表,例如:
text
user
student
article
order图形化工具可以直接查看:
text
表结构
字段类型
主键
索引
表数据
视图
存储过程这样比命令行更加直观.
4.执行 SQL 语句
图形化工具通常都会提供 SQL 编辑窗口,可以直接执行 SQL.
例如查询数据:
sql
SELECT * FROM user;插入数据:
sql
INSERT INTO user(name, age) VALUES('张三', 18);修改数据:
sql
UPDATE user SET age = 20 WHERE name = '张三';删除数据:
sql
DELETE FROM user WHERE name = '张三';执行后,工具会在结果窗口中显示查询结果或影响行数.
5.图形化访问和命令行访问的关系
图形化工具看起来是点按钮、点表格,但底层仍然是在发送SQL命令.
例如你在界面中点击"查看表数据",本质上可能执行的是:
sql
SELECT * FROM user;你在界面中新增一条数据,本质上可能执行的是:
sql
INSERT INTO user(...) VALUES(...);所以图形化界面只是把 SQL 操作变得更加可视化,底层仍然离不开MySQL连接和SQL执行.
6.常见连接失败原因
用户名或密码错误
如果密码输入错误,可能会提示:
text
Access denied for user可以重新设置密码:
sql
ALTER USER 'connector'@'localhost' IDENTIFIED BY 'DbConn@2025#X';用户 Host 不匹配
如果创建的是:
sql
'connector'@'localhost'那么该用户只能从本机连接.
如果图形化工具在另一台电脑上连接 MySQL,需要创建允许远程访问的用户:
sql
CREATE USER 'connector'@'%' IDENTIFIED BY 'DbConn@2025#X';
GRANT ALL ON conn.* TO 'connector'@'%';
FLUSH PRIVILEGES;没有数据库权限
如果能连接成功,但看不到 conn 数据库,可能是没有授权.
可以执行:
sql
GRANT ALL ON conn.* TO 'connector'@'localhost';
FLUSH PRIVILEGES;MySQL 服务没有启动
如果提示无法连接服务器,需要检查 MySQL 服务是否正在运行.
Linux 下可以查看:
bash
systemctl status mysql或:
bash
systemctl status mysqld7.图形化访问的优点
图形化界面访问 MySQL 的优点是:
text
操作直观
查看表结构方便
查询结果展示清晰
支持数据导入导出
适合调试和管理数据库但也要注意,图形化工具只是辅助工具.真正理解MySQL,还是要掌握 SQL 语句和数据库访问流程.
MySQL 图形化界面访问,本质上仍然是客户端连接 MySQL 服务器.只不过它把命令行中的连接、查询、建表、修改数据等操作做成了可视化界面.
可以简单理解为:
text
图形化工具
↓
填写连接信息
↓
连接 MySQL
↓
执行 SQL
↓
查看或修改数据无论是命令行访问、程序访问,还是图形化工具访问,底层核心都是一样的:建立连接、发送 SQL、获取结果、关闭连接.
4.MySQL连接池原理与简易网站数据流动是如何进行的
在网站开发中,后端程序访问MySQL时,并不是每次都直接重新创建数据库连接.因为数据库连接的创建和销毁都需要消耗资源,如果每个请求都执行一次:
text
创建连接 → 执行 SQL → 关闭连接当访问量变大时,系统性能会明显下降.
所以实际开发中通常会使用数据库连接池.连接池会提前创建好一批MySQL连接,请求来了就从池子里取一个连接,用完后不真正关闭,而是归还给连接池,等待下次复用.
4.1为什么需要连接池
如果没有连接池,每次访问数据库都要经历:
text
客户端请求
↓
后端创建 MySQL 连接
↓
MySQL 认证用户名和密码
↓
执行 SQL
↓
关闭连接
↓
返回结果这种方式在请求少的时候没有问题,但如果网站同时有很多用户访问,就会出现几个问题:
text
频繁创建连接,开销大
频繁关闭连接,浪费资源
MySQL 连接数容易被占满
网站响应速度变慢
服务器压力增大数据库连接本质上是一种比较重的资源,创建连接要经过网络通信、身份认证、权限校验等过程,所以不适合频繁创建和销毁.
4.2连接池的基本思想
连接池的核心思想是:
text
提前创建连接,重复使用连接也可以理解为:
text
不用一次创建一次销毁,而是借出来,用完再还回去连接池内部会维护一批数据库连接,例如:
text
连接池
├── 连接1
├── 连接2
├── 连接3
├── 连接4
└── 连接5当后端程序需要访问数据库时:
text
从连接池获取一个空闲连接
↓
使用这个连接执行 SQL
↓
获取数据库返回结果
↓
把连接归还给连接池注意,这里的"归还"不是关闭连接,而是把连接状态恢复为空闲,供下一次请求继续使用.
4.3连接池的工作流程
一个完整的连接池访问过程大致如下:
text
网站启动
↓
连接池初始化
↓
提前创建若干 MySQL 连接
↓
请求到达后端
↓
后端从连接池获取连接
↓
执行 SQL 语句
↓
获取查询结果
↓
归还连接
↓
返回响应给浏览器可以画成这样:
text
浏览器/网页
↓ 请求
后端服务
↓ 获取连接
连接池
↓ 复用连接
MySQL数据库
↓ 返回结果
后端服务
↓ 响应
浏览器/网页4.4连接池中连接的状态
连接池里的连接通常有两种状态:
text
空闲连接:当前没有被使用,可以被请求获取
忙碌连接:正在被某个请求使用,暂时不能被其他请求使用例如连接池中有 5 个连接:
text
连接1:空闲
连接2:忙碌
连接3:空闲
连接4:忙碌
连接5:空闲此时如果有新的请求访问数据库,连接池就可以把 连接1、连接3 或 连接5 分配出去.
如果所有连接都在忙碌,连接池可能会:
text
等待空闲连接
或者创建新连接
或者超过最大连接数后报错具体行为取决于连接池的配置.
4.5连接池的核心参数
连接池一般会有几个重要参数:
| 参数 | 作用 |
|---|---|
| 初始连接数 | 程序启动时提前创建多少个连接 |
| 最大连接数 | 连接池最多允许创建多少个连接 |
| 最小空闲连接数 | 保持多少个空闲连接备用 |
| 最大等待时间 | 没有空闲连接时,请求最多等待多久 |
| 空闲连接回收时间 | 长时间不用的连接是否释放 |
例如:
text
初始连接数:5
最大连接数:20
最小空闲连接数:3
最大等待时间:3000毫秒意思是:程序启动时先创建 5 个连接;如果访问量变大,可以继续创建连接,但最多不能超过 20 个;如果连接不够,请求最多等待 3 秒.
4.6连接池带来的好处
连接池的优势主要有:
text
减少连接创建和销毁的开销
提高数据库访问速度
控制数据库连接数量
避免 MySQL 被大量连接压垮
提升系统稳定性简单来说,连接池不是让 SQL 本身变快,而是减少了连接管理上的浪费.
没有连接池:
text
每次请求都重新创建连接有连接池:
text
多个请求复用已有连接这就是连接池提升性能的关键原因.
4.7简易网站数据流动过程
以一个简单的文章列表页面为例,用户打开网站首页,后端需要从 MySQL 查询文章数据.
完整数据流动过程如下:
text
1. 用户在浏览器访问网站页面
2. 浏览器向后端服务器发送请求
3. 后端服务器接收到请求
4. 后端从连接池中获取一个数据库连接
5. 后端通过连接向 MySQL 发送 SQL 查询语句
6. MySQL 执行 SQL,查询文章数据
7. MySQL 把查询结果返回给后端
8. 后端处理数据,生成响应内容
9. 后端把响应返回给浏览器
10. 浏览器展示页面
11. 数据库连接归还连接池对应流程图:
text
用户
↓
浏览器/网页
↓ 请求
后端服务器
↓ 获取连接
连接池
↓ 数据库连接
MySQL数据库
↓ 查询结果
后端服务器
↓ 响应数据
浏览器/网页
↓
页面展示4.8结合 C API 理解数据库访问流程
如果使用 MySQL C API,普通数据库访问流程是:
text
mysql_init()
↓
mysql_real_connect()
↓
mysql_query()
↓
mysql_store_result()
↓
mysql_fetch_row()
↓
mysql_free_result()
↓
mysql_close()但如果使用连接池,流程会变成:
text
从连接池获取连接
↓
mysql_query()
↓
mysql_store_result()
↓
mysql_fetch_row()
↓
mysql_free_result()
↓
归还连接池区别在于:
text
普通访问:用完 mysql_close()
连接池访问:用完归还连接池,不马上关闭也就是说,连接池会尽量避免频繁执行:
c
mysql_real_connect();
mysql_close();而是让连接被多次复用.
4.9连接池中的"关闭连接"是什么意思
在普通数据库访问中:
c
mysql_close(conn);是真的关闭 MySQL 连接.
但在连接池中,业务代码里的"关闭"通常不是真正关闭连接,而是:
text
把连接归还给连接池例如:
text
请求A 获取连接1
请求A 执行 SQL
请求A 使用完成
请求A 归还连接1
请求B 来了
请求B 继续使用连接1这样连接就被复用了.
4.10一个简单例子
假设网站有 3 个用户同时访问文章页面:
text
用户A 请求文章列表
用户B 请求文章详情
用户C 请求用户信息如果没有连接池:
text
用户A 创建连接 → 查询 → 关闭连接
用户B 创建连接 → 查询 → 关闭连接
用户C 创建连接 → 查询 → 关闭连接如果有连接池:
text
用户A 从连接池取连接1 → 查询 → 归还连接1
用户B 从连接池取连接2 → 查询 → 归还连接2
用户C 从连接池取连接3 → 查询 → 归还连接3连接不会被频繁创建和销毁,而是在连接池中循环使用.
MySQL 连接池的核心原理是:提前创建连接、统一管理连接、重复复用连接.
简易网站的数据流动过程可以概括为:
text
浏览器发送请求
↓
后端服务器接收请求
↓
从连接池获取 MySQL 连接
↓
执行 SQL 访问数据库
↓
MySQL 返回结果
↓
后端处理数据
↓
响应返回浏览器
↓
连接归还连接池所以,连接池解决的不是"怎么写 SQL"的问题,而是解决数据库连接如何高效管理和复用的问题.它可以减少资源浪费,提高访问效率,是后端程序访问MySQL时非常重要的一层机制.

🚀真正的勇者不是流泪的人,而是含泪奔跑的人!
敬请期待下一篇文章内容
每日心灵鸡汤: 真正的成长,是建立自己的未来坐标系!
人并不是因为不知道自己想要什么而迷茫,而是因为没有建立一个足够清晰的未来坐标系,所以被环境和短期欲望不断牵引.真正的成长,不是先寻找答案,而是先明确自己绝对不想成为谁、绝对不想过怎样的生活,然后围绕这个方向建立愿景、标准和行动系统.人生和创业本质上遵循同一个逻辑:发现问题、寻找解决方案、持续迭代.目标负责方向,行动负责验证,失败负责反馈.世界上不存在唯一正确的人生道路,别人能教给你的只是他们走过的路,而你最终需要通过不断行动和试错,找到属于自己的位置.
