从零手搓大模型前置知识(附录二)PyTorch GPU 训练基础
接着附录一,重点讲:
text
如何把 tensor、模型、数据移动到 GPU 上训练如果你没有 NVIDIA GPU,也可以阅读这篇,因为它解释的是后面训练大模型必须理解的设备管理逻辑。
1. GPU 训练为什么重要
深度学习训练里,大量计算都是矩阵乘法。
GPU 非常擅长并行矩阵计算,所以训练神经网络时通常比 CPU 快很多。
但是 PyTorch 有一个重要规则:
参与同一次计算的 tensor 必须在同一个设备上。
也就是说,不能让一个 tensor 在 CPU,另一个 tensor 在 GPU,然后直接相加或矩阵乘法。
2. 检查 PyTorch 和 GPU
python
import torch
print(torch.__version__)检查 CUDA 是否可用:
python
print(torch.cuda.is_available())如果输出:
text
True说明 PyTorch 可以使用 NVIDIA GPU。
如果是:
text
False说明当前环境没有可用 CUDA。原因可能是:
- 没有 NVIDIA 显卡。
- 没安装 CUDA 版 PyTorch。
- 驱动或环境没配好。
3. CPU tensor 运算
先创建两个 tensor:
python
tensor_1 = torch.tensor([1., 2., 3.])
tensor_2 = torch.tensor([4., 5., 6.])
print(tensor_1.device)
print(tensor_1 + tensor_2)输出
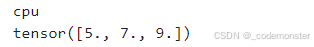
默认情况下,它们在 CPU 上。
可以查看:
python
print(tensor_1.device)一般是:
text
cpu4. 把 tensor 移动到 GPU
如果 CUDA 可用,可以写:
python
tensor_1 = tensor_1.to("cuda")
tensor_2 = tensor_2.to("cuda")
print(tensor_1 + tensor_2)输出
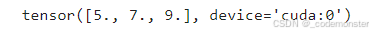
.to("cuda") 的意思是:
text
把 tensor 复制/移动到 GPU 设备上也可以移回 CPU:
python
tensor_1 = tensor_1.to("cpu")5. 最常见的设备错误
如果一个 tensor 在 CPU,另一个在 GPU:
python
tensor_1 = tensor_1.to("cpu")
print(tensor_1 + tensor_2)
这通常会报错。
原因是:
text
tensor_1 在 CPU
tensor_2 在 CUDAPyTorch 不允许它们直接相加。
所以训练时要记住:
text
模型、输入、标签必须在同一个 device 上。6. 更稳的设备写法
真实代码里一般不直接写死 "cuda",而是:
python
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")这样:
text
有 GPU 就用 GPU
没有 GPU 就自动退回 CPU后面所有东西都往这个 device 上移动:
python
model.to(device)
features = features.to(device)
labels = labels.to(device)7. 准备训练数据
复用了附录一的玩具数据:
python
X_train = torch.tensor([
[-1.2, 3.1],
[-0.9, 2.9],
[-0.5, 2.6],
[2.3, -1.1],
[2.7, -1.5]
])
y_train = torch.tensor([0, 0, 0, 1, 1])
X_test = torch.tensor([
[-0.8, 2.8],
[2.6, -1.6],
])
y_test = torch.tensor([0, 1])这是一个简单二分类问题。
8. Dataset 仍然一样
Dataset 和 CPU 训练时一样:
python
from torch.utils.data import Dataset
class ToyDataset(Dataset):
def __init__(self, X, y):
self.features = X
self.labels = y
def __getitem__(self, index):
one_x = self.features[index]
one_y = self.labels[index]
return one_x, one_y
def __len__(self):
return self.labels.shape[0]
train_ds = ToyDataset(X_train, y_train)
test_ds = ToyDataset(X_test, y_test)注意:通常 Dataset 里的原始数据可以先放 CPU。
训练循环里,每取出一个 batch,再把 batch 移动到 GPU。
9. DataLoader
python
from torch.utils.data import DataLoader
torch.manual_seed(123)
train_loader = DataLoader(
dataset=train_ds,
batch_size=2,
shuffle=True,
num_workers=1,
drop_last=True
)
test_loader = DataLoader(
dataset=test_ds,
batch_size=2,
shuffle=False,
num_workers=1
)参数 drop_last=True 的意思是:
text
如果最后一个 batch 不够 batch_size,就丢掉。在某些训练场景里,这可以让每个 batch 形状保持一致。
Windows 环境如果遇到 DataLoader 多进程问题,可以把:
python
num_workers=1改成:
python
num_workers=010. 定义模型
模型和之前的附录一是一样的:
python
class NeuralNetwork(torch.nn.Module):
def __init__(self, num_inputs, num_outputs):
super().__init__()
self.layers = torch.nn.Sequential(
torch.nn.Linear(num_inputs, 30),
torch.nn.ReLU(),
torch.nn.Linear(30, 20),
torch.nn.ReLU(),
torch.nn.Linear(20, num_outputs),
)
def forward(self, x):
logits = self.layers(x)
return logitsCPU 训练和 GPU 训练的模型定义通常不需要不同。
不同的是:
text
模型创建后,要移动到 device。11. 单 GPU 训练循环
这是这部分最重要的代码:
python
import torch.nn.functional as F
torch.manual_seed(123)
model = NeuralNetwork(num_inputs=2, num_outputs=2)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model.to(device)
optimizer = torch.optim.SGD(model.parameters(), lr=0.5)
num_epochs = 3
for epoch in range(num_epochs):
model.train()
for batch_idx, (features, labels) in enumerate(train_loader):
features, labels = features.to(device), labels.to(device)
logits = model(features)
loss = F.cross_entropy(logits, labels)
optimizer.zero_grad()
loss.backward()
optimizer.step()
print(f"Epoch: {epoch+1:03d}/{num_epochs:03d}"
f" | Batch {batch_idx+1:03d}/{len(train_loader):03d}"
f" | Train/Val Loss: {loss:.2f}")
model.eval()DataLoader 迭代只是批量调度器,真正读取单条数据的核心入口永远是 Dataset 的 getitem。
相比附录一,只多了几行关键代码。
创建 device:
python
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")移动模型:
python
model.to(device)移动每个 batch:
python
features, labels = features.to(device), labels.to(device)这是 GPU 训练最核心的三步。
12. 为什么每个 batch 都要 .to(device)
DataLoader 每次取出来的 features 和 labels 默认通常在 CPU。
而模型已经被移动到 GPU:
python
model.to(device)所以输入也必须移动到同一个设备:
python
features = features.to(device)
labels = labels.to(device)否则你会看到类似错误:
text
Expected all tensors to be on the same device这个错误非常常见。
13. GPU 版本的准确率函数
现在对 compute_accuracy 也做了设备适配:
python
def compute_accuracy(model, dataloader, device):
model = model.eval()
correct = 0.0
total_examples = 0
for idx, (features, labels) in enumerate(dataloader):
features, labels = features.to(device), labels.to(device)
with torch.no_grad():
logits = model(features)
predictions = torch.argmax(logits, dim=1)
compare = labels == predictions
correct += torch.sum(compare)
total_examples += len(compare)
return (correct / total_examples).item()和 CPU 版相比,关键新增:
python
features, labels = features.to(device), labels.to(device)评估时也要保证:
text
模型、输入、标签在同一个 device 上。14. 训练后评估
训练集准确率:
python
compute_accuracy(model, train_loader, device=device)测试集准确率:
python
compute_accuracy(model, test_loader, device=device)这里的 device=device 是显式传入当前设备。
这样函数里就知道应该把 batch 移到哪里。
15. 多 GPU 训练
DDP 是 Distributed Data Parallel,分布式数据并行。
初学阶段不用急着看。建议顺序是:
text
先会 CPU 训练
再会单 GPU 训练
最后再看多 GPU / DDP训练大模型时,多 GPU 很重要;但理解手搓 LLM 主线时,单 GPU 思维已经够用了。
16.本章和 LLM 的关系
后面训练 GPT 时,也会用同样逻辑:
python
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model.to(device)
for input_batch, target_batch in train_loader:
input_batch = input_batch.to(device)
target_batch = target_batch.to(device)
logits = model(input_batch)
loss = loss_fn(logits, target_batch)
optimizer.zero_grad()
loss.backward()
optimizer.step()也就是说,Part 2 学的是训练大模型前必须养成的设备习惯。
17. 你最该记住的模板
单 GPU/CPU 自适应训练模板:
python
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model = NeuralNetwork(num_inputs=2, num_outputs=2)
model.to(device)
for features, labels in train_loader:
features = features.to(device)
labels = labels.to(device)
logits = model(features)
loss = F.cross_entropy(logits, labels)
optimizer.zero_grad()
loss.backward()
optimizer.step()这套模板后面会反复出现,只是模型从小 MLP 换成 GPT,数据从二维点换成 token 序列。
18. 常见错误排查
错误 1:CUDA 不可用
python
torch.cuda.is_available()输出 False,就不要强行 .to("cuda")。
用:
python
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")错误 2:模型在 GPU,数据在 CPU
解决:
python
features = features.to(device)
labels = labels.to(device)错误 3:评估时忘记移动数据
评估函数里也要写:
python
features, labels = features.to(device), labels.to(device)错误 4:Windows DataLoader 报多进程问题
把:
python
num_workers=1改成:
python
num_workers=019. 建议
学习顺序:
- 先运行
torch.cuda.is_available(),确认有没有 GPU。 - 如果没有 GPU,也继续看
.to(device)逻辑。 - 跑 tensor
.to("cuda")示例时,如果没 GPU,跳过硬编码"cuda"的单元。 - 重点跑单 GPU 训练循环,把
model.to(device)和features.to(device)记牢。 - 多 GPU DDP 先跳过,等主线学完再回来看。
一句话总结:
text
附录一教你怎么训练模型,附录二教你怎么把训练搬到 GPU 上。