第1类题型:哈希表
为什么哈希表题看起来简单,你却最容易写错
很多同学第一次刷哈希表题时,会觉得这类题不难,因为经典题像
两数之和、存在重复元素看上去都不复杂。但真到了面试现场,哈希表反而是最容易暴露基本功的一类题,原因通常有这几种:
- 你知道这题和"查找"有关,但第一反应还是双重循环。
- 你隐约觉得要用哈希结构,却分不清该用
Map还是Set。- 你会写
HashMap,但"先查再放"还是"先放再查"总是容易写反。- 你能把代码写出来,却说不清为什么它能把复杂度从
O(n^2)压到O(n)。如果你现在正处在"会做部分 Easy,但题面一变就没把握,面试一追问就容易乱"的阶段,这一类题最值得先练。读完这篇,你至少要把 3 件事练熟:看到题先想到哈希、能把模板写稳、能在面试里把思路讲清楚。
文章目录
- 第1类题型:哈希表
-
- 核心知识点
-
- [动画辅助理解:先查 complement,再写入 map](#动画辅助理解:先查 complement,再写入 map)
- 这类题在面试里考什么
- 高频题清单
- [这类题最容易犯的 3 个错误](#这类题最容易犯的 3 个错误)
- [代表题精讲 1](#代表题精讲 1)
-
- 题目
- 思路
- [Java 代码](#Java 代码)
- 复杂度
- 如果这是面试现场,你可以这样说
- 手推一遍最容易记住的状态变化
- [代表题精讲 2](#代表题精讲 2)
-
- 题目
- 思路
- [Java 代码](#Java 代码)
- 复杂度
- 如果这是面试现场,你可以这样说
- [为什么这里用 `Set` 就够了](#为什么这里用
Set就够了)
- 其余题模板与关键片段
-
- [\`217. 存在重复元素\`(https://leetcode.cn/problems/contains-duplicate/)](#
217. 存在重复元素) - [\`242. 有效的字母异位词\`(https://leetcode.cn/problems/valid-anagram/)](#
242. 有效的字母异位词)
- [\`217. 存在重复元素\`(https://leetcode.cn/problems/contains-duplicate/)](#
- 边界、易混点与替代方案
-
- [`Map` 和 `Set` 怎么选](#
Map和Set怎么选) - 哈希和排序怎么选
- 哈希和计数数组怎么选
- 哪些情况要格外小心
- [`Map` 和 `Set` 怎么选](#
- 你学完后怎么验证自己真的会了
- 错题本记录方式
- 适用范围与边界
- [面试前 3 分钟速记](#面试前 3 分钟速记)
- 结尾:把"会做题"变成"会识别、会写、会讲"
核心知识点
哈希表最适合解决这几类问题:
- 查某个值是否存在。
- 统计某个元素出现次数。
- 建立"值到位置"或"值到次数"的映射。
- 去重。
- 把原本需要两层循环的查找,压成一层循环。
实习面试里,你可以先这样判断:如果题目里出现"是否存在""两数配对""出现次数""去重""映射关系",优先想哈希表。
Java 里最常用的是两个结构:
HashMap<K, V>:需要存键值对时用。HashSet<E>:只关心某个元素是否出现过时用。
最常见的写法有这几类:
java
Map<Integer, Integer> map = new HashMap<>();
map.put(nums[i], i);
map.get(target);
map.getOrDefault(x, 0);
Set<Integer> set = new HashSet<>();
set.add(x);
set.contains(x);边界上最容易错的是两件事:
- 先判断还是先插入。
- 值重复时,旧下标是否会被覆盖。
动画辅助理解:先查 complement,再写入 map
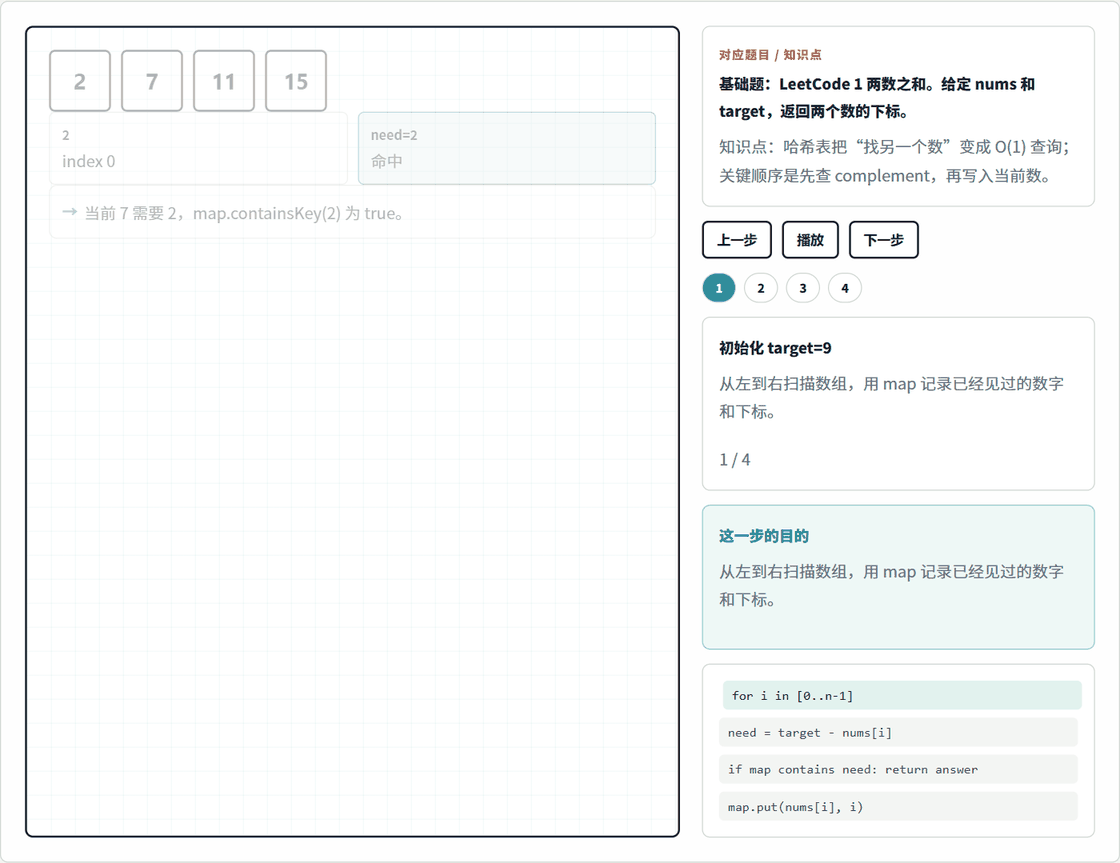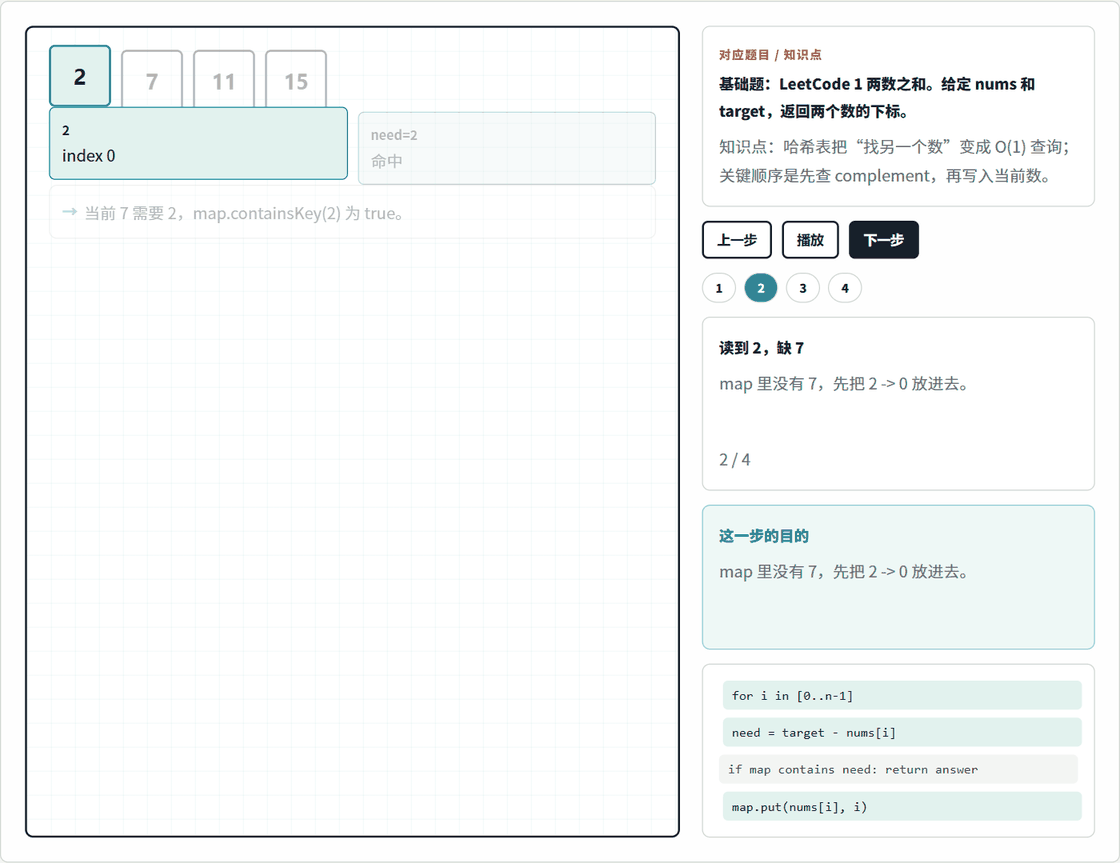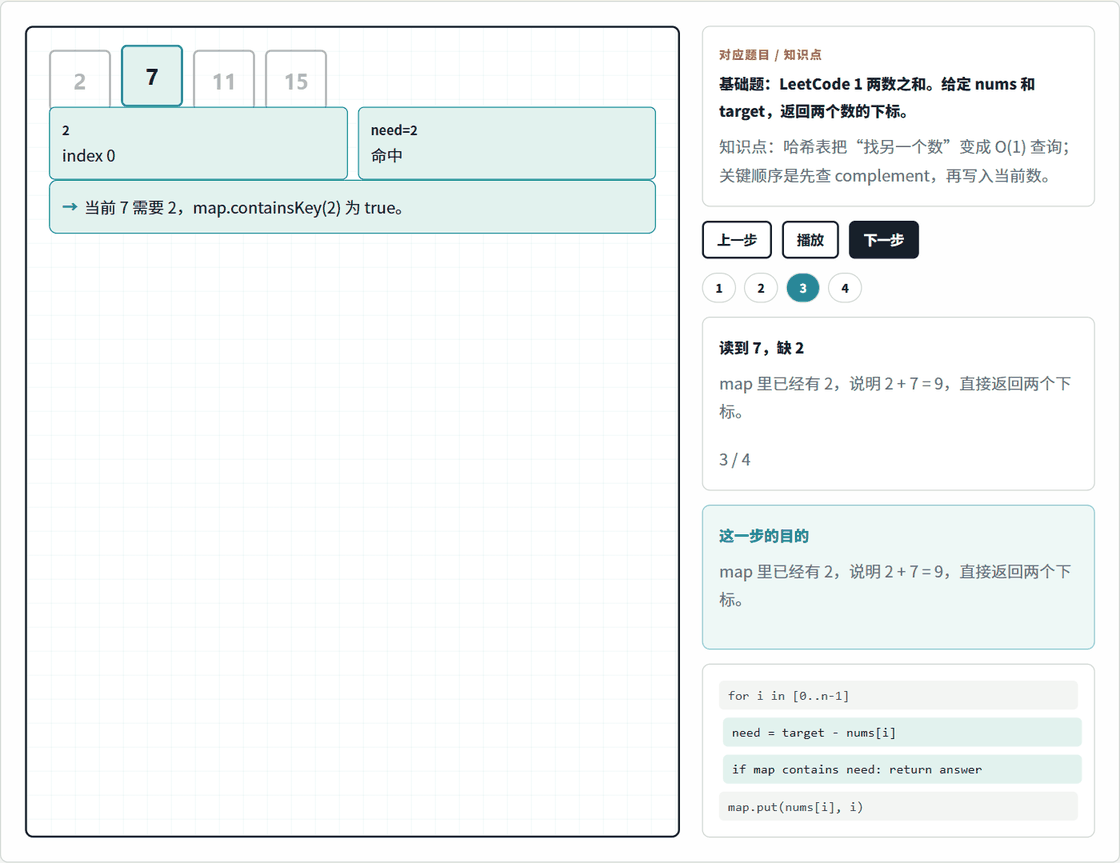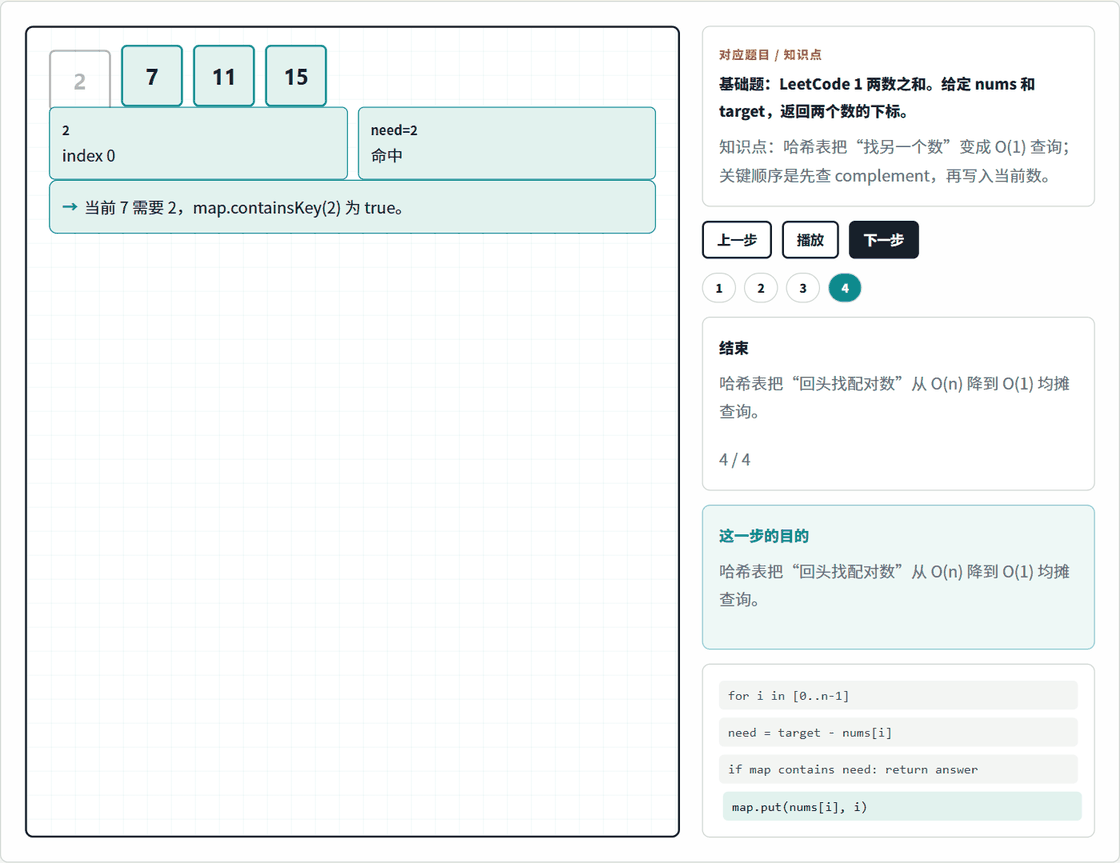
哈希表题最适合用 1. 两数之和 来建立第一印象。你可以先打开本地动画页:

这个动画只看一件事:遍历到当前数时,先计算它缺的另一个数,也就是 complement = target - nums[i],再去 map 里查这个 complement 是否已经出现过。
以 nums = [2, 7, 11, 15]、target = 9 为例:
| 当前值 | 需要的 complement | 查询 map | 下一步 |
|---|---|---|---|
2 |
7 |
查不到 7 |
把 2 -> 0 写入 map |
7 |
2 |
查到 2 -> 0 |
返回 [0, 1] |
这一步能解释为什么代码必须"先查再放"。如果你先把当前的 7 放进 map,再去查 complement,就会混淆"之前出现过的数"和"当前正在处理的数"。在面试里,哈希表题经常不是难在 API,而是难在这个状态更新顺序。
这类题在面试里考什么
哈希表题的面试考察很基础,但非常能看出习惯是否成熟。
- 你能不能把暴力查找压成线性时间。
- 你是否熟悉 Java 的
Map/Set写法。 - 你能不能在一次遍历里同时维护状态和答案。
- 你是否会处理重复值、缺失值、默认值这些细节。
面试官想看到的,不是你会背 HashMap 定义,而是你能快速说出:
- 为什么不用双重循环。
- 为什么这里用
Map而不是Set。 - 为什么这里应该先查再放,或者先放再查。
高频题清单
| 题目 | 来源 | 难度 | 高频属性 |
|---|---|---|---|
1. 两数之和 |
LeetCode 热题 100 | Easy | 面试高频 |
217. 存在重复元素 |
面试经典 150 | Easy | 面试高频 |
242. 有效的字母异位词 |
面试经典 150 | Easy | 基础高频 |
128. 最长连续序列 |
LeetCode 热题 100 | Medium | 真实面经高频 |
这类题最容易犯的 3 个错误
- 题目本质是查找和配对,结果还在写双重循环。
- 该用
Set的地方用了Map,把简单题写复杂。 Map更新顺序写反,导致同一个元素被重复使用或下标覆盖。
代表题精讲 1
题目
思路
暴力做法是双重循环,枚举每一对数,看它们的和是不是 target,复杂度是 O(n^2)。
更好的办法是边遍历边查找。假设当前数是 nums[i],那我只需要看前面有没有一个数等于 target - nums[i]。这个"前面有没有"非常适合用哈希表维护。
因此做法是:
- 遍历数组。
- 先查哈希表中是否存在
target - nums[i]。 - 如果存在,直接返回答案。
- 如果不存在,把当前值和当前下标放进哈希表。
这里"先查再放"非常关键,因为题目不允许同一个元素使用两次。
Java 代码
java
import java.util.HashMap;
import java.util.Map;
class Solution {
public int[] twoSum(int[] nums, int target) {
Map<Integer, Integer> indexMap = new HashMap<>();
for (int i = 0; i < nums.length; i++) {
int need = target - nums[i];
if (indexMap.containsKey(need)) {
return new int[] {indexMap.get(need), i};
}
indexMap.put(nums[i], i);
}
return new int[0];
}
}复杂度
- 时间复杂度:
O(n) - 空间复杂度:
O(n)
如果这是面试现场,你可以这样说
这题我会先把它归类为哈希查找题。暴力做法是双重循环,时间复杂度 O(n^2)。更好的做法是一边遍历一边用 HashMap 记录已经出现过的数字及其下标。对于当前元素 nums[i],只需要看 target - nums[i] 是否已经出现过。如果出现过就能直接得到答案,这样整体时间复杂度降到 O(n)。
手推一遍最容易记住的状态变化
以 nums = [2, 7, 11, 15]、target = 9 为例:
当前下标 i |
当前值 nums[i] |
需要找的值 target - nums[i] |
哈希表查询前内容 | 结果 |
|---|---|---|---|---|
| 0 | 2 | 7 | {} |
找不到,放入 2 -> 0 |
| 1 | 7 | 2 | {2=0} |
找到,返回 0, 1 |
这个过程最值得记住的不是答案本身,而是顺序:先查补数,再放当前元素。只要你把顺序写反,就有机会把同一个元素错误复用两次。
代表题精讲 2
题目
思路
这题最容易误入排序思路。排序后当然能做,但时间复杂度是 O(n log n)。题目真正想考的是:你能不能用哈希表把它压到 O(n)。
关键观察是:如果一个数 x 的前一个数 x - 1 不存在,那么 x 就可能是一段连续序列的起点。只有在起点处才继续向后扩展,统计长度。
做法:
- 先把所有数放进
HashSet。 - 遍历每个数
x。 - 如果
x - 1存在,说明它不是起点,跳过。 - 如果
x - 1不存在,就从x开始不断检查x + 1, x + 2...。 - 统计最长长度。
这样每个数最多被作为扩展的一部分检查一次,总体还是线性复杂度。
Java 代码
java
import java.util.HashSet;
import java.util.Set;
class Solution {
public int longestConsecutive(int[] nums) {
Set<Integer> set = new HashSet<>();
for (int num : nums) {
set.add(num);
}
int best = 0;
for (int num : set) {
if (set.contains(num - 1)) {
continue;
}
int current = num;
int length = 1;
while (set.contains(current + 1)) {
current++;
length++;
}
best = Math.max(best, length);
}
return best;
}
}复杂度
- 时间复杂度:
O(n) - 空间复杂度:
O(n)
如果这是面试现场,你可以这样说
这题虽然也能排序做,但排序会把复杂度带到 O(n log n)。如果想做到线性时间,关键是把所有元素放进 HashSet,然后只从"可能的起点"开始往后扩展。判断起点的方法是看 num - 1 是否不存在。这样可以避免重复扫描同一段连续区间。
为什么这里用 Set 就够了
这题不需要记录下标,也不需要记录次数,真正需要的是两件事:
- 某个数是否存在。
- 某个数是不是一段连续区间的起点。
这两件事都只和"存在性"有关,所以 HashSet 已经足够。很多同学会下意识写成 Map<Integer, Integer>,但那只会让代码更重,并没有提供额外价值。
其余题模板与关键片段
217. 存在重复元素
核心就是去重:
java
Set<Integer> seen = new HashSet<>();
for (int num : nums) {
if (!seen.add(num)) {
return true;
}
}
return false;242. 有效的字母异位词
如果只包含小写字母,直接用计数数组:
java
int[] count = new int[26];
for (char c : s.toCharArray()) count[c - 'a']++;
for (char c : t.toCharArray()) count[c - 'a']--;
for (int x : count) {
if (x != 0) return false;
}
return true;这题的重点不是哈希一定比数组好,而是你要知道在字符范围固定时,数组比 Map<Character, Integer> 更直接。
边界、易混点与替代方案
Map 和 Set 怎么选
- 只关心元素是否出现过:优先
Set - 还要记录下标、次数、映射关系:优先
Map
如果你发现自己在代码里存了一个值,却从头到尾没有用到这个值对应的附加信息,通常就说明结构选重了。
哈希和排序怎么选
很多题都能"排序后再做",但排序会改变复杂度,也可能打乱原始下标信息。像 两数之和 这类要保留下标的题,哈希往往更直接;像 最长连续序列 这种题,排序可做但不是题目真正想考的最优思路。
哈希和计数数组怎么选
如果值域或字符集固定,计数数组常常比哈希更轻,比如 有效的字母异位词。如果值域不固定、需要通用映射能力,哈希就更稳。
哪些情况要格外小心
- 题目不允许同一个元素用两次时,重点检查"先查后放"。
- 题目有重复值时,重点检查旧值被覆盖后是否影响答案。
- 题目只问存在性时,别把简单题写成维护复杂映射的大题。
你学完后怎么验证自己真的会了
不要只看完文章就算结束。更有效的做法,是用下面 3 组自测来判断你是否真的掌握:
- 10 分钟内独立写出
两数之和,并且不用回忆题解文字,只靠"先查再放"的识别信号完成。 - 看见
最长连续序列时,能主动说出为什么不是必须排序,为什么只从起点开始扩展。 - 看到
存在重复元素、有效的字母异位词这类题时,能快速判断该用Set、Map还是计数数组。
如果你在自测时出现下面任意一种情况,就说明还没有真正掌握:
- 能看懂代码,但自己从空白开始写不出来。
- 写得出来,但说不清为什么复杂度是
O(n)。 - 知道要用哈希,但结构一会儿用
Map,一会儿用Set,没有判断标准。
比较稳妥的过关标准是:你能在 15 分钟内做出一道基础哈希题,并且在 1 分钟内口述题型判断、核心思路和复杂度。
错题本记录方式
哈希表题建议重点记录这几类卡点:
- 我到底为什么没想到用哈希,而是写了暴力。
- 我是否判断错了应该用
Map还是Set。 - 我是"先查后放"写错,还是默认值更新写错。
- 这题的识别信号是什么,比如"配对""频次""去重""是否存在"。
适用范围与边界
- 本文默认你已经会 Java 数组遍历、条件判断和基础集合写法。
- 本文重点服务于 Java 实习面试、LeetCode 高频 Easy / Medium 和常见笔试基础题。
- 本文不覆盖哈希冲突底层实现、并发哈希容器或竞赛向复杂技巧。
如果你当前连 HashMap / HashSet 的基本 API 都不熟,建议先补 Java 集合基础,再回来刷这类题,效果会更好。
面试前 3 分钟速记
- 看到"配对、是否存在、频次、去重",优先想哈希表。
- 只关心是否出现过,用
HashSet。 - 还要记下标或次数,用
HashMap。 两数之和记住"先查再放"。最长连续序列记住"只从起点开始扩展"。- Java 常用写法:
containsKey、getOrDefault、add返回值。
结尾:把"会做题"变成"会识别、会写、会讲"
哈希表之所以适合作为第一类题型,不是因为它最简单,而是因为它最适合帮你建立题型意识。你从这类题开始练,最重要的收获不是记住某道题的答案,而是养成几个稳定动作:
- 看到题先判断是不是"存在性、配对、频次、去重"问题。
- 写代码时先想清楚
Map和Set的职责区别。 - 做完题后,能用一句话解释为什么哈希把暴力查找压成了线性复杂度。
如果这几个动作稳定下来,后面的双指针、滑动窗口、图论和动态规划,你都会更容易进入状态。
感谢阅读,记得点赞、关注、收藏,欢迎各位评论区交流!!!
下一篇继续看第 2 类高频题型:->->->【Java实习面试算法冲刺】双指针<-<-<-
