哨兵是什么
哨兵就是一种自动监视程序(即一个进程),他可以监视redis主从架构,自动故障转移,通知故障。如果主从架构中的主节点瘫痪,哨兵可以自动推举出新的主节点(避免了人工干预),恢复写功能;如果主从架构中的从节点瘫痪,哨兵可以将该节点标记为不可用并使得客户端得知该消息,客户端就会从其他节点进行读取。
一般来说,一个主从架构不止被一个哨兵监视,而是被一个哨兵集群监视,这主要是出于以下两点考虑:
- 单点哨兵可用性不高,如果瘫痪就无法对redis主从架构进行监视
- 单点哨兵判断不可信,有可能是因为网络抖动误判了redis节点的瘫痪,而如果有多个哨兵都认为该节点瘫痪,那大概率是可信的。
总而言之,哨兵就是将人工需要做的事情用程序来做,问题发现更及时,解决更及时,出错概率小。下面是哨兵和redis的关系图:
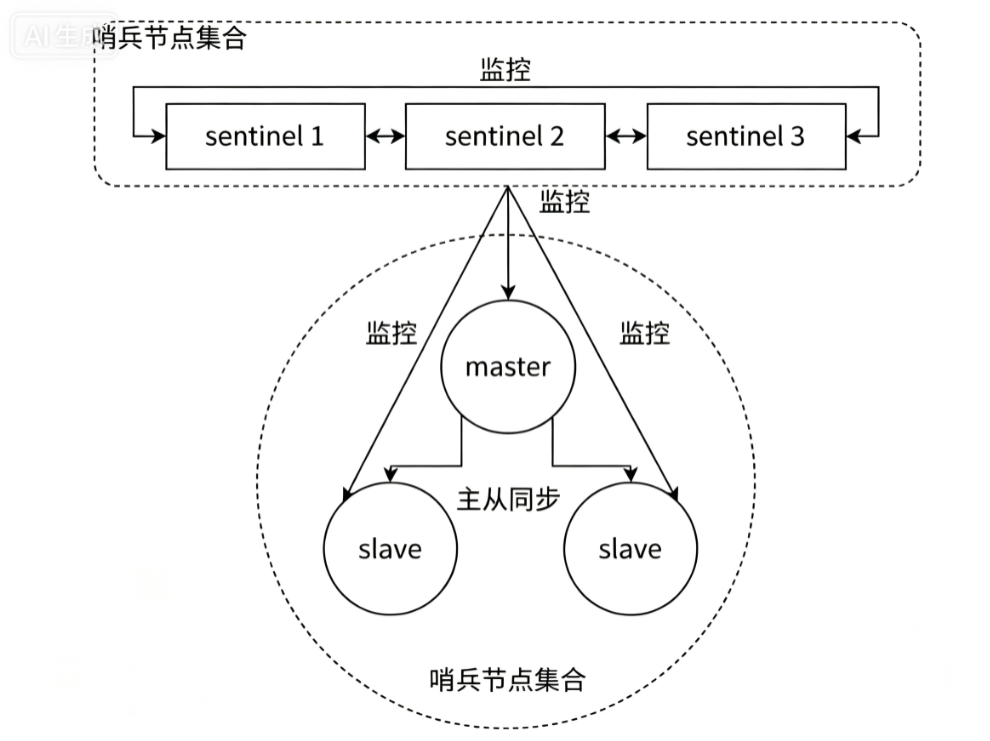
故障转移流程
哨兵会定期给各个redis节点发送心跳包,如果某节点没有在规定时间做出回复那么哨兵就有理由认为该节点瘫痪
主观下线(SDown)
-
触发条件:Redis 主节点(master)宕机,与所有哨兵之间的心跳通信中断。
-
哨兵行为:每个哨兵独立判断主节点"严重故障",将其标记为主观下线。
-
特点:此时只是单个哨兵自己的看法,不代表集群共识。
客观下线(ODown)
-
投票判定:所有哨兵(例如 sentinel1、sentinel2、sentinel3)就"主节点是否故障"发起投票。
-
法定票数(quorum):当赞成票数 ≥ 配置的
quorum值时,故障被做实。 -
结果:一旦达到 quorum,主节点被标记为客观下线,确认需要执行故障转移。
选举哨兵 Leader(Raft 算法)
-
目的:只需要一个哨兵作为"代表"来完成后续的选主、提主操作,避免多人同时干预。
-
选举过程:
-
每个哨兵向其他所有哨兵发送"拉票请求"。
-
收到拉票请求的哨兵回复"投票响应",每个哨兵只有一票。
-
如果回复者还没有给任何人投过票,就投给第一个来拉票的哨兵;
-
如果已经投过,则不再投票(先到先得)。
-
-
一轮投票后,得票数超过半数的哨兵自动成为 Leader。
-
如果出现平票(如三人各得一票),则重新发起一轮投票,直到选出 Leader。
-
-
设计建议:哨兵节点数配置为奇数(如 3、5),可降低平票概率,减少重选开销。
-
关键因素:网络延时的微小差异决定了谁先发出拉票请求,因此结果带有随机性------这并不重要,只要能选出一个 Leader 即可。
Leader 挑选新 Master 的规则
Leader 从剩余的 slave 节点中,按以下优先级顺序挑选新 master:
-
比较优先级(slave-priority / replica-priority)
数值越小优先级越高,节点优先级高的直接上位(类似"钦定",优先级可以在配置文件中设置)。 -
比较复制偏移量(replication offset)
数据同步进度领先的 slave 上位(复制数据越多越新)。 -
比较 run id
若前两项都相同,则选择 run id 字典序更小的 slave(相当于按随便选了)。
执行故障转移
一旦某个 slave 被选定,Leader 会执行:
-
让该 slave 执行
SLAVEOF NO ONE,使其成为新的 master。 -
通知其余 slave 节点,将它们的主节点指向这个新 master,完成切换。
-
其他哨兵一旦发现新 master 出现,就知道选举与转移已结束,整个集群恢复正常。
-
如果后续原来的主节点恢复,他将被设置为新主节点的从节点。