图的存储的选择:
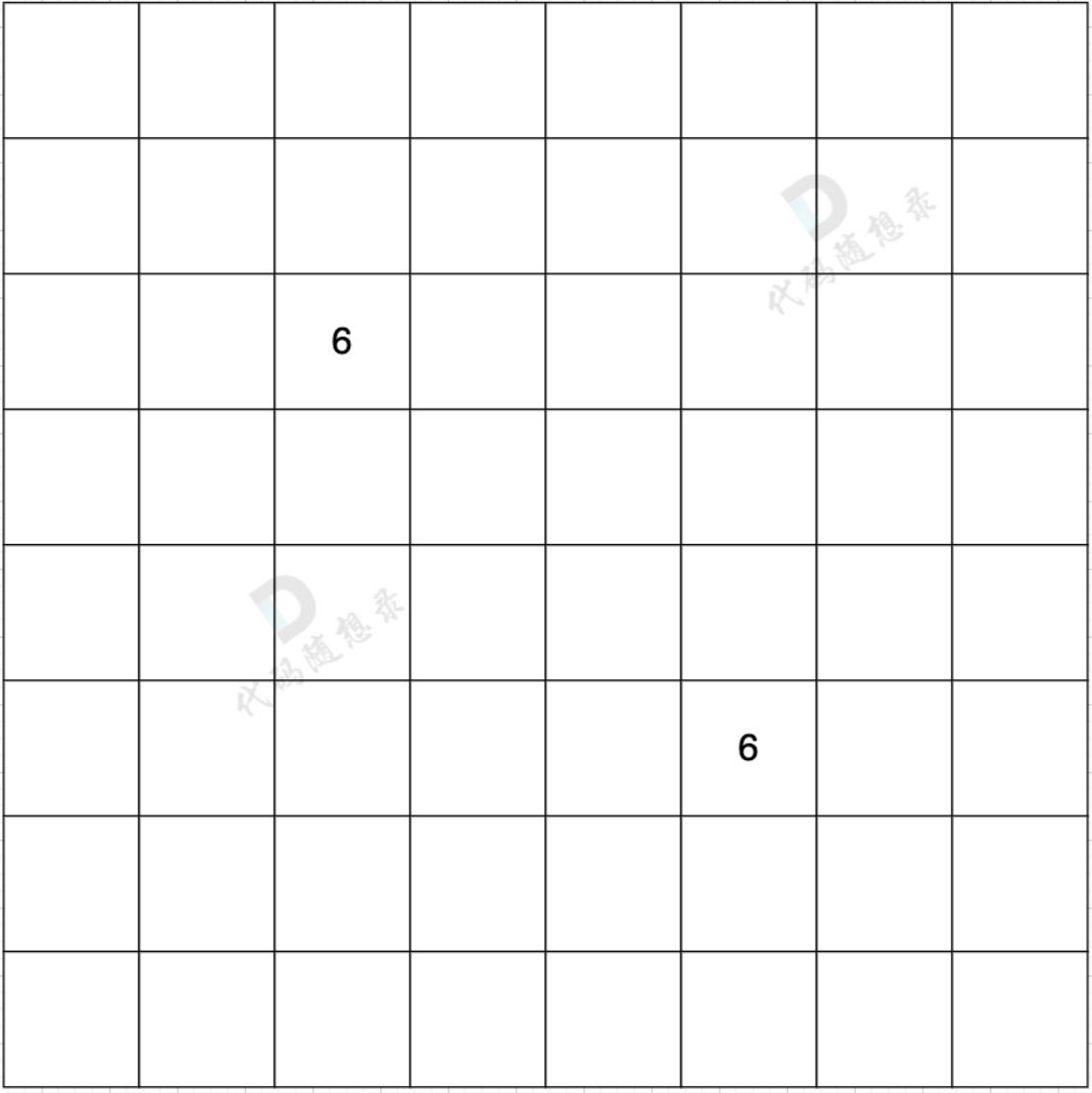
邻接矩阵
邻接矩阵 使用 二维数组来表示图结构。 邻接矩阵是从节点的角度来表示图,有多少节点就申请多大的二维数组。
问题:
在一个 n (节点数)为8 的图中,就需要申请 8 * 8 这么大的空间,有一条双向边,即:grid25 = 6,grid52 = 6。这种表达方式(邻接矩阵) 在 边少,节点多的情况下,会导致申请过大的二维数组,造成空间浪费。
而且在寻找节点链接情况的时候,需要遍历整个矩阵,即 n * n 的时间复杂度,同样造成时间浪费。
邻接矩阵的优点:
- 表达方式简单,易于理解
- 检查任意两个顶点间是否存在边的操作非常快
- 适合稠密图,在边数接近顶点数平方的图中,邻接矩阵是一种空间效率较高的表示方法。
缺点:
- 遇到稀疏图,会导致申请过大的二维数组造成空间浪费 且遍历边的时候需要遍历整个n * n矩阵,造成时间浪费
邻接表
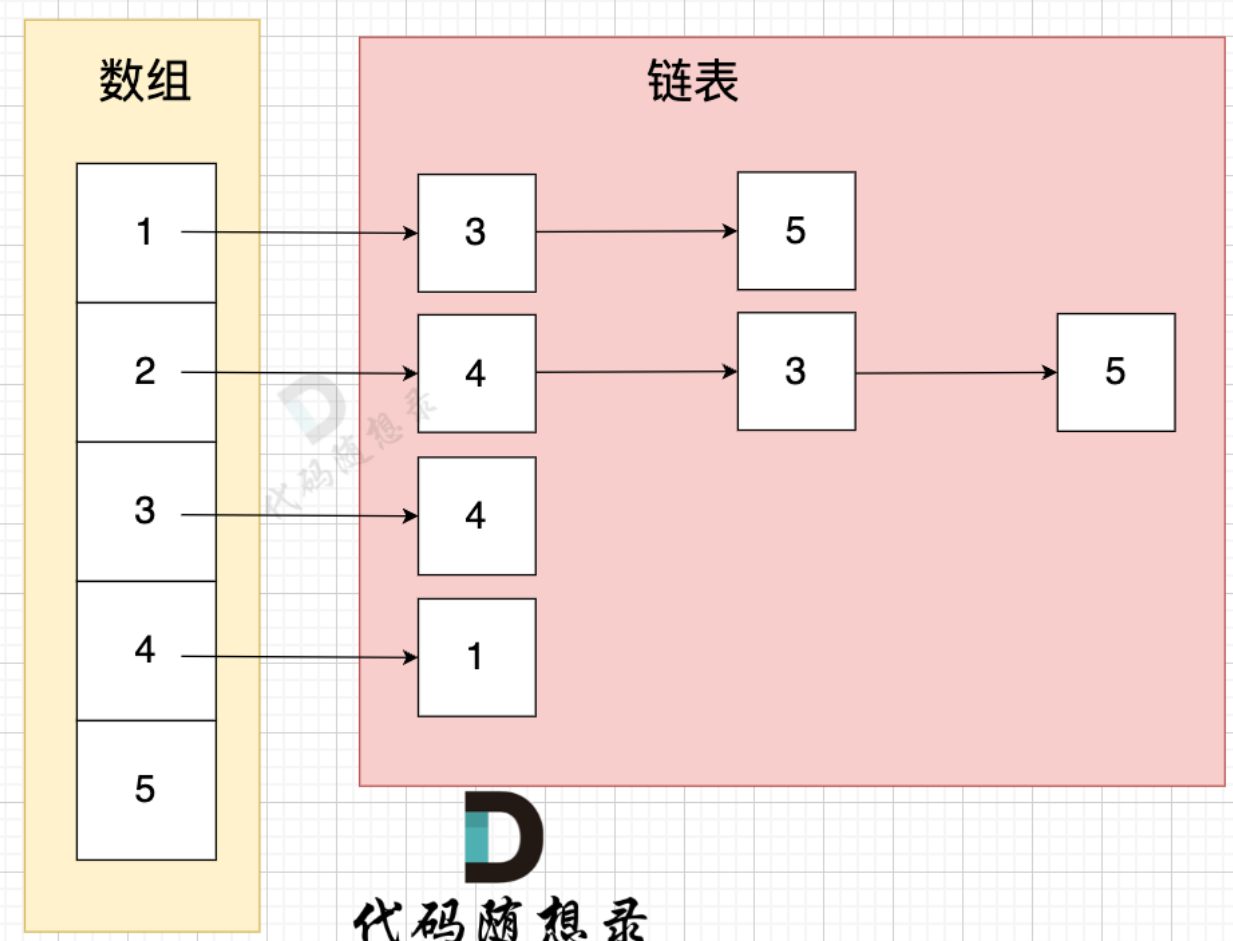
邻接表 使用 数组 + 链表的方式来表示。 邻接表是从边的数量来表示图,有多少边 才会申请对应大小的链表。
邻接表的优点:
- 对于稀疏图的存储,只需要存储边,空间利用率高
- 遍历节点链接情况相对容易
缺点:
- 检查任意两个节点间是否存在边,效率相对低,需要 O(V)时间,V表示某节点链接其他节点的数量。
- 实现相对复杂,不易理解
1.最小生成树,prim算法
概念:
用最短的路径连接所有点
- 最小生成树是所有节点的最小连通子图,即:以最小的成本(边的权值)将图中所有节点链接到一起。
- 图中有n个节点,那么一定可以用n-1条边将所有节点连接到一起。
- 那么如何选择这n-1条边就是最小生成树算法的任务所在。
prim算法是从节点的角度采用贪心的策略每次寻找距离最小生成树最近的节点并加入到最小生成树中。
过程:
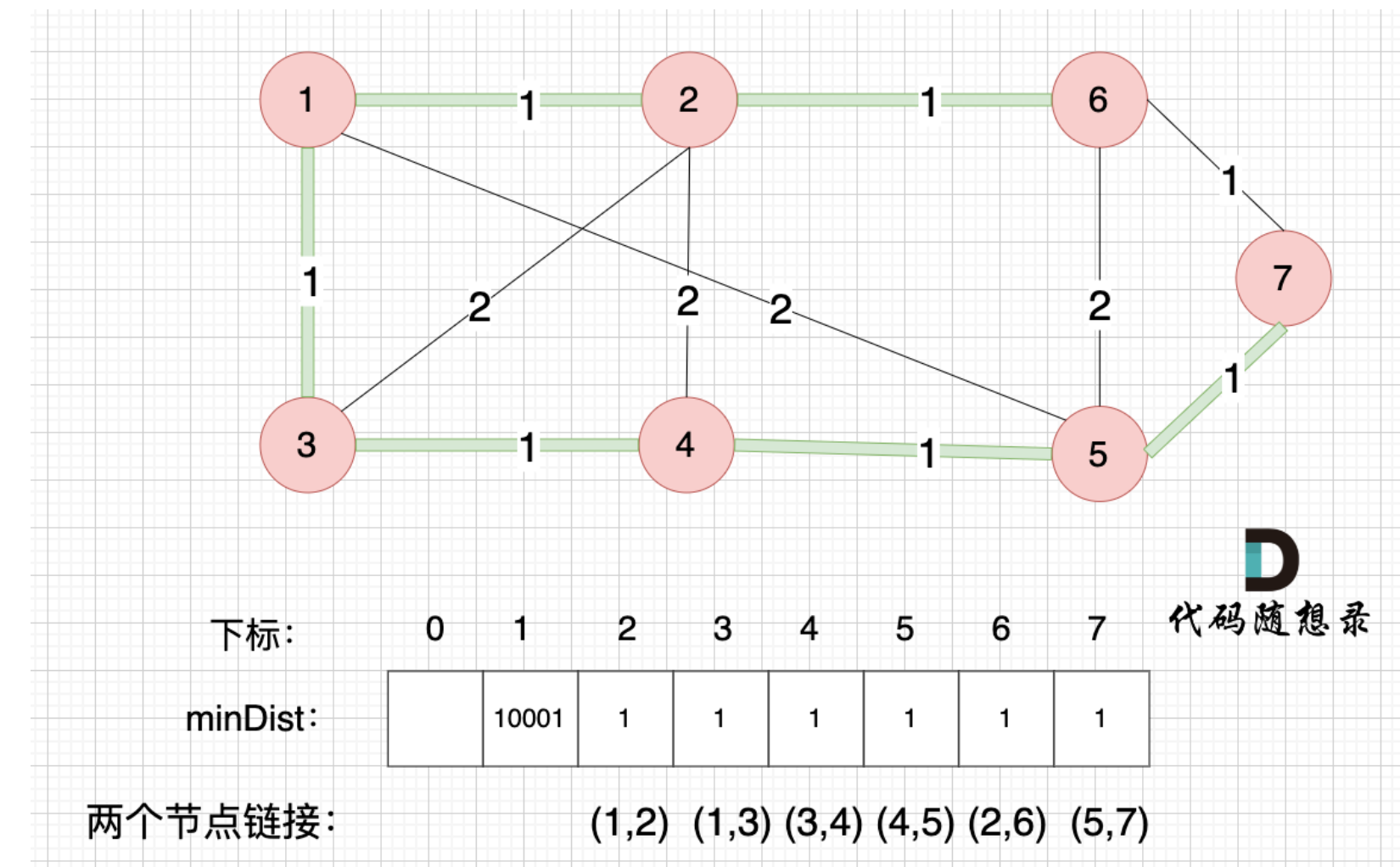
prim算法核心就是三步,我称为prim三部曲,大家一定要熟悉这三步,代码相对会好些很多:
- 第一步,选距离生成树最近节点(即选择下一个没有被访问过,且最短路径的节点)
- 第二步,最近节点加入生成树(即把刚访问的节点设置成已访问)
- 第三步,更新非生成树节点到生成树的距离(即更新minDist数组)
java
import java.util.*;
public class Main {
public static void main(String[] args) {
Scanner scanner = new Scanner(System.in);
int v = scanner.nextInt();
int e = scanner.nextInt();
// 初始化邻接矩阵,所有值初始化为一个大值,表示无穷大
int[][] grid = new int[v + 1][v + 1];
for (int i = 0; i <= v; i++) {
Arrays.fill(grid[i], 10001);
}
// 读取边的信息并填充邻接矩阵
for (int i = 0; i < e; i++) {
int x = scanner.nextInt();
int y = scanner.nextInt();
int k = scanner.nextInt();
grid[x][y] = k;
grid[y][x] = k;
}
// 所有节点到最小生成树的最小距离
int[] minDist = new int[v + 1];
Arrays.fill(minDist, 10001);
// 记录节点是否在树里
boolean[] isInTree = new boolean[v + 1];
// Prim算法主循环
for (int i = 1; i < v; i++) {
int cur = -1;
int minVal = Integer.MAX_VALUE;
// 选择距离生成树最近的节点
for (int j = 1; j <= v; j++) {
if (!isInTree[j] && minDist[j] < minVal) {
minVal = minDist[j];
cur = j;
}
}
// 将最近的节点加入生成树
isInTree[cur] = true;
// 更新非生成树节点到生成树的距离
for (int j = 1; j <= v; j++) {
if (!isInTree[j] && grid[cur][j] < minDist[j]) {
minDist[j] = grid[cur][j];
}
}
}
// 统计结果
int result = 0;
for (int i = 2; i <= v; i++) {
result += minDist[i];
}
System.out.println(result);
scanner.close();
}
}2.最小生成树,kruskal算法
概念:
prim 算法是维护节点的集合,而 Kruskal 是维护边的集合。
选择最小的边,当所选边的节点形成了环,则选择结束,生成最小生成树
过程:
kruscal的思路:
- 边的权值排序,因为要优先选最小的边加入到生成树里
- 遍历排序后的边
- 如果边首尾的两个节点在同一个集合,说明如果连上这条边图中会出现环
- 如果边首尾的两个节点不在同一个集合,加入到最小生成树,并把两个节点加入同一个集合
但在代码中,如果将两个节点加入同一个集合,又如何判断两个节点是否在同一个集合呢?
使用并查集。
- 将两个元素添加到一个集合中
- 判断两个元素在不在同一个集合
java
import java.util.*;
class Edge {
int l, r, val;
Edge(int l, int r, int val) {
this.l = l;
this.r = r;
this.val = val;
}
}
public class Main {
private static int n = 10001;
private static int[] father = new int[n];
// 并查集初始化
public static void init() {
for (int i = 0; i < n; i++) {
father[i] = i;
}
}
// 并查集的查找操作
public static int find(int u) {
if (u == father[u]) return u;
return father[u] = find(father[u]);
}
// 并查集的加入集合
public static void join(int u, int v) {
u = find(u);
v = find(v);
if (u == v) return;
father[v] = u;
}
public static void main(String[] args) {
Scanner scanner = new Scanner(System.in);
int v = scanner.nextInt();
int e = scanner.nextInt();
List<Edge> edges = new ArrayList<>();
int result_val = 0;
for (int i = 0; i < e; i++) {
int v1 = scanner.nextInt();
int v2 = scanner.nextInt();
int val = scanner.nextInt();
edges.add(new Edge(v1, v2, val));
}
// 执行Kruskal算法
edges.sort(Comparator.comparingInt(edge -> edge.val));
// 并查集初始化
init();
// 从头开始遍历边
for (Edge edge : edges) {
int x = find(edge.l);
int y = find(edge.r);
if (x != y) {
result_val += edge.val;
join(x, y);
}
}
System.out.println(result_val);
scanner.close();
}
}3.拓扑排序
概念:
拓扑排序在文件处理上也有应用,我们在做项目安装文件包的时候,经常发现 复杂的文件依赖关系, A依赖B,B依赖C,B依赖D,C依赖E 等等。
拓扑排序就是专门解决如果依赖关系是一百对呢,一千对甚至上万个依赖关系,这些依赖关系中可能还有循环依赖,你如何发现循环依赖呢,又如果排出线性顺序呢。
概括来说,给出一个 有向图,把这个有向图转成线性的排序 就叫拓扑排序。
当然拓扑排序也要检测这个有向图 是否有环,即存在循环依赖的情况,因为这种情况是不能做线性排序的。
所以拓扑排序也是图论中判断有向无环图的常用方法。
过程:
其实只要能在把 有向无环图 进行线性排序 的算法 都可以叫做 拓扑排序。
实现拓扑排序的算法有两种:卡恩算法(BFS)和DFS
接下来我给出 拓扑排序的过程,其实就两步:
- 找到入度为0 的节点,加入结果集
- 将该节点从图中移除
java
package kanong;
import java.util.*;
public class ruan117 {
public static void main(String[] args) {
Scanner sc=new Scanner(System.in);
int n = sc.nextInt();
int m = sc.nextInt();
List<List<Integer>> list=new ArrayList<>();
for (int i = 0; i < n; i++) {
list.add(new ArrayList<>());
}
int[] a=new int[n];
for (int i = 0; i < m; i++) {
int x = sc.nextInt();
int y = sc.nextInt();
list.get(x).add(y);
a[y]++;
}
Queue<Integer> queue=new LinkedList<>();
for (int i = 0; i < n; i++) {
if (a[i]==0){
queue.add(i);
}
}
List<Integer> result=new ArrayList<>();
while (!queue.isEmpty()){
Integer cur = queue.poll();
result.add(cur);
for(Integer j:list.get(cur)){
a[j]--;
if (a[j]==0){
queue.add(j);
}
}
}
if (result.size() == n) {
for (int i = 0; i < result.size(); i++) {
System.out.print(result.get(i));
if (i < result.size() - 1) {
System.out.print(" ");
}
}
} else {
System.out.println(-1);
}
}
}4.最短路径:dijkstra 算法
概念:
求最短路径,最短路是图论中的经典问题即:给出一个有向图,一个起点,一个终点,问起点到终点的最短路径。
dijkstra算法:在有权图(权值非负数)中求从起点到其他节点的最短路径算法。
需要注意两点:
- dijkstra 算法可以同时求起点到所有节点的最短路径
- 权值不能为负数
过程:
dijkstra三部曲:
- 第一步,选源点到哪个节点近且该节点未被访问过
- 第二步,该最近节点被标记访问过
- 第三步,更新非访问节点到源点的距离(即更新minDist数组)
java
import java.util.Arrays;
import java.util.Scanner;
public class Main {
public static void main(String[] args) {
Scanner scanner = new Scanner(System.in);
int n = scanner.nextInt();
int m = scanner.nextInt();
int[][] grid = new int[n + 1][n + 1];
for (int i = 0; i <= n; i++) {
Arrays.fill(grid[i], Integer.MAX_VALUE);
}
for (int i = 0; i < m; i++) {
int p1 = scanner.nextInt();
int p2 = scanner.nextInt();
int val = scanner.nextInt();
grid[p1][p2] = val;
}
int start = 1;
int end = n;
// 存储从源点到每个节点的最短距离
int[] minDist = new int[n + 1];
Arrays.fill(minDist, Integer.MAX_VALUE);
// 记录顶点是否被访问过
boolean[] visited = new boolean[n + 1];
minDist[start] = 0; // 起始点到自身的距离为0
for (int i = 1; i <= n; i++) { // 遍历所有节点
int minVal = Integer.MAX_VALUE;
int cur = 1;
// 1、选距离源点最近且未访问过的节点
for (int v = 1; v <= n; ++v) {
if (!visited[v] && minDist[v] < minVal) {
minVal = minDist[v];
cur = v;
}
}
visited[cur] = true; // 2、标记该节点已被访问
// 3、第三步,更新非访问节点到源点的距离(即更新minDist数组)
for (int v = 1; v <= n; v++) {
if (!visited[v] && grid[cur][v] != Integer.MAX_VALUE && minDist[cur] + grid[cur][v] < minDist[v]) {
minDist[v] = minDist[cur] + grid[cur][v];
}
}
}
if (minDist[end] == Integer.MAX_VALUE) {
System.out.println(-1); // 不能到达终点
} else {
System.out.println(minDist[end]); // 到达终点最短路径
}
}
}dijkstra与prim算法的区别
prim是求非访问节点到最小生成树的最小距离(即是求非访问节点到上一个节点的最小距离)
而 dijkstra是求 非访问节点到源点的最小距离。
5.最短路径(支持负数)Bellman_ford 算法
概念:
Bellman_ford算法的核心思想是 对所有边进行松弛n-1次操作(n为节点数量),从而求得目标最短路。
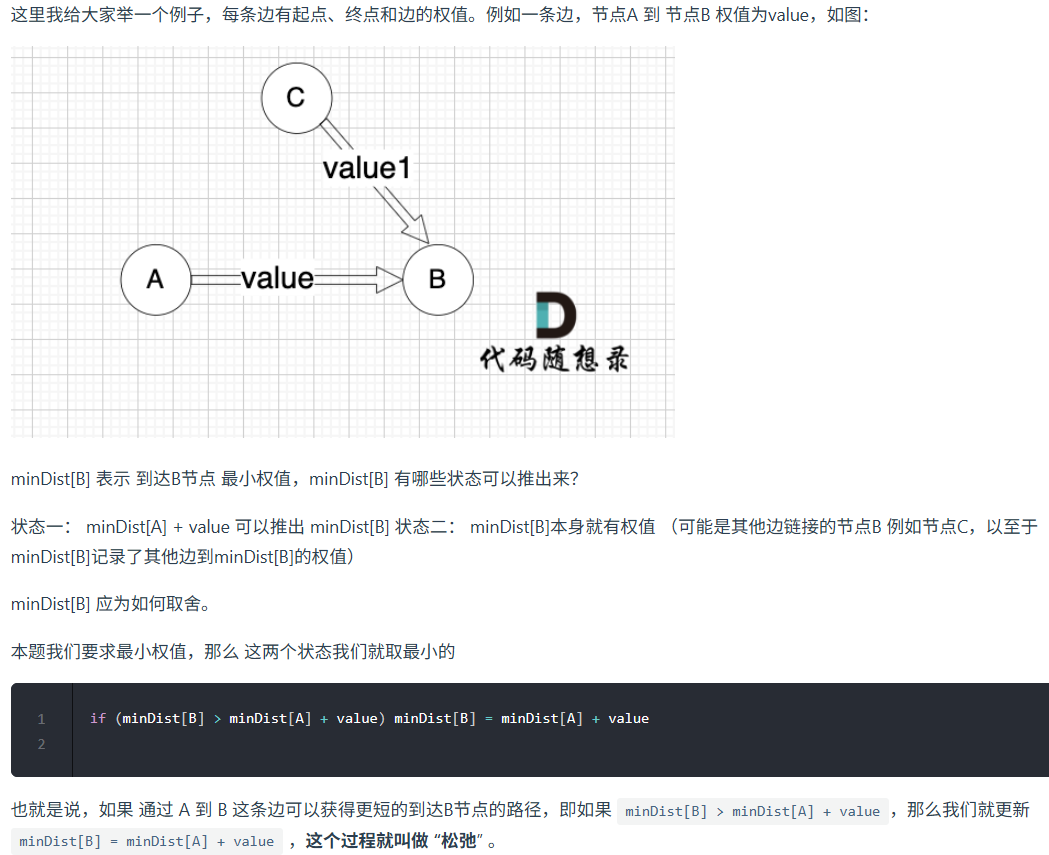
过程:
需要对所有边松弛几次才能得到 起点(节点1) 到终点(节点6)的最短距离呢?
节点数量为n,那么起点到终点,最多是 n-1 条边相连。
那么无论图是什么样的,边是什么样的顺序,我们对所有边松弛 n-1 次 就一定能得到 起点到达 终点的最短距离。
其实也同时计算出了,起点到达所有节点的最短距离,因为所有节点与起点连接的边数最多也就是 n-1 条边。
那么Bellman_ford的解题解题过程其实就是对所有边松弛 n-1 次,然后得出得到终点的最短路径。
java
package kanong;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.List;
import java.util.Scanner;
public class city94 {
static class Edge{
int from;
int to;
int val;
public Edge(int from,int to,int val){
this.from=from;
this.to=to;
this.val=val;
}
}
public static void main(String[] args) {
Scanner sc=new Scanner(System.in);
int n = sc.nextInt();
int m = sc.nextInt();
List<Edge> list=new ArrayList<>();
for (int i = 0; i < m; i++) {
int form = sc.nextInt();
int to = sc.nextInt();
int val = sc.nextInt();
list.add(new Edge(form,to,val));
}
int[] minDist=new int[n+1];
Arrays.fill(minDist,Integer.MAX_VALUE);
minDist[1]=0;
for (int i = 1; i <=n ; i++) {
for(Edge e:list){
if (minDist[e.from]<Integer.MAX_VALUE&&minDist[e.to]>minDist[e.from]+e.val){
minDist[e.to]=minDist[e.from]+e.val;
}
}
}
if (minDist[n]<Integer.MAX_VALUE){
System.out.println(minDist[n]);
}else{
System.out.println("unconnected");
}
}
}减少松弛次数,优化
java
import java.util.*;
public class Main {
// Define an inner class Edge
static class Edge {
int from;
int to;
int val;
public Edge(int from, int to, int val) {
this.from = from;
this.to = to;
this.val = val;
}
}
public static void main(String[] args) {
// Input processing
Scanner sc = new Scanner(System.in);
int n = sc.nextInt();
int m = sc.nextInt();
List<List<Edge>> graph = new ArrayList<>();
for (int i = 0; i <= n; i++) {
graph.add(new ArrayList<>());
}
for (int i = 0; i < m; i++) {
int from = sc.nextInt();
int to = sc.nextInt();
int val = sc.nextInt();
graph.get(from).add(new Edge(from, to, val));
}
// Declare the minDist array to record the minimum distance form current node to the original node
int[] minDist = new int[n + 1];
Arrays.fill(minDist, Integer.MAX_VALUE);
minDist[1] = 0;
// Declare a queue to store the updated nodes instead of traversing all nodes each loop for more efficiency
Queue<Integer> queue = new LinkedList<>();
queue.offer(1);
// Declare a boolean array to record if the current node is in the queue to optimise the processing
boolean[] isInQueue = new boolean[n + 1];
while (!queue.isEmpty()) {
int curNode = queue.poll();
isInQueue[curNode] = false; // Represents the current node is not in the queue after being polled
for (Edge edge : graph.get(curNode)) {
if (minDist[edge.to] > minDist[edge.from] + edge.val) { // Start relaxing the edge
minDist[edge.to] = minDist[edge.from] + edge.val;
if (!isInQueue[edge.to]) { // Don't add the node if it's already in the queue
queue.offer(edge.to);
isInQueue[edge.to] = true;
}
}
}
}
// Outcome printing
if (minDist[n] == Integer.MAX_VALUE) {
System.out.println("unconnected");
} else {
System.out.println(minDist[n]);
}
}
}