****论文题目:****CWNet: Causal Wavelet Network for Low-Light Image Enhancement(用于微光图像增强的因果小波网络)
会议:ICCV2025
****摘要:****传统的微光图像增强(LLie)方法主要关注均匀的亮度调整,往往忽略了实例级的语义信息和不同特征的内在特征。为了解决这些局限性,我们提出了一种利用小波变换进行因果推理的新型结构--CWNet(因果小波网络)。具体地说,我们的方法包括两个关键部分:1)受因果关系干预概念的启发,我们采用因果推理的观点来揭示微光增强中潜在的因果关系。从全局的角度来看,我们使用度量学习策略来确保因果嵌入遵循因果原则,将它们与非因果混淆因素分开,同时关注因果因素的不变性。在局部层次上,我们引入了实例级的裁剪语义损失来精确地维护因果因素的一致性。2)在因果分析的基础上,提出了一种基于小波变换的主干网络,该网络有效地优化了频率信息的恢复,确保了针对小波变换特定属性的精确增强。大量的实验表明,CWNet在多个数据集上的性能显著优于当前最先进的方法,展示了其在不同场景中的健壮性能。
CWNet:用因果推理和小波变换重新定义低光照图像增强
一、论文指出的问题
在深入介绍 CWNet 之前,我们先梳理一下这篇论文的出发点------现有方法存在哪些核心局限。
1.1 忽视实例级语义信息
传统低光照增强(LLIE)方法的目标几乎全部集中在均匀亮度调整 上,不论是 gamma 校正、Retinex 理论还是直方图均衡化,都把图像视为一个整体来提亮。深度学习方法虽然有所改进,但同样缺乏对实例级语义信息的建模。论文通过 ATE(平均处理效应)热力图分析直观地证明了这一点:不同语义区域(如天空、建筑、植被)对光照退化的敏感程度差异显著,但现有方法对所有区域一视同仁。

【此处配图:图2 --- ATE 热力图分析。展示 Ground Truth、光照退化样本、颜色异常样本,以及对应的 ATE 热力图,亮度越高代表该区域对退化越敏感。】
1.2 频率域特征利用不充分
基于频率域的方法是 LLIE 的重要分支。论文指出当前方法存在两类问题:
- 基于傅里叶变换的方法(如 FourLLIE、DMFourLLIE)擅长捕获全局低频信息、整体提亮,但缺乏空间局部性,难以保留边缘和纹理等高频细节,往往"亮了但糊了"。
- 基于小波变换的方法 (如 Wave-Mamba)虽然具有优秀的空间局部性,能够分离图像内容和噪声,但没有充分利用小波频域各子带的独特特性(水平、垂直、对角高频分量各有不同的物理意义),限制了恢复潜力。
1.3 颜色和语义一致性难以保证
许多先进方法在提升亮度的同时,会出现颜色偏移或语义失真。虽然部分工作(如 SKF)引入了语义分割网络来辅助增强,CLIP 也被一些方法用于语义引导,但这些方法只关注全局语义一致性,缺乏实例级(instance-level)的精细一致性保障。
二、CWNet 的核心创新
针对上述三大问题,CWNet 提出了两条主线创新,共同构成一个有机整体。
2.1 创新一:面向 LLIE 的因果推理框架
这是本文最具理论深度的贡献。
2.1.1 结构因果模型(SCM)
论文首先为 LLIE 任务建立了一个结构因果模型(Structural Causal Model, SCM)。在这个框架下,图像的特征被分为两类:
- 因果因子 S(Causal Factors) :语义信息,如物体的形状、结构、纹理------这是增强过程中应当保持不变的;
- 非因果因子 U(Non-Causal Factors) :亮度异常和颜色偏移------这是增强过程中应当被过滤掉的。
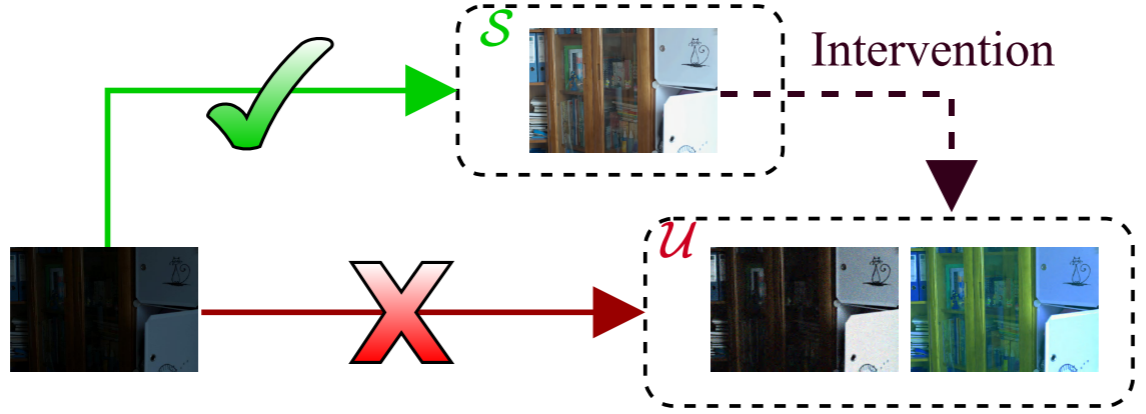
【此处配图:图1 --- LLIE 的结构因果模型(SCM)。展示因果因子 S 与非因果因子 U 的关系,以及干预(Intervention)操作。】
2.1.2 有意义且无害的因果干预
为了让因果分析具有实际操作性,论文设计了两种施加在正常光照图像上的合成退化干预:
光照退化干预:基于物理照明退化模型,对正常光图像 I 生成低光版本:
其中 L 是通过 LIME 生成的光照图, 控制退化程度,
是均值为 0、方差在
之间的高斯噪声。这种方式在保留语义内容的同时实现了真实的亮度变化。
颜色异常干预 :对正常光图像施加色调偏移()、饱和度偏移(
)和 RGB 通道偏移(
):
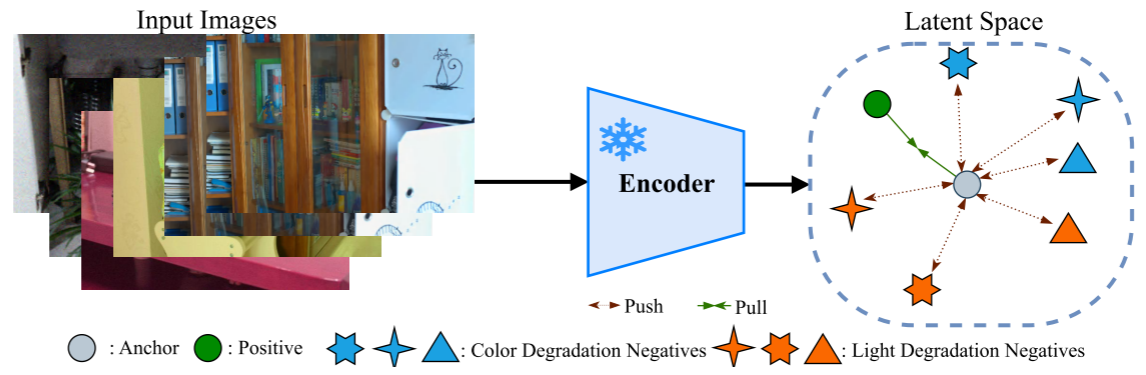
【此处配图:图3(a) --- 因果引导的度量学习策略。展示潜在空间中 Anchor(低光处理图)、Positive(正常光参考)、颜色退化负样本(蓝色)、光照退化负样本(橙色)的组织方式,以及 Push/Pull 操作。】
2.1.3 因果引导的度量学习(全局一致性)
基于上述干预,论文设计了因果引导的度量学习策略来实现全局因果一致性:
- 锚点(Anchor):经过网络处理的低光图像;
- 正样本(Positive):与锚点对应的正常光参考图(共享相同的因果语义因子);
- 负样本 :对不同场景的正常光图像施加颜色扰动(颜色退化负样本)或亮度扰动(光照退化负样本)生成的反事实样本。
这种策略刻意排除其他低光图像作为负样本,防止模型混淆因果特征和非因果特征,迫使模型专注于辨别根本性的语义差异。度量损失定义为:
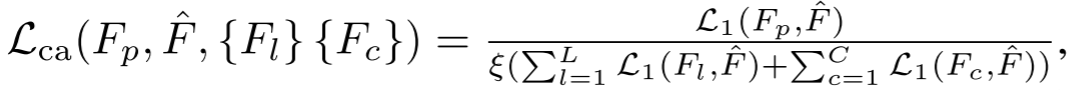
其中 归一化光照和颜色负样本的贡献。
2.1.4 实例级 CLIP 语义损失(局部一致性)
全局度量学习无法处理 ATE 分析揭示的区域级敏感性差异 。因此,论文引入了实例级 CLIP 语义损失来保障局部一致性:
- 使用在 PASCAL-Context 上预训练的 HRNet 对增强结果
提取语义实例分割图
- 每个实例子图与可学习的文本提示一起送入 CLIP 编码器计算语义相似度分数;
- 用交叉熵损失优化,使增强后的每个实例在语义空间中向正常光靠拢:
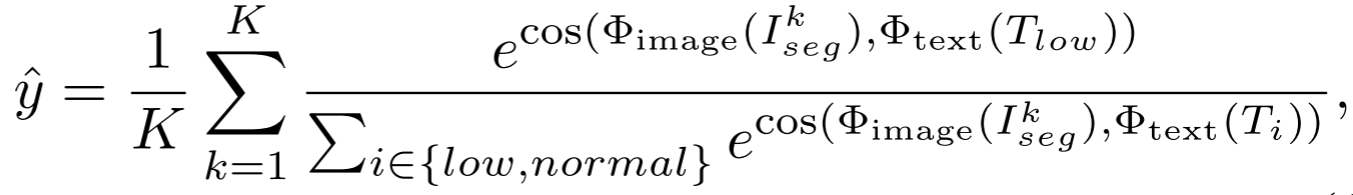
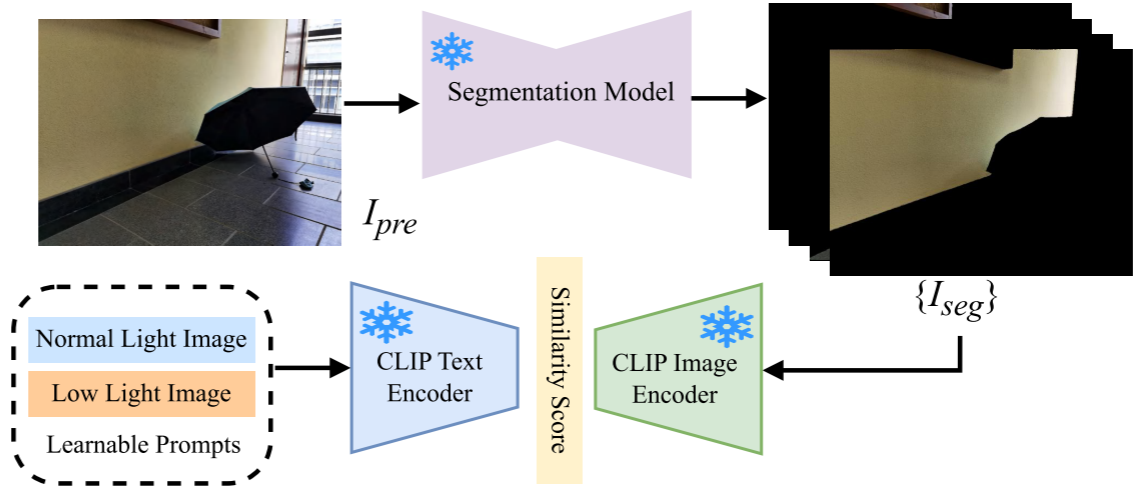
【此处配图:图3(b) --- 实例级 CLIP 语义损失。展示 HRNet 分割 → 实例子图 → CLIP 编解码器 → 相似度分数的完整流程。】
2.2 创新二:因果小波网络(CWNet)主干
基于 SCM 的分析,论文设计了 CWNet 作为实现因果一致性的"药方"(论文用一个有趣的类比:低光图像是患者,网络主干是药物,因果分析是精密的测量仪器)。
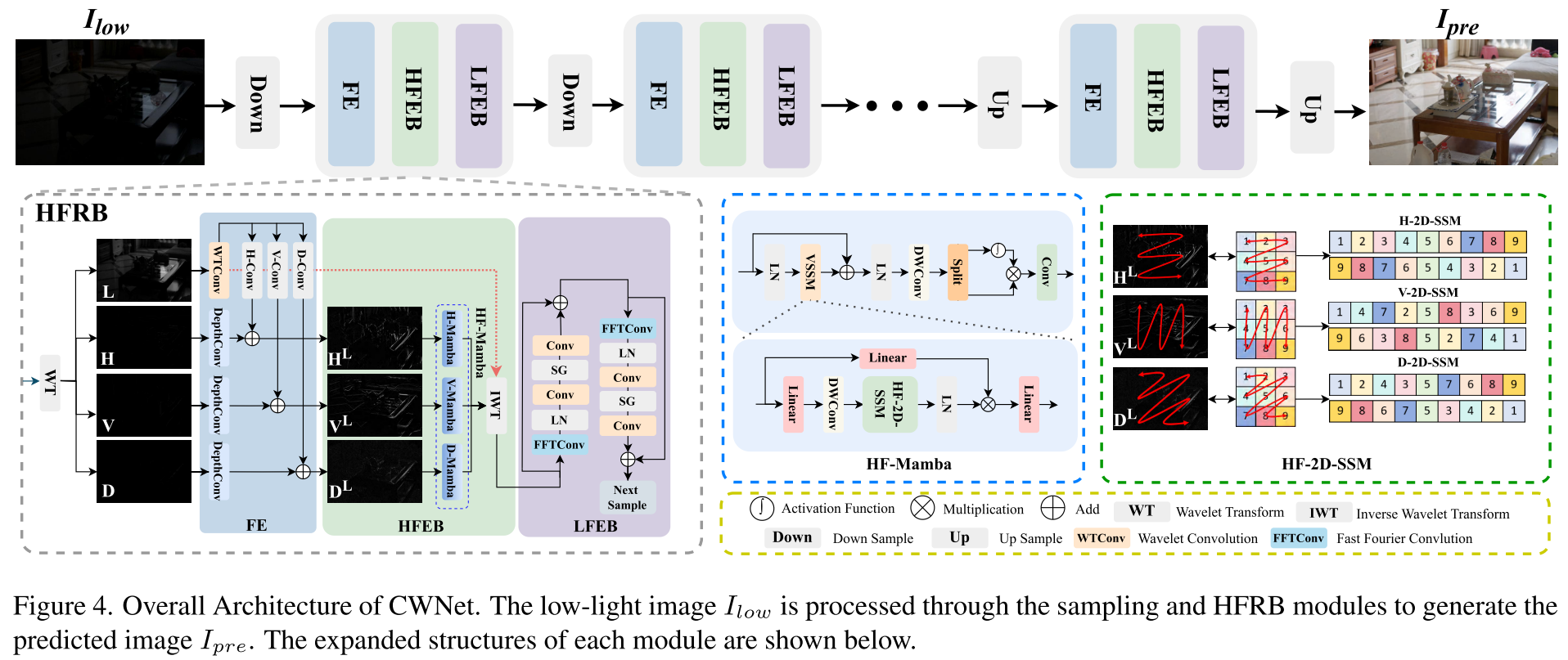
【此处配图:图4 --- CWNet 整体架构图。展示从
CWNet 采用类 U-Net 结构,核心模块是层次特征恢复块(Hierarchical Feature Restoration Block, HFRB),包含三个子模块:特征提取(FE)、高频增强块(HFEB)、低频增强块(LFEB)。
2.2.1 特征提取(FE)
对输入低光图像进行小波变换(WT),分解为四个频率子带:
其中 分别代表低频分量、水平/垂直/对角高频分量。
FE 的设计充分考虑了各子带的物理特性:
- 高频子带(H, V, D):用深度可分离卷积(DepthConv)提取,捕获方向性边缘细节;
- 低频子带 (L):用 WTConv(小波卷积)处理,在不增加参数量的前提下获得更大感受野;
- 关键的跨频率补偿 :低频特征
这一设计基于一个重要观察:在低光场景下,高频细节(边缘、纹理)的信息大量"藏"在低频分量中,通过低频引导高频提取可以有效补偿缺失信息。
2.2.2 高频增强块(HFEB)
论文受 State Space Model(SSM)/ Mamba 启发,提出 HF-Mamba 处理高频子带。
现有大多数方法(如 Wave-Mamba、RetinexMamba)直接沿用 VMamba 的通用 2D-SSM 结构扫描所有方向,论文认为这没有充分利用小波高频分量的方向性特性。CWNet 专门设计了:
- H-2D-SSM :水平方向扫描处理
- V-2D-SSM :垂直方向扫描处理
- D-2D-SSM :对角方向扫描处理
这种"扫描方向与小波高频分量方向一致"的设计,使高频细节的恢复更加精准。
2.2.3 低频增强块(LFEB)
HFEB 完成高频增强后,先用逆小波变换(IWT)重建图像:
重建图像作为 LFEB 的输入。LFEB 由两个残差块构成,均采用**快速傅里叶卷积(FFC)**以获得更大感受野:
- 第一个残差块:5×5 卷积扩展感受野 + SimpleGate 高效激活 + 1×1 卷积恢复维度;
- 第二个残差块:1×1 卷积将通道数扩至 4 倍 + SimpleGate + 1×1 卷积压缩回原始通道数。
最终,低频分量在高频分量的引导下得到精细化,生成增强预测结果 I_{pre}。
2.3 总损失函数
CWNet 的总损失由五部分组成:
各权重设置为 :
三、实验结果
3.1 训练设置
- 框架:PyTorch,端到端训练;
- 架构:类 U-Net,特征通道数 16,低频/高频分支的非对称块配置分别为 1,3,4,3,1 和 1,2,2,2,1;
- 数据增强:随机裁剪至 256×256,随机水平/垂直翻转和旋转;
- 优化器 :Adam(
- 训练量 :
- 测试数据集:LOL-v1、LOL-v2-Real(用 LOL-v1 训练的模型测试,验证跨数据集泛化)、LOL-v2-Syn、LSRW-Huawei。
3.2 定量对比
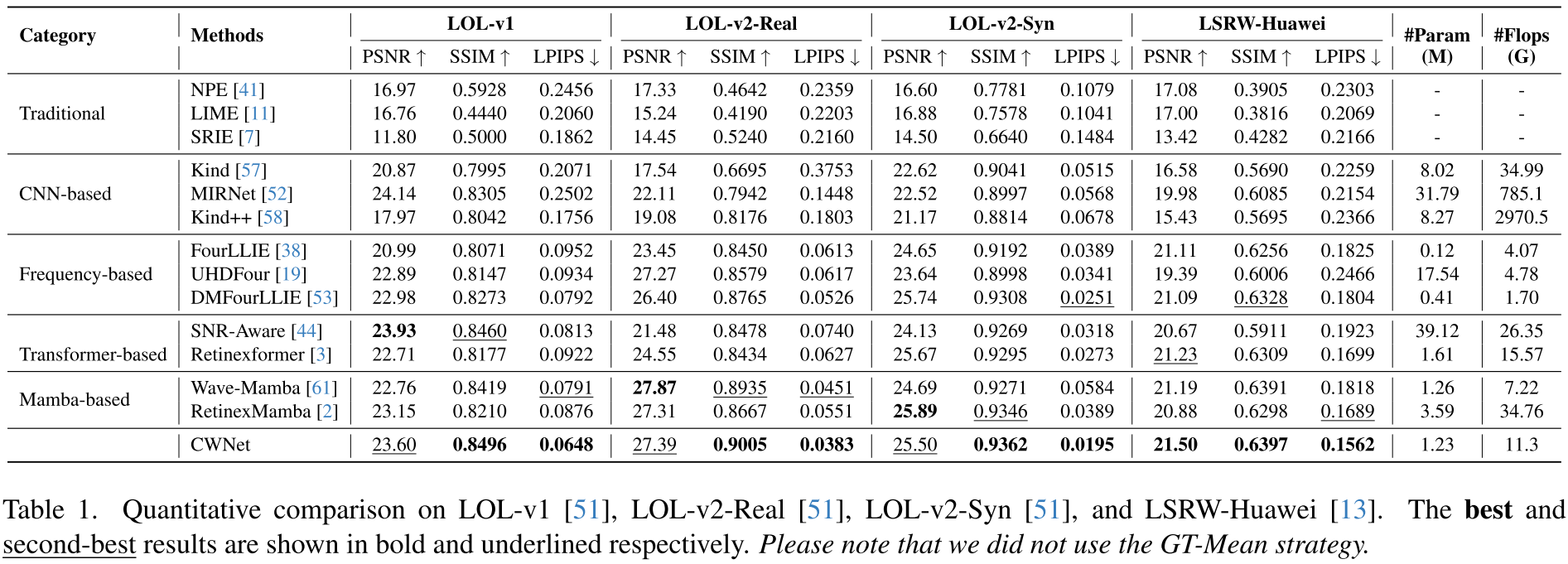
【此处配表:表1 --- 在 LOL-v1、LOL-v2-Real、LOL-v2-Syn、LSRW-Huawei 四个数据集上与传统方法、CNN 方法、频率域方法、Transformer 方法、Mamba 方法的 PSNR/SSIM/LPIPS 全面对比,以及参数量(M)和 FLOPs(G)。】
核心数据一览:
| 数据集 | PSNR | SSIM | LPIPS |
|---|---|---|---|
| LOL-v1 | 23.60 dB | 0.8496 | 0.0648 |
| LOL-v2-Real(跨数据集) | 27.39 dB | 0.9005(最优) | 0.0383(最优) |
| LOL-v2-Syn | 25.50 dB | 0.9362(最优) | 0.0195(最优) |
| LSRW-Huawei | 21.50 dB | 0.6397 | 0.1562(最优) |
参数与计算效率 :仅 1.23M 参数 ,11.3G FLOPs,在所有深度学习方法中属于最轻量级别。显著优于 MIRNet(31.79M 参数,785.1G FLOPs)和 SNR-Aware(39.12M 参数,26.35G FLOPs)。
特别值得注意的是 LOL-v2-Real 的跨数据集结果:用 LOL-v1 训练的模型直接在 LOL-v2-Real 上测试,取得最优 SSIM(0.9005)和最低 LPIPS(0.0383),充分证明了因果推理框架带来的强泛化能力。
3.3 定性可视化对比

【此处配图:图5 --- LOL-v2-Real 数据集上与 FECNet、FourLLIE、Wave-Mamba、Retinexformer、SKF-SNR、UHDFormer、UHDFour 的视觉对比。】

【此处配图:图6 --- LSRW-Huawei 数据集上与 FECNet、FourLLIE、Wave-Mamba、Retinexformer、SKF-SNR、UHDFormer、DMFourLLIE 的视觉对比。】
在视觉效果上,对比方法普遍存在以下问题:
- FECNet、FourLLIE、Wave-Mamba:颜色偏差和噪声;
- Retinexformer、SKF-SNR:提亮不足;
- UHDFormer、UHDFour:表现较好但仍有噪声伪影,缺乏平滑性。
CWNet 产生的结果更清晰、自然、平滑,颜色和语义更为一致。
四、消融实验
4.1 组件消除实验
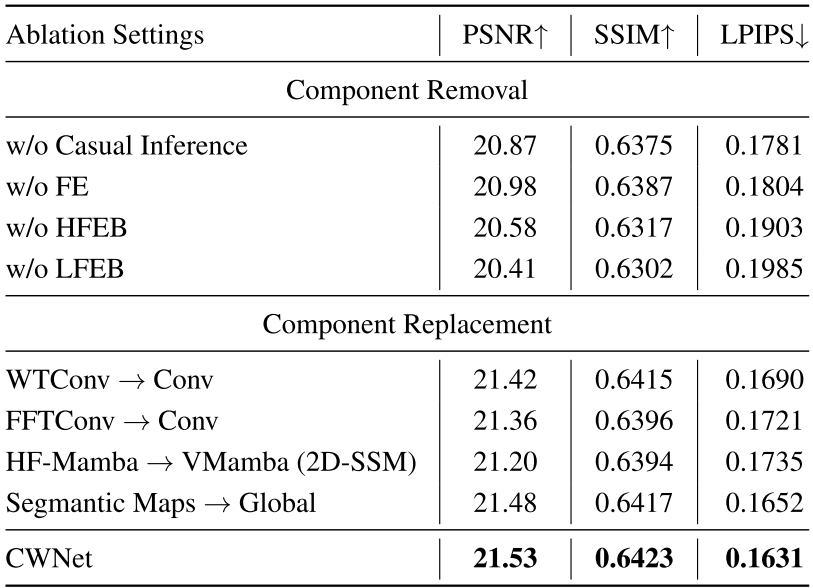
【表2(上半部分) --- 逐个去除因果推理机制、FE、HFEB、LFEB 在 LSRW-Huawei 上的性能变化。】
各组件对 PSNR 的贡献:
| 去除组件 | PSNR | 下降幅度 |
|---|---|---|
| 完整 CWNet | 21.53 | --- |
| 去除因果推理 | 20.87 | -0.66 dB(最大) |
| 去除 FE | 20.98 | -0.55 dB |
| 去除 HFEB | 20.58 | -0.95 dB |
| 去除 LFEB | 20.41 | -1.12 dB(影响最大) |
LFEB 的去除导致最大幅度的性能下降(PSNR 降至 20.41 dB),说明低频处理在整个双分支架构中扮演着最关键的角色。
4.2 组件替换实验
【表2(下半部分) --- 用标准卷积替换 WTConv/FFTConv,用 VMamba 替换 HF-Mamba,用全局特征替换语义图的性能对比。】
| 替换方案 | PSNR | 说明 |
|---|---|---|
| WTConv → 标准卷积 | 21.42 | 频率域处理有效 |
| FFTConv → 标准卷积 | 21.36 | 全局感受野有效 |
| HF-Mamba → VMamba 2D-SSM | 21.20 | 方向对齐扫描有效 |
| 语义图 → 全局特征 | 21.48 | 实例级一致性有效 |
4.3 损失权重分析
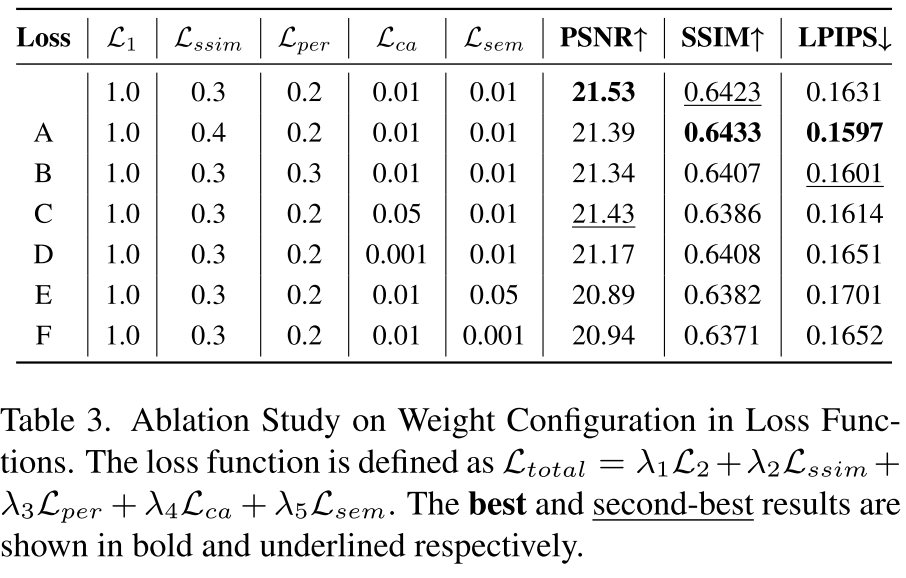
【此处配表:表3 --- 系统变化各损失权重(
基线配置()取得最优 PSNR(21.53)和次优 SSIM(0.6423)。实验表明:
- 增大
五、局限性与失败案例

【此处配图:图7 --- 多退化场景下的失败案例。展示同时存在模糊或雾霾时,CWNet 与 Retinexformer、RetinexMamba、Wave-Mamba、UHDFormer 的对比。】
论文坦诚地指出,当图像同时面临多种退化(如低光 + 模糊、低光 + 雾霾)时,CWNet 虽然在亮度和颜色保持上优于对比方法,但整体恢复质量不理想。这为后续研究指明了方向:如何在多退化条件下实现更有效的低光图像恢复。
六、因果与小波的哲学连接
【此处配图:图8 --- 小波结构与因果推理的类比图。因果推理 ≈ 精密测量仪器,低光图像 ≈ 患者,网络主干 ≈ 药物。】
论文用一个生动的类比来解释 CWNet 的可解释性:
- 低光图像是需要治疗的患者;
- 因果推理机制是精密的测量仪器,确保治疗精准定位到问题所在(分离因果因子和非因果因子);
- 小波网络主干是药物,其架构设计直接决定治疗效果------低频增强负责颜色和亮度一致性,高频 Mamba 一致性扫描负责细节建模和结构一致性。
七、总结与思考
CWNet 的核心贡献可以归结为一句话:用因果推理"想清楚了该做什么",再用小波网络"精准地做到"。
从研究方法论的角度看,这篇论文有几点值得特别关注:
-
理论驱动的框架设计:引入 SCM 和 ATE 分析不仅仅是方法的"包装",而是真正指导了网络架构(为什么需要实例级而非全局语义损失)和训练策略(为什么要构造特定类型的负样本)的设计。
-
轻量与高性能的平衡:1.23M 参数和 11.3G FLOPs 的代价换来了多数据集 SOTA,这得益于小波变换天然的高效性(下采样减少空间维度)和 Mamba 相比 Transformer 的线性计算复杂度。
-
跨数据集泛化的意义:在 LOL-v2-Real 上的跨数据集测试(用 LOL-v1 训练)取得最优 SSIM 和 LPIPS,这是对因果推理框架"分离不变因果特征"这一核心目标最直接的验证。
-
局限性的坦诚:论文没有回避多退化场景下的失败案例,这种学术诚实值得肯定,也为后续研究留下了清晰的开放问题。
如果你对低光照图像增强、因果推理在视觉任务中的应用,或者 Mamba/SSM 模型有兴趣,欢迎进一步探讨。