Java 线程池:从参数到拒绝策略
目录
- 为什么需要线程池
- 线程池核心参数
- 任务提交流程
- 拒绝策略
- [Executors 的几个预设线程池](#Executors 的几个预设线程池)
- [execute 和 submit 的区别](#execute 和 submit 的区别)
- 小结
为什么需要线程池
new Thread() 每次调用都会创建一个新线程。创建线程要分配栈空间、要向操作系统申请资源,一个线程默认占 1MB 核外内存。如果请求量变大,线程数随之暴涨,内存就有可能扛不住,CPU 忙着调度线程而不是执行业务逻辑,直接内存溢出了。
所以需要线程池来管理线程:提前创建好一批线程,有任务来了就分配一个去执行,执行完把线程还回来,下一个任务继续用。
线程池核心参数
ThreadPoolExecutor 是 Java 线程池的核心类,构造函数有七个参数:
java
public ThreadPoolExecutor(
int corePoolSize, // 核心线程数
int maximumPoolSize, // 最大线程数
long keepAliveTime, // 临时线程存活时间
TimeUnit unit, // 时间单位
BlockingQueue<Runnable> workQueue, // 任务队列
ThreadFactory threadFactory, // 线程工厂
RejectedExecutionHandler handler // 拒绝策略
)逐个来看。
corePoolSize(核心线程数): 线程池里长期存活的线程数量。对应后厨的"正式厨师",不管忙不忙都在岗。默认情况下,即使核心线程空闲也不会被回收,除非设置了 allowCoreThreadTimeOut(true)。
maximumPoolSize(最大线程数): 线程池最多能容纳的线程数。核心线程全忙、队列也满了,才会创建临时线程,但总数不能超过这个值。对应后厨的"正式厨师 + 临时工"的上限。
keepAliveTime(临时线程存活时间): 临时线程空闲多久后被回收。饭点过了,临时工没活干了,等一段时间还不来新单就让他们回去。注意:这个参数默认只对临时线程生效,核心线程不会被回收。
unit: keepAliveTime 的时间单位,秒、毫秒、分钟,看场景选。
workQueue(任务队列): 核心线程全忙时,新任务排在哪里等待。这是一个阻塞队列,常用的有三种:
| 队列类型 | 特点 | 适用场景 |
|---|---|---|
| LinkedBlockingQueue | 无界队列(默认 Integer.MAX_VALUE) | 任务量可控,不想丢任务 |
| ArrayBlockingQueue | 有界队列,需要指定容量 | 需要控制内存,宁可拒绝也不堆积 |
| SynchronousQueue | 不存储元素,直接交给线程 | 任务短平快,不希望排队 |
threadFactory(线程工厂): 控制线程的创建方式。可以设置线程名、是否是守护线程等。线上排查问题时,给线程起个有意义的名字比 pool-1-thread-3 好找得多:
java
ThreadFactory factory = new ThreadFactory() {
private int count = 0;
@Override
public Thread newThread(Runnable r) {
return new Thread(r, "order-pool-" + count++);
}
};handler(拒绝策略): 线程全忙、队列也满了,新来的任务怎么处理。
任务提交流程
当调用 execute(task) 提交一个任务时,线程池的处理流程是这样的:
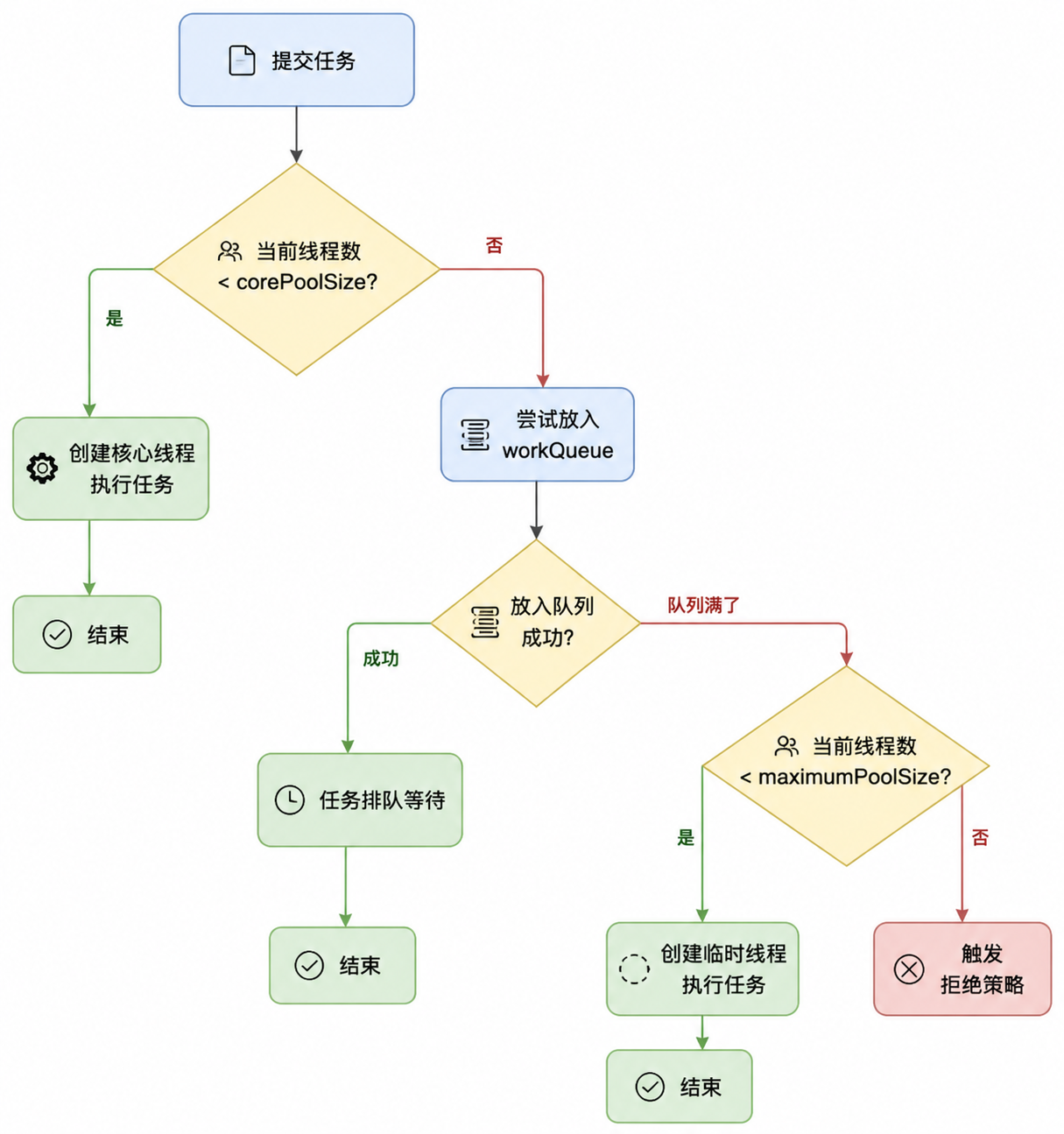
三个判断节点,三种结果:直接执行、排队等待、创建临时线程、被拒绝。任务优先排队,不是优先创建临时线程。 只有队列满了才会创建临时线程。
拒绝策略
任务被拒绝时,Java 提供了四种内置策略:
AbortPolicy(默认): 直接抛 RejectedExecutionException 异常。调用方能立刻知道任务被拒了。
CallerRunsPolicy: 谁提交的谁执行。如果主线程提交的任务被拒绝,主线程自己去执行这个任务。好处是不丢任务,坏处是会阻塞主线程,如果主线程是处理 HTTP 请求的线程,那这个请求的响应时间会变长。
DiscardPolicy: 静默丢弃。不抛异常,任务直接消失。适用于日志采集这类场景,丢几条无所谓。
DiscardOldestPolicy: 丢弃队列里等待最久的那个任务,然后重新提交当前任务。适用于只关心最新数据的场景,比如实时价格推送,旧的价格数据留着也没用。
| 策略 | 行为 | 是否丢任务 | 适用场景 |
|---|---|---|---|
| AbortPolicy | 抛异常 | 否(但中断流程) | 默认选择,需要快速失败 |
| CallerRunsPolicy | 提交者自己执行 | 否 | 不能丢任务,可接受延迟 |
| DiscardPolicy | 静默丢弃 | 是 | 允许丢失,如日志采集 |
| DiscardOldestPolicy | 丢弃最旧的 | 是 | 只关心最新数据 |
Executors 的几个预设线程池
实际开发中很少直接 new ThreadPoolExecutor(),Executors 工厂类提供了几个预设配置:
newFixedThreadPool: 固定大小线程池。核心线程数 = 最大线程数,没有临时线程。队列用 LinkedBlockingQueue(无界)。适合任务量稳定、对延迟不敏感的场景。
java
ExecutorService pool = Executors.newFixedThreadPool(5);它的问题在于队列无界 。如果任务提交速度持续高于处理速度,队列会无限增长,最终 OOM。阿里开发手册明确禁止使用 Executors 创建线程池,根源就在这个无界队列。
newCachedThreadPool: 缓存线程池。核心线程数为 0,最大线程数为 Integer.MAX_VALUE(相当于无限),临时线程空闲 60 秒后回收。队列用 SynchronousQueue,不排队,直接创建线程。
java
ExecutorService pool = Executors.newCachedThreadPool();它的问题在于线程数不设上限。如果瞬间来了大量任务,会创建大量线程,有可能把系统资源耗尽。适合任务量波动大、每个任务执行时间短的场景。
newSingleThreadExecutor: 单线程池。只有一个线程,保证任务按提交顺序执行。队列同样是无界的 LinkedBlockingQueue。
java
ExecutorService pool = Executors.newSingleThreadExecutor();适合需要严格顺序执行的场景,比如日志写入。
newScheduledThreadPool: 定时线程池。支持定时任务和周期任务,底层用 DelayedWorkQueue。适合定时轮询、心跳检测这类场景。
对比一下:
| 预设 | 核心线程 | 最大线程 | 队列 | 风险 |
|---|---|---|---|---|
| FixedThreadPool | N | N | LinkedBlockingQueue(无界) | 队列堆积导致 OOM |
| CachedThreadPool | 0 | MAX_VALUE | SynchronousQueue | 线程暴涨导致 OOM |
| SingleThreadExecutor | 1 | 1 | LinkedBlockingQueue(无界) | 队列堆积导致 OOM |
| ScheduledThreadPool | N | MAX_VALUE | DelayedWorkQueue | 相对安全 |
所以生产环境一般不直接用 Executors,而是手动 new ThreadPoolExecutor(),显式指定队列容量和拒绝策略,让系统行为可预期。
execute 和 submit 的区别
提交任务有两种方式:execute 和 submit。
java
// execute:提交 Runnable,没有返回值
executor.execute(() -> doSomething());
// submit:提交 Callable,有返回值
Future<String> future = executor.submit(() -> {
return queryFromDB();
});
String result = future.get(); // 阻塞等待结果区别在于:
execute接收Runnable,没有返回值,异常只能在任务内部捕获submit接收Callable,返回Future对象,可以通过future.get()获取结果。如果任务抛了异常,get()时会抛出ExecutionException
还有一个容易忽略的点:submit 内部把传入的 Callable 包装成了 FutureTask,然后调用的还是 execute。所以 submit 是 execute 的上层封装。
java
// submit 的简化内部实现
public Future<?> submit(Runnable task) {
FutureTask<Void> ftask = new FutureTask<>(task, null);
execute(ftask); // 最终还是调 execute
return ftask;
}怎么选?需要返回值用 submit,不需要就用 execute。如果用 submit 但不调 future.get(),异常会被吞掉,任务悄悄失败,排查起来很痛苦。
小结
线程池就是把线程的创建和回收管理起来,让系统在高并发下既不浪费资源,也不失控。 七个参数里,corePoolSize 决定常态并发能力,maximumPoolSize 决定峰值承受能力,workQueue 决定过载时的行为,handler 决定兜底策略。生产环境别用 Executors 的预设,手动 new ThreadPoolExecutor 显式指定每个参数,让线程池的行为可预期、可监控、可调优。