文章目录
-
- 每日一句正能量
- 一、前言:数据科学时代的开发新范式
- 二、环境准备:AtomCode中的数据科学工作站
-
- [2.1 开箱即用的Python环境](#2.1 开箱即用的Python环境)
- [2.2 启动Jupyter Notebook](#2.2 启动Jupyter Notebook)
- 三、数据清洗与预处理:让脏数据变干净
-
- [3.1 数据加载与初步检查](#3.1 数据加载与初步检查)
- [3.2 缺失值处理](#3.2 缺失值处理)
- [3.3 异常值检测与处理](#3.3 异常值检测与处理)
- [3.4 数据类型转换与格式标准化](#3.4 数据类型转换与格式标准化)
- [3.5 重复值处理](#3.5 重复值处理)
- [3.6 现代链式清洗模式(2026推荐)](#3.6 现代链式清洗模式(2026推荐))
- 四、探索性数据分析(EDA):发现数据中的故事
-
- [4.1 统计描述](#4.1 统计描述)
- [4.2 分组聚合分析](#4.2 分组聚合分析)
- [4.3 时间序列分析](#4.3 时间序列分析)
- 五、数据可视化:让数据开口说话
-
- [5.1 Matplotlib:基础绘图](#5.1 Matplotlib:基础绘图)
- [5.2 Seaborn:统计可视化](#5.2 Seaborn:统计可视化)
- [5.3 Plotly:交互式可视化](#5.3 Plotly:交互式可视化)
- 六、机器学习模型训练:从数据到预测
-
- [6.1 数据准备与特征工程](#6.1 数据准备与特征工程)
- [6.2 构建预处理管道](#6.2 构建预处理管道)
- [6.3 模型训练与调优](#6.3 模型训练与调优)
- [6.4 模型评估](#6.4 模型评估)
- [6.5 模型保存与加载](#6.5 模型保存与加载)
- [七、Jupyter Notebook集成体验:交互式开发的魅力](#七、Jupyter Notebook集成体验:交互式开发的魅力)
-
- [7.1 魔法命令提升效率](#7.1 魔法命令提升效率)
- [7.2 内联可视化](#7.2 内联可视化)
- [7.3 变量浏览器](#7.3 变量浏览器)
- [7.4 与AtomCode的协同优势](#7.4 与AtomCode的协同优势)
- 八、数据管道自动化:从手动到自动
-
- [8.1 使用Apache Airflow编排任务](#8.1 使用Apache Airflow编排任务)
- [8.2 轻量级替代方案:使用Python脚本 + Cron](#8.2 轻量级替代方案:使用Python脚本 + Cron)
- 九、实战案例:完整的电商销售数据分析
-
- [9.1 业务问题清单](#9.1 业务问题清单)
- [9.2 完整分析代码](#9.2 完整分析代码)
- 十、总结与展望

每日一句正能量
善良的人总是会在你难堪时,给予适时的鼓励和赞美,而不是落井下石。
真正的善意不是锦上添花,而是在别人跌倒时递上一只手。不借机踩低,也不冷眼旁观,而是用一句合时宜的话帮人重拾体面。
一、前言:数据科学时代的开发新范式
在人工智能与大数据蓬勃发展的今天,Python数据科学已成为技术领域最热门的方向之一。从商业智能分析到机器学习预测,从金融风控到医疗诊断,数据科学正在重塑各行各业的决策方式。然而,对于许多初学者而言,数据科学项目的入门门槛并不低------需要配置复杂的Python环境、安装数十个依赖库、管理不同版本的数据处理工具。
AtomCode 作为AtomGit推出的云端IDE,为数据科学开发提供了全新的解决方案。它预装了完整的Python数据科学工具链(pandas、numpy、matplotlib、scikit-learn等),支持Jupyter Notebook原生运行,让开发者打开浏览器即可开始数据分析。本文将以一个电商销售数据分析的实战项目为例,完整演示从数据清洗到可视化、从探索分析到机器学习建模、再到自动化数据管道的全流程,所有操作均在AtomCode中完成。
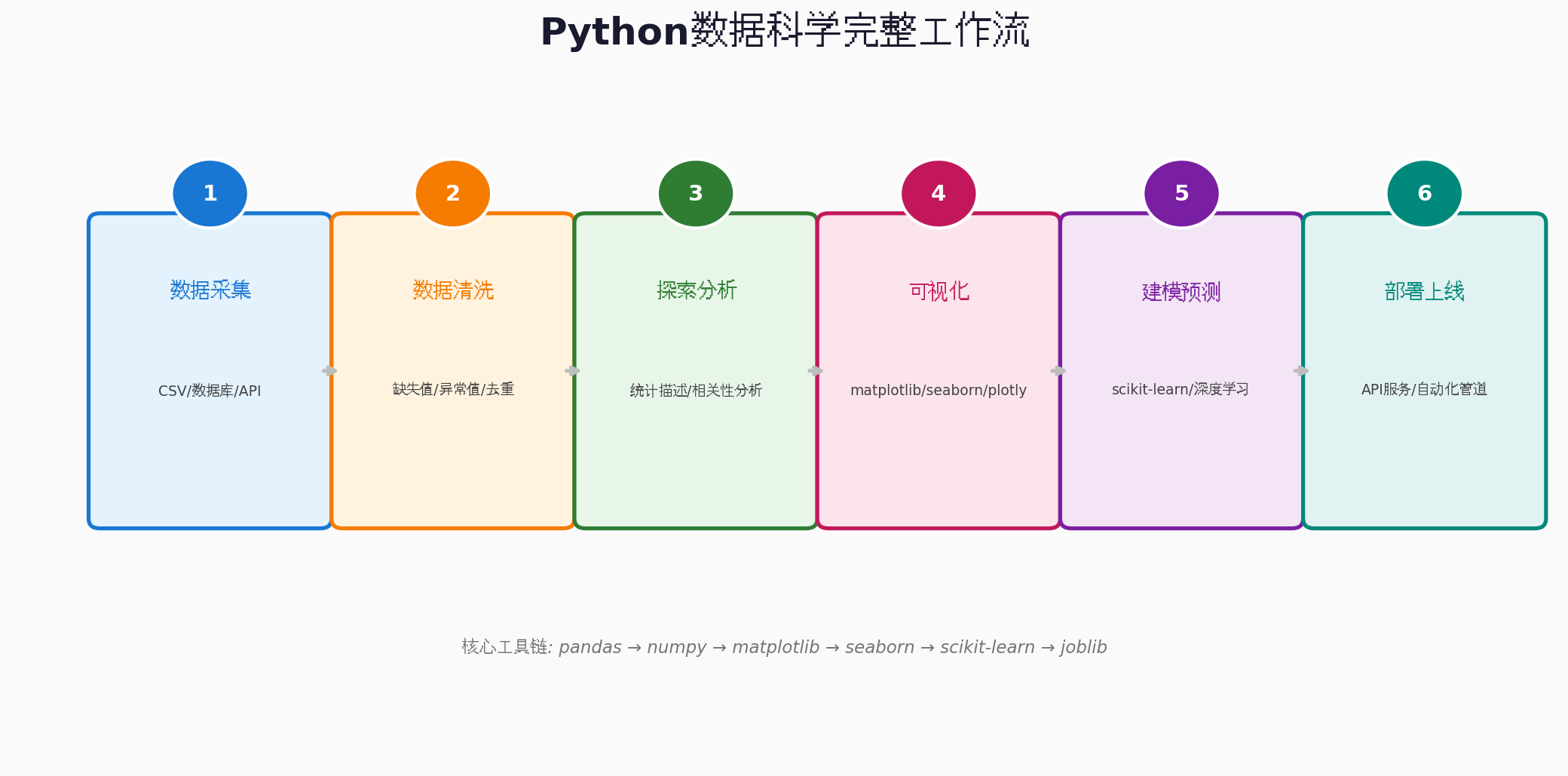
二、环境准备:AtomCode中的数据科学工作站
2.1 开箱即用的Python环境
在AtomCode中创建Python项目后,你会发现以下工具已预装就绪:
bash
# 查看已安装的常用库
pip list | grep -E "pandas|numpy|matplotlib|seaborn|scikit-learn|jupyter"
# 输出示例:
# pandas 2.2.0
# numpy 1.26.0
# matplotlib 3.8.0
# seaborn 0.13.0
# scikit-learn 1.4.0
# jupyter 1.0.0
# plotly 5.18.0这意味着你无需执行任何安装命令,即可开始数据科学项目。对于需要额外库的情况,AtomCode提供了虚拟环境隔离:
bash
# 创建项目专属虚拟环境
python -m venv venv
source venv/bin/activate
# 安装项目依赖
pip install -r requirements.txt2.2 启动Jupyter Notebook
AtomCode原生支持Jupyter Notebook,直接在终端输入:
bash
jupyter notebook --ip=0.0.0.0 --port=8888 --no-browser然后在浏览器中访问提供的URL,即可打开交互式Notebook界面。与传统本地环境相比,AtomCode的Jupyter具有以下优势:
- 云端持久化:Notebook文件自动保存在云端,换设备也能继续工作
- 计算资源弹性:可根据数据量大小选择不同配置的计算实例
- 协作共享:一键分享Notebook链接,团队成员可实时查看和编辑
三、数据清洗与预处理:让脏数据变干净
俗话说"数据科学家80%的时间都在清洗数据",数据清洗是数据分析的第一步,也是最关键的一步。本文以一份电商销售数据为例,演示完整的清洗流程。
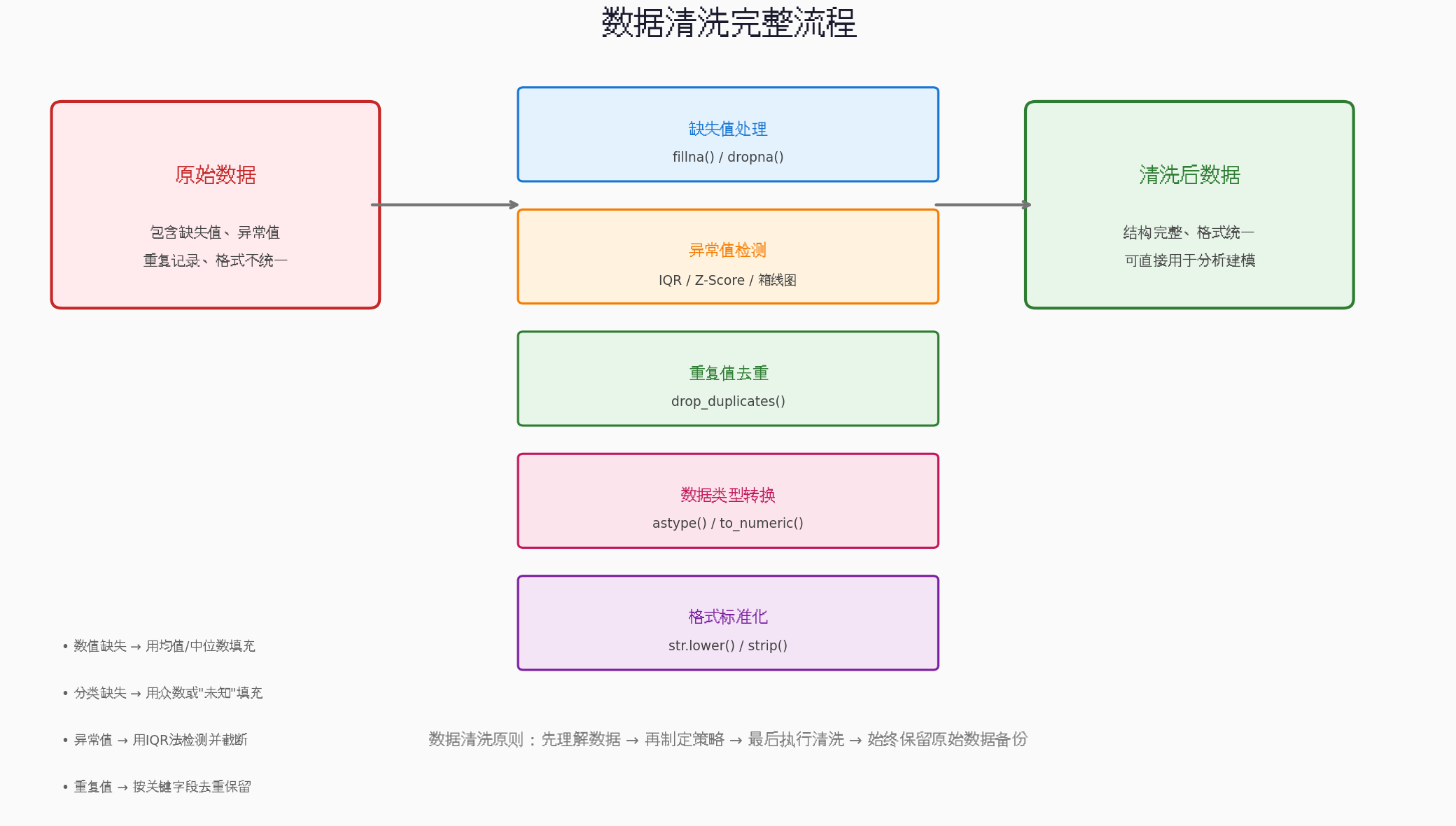
3.1 数据加载与初步检查
python
import pandas as pd
import numpy as np
# 加载数据(AtomCode支持直接上传CSV文件到工作区)
df = pd.read_csv('ecommerce_sales.csv', engine='pyarrow')
# 查看数据基本信息
print(f"数据形状: {df.shape}")
print(f"\n列名: {df.columns.tolist()}")
print(f"\n数据类型:\n{df.dtypes}")
print(f"\n前5行:\n{df.head()}")3.2 缺失值处理
python
# 统计缺失值情况
missing_info = pd.DataFrame({
'缺失数量': df.isnull().sum(),
'缺失比例': (df.isnull().sum() / len(df) * 100).round(2).astype(str) + '%'
})
print(missing_info[missing_info['缺失数量'] > 0])
# 处理策略:数值型用中位数填充,分类型用众数填充
# 数值列
numeric_cols = df.select_dtypes(include=[np.number]).columns
df[numeric_cols] = df[numeric_cols].fillna(df[numeric_cols].median())
# 分类列
cat_cols = df.select_dtypes(include=['object']).columns
for col in cat_cols:
df[col].fillna(df[col].mode()[0], inplace=True)3.3 异常值检测与处理
使用IQR(四分位距)方法检测异常值:
python
def handle_outliers(df, column):
"""使用IQR方法处理异常值"""
Q1 = df[column].quantile(0.25)
Q3 = df[column].quantile(0.75)
IQR = Q3 - Q1
lower_bound = Q1 - 1.5 * IQR
upper_bound = Q3 + 1.5 * IQR
# 用边界值替换异常值(截断而非删除)
df[column] = df[column].clip(lower=lower_bound, upper=upper_bound)
return df
# 应用到金额相关列
amount_cols = ['price', 'quantity', 'total_amount']
for col in amount_cols:
df = handle_outliers(df, col)3.4 数据类型转换与格式标准化
python
# 日期转换
df['order_date'] = pd.to_datetime(df['order_date'], errors='coerce')
# 分类数据优化内存
df['category'] = df['category'].astype('category')
# 字符串标准化
df['customer_name'] = df['customer_name'].str.strip().str.title()
df['email'] = df['email'].str.lower().str.strip()
# 价格列去除千分位逗号并转为数值
df['price'] = df['price'].astype(str).str.replace(',', '').astype(float)3.5 重复值处理
python
# 检查重复
print(f"重复行数: {df.duplicated().sum()}")
# 基于订单号去重(保留最新记录)
df = df.drop_duplicates(subset=['order_id'], keep='last')
# 最终数据检查
print(f"清洗后数据形状: {df.shape}")
print(f"缺失值总数: {df.isnull().sum().sum()}")3.6 现代链式清洗模式(2026推荐)
pandas 2.x版本支持更优雅的链式操作:
python
df_clean = (
df
.assign(price=lambda d: pd.to_numeric(d['price'], errors='coerce'))
.assign(order_date=lambda d: pd.to_datetime(d['order_date']))
.assign(category=lambda d: d['category'].str.strip().str.title())
.drop_duplicates(subset=['order_id'])
.dropna(subset=['order_id', 'customer_id'])
.reset_index(drop=True)
)这种写法可读性更强、可复现性更好,避免了中间变量的混乱。
四、探索性数据分析(EDA):发现数据中的故事
清洗后的数据需要通过EDA来理解其分布特征、相关关系和潜在模式。
4.1 统计描述
python
# 数值列统计描述
print(df_clean.describe())
# 分类列分布
print(df_clean['category'].value_counts())
print(df_clean['payment_method'].value_counts(normalize=True)) # 占比4.2 分组聚合分析
python
# 2026年推荐的新式聚合语法
category_stats = df_clean.groupby('category', as_index=False).agg(
total_sales=('total_amount', 'sum'),
avg_order_value=('total_amount', 'mean'),
order_count=('order_id', 'count'),
unique_customers=('customer_id', 'nunique')
).sort_values('total_sales', ascending=False)
print(category_stats)4.3 时间序列分析
python
# 按月聚合销售数据
monthly_sales = df_clean.groupby(
df_clean['order_date'].dt.to_period('M')
).agg({
'total_amount': 'sum',
'order_id': 'count'
}).reset_index()
monthly_sales['order_date'] = monthly_sales['order_date'].astype(str)
print(monthly_sales)五、数据可视化:让数据开口说话
Python数据可视化生态丰富,不同场景应选择不同的工具:

5.1 Matplotlib:基础绘图
python
import matplotlib.pyplot as plt
# 设置中文字体(AtomCode已预配置)
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# 月度销售趋势图
fig, ax = plt.subplots(figsize=(12, 6))
ax.plot(monthly_sales['order_date'], monthly_sales['total_amount'],
marker='o', linewidth=2, markersize=8, color='#1976d2')
ax.fill_between(monthly_sales['order_date'], monthly_sales['total_amount'],
alpha=0.3, color='#1976d2')
ax.set_title('2026年月度销售趋势', fontsize=16, fontweight='bold', pad=20)
ax.set_xlabel('月份', fontsize=12)
ax.set_ylabel('销售额 (万元)', fontsize=12)
ax.grid(True, alpha=0.3)
ax.tick_params(axis='x', rotation=45)
# 添加数据标签
for x, y in zip(monthly_sales['order_date'], monthly_sales['total_amount']):
ax.annotate(f'{y:.0f}', xy=(x, y), xytext=(0, 10),
textcoords='offset points', ha='center', fontsize=9)
plt.tight_layout()
plt.show()5.2 Seaborn:统计可视化
python
import seaborn as sns
# 品类销售额分布箱线图
fig, ax = plt.subplots(figsize=(10, 6))
sns.boxplot(data=df_clean, x='category', y='total_amount', palette='Set2', ax=ax)
ax.set_title('各品类订单金额分布', fontsize=16, fontweight='bold')
ax.set_xlabel('商品品类', fontsize=12)
ax.set_ylabel('订单金额 (元)', fontsize=12)
plt.xticks(rotation=45)
plt.tight_layout()
plt.show()
# 相关性热力图
numeric_df = df_clean[['price', 'quantity', 'total_amount', 'customer_age']]
corr_matrix = numeric_df.corr()
fig, ax = plt.subplots(figsize=(8, 6))
sns.heatmap(corr_matrix, annot=True, cmap='RdYlBu_r', center=0,
square=True, fmt='.2f', ax=ax)
ax.set_title('数值特征相关性矩阵', fontsize=16, fontweight='bold')
plt.tight_layout()
plt.show()5.3 Plotly:交互式可视化
python
import plotly.express as px
# 交互式散点图:客单价 vs 购买频次
customer_stats = df_clean.groupby('customer_id').agg(
total_spent=('total_amount', 'sum'),
order_count=('order_id', 'count'),
category=('category', lambda x: x.mode()[0])
).reset_index()
fig = px.scatter(customer_stats, x='order_count', y='total_spent',
color='category', size='total_spent',
hover_data=['customer_id'],
title='客户价值分析:购买频次 vs 消费总额',
labels={'order_count': '购买次数', 'total_spent': '消费总额'})
fig.show()Plotly在Jupyter Notebook中可以直接渲染交互式图表,支持缩放、筛选、悬停查看详情等操作,非常适合数据探索。
六、机器学习模型训练:从数据到预测
当完成数据清洗和探索分析后,下一步是构建预测模型。本文以销售预测为例,演示scikit-learn的完整建模流程。
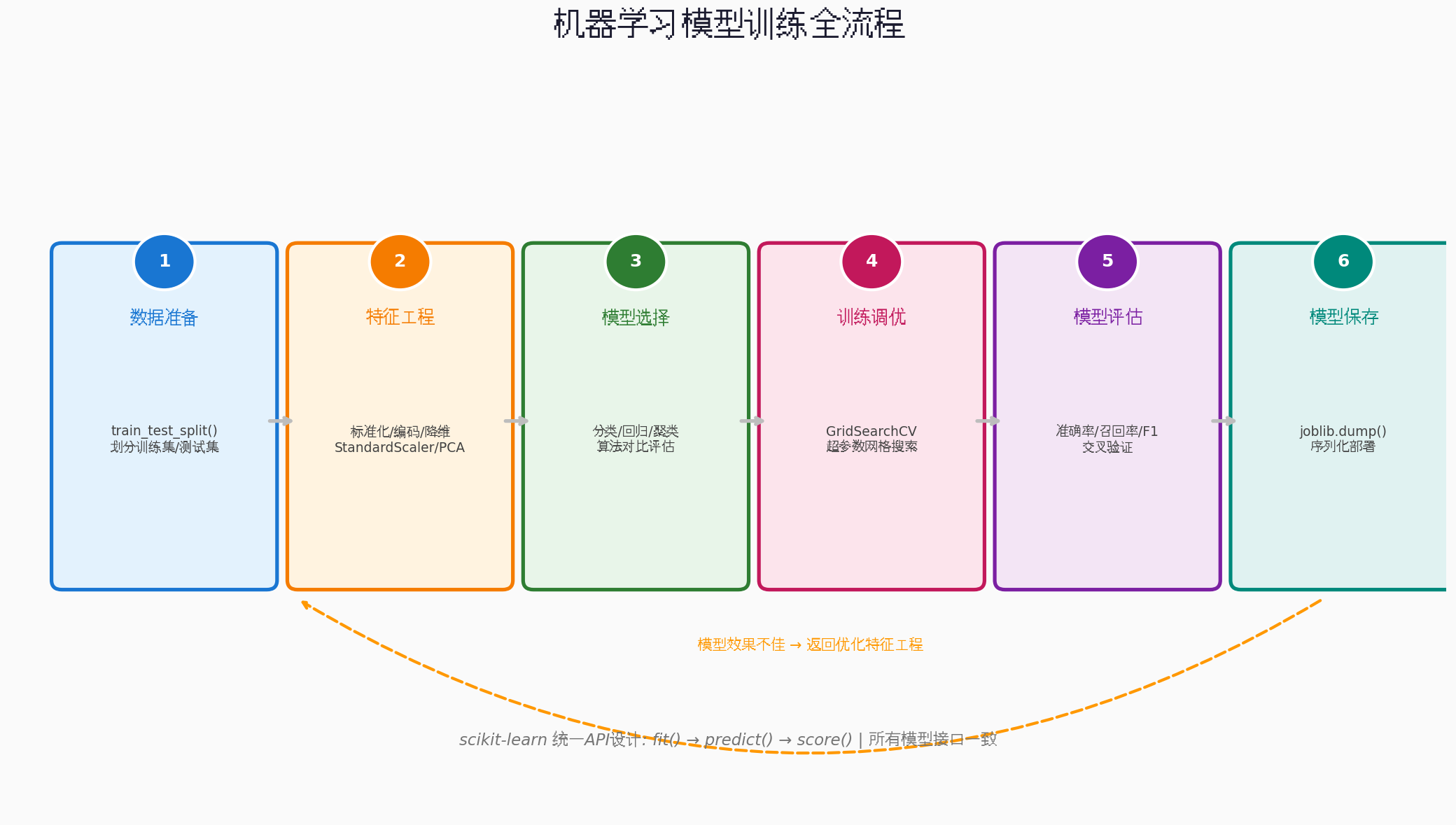
6.1 数据准备与特征工程
python
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler, LabelEncoder
from sklearn.compose import ColumnTransformer
from sklearn.pipeline import Pipeline
# 构建特征
df_model = df_clean.copy()
df_model['month'] = df_model['order_date'].dt.month
df_model['day_of_week'] = df_model['order_date'].dt.dayofweek
df_model['is_weekend'] = df_model['day_of_week'].isin([5, 6]).astype(int)
# 特征与标签
features = ['price', 'quantity', 'month', 'day_of_week', 'is_weekend', 'category']
X = df_model[features]
y = df_model['total_amount']
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42
)6.2 构建预处理管道
python
# 数值特征与分类特征
numeric_features = ['price', 'quantity', 'month', 'day_of_week', 'is_weekend']
categorical_features = ['category']
# 预处理管道
preprocessor = ColumnTransformer(
transformers=[
('num', StandardScaler(), numeric_features),
('cat', OneHotEncoder(drop='first'), categorical_features)
])
# 完整建模管道
from sklearn.ensemble import RandomForestRegressor
model_pipeline = Pipeline([
('preprocessor', preprocessor),
('regressor', RandomForestRegressor(n_estimators=100, random_state=42))
])6.3 模型训练与调优
python
from sklearn.model_selection import GridSearchCV
# 超参数网格搜索
param_grid = {
'regressor__n_estimators': [50, 100, 200],
'regressor__max_depth': [10, 20, None],
'regressor__min_samples_split': [2, 5, 10]
}
grid_search = GridSearchCV(
model_pipeline, param_grid,
cv=5, scoring='neg_mean_squared_error',
n_jobs=-1, verbose=1
)
grid_search.fit(X_train, y_train)
print(f"最佳参数: {grid_search.best_params_}")
print(f"最佳得分: {-grid_search.best_score_:.2f}")6.4 模型评估
python
from sklearn.metrics import mean_squared_error, r2_score, mean_absolute_error
# 使用最佳模型预测
best_model = grid_search.best_estimator_
y_pred = best_model.predict(X_test)
# 评估指标
mse = mean_squared_error(y_test, y_pred)
rmse = np.sqrt(mse)
mae = mean_absolute_error(y_test, y_pred)
r2 = r2_score(y_test, y_pred)
print(f"均方误差 (MSE): {mse:.2f}")
print(f"均方根误差 (RMSE): {rmse:.2f}")
print(f"平均绝对误差 (MAE): {mae:.2f}")
print(f"R² 分数: {r2:.4f}")
# 可视化预测效果
fig, ax = plt.subplots(figsize=(10, 6))
ax.scatter(y_test, y_pred, alpha=0.5, color='#1976d2')
ax.plot([y_test.min(), y_test.max()], [y_test.min(), y_test.max()],
'r--', lw=2, label='完美预测线')
ax.set_xlabel('实际销售额', fontsize=12)
ax.set_ylabel('预测销售额', fontsize=12)
ax.set_title('模型预测效果评估', fontsize=16, fontweight='bold')
ax.legend()
ax.grid(True, alpha=0.3)
plt.tight_layout()
plt.show()6.5 模型保存与加载
python
import joblib
# 保存训练好的模型
joblib.dump(best_model, 'sales_prediction_model.pkl')
# 加载模型用于预测
loaded_model = joblib.load('sales_prediction_model.pkl')
new_prediction = loaded_model.predict(new_data)scikit-learn的统一API设计 (所有模型都有fit()、predict()、score()方法)让模型切换和对比变得异常简单,这也是它成为Python机器学习首选库的重要原因。
七、Jupyter Notebook集成体验:交互式开发的魅力
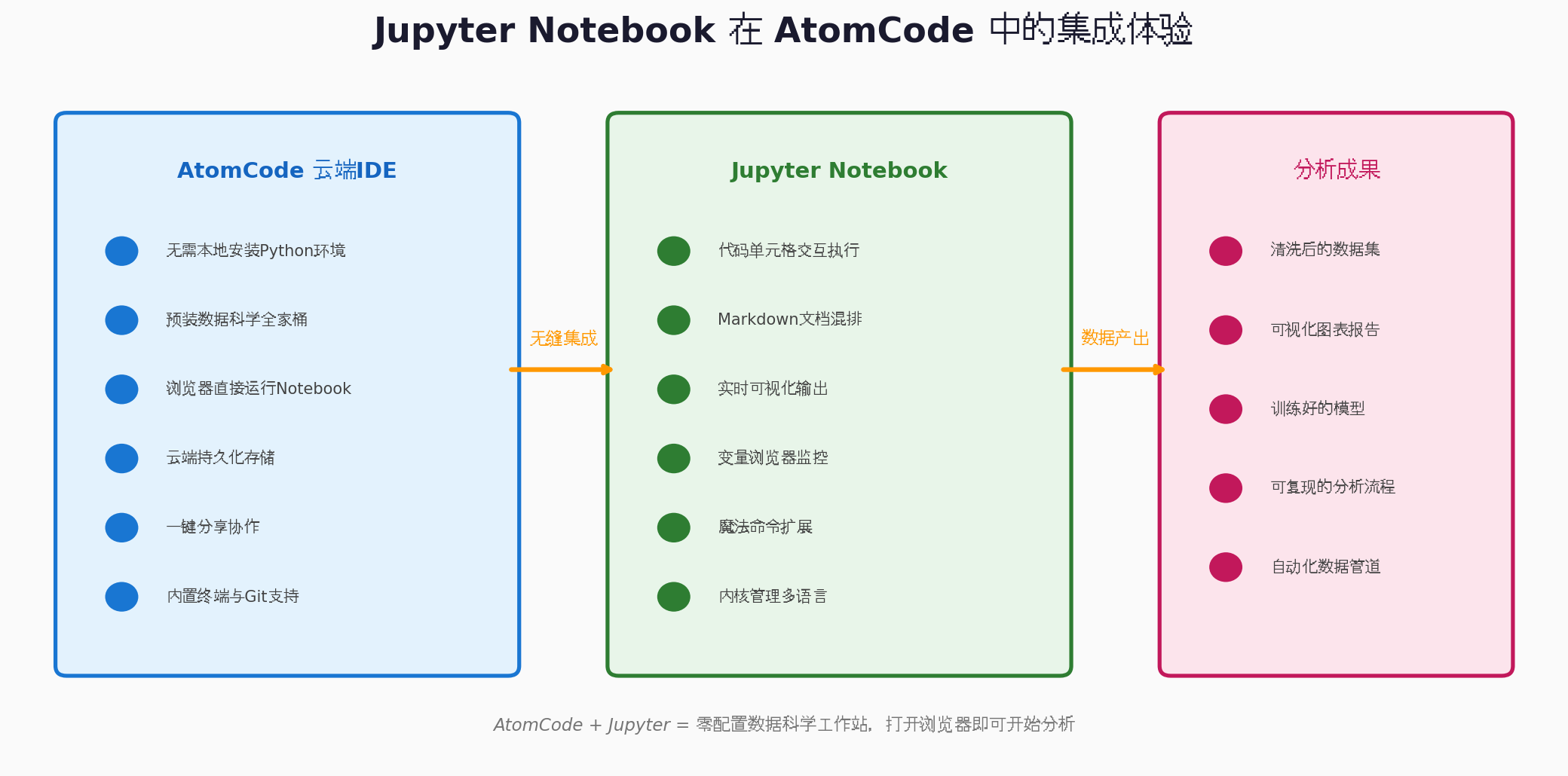
Jupyter Notebook是数据科学领域的"杀手级"工具,它将代码、文档、可视化融为一体。在AtomCode中使用Jupyter Notebook,体验更上一层楼:
7.1 魔法命令提升效率
python
# 查看当前变量
%who
# 测量代码执行时间
%timeit df_clean.groupby('category').agg({'total_amount': 'sum'})
# 加载外部Python文件
%load utils.py
# 查看当前工作目录
%pwd
# 列出文件
%ls7.2 内联可视化
python
# 设置matplotlib在Notebook中内联显示
%matplotlib inline
# 设置高清输出
%config InlineBackend.figure_format = 'retina'7.3 变量浏览器
AtomCode的Jupyter扩展提供了变量浏览器面板,可以实时查看当前Notebook中所有变量的类型、形状和值,极大方便了调试过程。
7.4 与AtomCode的协同优势
| 功能 | 传统本地Jupyter | AtomCode中的Jupyter |
|---|---|---|
| 环境配置 | 需手动安装所有依赖 | 开箱即用,预装数据科学全家桶 |
| 文件管理 | 本地文件系统 | 云端持久化,支持Git版本控制 |
| 计算资源 | 受限于本地硬件 | 弹性计算,大数据量也能流畅处理 |
| 协作分享 | 需额外配置 | 一键生成分享链接 |
| 多设备访问 | 需同步环境 | 任何设备打开浏览器即可继续 |
八、数据管道自动化:从手动到自动
当分析流程稳定后,下一步是将其自动化,实现定时更新、无人值守的数据管道。
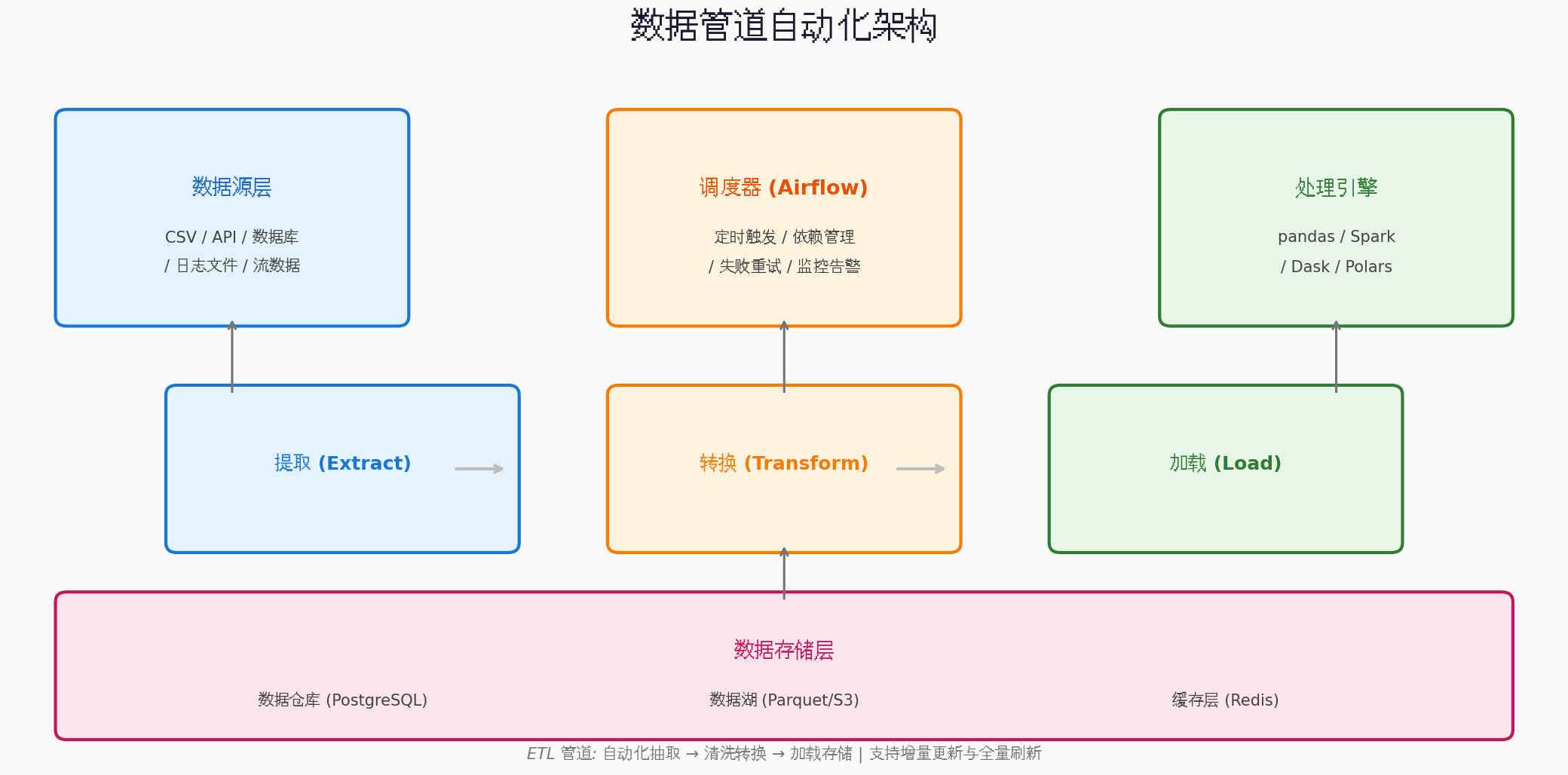
8.1 使用Apache Airflow编排任务
python
# airflow/dags/sales_analysis_dag.py
from airflow import DAG
from airflow.operators.python import PythonOperator
from airflow.providers.mysql.hooks.mysql import MySqlHook
from datetime import datetime, timedelta
default_args = {
'owner': 'data_team',
'depends_on_past': False,
'email_on_failure': True,
'email': ['data@company.com'],
'retries': 3,
'retry_delay': timedelta(minutes=5),
}
def extract_data(**context):
"""从数据库提取昨日数据"""
mysql = MySqlHook(mysql_conn_id='sales_db')
sql = """
SELECT * FROM orders
WHERE DATE(order_date) = DATE_SUB(CURDATE(), INTERVAL 1 DAY)
"""
df = mysql.get_pandas_df(sql)
df.to_csv('/tmp/daily_sales_raw.csv', index=False)
return f"提取了 {len(df)} 条记录"
def transform_data(**context):
"""数据清洗与转换"""
df = pd.read_csv('/tmp/daily_sales_raw.csv')
# 应用清洗逻辑
df_clean = (
df
.assign(order_date=lambda d: pd.to_datetime(d['order_date']))
.drop_duplicates(subset=['order_id'])
.dropna(subset=['order_id', 'customer_id'])
)
df_clean.to_csv('/tmp/daily_sales_clean.csv', index=False)
return f"清洗后剩余 {len(df_clean)} 条记录"
def load_to_warehouse(**context):
"""加载到数据仓库"""
df = pd.read_csv('/tmp/daily_sales_clean.csv')
# 写入数据仓库...
return "数据加载完成"
def generate_report(**context):
"""生成日报"""
# 生成可视化报告并发送邮件...
return "报告已发送"
# DAG定义
with DAG(
'daily_sales_pipeline',
default_args=default_args,
description='每日销售数据处理管道',
schedule_interval='0 6 * * *', # 每天凌晨6点执行
start_date=datetime(2026, 1, 1),
catchup=False,
tags=['sales', 'etl'],
) as dag:
extract = PythonOperator(task_id='extract', python_callable=extract_data)
transform = PythonOperator(task_id='transform', python_callable=transform_data)
load = PythonOperator(task_id='load', python_callable=load_to_warehouse)
report = PythonOperator(task_id='report', python_callable=generate_report)
# 定义依赖关系
extract >> transform >> load >> report8.2 轻量级替代方案:使用Python脚本 + Cron
对于小型项目,可以使用更简单的方案:
python
# pipeline.py
import schedule
import time
def daily_job():
print(f"[{datetime.now()}] 开始执行每日数据处理...")
# 执行数据提取、清洗、分析、保存
print("处理完成!")
# 每天凌晨2点执行
schedule.every().day.at("02:00").do(daily_job)
while True:
schedule.run_pending()
time.sleep(60)九、实战案例:完整的电商销售数据分析
让我们将上述所有技术整合到一个完整的分析项目中。假设你是一家电商公司的数据分析师,需要回答以下业务问题:
9.1 业务问题清单
- 销售趋势:近半年销售额变化趋势如何?
- 品类分析:哪个品类贡献最大?各品类利润率如何?
- 客户画像:高价值客户有什么特征?复购率如何?
- 预测预警:下月销售额预计多少?是否需要备货?
9.2 完整分析代码
python
# 1. 数据加载与清洗
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestRegressor
from sklearn.metrics import r2_score
import joblib
# 加载数据
df = pd.read_csv('ecommerce_sales.csv', engine='pyarrow')
# 清洗
df['order_date'] = pd.to_datetime(df['order_date'])
df['month'] = df['order_date'].dt.month
df['profit'] = df['total_amount'] - df['cost']
# 2. 销售趋势分析
monthly = df.groupby(df['order_date'].dt.to_period('M')).agg({
'total_amount': 'sum',
'order_id': 'count',
'profit': 'sum'
}).reset_index()
monthly['order_date'] = monthly['order_date'].astype(str)
# 3. 品类分析
category_perf = df.groupby('category').agg({
'total_amount': 'sum',
'profit': 'sum',
'order_id': 'count'
}).assign(profit_margin=lambda x: x['profit'] / x['total_amount'] * 100)
category_perf = category_perf.sort_values('total_amount', ascending=False)
# 4. 客户价值分析(RFM模型)
from datetime import datetime
snapshot_date = df['order_date'].max()
rfm = df.groupby('customer_id').agg({
'order_date': lambda x: (snapshot_date - x.max()).days, # Recency
'order_id': 'count', # Frequency
'total_amount': 'sum' # Monetary
}).rename(columns={
'order_date': 'Recency',
'order_id': 'Frequency',
'total_amount': 'Monetary'
})
# 5. 销售预测模型
features = ['month', 'price', 'quantity', 'category']
X = pd.get_dummies(df[features], columns=['category'])
y = df['total_amount']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
model = RandomForestRegressor(n_estimators=100, random_state=42)
model.fit(X_train, y_train)
print(f"模型R²分数: {r2_score(y_test, model.predict(X_test)):.4f}")
# 保存模型
joblib.dump(model, 'sales_forecast_model.pkl')
# 6. 生成可视化报告
fig, axes = plt.subplots(2, 2, figsize=(16, 12))
# 趋势图
axes[0,0].plot(monthly['order_date'], monthly['total_amount'], marker='o')
axes[0,0].set_title('月度销售趋势')
axes[0,0].tick_params(axis='x', rotation=45)
# 品类占比
axes[0,1].pie(category_perf['total_amount'], labels=category_perf.index, autopct='%1.1f%%')
axes[0,1].set_title('品类销售占比')
# RFM散点图
axes[1,0].scatter(rfm['Frequency'], rfm['Monetary'], c=rfm['Recency'], cmap='viridis')
axes[1,0].set_xlabel('购买频次')
axes[1,0].set_ylabel('消费金额')
axes[1,0].set_title('客户价值分布')
# 特征重要性
importances = pd.Series(model.feature_importances_, index=X.columns)
importances.nlargest(10).plot(kind='barh', ax=axes[1,1])
axes[1,1].set_title('预测模型特征重要性')
plt.tight_layout()
plt.savefig('sales_analysis_report.png', dpi=300, bbox_inches='tight')
plt.show()十、总结与展望
通过本文的实战演练,我们完成了一个完整的Python数据科学项目:
| 阶段 | 核心内容 | 关键工具 |
|---|---|---|
| 数据清洗 | 缺失值/异常值/重复值处理 | pandas |
| 探索分析 | 统计描述、分组聚合、相关性 | pandas + numpy |
| 可视化 | 静态图表、统计图、交互图 | matplotlib + seaborn + plotly |
| 机器学习 | 特征工程、模型训练、调优评估 | scikit-learn |
| Notebook | 交互式开发、文档混排、魔法命令 | Jupyter |
| 自动化 | ETL管道、定时任务、工作流编排 | Airflow / schedule |
AtomCode作为云端IDE,在整个数据科学工作流中展现了显著优势:零环境配置、预装工具链、云端协作、弹性计算,让数据科学家可以专注于分析本身而非环境管理。
未来可以进一步探索的方向包括:
- 大数据处理:使用PySpark或Dask处理TB级数据
- 深度学习:集成TensorFlow/PyTorch进行图像/文本分析
- MLOps:构建模型版本管理、A/B测试、监控告警体系
- 实时分析:使用Apache Kafka + Flink实现流式数据处理
Python数据科学生态日趋完善,配合AtomCode的高效开发体验,数据分析师和机器学习工程师可以快速从数据中发现价值、构建智能应用。希望本文能为你的数据科学之旅提供有价值的参考。
转载自:https://blog.csdn.net/u014727709/article/details/162586685
欢迎 👍点赞✍评论⭐收藏,欢迎指正