前言:别再死磕Prompt了,大厂早已换赛道
不知道你有没有踩过这些AI开发大坑:
- 写几千字超长提示词,换个模型输出直接跑偏,疯狂幻觉
- 用Cursor、Trae写代码,简单需求还行,复杂业务库直接逻辑错乱
- 大模型生成结果格式混乱,JSON解析报错,线上频繁崩流程
- 通用大模型不懂你的业务,奶茶店、企业内部系统专业知识一问三不知
前两年全网都在卷Prompt Engineering提示词工程,所有人都在抠完美指令。 但2024-2026行业早就迭代到上下文工程 Context Engineering,再进阶到Harness工程闭环落地。
看完这篇你能学到:
- 搞懂三代LLM工程演进:提示词→上下文→闭环落地工程
- 一套可直接运行的上下文工程Node.js实战代码
- 避开LLM幻觉、格式错乱、业务知识缺失的4个核心坑
- 企业级AI数字化落地完整流程,适配RAG、MCP技能、循环校验

一、时代变了:单纯写Prompt早已跟不上大模型迭代
1.1 早期:Prompt Engineering(22-23年)
核心逻辑:靠人工堆砌详尽指令、示例、步骤,约束大模型输出。 痛点极其明显:
- 提示词越长越难维护,改一个需求整段重写
- 模型存在天然幻觉,只靠文字约束很难消除
- 脱离业务本地数据,通用预训练知识和真实业务脱节
哪怕你打磨出完美提示词,依旧容易翻车。 LLM基于Transformer架构,只会根据预训练文本预测文字,没有实时、专属业务上下文支撑。
1.2 现阶段:Context Engineering 上下文工程(24-25)
行业主流工具:Cursor、Trae、各类企业RAG系统、代码AI助手 核心思路:不依赖纯文字指令,提前结构化注入专属上下文 上下文包含三类核心信息:
- 业务背景:使用者身份、业务场景、目标人群
- 硬性约束:成本、风格、输出格式、限制条件
- 静态资料:本地文档、代码库、业务规则、产品资料
优势肉眼可见:
- 简短Prompt就能拿到高质量结果,不用长篇大论
- 把代码库、业务文档作为上下文,AI深度贴合业务
- 大幅降低幻觉,输出稳定性提升数倍
- 主流大模型(DeepSeek、Claude4.6、Gemini3)自动适配上下文逻辑
1.3 下一代:Harness Engineering 闭环落地工程(25-26)
当下成熟企业AI数字化标准方案,完整链路: 用户简易Prompt → LLM自动优化提示词+注入上下文+加载MCP技能 → 模型生成内容 → 循环校验Loop + 安全围栏Harness约束 → 标准化工程落地FDE 配套能力:
- LLM安全围栏:限制违规输出,规避风险
- Loop循环校验:自动重试、修正错误格式
- MCP标准化技能:给大模型赋予工具调用、数据查询能力 彻底解决"AI生成好看,但无法上线"的行业通病。
二、实战落地:奶茶店饮品研发AI(完整可运行代码)
2.1 业务场景
我是高校周边奶茶店老板,客群17-22岁学生,客单价15-20元。 需求:夏季清爽新品,单杯成本≤8元,颜值高适合学生发朋友圈,输出标准JSON方便后台导入。
2.2 完整Node.js代码(DeepSeek兼容OpenAI接口)
新建index.js,依赖dotenv、openai
javascript
import 'dotenv/config';
import OpenAI from 'openai';
// 初始化大模型客户端,兼容DeepSeek、OpenAI、Claude
const client = new OpenAI({
apiKey: process.env.DEEPSEEK_API_KEY,
baseURL: process.env.DEEPSEEK_BASE_URL
});
// 【上下文工程核心】结构化拆分上下文,解耦易维护
const context = {
// 背景:身份、场景、用户画像
background: "我是大学附近的奶茶店老板,客户多是17-22岁学生, 客单价15-20元",
// 硬性约束:成本、季节、限制条件
constraints: "夏季要清爽, 成本控制在8元内 ",
// 输出规范:统一格式,避免解析报错
outputRequirements: `要颜值高(适合拍照发朋友圈), 请输出纯JSON,无多余文字,包含
饮料名、配料、成本、定价。
`
}
// 系统提示词统一拼接结构化上下文,可读性拉满
const systemPrompt = `
你是一个专业的饮品研发专家,请严格依据下方上下文完成新品研发。
【业务背景】 ${context.background}
【硬性约束】 ${context.constraints}
【输出强制要求】${context.outputRequirements}
`
// 封装生成函数,增加双重容错(网络异常+JSON格式异常)
async function generateNewTea() {
try {
console.log(`正在请求大模型,上下文工程已就绪...`);
const completion = await client.chat.completions.create({
model: "deepseek-v4-pro",
messages: [
{
role: "system",
content: systemPrompt
},
{
role: "user",
content: "请开始你的研发设计"
}
],
temperature: 0.7 // 适度创造力,平衡稳定与创意
});
const aiResponse = completion.choices[0].message.content;
console.log("\n AI 研发成果原始返回:");
console.log(aiResponse);
// 第一层容错:校验JSON格式,解决线上解析崩溃问题
try {
const jsonData = JSON.parse(aiResponse);
console.log("✅ 成功解析为JSON 对象", jsonData);
} catch(err) {
console.log("❌ 返回内容非标准JSON,需开启Loop循环重生成");
}
} catch(err) {
// 第二层容错:捕获接口超时、密钥错误、服务限流等网络异常
console.error("大模型接口请求失败:", err.message);
}
}
// 执行函数
generateNewTea();2.3 环境配置 .env
env
DEEPSEEK_API_KEY=你的密钥
DEEPSEEK_BASE_URL=https://api.deepseek.com/v1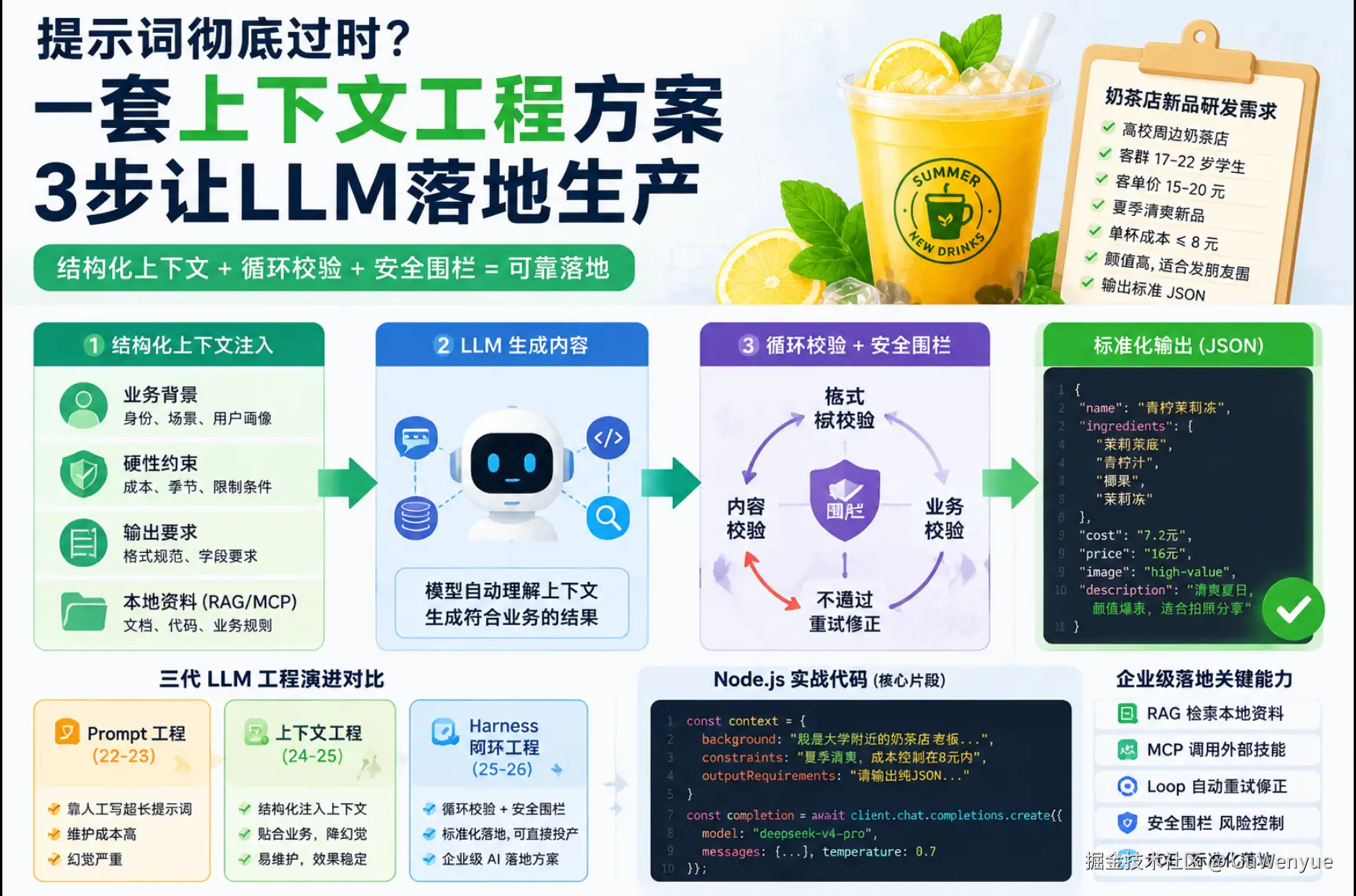
2.4 运行&效果说明
- 安装依赖:
npm i dotenv openai - 填充密钥后执行
node index.js - 模型会自动结合奶茶店场景、成本约束输出标准化JSON
- 相比直接写零散prompt,结构化上下文修改需求只改context对象,不用大段重写提示词
三、上下文工程落地4个高频踩坑提醒
坑1:上下文杂乱无章,全部塞进一句话
很多新手把背景、约束、格式混在一段文字里,模型识别优先级混乱。 ✅ 正确做法:拆分background/constraints/outputRequirements,分段标注,层级清晰。
坑2:忽略格式容错,直接JSON.parse
大模型偶尔会附带解释文字、markdown代码块,直接解析必报错。 ✅ 正确做法:增加try-catch捕获格式异常,搭配Loop工程自动重试生成。
坑3:只用通用大模型,不注入本地业务资料
通用模型预训练数据滞后,不懂企业内部代码、业务规则,幻觉严重。 ✅ 正确做法:搭配RAG检索本地文档、代码库作为补充上下文。
坑4:停留在上下文,缺少Harness安全约束
无围栏限制时,AI可能输出违规内容、超出成本、偏离业务目标。 ✅ 正确做法:增加校验循环,生成后自动校验成本、格式、合规性,不合格重新生成。
四、对比总结:三代LLM工程化优劣一览
| 方案 | 适用阶段 | 优点 | 致命短板 |
|---|---|---|---|
| Prompt工程 | 22-23早期模型 | 上手简单,无需额外开发 | 维护成本极高,幻觉严重,脱离业务数据 |
| 上下文工程Context | 24-25主流 | 易维护、贴合业务、降低幻觉、适配现代大模型 | 缺少闭环校验,无法保障输出100%可用 |
| Harness闭环工程 | 25-26企业落地 | 标准化、安全可控、自动校验、可直接投产 | 开发链路更长,适合中大型AI项目 |
核心结论
- 个人小工具、简单需求:上下文工程足够,上面奶茶店代码直接复用
- 企业线上AI系统:必须搭配Loop循环校验+安全围栏Harness工程,完成FDE落地
- 不要再死磕超长提示词,结构化上下文才是提效核心
五、最后
传统写提示词的时代已经落幕,现在主流大模型会自动优化用户输入,海量交互数据让AI更懂人类需求。 完整链路:用户简易输入 → 结构化上下文注入 → 模型生成 → 循环校验容错 → 业务落地