🔥 从点积到 Transformer:我终于搞懂大模型是怎么"猜"出下一个词的了
摘要 :很多人天天用 ChatGPT,但不知道它内部怎么运作。本文从最基础的向量点积出发,用生活化的例子,一步步带你理解 Transformer 注意力机制的本质------看完你会发现,大模型的核心就是一堆精心组织的矩阵乘法。
📌 前言:一个让我困惑了很久的问题
我第一次读 Transformer 论文时,被满屏的公式劝退了。Q、K、V、Softmax、多头注意力......每个字都认识,连在一起就不知道在说什么。
后来我发现,理解 Transformer 不需要高深数学。它的一切都建立在两个你初中就学过的概念上:
- 向量点积:衡量两个方向有多"像"
- 矩阵乘法:批量计算点积
把这两个搞懂,Transformer 的注意力机制就是水到渠成的事。
🎯 本文适合谁
- 用过 ChatGPT 但好奇它怎么工作的人
- 想入门 Transformer 但被论文公式劝退的人
- 学过线性代数但忘了差不多的人(我会帮你回忆)
- 想理解大模型底层原理的开发者
Transformer 流程图 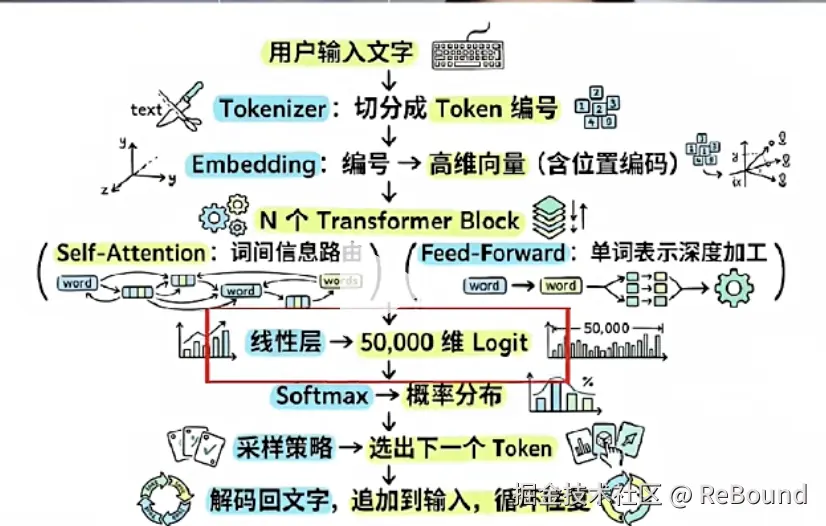
一、从文字到向量:Token、Embedding 与位置编码
1.1 Token:LLM 的字母表
要解决的问题:计算机只认识数字,不认识文字。怎么把"中国的首都是"变成计算机能处理的东西?
模型的第一步是把文字切成 Token(词元):
arduino
"中国的首都是" → ["中国", "的", "首都", "是"]为什么要切词而不是直接用字?如果模型要记住每个完整的词,需要几十万个英文单词和几百万个中文词汇,词表太大了。切成子词后,模型只需要掌握几万个基础"积木",效率大幅提升。
每个 Token 对应一个 Token ID(整数),这就是模型的原始输入。但 Token ID 只是索引号,没有语义------就像字典的页码,页码本身没有意义,翻到那一页才有内容。
1.2 Embedding:给每个词一个"语义坐标"
要解决的问题 :Token ID 只是一个编号(比如 2345),它没有语义。"猫"的 ID 可能是 100,"狗"的 ID 可能是 200,但 100 和 200 之间的数字关系(差 100)跟"猫和狗是相似的动物"完全没关系。我们需要一种方式,让语义相近的词,数字也相近。
模型内部有一个 Embedding 查找表:给定 Token ID,查出对应的语义向量。
yaml
Token ID: 2345 → 查表 → [0.21, -0.05, 0.87, ..., 0.33] (768维向量)这个查找表本质上是一个巨大的矩阵,形状为 [词表大小, 维度],比如 [50000, 768]。每一行就是一个词的"语义坐标"。
💡 Embedding 最神奇的地方:意思相近的词,向量也相近。 比如"猫"和"狗"的向量很接近,"猫"和"汽车"的向量就差很远。
更经典的是,向量还能做加减法捕捉语义关系:
king - man + woman ≈ queen这不是人工设计的,而是模型通过海量文本自动学到的------一个词的含义由它周围的词决定。
1.3 位置编码:告诉模型"谁在前谁在后"
要解决的问题:Transformer 会把一句话里所有词的向量同时处理。但这样一来,"我爱你"和"你爱我"在模型眼里是一样的------因为三个词的向量完全相同,只是顺序不同。我们需要给每个词打上"位置标签"。
原始方案(正弦位置编码):给每个位置生成一个固定的"位置向量",加到词向量上:
scss
PE(pos, 2i) = sin(pos / 10000^(2i/d))
PE(pos, 2i+1) = cos(pos / 10000^(2i/d))
X = Embedding + PE现代方案(RoPE,旋转位置编码) :LLaMA、GPT-NeoX 等模型的主流选择。核心思想------用旋转代替加法:
把向量的每两个维度看作一个二维平面上的点,然后根据位置旋转一个角度:
css
位置 0 的词:[q₁, q₂] 旋转 0°
位置 1 的词:[q₁, q₂] 旋转 θ
位置 2 的词:[q₁, q₂] 旋转 2θ
...💡 RoPE 的巧妙之处 :两个词做点积时,结果只取决于它们的相对距离,与绝对位置无关。就像两个人站在旋转木马上------不管木马转到什么位置,他们之间的角度差是固定的。
实验表明 RoPE 在长序列上表现更好、收敛更快(详见 EleutherAI 的对比实验),这就是为什么 LLaMA、GPT-NeoX 等现代大模型都选择它。
二、向量点积:注意力的数学基础
2.1 什么是点积?
要解决的问题 :我们把每个词变成了一个向量(一组数字)。现在需要一种方法来衡量两个词有多"像"。比如"首都"和"北京"应该很像,"首都"和"吃"应该不太像。点积就是最简单、最高效的衡量方式。
两个等长向量,对应位置相乘再求和:
css
A = [1, 2, 3], B = [4, 5, 6]
A · B = 1×4 + 2×5 + 3×6 = 4 + 10 + 18 = 32就这么简单?对,就这么简单。但它的含义很深。
用一个生活例子来理解:
假设你要比较两个人的电影喜好。每个人对 5 种类型的电影打分(1-10 分):
css
小明:[动作 8, 喜剧 6, 爱情 2, 科幻 9, 恐怖 1]
小红:[动作 7, 喜剧 5, 爱情 3, 科幻 8, 恐怖 2]
小刚:[动作 1, 喜剧 2, 爱情 9, 科幻 1, 恐怖 8]小明和小红的点积:8×7 + 6×5 + 2×3 + 9×8 + 1×2 = 56+30+6+72+2 = 166 小明和小刚的点积:8×1 + 6×2 + 2×9 + 9×1 + 1×8 = 8+12+18+9+8 = 55
点积越大,喜好越相似! 小明和小红(166)明显比小明和小刚(55)更像。
这就是注意力机制的核心------用点积衡量两个词有多相关。
核心直觉:点积越大,两个向量越"像"。
| 方向关系 | 点积值 | 含义 |
|---|---|---|
| 完全一致 | 正数(最大) | 高度相似 |
| 垂直 | 0 | 无关 |
| 完全相反 | 负数(最小) | 对立 |
💡 这是理解注意力机制的关键------注意力的本质就是一堆点积。后面你会看到,Transformer 的所有计算都是围绕"怎么高效地算点积"展开的。
2.2 矩阵乘法:批量点积的工厂
要解决的问题 :一句话有 10 个词,每个词要和其他 9 个词算点积,那就是 10×10=100 次点积。一个一个算太慢了,能不能一次全算出来?
能。这就是矩阵乘法。
矩阵乘法 = 一堆点积的集合。左矩阵的行 × 右矩阵的列 = 结果的一个元素:
css
A (2×3) B (3×2) C (2×2)
┌─────────┐ ┌───────┐ ┌──────────┐
│ 1 2 3 │ │ 4 5 │ │ 40 46 │
│ 4 5 6 │× │ 6 7 │ = │ 94 109 │
└─────────┘ │ 8 9 │ └──────────┘
└───────┘
C[0][0] = 1×4 + 2×6 + 3×8 = 40 ← A的第1行 和 B的第1列 做点积
C[0][1] = 1×5 + 2×7 + 3×9 = 46 ← A的第1行 和 B的第2列 做点积
C[1][0] = 4×4 + 5×6 + 6×8 = 94 ← A的第2行 和 B的第1列 做点积
C[1][1] = 4×5 + 5×7 + 6×9 = 109 ← A的第2行 和 B的第2列 做点积矩阵乘法 = 一次运算,批量完成所有点积。 这就是为什么 Transformer 用矩阵乘法------一句话有多个词,矩阵乘法能一次算出所有词之间的关系。GPU 擅长的正是这种大规模并行运算。
三、注意力机制:Transformer 的心脏 ⭐
这是全文最重要的部分。 理解了这一章,你就理解了 Transformer 的 70%。
3.1 要解决什么问题?
考虑这句话:
"小明把球传给了小红,她很开心。"
当模型处理"她"这个词时,它需要知道"她"指的是谁。是"小明"?还是"小红"?答案显然是"小红"。
核心问题:每个词需要从句子中其他词那里获取信息,但不是所有词都同等重要。 "她"应该重点关注"小红",而不需要关注"球"或"传"。
注意力机制就是解决这个问题的------让每个词自动找到句子中和自己最相关的词,然后重点参考那些词的信息。
3.2 Q、K、V:三个角色各司其职
怎么让一个词找到和自己最相关的词?用一个招聘面试的类比:
想象一个招聘会,每个求职者(词)都有三样东西:
| 角色 | 含义 | 面试类比 | 具体是什么 |
|---|---|---|---|
| Q(Query) | 我在找什么 | 招聘方的问题 | "我需要什么样的信息?" |
| K(Key) | 我能提供什么 | 求职者简历上的标签 | "我身上有什么特征?" |
| V(Value) | 我的详细信息 | 求职者的实际能力 | "如果你选中了我,这是我的全部信息" |
面试过程:
- 招聘方提出问题(Q)
- 每个求职者展示自己的标签(K)
- 招聘方用问题和标签做匹配------点积越大,越匹配
- 匹配度高的求职者,招聘方重点参考他们的能力(V)
回到"她很开心"的例子:
- "她"的 Q = "我在找一个女性名词"
- "小红"的 K = "我是女性名词"
- "小明"的 K = "我是男性名词"
- Q 和"小红"的 K 点积大 → 匹配度高 → 重点参考"小红"的 V
- Q 和"小明"的 K 点积小 → 匹配度低 → 忽略"小明"的 V
为什么要分三个矩阵,而不是一个? 因为"提问的方式"、"展示自己的方式"和"提供信息的方式"应该是不同的。就像同一个人,写简历(Key)、面试提问(Query)和实际工作(Value)时的表现是不一样的。模型通过学习这三个矩阵,自己决定每种角色该怎么演。
3.3 计算过程:一步步拆解
给定输入矩阵 X(每行是一个词的向量),注意力的完整计算分 6 步:
ini
① Q = X × Wq ← 每个词生成自己的"问题"(Query)
② K = X × Wk ← 每个词生成自己的"标签"(Key)
③ V = X × Wv ← 每个词生成自己的"信息"(Value)
④ Score = Q × Kᵀ / √d ← 用点积计算:谁和谁最匹配?
⑤ Weight = Softmax(Score) ← 把分数变成概率(和为1)
⑥ Output = Weight × V ← 按概率加权提取信息合为一行公式:
Attention(Q,K,V)=Softmax(d Q⋅KT)⋅V
接下来我们一步步解释每一步在做什么,以及为什么要这样做。
3.4 第④步详解:为什么要除以 √d?
要解决的问题:假设向量维度 d=64,两个随机初始化的向量做点积,结果的方差大约是 64。也就是说,点积的值可能很大(比如 20、30)。
这么大的数送到 Softmax 里会怎样?看一个例子:
ini
不缩放: Softmax([20, 1, 0.5]) = [0.9999, 0.0001, 0.0000]几乎所有的注意力都集中在一个词上,其他词的权重接近于零。这意味着模型只看一个词,完全忽略了其他词。更严重的是,梯度也接近于零,模型学不动。
除以 √d = √64 = 8 后:
ini
缩放后: Softmax([20/8, 1/8, 0.5/8]) = Softmax([2.5, 0.125, 0.0625])
= [0.85, 0.10, 0.05]现在注意力分布更平滑了,模型能同时关注多个词,梯度也正常了。
💡 一句话总结:除以 √d 是为了防止点积值太大导致 Softmax 变成"只关注一个词"的极端情况。
3.5 第⑤步详解:Softmax 是什么?
要解决的问题 :点积算出来的分数可能是任意数字(比如 3.2、0.5、1.8),有正有负,不方便理解。我们需要把它们变成概率分布------所有值在 0 到 1 之间,加起来等于 1。
Softmax 做的就是这件事:
makefile
原始分数: [3.2, 0.5, 1.8, 0.3]
↓ Softmax(每个数取指数,再归一化)
注意力权重: [0.65, 0.04, 0.17, 0.14] ← 和为 1.0
"中国" "的" "首都" "是"含义:当前词 65% 的注意力给了"中国",16% 给了"首都","的"和"是"几乎被忽略。
3.6 第⑥步详解:加权求和
有了注意力权重后,用它对 V 做加权求和:
makefile
V₁ V₂ V₃ V₄
"中国" "的" "首都" "是"
↓ ↓ ↓ ↓
Output = 0.65 × V₁ + 0.04 × V₂ + 0.16 × V₃ + 0.03 × V₄每个词的输出 = 所有词的 Value 的加权平均,权重就是注意力分数。
💡 直觉理解:注意力机制就像一个"信息聚合器"------每个词根据相关性,从整个句子中提取自己需要的信息,重新表示自己。
3.7 完整例子:手推一遍
假设 2 个词,维度 d=3,权重矩阵为单位矩阵(简化):
ini
输入 X = [[1, 0, 1], ← 词1
[0, 1, 1]] ← 词2
Q = K = V = X(因为权重矩阵是单位矩阵)
① Q × Kᵀ = [[1,0,1], × [[1, 0], [[2, 1],
[0,1,1]] [0, 1], = [1, 2]]
[1, 1]]
逐个计算(就是点积):
Q₁·K₁ = 1×1 + 0×0 + 1×1 = 2 (词1和自己的相似度)
Q₁·K₂ = 1×0 + 0×1 + 1×1 = 1 (词1和词2的相似度)
Q₂·K₁ = 0×1 + 1×0 + 1×1 = 1 (词2和词1的相似度)
Q₂·K₂ = 0×0 + 1×1 + 1×1 = 2 (词2和自己的相似度)
② ÷ √3 ≈ [[1.15, 0.58],
[0.58, 1.15]]
③ Softmax → [[0.64, 0.36], ← 词1: 64%关注自己,36%关注词2
[0.36, 0.64]] ← 词2: 36%关注词1,64%关注自己
④ Output = Weight × V
词1的输出 = 0.64×[1,0,1] + 0.36×[0,1,1] = [0.64, 0.36, 1.00]词1 的新表示 = 64% 自身 + 36% 词2 的信息。 词1 通过注意力机制,从词2 那里获取了一部分信息,丰富了自己的表示。
这就是注意力的全部计算。真实模型只是维度更大(几百到上万维)、词更多(几百到几万个)、层数更深(几十到上百层),数学原理完全一样。
四、因果掩码:只看过去,不看未来
要解决的问题:GPT 的任务是"根据前面的词预测下一个词"。在训练时,模型会一次性看到整句话。但如果不加限制,模型在预测第 3 个词时就能看到第 4、5 个词------这等于考试时偷看答案,学不到东西。
解决方案: 在 Softmax 之前,把"未来位置"的分数设为 -∞。这样 Softmax 后,未来位置的概率就变成 0:
lua
掩码前: [[2.0, 1.0, 0.5], 掩码后: [[2.0, -∞, -∞ ],
[0.8, 1.5, 0.9], → [0.8, 1.5, -∞ ],
[0.4, 0.7, 2.1]] [0.4, 0.7, 2.1]]
Softmax后:
[[1.00, 0.00, 0.00], ← 词1 只看自己(因为后面都被遮住了)
[0.33, 0.67, 0.00], ← 词2 看词1和自己
[0.12, 0.18, 0.70]] ← 词3 看所有词(≈1.0)💡 注意力矩阵变成了下三角矩阵------每个词只能关注自己和之前的词。这就是"因果"(Causal)的含义。
有了因果掩码,模型的推理过程就是逐词生成的:
arduino
第1步: "中国" → 模型预测 → "的"
第2步: "中国 的" → 模型预测 → "首都"
第3步: "中国 的 首都" → 模型预测 → "是"
第4步: "中国 的 首都 是" → 模型预测 → "北京" ✓每一步只生成一个词,然后拼到输入末尾,再跑一次模型。这个过程叫自回归(Autoregressive)生成。
五、多头注意力:多角度看世界
要解决的问题:一个注意力头只能学一种关注模式。但语言是复杂的------
- "她很开心" → 需要关注指代关系("她"→"小红")
- "她跑得很快" → 需要关注动作关系("跑"→"她")
- "红色的球" → 需要关注修饰关系("红色"→"球")
一个头搞不定这么多关系。怎么办?
解决方案:多头注意力------同时运行 12 个注意力机制,每个头用不同的权重矩阵,关注不同的关系模式。最后把 12 个头的结果拼起来。
ini
输入 X [n, 768]
│
├──→ head₁ (d=64) ─┐
├──→ head₂ (d=64) ─┤
├──→ ... ─┤→ Concat → [n, 768] → × Wo → Output
└──→ head₁₂ (d=64) ─┘💡 12 个头,每个只处理 64 维(而不是 768 维),计算量和单头差不多,但能学到 12 种不同的语言关系。就像一群人从不同角度分析同一篇文章------有人关注语法,有人关注逻辑,有人关注情感,综合起来才能全面理解。
六、KV Cache:推理加速的秘密 ⭐
要解决的问题:回顾自回归生成过程------
arduino
第1步: "中国" → 计算 K₁, V₁ → 预测 "的"
第2步: "中国 的" → 重算 K₁, V₁,再算 K₂, V₂ → 预测 "首都"
第3步: "中国 的 首都" → 重算 K₁, V₁, K₂, V₂,再算 K₃, V₃ → 预测 "是"每生成一个新词,所有之前的 K 和 V 都要重新计算一遍!但根据因果掩码,第 2 步中词1 的 K₁ 和 V₁ 跟第 1 步算出来的完全一样------因为它只能看自己,不会因为后面的词而改变。
这是巨大的浪费。
解决方案:KV Cache ------ 把已经计算过的 K 和 V 缓存起来,下一步直接复用,不再重复计算。
makefile
预填充阶段(处理完整输入):
输入 "中国 的 首都 是"
→ 一次性计算所有词的 K, V
→ 存入缓存: K_cache = [K₁, K₂, K₃, K₄], V_cache = [V₁, V₂, V₃, V₄]
→ 用词4("是")的注意力表示预测 "北京"
解码阶段(逐词生成,每次只有1个新词):
输入 "北京"(只有1个新词)
→ 只计算 "北京" 的 Q₅, K₅, V₅
→ 把 K₅, V₅ 追加到缓存
→ Q₅ 与完整的 [K₁,...,K₅] 做注意力
→ 预测下一个词效果
| 方式 | 耗时(GPT-2 生成 1000 token) | 加速比 |
|---|---|---|
| 无 KV Cache | 56.2 秒 | 1× |
| 有 KV Cache | 11.9 秒 | 4.7× |
💡 不改变任何精度,纯靠"空间换时间",推理快近 5 倍。 代价是额外显存------对于长序列推理,KV Cache 可占用数十 GB 显存,这就是为什么大模型推理需要高端 GPU。
核心代码只有几行:
python
# GPT-2 的 KV Cache 实现
if layer_past is not None:
past_key, past_value = layer_past
key = torch.cat((past_key, key), dim=-2) # 把历史 K 和当前 K 拼接
value = torch.cat((past_value, value), dim=-2) # 把历史 V 和当前 V 拼接七、前馈网络(FFN):独立思考
要解决的问题:注意力机制解决了"词与词之间的关系"------每个词通过参考其他词来丰富自己的表示。但每个词自身的语义变换还需要另一个组件。
类比:开完团队讨论会(注意力)后,每个人回到工位独立消化讨论内容,形成自己的理解(FFN)。
scss
FFN(X) = W₂ · GELU(W₁ · X) + X
768→3072→768| 组件 | 职责 | 比喻 |
|---|---|---|
| 注意力层 | 捕捉词与词之间的关系 | 团队讨论 |
| FFN 层 | 对每个词独立做变换 | 独立思考 |
一个 Transformer 块 = 注意力 + FFN,交替进行,层层深入。
7.2 残差连接和 LayerNorm:防止"学着学着就崩了"
你可能注意到流水线图里有"残差连接 & LayerNorm"。这两个组件看似不起眼,但没有它们模型根本训不起来。
残差连接(Residual Connection):把输入直接加到输出上。
scss
输出 = Attention(X) + X ← 不是只算 Attention,还要把原始 X 加回去为什么要加回去?想象你让 96 个人依次修改一篇文章。如果每个人只能看前一个人的版本,改着改着原文就面目全非了。残差连接相当于"保留原稿"------每个人在修改的同时,原文始终在旁边,不会丢失。
从数学上看,残差连接让梯度能直接"跳过"中间层回传,解决了深层网络的梯度消失问题。
Layer Normalization:对每一层的输出做归一化,把数值拉到合理的范围。
scss
LayerNorm([100, 200, 300]) → [−1.22, 0.00, 1.22] ← 数值稳定了为什么要归一化?经过多层矩阵乘法后,数值可能变得很大或很小,导致训练不稳定。LayerNorm 就像一个"调节阀",让每层的输出都在一个稳定的范围内。 96 层下来,每个词的表示越来越"深思熟虑"。
八、完整流水线:从"中国的首都是"到"北京"
把上面所有概念串起来:
scss
输入文本 "中国的首都是"
│
│ ① 分词
▼
["中国", "的", "首都", "是"]
│
│ ② Token ID → Embedding 查表(把文字变成向量)
▼
语义向量矩阵 [4, 768]
│
│ ③ + 位置编码 RoPE(告诉模型谁在前谁在后)
▼
┌─────────────────────────────────────────────────┐
│ Transformer Block × 96 │
│ ┌───────────────────────────────────────────┐ │
│ │ Multi-Head Attention │ │
│ │ Q=X·Wq, K=X·Wk, V=X·Wv │ │
│ │ Score = Softmax(Q·Kᵀ/√d)·V │ │ ← 词与词的关系
│ │ + 因果掩码(只看过去) │ │
│ │ + KV Cache(缓存 K,V) │ │
│ │ + 残差连接 & LayerNorm │ │
│ ├───────────────────────────────────────────┤ │
│ │ FFN (768→3072→768) │ │ ← 每个词独立思考
│ │ + 残差连接 & LayerNorm │ │
│ └───────────────────────────────────────────┘ │
└─────────────────────────────────────────────────┘
│
│ ④ 取最后一个位置的向量,映射到词表大小
▼
线性层 → logits → Softmax
│
│ ⑤ 选概率最高的词
▼
"北京" (92%) ✓九、💡 我的几点思考
写到这里,分享几个我理解 Transformer 后的感悟:
1. 简单的数学,涌现的智能
Transformer 的每一个组件都不复杂------点积、矩阵乘法、Softmax。但当这些简单操作在 96 层、数千亿参数的规模上堆叠时,就涌现出了理解和生成语言的能力。这让我想起一句话:"More is different"(更多就是不同)。
2. 注意力机制的本质是"民主投票"
每个词都有一票(Q),每个词都展示自己的竞选纲领(K),最后根据匹配度分配权重(V)。没有绝对的中心,一切都是相对的。
3. KV Cache 教会我一个工程思维
好的工程不是推翻重来,而是记住已经算过的东西。这个"空间换时间"的思想在计算机科学中无处不在------缓存、记忆化、数据库索引......KV Cache 只是又一次精彩的实践。
📊 重点总结
arduino
向量点积 → 衡量两个词有多"像"
↓
矩阵乘法 → 批量计算点积,一次算出所有词的关系
↓
注意力机制 → Q·Kᵀ 找出谁和谁相关,加权 V 提取信息
↓
因果掩码 → 只看过去,不看未来(自回归生成)
↓
多头注意力 → 12 个头,12 种关注模式
↓
残差连接 + LayerNorm → 保留原稿 + 稳定数值
↓
KV Cache → 缓存 K/V,避免重复计算,加速 5 倍
↓
FFN → 每个词独立变换,消化注意力的结果
↓
96 层堆叠 → 逐层提炼语义 → 预测下一个词Transformer 的本质:用精心设计的矩阵乘法,让模型学会词与词之间的关系,从而理解语言并预测下一个词。
🔗 参考资料
- Attention Is All You Need (2017) --- Transformer 原始论文
- The Illustrated Transformer --- 经典图解
- The Illustrated Word2vec --- Embedding 原理图解
- Rotary Embeddings: A Relative Revolution --- RoPE 原理详解
- 大模型推理优化技术-KV Cache --- KV Cache 原理与实现
💬 你在学习 Transformer 时,哪个概念最难理解? 欢迎评论区聊聊,我会一一回复!
如果这篇文章帮你搞懂了 Transformer,点个赞👍 + 收藏⭐ 让更多人看到。关注我,后续会更新 KV Cache 优化 、FlashAttention 、模型量化 等大模型工程实践系列~
本文首发于掘金,转载请注明出处。
推荐标签 :Transformer 深度学习 大模型 LLM 注意力机制 机器学习 自然语言处理 AI