一、简介
1.1 NumPy
简介
- NumPy(Numerical Python)是Python数据分析必不可少的第三方库。
- Numpy的出现一定程度上解决了Python运算性能不佳的问题,同时提供了更加精确的数据类型,使其具备了构造复杂数据类型的能力。
- 本身是由C语言开发,是个很基础的扩展,NumPy被Python其它科学计算包作为基础包,因此理解np的数据类型对
- NumPy重在数值计算,主要用于多维数组(矩阵)处理的库。用来存储和处理大型矩阵,比Python自身的嵌套列表结构要高效的多.
NumPy重要功能如下
1.高性能科学计算和数据分析的基础包
多维数组,具有矢量运算能力,快速、节省空间2. ndarray,
3.矩阵运算 ,无需循环,可完成类似Matlab中的矢量运算
4.用于读写磁盘数据的工具以及用于操作内存映射文件的工具
是一个运行速度非常快的数学库,主要用于数组计算。包含:
- 一个强大的N维数组对象 ndarray
- 广播功能函数
- 整合 C/C++/Fortran 代码的工具
- 线性代数、傅里叶变换、随机数生成等功能

Numpy属性
NumPy的数组类被称作ndarray,通常被称作数组。ndarray对象属性有:
- ndarray. ndim:纬度,几层嵌套
- ndarray. shape:形状
- ndarray. size:大小,元素个数
- ndarray. dtype:元素类型
- ndarray.itemsize:
1.2 Pandas
- Pandas是一个强大的分析结构化数据的工具集
- 它的使用基础是Numpy(提供高性能的矩阵运算)
- 用于数据挖掘和数据分析,同时也提供数据清洗功能
*- Pandas利器之 Series,是一种类似于一维数组的对象
-
- Pandas利器之 DataFrame,是Pandas中的一个表格型的数据结构

- Pandas利器之 DataFrame,是Pandas中的一个表格型的数据结构
1.3 Matplotlib
Matplotlib是一个功能强大的数据可视化开源Python库。
- Python中使用最多的图形绘图库
- 可以创建静态,动态和交互式的图表

1.4 Seaborn
Seaborn是一个Python数据可视化开源库。
- 建立在matplotlib之上,并集成了pandas的数据结构
- Seaborn通过更简洁的API来绘制信息更丰富,更具吸引力的图像
- 面向数据集的API,与Pandas配合使用起来比直接使用Matplotlib更方便

1.5 Sklearn
scikit-learn是基于 Python 语言的机器学习工具
- 简单高效的数据挖掘和数据分析工具
- 可供大家在各种环境中重复使用
- 建立在 NumPy ,SciPy 和 matplotlib 上
二、Anaconda
Anaconda 是最流行的数据分析平台,全球两千多万人在使用
- Anaconda 附带了一大批常用数据科学包
- Anaconda 是在 conda(一个包管理器和环境管理器)上发展出来的
- 可以帮助你在计算机上安装和管理数据分析相关包
- 包含了虚拟环境管理工具
bash
conda create -n 虚拟环境名字 python=<python版本号> #创建虚拟环境
conda activate 虚拟环境名字 #进入虚拟环境
conda deactivate 虚拟环境名字 #退出虚拟环境
conda remove-n 虚拟环境名字 --all #删除虚拟环境
conda env list #列举所有环境
conda search <模块> #检索可安装的包的所有版本
conda list <模块> #检查当前环境是否存安装
jupyter notebook #activate后打开jupter三、API
Numpy数组是一个多维的数组对象(矩阵),称为ndarray,具有矢量算术运算能力和复杂的广播能力,并具有执行速
度快和节省空间的特点。注意:ndarray的下标从0开始,且数组里的所有元素必须是相同类型。
arange()
类似 python 的 range(),创建一个一维 ndarrayy数组。
python
import numpy as np
# [ 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14]
print(np.arange(15))
a = np.arange(15).reshape(3, 5)
print(a)
'''
[[ 0 1 2 3 4]
[ 5 6 7 8 9]
[10 11 12 13 14]]
'''
print("数组的纬度", a.shape) #几行几列 (3, 5)
print("数组轴的个数:", a.ndim) #数组纬度,几层, 2纬数组
print("数组元素类型:", a.dtype) # int64
print("数组中每个元素的字节大小:", a.itemsize) # int64占用8字节
print("数组元素的总个数", a.size) # 所有元素个数 15
print("类型:", type(a)) # <class 'numpy.ndarray'>
# 范围 0~10, 步长=2, 类型为int64
# [0 2 4 6 8]
arr = np.arange(0, 10, 2, dtype=np.int64)array()
把Python列表 -> ndarray对象
python
b = np.array([6,7,8])
print("数组b:", b) # [6 7 8]
print("数组b类型:", type(b)) # <class 'numpy.ndarray'>rand()、randint()、uniform()、randn()
随机生成
python
# 生成指定维度大小(3行4列)的随机多维浮点型数据(二维),rand固定区间0.0 ~ 1.0
'''
[[0.31691335 0.90146359 0.82516704 0.46770785]
[0.29621857 0.51238154 0.74082077 0.60887821]
[0.67011043 0.77226119 0.21435528 0.17993468]]
'''
arr = np.random.rand(3, 4)
print(arr)
print(type(arr)) # <class 'numpy.ndarray'>
# 生成指定维度大小(3行4列)的随机多维整型数据(二维),randint()可指定区间(-1,5)
'''
[[ 2 1 2 4]
[ 0 -1 3 0]
[ 1 -1 3 1]]
'''
arr = np.random.randint(-1, 5, size=(3, 4))
# 生成指定维度大小(3行4列)的随机多维小数数据(二维),randint()可指定区间(-1,5)
'''
[[ 2.66014273 1.47597597 3.03103291 4.66081343]
[ 2.01176883 1.14651087 4.91733097 -0.85668461]
[-0.25588651 1.11584233 0.56430666 2.36723165]]
'''
arr = np.random.uniform(-1, 5, size=(3, 4))
# 返回具有标准正态分布的序列
'''
[[ 0.30547271 0.31586077 -1.13650364]
[-0.36588039 -0.97770015 1.24721691]]
'''
arr = np.random.randn(2, 3)astype()
类型转换
python
# 范围 0~10, 步长=2, 类型为int64
# [0 2 4 6 8]
arr = np.arange(0, 10, 2, dtype=np.int64)
print(arr)
# [0. 2. 4. 6. 8.]
arr2 = arr.astype(np.float32)
print(arr2.dtype) # float32logspace()
等比数列 logspace中,开始点和结束点是底数为10的幂我们让开始点为10的0次方,结束点为9次方,元素个数为10
python
# [ 1. 10. 100. 1000.]
a = np.logspace(0, 3, 4)
# base=2 底数为2, 默认为10
# 0: 表示开始为2的0次方
# 3: 表示结束为2的3次方
# 4: 表示个数,生成4个
# 包左包右
# [1. 2. 4. 8.]
a = np.logspace(0, 3, 4, base=2)linspace
等差数列:np.linspace是用于创建一个一维数组,并且是等差数列构成的一维数组,它最常用的有三个参数。
第一个例子,用到三个参数,第一个参数表示起始点,第二个参数表示终止点,第三个参数表示数列的个数。
python
# 1: start 起始
# 10: stop 结束
# 4: num 总个数
# endpoint: 默认True,右闭
# [ 1. 4. 7. 10.]
a = np.linspace(1, 10, 4, endpoint=True, dtype=np.int32)基础API
对数组中的每个元素进行操作。
- np.ceil():向上最接近的整数,参数是 number 或 array
- np.floor():向下最接近的整数,参数是 number 或 array
- np.rint():四舍五入,参数是 number 或 array
- np.isnan():判断元素是否为 NaN(Not a Number),参数是 number 或 array
- np.multiply():元素相乘,参数是 number 或 array
- np. divide():元素相除,参数是 number 或 array
- np.abs():元素的绝对值,参数是 number 或 array
- np. where(condition,x,y):三元运算符,xif condition else y
python
print(np.ceil(arr))
print(np.floor(arr))
print(np.rint(arr))
print(np.abs(arr))
# 相乘:行列数必须相同,等同于 arr * arr
print(np.multiply(arr, arr))
print(np.divide(arr, arr))
# arr中的每个元素是否大于0
print(np.where(arr > 0, 1, -1))统计函数
- np.mean(),np.sum():所有元素的平均值,所有元素的和,参数是 number 或 array
- np. max(),np.min():所有元素的最大值,所有元素的最小值,参数是 number 或 array
- np.std(),np.var ():所有元素的标准差,所有元素的方差,参数是 number 或 array
- np. argmax(),np.argmin():最大值的下标索引值,最小值的下标索引值,参数是 number 或 array
- np.cumsum(),np.cumprod():返回一个一维数组,每个元素都是之前所有元素的 累加和 和 累乘积,参数是 number或 array,多维数组默认统计全部维度,axis参数可以按指定轴心统计,值为0则按列统计,值为1则按行统计。
python
arr = np.arange(12).reshape(3, 4)
'''
[[ 0 1 2 3]
[ 4 5 6 7]
[ 8 9 10 11]]
'''
print(arr)
# [ 0 1 3 6 10 15 21 28 36 45 55 66]
print(np.cumsum(arr)) # 累加和
# 66
print(np.sum(arr)) # 求和
# 列: [12 15 18 21]
print(np.sum(arr, axis=0))
# 行: [ 6 22 38]
print(np.sum(arr, axis=1))去重函数:np.unique():找到唯一值并返回排序结果,类似于Python的set集合
python
arr = np.array([[1, 2, 1], [2, 3, 4]])
'''
[[1 2 1]
[2 3 4]]
'''
print(arr)
# [1 2 3 4]
print(np.unique(arr))排序函数:np.sort() 对数组元素进行排序
python
# [ 1 2 34 5]
arr = np.array([1, 2, 34, 5])
#np.sort()函数排序,返回排序后的副本
# [ 1 2 5 34]
sortarr = np.sort(arr)
# ndarray直接调用sort,在原数据上进行修改
# [ 1 2 5 34]
arr.sort()基本运算
减法、乘法(行列一致和行列不一致)。
数组的算数运算是按照元素的。新的数组被创建并且被结果填充。
python
# [20 30 40 50]
a = np.array([20, 30, 40, 50])
# [0 1 2 3]
b = np.arange(4)
# [20 29 38 47]
c = a - b矩阵乘法:行列数一致
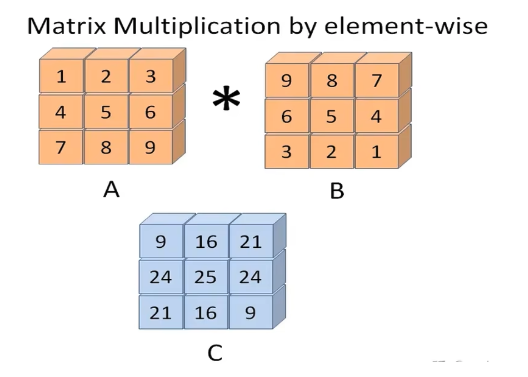
python
a = np.array([[1, 2, 3], [4, 5, 6]])
b = np.array([[1, 2, 3], [4, 5, 6]])
'''
相同位置的元素互相相乘。如
a[0][0] * b[0][0] = 1 * 1 = 1。
a[0][1] * b[0][1] = 2 * 2 = 4。
a[0][2] * b[0][2] = 3 * 3 = 9。
a[1][0] * b[1][0] = 4 * 4 = 16。
a[1][1] * b[1][1] = 5 * 5 = 25。
a[1][2] * b[1][2] = 6 * 6 = 36。
[[ 1 4 9]
[16 25 36]]
'''
# 行列数要一致
print(a * b)
# 必须要求行列数一致
print(np.multiply(a, b))矩阵乘法:行列数不一致
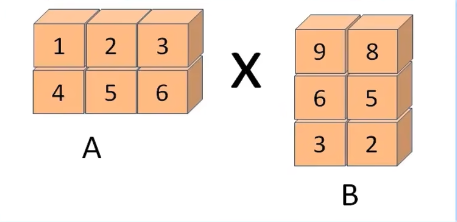
python
'''
[[1 2 3]
[4 5 6]]
'''
x = np.array([[1, 2, 3], [4, 5, 6]])
'''
[[9 8]
[6 5]
[3 2]]
'''
y = np.array([[9, 8], [6, 5], [3, 2]])
'''
x[0][0] * y[0][0]
x[0][1] * y[1][0]
x[0][2] * y[2][0]
[1, 2, 3] * [9, 6, 3] = 1 * 9 + 2 * 6 + 3 * 3 = 9 + 12 + 9 = 30
[1, 2, 3] * [8, 5, 2] = 1 * 8 + 2 * 5 + 3 * 2 = 8 + 10 + 6 = 24
[4, 5, 6] * [9, 6, 3] = 4 * 9 + 5 * 6 + 6 * 3 = 36 + 30 + 18 = 84
[4, 5, 6] * [8, 5, 2]
[[30 24]
[84 69]]
'''
print(x.dot(y))
#print(np.dot(x, y))
print(x @ y) # 行列数不一致通过语法糖@, A列 = B行即可操作,结果是:A行B列