1.3.3 模型类序列化器
如果我们想要使用序列化器对应的是Django的模型类,DRF为我们提供了ModelSerializer模型类序列化器来帮助我们快速创建一个Serializer类。
ModelSerializer与常规的Serializer相同,但提供了:
- 基于模型类自动生成一系列字段
- 基于模型类自动为Serializer生成validators,比如unique_together
- 包含默认的create()和update()的实现
1.3.3.1 定义
比如我们创建一个BookInfoSerializer
python
class BookInfoSerializer(serializers.ModelSerializer):
"""图书数据序列化器"""
class Meta:
model = BookInfo
fields = '__all__'- model 指明参照哪个模型类
- fields 指明为模型类的哪些字段生成
我们可以在python manage.py shell中查看自动生成的BookInfoSerializer的具体实现
python
>>> from booktest.serializers import BookInfoSerializer
>>> serializer = BookInfoSerializer()
>>> serializer
BookInfoSerializer():
id = IntegerField(label='ID', read_only=True)
btitle = CharField(label='名称', max_length=20)
bpub_date = DateField(allow_null=True, label='发布日期', required=False)
bread = IntegerField(label='阅读量', max_value=2147483647, min_value=-2147483648, required=False)
bcomment = IntegerField(label='评论量', max_value=2147483647, min_value=-2147483648, required=False)
image = ImageField(allow_null=True, label='图片', max_length=100, required=False)1.3.3.2 指定字段
\1) 使用fields 来明确字段,__all__表名包含所有字段,也可以写明具体哪些字段,如
python
class BookInfoSerializer(serializers.ModelSerializer):
"""图书数据序列化器"""
class Meta:
model = BookInfo
fields = ('id', 'btitle', 'bpub_date')\2) 使用exclude可以明确排除掉哪些字段
python
class BookInfoSerializer(serializers.ModelSerializer):
"""图书数据序列化器"""
class Meta:
model = BookInfo
exclude = ('image',)\3) 显示指明字段,如:
python
class HeroInfoSerializer(serializers.ModelSerializer):
hbook = BookInfoSerializer()
class Meta:
model = HeroInfo
fields = ('id', 'hname', 'hgender', 'hcomment', 'hbook')\4) 指明只读字段
可以通过read_only_fields指明只读字段,即仅用于序列化输出的字段
python
class BookInfoSerializer(serializers.ModelSerializer):
"""图书数据序列化器"""
class Meta:
model = BookInfo
fields = ('id', 'btitle', 'bpub_date', 'bread', 'bcomment')
read_only_fields = ('id', 'bread', 'bcomment')1.3.3.3 添加额外参数选项
我们可以使用extra_kwargs参数为ModelSerializer添加或修改原有的选项参数
python
class BookInfoSerializer(serializers.ModelSerializer):
"""图书数据序列化器"""
class Meta:
model = BookInfo
fields = ('id', 'btitle', 'bpub_date', 'bread', 'bcomment')
extra_kwargs = {
'bread': {'min_value': 0, 'required': True},
'bcomment': {'min_value': 0, 'required': True},
}
# BookInfoSerializer():
# id = IntegerField(label='ID', read_only=True)
# btitle = CharField(label='名称', max_length=20)
# bpub_date = DateField(allow_null=True, label='发布日期', required=False)
# bread = IntegerField(label='阅读量', max_value=2147483647, min_value=0, required=True)
# bcomment = IntegerField(label='评论量', max_value=2147483647, min_value=0, required=True)1.4 局部全局校验源码分析
python
#is_valid---->self.run_validation-(执行Serializer的run_validation)-->self.to_internal_value(data)---(执行Serializer的run_validation:485行)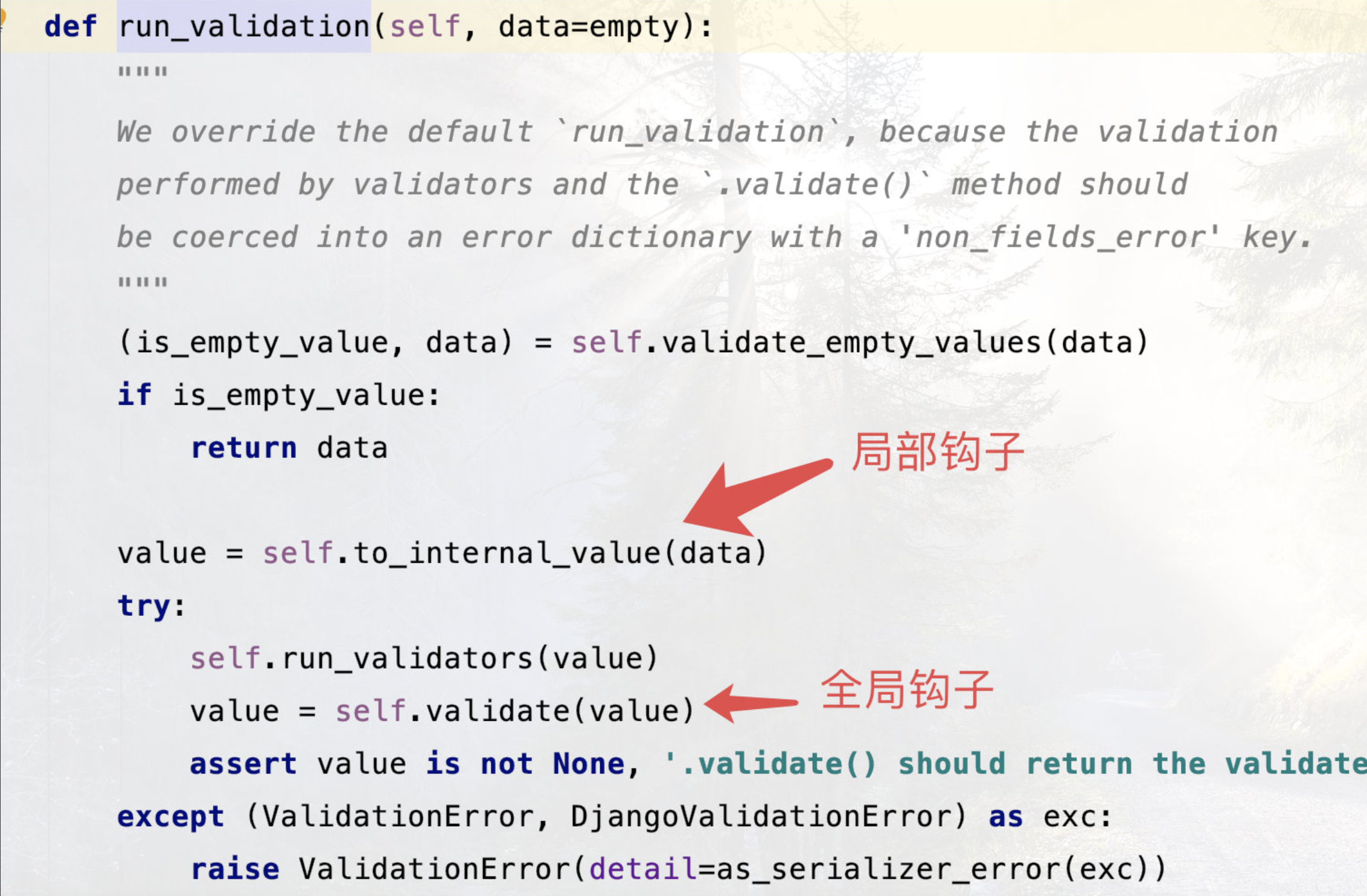
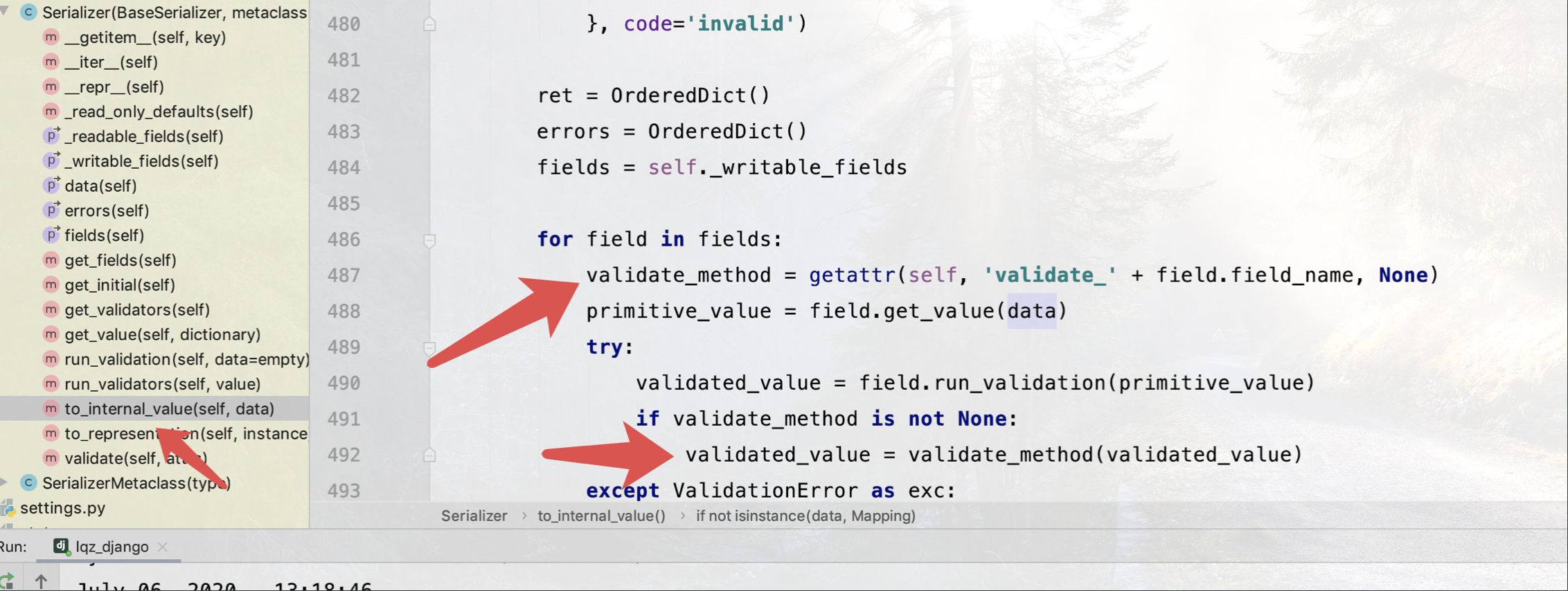
1.5 序列化组件源码分析
python
序列化组件,先调用__new__方法,如果many=True,生成ListSerializer对象,如果为False,生成Serializer对象
序列化对象.data方法--调用父类data方法---调用对象自己的to_representation(自定义的序列化类无此方法,去父类找)
Aerializer类里有to_representation方法,for循环执行attribute = field.get_attribute(instance)
再去Field类里去找get_attribute方法,self.source_attrs就是被切分的source,然后执行get_attribute方法,source_attrs
当参数传过去,判断是方法就加括号执行,是属性就把值取出来