0. 简介
环视BEV已经是很多场景中需要的功能,也是视觉代替激光雷达的有效解决方案,而《SurroundOcc: Multi-camera 3D Occupancy Prediction for Autonomous Driving》一吻则代表了这个领域的SOTA算法,文中通过多帧点云构建了稠密占据栅格数据集,并设计了基于transformer的2D-3D Unet结构的三维占据栅格网络。同时也开源立相关的算法,并可以在Github中找到。
1. 主要贡献
文中提出了一种SurroundOcc方法,旨在通过多摄像头图像输入来预测密集和准确的三维占据情况。
- 我们首先使用一个二维骨干网络从每个图像中提取多尺度特征图。然后,我们执行二维-三维空间注意力,将多摄像头图像信息提升到三维体积特征而不是BEV特征。
- 然后,我们使用三维卷积网络逐步上采样低分辨率体积特征,并将其与高分辨率特征融合,以获得细粒度的三维表示。在每个级别上,我们使用衰减加权损失来监督网络。
- 为了避免昂贵的占据注释,我们设计了一个流程,只使用现有的三维检测和三维语义分割标签生成密集的占据真值。具体而言,我们首先分别组合动态物体和静态场景的多帧点云。然后,我们利用Poisson重建24算法进一步填补空洞。最后,我们使用NN和体素化来获得密集的三维占据标签。有了密集的占据真值,我们训练模型并在nuScenes 7数据集上与其他最先进的方法进行比较。定量结果和可视化结果都证明了我们方法的有效性。
2. 整体流程
2.1 问题阐述

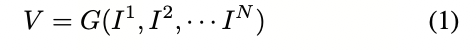

2.2 概述

 图2. 提出方法的流程。首先,我们使用骨干网络提取多摄像头图像的多尺度特征。然后,我们采用2D-3D空间注意力来融合多摄像头信息,并以多尺度方式构建3D体积特征。最后,使用3D反卷积层对3D体积进行上采样,并在每个层级上进行占据预测的监督
图2. 提出方法的流程。首先,我们使用骨干网络提取多摄像头图像的多尺度特征。然后,我们采用2D-3D空间注意力来融合多摄像头信息,并以多尺度方式构建3D体积特征。最后,使用3D反卷积层对3D体积进行上采样,并在每个层级上进行占据预测的监督
2.32D-3D空间注意力
许多3D场景重建方法8, 37通过将多视角2D特征重新投影到已知姿态的3D体积中,将2D特征整合到3D空间中。网格特征通过简单地对该网格中的所有2D特征进行平均计算得到。然而,这种方法假设不同视角对3D体积的贡献相等,这并不总是成立,特别是当一些视角被遮挡或模糊时。



 图3. 基于3D和BEV的交叉视图注意力的比较。基于3D的注意力可以更好地保留3D信息。对于每个3D体积查询,我们将其投影到相应的2D视图中进行特征采样
图3. 基于3D和BEV的交叉视图注意力的比较。基于3D的注意力可以更好地保留3D信息。对于每个3D体积查询,我们将其投影到相应的2D视图中进行特征采样