MYSQL数据库的数据类型(一般只需要用到这些)
整型类型:用于存储整数值,可以选择不同的大小范围来适应特定的整数值。
- TINYINT
- SMALLINT
- MEDIUMINT
- INT
- BIGINT
浮点型类型:用于存储带有小数部分的数值,提供了单精度(FLOAT)和双精度(DOUBLE)两种浮点数类型。
- FLOAT
- DOUBLE
定点数类型:用于精确存储十进制数值,例如货币或精确计数情况下使用。
- DECIMAL
- NUMERIC
日期与时间类型:用于存储日期、时间或日期时间组合。
- DATE
- TIME
- DATETIME
- TIMESTAMP
- YEAR
字符串类型:用于存储文本和字符数据,提供了不同长度和存储方式的选项。
- CHAR
- VARCHAR
- BLOB
- TEXT
- ENUM
- SET
操作数据 库 相关的语句:
数据库创建:
create database if not exists 数据库名
default character set utfmb4 -- 字符集
default collate utf8mb4_unicode_ci; -- 排序规则- 【if not exists,default character set Xxx,default collate Xxx】可以选择是否使用
- 字符集:
- 字符集不同,数据库的存储和显示结果可能不同
- 如utf8mb3:可以存储中文,但不能存储一些特殊字符如表情符号。utf8mb4就可以表情符号。
- 排序规则:对字符进行排序使用的规则
- 比如不同排序规则对中文的标准可能不同,
- 像【一,二,三】这些数据,a规则可能将他们排为【一,二,三】,b规则可能将他们排为【三,一,二】
数据库删除:
drop database if exists 数据库;- 【if exists】可以选择是否使用
数据库修改:
-- 修改数据库的character set:
alter database 数据库 character set utf8mb4;
-- 修改数据库的collate:
alter database 数据库 collate utf8mb4_general_ci;数据库选择
use 数据库操作数据 表 的相关的语句:
数据表创建:
CREATE TABLE IF NOT EXISTS 数据库.数据表 (
id INT AUTO_INCREMENT PRIMARY KEY,
name VARCHAR(50) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NOT NULL,
age INT DEFAULT 18,
email VARCHAR(100) UNIQUE,
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
active BOOLEAN DEFAULT TRUE,
salary DECIMAL(10,2) DEFAULT 0.00,
CONSTRAINT fk_department FOREIGN KEY (department_id) REFERENCES department(id)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_general_ci;- IF NOT EXISTS:用于检查是否存在同名的表,如果不存在则创建。
- AUTO_INCREMENT:使 id字段自动增长,并将其设置为主键。
- CHARACTER SET utf8mb4:设置name 字段的字符集。
- COLLATE utf8mb4_general_ci:设置name 字段的排序规则。
- NOT NULL:确保 name 字段不为空。
- DEFAULT 18:设置 age 字段的默认值为18。
- UNIQUE:确保 email 字段的值是唯一的。
- DEFAULT CURRENT_TIMESTAMP:设置 created_at字段的默认值为当前时间戳。
- BOOLEAN DEFAULT TRUE:设置 active 字段的默认值为 TRUE。
- DECIMAL(10,2) DEFAULT 0.00:设置 salary 字段的数据类型为 DECIMAL,精度为 10 位,小数位为 2位,默认值为 0.00。
- CONSTRAINT fk_department FOREIGN KEY (department_id)REFERENCES department(id):定义了外键约束,将 department_id 字段作为外键关联到department 表的 id 字段。
- ENGINE=InnoDB:设置表的引擎为 InnoDB。
- DEFAULT CHARSET=utf8mb4:默认字符集为 utf8mb4。
- COLLATE=utf8mb4_general_ci:排序规则为utf8mb4_general_ci。
数据表修改
添加新列:
ALTER TABLE table_name ADD COLUMN column_name column_type;
修改现有列:
ALTER TABLE table_name MODIFY COIUMN column_name new_column_tyoe;
删除列:
ALTER TABLE table_name DROP COLUMN column_name;
修改表名:
ALTER TABLE old_table_name RENAME TO new_table_name;
添加约束条件:
ALTER TABLE table_name ADD CONSTRAINT constraint_name constraint_type(column_name);
- constraint_type有:
- UNIQUE:用于确保列中的所有值都是唯一的。
- NOT NULL:用于确保列中的值不为空。
CHECK:用于定义要求满足的条件。
删除约束条件:
ALTER TABLE table_name DROP CONSTRAINT constraint_name;
添加主键:
ALTER TABLE table_name ADD CONSTRAINT pk_constraint_name PRIMARY KEY(column_name);
删除主键:
ALTER TABLE table_name DROP CONSTRAINT pk_constraint_name;
添加外键:
ALTER TABLE table_name ADD CONSTRAINT fk_constraint_name FOREIGN KEY(column_name) REFERENCES other_table(other_column);
删除外键:
ALTER TABLE table_name DROP CONSTRAINT fk_constraint_name;数据表删除
完全删除数据表:
DROP TABLE table_name;
仅删除数据表中的数据,保留数据表的结构:
TRUNCATE TABLE table_name;单表数据增删改查的语句
插入数据
INSERT INTO table_name(column1, column2, ...) VALUES (value1, value2, ...);更新数据
UPDATE table_name SET column1 = value1, column2 = value2, ... WHERE condition;删除数据
DELETE FROM table_name WHERE condition;查询数据
SELETE column1, column2, ... FROM table_name WHERE condition;condition的写法
1.等于(Equal to):
WHERE column = value
2.不等于(Not Equal to):
WHERE column <> value
3.大于(Greater than):
WHERE column > value
4.小于(Less than):
WHERE column < value
5.大于等于(Greater than or equal to):
WHERE column >= value
6.小于等于(Less than or equal to):
WHERE column <= value
7.包含(IN):
WHERE column IN (value1, value2, ...)
8.不包含(NOT IN):
WHERE column NOT IN (value1, value2, ...)
9.模糊匹配(LIKE):
WHERE column LIKE 'pattern'
10.范围(BETWEEN):
WHERE column BETWEEN value1 AND value2
11.空值(IS NULL):
WHERE column IS NULL
12.非空值(IS NOT NULL):
WHERE column IS NOT NULL多表联查的SQL语句
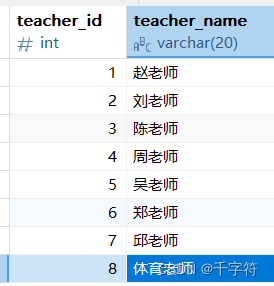
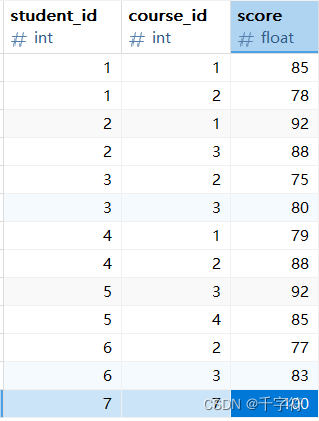
以例子演示:表结构如下:
- students:student_id,student_name
- teachers:teacher_id,teacher_name
- courses:course_id,course_name,teacher_id
- scores:student_id,course_id,score
表数据:


内连接(Inner Join):连接学生、课程和成绩表,找出每个学生所修的课程及成绩
SELECT students.student_name, courses.course_name, scores.score
FROM students
INNER JOIN scores ON students.student_id = scores.student_id
INNER JOIN courses ON scores.course_id = courses.course_id;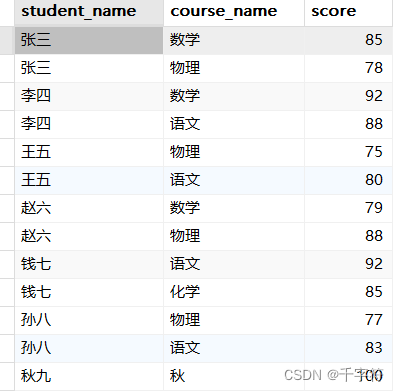
左连接(Left Join):列出每门课程及其对应的老师,即使没有老师也要显示出来
SELECT courses.course_name, teachers.teacher_name
FROM courses
LEFT JOIN teachers ON courses.teacher_id = teachers.teacher_id;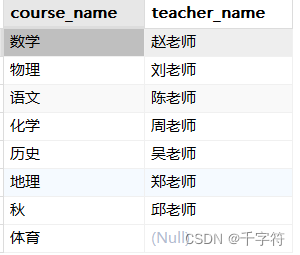
联合查询(Union):
1、将学生表和教师表的姓名合并为一个结果集
SELECT student_name as name FROM students
UNION
SELECT teacher_name as name FROM teachers;
2、将学生、教师和课程表的姓名合并为一个结果集
SELECT student_name as name FROM students
UNION
SELECT teacher_name as name FROM teachers
UNION
SELECT course_name as name FROM courses;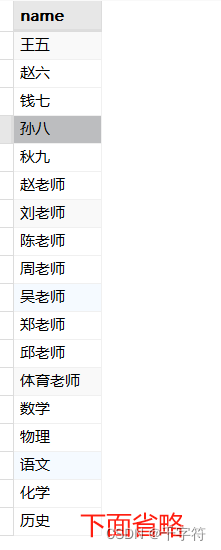
右连接(Right Join):列出每个老师及其对应的课程,即使没有课程也要显示出来
SELECT teachers.teacher_name, courses.course_name
FROM teachers
RIGHT JOIN courses ON teachers.teacher_id = courses.teacher_id;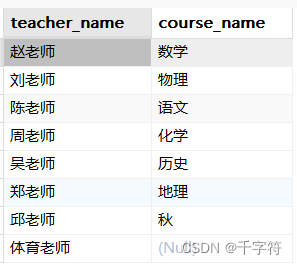
多重连接(Multiple Joins):连接学生、课程、教师和成绩表,找出每个学生所修的课程、对应的老师和成绩
SELECT students.student_name, courses.course_name, teachers.teacher_name, scores.score
FROM students
INNER JOIN scores ON students.student_id = scores.student_id
INNER JOIN courses ON scores.course_id = courses.course_id
INNER JOIN teachers ON courses.teacher_id = teachers.teacher_id;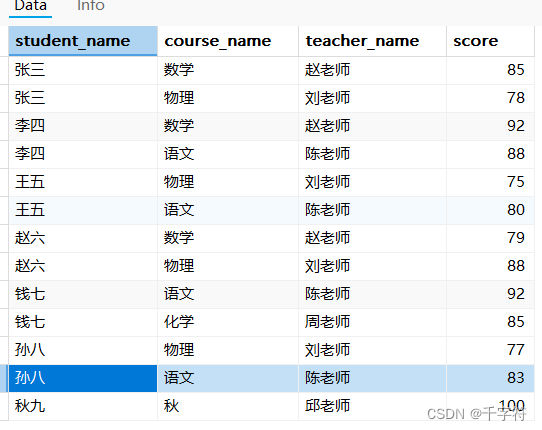
分组联查(Group By):统计每门课程的平均成绩
SELECT courses.course_name, AVG(scores.score) as average_score
FROM courses
LEFT JOIN scores ON courses.course_id = scores.course_id
GROUP BY courses.course_name;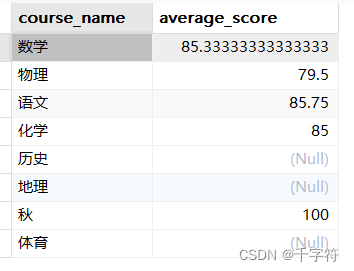
带有条件的联查(Join with Where Clause):找出某个学生所修的所有课程及成绩
SELECT students.student_name, courses.course_name, scores.score
FROM students
INNER JOIN scores ON students.student_id = scores.student_id
INNER JOIN courses ON scores.course_id = courses.course_id
WHERE students.student_name = "John";子查询(Subquery):找出每位学生的平均成绩,并与学生信息进行关联
SELECT students.student_name, average_score
FROM students
LEFT JOIN (
SELECT student_id,AVG(score) as average_score
FROM scores
GROUP BY student_id
) AS subquery
ON students.student_id = subquery.student_id;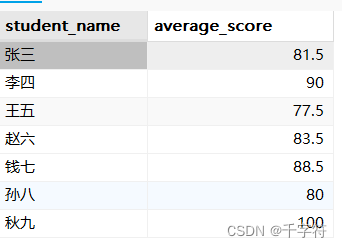
多重连接和条件(Multiple Joins with Conditions):找出每门课程及其对应的老师、学生选修情况和成绩
SELECT courses.course_name, teachers.teacher_name, students.student_name, scores.score
FROM courses
LEFT JOIN teachers ON courses.teacher_id = teachers.teacher_id
LEFT JOIN scores ON courses.course_id = scores.course_id
LEFT JOIN students ON scores.student_id = students.student_id;
多种连接类型组合(Combining Different Join Types):列出所有学生、他们所修的课程及成绩,即使没有成绩也要显示学生和课程信息
SELECT s.student_name, c.course_name, COALESCE(sc.course, "No score") as score
FROM student s
CROSS JOIN courses c
LEFT JOIN score sc ON s.student_id = sc.student_id AND c.course_id = sc.course_id;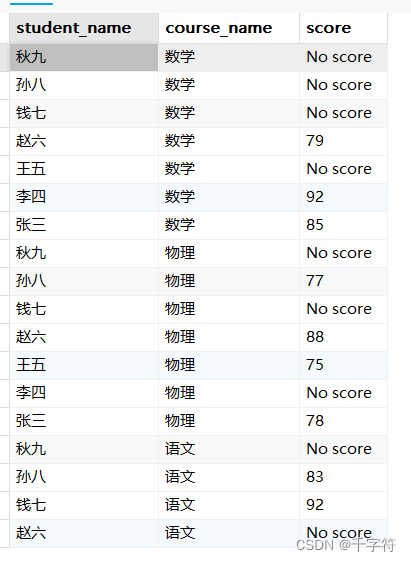
联合查询与排序(Union with Ordering):将学生和老师姓名合并,并按字母顺序排序
SELECT name FROM (
SELECT student_name as name FROM students
UNION
SELECT teacher_name as name FROM teachers
) AS combined_names
ORDER BY name ASC;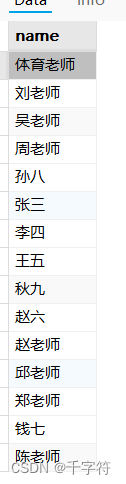
多表联查与分组筛选(Join with Grouping and Filtering):统计每个老师所教课程数超过1门的情况
SELECT teachers.teacher_name, COUNT(courses.course_id) as num_courses_taught
FROM teachers
LEFT JOIN courses ON teachers.teacher_id = courses.teacher_id
GROUP BY teachers.teacher_name
HAVING COUNT(courses.course_id) > 2;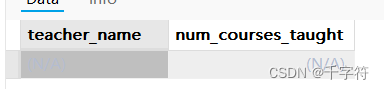
左连接与条件筛选(Left Join with Conditional Filter):找出没有分配老师的课程
SELECT courses.course_name
FROM courses
LEFT JOIN teachers ON courses.teacher_id = teachers.teacher_id
WHERE teachers.teacher_id IS NULL;
多表联查与排名(Join with Ranking):按照成绩排名找出每门课程的前三名学生
SELECT course_name, student_name, score, ranking
FROM (
SELECT courses.course_name,
students.student_name,
scores.score,
RANK() OVER (PARTITION BY courses.course_id ORDER BY scores.score DESC) AS ranking
FROM courses
INNER JOIN scores ON scores.course_id = courses.course_id
INNER JOIN students ON students.student_id = scores.student_id
) AS ranked_scores
WHERE ranking <= 3;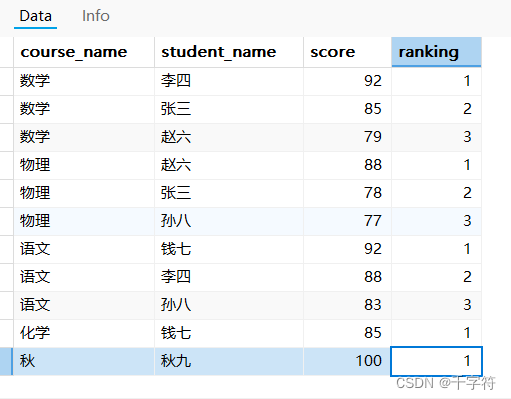
联合查询与条件过滤(Union with Conditional Filtering):将学生和老师姓名合并,并只显示姓氏为"Smith"的人员
SELECT name FROM (
SELECT student_name as name FROM students WHERE student_name LIKE 'Smith%'
UNION
SELECT teacher_name as name FROM teachers WHERE teacher_name LIKE 'Smith%'
) AS combined_names;
MYSQL函数
-- 数学运算
SELECT abs(-10);/*绝对值:0*/
SELECT ceiling(9.4);/*向上取整:10*/
SELECT floor(9.4);/*向下取整:9*/
SELECT rand();/*生成随机数,0~1:0.40571950134422585*/
SELECT sign(122);/*值为0返回0,值为正数返回1,值为负数返回-1:1*/
-- 字符串相关操作
SELECT char_length('123456789');/*获取值的长度:9*/
SELECT concat('a','b','c');/*拼接字符串:abc*/
SELECT insert('1234567',1,2,'a');/*根据位置替换字符串,从第1个位置开始的2个数替换为'a':a34567*/
SELECT lower('Abc');/*小写:abc*/
SELECT upper('Abc');/*大写:ABC*/
SELECT replace('12345678','345','abc');/*根据内容替换字符串,把'345'替换为'abc':12abc678*/
SELECT substr('123456',2,2);/*返回第2个位置开始的2个数:23*/
SELECT instr('1234567','456');/*返回456的第一次的位置,找不到返回0:4*/
SELECT reverse('123456');/*反转:654321*/
-- 日期和时间函数
SELECT current_date();/*获取当前日期:2024-05-31*/
SELECT curdate();/*获取当前日期:2024-05-31*/
SELECT now();/*获取当前时间:2024-05-31 11:28:04*/
SELECT localtime();/*获取当前时间:2024-05-31 11:28:24*/
SELECT sysdate();/*获取当前时间:2024-05-31 11:28:44*/
SELECT year(now());/*获取当前年份:2024*/
SELECT month(now());/*获取当前月份:5*/
SELECT date(now());/*获取当前日期:2024-05-31*/
SELECT hour(now());/*获取当前小时:11*/
SELECT minute(now());/*获取当前分钟:32*/
SELECT second(now());/*获取当前秒数:56*/
-- 聚合函数
USE test;
-- count(...) 对查询到的数据进行统计
SELECT COUNT(1) FROM students;
-- SUM(...) 对查询到的数据进行求和,如果数据不能求和(字符串),返回0
SELECT SUM(scores.score) FROM scores;
-- AVG(...) 对查询到的数据进行求平均值
SELECT AVG(scores.score) FROM scores;
-- MAX(...) 返回查询到的数据的最大值
SELECT MAX(scores.score) FROM scores;
-- MIN(...) 返回查询到的数据的最小值
SELECT MIN(scores.score) FROM scores;